张量(Tensor)
深度学习中的张量
Pytorch 中的张量 Tensor 就是一个多维矩阵,它是 torch.Tensor 类型的对象,比如二阶张量,在数学中就是一个方阵,在 Pytorch 中可以是任意形
状的矩阵。在 PyTorch 中,张量 Tensor 是最基础的运算单位,与 NumPy 中的 NDArray 类似,张量表示的是一个多维矩阵。不同的是,PyTorch 中的
Tensor可以运行在 GPU 上,而 NumPy 的 NDArray 只能运行在 CPU 上。由于 Tensor 能在 GPU 上运行,因此大大加快了运算速度。
我们所要创建的是一个 Tensor 对象,有多种不同数据类型的 Tensor,比如可以通过类 torch.FloatTensor 创建 $32$ 位的浮点型数据类型的 Tensor,
可以通过 torch.DoubleTensor 创建 $64$ 位浮点型数据类型的 Tensor,可以通过 torch.ShortTensor 创建 $16$ 位短整形数据类型的 Tensor......
也可以通过 torch.tensor 来指定类型构建 Tensor 对象。因为 Tensor 和 ndarray 类似,有些细节就不介绍了,可以去阅读博客。
1)torch.tensor():相当于 np.array,使用方法如下:
# data - 可以是list, tuple, numpy array, scalar或其他可以转化为 tensor 的类型,需要注意的是 torch.tensor 总是会复制 data, # dtype - 可以返回想要的 tensor 类型(元素类型) # device - 可以指定返回的设备 # requires_grad - 可以指定是否进行记录图的操作,默认为False torch.tensor(data, dtype=None, device=None, requires_grad=False)
举个例子
a = torch.tensor([[0.1, 1.2], [2.2, 3.1], [4.9, 5.2]])
b = torch.tensor([[0.11111, 0.222222, 0.3333333]],
dtype=torch.float64,
device=torch.device('cuda:0')) # creates a torch.cuda.DoubleTensor
c = torch.tensor(3.14159) # Create a scalar (zero-dimensional tensor)
d = torch.tensor([]) # Create an empty tensor (of size (0,))
print(a)
print(b)
print(c)
print(d)
"""
tensor([[ 0.1000, 1.2000],
[ 2.2000, 3.1000],
[ 4.9000, 5.2000]])
tensor([[ 0.1111, 0.2222, 0.3333]], dtype=torch.float64, device='cuda:0')
tensor(3.1416)
tensor([])
"""
2)torch.randn():返回一个包含了从标准正态分布中抽取的一组随机数的张量,使用方法如下:
# *size - 定义输出张量形状的整数序列,可以是数量可变的参数,也可以是列表或元组之类的集合 # out - 不知道干嘛用 # dtype - 返回张量所需的数据类型,如果未指定,默认为 float64 # layout - 返回张量的期望内存布局,默认值为 torch.strided # device - 指定在哪个设备上分配 tensor 内存,如果没有,则分配在当前设备上 # requires_grad - 说明当前量是否需要在计算中保留对应的梯度信息,默认为 False torch.randn(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
举个例子:
input = torch.rand(2,3,4,5)
print(input)
"""
tensor([[[[0.0281, 0.4571, 0.6217, 0.1217, 0.1928],
[0.3937, 0.9124, 0.1930, 0.8149, 0.9404],
[0.9092, 0.9051, 0.1971, 0.7260, 0.5478],
[0.1046, 0.0478, 0.1549, 0.0515, 0.4044]],
[[0.6168, 0.4144, 0.7250, 0.9009, 0.7051],
[0.6821, 0.1252, 0.7714, 0.7174, 0.6250],
[0.9904, 0.8699, 0.3842, 0.8236, 0.8011],
[0.7210, 0.4677, 0.4332, 0.3709, 0.0096]],
[[0.4517, 0.5964, 0.9885, 0.3398, 0.2666],
[0.1888, 0.1724, 0.0055, 0.8332, 0.5358],
[0.0345, 0.6532, 0.2302, 0.8023, 0.7079],
[0.5355, 0.4972, 0.1681, 0.0654, 0.2454]]],
[[[0.8100, 0.1380, 0.1639, 0.3394, 0.2056],
[0.7924, 0.1002, 0.9050, 0.4262, 0.6235],
[0.7628, 0.0173, 0.5906, 0.0316, 0.7421],
[0.7950, 0.2122, 0.9087, 0.7125, 0.8476]],
[[0.2795, 0.0515, 0.0831, 0.9508, 0.5300],
[0.4314, 0.4104, 0.8774, 0.0929, 0.8994],
[0.7634, 0.3764, 0.9259, 0.1446, 0.6277],
[0.3010, 0.5013, 0.9632, 0.7023, 0.1693]],
[[0.1698, 0.5041, 0.6477, 0.1020, 0.2779],
[0.8552, 0.4449, 0.3214, 0.5170, 0.2851],
[0.4650, 0.0781, 0.2845, 0.0876, 0.1495],
[0.0791, 0.6375, 0.3547, 0.3830, 0.1621]]]])
"""
输出的书写方式是很有规律的,元素如果是标量,则是横着写的,元素如果是矢量,则是竖着写的,括号的对齐方式以及元素之间的空格都可以
方便观察。每个数字可以这么理解:
a. $2$:形状为 $(3,4,5)$ 的张量复制 $2$ 份(里面的元素不一样,只是结构一样)。
b. $3$:形状为 $(4,5)$ 的张量复制 $3$ 份。
c. $4$:形状为 $(5)$ 的张量(其实就是长度为 $5$ 的向量)复制 $4$ 份。
d. $5$:元素为 $5$ 个标量。
3)torch.from_numpy():把数组转换成张量,且二者共享内存,对张量进行修改比如重新赋值,那么原始数组也会相应发生改变。
Tensor torch.from_numpy(ndarray)
举个例子:
import torch import numpy a = numpy.array([1, 2, 3]) t = torch.from_numpy(a) print(t) t[0] = -1 print(a) """ tensor([1, 2, 3], dtype=torch.int32) [-1 2 3] """
3. 张量运算
深度学习中的神经网络本质就是张量运算,有四类张量运算:
1)重塑形状:重塑张量的形状意味着重新排列各个维度的元素个数以匹配目标形状,重塑形成的张量和初始张量有同样的元素。
reshape 不更改原张量形状,而是会生成一个副本。
x = torch.tensor( [[0, 1], [2, 3], [4, 5]], dtype=torch.int)
print(x)
print(x.shape)
x = x.reshape(6, 1) # python 里是按行来获取元素来排列的
print(x)
print(x.shape)
x = x.reshape(2, -1) # 这里在 reshape 函数的第二个参数放的是 -1,意思是我不想费力来设定这一维度的元素个数,python 来帮我算出.
print(x)
print(x.shape)
"""
tensor([[0, 1],
[2, 3],
[4, 5]], dtype=torch.int32)
torch.Size([3, 2])
tensor([[0],
[1],
[2],
[3],
[4],
[5]], dtype=torch.int32)
torch.Size([6, 1])
tensor([[0, 1, 2],
[3, 4, 5]], dtype=torch.int32)
torch.Size([2, 3])
"""
2)元素层面:用运算符 $+,–, *, /$ 来连接两个形状一样的张量 (要不然触发广播机制),只是相同位置的元素进行 $+,–, *, /$ 操作。
x = torch.tensor([2, 3, 4], dtype=torch.int) y = torch.tensor([4, 3, 2], dtype=torch.int) print(x) print(y) print(x + y) print(x - y) print(x * y) print(x / y) """ tensor([2, 3, 4], dtype=torch.int32) tensor([4, 3, 2], dtype=torch.int32) tensor([6, 6, 6], dtype=torch.int32) tensor([-2, 0, 2], dtype=torch.int32) tensor([8, 9, 8], dtype=torch.int32) tensor([0.5000, 1.0000, 2.0000]) """
3)广播机制:当操作两个形状不同的张量时,可能会触发广播机制。广播的张量只会在缺失的维度和长度为 $1$ 的维度上进行。过程如下:
当对两个张量进行 $+-*/$ 时,我们先要写出张量的形状,然后进行右对齐,比较相同位置上的元素个数,如果不同,则操作较少的那个
张量,进行元素复制(元素完全相同),比如有两个张量的形状如下所示:
$$s_{1} = (5, 4, 2, 2) \\
s_{2} = (\;\;\; 1, 1, 1)$$
从尾部开始比较维度,$1 < 2$,所以将 $s_{2}$ 中的标量元素再复制一份,使 $s_{2}$ 的形状变为 $(\;\;\; 1, 1, 2)$;比较倒数第二个元素,$1 < 2$,所以
将 $s_{2}$ 形状为 $(2)$ 的子张量再复制 $1$ 次,此时 $s_{2}$ 的形状变为 $(\;\;\; 1, 2, 2)$;比较倒数第 $3$ 个元素,$1 < 4$,所以将 $s_{2}$ 形状为 $(2,2)$ 的
子张量再复制 $4$ 次,此时 $s_{2}$ 的形状变为 $(\;\;\; 4, 2, 2)$;最后比较第一个元素,发现缺失,于是将 $s_{2}$ 形状为 $(4, 2, 2)$ 的子张量复制 $5$ 次,
这样一来 $s_{1}$ 和 $s_{2}$ 的形状就一致了,就可以进行对应元素的操作。

图中有两行无法进行广播,因为需要维度拓展的位置长度不为 $1$。
4)张量点乘:
a. torch.dot
x = torch.tensor([1, 2, 3], dtype=torch.int) y = torch.tensor([3, 2, 1], dtype=torch.int) print(x) print(y) print(torch.dot(x,y)) # 计算两个张量的点积(内积),不能进行广播(broadcast), 且只允许一维的 tensor, 即向量
b. torch.mm
A = torch.randn(2, 3) B = torch.randn(3, 4) print(A) print(B) print(torch.mm(A,B)) # 执行矩阵乘法,如果 x 为(n x m)张量,y 为(m x p)张量,那么输出(n x p)张量, 此功能不广播
c. torch.matmul
x = torch.tensor([1, 2, 3], dtype=torch.int)
y = torch.tensor([3, 2, 1], dtype=torch.int)
print(torch.matmul(x,y)) # 如果两个张量都是一维的,则返回点积(标量)
A = torch.tensor([[3, 2, 1],
[1, 1, 1]], dtype=torch.int)
B = torch.tensor([[1, 2],
[1, 1],
[3, 4]], dtype=torch.int)
print(torch.matmul(A,B)) # 如果两个参数都是二维的,则返回矩阵矩阵乘积
# 果第一个参数是一维的,而第二个参数是二维的,则为了矩阵乘法,会将 1 附加到其维数上。矩阵相乘后,将删除前置尺寸。
# 也就是让 x 变成矩阵表示,1x3 的矩阵和 3x2 的矩阵,得到 1x2 的矩阵,然后删除 1
print(torch.matmul(x,B))
print(torch.matmul(A,x)) # 返回矩阵向量乘积
"""
tensor(10, dtype=torch.int32)
tensor([[ 8, 12],
[ 5, 7]], dtype=torch.int32)
tensor([12, 16], dtype=torch.int32)
tensor([10, 6], dtype=torch.int32)
"""
如果两个自变量至少为一维且至少一个自变量为 $N$ 维(其中 $N > 2$),则返回批处理矩阵乘法。
""" 针对多维数据 matmul 乘法,我们可以认为该 matmul 乘法使用使用两个参数的后两个维度来计算,其他的维度都可以认 为是 batch 维度。假设两个输入的维度分别是 input(100,50,99,11), other(50, 11, 99),那么我们可以认为 torch.matmul(input, other) 乘法首先是进行后两位矩阵乘法得到 (99,99) ,然后分析两个参数的 batch size 分 别是 (100,50) 和 (50) , 可以广播成为 (100,50), 因此最终输出的维度是 (100,50,99,99) """ x = torch.randn(100,50,99,11) y = torch.randn(50, 11, 99) print(torch.matmul(x, y).size()) """ torch.Size([100, 50, 99, 99]) """
5)次方和次方根运算:操作的是向量或矩阵的每个元素,是元素层面的运算
a. torch.pow:次方运算
b. **:次方运算重载符号
import torch a = torch.tensor([2,3]) print(a) print(a ** 2) print(a.pow(3)) print(torch.pow(a, 4)) """ tensor([2, 3]) tensor([4, 9]) tensor([ 8, 27]) tensor([16, 81]) """
6)torch.max():这个函数是用来消去维度的,被消去的维度只保留最大值,很抽象,下面举个例子来解释一下。
首先需要明白什么是维度 $dim$,一个张量需要几个变量去访问到标量元素,那它的 $dim$ 就是几,比如下面这个张量因为需要 $i,j,k$ 才能
确定一个标量元素,所以 $dim = 3$。在 Pytorch 里面一个张量的维数就是阶数,但在数学里面张量的维数和阶数是两个概念,这要注意一下。
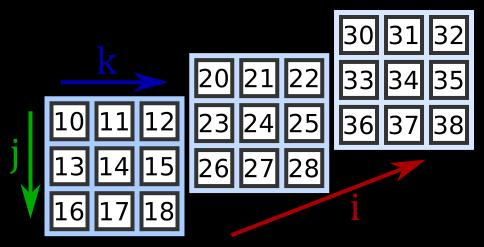
怎么写出来这个张量呢?取决于你怎么定义每个维度的方向。
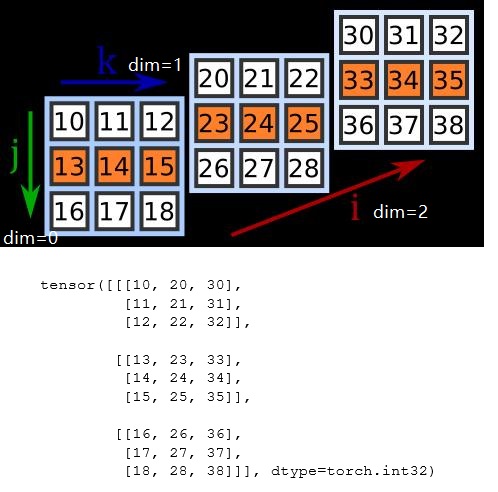
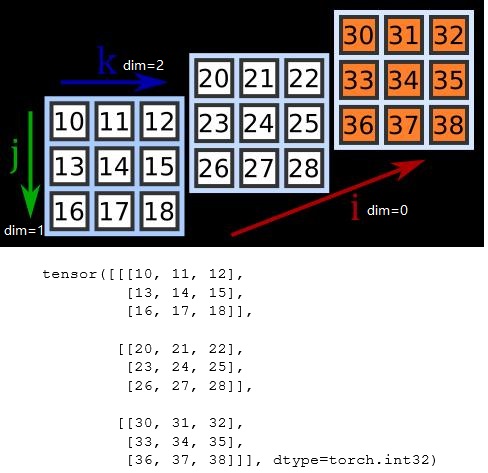
对于左图,$j$ 方向为 $dim=0$ 方向,$j=1$ 可以确定一层纵向的数据(橙色部分)。对于右图,$i$ 方向为 $dim=0$ 方向,$i=2$ 可以得到一平面数据(橙色部分)。
现在我们以左图为例来解释一下 torch.max 函数,其实本质就是一种维度规约的规则。torch.max 函数原型如下:
""" input (Tensor) – the input tensor. dim (int) – the dimension to reduce.即所要消去的那个维度 keepdim (bool) – 输出张量是否保留规约掉的那个维度. Default: False. """ torch.max(input, dim, keepdim=False) -> (Tensor, LongTensor)
现在我们要规约 $dim = 0$,这个张量的维度 $0$ 有三个元素,每个元素都是一个二维矩阵,规约后就只剩下一个元素,即一个二维矩阵。
规约的规则如下:

就是取每个元素相同位置的最大值作为结果矩阵该位置的值,因为规约后这个维度就剩一个元素了,所以该维度可以去掉。代码如下:
import torch
x = torch.tensor([[[10, 20, 30],
[11, 21, 31],
[12, 22, 32]],
[[13, 23, 33],
[14, 24, 34],
[15, 25, 35]],
[[16, 26, 36],
[17, 27, 37],
[18, 28, 38]]],
dtype=torch.int)
z = torch.max(x,dim = 0)
print(z)
"""
torch.return_types.max(
values=tensor([[16, 26, 36],
[17, 27, 37],
[18, 28, 38]], dtype=torch.int32),
indices=tensor([[2, 2, 2],
[2, 2, 2],
[2, 2, 2]]))
"""
现在我们要规约 $dim = 1$,当维度 $0$ 确定的时候,维度 $1$ 有 $3$ 个元素,每个元素是一个向量,现在要把 $3$ 个向量变成一个向量。

就是取每个元素相同位置的最大值作为结果向量该位置的值,举得例子比较极端,刚好最后一个向量就是结果。代码如下:
import torch
x = torch.tensor([[[10, 20, 30],
[11, 21, 31],
[12, 22, 32]],
[[13, 23, 33],
[14, 24, 34],
[15, 25, 35]],
[[16, 26, 36],
[17, 27, 37],
[18, 28, 38]]],
dtype=torch.int)
z = torch.max(x,dim = 1)
print(z)
"""
torch.return_types.max(
values=tensor([[12, 22, 32],
[15, 25, 35],
[18, 28, 38]], dtype=torch.int32),
indices=tensor([[2, 2, 2],
[2, 2, 2],
[2, 2, 2]]))
"""
现在我们要规约 $dim = 2$,当维度 $0,1$ 都确定的时候,维度 $2$ 有 $3$ 个元素,每个元素是一个标量,现在要把 $3$ 个标量变成一个标量。

就是每组向量取最大的那个元素,设置 keepdim=True,代码如下:
import torch
x = torch.tensor([[[10, 20, 30],
[11, 21, 31],
[12, 22, 32]],
[[13, 23, 33],
[14, 24, 34],
[15, 25, 35]],
[[16, 26, 36],
[17, 27, 37],
[18, 28, 38]]],
dtype=torch.int)
z = torch.max(x,dim = 2,keepdim=True)
print(z[0])
"""
tensor([[[30],
[31],
[32]],
[[33],
[34],
[35]],
[[36],
[37],
[38]]], dtype=torch.int32)
"""
7)torch.cat:将两个张量(tensor)拼接在一起。函数原型如下:
""" tensors (sequence of Tensors) – 同类型的 Tensor 序列。除了要拼接的维度外,其它维度的形状必须一样。 dim (int, optional) – 需要拼接的维度 """ torch.cat(tensors, dim=0) -> Tensor
举个例子:
import torch
A = torch.ones(2,3)
B = 2 * torch.ones(2,4)
print(A)
print(B)
C = torch.cat((A, B), 1) # 拼接维度 1
print(C)
"""
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[2., 2., 2., 2.],
[2., 2., 2., 2.]])
tensor([[1., 1., 1., 2., 2., 2., 2.],
[1., 1., 1., 2., 2., 2., 2.]])
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号