Word2vec 原理详解
$2013$ 年,$Google$ 团队发表了 $word2vec$ 工具。$Word2vec$ 工具主要包含两个模型:跳字模型($skip-gram$)和连续词袋模型
($continuous \; bag \; of \; words$,简称 $CBOW$),以及两种高效训练的方法:负采样($negative \; sampling$)和层序 $softmax$($hierarchical \; softmax$)。
1. 语言模型
语言模型是一种对语言打分的方法,而概率语言模型把语言的“得分”通过概率来体现,比如有如下几个词:“小明”,“牛奶”,“打翻”,“了”,“的”。
现在机器根据这几个词造了两个句子:
“小明打翻了桌上的牛奶” # 0.8,比较常见的说法,得分较高 “小明牛奶打翻的桌上了” # 0.1,不太常见的说法,得分比较低
以上过程可以形式化为求解概率
$$P\left (w_{1},w_{2},\cdots,w_{n} \right ) = P(w_{1}^{n})$$
$w_{i}$ 的可能取值来自语料库对应的词典,可以直接通过统计某个句子在语料库中出现的频次,然后除以语料库大小(句子数量),便可以得出对应的概率。
但是这么做每次统计都是独立的,没办法利用已有的统计结果,将上式子利用条件概率公式展开得
$$P( w_{1},w_{2},\cdots,w_{n}) = P(w_{1})P(w_{2} | w_{1})P(w_{3} | w_{1},w_{2}) \cdots P(w_{n} | w_{1},w_{2},\cdots,w_{n-1})$$
其中每个条件概率就是模型的参数,如果这个参数都是已知的,那么就能得到整个序列的概率了。
2. $n-gram$ 统计语言模型
假设语料库 $C$ 足够大,词典大小为 $N$,现在想计算任意一个长度为 $L$ 的句子的概率,需要求得多少个参数呢?
因为每一个长度为 $L$ 的句子都由 $L$ 个条件概率因子相乘,易知第 $i$ 个因子存在 $N^{i}$ 种可能,那么需要存储的因子总数为
$$\sum_{i = 1}^{L}N^{i} = \frac{N(1 - N^{L})}{1 - N} \approx N^{L}$$
假设词汇量 $N = 1000$,那么即使句子长度只取 $2$,这个存储量都达到 $100$ 万了。
$n-gram$ 模型基于马尔可夫假设:一个词出现的概率只与他前面有限的 $n$ 个词相关。最常取的是 $n=2$,对应语言模型被称为是二元模型,此时
概率展开就变成
$$P(w_{1}^{n}) = P(w_{1})P(w_{2} | w_{1})P(w_{3} | w_{2}) \cdots P(w_{n} | w_{n-1})$$
针对之前的问题,在 $n-gram$ 模型下需要存储的参数为
$$N + N^{2} \approx N^{2}$$
即无论句子长度 $L$ 怎么变,就只需要存储将近 $N^{2}$ 个概率值就足够了。
为了得到这些参数,需要在语料库中统计各种词串出现的次数,然后计算概率值并存储起来,下次需要计算一个句子出现的概率时,只需查找相应的
因子然后连乘起来即可,概率计算公式为
$$P(w_{k} | w_{k-1}) \approx \frac{count(w_{k-1}^{k})}{count(w_{k-1})}$$
3. $n-gram$ 神经语言模型
神经概率语言模型依然是一个概率语言模型,它通过神经网络来计算语言模型中每个参数(因子),不妨设 $n = 4$,那么所计算的概率为
$$P(w_{k} | w_{k - 1}, w_{k - 2}, w_{k - 3})$$
要构造这样的神经网络,至少要解决两个问题:
1)如何将一个个词转为能够作为神经网络输入的数值?
2)如何构造条件概率?
将词转为数值采用的是 $one-hot$ 编码:词汇量有多少个,每个词就采用多少维向量,每个向量只有一个坐标为 $1$,其余均为 $0$,形如
$$x = \begin{bmatrix}
0\\
0\\
\vdots \\
1\\
\vdots \\
0
\end{bmatrix}$$
由此可知,编码后的每个词对应的向量均正交,将 $one-hot$ 向量作为神经网络的输入。
将神经网络输出的数值做一个 $softmax$ 归一化,归一化的结果就用来表征条件概率。
设 $n = 3$,词汇量为 $V$,那么 $one-hot$ 向量维度就是 $V$,$n-gram$ 神经网络模型的结构如下图所示:
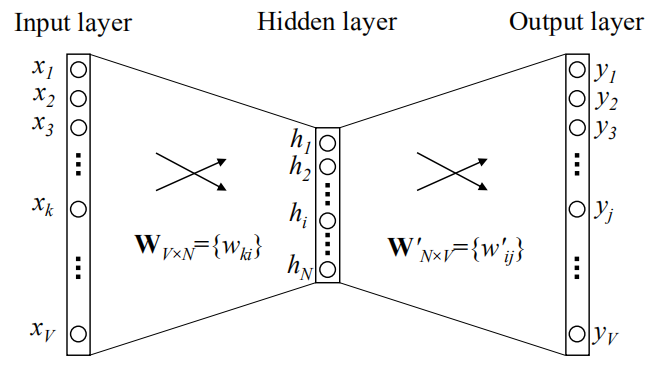
输入层是一个 $V$ 维的 $one-hot$ 向量,在权重矩阵 $W_{V \times N}$ 的作用下,维度从 $V$ 变成了 $N$,即隐藏层输出一个 $N$ 维的向量,
由于 $one-hot$ 向量只有一个维度是 $1$,设 $x_{k} = 1$,那么
$$\begin{bmatrix}
x_{1} & x_{2} & \cdots & x_{k} & \cdots & x_{V}
\end{bmatrix}W_{V \times N} = W_{k}$$
即隐藏层输出就是矩阵 $W$ 的第 $k$ 行向量。
隐藏层的输出向量 $W_{k}$ 在输出层权重矩阵 $W^{'}_{N \times V}$ 的作用下得到一个 $V$ 维向量,对应 $V$ 个神经元的输出,即 $y_{i},i = 1,2,3,...,V$。
这里的矩阵 $W^{'}_{N \times V}$ 并不是矩阵 $W_{V \times N}$ 的转置,它们是两个不同的矩阵。
上面的网络结构少了 $softmax$ 层,输出 $y_{i}$ 还需要做一个归一化转化为概率,即
$$y_{j}^{'} = \frac{e^{y_{j}}}{\sum_{t = 1}^{V}e^{y_{t}}}, j = 1,2,\cdots,V$$
训练的时候,对语料库中的每个句子用长度为 $3$ 的窗口进行滑动,以下面句子为例:
I like playing games very much
用长度为 $3$ 的窗口滑动时,得到如下样本
(I like, playing) (like playing, games) (playing games, very) (games very, much)
对语料库中的每个句子都做这样的窗口滑动,产生用于训练的样本数据集。
对于每组样本,将前两个词对应的向量输入神经网络,比如 $I,like$,我们训练的目的是希望词 $playing$ 对应的神经元输出的概率最高,每一
组样本都希望如此,但事实上不一定会存在使每组样本都满足这个条件的解,于是采用极大似然估计的思想,将目标函数设为
$$L = \sum_{w \in C}^{} \ln P(w | Context(w))$$
对于 $n = 2$,$Context(w)$ 为 $w$ 的前两个词,$C$ 为语料库,用 $w$ 遍历语料库中的每一个词。我们需要最大化这个式子。
训练过程采用的方法是随机梯度上升,即每代入一个样本,就对目标函数中所有的参数($W,W^{'}$)做调整,每次迭代到最后有
$$W,W^{'} = arg \; \max_{W,W^{'}} \; \ln P(w | Context(w))$$
下面来推导一下权重矩阵的更新公式。
1)隐藏层 $\rightarrow$ 输出层
由图可知,隐藏层输出向量为 $h = (h_{1},h_{2},...,h_{N})$,设 $y_{j*}$ 为目标神经元,即使该神经元对应的输出概率 $y$ 最大,对矩阵 $W^{'}$ 进行列分
块得到 $W^{'} = (u_{1},u_{2},...,u_{V})$,于是有
$$y = \ln \frac{e^{y_{j*}}}{\sum_{j = 1}^{V}e^{y_{j}}} = y_{j*} - \ln \sum_{j = 1}^{V}e^{y_{j}} \\
y_{j} = h^{T}u_{j}$$
根据链式求导法则得
$$\frac{\partial y}{\partial u_{j}} = \frac{\partial y}{\partial y_{j}} \cdot \frac{\partial y_{j}}{\partial u_{j}} = \left ( t_{j} - \frac{e^{y_{j}}}{\sum_{j = 1}^{V}e^{y_{j}}} \right ) \cdot h = (t_{j} - y)h$$
这里引入了一个变量 $t_{j}$,当 $t = j*$ 时,$t_{j} = 1$,反之,$t_{j} = 0$。
设学习率为 $\eta$,则列向量 $u_{j}$ 的更新公式为
$$u_{j} = u_{j} + \eta(t_{j} - y)h$$
可以看出矩阵 $W^{'}$ 的每一列都需要调整,但是目标神经元对应的第 $j*$ 列和其它列调整的方向不同。
2)输入层 $\rightarrow$ 隐藏层
由图可知,神经网络的输入向量为 $x = (x_{1},x_{2},...,x_{n})$,对于 $4-gram$ 而言,神经网络的输入向量就等于词 $w_{1},w_{2},w_{3}$ 对应
的 $3$ 个 $one-hot$ 向量叠加,对矩阵 $W$ 进行列分块得 $W = (v_{1},v_{2},...,v_{N})$。根据链式求导法则有:
$$\frac{\partial y}{\partial v_{k}} = \sum_{j = 1}^{V} \frac{\partial y}{\partial y_{j}} \cdot \frac{\partial y_{j}}{\partial h_{k}} \cdot \frac{\partial h_{k}}{\partial v_{k}}= \sum_{j = 1}^{V}(t_{j} - y)w^{'}_{kj}x$$
设学习率为 $\eta$,则列向量 $v_{k}$ 的更新公式为
$$v_{k} = v_{k} + \eta \sum_{j = 1}^{V}(t_{j} - y)w^{'}_{kj}x$$
可以看出矩阵 $W$ 每一行的元素所做的调整是相同的,对于第 $i$ 行元素有
$$w_{i*} = w_{i*} + \eta\sum_{j = 1}^{V}(t_{j} - y)w^{'}_{kj}x_{i}$$
4. $CBOW$ 模型
对于 $one-hot$ 编码,当语料中添加新的词,那么每个词的词向量就会发生变化,而且向量中充斥着大量的 $0$,使得过于稀疏,除此之外,词典有多大,
词向量的维度就有多大,使得最终的矩阵变得过于庞大,不利于存储及计算。尤其是 $one-hot$ 不能表示词语之间的关系,因为任意两个不同的表示向量
都是正交的,即相似度都是 $0$。
从 $n-gram$ 模型中可以发现,训练完成后,矩阵 $W$ 的每个行向量与输入的 $one-hot$ 向量是一一对应的,这些行向量能不能作为词向量呢?
显然是可以的,因为模型的训练是依据概率规律来进行的,自然训练出来的权重矩阵就能反映词出现的规律。
与 $n-gram$不同的是,$CBOW$ 模型的输出并不是为了计算语言模型的各个条件概率因子,而是为了得到更好的能够表征词的向量,它是基于分布式假设:
可以通过一个词的文本上下文来理解它的含义。$n-gram$ 假设了一个词出现的概率仅与前 $n - 1$ 个词有关,而 $CBOW$ 则是认为一个词出现的概率和
它前后的词相关性更大。举个例子,对于词序列:$w_{1},w_{2},w_{3},w_{4},w_{5}$,假设窗口大小为 $5$,训练的时候
1)对于 $n-gram$ 模型,输入 $w_{1},w_{2},w_{3},w_{4}$,调整权重使 $P(w_{5} | w_{1},w_{2},w_{3},w_{4})$ 取到最大值。
2)对于 $CBOW$ 模型,输入 $w_{1},w_{2},w_{4},w_{5}$,调整权重使 $P(w_{3} | w_{1},w_{2},w_{4},w_{5})$ 取到最大值。
三层的神经网络结构最大的问题在于从隐藏层到输出的 $softmax$ 层的计算量很大,因为要计算所有词的 $softmax$ 概率,再去找目标神经元的输出,
这个过程在权重矩阵的更新公式就可以看出。
为了避免要计算所有词的 $softmax$ 概率,$CBOW$ 模型采样了霍夫曼树来代替从隐藏层到输出 $softmax$ 层的映射,输入层到隐藏层之间仍然是全连接结构。
隐藏层到输出层的网络结构如下图所示:
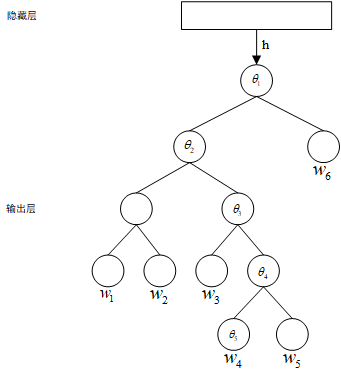
输出层是一个二叉树,它是以语料中出现过的词当作叶子结点,以各词在语料中出现的次数当权值构造出来的 $Huffman$ 树,在这棵树中,叶子结点
有 $V$ 个,非叶子结点有 $V - 1$ 个。那怎么根据这棵树来构造概率呢?
1)首先为每个非叶子结点构造一个长度为 $N$(隐藏层神经元个数)的向量 $\theta$,它的作用就相当于 $n-gram$ 神经元模型中输出层权重矩阵 $W^{'}$,
都是作为构造概率的辅助向量。
2)采用了二元逻辑回归的方法,即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。正类和
负类的概率使用 $sigmoid$ 函数来构造,设定正类的概率为
$$P_{+} = \sigma(h^{T}\theta) = \frac{1}{1 + e^{-h^{T}\theta}}$$
其中,$h$ 是隐藏层的输出向量,$\theta$ 是非叶子结点对应的辅助向量。
现在就可以构造概率了,以上图为例,设滑动窗口 $n = 5$,当滑动到文本 $w_{2},w_{3},w_{4},w_{5},w_{6}$ 时,有
$$P(w_{4} | w_{2},w_{3},w_{5},w_{6}) = \left [1 - \sigma(h^{T}\theta_{1}) \right ] \cdot \sigma(h^{T}\theta_{2}) \cdot \sigma(h^{T}\theta_{3}) \cdot \left [ 1 - \sigma(h^{T}\theta_{4}) \right ]$$
下面来推导一下参数更新公式,先约定如下几个符号:
1)对词典中的任一个词 $w$,哈夫曼树中必然存在一条从根节点到词 $w$ 的路径,设这条路径为 $p^{w}$,$p_{j}^{w}$ 表示路径中的第 $j$ 个结点。
2)$\theta_{j}^{w}$ 为结点 $p_{j}^{w}$ 对应的辅助向量。
3)$d^{w}$ 为词 $w$ 的哈夫曼编码,$d_{j}^{w}$ 表示路径 $p^{w}$ 上第 $j$ 个分支对应的编码。
4)路径长度为 $l^{w}$,这里的长度指的是路径上结点的个数。
路径 $p^{w}$ 上有 $l^{w} - 1$ 个分支,将每个分支看作一次二分类,每一次分类就产生一个概率,将这些概率连乘起来,就得到所要优化的目标概率 $y$,即
$$y = \ln \prod_{j = 2}^{l^{w}}\left [ \sigma \left (h^{T}\theta_{j - 1}^{w} \right ) \right ]^{1 - d_{j - 1}} \; \left [ 1 - \sigma \left (h^{T}\theta_{j - 1}^{w} \right ) \right ]^{d_{j - 1}} \\
= \sum_{j = 2}^{l^{w}}(1 - d_{j - 1})\ln \sigma \left ( h^{T}\theta_{j - 1}^{w} \right ) + \sum_{j = 2}^{l^{w}}d_{j - 1}\ln \left [ 1 - \sigma \left (h^{T}\theta_{j - 1}^{w} \right ) \right ]$$
$sigmod$ 函数的相关导数为
$$\sigma^{'}(x)= \sigma (x)\left [ 1 - \sigma (x) \right ] \\
\ln^{'} \sigma(x) = 1 - \sigma(x) \\
\ln^{'} \left [ 1 - \sigma(x) \right ] = -\sigma(x)$$
计算 $y$ 关于 $\theta_{j - 1}^{w}$ 的偏导数得
$$\frac{\partial y}{\partial \theta_{j - 1}^{w}} = (1 - d_{j - 1})\left [ 1 - \sigma \left ( h^{T}\theta_{j - 1}^{w} \right ) \right ]h - d_{j - 1}\sigma \left (h^{T}\theta_{j - 1}^{w} \right ) h \\
= \left [ 1 - d_{j - 1} - \sigma \left ( h^{T}\theta_{j - 1}^{w} \right ) \right ]h$$
设学习率为 $\eta$,则 $\theta_{j - 1}^{w}$ 的更新公式为
$$\theta_{j - 1}^{w} = \theta_{j - 1}^{w} + \eta \left [ 1 - d_{j - 1} - \sigma \left ( h^{T}\theta_{j - 1}^{w} \right ) \right ]h$$

 浙公网安备 33010602011771号
浙公网安备 33010602011771号