数据挖掘(DM)基本概念
问题:数据总量爆炸式增加,如何从中提取真正有价值的信息,产生了新的领域(DM)。几个名词:
1)Data Mining:数据挖掘
2)Knowledge Discovery:知识发现
3)Machine Learning:机器学习(机器学习是数据挖掘的一个重要工具)
4)Knowledge Discovery in Database:KDD
数据挖掘的主要功能:
1)概化:归纳、总结和对比数据的特性,将数据特征化或区分,比如对学生的成绩按分数段就行统计。
2)关联分析:发现数据之间的关联规则,描述某些属性在给定数据中一起频繁出现的条件。
3)分类和预测:通过已知类别的数据来训练模型或者函数,评估合格之后用来对未知类别的数据做预测。
4)聚类分析:审视数据的分布特色,自动得将数据划分为不同的组,即将类似的数据归类到一组。
5)离群点分析:在数据当中,跟主流的数据分布显著不一致的那些点,通常被认为是噪声或者异常。
6)趋势和演变分析:描述行为随时间变化的对象的发展规律或趋势。
中心趋势度量:度量数据分布的中部或中心位置,或者说,给定一个属性,它的值大部分落在何处?有 $3$ 个指标:
1)均值:最常用最有效的是的算术均值或加权均值,对极端值很敏感。
2)中位数:对于非对称数据,数据中心更好的度量是中位数,但在观测数量很大时,计算开销很大。
3)众数:出现最频繁的值,也叫模。具有一个、两个、三个众数的数据集合分别称为单峰(单模态)、双峰的、三峰的。
a. 当数据对称时,众数 = 中位数 = 均值。
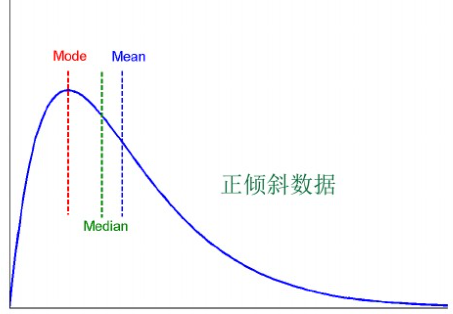
b. 当数据分布正倾斜时,均值受偏高数值的影响较大,其位置在众数之右,中位数在众数与算术平均数之间,众数 < 中位数 < 均值。
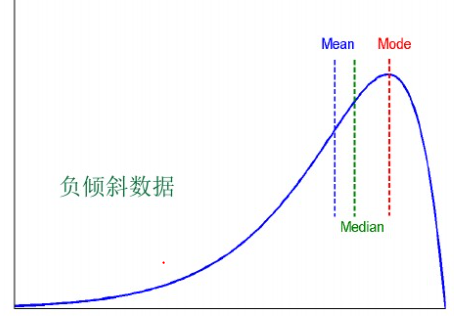
c. 当数据分布负倾斜时,均值受偏小数值的影响较大,其位置在众数之左,中位数仍在两者之间,均值 < 中位数 < 众数。

数据的散布:度量数据的离散程度。
1)极差:最大值和最小值之差。
2)方差和标准差:衡量数据偏离均值的范围,代表模型的稳定性。
3)四分位数:把数据划分成四个基本上大小相等的连贯集合。$Q_{1}$:有 25% 的数据;$Q_{2}$:有 50% 的数据;$Q_{3}$:有 75% 的数据在此之下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号