map/unordered_map
1. map
1)map是标准的关联式容器,一个map是一个键值对序列,即(key,value)对。它提供基于key的快速检索能力。
2)map中key值是唯一的。集合中的元素按一定的顺序排列。元素插入过程是按排序规则插入,所以不能指定插入位置。
3)map的具体实现采用红黑树变体的平衡二叉树的数据结构。在插入操作和删除操作上比vector快。
4)map可以直接存取key所对应的value,支持[]操作符,如map[key]=value。
map对象的构造
map<T1,T2> mapX;
map的插入与迭代器
map<int, string> mapStu;
mapStu.insert(pair<int,string>(3,"Jack")); // return pair<map<int, string>::iterator,bool>
mapStu.inset(make_pair(0, "John")); // return pair<map<int, string>::iterator,bool>
mapStu.insert(map<int,string>::value_type(1,"小李")); // return pair<map<int, string>::iterator,bool>
void insert(InputIterator first, InputIterator last); // 插入一个范围
mapStu[3] = "小明"; // 这种方法虽然非常直观,但存在一个性能的问题。插入3时,先在mapStu中查找主键为3的项,
// 若没发现,则将一个键为3,值为初始化值的对组插入到mapStu中,然后再将值修改成"小明"。
// 若发现已存在3这个键,则修改这个键对应的value
string strName = mapStu[2]; // 只有当mapStu存在2这个键时才是正确的取操作,否则会自动插入一个实例,键为2,值为初始化值。
map.begin(); // 返回容器中第一个数据的迭代器。
map.end(); // 返回容器中最后一个数据之后的迭代器。
map.rbegin(); // 返回容器中倒数第一个元素的迭代器。
map.rend(); // 返回容器中倒数最后一个元素的后面的迭代器。
// 迭代器遍历
for (map<int,string>::iterator it=mapA.begin(); it!=mapA.end(); ++it)
{
pair<int, string> pr = *it;
int iKey = pr.first;
string sValue = pr.second;
}
map选择key排序方式
map<T1,T2,less<T1> > mapA; // 该容器是按键的升序方式排列元素。未指定函数对象,默认采用less<T1>函数对象。 map<T1,T2,greater<T1>> mapB; // 该容器是按键的降序方式排列元素。 // less<T1> 与 greater<T1> 可以替换成其它的函数对象functor。
map对象的拷贝构造与赋值
map(const map &mp); // 拷贝构造函数 map& operator=(const map &mp); // 重载等号操作符 map.swap(mp); // 交换两个容器集合
map的大小
map.size(); // 返回容器中元素的数目 map.empty(); // 判断容器是否为空
map的删除
map.clear(); // 删除所有元素 iterator erase(const_iterator position); // 删除pos迭代器所指的元素,返回下一个元素的迭代器 size_type erase(const key_type& k); // 删除容器中key为k的pair iterator erase(const_iterator first, const_iterator last); // 除区间[beg,end)的所有元素,返回下一个元素的迭代器
map的查找
iterator find(const key_type& k); // 查找键key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回map.end(); size_type count(const key_type& k) const; // 返回容器中key为 k 的对组个数。对map来说,要么是0,要么是1 iterator lower_bound(const key_type& k); // 返回第一个 key>=k 元素的迭代器 iterator upper_bound(const key_type& k); // 返回第一个 key>k 元素的迭代器
2. unordered_map
它是一个关联容器,内部采用的是hash表结构,拥有快速检索的功能。每个key会通过一些特定的哈希运算映射到一个特定的位置,我们知道,
hashtable是可能存在冲突的(多个key通过计算映射到同一个位置),在同一个位置的元素会按顺序链在后面。所以把这个位置称为一个bucket是
十分形象的(像桶子一样,可以装多个元素)。
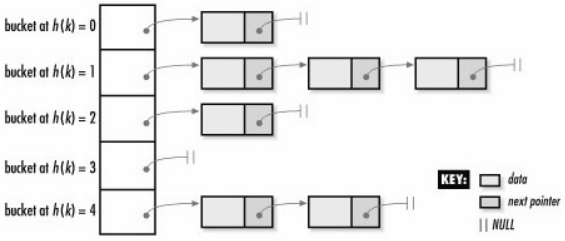
所以 unordered_map 内部其实是由很多哈希桶组成的,每个哈希桶中可能没有元素,也可能有多个元素。每当桶不够用时,桶数会以
大致 bucket[n] = 2 * bucket[n-1] + 奇数 (1, 3, 5, 9 ...)来增长。与 vector 成倍增长是不同的。
这里我们将map和unordered_map做一个对比:
1)map在缺省下,按照递增的排序顺序,unordered_map不排序。
2)Map中桶的元素初始化是链表保存的,其查找性能是O(n)。当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断
变长,肯定会对查询性能有一定的影响,而树结构能将查找性能提升到O(log(n)),这时map内部存储结构由链表转成树。
unordered_map内部实现是哈希表(数组),由链地址法解决冲突。
3)map搜索时间复杂度为log(n)。unordered_map搜索时间复杂度,O(1)为平均时间,最坏情况下的时间复杂度为O(n)。
4)map空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,
使得每一个节点都占用大量的空间。unordered_map建立哈希表比较耗费时间,但查找速度更快(受到冲突的影响)。
unordered_map对象的构造
unordered_map<T1,T2> mapX;
unordered_map的插入与迭代器
std::unordered_map<std::string, double> map1, map2 = { {"milk",2.0},{"flour",1.5} };
std::pair<std::string, double> myshopping("baking powder",0.3);
map1.insert(myshopping); // copy insertion
map1.insert(std::make_pair<std::string, double>("eggs",6.0)); // move insertion
map1.insert(map2.begin(), map2.end()); // range insertion
map1.insert({ {"sugar",0.8}, {"salt",0.1} }); // initializer list insertion
umap.begin(); // 返回容器中第一个数据的迭代器。
umap.end(); // 返回容器中最后一个数据之后的迭代器。
for (auto& x: map1) {
std::cout << x.first << ": " << x.second << std::endl;
}
自定义哈希函数
使用自定义哈希函数可以有效避免构造数据产生的大量哈希冲突。要想使用自定义哈希函数,需要定义一个结构体,并在结构体中重载()运算符。
// 通过 unordered_map<int, int, my_hash> my_map; 的定义方式将自定义的哈希函数传入容器了。
struct my_hash
{
static uint64_t splitmix64(uint64_t x)
{
x += 0x9e3779b97f4a7c15;
x = (x ^ (x >> 30)) * 0xbf58476d1ce4e5b9;
x = (x ^ (x >> 27)) * 0x94d049bb133111eb;
return x ^ (x >> 31);
}
size_t operator()(uint64_t x) const
{
static const uint64_t FIXED_RANDOM = chrono::steady_clock::now().time_since_epoch().count();
return splitmix64(x + FIXED_RANDOM);
}
};
unordered_map对象的拷贝构造与赋值
unordered_map(const unordered_map& ump); // 拷贝构造函数 unordered_map(unordered_map&& ump); // 移动构造函数 unordered_map& operator=(const unordered_map& ump); // 重载赋值运算符 unordered_map& operator=(unordered_map&& ump); // 移动赋值 void swap(unordered_map& ump); // 交换两个容器集合
unordered_map的大小
umap.size(); // 返回容器中元素的数目 umap.empty(); // 判断容器是否为空 umap.bucket_count(); // 返回容器中桶的数目 umap.bucket_size(n); // 返回第n个桶中元素个数
unordered_map的删除
umap.clear(); // 删除所有元素 iterator erase(const_iterator position); // 删除pos迭代器所指的元素,返回下一个元素的迭代器 size_type erase(const key_type& k); // 删除容器中key为k的pair iterator erase(const_iterator first, const_iterator last); // 除区间[beg,end)的所有元素,返回下一个元素的迭代器
unordered_map的查找
iterator find(const key_type& k); // 查找键key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回umap.end(); size_type count(const key_type& k) const; // 返回容器中key为 k 的对组个数。对umap来说,要么是0,要么是1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号