
性能检测
性能检测
性能检测的基础
记录所有的事情
- 记录软件硬件的基本配置情况
os版本、cpu类型、内存容量、磁盘文件系统、网络信息、相关的配置文件
可以写一个脚本程序,基本的配置情况写到基本的类当中,每一次测试都会自动记录 - 保存并组织性能结果
每一次测试完成以后有条理正的整理到笔记当中,这样当下一次查看的时候就不需要去再次测试,花费时间
也可以在性能测试之前就先将测试的数据都封装好。测试数据输出以后就直接粘贴到笔记当中来,不需要花费太多的时间 - 写下命令行的调用
在测试数据的时候,需要将命令行中输入的命令全部记录下来 - 记录研究信息和url
就是当搞不懂一件事情的时候,去网上或者找人沟通弄明白以后,需要把url记录下来,并写下自己相关的理解信息。这样的话如果下一次自己回来看,或者别人看的时候有相同的问题,也能活获取到对应的研究信息
性能测试时的心态
- 结果的含义可能是不正确的
性能测试的工具给与的我们的信息可能不是太清晰的。就有可能需要重新的梳理一遍从头开始的测试数据。 - 所有的信息都是有用的。
已经运行的测试信息和系统的配置信息,不一定会证明立刻性能问题的瓶颈,需要在之后进行分析之后才能得出结果。可以通过这些记录的过程和测试结果支持我得出的结论,给开发人员解释 - 定期回顾你的笔记可以得到新的想法
当我们存在了大量的测试数据和结论的时候,再次对测试出来的数据进行整合分析。可能会出现新的结论 - 相信你的工具
应为工具就是一个输出。当你的工具输出以后不太可能的信息以后。肯定是系统之中存在一些问题。不要以为是工具有bug(当然工具有bug也是有可能的)
自动执行重复的任务
将所有的工作都脚本化了,定制输出,减少误操作、记录所有的事情。就是把所有测试过程中所有的数据记录下来,依赖脚本实现。
性能调查的概要
性能调查的前提条件
- 系统存在性能问题
- 系统可能存在性能瓶颈
当你的系统确实存在性能瓶颈的或者性能问题的时候去研究性能问题才会有意义。不然的话花费大量的时间和精力提升了系统5%的性能,但是实际上根本用不着那么性能研究就是没有意义的。
确定性能调查的指标
- 确定优化指标: 比如选择一个web请求的qps作为指标
- 确定优化的基线: 比如这个web请求qps的基础基线
- 确定优化的目标: 比如这个某一的web请求的qps优化到的数值
如何获取比较合理的web请求的qps优化到数值
1、 寻找配置相同的系统询问他们的qps情况
2、 找到对于基础系统的测试结果作为参照:比如说如果别人测试了某一配置的qps的数值,虽然这个数据不一定准确可以但是可以作为参考
定下目标后的第一件事情
1、有了目标以后直接上网查这个目标是否有人已经有了结果。
2、询问要提升的应用的开发者了解信息。看是否是可以优化代码
开始我们的性能测试
- 分离问题: 删除测试系统上所有无关的应用
- 利用系统差异发现问题:如果能找到一个相同的系统但是确有性能的差异,比如说繁忙的宿主机上的虚拟机和不繁忙的宿主机上的虚拟机
- 一次只改变意见事情:一次改变意见意见事情方便问题的定位
- 始终在优化后重新测量:不管大或者小的调整了系统,使用测量工具测试来获取改变对系统性能影响。
- 就是疯狂记录,有的没的都记录下来,之后作为元数据进行分析
cpu的性能统计信息
运行队列的统计
- 运行队列
进程有三个状态,可运行、运行、阻塞
运行:就是当前在cpu中运行的进程
可运行:就是等待使用cpu进程
阻塞:就是等待io的进程
运行队列:等待使用cpu的进程队列
- 平均负载
就是使用top右上角的三个数值:1分钟平均负载、5分钟平均负载、15分钟平均负载
负载的计算方式:可运行的进程数3+正在运行的进程数2=1分钟内的平均负载5
平均负载:就是给定时间的负载量
上下文切换
1、上下文的切换是内核调度的结果。
2、上下文中保存了新进程的大量的追踪信息:进程正在执行的指令,分配给进程的内存,进程打开的文件等等
3、上下文触发的条件:内核周期性的中断正在运行的进程,让新的进程运行
4、上下文中断的频率:
# cat /proc/interrupts | grep "timer interrupts" ; sleep 10 ; cat /proc/interrupts | grep "timer interrupts"
LOC: 1783210654 4239365349 3634409204 3104798540 2427574269 2114868106 1940182285 1865923815 Local timer interrupts
LOC: 1783219201 4239375442 3634418895 3104807695 2427583438 2114876906 1940191020 1865932206 Local timer interrupts
选择第一个cpu计算
(1783219201-1783210654)=8547/10=85/s
大约是1s85次中断
这个中断的次数可以设置
上下文切换:不通进程间的切换叫上下文切换
中断
硬中断:硬中断一般是从硬件设备中接收,硬中断的优先级比较高,执行速度比较快
软中断:当中断的处理程序有工作要做,而且不需要高优先级,他可以启动“下半部”(bottom half)
cpu使用率
一般cpu的使用情况分为7种
cpu用户使用 us: 用户代码使用的比例
cpu系统使用 sy: linux内核应用程序使用的比例
cpu优先级搞的进程 ni: cpu被设置低于一般进程的代码使用的比例
cpu处于空闲的状态 id: cpu不在被使用的比例
cpu处于iowait状态 wa: 等待系统io完成的比例
cpu处于中断的状态 hi si: cpu处理中断就是执行上下文切换的时间 hi(硬中断)si(软终端)
cpu被偷走的状态 st: 一般用在虚拟化的状态,被偷走的时间比例
linux性能工具: cpu
vmstat(虚拟内存的统计)
特点:vmstat使用linux的资源非常的少。在比较繁忙的机器上使用也不会占用多少资源
vmstat
1. 能展示虚拟内存的性能信息
2. 能获取整个系统性能的粗略的信息。
包括:
正在运行的进程个数
cpu的使用情况
cpu接收中端的个数
调度器执行的上下文切换次数
vmstat命令:
vmstat [options] [delay [count]]
-n 2 : 后边加数字可以显示0-2s之间的数据统计,按照延迟秒数做的统计
-s: 发一次性显示系统启动以来所有统计数据的平均值
vmstat 与cpu相关的vmstat的输出
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
r:当前可运行的进程数
b:等待i/o完成的被阻塞的进程数
forks:创建进程的次数
in:系统发生中断的次数
cs:系统发生中断的次数
us: 用户进程消耗cpu时间的%
sy:内核消耗cpu的时间% (top: sys+st+hi+si)
wa:等待i/o消耗的总cpu时间%
id: 系统控销小孩的总cpu时间%
vmstat模式:采样模式和平均模式
平均模式:
一次性展示从系统开始到现在的所有统计数据的平均
vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 218172 0 703968 0 0 0 1 0 2 0 0 100 0 0
vmstat -s
1015380 K total memory
92476 K used memory
351412 K active memory
290268 K inactive memory
217224 K free memory
0 K buffer memory
705680 K swap cache
2097148 K total swap
0 K used swap
2097148 K free swap
cpu相关
264557 non-nice user cpu ticks # 没有配置优先级的用户进程 cpu的使用时间
2722 nice user cpu ticks # 有配置优先级的 用户进程使用时间
208325 system cpu ticks # 系统的cpu使用时间
1823007772 idle cpu ticks # 空闲时间
2671 IO-wait cpu ticks # io-WAIT时间
0 IRQ cpu ticks # 高优先级的代码使用时间
610 softirq cpu ticks # 运行的内核代码,但是优先级低的进程使用时间
1890 stolen cpu ticks # 被偷走的时间
278078 pages paged in
10182460 pages paged out
0 pages swapped in
0 pages swapped out
347040153 interrupts # 从系统起到到现在的中断次数
386371722 CPU context switches
1557129912 boot time # 系统的启动时间
14939391 forks # 从系统开始,已经创建的新进程的数量
采样模式:
每次输出2s内的统计,总共数据5次
# vmstat -n 2 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 215684 0 705584 0 0 0 1 0 2 0 0 100 0 0
0 0 0 215684 0 705584 0 0 0 0 50 67 1 1 99 0 0
0 0 0 215684 0 705584 0 0 0 0 176 253 2 3 95 0 0
0 0 0 215684 0 705584 0 0 0 0 177 248 2 2 96 0 0
0 0 0 215684 0 705584 0 0 0 0 175 246 3 3 95 0 0
cpu相关的数据分析:
in和cs是中断次数和上下文切换的次数
cs>in 从数据上来说就是cpu的上下文切换数大于中断数,就是说系统中断触发的时候调度器都有工作要做(就是说有进程要换入cpu去执行)。
top
top:可以将系统的整体性能信息放在一个屏幕上
top命令
top -hv|-bcHiOSs -d secs -n max -u|U user -p pid -o fld -w [cols]
top命令有俩种模式:命令行选项和运行时选项
top命令行模式
-d delay: 统计信息更新的时间间隔
-n iterations: 脱出前迭代的次数。top更新信息统计信息的粗疏为iterations次
-i: 是否显示空闲进程
-b: 输出所有的进程,不进入运行模式,可以通过把输出交给管道符处理
top运行时的选项:
top根据延迟定期的更新这个列表(默认是3秒)
top可以在运行的时候修改统计信息(就是能自定义统计的信息的输出,)

打开关闭各种系统级别的信息的显示(就是可以选择展示的信息的列表就像是)

top运行时的输出切换选项(就是按照cpu排序,按照内存排序等等)
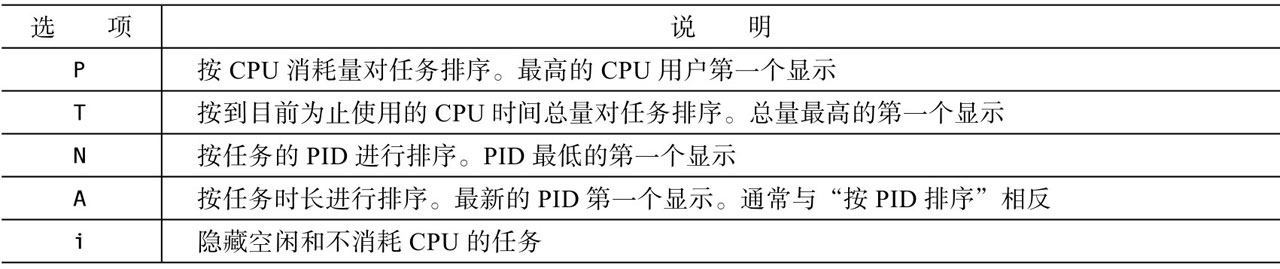
top的性能统计信息(实际上就是每一个字段的含义)
procinfo
procinfo的
- 特点:低消耗,输出格式比vmstat稍微强一点,会占用更多的屏幕空间,和vmstat的输出比较相同,能给出cpu从每个设备接收的中断数量。
- 优点: 可以看到物理设备的显卡,硬盘控制器,网络设备、显卡,声卡中断数量相对比较高的进程
- 缺点: 缺乏网络和磁盘性能的详细信息。
-
procinfo的命令行选项
![]()
-
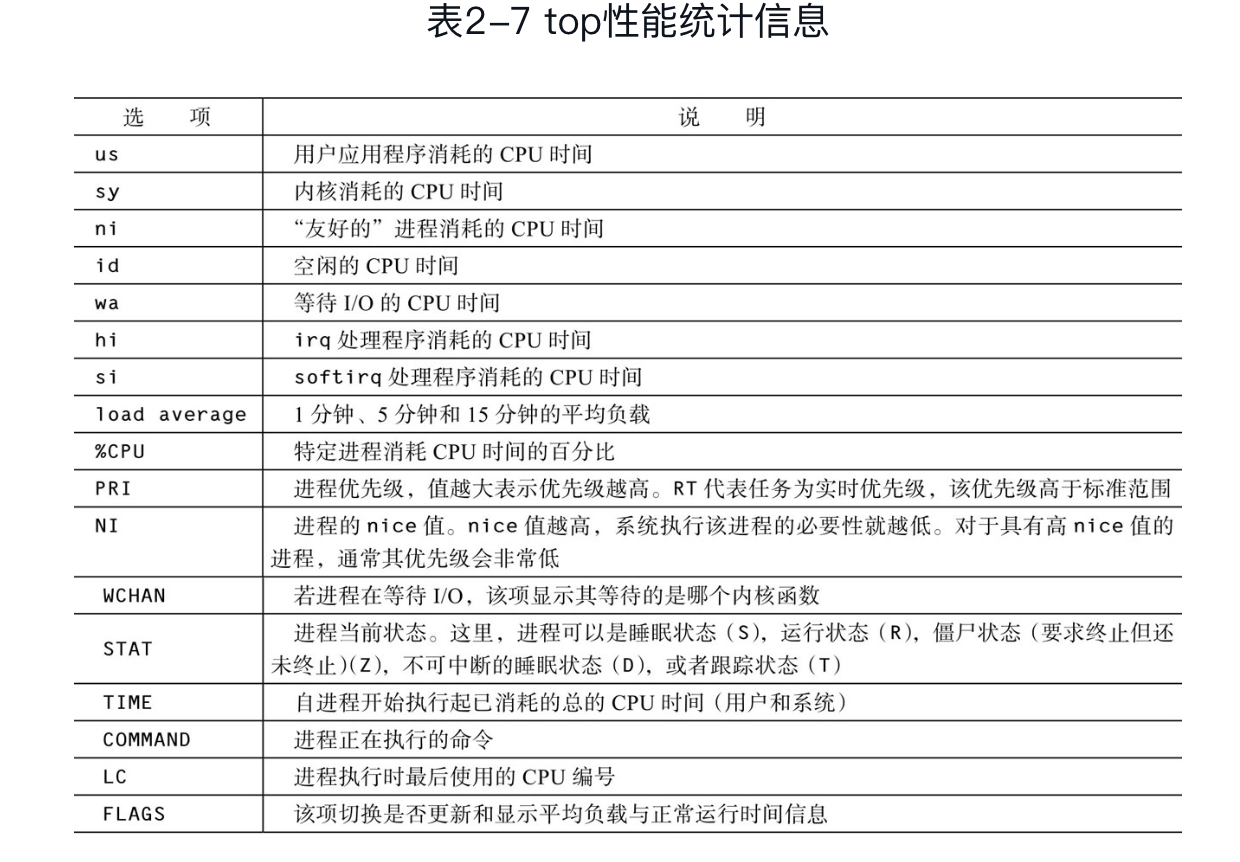
procinfo cpu统计信息
![]()
-
用法示例
直接输出显示的是从系统启动到现在的统计时间。加-n second会显示系统实时性能的变化


Memory: Total Used Free Buffers
RAM: 8174676 7808464 366212 1143064
Swap: 16777212 98232 16678980
Bootup: Wed Jul 31 11:40:17 2019 Load average: 0.12 0.06 0.02 1/253 967642
user : 4d 01:45:42.69 0.7% page in : 1222778451
nice : 00:45:28.23 0.0% page out: 1835059301
system: 1d 01:00:07.64 0.2% page act: 89714192
IOwait: 03:46:49.57 0.0% page dea: 59360198
hw irq: 00:00:00.00 0.0% page flt: 8769963286
sw irq: 00:40:24.11 0.0% swap in : 65325
idle : 77w 6d 16:12:54.24 99.0% swap out: 105058
uptime: 4m 2w 22:05:05.99 context : 2728511464
irq 0: 27 2-edge timer irq 15: 0 15-edge ata_piix
irq 1: 10 1-edge i8042 irq 24: 0 65536-edge virtio
irq 4: 2229 4-edge serial irq 25: 20893787 65537-edge virtio
irq 6: 3 6-edge floppy irq 26: 0 81920-edge virtio
irq 8: 139 8-edge rtc0 irq 27: 63295 81921-edge virtio
irq 9: 0 9-fasteoi acpi irq 28: 0 98304-edge virtio
irq 10: 1191623 10-fasteoi virtio irq 29: 219 98305-edge virtio
irq 11: 36 11-fasteoi uhci_h irq 30: 0 49152-edge virtio
irq 12: 15 12-edge i8042 irq 31: 967470301 49153-edge virtio
irq 14: 0 14-edge ata_piix irq 32: 1110 49154-edge virtio
loop0 2r 0 vdb 39652r 25275w
vda 14919182r 14858016w vdc 245r 0w
vda1 14918491r 14776149w
br-066b6211b380 TX 226.15MiB RX 1.25MiB ens3 TX 71.77GiB RX 168.85GiB
br-81b8a2cecdda TX 0.00B RX 0.00B lo TX 581.93MiB RX 581.93MiB
docker0 TX 1.20GiB RX 7.43MiB
procinfo -n 2 # 没俩秒更新一次数据
Memory: Total Used Free Buffers
RAM: 8174676 7810564 364112 1143092
Swap: 16777212 98232 16678980
Bootup: Wed Jul 31 11:40:17 2019 Load average: 0.00 0.01 0.00 1/247 968669
user : 00:00:00.05 inf% page in : 1222778451
nice : 00:00:00.00 -nan% page out: 1835097265
system: 00:00:00.01 inf% page act: 89714251
IOwait: 00:00:00.00 -nan% page dea: 59360370
hw irq: 00:00:00.00 -nan% page flt: 8770082964
sw irq: 00:00:00.00 -nan% swap in : 65325
idle : 00:00:07.95 inf% swap out: 105058
uptime: 4m 2w 22:17:09.80 context : 2728684501
irq 0: 27 2-edge timer irq 15: 0 15-edge ata_piix
irq 1: 10 1-edge i8042 irq 24: 0 65536-edge virtio
irq 4: 2229 4-edge serial irq 25: 20894239 65537-edge virtio
irq 6: 3 6-edge floppy irq 26: 0 81920-edge virtio
irq 8: 139 8-edge rtc0 irq 27: 63295 81921-edge virtio
irq 9: 0 9-fasteoi acpi irq 28: 0 98304-edge virtio
irq 10: 1191696 10-fasteoi virtio irq 29: 219 98305-edge virtio
irq 11: 36 11-fasteoi uhci_h irq 30: 0 49152-edge virtio
irq 12: 15 12-edge i8042 irq 31: 967615917 49153-edge virtio
irq 14: 0 14-edge ata_piix irq 32: 1110 49154-edge virtio
loop0 2r 0 vdb 39652r 25275w
vda 14919183r 14858700w vdc 245r 0w
vda1 14918492r 14776830w
br-066b6211b380 TX 226.15MiB RX 1.25MiB ens3 TX 71.77GiB RX 168.86GiB
br-81b8a2cecdda TX 0.00B RX 0.00B lo TX 581.97MiB RX 581.97MiB
docker0 TX 1.20GiB RX 7.43MiB
输出说明:
输出的话是没俩秒更新一次,但是idle的输出却是07.95,这是为什么?
因为这个机器的cpu是4c的,上边的性能统计都是统计4个cpu的时间。
Load average: 0.00 0.01 0.00 怎么解读?
就是在俩秒内这个机器上可运行和正在运行的进程数量一个都没有,就说明这个机器的cpu浪费是极其严重的。
irq 0: 27 2-edge timer irq 15: 0 15-edge ata_piix
irq 1: 10 1-edge i8042 irq 24: 0 65536-edge virtio
irq 4: 2229 4-edge serial irq 25: 20894512 65537-edge virtio
irq 6: 3 6-edge floppy irq 26: 0 81920-edge virtio
irq 8: 139 8-edge rtc0 irq 27: 63295 81921-edge virtio
irq 9: 0 9-fasteoi acpi irq 28: 0 98304-edge virtio
irq 10: 1191754 10-fasteoi virtio irq 29: 219 98305-edge virtio
irq 11: 36 11-fasteoi uhci_h irq 30: 0 49152-edge virtio
irq 12: 15 12-edge i8042 irq 31: 967733662 49153-edge virtio
irq 14: 0 14-edge ata_piix irq 32: 1110 49154-edge virtio
这些输出是什么意思?
procinfo能看到当前iowait、irq(硬中断)、softirq(软中断)的进程信息
mpstat 多处理器统计
- mpstat的优点:在输出的最左边会输出时间。可以对比cpu使用率和时间的关系
- mpstat的特点:他可以将cpu的使用率按照处理器进行区分。
- mpstat的缺点:他只显示和cpu相关的信息
- mpstat的特殊的使用场景:当有这个机器上的服务只使用了单个cpu或者单个cpu的中断或者io很高,但是其他的处理器都是比较空闲的。可以使用这个命令发现
-
命令行选项
![]()
-
cpu统计信息
![]()
-
用法示例


mpstat -P 1 2 10 # 查看第一个cpu, 每2秒更新一次,输出10次
Linux 3.10.0-862.11.6.el7.x86_64 (salt-master2.sys.ops.bj1.wormpex.com) 12/16/2019 _x86_64_ (8 CPU)
10:19:55 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:19:57 AM 1 1.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 98.01
10:19:59 AM 1 1.01 0.00 0.00 0.00 0.00 0.00 0.51 0.00 0.00 98.48
10:20:01 AM 1 4.00 0.00 2.00 0.00 0.00 0.00 4.50 0.00 0.00 89.50
10:20:03 AM 1 6.47 0.00 2.99 0.00 0.00 0.50 0.00 0.00 0.00 90.05
10:20:05 AM 1 9.09 0.00 5.05 0.00 0.00 0.00 0.00 0.00 0.00 85.86
10:20:07 AM 1 13.64 0.00 2.53 0.00 0.00 0.51 0.00 0.00 0.00 83.33
10:20:09 AM 1 5.53 0.00 4.52 0.00 0.00 0.50 0.00 0.00 0.00 89.45
10:20:11 AM 1 2.05 0.00 1.54 0.00 0.00 0.00 0.00 0.00 0.00 96.41
10:20:13 AM 1 15.15 0.00 8.08 0.00 0.00 0.00 0.00 0.00 0.00 76.77
10:20:15 AM 1 14.72 0.00 9.64 0.00 0.00 0.51 0.00 0.00 0.00 75.13
Average: 1 7.25 0.00 3.73 0.00 0.00 0.20 0.50 0.00 0.00 88.31
sar (系统的活动报告)
- sar的特点:能够将收集到的系统性能数据记录到二进制文件中,之后可以重播这些文件。
- sar的有点:记录性能的信息,回放。还能显示当前系统的实时信息。还可以进行格式化,使数据更加易于处理
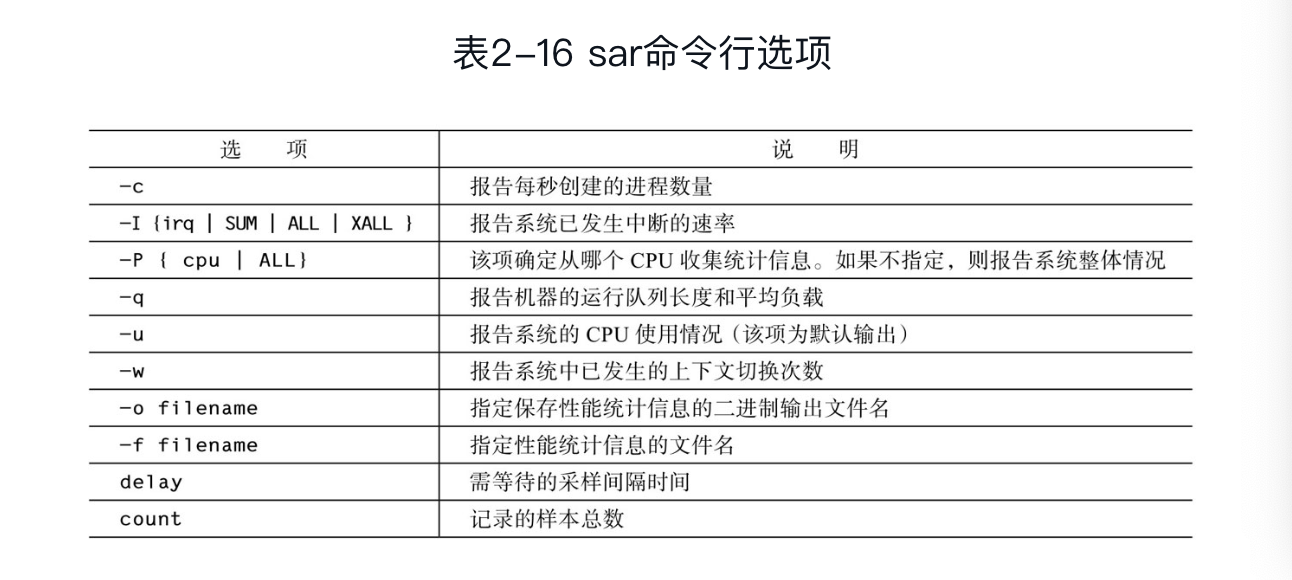
- cpu性能的相关选项:
cpu命令行选项:
![]()
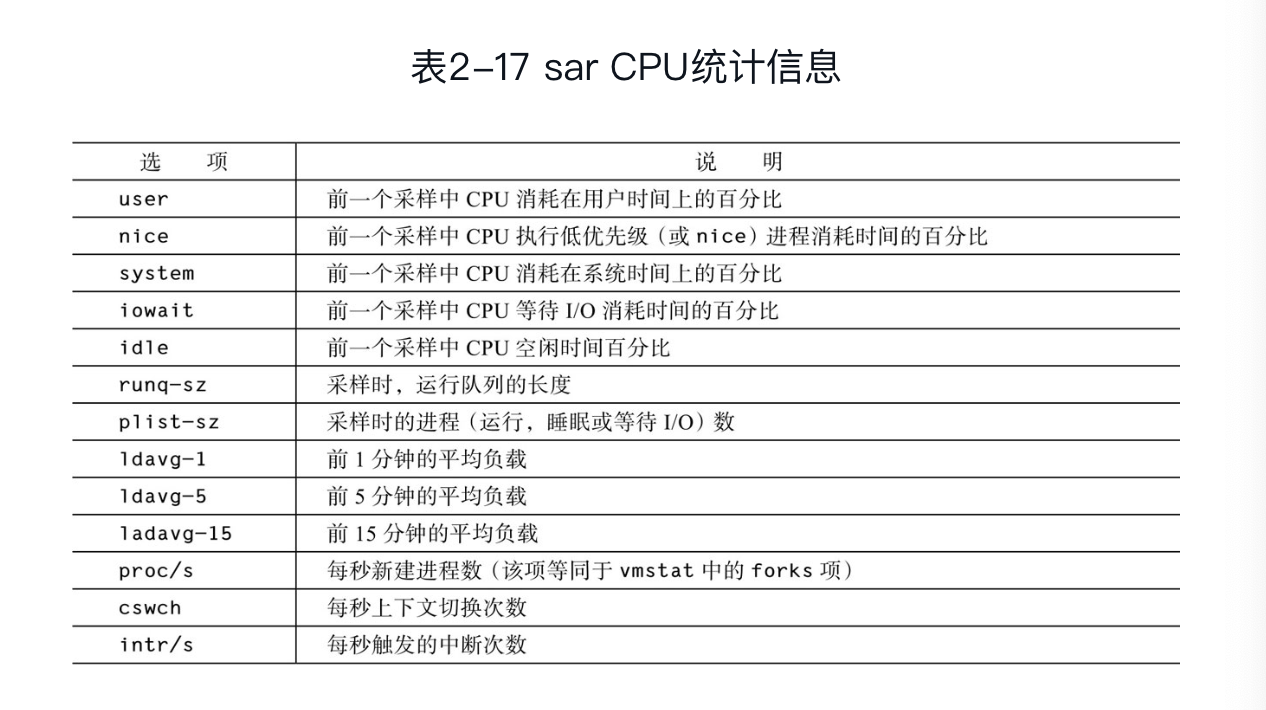
cpu统计信息:
-
用法示例
sar -o /tmp/apache_test 1 3 # 输出到文件中,文件是二进制文件,每秒进行一次记录,统计输出三次 sar -f /tmp/apache_test # 读取文件中的内容
sar -f /tmp/apache_test
Linux 3.10.0-862.11.6.el7.x86_64 (salt-master2.sys.ops.bj1.wormpex.com) 12/16/2019 _x86_64_ (8 CPU)
10:59:49 AM CPU %user %nice %system %iowait %steal %idle
10:59:50 AM all 1.13 0.00 0.38 0.00 0.00 98.49
10:59:51 AM all 0.38 0.00 0.25 0.00 0.00 99.37
10:59:52 AM all 0.38 0.00 0.38 0.00 0.00 99.25
Average: all 0.63 0.00 0.33 0.00 0.00 99.04
sar的数据收集文件:
/var/log/sa/sadd
dd代表的是这个月的日期
/var/log/sa/这个目录下,内核可用的所有数据都保存在数据文件中。
默认是:每秒收集一次,存储1个月
sar详细信息:
或者上机器man一下sar更加详细
sar详解
oprofile
- oprofile特点:可以测量关于cpu执行的非常底层的信息。根据底层处理器支持的时间,他可以测量的内容包括:cache确实、分支预测错误和内存引用,以及浮点操作。
oprofile不会记录发生的每一个时间,相反,他与处理器性能硬件一起工作。oprofile启动时可以指定count(数值),count值越低准确度越高。 - oprofile缺点:和大多数的性能检测工具一样可以查到特定进程使用比例,但是找不到具体的原因(比如说是由什么程序调用的)。
oprofile功能特性:
- 是一守护进程在后台运行
- oprofile会将采样的数据保存在内部的一个缓冲区内,但是缓冲区内的数据无法分析查看
- 想要分析数据的话需要将数据导入到磁盘,才能分析。
- oprofile会定期的将缓冲区的内数据写入到磁盘中。如果想要立刻分析,使用opcontrol手动将分析数据写入到磁盘当中 进行分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号