spark
spark配置项
http://www.tuicool.com/articles/zIvayyf
1.Spark 中也有一个优化版的 repartition(),叫作 coalesce()。
2.combineByKey() 的原理
def testCombineByKey2() { ini() val initialScores = Array(("Fred", 88.0), ("Fred", 95.0), ("Fred", 91.0), ("Wilma", 93.0), ("Wilma", 95.0), ("Wilma", 98.0)) val d1 = sc.parallelize(initialScores) type MVType = (Int, Double) //定义一个元组类型(科目计数器,分数) d1.combineByKey( score => (1, score), //处理相同key的value(预处理value) --在同一个分区内 (c1: MVType, newScore) => (c1._1 + 1, c1._2 + newScore), //合并2个相同key的value --在同一个分区内, (c1: MVType, c2: MVType) => (c1._1 + c2._1, c1._2 + c2._2) //跨分区合并--不同分区合并value ).map { case (name, (num, socre)) => (name, socre / num) }.collect }
3.cogroup() 使用场景--合并2个rdd 例如:合并 dns日志和radius 日志(类似于MR中组合键二次排序实现join)
对两个键的类型均为 K 而值的类型分别为 V 和 W 的 RDD 进行
cogroup() 时,得到的结果 RDD 类型为 [(K, (Iterable[V], Iterable[W]))]。如果其中的
一个 RDD 对于另一个 RDD 中存在的某个键没有对应的记录,那么对应的迭代器则为空。
cogroup() 提供了为多个 RDD 进行数据分组的方法。
4.countByKey() 等xxByKey类
5.从分区中获益的操作
Spark 的许多操作都引入了将数据根据键跨节点进行混洗的过程。所有这些操作都会从数据分区中获益。 就 Spark 1.0 而言,能够从数据分区中获益的操作有 cogroup()、groupWith()、 join()、 leftOuterJoin()、 rightOuterJoin()、 groupByKey()、 reduceByKey()、 combineByKey() 以及 lookup()。对于像 reduceByKey() 这样只作用于单个 RDD 的操作,运行在未分区的 RDD 上的时候会导致每个键的所有对应值都在每台机器上进行本地计算,只需要把本地最终归约出的结果值从各工作节点传回主节点, 所以原本的网络开销就不算大。而对于诸如 cogroup() 和 join() 这样的二元操作,预先进行数据分区会导致其中至少一个 RDD(使用已知分区器注 3: Python API 没有提供查询分区方式的方法,但是 Spark 内部仍然会利用已有的分区信息。键值对操作 | 57的那个 RDD)不发生数据混洗。如果两个 RDD 使用同样的分区方式, 并且它们还缓存在 同样的机器上( 比如一个 RDD 是通过 mapValues() 从另一个 RDD 中创建出来的,这两个RDD 就会拥有相同的键和分区方式),或者其中一个 RDD 还没有被计算出来,那么跨节点的数据混洗就不会发生了。
6.影响分区方式的操作
Spark 内部知道各操作会如何影响分区方式,并将会对数据进行分区的操作的结果 RDD 自动设置为对应的分区器。 例如,如果你调用 join() 来连接两个 RDD;由于键相同的元素会被哈希到同一台机器上, Spark 知道输出结果也是哈希分区的,这样对连接的结果进行
诸如 reduceByKey() 这样的操作时就会明显变快。不过,转化操作的结果并不一定会按已知的分区方式分区, 这时输出的 RDD 可能就会没有设置分区器。 例如,当你对一个哈希分区的键值对 RDD 调用 map() 时,由于传给 map()
的函数理论上可以改变元素的键,因此结果就不会有固定的分区方式。 Spark 不会分析你的函数来判断键是否会被保留下来。 不过, Spark 提供了另外两个操作 mapValues() 和flatMapValues() 作为替代方法,它们可以保证每个二元组的键保持不变。
这里列出了所有会为生成的结果 RDD 设好分区方式的操作: cogroup()、 groupWith()、join()、 lef tOuterJoin()、 rightOuterJoin()、 groupByKey()、 reduceByKey()、combineByKey()、 partitionBy()、 sort()、 mapValues()(如果父 RDD 有分区方式的话)、
flatMapValues()(如果父 RDD 有分区方式的话),以及 filter()(如果父 RDD 有分区方式的话)。 其他所有的操作生成的结果都不会存在特定的分区方式。
最后,对于二元操作,输出数据的分区方式取决于父 RDD 的分区方式。默认情况下,结果会采用哈希分区, 分区的数量和操作的并行度一样。不过,如果其中的一个父 RDD 已经设置过分区方式, 那么结果就会采用那种分区方式;
如果两个父 RDD 都设置过分区方式,结果 RDD 会采用第一个父 RDD 的分区方式。
7.为了最大化分区相关优化的潜在作用,你应该在无需改变元素的键时尽量使用 mapValues() 或 flatMapValues()。
8.scala 处理json数据和捕获异常
import com.fasterxml.jackson.module.scala.DefaultScalaModule import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper import com.fasterxml.jackson.databind.ObjectMapper import com.fasterxml.jackson.databind.DeserializationFeature ... case class Person(name: String, lovesPandas: Boolean) // 必须是顶级类 ... // 将其解析为特定的case class。使用flatMap,通过在遇到问题时返回空列表( None) // 来处理错误,而在没有问题时返回包含一个元素的列表 ( Some(_)) val result = input.flatMap(record => { try { Some(mapper.readValue(record, classOf[Person])) } catch { case e: Exception => None }
})
9.处理csv数据
import Java.io.StringReader import au.com.bytecode.opencsv.CSVReader ... val input = sc.textFile(inputFile) val result = input.map{ line => val reader = new CSVReader(new StringReader(line)); reader.readNext(); }
10.保存对象文件--saveAsObjectFile
要保存对象文件, 只需在 RDD 上调用 saveAsObjectFile 就行了。读回对象文件也相当简
单:用 SparkContext 中的 objectFile() 函数接收一个路径,返回对应的 RDD。
11.累加器弃用的原因,在rdd的转换操作中的累加器,可能由于任务失败,再次计算rdd二重复计算,所以累加器就不那么可靠了。
书中提到,要想绝对可靠需要把累加器放到foreach{}这种行动中。
12.分区执行操作符

13.数值rdd的操作符

14.spark-submit 参数
--conf spark.ui.port=36000 配置文件里的参数可以用该参数覆盖

示例


# 使用独立集群模式提交Java应用 $ ./bin/spark-submit \ --master spark://hostname:7077 \ --deploy-mode cluster \ --class com.databricks.examples.SparkExample \ --name "Example Program" \ --jars dep1.jar,dep2.jar,dep3.jar \ --total-executor-cores 300 \ --executor-memory 10g \ myApp.jar "options" "to your application" "go here" # 使用YARN客户端模式提交Python应用 $ export HADOP_CONF_DIR=/opt/hadoop/conf $ ./bin/spark-submit \ --master yarn \ --py-files somelib-1.2.egg,otherlib-4.4.zip,other-file.py \ --deploy-mode client \ --name "Example Program" \
--queue exampleQueue \
--num-executors 40 \
--executor-memory 10g \
my_script.py "options" "to your application" "go here"
15.依赖冲突
通常,依赖冲突表现为 Spark 作业执行过程中抛出 NoSuchMethodError、 ClassNotFoundException,或其他与类加载相关的 JVM 异常。
解决:
对于这种问题, 主要有两种解决方式:一是修改你的应用,使其使用的依赖库的版本与 Spark 所使用的相同,二是使用通常被称为“ shading”的方式打包你的应用。 Maven 构建工具通过对例 7-5 中使用的插件(事实上, shading 的功能也是这个插件取名为 mavenshade-plugin 的原因)进行高级配置来支持这种打包方式。 shading 可以让你以另一个命名空间保留冲突的包, 并自动重写应用的代码使得它们使用重命名后的版本。这种技术有些简单粗暴,不过对于解决运行时依赖冲突的问题非常有效。如果要了解使用这种打包方式的具体步骤,请参阅你所使用的构建工具对应的文档
16.spark数据和计算不靠拢的情况

LocalityLevel如果worker和datanode不在一台服务器,就是ANY;如果在一起就是PROCESS_LOCAL/NODE_LOCAL。在一起是最好的,无需网络传输,访问最快。
Spark执行任务Locality Level总是为ANY的问题
http://blog.zhaishidan.cn/2016/03/17/sparkzhi-xing-ren-wu-locality-levelzong-shi-wei-anyde-wen-ti/
原文如下:
/**集群管理器用的是Spark Standalone,后来从Spark Master的Web UI中发现Worker的Address和Hadoop中显示的不一致,一个为主机名,一个为ip地址。
看了下Spark的源代码(org/apache/spark/scheduler/TaskSetManager.scala),发现Spark在分发任务的时候,或调用Hadoop的API得到文件在所服务器的信息,这个信息需要和Spark的Executor的保持一致才能正常分发。
也就是说,如果hadoop的datanode列表中显示的是主机名,那么Executor启动时也要按主机名的方式启动。*/
-----------------------分割线----------------
《spark快》中介绍spark on yarn 有一句话 :
在这样配置的 YARN 集群上运行 Spark 是很有意义的,它可以让 Spark 在存储数据的物理节点上运行,以快速访问 HDFS 中的数据。
我已次在用spark跑任务,发现所有LocalityLevel都是any,网络传输花销很大,找了半天找不到原因,后来发现,spark是 standalone模式。。
17.有个坑
# Options read in YARN client mode # - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files # - SPARK_EXECUTOR_INSTANCES, Number of executors to start (Default: 2) # - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1). # - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G) # - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G) SPARK_EXECUTOR_CORES=4 SPARK_EXECUTOR_INSTANCES=5 SPARK_EXECUTOR_MEMORY=12G SPARK_DRIVER_MEMORY=4G
这个配置说的是每个节点的配置,每个节点5个EXECUTOR,每个EXECUTOR4个core,也就是说每个节点5*4=20个core。
而/spark-submit --master yarn --deploy-mode cluster --num-executors 20 --class 。。。 这里配置的是集群总共的executors数量。
现在还没找到spark on yarn 动态调整executors数量的配置项。只知道运行可以加参数。
18.调优中,选择序列化的类库也是重要优化手段
19.几乎所有的 Spark 配置都发生在 SparkConf 的创建过程中,但有一个重要的选项是个例外。
你需要在 conf/spark-env.sh 中将环境变量 SPARK_LOCAL_DIRS 设置为用逗号隔开的存储位置
列表,来指定 Spark 用来混洗数据的本地存储路径。
20.sparkRDD计划生成过程
Spark 调度器从最终被调用行动操作的 RDD( 在本例中是 counts)出发,向上回溯所有必须计算的 RDD。 调度器会访问 RDD 的父节点、父节点的父节点,以此类推,递归向上生成计算所有必要的祖先 RDD 的物理计划。
21.spark内部优化--1.缓存 2.shuffl洗牌
当一个 RDD 已经缓存在集群内存或磁盘上时, Spark 的内部调度器也会自动截短 RDD 谱系图。在这种情况下, Spark 会“短路”求值,直接基于缓存下来的 RDD 进行计算。还有一种截短 RDD 谱系图的情况发生在当 RDD 已经在之前的数据混洗中作为副产品物化出来时,哪怕该 RDD 并没有被显式调用 persist() 方法。这种内部优化是基于 Spark 数据混洗操作的输出均被写入磁盘的特性,同时也充分利用了 RDD 图的某些部分会被多次计算的事实。
22.Spark 的大部分日志信息和工具都是以步骤、 任务或数据混洗为单位的。理解用户代码如何编译为物理执行的内容是一个高深的话题,但对调优和调试应用有非常大的帮助。
23.spark调优
(1)Spark 提供了两种方法来对操作的并行度进行调优。
第一种方法是在数据混洗操作时,使用参数的方式为混洗后的 RDD 指定并行度。
第二种方法是对于任何已有的 RDD,可以进行重新分区来获取更多或者更少的分区数。
重新分区操作通过 repartition() 实现,该操作会把 RDD 随机打乱并分成设定的分区数目。如果你确定要减少 RDD 分区,可以使用coalesce() 操作。由于没有打乱数据,该操作比 repartition() 更为高效。如果你认为当前的并行度过高或者过低,可以利用这些方法对数据分布进行重新调整。
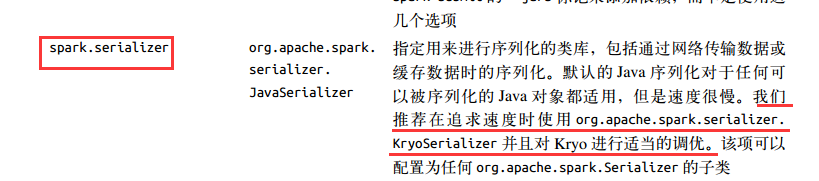
(2)序列化格式
默认情况下,Spark 会使用 Java 内建的序列化库。Spark也支持使用第三方序列化库 Kryo( https://github.com/EsotericSoftware/kryo),可以提供比Jav 的序列化工具更短的序列化时间和更高压缩比的二进制表示, 但不能直接序列化全部类型的对象。几乎所有的应用都在迁移到 Kryo 后获得了更好的性能。
例 8-12: 使用 Kryo 序列化工具并注册所需类
val conf = new SparkConf()
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 严格要求注册类
conf.set("spark.kryo.registrationRequired", "true")
conf.registerKryoClasses(Array(classOf[MyClass], classOf[MyOtherClass]))
(3)内存分配
在默认情况下,Spark会使用60%的空间来存储RDD,20%存储数据混洗操作产生的数据,剩下的20%留给用户程序。
如果用户代码中分配了大量的对象,那么降低RDD存储和数据混洗存储所占用的空间可以有效避免程序内存不足的情况。
在内存中缓存序列化的对象,1.节约内存 2.减少垃圾回收的时间 (这种缓存方式会把大量对象序列化为一个巨大的缓存区对象)
要使用 Kryo 序列化工具,你需要设置 spark.serializer 为 org.apache.spark.serializer.KryoSerializer。为了获得最佳性能,你还应该向 Kryo 注册你想要序列化的类,如例 8-12 所示。注册类可以让 Kryo 避免把每个对象的完整的类名写下来,成千上万条记录累计节省的空间相当可观。 如果你想强制要求这种注册,可以把 spark.kryo.
registrationRequired设置为 true,这样 Kryo 会在遇到未注册的类时抛出错误。
24.sparkSQL
官方文档 http://spark.apache.org/docs/1.3.0/sql-programming-guide.html#creating-dataframes
STRUCT<COL1:COL1_TYPE, ...> 这种类型,也就是结构体,在 Spark SQL 中直接被表示为其他的 Row 对象。
val schema = StructType( schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true))) // Convert records of the RDD (people) to Rows. val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim)) // Apply the schema to the RDD. val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
25.sparkStreaming
1.无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上 ,无状态转化操作也能在多个 DStream 间整合数据,不过也是在各个时间区间内。
如果这些无状态转化操作不够用, DStream 还提供了一个叫作 transform() 的高级操作符,可以让你直接操作其内部的 RDD。
2.DStream 的有状态转化操作是跨时间区间跟踪数据的操作;也就是说,一些先前批次的数据也被用来在新的批次中计算结果。 主要的两种类型是滑动窗口和 updateStateByKey(),前者以一个时间阶段为滑动窗口进行操作, 后者则用来跟踪每个键的状态变化
26.stream时间窗口
如果有一个以 10 秒为批次间隔的源DStream,要创建一个最近 30 秒的时间窗口(即最近 3 个批次),就应当把 windowDuration设为 30 秒。而滑动步长的默认值与批次间隔相等

