内存模型学习-- Container Executor task之间的关系
(分割线前的都是废话)
java8内存模型:
http://www.cnblogs.com/paddix/p/5309550.html
http://www.cnblogs.com/dingyingsi/p/3760447.html
帖子里提到
5、方法区:
方法区也是所有线程共享。主要用于存储类的信息、常量池、方法数据、方法代码等。
方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。
1.7和1.8后这个方法区 没有了,被原空间取代了
不过元空间与永久代之间最大的区别在于:
元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
--------------分割线---------------------------------------------------------------------------------
那么这些jvm在yarn 和spark的内存模型上是怎么工作的?
其实我是想知道:
spark on yarn下
一个yarn的Container 可以包含几个spark Executor?
还是一个Executor 下可以有多个Container ?
是一个Container 起了一个jvm,在这个jvm下执行多个task?
一篇帖子spark架构中提到
传送门: http://www.cnblogs.com/gaoxing/p/5041806.html
任何Spark的进程都是一个JVM进程
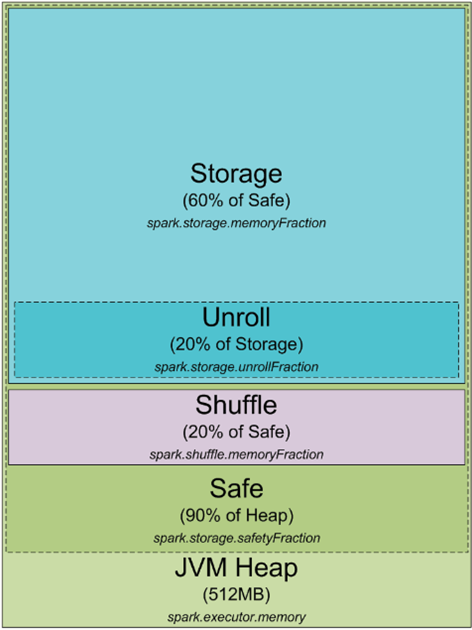

把其中一部分摘出来:
1.当运行在yarn集群上时,Yarn的ResourceMananger用来管理集群资源,集群上每个节点上的NodeManager用来管控所在节点的资源,从yarn的角度来看,每个节点看做可分配的资源池,当向ResourceManager请求资源时,它返回一些NodeManager信息,这些NodeManager将会提供execution container给你,每个execution container就是满足请求的堆大小的JVM进程,JVM进程的位置是由ResourceMananger管理的,不能自己控制,如果一个节点有64GB的内存被yarn管理(通过yarn.nodemanager.resource.memory-mb配置),当请求10个4G内存的executors时,这些executors可能运行在同一个节点上。
2.当在集群上执行应用时,job会被切分成stages,每个stage切分成task,每个task单独调度,可以把executor的jvm进程看做task执行池,每个executor有 spark.executor.cores / spark.task.cpus execution 个执行槽
3.task基本上就是spark的一个工作单元,作为exector的jvm进程中的一个线程执行,这也是为什么spark的job启动时间快的原因,在jvm中启动一个线程比启动一个单独的jvm进程块(在hadoop中执行mapreduce应用会启动多个jvm进程)
总结:所以就是一个container对应一个JVM进程(也就是一个executor)
具体的每个节点下container和executor内存分配看下面的帖子

