
bevdepth- 数据处理部分

BevDepth环境配置
https://blog.csdn.net/yang332233/article/details/145941768?spm=1001.2014.3001.5501
1. 数据处理部分
bevdepth/datasets/nusc_det_dataset.py
def __getitem__(self, idx):
if self.use_cbgs:
idx = self.sample_indices[idx]
cam_infos = list()
lidar_infos = list()
# TODO: Check if it still works when number of cameras is reduced.
cams = self.choose_cams()
for key_idx in self.key_idxes: #[0]
cur_idx = key_idx + idx
# Handle scenarios when current idx bdoesn't have previous key
# frame or previous key frame is from another scene.
if cur_idx < 0:
cur_idx = idx
elif self.infos[cur_idx]['scene_token'] != self.infos[idx][
'scene_token']:
cur_idx = idx
info = self.infos[cur_idx]
cam_infos.append(info['cam_infos'])
lidar_infos.append(info['lidar_infos'])
lidar_sweep_timestamps = [
lidar_sweep['LIDAR_TOP']['timestamp']
for lidar_sweep in info['lidar_sweeps']
]
for sweep_idx in self.sweeps_idx: #self.sweeps_idx []
if len(info['cam_sweeps']) == 0:
cam_infos.append(info['cam_infos'])
lidar_infos.append(info['lidar_infos'])
else:
# Handle scenarios when current sweep doesn't have all
# cam keys.
for i in range(min(len(info['cam_sweeps']) - 1, sweep_idx),
-1, -1):
if sum([cam in info['cam_sweeps'][i]
for cam in cams]) == len(cams):
cam_infos.append(info['cam_sweeps'][i])
cam_timestamp = np.mean([
val['timestamp']
for val in info['cam_sweeps'][i].values()
])
# Find the closest lidar frame to the cam frame.
lidar_idx = np.abs(lidar_sweep_timestamps -
cam_timestamp).argmin()
lidar_infos.append(info['lidar_sweeps'][lidar_idx])
break
if self.return_depth or self.use_fusion:
image_data_list = self.get_image(cam_infos, cams, lidar_infos)
else:
image_data_list = self.get_image(cam_infos, cams)
ret_list = list()
(
sweep_imgs,
sweep_sensor2ego_mats,
sweep_intrins,
sweep_ida_mats,
sweep_sensor2sensor_mats,
sweep_timestamps,
img_metas,
) = image_data_list[:7]
img_metas['token'] = self.infos[idx]['sample_token']
if self.is_train:
gt_boxes, gt_labels = self.get_gt(self.infos[idx], cams)
# Temporary solution for test.
else:
gt_boxes = sweep_imgs.new_zeros(0, 7)
gt_labels = sweep_imgs.new_zeros(0, )
rotate_bda, scale_bda, flip_dx, flip_dy = self.sample_bda_augmentation(
)
bda_mat = sweep_imgs.new_zeros(4, 4)
bda_mat[3, 3] = 1
gt_boxes, bda_rot = bev_transform(gt_boxes, rotate_bda, scale_bda,
flip_dx, flip_dy)
bda_mat[:3, :3] = bda_rot
ret_list = [
sweep_imgs,
sweep_sensor2ego_mats,
sweep_intrins,
sweep_ida_mats,
sweep_sensor2sensor_mats,
bda_mat,
sweep_timestamps,
img_metas,
gt_boxes,
gt_labels,
]
if self.return_depth:
ret_list.append(image_data_list[7])
return ret_list
def get_image(self, cam_infos, cams, lidar_infos=None):
"""Given data and cam_names, return image data needed.
Args:
sweeps_data (list): Raw data used to generate the data we needed.
cams (list): Camera names.
Returns:
Tensor: Image data after processing.
Tensor: Transformation matrix from camera to ego.
Tensor: Intrinsic matrix.
Tensor: Transformation matrix for ida.
Tensor: Transformation matrix from key
frame camera to sweep frame camera.
Tensor: timestamps.
dict: meta infos needed for evaluation.
"""
assert len(cam_infos) > 0
sweep_imgs = list()
sweep_sensor2ego_mats = list()
sweep_intrin_mats = list()
sweep_ida_mats = list()
sweep_sensor2sensor_mats = list()
sweep_timestamps = list()
sweep_lidar_depth = list()
if self.return_depth or self.use_fusion:
sweep_lidar_points = list()
for lidar_info in lidar_infos:
lidar_path = lidar_info['LIDAR_TOP']['filename']
lidar_points = np.fromfile(os.path.join(
self.data_root, lidar_path),
dtype=np.float32,
count=-1).reshape(-1, 5)[..., :4] #[34752, 4]
sweep_lidar_points.append(lidar_points) #[34720, 4]
for cam in cams: #['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT', 'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT']
imgs = list()
sensor2ego_mats = list()
intrin_mats = list()
ida_mats = list()
sensor2sensor_mats = list()
timestamps = list()
lidar_depth = list()
key_info = cam_infos[0]
resize, resize_dims, crop, flip, \
rotate_ida = self.sample_ida_augmentation(
)
for sweep_idx, cam_info in enumerate(cam_infos):
img = Image.open(
os.path.join(self.data_root, cam_info[cam]['filename']))
# img = Image.fromarray(img)
w, x, y, z = cam_info[cam]['calibrated_sensor']['rotation']
# sweep sensor to sweep ego
sweepsensor2sweepego_rot = torch.Tensor(
Quaternion(w, x, y, z).rotation_matrix)
sweepsensor2sweepego_tran = torch.Tensor(
cam_info[cam]['calibrated_sensor']['translation'])
sweepsensor2sweepego = sweepsensor2sweepego_rot.new_zeros(
(4, 4))
sweepsensor2sweepego[3, 3] = 1
sweepsensor2sweepego[:3, :3] = sweepsensor2sweepego_rot
sweepsensor2sweepego[:3, -1] = sweepsensor2sweepego_tran
# sweep ego to global
w, x, y, z = cam_info[cam]['ego_pose']['rotation']
sweepego2global_rot = torch.Tensor(
Quaternion(w, x, y, z).rotation_matrix)
sweepego2global_tran = torch.Tensor(
cam_info[cam]['ego_pose']['translation'])
sweepego2global = sweepego2global_rot.new_zeros((4, 4))
sweepego2global[3, 3] = 1
sweepego2global[:3, :3] = sweepego2global_rot
sweepego2global[:3, -1] = sweepego2global_tran
# global sensor to cur ego
w, x, y, z = key_info[cam]['ego_pose']['rotation']
keyego2global_rot = torch.Tensor(
Quaternion(w, x, y, z).rotation_matrix)
keyego2global_tran = torch.Tensor(
key_info[cam]['ego_pose']['translation'])
keyego2global = keyego2global_rot.new_zeros((4, 4))
keyego2global[3, 3] = 1
keyego2global[:3, :3] = keyego2global_rot
keyego2global[:3, -1] = keyego2global_tran
global2keyego = keyego2global.inverse()
# cur ego to sensor
w, x, y, z = key_info[cam]['calibrated_sensor']['rotation']
keysensor2keyego_rot = torch.Tensor(
Quaternion(w, x, y, z).rotation_matrix)
keysensor2keyego_tran = torch.Tensor(
key_info[cam]['calibrated_sensor']['translation'])
keysensor2keyego = keysensor2keyego_rot.new_zeros((4, 4))
keysensor2keyego[3, 3] = 1
keysensor2keyego[:3, :3] = keysensor2keyego_rot
keysensor2keyego[:3, -1] = keysensor2keyego_tran
keyego2keysensor = keysensor2keyego.inverse()
keysensor2sweepsensor = (
keyego2keysensor @ global2keyego @ sweepego2global
@ sweepsensor2sweepego).inverse()
sweepsensor2keyego = global2keyego @ sweepego2global @\
sweepsensor2sweepego
sensor2ego_mats.append(sweepsensor2keyego)
sensor2sensor_mats.append(keysensor2sweepsensor)
intrin_mat = torch.zeros((4, 4))
intrin_mat[3, 3] = 1
intrin_mat[:3, :3] = torch.Tensor(
cam_info[cam]['calibrated_sensor']['camera_intrinsic'])
if self.return_depth and (self.use_fusion or sweep_idx == 0):
point_depth = self.get_lidar_depth(
sweep_lidar_points[sweep_idx], img,
lidar_infos[sweep_idx], cam_info[cam], cam=cam)
point_depth_augmented = depth_transform(
point_depth, resize, self.ida_aug_conf['final_dim'],
crop, flip, rotate_ida) #point_depth_augmented[256, 704]
lidar_depth.append(point_depth_augmented)
img, ida_mat = img_transform(
img,
resize=resize,
resize_dims=resize_dims,
crop=crop,
flip=flip,
rotate=rotate_ida,
)
## 可视化数据增强之后的img和lidar
#2025 调用可视化visualize_lidar_on_image, pts需要转为[2,N], point_depth_augmented的shape是[256, 704]
nonzero_mask = point_depth_augmented.numpy() > 0
assert isinstance(nonzero_mask, np.ndarray)
assert nonzero_mask.ndim == 2
y_idx, x_idx = np.nonzero(nonzero_mask) #y_idx[1933] x_idx[1933]
depths = point_depth_augmented[nonzero_mask]
pts = np.stack([x_idx, y_idx], axis=0) #[2, 1933]
visualize_lidar_on_image(img, pts, coloring=depths, point_size=1, save_path=f'./assets/{cam}_01.png')
###########################################
ida_mats.append(ida_mat)
img = mmcv.imnormalize(np.array(img), self.img_mean,
self.img_std, self.to_rgb)
img = torch.from_numpy(img).permute(2, 0, 1)
imgs.append(img)
intrin_mats.append(intrin_mat)
timestamps.append(cam_info[cam]['timestamp'])
sweep_imgs.append(torch.stack(imgs))
sweep_sensor2ego_mats.append(torch.stack(sensor2ego_mats))
sweep_intrin_mats.append(torch.stack(intrin_mats))
sweep_ida_mats.append(torch.stack(ida_mats))
sweep_sensor2sensor_mats.append(torch.stack(sensor2sensor_mats))
sweep_timestamps.append(torch.tensor(timestamps))
if self.return_depth:
sweep_lidar_depth.append(torch.stack(lidar_depth))
#end for cam in cams:
# Get mean pose of all cams.
ego2global_rotation = np.mean(
[key_info[cam]['ego_pose']['rotation'] for cam in cams], 0)
ego2global_translation = np.mean(
[key_info[cam]['ego_pose']['translation'] for cam in cams], 0)
img_metas = dict(
box_type_3d=LiDARInstance3DBoxes,
ego2global_translation=ego2global_translation,
ego2global_rotation=ego2global_rotation,
)
ret_list = [
torch.stack(sweep_imgs).permute(1, 0, 2, 3, 4), #[1,6,3,256,704]
torch.stack(sweep_sensor2ego_mats).permute(1, 0, 2, 3), #[1, 6, 4, 4]
torch.stack(sweep_intrin_mats).permute(1, 0, 2, 3),#[1, 6, 4, 4]
torch.stack(sweep_ida_mats).permute(1, 0, 2, 3),#[1, 6, 4, 4]
torch.stack(sweep_sensor2sensor_mats).permute(1, 0, 2, 3),#[1, 6, 4, 4]
torch.stack(sweep_timestamps).permute(1, 0), #[1, 6]
img_metas,
]
if self.return_depth: #sweep_lidar_depth list: [1, 256, 704] torch.stack(sweep_lidar_depth)[6, 1, 256, 704]) [1, 6, 256, 704]
ret_list.append(torch.stack(sweep_lidar_depth).permute(1, 0, 2, 3))
return ret_list
keysensor2sweepsensor = (
keyego2keysensor @ global2keyego @ sweepego2global
@ sweepsensor2sweepego).inverse()
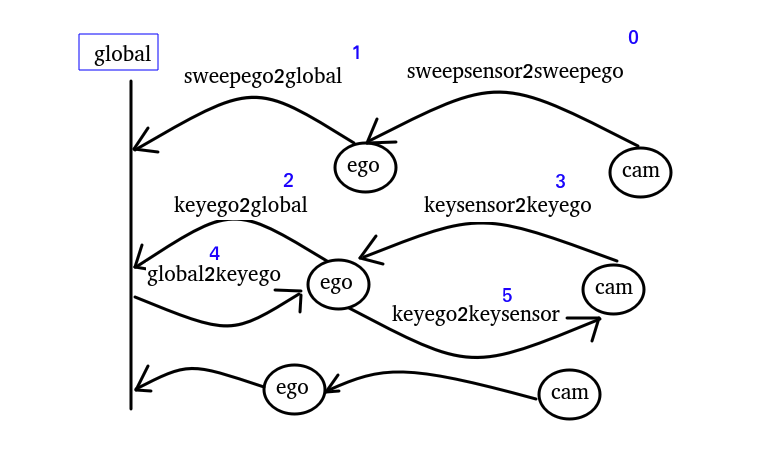
图中这里每行交错代表不同时刻,最后的cam不一定就是相机,也有可能是lidar,
比如后面有把雷达的点云转到图像上,但是雷达和相机是不同时刻触发的,就需要先把雷达转到global,再由global转到相机。因为global就是起点一致。global作为桥接,可以对齐不同时刻的不同设备的信息;
如图,sweepsensor2keysensor的转换流程就是0,1,4,5。
即sweepsensor2keysensor = keyego2keysensor @ global2keyego @ sweepego2global @ sweepsensor2sweepego
sweepsensor2keyego即0,1,4。
sweepsensor2keyego = global2keyego @ sweepego2global @ sweepsensor2sweepego
def get_lidar_depth(self, lidar_points, img, lidar_info, cam_info, cam=None):
lidar_calibrated_sensor = lidar_info['LIDAR_TOP']['calibrated_sensor']
lidar_ego_pose = lidar_info['LIDAR_TOP']['ego_pose']
cam_calibrated_sensor = cam_info['calibrated_sensor']
cam_ego_pose = cam_info['ego_pose']
pts_img, depth = map_pointcloud_to_image(
lidar_points.copy(), img, lidar_calibrated_sensor.copy(),
lidar_ego_pose.copy(), cam_calibrated_sensor, cam_ego_pose)
#add 2025
visualize_lidar_on_image(img, pts_img, coloring=depth, point_size=1, save_path=f'./assets/{cam}_00.png')
return np.concatenate([pts_img[:2, :].T, depth[:, None]],
axis=1).astype(np.float32)
点云点转到图像,由于雷达点和图像不是同一时刻,需要把雷达点先转自车再转global,再通过global转相机时刻的ego,再转相机。
多传感器融合时的坐标转换
不同传感器采集频率不同,不是同步触发,一个传感器的数据需要投影到全局坐标系下,经过全局坐标系再投影到另一个传感器下达到时间对齐。借助于全局坐标系(绝对坐标系)进行运动补偿,从而完成了不同传感器之间的时间对齐。
-
radar外参:radar坐标系到ego(车身)坐标系的复合变换矩阵,
-
camera外参:camera坐标系到ego坐标系的复合变换矩阵
-
ego_pose:ego坐标系到全局坐标系的复合变换矩阵

def map_pointcloud_to_image(
lidar_points,
img,
lidar_calibrated_sensor,
lidar_ego_pose,
cam_calibrated_sensor,
cam_ego_pose,
min_dist: float = 0.0,
):
# Points live in the point sensor frame. So they need to be
# transformed via global to the image plane.
# First step: transform the pointcloud to the ego vehicle
# frame for the timestamp of the sweep.
lidar_points = LidarPointCloud(lidar_points.T)
lidar_points.rotate(
Quaternion(lidar_calibrated_sensor['rotation']).rotation_matrix)
lidar_points.translate(np.array(lidar_calibrated_sensor['translation']))
# Second step: transform from ego to the global frame.
lidar_points.rotate(Quaternion(lidar_ego_pose['rotation']).rotation_matrix)
lidar_points.translate(np.array(lidar_ego_pose['translation']))
# Third step: transform from global into the ego vehicle
# frame for the timestamp of the image.
lidar_points.translate(-np.array(cam_ego_pose['translation']))
lidar_points.rotate(Quaternion(cam_ego_pose['rotation']).rotation_matrix.T)
# Fourth step: transform from ego into the camera.
lidar_points.translate(-np.array(cam_calibrated_sensor['translation']))
lidar_points.rotate(
Quaternion(cam_calibrated_sensor['rotation']).rotation_matrix.T)
# Fifth step: actually take a "picture" of the point cloud.
# Grab the depths (camera frame z axis points away from the camera).
depths = lidar_points.points[2, :] #[4, 34752]
coloring = depths
# Take the actual picture (matrix multiplication with camera-matrix
# + renormalization).
points = view_points(lidar_points.points[:3, :],
np.array(cam_calibrated_sensor['camera_intrinsic']),
normalize=True)
# Remove points that are either outside or behind the camera.
# Leave a margin of 1 pixel for aesthetic reasons. Also make
# sure points are at least 1m in front of the camera to avoid
# seeing the lidar points on the camera casing for non-keyframes
# which are slightly out of sync.
mask = np.ones(depths.shape[0], dtype=bool)
mask = np.logical_and(mask, depths > min_dist)
mask = np.logical_and(mask, points[0, :] > 1)
mask = np.logical_and(mask, points[0, :] < img.size[0] - 1)
mask = np.logical_and(mask, points[1, :] > 1)
mask = np.logical_and(mask, points[1, :] < img.size[1] - 1)
points = points[:, mask]
coloring = coloring[mask]
return points, coloring
可视化雷达点云点映射到图片上函数:
def visualize_lidar_on_image(img, points, coloring, point_size=1, save_path='output_projection.png'):
"""
将点云投影画到图像上并保存为文件(适用于无GUI环境)。
Args:
img (PIL.Image): 原图像
points (np.ndarray): 投影后的点 [2, N]
coloring (np.ndarray): 每个点的深度值(用于着色)
point_size (int): 点的大小
save_path (str): 图像保存路径
"""
import matplotlib.pyplot as plt
import numpy as np
img = np.array(img)
plt.figure(figsize=(12, 8))
plt.imshow(img)
plt.scatter(points[0], points[1], c=coloring, cmap='jet', s=point_size)
plt.axis('off')
plt.tight_layout()
# 保存图像
plt.savefig(save_path, bbox_inches='tight', pad_inches=0)
plt.close()
print(f"图像已保存至:{save_path}")

点云点也需要做同样的数据增强;#cam_depth [3778, 3] x_img,y_img,depth
def depth_transform(cam_depth, resize, resize_dims, crop, flip, rotate):
"""Transform depth based on ida augmentation configuration.
Args:
cam_depth (np array): Nx3, 3: x,y,d.
resize (float): Resize factor.
resize_dims (list): Final dimension.
crop (list): x1, y1, x2, y2
flip (bool): Whether to flip.
rotate (float): Rotation value.
Returns:
np array: [h/down_ratio, w/down_ratio, d]
"""
H, W = resize_dims #[256, 704]
cam_depth[:, :2] = cam_depth[:, :2] * resize
cam_depth[:, 0] -= crop[0]
cam_depth[:, 1] -= crop[1]
if flip:
cam_depth[:, 0] = resize_dims[1] - cam_depth[:, 0]
cam_depth[:, 0] -= W / 2.0
cam_depth[:, 1] -= H / 2.0
h = rotate / 180 * np.pi
rot_matrix = [
[np.cos(h), np.sin(h)],
[-np.sin(h), np.cos(h)],
]
cam_depth[:, :2] = np.matmul(rot_matrix, cam_depth[:, :2].T).T
cam_depth[:, 0] += W / 2.0
cam_depth[:, 1] += H / 2.0
depth_coords = cam_depth[:, :2].astype(np.int16) #[3778,2]
depth_map = np.zeros(resize_dims) #[256, 704]
valid_mask = ((depth_coords[:, 1] < resize_dims[0])
& (depth_coords[:, 0] < resize_dims[1])
& (depth_coords[:, 1] >= 0)
& (depth_coords[:, 0] >= 0)) #cam_depth[3379,3] valid_mask[3379,]
depth_map[depth_coords[valid_mask, 1],
depth_coords[valid_mask, 0]] = cam_depth[valid_mask, 2]
return torch.Tensor(depth_map)
这里把离散的点云点#[3778,2],给映射到depth_map[256, 704]中,没有点云的地方就是默认值0.
图像resize,crop,rotate
def img_transform(img, resize, resize_dims, crop, flip, rotate):
ida_rot = torch.eye(2)
ida_tran = torch.zeros(2)
# adjust image
img = img.resize(resize_dims)
img = img.crop(crop)
if flip:
img = img.transpose(method=Image.FLIP_LEFT_RIGHT)
img = img.rotate(rotate)
# post-homography transformation
ida_rot *= resize
ida_tran -= torch.Tensor(crop[:2])
if flip:
A = torch.Tensor([[-1, 0], [0, 1]])
b = torch.Tensor([crop[2] - crop[0], 0])
ida_rot = A.matmul(ida_rot)
ida_tran = A.matmul(ida_tran) + b
A = get_rot(rotate / 180 * np.pi)
b = torch.Tensor([crop[2] - crop[0], crop[3] - crop[1]]) / 2
b = A.matmul(-b) + b
ida_rot = A.matmul(ida_rot)
ida_tran = A.matmul(ida_tran) + b
ida_mat = ida_rot.new_zeros(4, 4)
ida_mat[3, 3] = 1
ida_mat[2, 2] = 1
ida_mat[:2, :2] = ida_rot
ida_mat[:2, 3] = ida_tran
return img, ida_mat
可视化增强后的图像和点云
## 可视化数据增强之后的img和lidar
#2025 调用可视化visualize_lidar_on_image, pts需要转为[2,N], point_depth_augmented的shape是[256, 704]
nonzero_mask = point_depth_augmented.numpy() > 0
assert isinstance(nonzero_mask, np.ndarray)
assert nonzero_mask.ndim == 2
y_idx, x_idx = np.nonzero(nonzero_mask) #y_idx[1933] x_idx[1933]
depths = point_depth_augmented[nonzero_mask]
pts = np.stack([x_idx, y_idx], axis=0) #[2, 1933]
visualize_lidar_on_image(img, pts, coloring=depths, point_size=1, save_path=f'./assets/{cam}_01.png')
###########################################

返回ret_list
# Get mean pose of all cams.
ego2global_rotation = np.mean(
[key_info[cam]['ego_pose']['rotation'] for cam in cams], 0)
ego2global_translation = np.mean(
[key_info[cam]['ego_pose']['translation'] for cam in cams], 0)
img_metas = dict(
box_type_3d=LiDARInstance3DBoxes,
ego2global_translation=ego2global_translation,
ego2global_rotation=ego2global_rotation,
)
ret_list = [
torch.stack(sweep_imgs).permute(1, 0, 2, 3, 4), #[1,6,3,256,704]
torch.stack(sweep_sensor2ego_mats).permute(1, 0, 2, 3), #is sweepsensor2keyego [1, 6, 4, 4]
torch.stack(sweep_intrin_mats).permute(1, 0, 2, 3),#[1, 6, 4, 4]
torch.stack(sweep_ida_mats).permute(1, 0, 2, 3),#[1, 6, 4, 4]
torch.stack(sweep_sensor2sensor_mats).permute(1, 0, 2, 3),#is keysensor2sweepsensor [1, 6, 4, 4]
torch.stack(sweep_timestamps).permute(1, 0), #[1, 6]
img_metas,
]
if self.return_depth: #sweep_lidar_depth list: [1, 256, 704] torch.stack(sweep_lidar_depth)[6, 1, 256, 704]) [1, 6, 256, 704]
ret_list.append(torch.stack(sweep_lidar_depth).permute(1, 0, 2, 3))
return ret_list
get_gt
def get_gt(self, info, cams):
"""Generate gt labels from info.
Args:
info(dict): Infos needed to generate gt labels.
cams(list): Camera names.
Returns:
Tensor: GT bboxes.
Tensor: GT labels.
"""
ego2global_rotation = np.mean(
[info['cam_infos'][cam]['ego_pose']['rotation'] for cam in cams],
0)
ego2global_translation = np.mean([
info['cam_infos'][cam]['ego_pose']['translation'] for cam in cams
], 0)
trans = -np.array(ego2global_translation)
rot = Quaternion(ego2global_rotation).inverse
gt_boxes = list()
gt_labels = list()
for ann_info in info['ann_infos']:
# Use ego coordinate.
if (map_name_from_general_to_detection[ann_info['category_name']]
not in self.classes
or ann_info['num_lidar_pts'] + ann_info['num_radar_pts'] <=
0):
continue
box = Box(
ann_info['translation'],
ann_info['size'],
Quaternion(ann_info['rotation']),
velocity=ann_info['velocity'],
)
box.translate(trans)
box.rotate(rot) #转到自车ego坐标系
box_xyz = np.array(box.center)
box_dxdydz = np.array(box.wlh)[[1, 0, 2]]
box_yaw = np.array([box.orientation.yaw_pitch_roll[0]])
box_velo = np.array(box.velocity[:2])
gt_box = np.concatenate([box_xyz, box_dxdydz, box_yaw, box_velo]) #[9]
gt_boxes.append(gt_box)
gt_labels.append(
self.classes.index(map_name_from_general_to_detection[
ann_info['category_name']]))
return torch.Tensor(gt_boxes), torch.tensor(gt_labels)
bev层面的数据增强
def sample_bda_augmentation(self):
"""Generate bda augmentation values based on bda_config."""
if self.is_train:
rotate_bda = np.random.uniform(*self.bda_aug_conf['rot_lim'])
scale_bda = np.random.uniform(*self.bda_aug_conf['scale_lim'])
flip_dx = np.random.uniform() < self.bda_aug_conf['flip_dx_ratio']
flip_dy = np.random.uniform() < self.bda_aug_conf['flip_dy_ratio']
else:
rotate_bda = 0
scale_bda = 1.0
flip_dx = False
flip_dy = False
return rotate_bda, scale_bda, flip_dx, flip_dy
rotate_bda, scale_bda, flip_dx, flip_dy = self.sample_bda_augmentation(
)
bda_mat = sweep_imgs.new_zeros(4, 4)
bda_mat[3, 3] = 1
gt_boxes, bda_rot = bev_transform(gt_boxes, rotate_bda, scale_bda,
flip_dx, flip_dy)
bda_mat[:3, :3] = bda_rot
ret_list = [
sweep_imgs,
sweep_sensor2ego_mats,
sweep_intrins,
sweep_ida_mats,
sweep_sensor2sensor_mats,
bda_mat,
sweep_timestamps,
img_metas,
gt_boxes,
gt_labels,
]
if self.return_depth:
ret_list.append(image_data_list[7])
return ret_list
def bev_transform(gt_boxes, rotate_angle, scale_ratio, flip_dx, flip_dy):
rotate_angle = torch.tensor(rotate_angle / 180 * np.pi)
rot_sin = torch.sin(rotate_angle)
rot_cos = torch.cos(rotate_angle)
rot_mat = torch.Tensor([[rot_cos, -rot_sin, 0], [rot_sin, rot_cos, 0],
[0, 0, 1]])
scale_mat = torch.Tensor([[scale_ratio, 0, 0], [0, scale_ratio, 0],
[0, 0, scale_ratio]])
flip_mat = torch.Tensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]])
if flip_dx:
flip_mat = flip_mat @ torch.Tensor([[-1, 0, 0], [0, 1, 0], [0, 0, 1]])
if flip_dy:
flip_mat = flip_mat @ torch.Tensor([[1, 0, 0], [0, -1, 0], [0, 0, 1]])
rot_mat = flip_mat @ (scale_mat @ rot_mat)
if gt_boxes.shape[0] > 0:
gt_boxes[:, :3] = (rot_mat @ gt_boxes[:, :3].unsqueeze(-1)).squeeze(-1)
gt_boxes[:, 3:6] *= scale_ratio
gt_boxes[:, 6] += rotate_angle
if flip_dx:
gt_boxes[:, 6] = 2 * torch.asin(torch.tensor(1.0)) - gt_boxes[:, 6]
if flip_dy:
gt_boxes[:, 6] = -gt_boxes[:, 6]
gt_boxes[:, 7:] = (
rot_mat[:2, :2] @ gt_boxes[:, 7:].unsqueeze(-1)).squeeze(-1)
return gt_boxes, rot_mat
数据处理部分总结:
在get_image函数中,分别遍历6个相机'CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT', 'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT', 通过get_lidar_depth把雷达点和每个相机得到的图像匹配,得到point_depth,shape是[3778,3], (x_img,y_img,depth)每个图像像素坐标点配置上depth。


然后通过depth_transform,把得到的point_depth同样经过图像增强的resize,crop,flip,rotate,得到point_depth_augmented[256, 704],这个一个和网络输入尺寸一样大的单通道,每个位置保存的雷达深度值,大部分是0,只是把有雷达点的位置赋值上;

通过get_gt拿标注的框,gt_boxes转到了自车坐标系,一个box9个值,gt_box = np.concatenate([box_xyz, box_dxdydz, box_yaw, box_velo]) #[9]
gt_boxes, gt_labels = self.get_gt(self.infos[idx], cams)
最后在bev空间做增强:gt_boxes, bda_rot = bev_transform(gt_boxes, rotate_bda, scale_bda, flip_dx, flip_dy)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号