
kitti 数据集 可视化
1. 网址
KITTI官网网址:https://www.cvlibs.net/datasets/kitti/index.php
下载数据集:https://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
KITTI数据集论文:Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite
github可视化代码:https://github.com/kuixu/kitti_object_vis
其他: https://bbs.huaweicloud.com/blogs/371967
KITTI数据集的可视化 open3d库, https://zhuanlan.zhihu.com/p/691586674
2. kitti简介
KITTI数据集是由德国卡尔斯鲁厄理工学院 Karlsruhe Institute of Technology (KIT) 和美国芝加哥丰田技术研究院 Toyota Technological Institute at Chicago (TTI-C) 于2012年联合创办,是目前国际上最为常用的自动驾驶场景下的计算机视觉算法评测数据集之一。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI数据集包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。 KITTI数据集针对3D目标检测任务提供了14999张图像以及对应的点云,其中7481组用于训练,7518组用于测试,针对场景中的汽车、行人、自行车三类物体进行标注,共计80256个标记对象。
3. 采集车和传感器
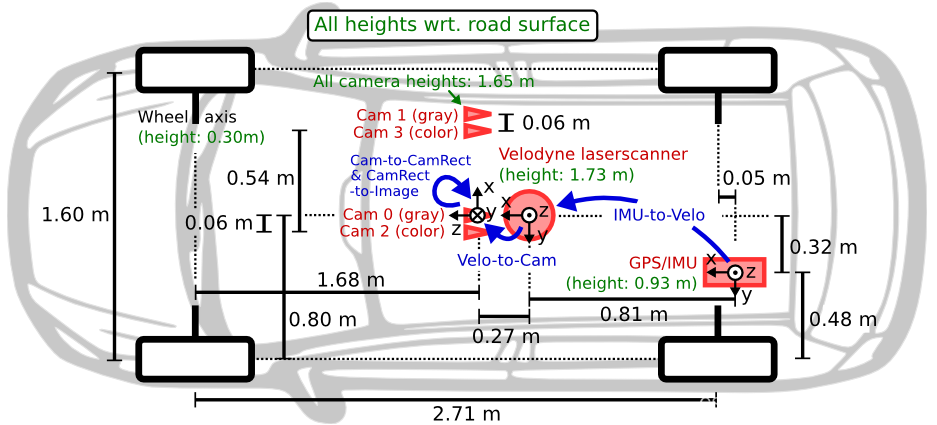
KITTI数据集采集车的传感器布置平面如上图所示,车辆装配有2个灰度摄像机,2个彩色摄像机,一个Velodyne 64线3D激光雷达,4个光学镜头,以及1个GPS导航系统,在上图中使用了红色标记。
2个一百四十万像素的PointGray Flea2灰度相机
2个一百四十万像素的PointGray Flea2彩色相机
1个64线的Velodyne激光雷达,10Hz,角分辨率为0.09度,每秒约一百三十万个点,水平视场360°,垂直视场26.8°,至多120米的距离范围
4个Edmund的光学镜片,水平视角约为90°,垂直视角约为35°
1个OXTS RT 3003的惯性导航系统(GPS/IMU),6轴,100Hz,分别率为0.02米,0.1°
注意:双目相机之间的距离为0.54米,点云到相机之间的距离为0.27米,在上图中使用了蓝色标记。
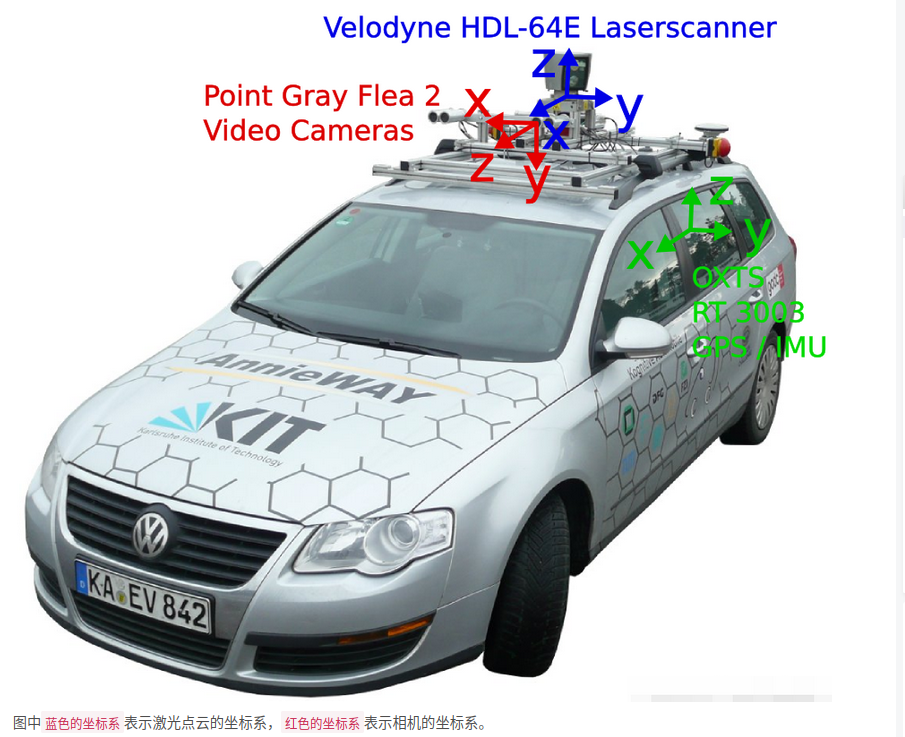
4.坐标系
5. 数据文件介绍
5.1 图像:
training/image_2/000001.png

5.2 点云:
training/velodyne/000001.bin
激光点云数据是以浮点二进制文件格式存储,每行包含8个浮点数数据,其中每个浮点数数据由四位十六进制数表示且通过空格隔开。一个点云数据由4个浮点数数据构成,分别表示点云的x、y、z、r(其中xyz表示点云的坐标,r表示强度或反射值),点云的存储方式如下表所示:

calib文件:
training/calib/000001.txt
P0: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 0.000000000000e+00 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.875744000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 4.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03
P3: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.395242000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.199936000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.729905000000e-03
R0_rect: 9.999239000000e-01 9.837760000000e-03 -7.445048000000e-03 -9.869795000000e-03 9.999421000000e-01 -4.278459000000e-03 7.402527000000e-03 4.351614000000e-03 9.999631000000e-01
Tr_velo_to_cam: 7.533745000000e-03 -9.999714000000e-01 -6.166020000000e-04 -4.069766000000e-03 1.480249000000e-02 7.280733000000e-04 -9.998902000000e-01 -7.631618000000e-02 9.998621000000e-01 7.523790000000e-03 1.480755000000e-02 -2.717806000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01



R0_rect矩阵的介绍:
Kitti 数据集是一个用于移动视觉和机器学习的著名数据集,经常用于自动驾驶汽车系统的研究。在 Kitti 数据集中,R0_rect表示的是矩形校正矩阵(rectifying rotation matrix)、即0号相机坐标系到矫正坐标系的旋转矩阵。
矩形校正是立体视觉计算中常用的一步,用于使得成对的立体相机的成像平面对齐,这样可以简化如立体匹配这样的后续处理步骤。实质上,它通过一个旋转将两个相机成像平面调整为共面,且使得它们的光轴平行。
R0_rect 矩阵用于将点从未校正的相机坐标系变换到校正后的坐标系。这一步是使用其他有关投影数据(如相机内部矩阵、深度信息等)之前必须进行的步骤。


5.3 label文件
training/label_2/000001.txt
Truck 0.00 0 -1.57 599.41 156.40 629.75 189.25 2.85 2.63 12.34 0.47 1.49 69.44 -1.56
Car 0.00 0 1.85 387.63 181.54 423.81 203.12 1.67 1.87 3.69 -16.53 2.39 58.49 1.57
Cyclist 0.00 3 -1.65 676.60 163.95 688.98 193.93 1.86 0.60 2.02 4.59 1.32 45.84 -1.55
DontCare -1 -1 -10 503.89 169.71 590.61 190.13 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 511.35 174.96 527.81 187.45 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 532.37 176.35 542.68 185.27 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 559.62 175.83 575.40 183.15 -1 -1 -1 -1000 -1000 -1000 -10



6. 可视化代码


import os
import sys
import numpy as np
import cv2
path_img = "/media/algo/data_1/everyday/20240928/kitti_object_vis-master/data/object/training/image_2/000001.png"
path_txt = "/media/algo/data_1/everyday/20240928/kitti_object_vis-master/data/object/training/label_2/000001.txt"
path_lidar = "/media/algo/data_1/everyday/20240928/kitti_object_vis-master/data/object/training/velodyne/000001.bin"
path_calib = "/media/algo/data_1/everyday/20240928/kitti_object_vis-master/data/object/training/calib/000001.txt"
def roty(t):
""" Rotation about the y-axis. """
c = np.cos(t)
s = np.sin(t)
return np.array([[c, 0, s], [0, 1, 0], [-s, 0, c]])
def compute_box_3d(obj, P):
""" Takes an object and a projection matrix (P) and projects the 3d
bounding box into the image plane.
Returns:
corners_2d: (8,2) array in left image coord.
corners_3d: (8,3) array in in rect camera coord.
"""
# compute rotational matrix around yaw axis
R = roty(obj.ry) #[3,3]
# 3d bounding box dimensions
l = obj.l
w = obj.w
h = obj.h
# 3d bounding box corners
x_corners = [l / 2, l / 2, -l / 2, -l / 2, l / 2, l / 2, -l / 2, -l / 2]
y_corners = [0, 0, 0, 0, -h, -h, -h, -h]
z_corners = [w / 2, -w / 2, -w / 2, w / 2, w / 2, -w / 2, -w / 2, w / 2]
#corners_3d[3, 8] rotate and translate 3d bounding box [3,3] @ [3, 8]
corners_3d = np.dot(R, np.vstack([x_corners, y_corners, z_corners]))
# print corners_3d.shape
corners_3d[0, :] = corners_3d[0, :] + obj.t[0]
corners_3d[1, :] = corners_3d[1, :] + obj.t[1]
corners_3d[2, :] = corners_3d[2, :] + obj.t[2]
# print 'cornsers_3d: ', corners_3d
# only draw 3d bounding box for objs in front of the camera
if np.any(corners_3d[2, :] < 0.1):
corners_2d = None
return corners_2d, np.transpose(corners_3d)
# project the 3d bounding box into the image plane
corners_2d = project_to_image(np.transpose(corners_3d), P)
# print 'corners_2d: ', corners_2d
return corners_2d, np.transpose(corners_3d)
def project_to_image(pts_3d, P):
""" Project 3d points to image plane.
Usage: pts_2d = projectToImage(pts_3d, P)
input: pts_3d: nx3 matrix
P: 3x4 projection matrix
output: pts_2d: nx2 matrix
P(3x4) dot pts_3d_extended(4xn) = projected_pts_2d(3xn)
=> normalize projected_pts_2d(2xn)
<=> pts_3d_extended(nx4) dot P'(4x3) = projected_pts_2d(nx3)
=> normalize projected_pts_2d(nx2)
"""
n = pts_3d.shape[0]
pts_3d_extend = np.hstack((pts_3d, np.ones((n, 1)))) #[8,4] <-- [8, 3]
# print(('pts_3d_extend shape: ', pts_3d_extend.shape))
pts_2d = np.dot(pts_3d_extend, np.transpose(P)) # nx3
pts_2d[:, 0] /= pts_2d[:, 2]
pts_2d[:, 1] /= pts_2d[:, 2]
return pts_2d[:, 0:2]
def inverse_rigid_trans(Tr):
""" Inverse a rigid body transform matrix (3x4 as [R|t])
[R'|-R't; 0|1]
"""
inv_Tr = np.zeros_like(Tr) # 3x4
inv_Tr[0:3, 0:3] = np.transpose(Tr[0:3, 0:3])
inv_Tr[0:3, 3] = np.dot(-np.transpose(Tr[0:3, 0:3]), Tr[0:3, 3])
return inv_Tr
class Object3d(object):
""" 3d object label """
def __init__(self, label_file_line):
data = label_file_line.split(" ")
data[1:] = [float(x) for x in data[1:]]
# extract label, truncation, occlusion
self.type = data[0] # 'Car', 'Pedestrian', ...
self.truncation = data[1] # truncated pixel ratio [0..1]
self.occlusion = int(
data[2]
) # 0=visible, 1=partly occluded, 2=fully occluded, 3=unknown
self.alpha = data[3] # object observation angle [-pi..pi]
# extract 2d bounding box in 0-based coordinates
self.xmin = data[4] # left
self.ymin = data[5] # top
self.xmax = data[6] # right
self.ymax = data[7] # bottom
self.box2d = np.array([self.xmin, self.ymin, self.xmax, self.ymax])
# extract 3d bounding box information
self.h = data[8] # box height
self.w = data[9] # box width
self.l = data[10] # box length (in meters)
self.t = (data[11], data[12], data[13]) # location (x,y,z) in camera coord.
self.ry = data[14] # yaw angle (around Y-axis in camera coordinates) [-pi..pi]
def estimate_diffculty(self):
""" Function that estimate difficulty to detect the object as defined in kitti website"""
# height of the bounding box
bb_height = np.abs(self.xmax - self.xmin)
if bb_height >= 40 and self.occlusion == 0 and self.truncation <= 0.15:
return "Easy"
elif bb_height >= 25 and self.occlusion in [0, 1] and self.truncation <= 0.30:
return "Moderate"
elif (
bb_height >= 25 and self.occlusion in [0, 1, 2] and self.truncation <= 0.50
):
return "Hard"
else:
return "Unknown"
def print_object(self):
print(
"Type, truncation, occlusion, alpha: %s, %d, %d, %f"
% (self.type, self.truncation, self.occlusion, self.alpha)
)
print(
"2d bbox (x0,y0,x1,y1): %f, %f, %f, %f"
% (self.xmin, self.ymin, self.xmax, self.ymax)
)
print("3d bbox h,w,l: %f, %f, %f" % (self.h, self.w, self.l))
print(
"3d bbox location, ry: (%f, %f, %f), %f"
% (self.t[0], self.t[1], self.t[2], self.ry)
)
print("Difficulty of estimation: {}".format(self.estimate_diffculty()))
def draw_projected_box3d(image, qs, color=(0, 255, 0), thickness=2):
""" Draw 3d bounding box in image
qs: (8,3) array of vertices for the 3d box in following order:
1 -------- 0
/| /|
2 -------- 3 .
| | | |
. 5 -------- 4
|/ |/
6 -------- 7
"""
qs = qs.astype(np.int32)
for k in range(0, 4):
# Ref: http://docs.enthought.com/mayavi/mayavi/auto/mlab_helper_functions.html
i, j = k, (k + 1) % 4
# use LINE_AA for opencv3
# cv2.line(image, (qs[i,0],qs[i,1]), (qs[j,0],qs[j,1]), color, thickness, cv2.CV_AA)
cv2.line(image, (qs[i, 0], qs[i, 1]), (qs[j, 0], qs[j, 1]), color, thickness)
i, j = k + 4, (k + 1) % 4 + 4
cv2.line(image, (qs[i, 0], qs[i, 1]), (qs[j, 0], qs[j, 1]), color, thickness)
i, j = k, k + 4
cv2.line(image, (qs[i, 0], qs[i, 1]), (qs[j, 0], qs[j, 1]), color, thickness)
return image
def read_txt_to_objs(path_txt):
lines = [line.rstrip() for line in open(path_txt)]
objects = [Object3d(line) for line in lines]
return objects
def get_lidar_in_image_fov(
pc_velo, calib, xmin, ymin, xmax, ymax, return_more=False, clip_distance=2.0
):
""" Filter lidar points, keep those in image FOV """
pts_2d = calib.project_velo_to_image(pc_velo)
fov_inds = (
(pts_2d[:, 0] < xmax)
& (pts_2d[:, 0] >= xmin)
& (pts_2d[:, 1] < ymax)
& (pts_2d[:, 1] >= ymin)
)
fov_inds = fov_inds & (pc_velo[:, 0] > clip_distance)
imgfov_pc_velo = pc_velo[fov_inds, :]
if return_more:
return imgfov_pc_velo, pts_2d, fov_inds
else:
return imgfov_pc_velo
class Calibration(object):
""" Calibration matrices and utils
3d XYZ in <label>.txt are in rect camera coord.
2d box xy are in image2 coord
Points in <lidar>.bin are in Velodyne coord.
y_image2 = P^2_rect * x_rect
y_image2 = P^2_rect * R0_rect * Tr_velo_to_cam * x_velo
x_ref = Tr_velo_to_cam * x_velo
x_rect = R0_rect * x_ref
P^2_rect = [f^2_u, 0, c^2_u, -f^2_u b^2_x;
0, f^2_v, c^2_v, -f^2_v b^2_y;
0, 0, 1, 0]
= K * [1|t]
image2 coord:
----> x-axis (u)
|
|
v y-axis (v)
velodyne coord:
front x, left y, up z
rect/ref camera coord:
right x, down y, front z
Ref (KITTI paper): http://www.cvlibs.net/publications/Geiger2013IJRR.pdf
TODO(rqi): do matrix multiplication only once for each projection.
"""
def __init__(self, calib_filepath, from_video=False):
if from_video:
calibs = self.read_calib_from_video(calib_filepath)
else:
calibs = self.read_calib_file(calib_filepath)
# Projection matrix from rect camera coord to image2 coord
self.P = calibs["P2"]
self.P = np.reshape(self.P, [3, 4])
# Rigid transform from Velodyne coord to reference camera coord
self.V2C = calibs["Tr_velo_to_cam"]
self.V2C = np.reshape(self.V2C, [3, 4])
self.C2V = inverse_rigid_trans(self.V2C)
# Rotation from reference camera coord to rect camera coord
self.R0 = calibs["R0_rect"]
self.R0 = np.reshape(self.R0, [3, 3])
# Camera intrinsics and extrinsics
self.c_u = self.P[0, 2]
self.c_v = self.P[1, 2]
self.f_u = self.P[0, 0]
self.f_v = self.P[1, 1]
self.b_x = self.P[0, 3] / (-self.f_u) # relative
self.b_y = self.P[1, 3] / (-self.f_v)
def read_calib_file(self, filepath):
""" Read in a calibration file and parse into a dictionary.
Ref: https://github.com/utiasSTARS/pykitti/blob/master/pykitti/utils.py
"""
data = {}
with open(filepath, "r") as f:
for line in f.readlines():
line = line.rstrip()
if len(line) == 0:
continue
key, value = line.split(":", 1)
# The only non-float values in these files are dates, which
# we don't care about anyway
try:
data[key] = np.array([float(x) for x in value.split()])
except ValueError:
pass
return data
def read_calib_from_video(self, calib_root_dir):
""" Read calibration for camera 2 from video calib files.
there are calib_cam_to_cam and calib_velo_to_cam under the calib_root_dir
"""
data = {}
cam2cam = self.read_calib_file(
os.path.join(calib_root_dir, "calib_cam_to_cam.txt")
)
velo2cam = self.read_calib_file(
os.path.join(calib_root_dir, "calib_velo_to_cam.txt")
)
Tr_velo_to_cam = np.zeros((3, 4))
Tr_velo_to_cam[0:3, 0:3] = np.reshape(velo2cam["R"], [3, 3])
Tr_velo_to_cam[:, 3] = velo2cam["T"]
data["Tr_velo_to_cam"] = np.reshape(Tr_velo_to_cam, [12])
data["R0_rect"] = cam2cam["R_rect_00"]
data["P2"] = cam2cam["P_rect_02"]
return data
def cart2hom(self, pts_3d):
""" Input: nx3 points in Cartesian
Oupput: nx4 points in Homogeneous by pending 1
"""
n = pts_3d.shape[0]
pts_3d_hom = np.hstack((pts_3d, np.ones((n, 1))))
return pts_3d_hom
# ===========================
# ------- 3d to 3d ----------
# ===========================
def project_velo_to_ref(self, pts_3d_velo):
pts_3d_velo = self.cart2hom(pts_3d_velo) # nx4
return np.dot(pts_3d_velo, np.transpose(self.V2C))
def project_ref_to_velo(self, pts_3d_ref):
pts_3d_ref = self.cart2hom(pts_3d_ref) # nx4
return np.dot(pts_3d_ref, np.transpose(self.C2V))
def project_rect_to_ref(self, pts_3d_rect):
""" Input and Output are nx3 points """
return np.transpose(np.dot(np.linalg.inv(self.R0), np.transpose(pts_3d_rect)))
def project_ref_to_rect(self, pts_3d_ref):
""" Input and Output are nx3 points """
return np.transpose(np.dot(self.R0, np.transpose(pts_3d_ref)))
def project_rect_to_velo(self, pts_3d_rect):
""" Input: nx3 points in rect camera coord.
Output: nx3 points in velodyne coord.
"""
pts_3d_ref = self.project_rect_to_ref(pts_3d_rect)
return self.project_ref_to_velo(pts_3d_ref)
def project_velo_to_rect(self, pts_3d_velo):
pts_3d_ref = self.project_velo_to_ref(pts_3d_velo)
return self.project_ref_to_rect(pts_3d_ref)
# ===========================
# ------- 3d to 2d ----------
# ===========================
def project_rect_to_image(self, pts_3d_rect):
""" Input: nx3 points in rect camera coord.
Output: nx2 points in image2 coord.
"""
pts_3d_rect = self.cart2hom(pts_3d_rect)
pts_2d = np.dot(pts_3d_rect, np.transpose(self.P)) # nx3
pts_2d[:, 0] /= pts_2d[:, 2]
pts_2d[:, 1] /= pts_2d[:, 2]
return pts_2d[:, 0:2]
def project_velo_to_image(self, pts_3d_velo):
""" Input: nx3 points in velodyne coord.
Output: nx2 points in image2 coord.
"""
pts_3d_rect = self.project_velo_to_rect(pts_3d_velo)
return self.project_rect_to_image(pts_3d_rect)
def project_8p_to_4p(self, pts_2d):
x0 = np.min(pts_2d[:, 0])
x1 = np.max(pts_2d[:, 0])
y0 = np.min(pts_2d[:, 1])
y1 = np.max(pts_2d[:, 1])
x0 = max(0, x0)
# x1 = min(x1, proj.image_width)
y0 = max(0, y0)
# y1 = min(y1, proj.image_height)
return np.array([x0, y0, x1, y1])
def project_velo_to_4p(self, pts_3d_velo):
""" Input: nx3 points in velodyne coord.
Output: 4 points in image2 coord.
"""
pts_2d_velo = self.project_velo_to_image(pts_3d_velo)
return self.project_8p_to_4p(pts_2d_velo)
# ===========================
# ------- 2d to 3d ----------
# ===========================
def project_image_to_rect(self, uv_depth):
""" Input: nx3 first two channels are uv, 3rd channel
is depth in rect camera coord.
Output: nx3 points in rect camera coord.
"""
n = uv_depth.shape[0]
x = ((uv_depth[:, 0] - self.c_u) * uv_depth[:, 2]) / self.f_u + self.b_x
y = ((uv_depth[:, 1] - self.c_v) * uv_depth[:, 2]) / self.f_v + self.b_y
pts_3d_rect = np.zeros((n, 3))
pts_3d_rect[:, 0] = x
pts_3d_rect[:, 1] = y
pts_3d_rect[:, 2] = uv_depth[:, 2]
return pts_3d_rect
def project_image_to_velo(self, uv_depth):
pts_3d_rect = self.project_image_to_rect(uv_depth)
return self.project_rect_to_velo(pts_3d_rect)
def project_depth_to_velo(self, depth, constraint_box=True):
depth_pt3d = get_depth_pt3d(depth)
depth_UVDepth = np.zeros_like(depth_pt3d)
depth_UVDepth[:, 0] = depth_pt3d[:, 1]
depth_UVDepth[:, 1] = depth_pt3d[:, 0]
depth_UVDepth[:, 2] = depth_pt3d[:, 2]
# print("depth_pt3d:",depth_UVDepth.shape)
depth_pc_velo = self.project_image_to_velo(depth_UVDepth)
# print("dep_pc_velo:",depth_pc_velo.shape)
if constraint_box:
depth_box_fov_inds = (
(depth_pc_velo[:, 0] < cbox[0][1])
& (depth_pc_velo[:, 0] >= cbox[0][0])
& (depth_pc_velo[:, 1] < cbox[1][1])
& (depth_pc_velo[:, 1] >= cbox[1][0])
& (depth_pc_velo[:, 2] < cbox[2][1])
& (depth_pc_velo[:, 2] >= cbox[2][0])
)
depth_pc_velo = depth_pc_velo[depth_box_fov_inds]
return depth_pc_velo
calib = Calibration(path_calib)
img = cv2.imread(path_img)
objects = read_txt_to_objs(path_txt)
img1 = np.copy(img) # for 2d bbox
img2 = np.copy(img) # for 3d bbox
for obj in objects:
if obj.type == "DontCare":
continue
if obj.type == "Car":
cv2.rectangle(
img1,
(int(obj.xmin), int(obj.ymin)),
(int(obj.xmax), int(obj.ymax)),
(0, 255, 0),
2,
)
if obj.type == "Pedestrian":
cv2.rectangle(
img1,
(int(obj.xmin), int(obj.ymin)),
(int(obj.xmax), int(obj.ymax)),
(255, 255, 0),
2,
)
if obj.type == "Cyclist":
cv2.rectangle(
img1,
(int(obj.xmin), int(obj.ymin)),
(int(obj.xmax), int(obj.ymax)),
(0, 255, 255),
2,
)
box3d_pts_2d, _ = compute_box_3d(obj, calib.P)
if box3d_pts_2d is None:
print("something wrong in the 3D box.")
continue
if obj.type == "Car":
img2 = draw_projected_box3d(img2, box3d_pts_2d, color=(0, 255, 0))
elif obj.type == "Pedestrian":
img2 = draw_projected_box3d(img2, box3d_pts_2d, color=(255, 255, 0))
elif obj.type == "Cyclist":
img2 = draw_projected_box3d(img2, box3d_pts_2d, color=(0, 255, 255))
cv2.namedWindow("img-2d", 0)
cv2.imshow("img-2d", img1)
cv2.namedWindow("img-3d", 0)
cv2.imshow("img-3d", img2)
cv2.waitKey()
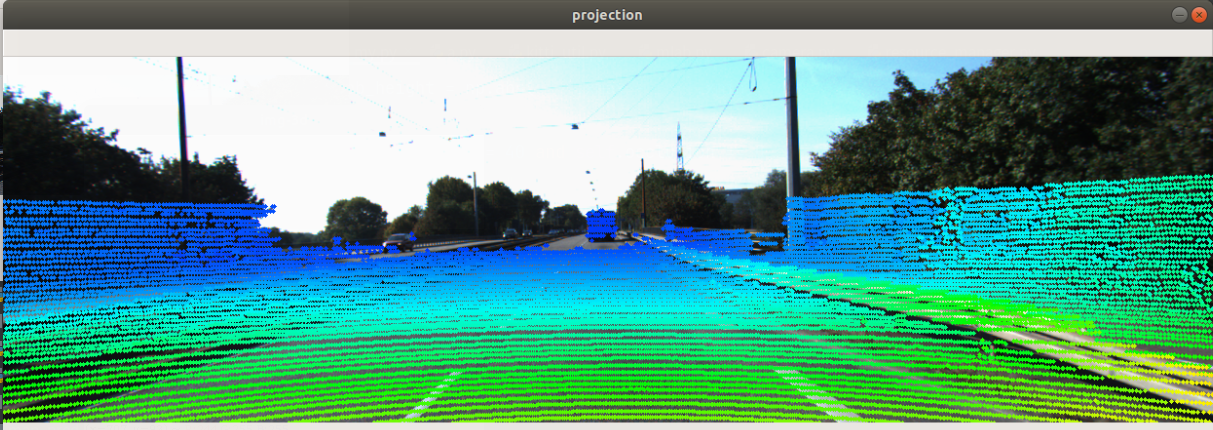
## show_lidar_on_image
dtype = np.float32
n_vec = 4
scan = np.fromfile(path_lidar, dtype=dtype)
pc_velo = scan.reshape((-1, n_vec))
pc_velo = pc_velo[:, 0:3]
img_height, img_width, _ = img.shape
imgfov_pc_velo, pts_2d, fov_inds = get_lidar_in_image_fov(
pc_velo, calib, 0, 0, img_width, img_height, True
)
imgfov_pts_2d = pts_2d[fov_inds, :]
imgfov_pc_rect = calib.project_velo_to_rect(imgfov_pc_velo)
import matplotlib.pyplot as plt
cmap = plt.cm.get_cmap("hsv", 256)
cmap = np.array([cmap(i) for i in range(256)])[:, :3] * 255
for i in range(imgfov_pts_2d.shape[0]):
depth = imgfov_pc_rect[i, 2]
color = cmap[int(640.0 / depth), :]
cv2.circle(
img,
(int(np.round(imgfov_pts_2d[i, 0])), int(np.round(imgfov_pts_2d[i, 1]))),
2,
color=tuple(color),
thickness=-1,
)
cv2.imshow("projection", img)
cv2.waitKey(0)
open3d库显示可视化kitti数据集, https://zhuanlan.zhihu.com/p/691586674
show_lidar_with_3dbox

open3d_kitti_vision.py
import os
import cv2
import numpy as np
import open3d as o3d
from open3d_vision_utils import draw_lidar, draw_2dbox, gen_3dbox,project_box3d, draw_project, draw_box3d_lidar, get_lidar_in_image_fov
class Kitti:
def __init__(self, root_path="./data/kitti/", ind=0) -> None:
self.root_path = root_path
train_file = os.path.join(root_path, "train.txt")
with open(train_file, 'r') as f:
names = f.readlines()
self.names = [name.rstrip() for name in names]
self.name = self.names[ind]
def get_image(self, show=False):
img_path = os.path.join(self.root_path, "training/image_2", self.name+".png")
img = cv2.imread(img_path)
if show and os.path.exists(img_path):
cv2.imshow("origin image", img)
if cv2.waitKey(0) == ord("q"):
cv2.destroyAllWindows()
return img
def get_lidar(self, show=False):
lidar_path = os.path.join(self.root_path, "training/velodyne", self.name+".bin")
lidar = np.fromfile(lidar_path, dtype=np.float32)
lidar = lidar.reshape((-1, 4))
if show:
#创建窗口
vis = o3d.visualization.Visualizer()
vis.create_window(width=800, height=600)
# 创建坐标轴
mesh_frame = o3d.geometry.TriangleMesh.create_coordinate_frame(size=5, origin=[0, 0, 0])
vis.add_geometry(mesh_frame)
vis = draw_lidar(lidar, vis)
vis.run()
return lidar
def get_calib(self):
calib = {}
calib_path = os.path.join(self.root_path, "training/calib", self.name+".txt")
with open(calib_path, 'r') as cf:
infos = cf.readlines()
infos = [x.rstrip() for x in infos]
for info in infos:
if len(info) == 0:
continue
key, value = info.split(":", 1)
calib[key] = np.array([float(x) for x in value.split()])
calib_format = self.format_calib(calib)
return calib_format
def format_calib(self, calib):
calib_format = {}
# projection matrix from rect coord to image coord.
rect2image = calib["P2"]
rect2image = rect2image.reshape([3, 4])
calib_format["rect2image"] = rect2image
# projection matrix from lidar coord to reference cam coord.
lidar2cam = calib["Tr_velo_to_cam"]
lidar2cam = lidar2cam.reshape([3, 4])
calib_format["lidar2cam"] = lidar2cam
# projection matrix from rect cam coord to reference cam coord.
rect2ref = calib["R0_rect"]
rect2ref = rect2ref.reshape([3, 3])
calib_format["rect2ref"] = rect2ref
return calib_format
def get_anns(self):
anns = []
label_path = os.path.join(self.root_path, "training/label_2", self.name+".txt")
with open(label_path, 'r') as lf:
labels = lf.readlines()
labels = [label.rstrip() for label in labels]
for label in labels:
ann_format = {}
ann = label.split(" ")
class_name = ann[0]
ann_format["class_name"]=class_name
ann_ = [float(x) for x in ann[1:]]
truncation = ann_[0] # truncated pixel ratio [0..1]
ann_format["truncation"]=truncation
occlusion = ann_[1] # 0=visible, 1=partly occluded, 2=fully occluded, 3=unknown
ann_format["occlusion"]=occlusion
alpha = ann_[2]
ann_format["alpha"]=alpha # object observation angle [-pi..pi]
#2D box
xmin, ymin, xmax, ymax = ann_[3], ann_[4], ann_[5], ann_[6]
box2d = np.array([xmin, ymin, xmax, ymax])
ann_format["box2d"]=box2d
#3D box
box3d = {}
h, w, l = ann_[7], ann_[8], ann_[9]
cx, cy, cz = ann_[10], ann_[11], ann_[12]
box3d["dim"] = np.array([l, w, h])
box3d["center"] = np.array([cx, cy, cz])
yaw = ann_[13]
box3d["rotation"] = yaw# yaw angle [-pi..pi]
ann_format["box3d"]=box3d
anns.append(ann_format)
return anns
class VisKitti:
def __init__(self, root_path="./data/kitti/", ind=0) -> None:
self.kitti = Kitti(root_path=root_path, ind=ind)
self.calib = self.kitti.get_calib()
self.anns = self.kitti.get_anns()
def show_origin_image(self):
self.kitti.get_image(show=True)
def show_origin_lidar(self):
self.kitti.get_lidar(show=True)
def show_image_with_2dbox(self, save=False):
img = self.kitti.get_image()
bbox = []
names = []
for ann in self.anns:
bbox.append(ann["box2d"])
names.append(ann["class_name"])
draw_2dbox(img, bbox, names, save=save)
def show_image_with_project_3dbox(self, show=True):
img = self.kitti.get_image()
bbox = []
for ann in self.anns:
bbox.append(ann["box3d"])
bbox3d = gen_3dbox(bbox3d=bbox)
project_xy,_ = project_box3d(bbox3d, self.calib)
draw_project(img, project_xy, save=False)
def show_lidar_with_3dbox(self, img_fov=False):
bbox = []
for ann in self.anns:
bbox.append(ann["box3d"])
bbox3d = gen_3dbox(bbox3d=bbox)
#创建窗口
vis = o3d.visualization.Visualizer()
vis.create_window(width=800, height=600)
# 创建坐标轴
mesh_frame = o3d.geometry.TriangleMesh.create_coordinate_frame(size=5, origin=[0, 0, 0])
vis.add_geometry(mesh_frame)
lidar = self.kitti.get_lidar()
vis = draw_lidar(lidar, vis)
vis = draw_box3d_lidar(bbox3d, self.calib, vis)
vis.run()
def show_lidar_on_image(self,img_width=1238, img_height=374):
""" Project LiDAR points to image """
img = self.kitti.get_image()
lidar = self.kitti.get_lidar()
calib = self.calib
imgfov_pc_velo, pts_2d, fov_inds = get_lidar_in_image_fov(
lidar, calib, 0, 0, img_width, img_height, True)
imgfov_pts_2d = pts_2d[fov_inds, :]
import matplotlib
cmap = matplotlib.colormaps["hsv"]
cmap = np.array([cmap(i) for i in range(256)])[:, :3] * 255
for i in range(imgfov_pts_2d.shape[0]):
depth = abs(imgfov_pc_velo[i, 0])
color = cmap[max(int(600.0 / depth),0), :]
cv2.circle(
img,
(int(np.round(imgfov_pts_2d[i, 0])), int(np.round(imgfov_pts_2d[i, 1]))),
2,
color=tuple(color),
thickness=-1,
)
cv2.imshow("projection", img)
if cv2.waitKey(0) == ord("q"):
cv2.destroyAllWindows()
return img
if __name__ == "__main__":
vis = VisKitti(root_path="/media/algo/data_1/everyday/20240928/kitti_object_vis-master/data/object", ind=1)
print("1: show_origin_image")
print("2: show_origin_lidar")
print("3: show_image_with_2dbox")
print("4: show_image_with_project_3dbox")
print("5: show_lidar_with_3dbox")
print("6: show_image_with_lidar")
choice = input("please choice number:")
if choice=="1":
vis.show_origin_image()
elif choice=="2":
vis.show_origin_lidar()
elif choice=="3":
vis.show_image_with_2dbox()
elif choice=="4":
vis.show_image_with_project_3dbox()
elif choice=="5":
vis.show_lidar_with_3dbox()
elif choice=="6":
vis.show_lidar_on_image()
open3d_vision_utils.py
import os
import cv2
import numpy as np
import open3d as o3d
def draw_lidar(pc,vis):
points=pc[:,:3]
points_intensity = pc[:, 3] *255 # intensity
#将array格式点云转为open3d
pointcloud = o3d.geometry.PointCloud()
pointcloud.points = o3d.utility.Vector3dVector(points)
# pointcloud.paint_uniform_color([1,0,0])
points_colors =np.zeros([points.shape[0],3])
for i in range(points_intensity.shape[0]):
points_colors[i,:] =[1, points_intensity[i], points_intensity[i]*0.5]
pointcloud.colors = o3d.utility.Vector3dVector(points_colors) # 根据 intensity 为点云着色
# 设置点云渲染参数
opt=vis.get_render_option()
# 设置背景色(这里为白色)
opt.background_color=np.array([255, 255, 255])
# 设置渲染点的大小
opt.point_size=2.0
# 添加点云
vis.add_geometry(pointcloud)
return vis
def draw_gt_boxes3d(gt_boxes3d, vis):
""" Draw 3D bounding boxes, gt_boxes3d: XYZs of the box corners"""
num = len(gt_boxes3d)
for n in range(num):
points_3dbox = gt_boxes3d[n]
lines_box = np.array([[0, 1], [1, 2], [2, 3],[0, 3], [4, 5], [5, 6], [6, 7], [4, 7],
[0, 4], [1, 5], [2, 6], [3, 7]]) #指明哪两个顶点之间相连
colors = np.array([[0, 1, 0] for j in range(len(lines_box))])
line_set = o3d.geometry.LineSet() #创建line对象
line_set.lines = o3d.utility.Vector2iVector(lines_box) #将八个顶点转换成o3d可以使用的数据类型
line_set.colors = o3d.utility.Vector3dVector(colors) #设置每条线段的颜色
line_set.points = o3d.utility.Vector3dVector(points_3dbox) #把八个顶点的空间信息转换成o3d可以使用的数据类型
#将矩形框加入到窗口中
vis.add_geometry(line_set)
return vis
def draw_box3d_lidar(bbox3d, calib, vis):
# method 1
lidar2cam = calib["lidar2cam"]
lidar2cam = expand_matrix(lidar2cam)
cam2rect_ = calib["rect2ref"]
cam2rect = np.eye(4, 4)
cam2rect[:3, :3] = cam2rect_
lidar2rec = np.dot(lidar2cam, cam2rect)
rec2lidar = np.linalg.inv(lidar2rec) #(AB)-1 = B-1@A-1
all_lidar_box3d = []
for box3d in bbox3d:
if np.any(box3d[2, :] < 0.1):
continue
box3d = np.concatenate([box3d, np.ones((1, 8))], axis=0)
lidar_box3d = np.dot(rec2lidar, box3d)[:3, :]
lidar_box3d = np.transpose(lidar_box3d)
all_lidar_box3d.append(lidar_box3d)
vis = draw_gt_boxes3d(all_lidar_box3d, vis)
return vis
def get_lidar_in_image_fov(pc_velo, calib, xmin, ymin, xmax, ymax, return_more=False, clip_distance=1.0):
""" Filter lidar points, keep those in image FOV """
lidar2cam = calib["lidar2cam"]
lidar2cam = expand_matrix(lidar2cam)
cam2rect_ = calib["rect2ref"]
cam2rect = np.eye(4, 4)
cam2rect[:3, :3] = cam2rect_
lidar2rec = np.dot(cam2rect, lidar2cam)
P = calib["rect2image"]
P = expand_matrix(P)
project_velo_to_image = np.dot(P, lidar2rec)
pc_velo_T = pc_velo.T
pc_velo_T = np.concatenate([pc_velo_T[:3,:], np.ones((1, pc_velo_T.shape[1]))], axis=0)
project_3dbox = np.dot(project_velo_to_image, pc_velo_T)[:3, :]
pz = project_3dbox[2, :]
px = project_3dbox[0, :]/pz
py = project_3dbox[1, :]/pz
pts_2d = np.vstack((px, py)).T
fov_inds = (
(pts_2d[:, 0] < xmax)
& (pts_2d[:, 0] >= xmin)
& (pts_2d[:, 1] < ymax)
& (pts_2d[:, 1] >= ymin)
)
fov_inds = fov_inds & (pc_velo[:, 0] > clip_distance)
imgfov_pc_velo = pc_velo[fov_inds, :]
return imgfov_pc_velo, pts_2d, fov_inds
def draw_2dbox(img, bbox, names=None, save=False):
assert len(bbox)==len(names), "names not match bbox"
color_map = {"Car":(0, 255, 0), "Pedestrian":(255, 0, 0), "Cyclist":(0, 0, 255)}
for i, box in enumerate(bbox):
name = names[i]
if name not in color_map.keys():
continue
color = color_map[name]
cv2.rectangle(
img,
(int(box[0]), int(box[1])),
(int(box[2]), int(box[3])),
color,
2,
)
name_coord = (int(box[0]), int(max(box[1]-5, 0)))
cv2.putText(img, name, name_coord,
cv2.FONT_HERSHEY_PLAIN, 1, color, 1)
cv2.imshow("image_with_2dbox", img)
if cv2.waitKey(0) == ord("q"):
cv2.destroyAllWindows()
if save:
cv2.imwrite("image_with_2dbox.jpg", img)
def rotx(t):
""" 3D Rotation about the x-axis. """
c = np.cos(t)
s = np.sin(t)
return np.array([[1, 0, 0], [0, c, -s], [0, s, c]])
def roty(t):
""" Rotation about the y-axis. """
c = np.cos(t)
s = np.sin(t)
return np.array([[c, 0, s], [0, 1, 0], [-s, 0, c]])
def rotz(t):
""" Rotation about the z-axis. """
c = np.cos(t)
s = np.sin(t)
return np.array([[c, -s, 0], [s, c, 0], [0, 0, 1]])
def expand_matrix(matrix):
new_matrix = np.eye(4, 4)
new_matrix[:3, :] = matrix
return new_matrix
def gen_3dbox(bbox3d):
corners_3d_all = []
for box in bbox3d:
center = box["center"]
l, w, h = box["dim"]
angle = box["rotation"]
R = roty(angle)
# 3d bounding box corners
x_corners = [l / 2, l / 2, -l / 2, -l / 2, l / 2, l / 2, -l / 2, -l / 2]
y_corners = [0, 0, 0, 0, -h, -h, -h, -h]
z_corners = [w / 2, -w / 2, -w / 2, w / 2, w / 2, -w / 2, -w / 2, w / 2]
corners = np.vstack([x_corners, y_corners, z_corners])
corners_3d = np.dot(R, corners)
corners_3d[0, :] += center[0]
corners_3d[1, :] += center[1]
corners_3d[2, :] += center[2]
corners_3d_all.append(corners_3d)
return corners_3d_all
def project_box3d(bbox3d, calib):
P = calib["rect2image"]
P = expand_matrix(P)
project_xy = []
project_z = []
for box3d in bbox3d:
if np.any(box3d[2, :] < 0.1):
continue
box3d = np.concatenate([box3d, np.zeros((1, 8))], axis=0)
project_3dbox = np.dot(P, box3d)[:3, :]
pz = project_3dbox[2, :]
px = project_3dbox[0, :]/pz
py = project_3dbox[1, :]/pz
xy = np.stack([px, py], axis=1)
project_xy.append(xy)
project_z.append(pz)
print(project_xy)
return project_xy, project_z
def draw_project(img, project_xy, save=False):
color_map = {"Car":(0, 255, 0), "Pedestrian":(255, 0, 0), "Cyclist":(0, 0, 255)}
for i, qs in enumerate(project_xy):
color = (0, 255, 0)
qs = qs.astype(np.int32)
for k in range(0, 4):
i, j = k, (k + 1) % 4
# use LINE_AA for opencv3
cv2.line(img, (qs[i, 0], qs[i, 1]), (qs[j, 0], qs[j, 1]), color, 1)
i, j = k + 4, (k + 1) % 4 + 4
cv2.line(img, (qs[i, 0], qs[i, 1]), (qs[j, 0], qs[j, 1]), color, 1)
i, j = k, k + 4
cv2.line(img, (qs[i, 0], qs[i, 1]), (qs[j, 0], qs[j, 1]), color, 1)
cv2.imshow("image_with_projectbox", img)
if cv2.waitKey(0) == ord("q"):
cv2.destroyAllWindows()
if save:
cv2.imwrite("image_with_projectbox.jpg", img)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号