pytorch ddp 范例
pytorch ddp 范例:
################
## main.py文件
import argparse
from tqdm import tqdm
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
# 新增:
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
### 1. 基础模块 ###
# 假设我们的模型是这个,与DDP无关
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.conv2_bn = nn.BatchNorm2d(16, eps=1e-4, momentum=0.01)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
#x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv2_bn(self.conv2(x))))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 假设我们的数据是这个
def get_dataset():
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
my_trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# DDP:使用DistributedSampler,DDP帮我们把细节都封装起来了。
# 用,就完事儿!sampler的原理,第二篇中有介绍。
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)
# DDP:需要注意的是,这里的batch_size指的是每个进程下的batch_size。
# 也就是说,总batch_size是这里的batch_size再乘以并行数(world_size)。
trainloader = torch.utils.data.DataLoader(my_trainset,
batch_size=16, num_workers=2, sampler=train_sampler)
return trainloader
### 2. 初始化我们的模型、数据、各种配置 ####
# DDP:从外部得到local_rank参数
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1, type=int)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank
# DDP:DDP backend初始化
torch.cuda.set_device(local_rank)
dist.init_process_group(backend='nccl') # nccl是GPU设备上最快、最推荐的后端
# 准备数据,要在DDP初始化之后进行
trainloader = get_dataset()
# 构造模型
model = ToyModel().to(local_rank)
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(local_rank)
# DDP: Load模型要在构造DDP模型之前,且只需要在master上加载就行了。
ckpt_path = None
if dist.get_rank() == 0 and ckpt_path is not None:
model.load_state_dict(torch.load(ckpt_path))
# DDP: 构造DDP model
model = DDP(model, device_ids=[local_rank], output_device=local_rank)
# DDP: 要在构造DDP model之后,才能用model初始化optimizer。
#因为optimizer和DDP是没有关系的,所以optimizer初始状态的同一性是不被DDP保证的!
#大多数官方optimizer,其实现能保证从同样状态的model初始化时,其初始状态是相同的。
#所以这边我们只要保证在DDP模型创建后才初始化optimizer,就不用做额外的操作。
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
# 假设我们的loss是这个
loss_func = nn.CrossEntropyLoss().to(local_rank)
### 3. 网络训练 ###
model.train()
iterator = tqdm(range(100))
for epoch in iterator:
# DDP:设置sampler的epoch,
# DistributedSampler需要这个来指定shuffle方式,
# 通过维持各个进程之间的相同随机数种子使不同进程能获得同样的shuffle效果。
trainloader.sampler.set_epoch(epoch)
# 后面这部分,则与原来完全一致了。
for data, label in trainloader:
data, label = data.to(local_rank), label.to(local_rank)
optimizer.zero_grad()
prediction = model(data)
loss = loss_func(prediction, label)
loss.backward()
iterator.desc = "loss = %0.3f" % loss
optimizer.step()
# DDP:
# 1. save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。
# 因为model其实是DDP model,参数是被`model=DDP(model)`包起来的。
# 2. 只需要在进程0上保存一次就行了,避免多次保存重复的东西。
if dist.get_rank() == 0:
torch.save(model.module.state_dict(), "%d.ckpt" % epoch)
################
## Bash运行
# DDP: 使用torch.distributed.launch启动DDP模式
# 使用CUDA_VISIBLE_DEVICES,来决定使用哪些GPU
# CUDA_VISIBLE_DEVICES="0,1" python -m torch.distributed.launch --nproc_per_node 2 main.py
pytorch ddp原理
- 更加深入的了解了下ddp模式下index的分配机制。
比如总共10个数据, 在程序开始的时候会随机打乱总的indices。
由于每张卡上打乱的随机种子是相同的,因此可以保证每个进程上的数据集是不重复的,并且能取到所有的数据集。
A机器数据量10,B机器数据量10,batchsize都是2
master机器分配的:
indices=[4, 7, 3, 0, 6]
Slave机器分配的:
indices=[1, 5, 9, 8, 2]
通过代码加的打印信息如下:
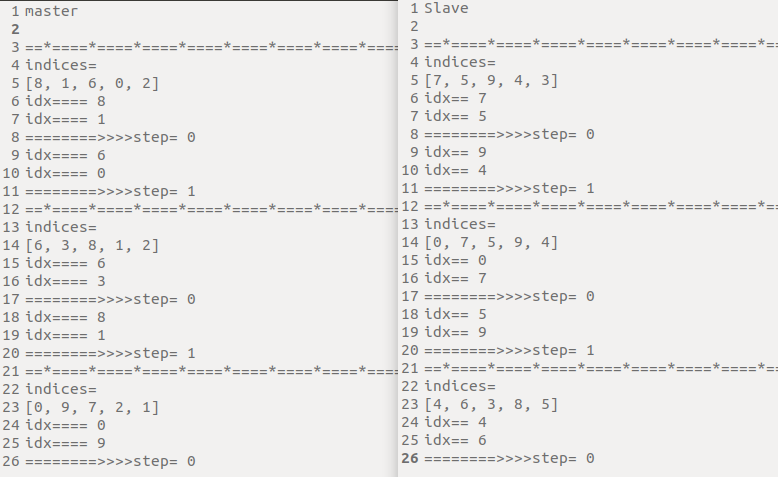
- 通过实验得知,DDP模式下都是根据当前机器上面的数据集来确定数据量大小的,只是在划分数据index的时候根据卡数来平分,
indices = indices[self.rank:self.total_size:self.num_replicas]
并且每轮迭代都会重新打乱总的indices。
附pytorch相关源码:
anaconda3/envs/pytorch1.7.0_general/lib/python3.7/site-packages/torch/utils/data/distributed.py
DistributedSampler的__iter__函数
def __iter__(self) -> Iterator[T_co]:
if self.shuffle:
"""
由于shuffle=True,因此这一步必定是会执行的
根据self.epoch + self.seed来确定每一个进程的都是一样的
"""
# deterministically shuffle based on epoch and seed
g = torch.Generator()
g.manual_seed(self.seed + self.epoch)
indices = torch.randperm(len(self.dataset), generator=g).tolist()
else:
indices = list(range(len(self.dataset)))
if not self.drop_last:
# add extra samples to make it evenly divisible
padding_size = self.total_size - len(indices)
if padding_size <= len(indices):
indices += indices[:padding_size]
else:
indices += (indices * math.ceil(padding_size / len(indices)))[:padding_size]
else:
# remove tail of data to make it evenly divisible.
indices = indices[:self.total_size]
assert len(indices) == self.total_size
# subsample
# 子采样,指定步长为显卡的数量,根据每张卡的不同次序,指定起点
# 由于每张卡上打乱的进程是相同的,因此可以保证每个进程上的数据集是不重复的,并且能取到所有的数据集
indices = indices[self.rank:self.total_size:self.num_replicas]
# self.num_samples在初始化的时候就已经是所有样本除以进程数量以后的
# 这里确保取得的索引是和样本数量长度相等的,由于是assert断言,因此必然是相等的
assert len(indices) == self.num_samples
return iter(indices)
https://blog.csdn.net/yang332233/article/details/129020200?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168630008716800213026543%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=168630008716800213026543&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-2-129020200-null-null.268v1koosearch&utm_term=ddp&spm=1018.2226.3001.4450
https://blog.csdn.net/yang332233/article/details/129053867?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168630012016800215051330%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=168630012016800215051330&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-1-129053867-null-null.268v1koosearch&utm_term=ddp&spm=1018.2226.3001.4450

 浙公网安备 33010602011771号
浙公网安备 33010602011771号