

attention is all you need --->> transform
经典图:
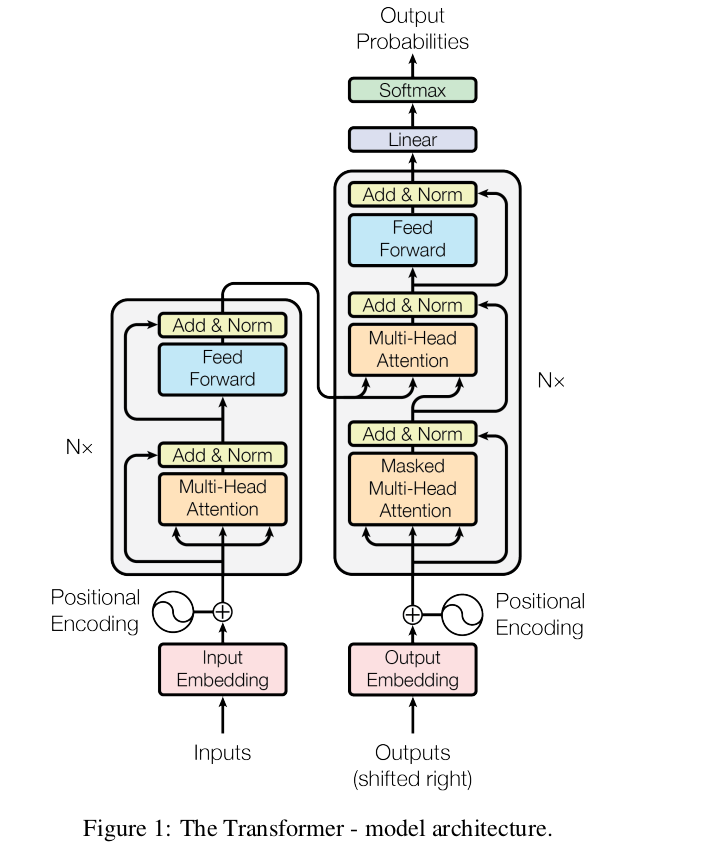
复现的github链接
https://github.com/jadore801120/attention-is-all-you-need-pytorch
注释的代码全集:
https://download.csdn.net/download/yang332233/87602895
目录
- /attention-is-all-you-need-pytorch-master/transformer/Layers.py
- /attention-is-all-you-need-pytorch-master/transformer/Models.py
- /attention-is-all-you-need-pytorch-master/transformer/Modules.py
- /attention-is-all-you-need-pytorch-master/transformer/SubLayers.py
- /attention-is-all-you-need-pytorch-master/train.py
/attention-is-all-you-need-pytorch-master/transformer/Layers.py
''' Define the Layers '''
import torch.nn as nn
import torch
from transformer.SubLayers import MultiHeadAttention, PositionwiseFeedForward
__author__ = "Yu-Hsiang Huang"
class EncoderLayer(nn.Module):
''' Compose with two layers
d_model = 512
d_inner = 2048
n_head = 8
d_k = 64
d_v = 64
'''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(EncoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
#enc_input[b, 18, 512] slf_attn_mask[b, 1, 18]
def forward(self, enc_input, slf_attn_mask=None):
#enc_output [64, 34, 512] enc_slf_attn[64, 8, 34, 34]
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask)
enc_output = self.pos_ffn(enc_output) #enc_output [64, 34, 512]
return enc_output, enc_slf_attn
class DecoderLayer(nn.Module):
''' Compose with three layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
#dec_input[64, 27, 512] enc_output[64, 28, 512] slf_attn_mask[64, 27, 27] dec_enc_attn_mask[64, 1, 28]
def forward(
self, dec_input, enc_output,
slf_attn_mask=None, dec_enc_attn_mask=None):
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask) #dec_output[64, 27, 512] dec_slf_attn[64, 8, 28, 28]
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask) #dec_output[64, 27, 512] dec_enc_attn[64, 8, 27, 28]
dec_output = self.pos_ffn(dec_output) #dec_output[64, 27, 512]
return dec_output, dec_slf_attn, dec_enc_attn
/attention-is-all-you-need-pytorch-master/transformer/Models.py
''' Define the Transformer model '''
import torch
import torch.nn as nn
import numpy as np
from transformer.Layers import EncoderLayer, DecoderLayer
__author__ = "Yu-Hsiang Huang"
def get_pad_mask(seq, pad_idx):
return (seq != pad_idx).unsqueeze(-2)
"""
1 0 0 0 0
1 1 0 0 0
1 1 1 0 0
1 1 1 1 0
"""
def get_subsequent_mask(seq):
''' For masking out the subsequent info. '''
sz_b, len_s = seq.size()#64 26
subsequent_mask = (1 - torch.triu(
torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool()
return subsequent_mask
class PositionalEncoding(nn.Module):
def __init__(self, d_hid, n_position=200):# d_hid=512
super(PositionalEncoding, self).__init__()
# Not a parameter
self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
def _get_sinusoid_encoding_table(self, n_position, d_hid):
''' Sinusoid position encoding table '''
# TODO: make it with torch instead of numpy
def get_position_angle_vec(position):
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
#[200,512]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
# a1 = sinusoid_table[:, 0::2] #[200,256]
# a2 = sinusoid_table[:, 1::2] #[200,256]
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
# cc = torch.FloatTensor(sinusoid_table).unsqueeze(0)
# [200,512] ---->>> [1, 200, 512]
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
def forward(self, x): #x[64, 25, 512]
aa0 = self.pos_table #[1, 200, 512]
aa = self.pos_table[:, :x.size(1)].clone().detach() #[1, 25, 512]
return x + self.pos_table[:, :x.size(1)].clone().detach()
class Encoder(nn.Module):
''' A encoder model with self attention mechanism. '''
def __init__(
self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, dropout=0.1, n_position=200, scale_emb=False):
super().__init__()
#n_src_vocab 9512 d_word_vec 512
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position) #d_word_vec512 n_position=200
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, src_seq, src_mask, return_attns=False): #src_seq[64, 27] src_mask[64, 1 27]
enc_slf_attn_list = []
# -- Forward src_seq[64, 27]是索引[0-9512] enc_output[64, 27, 512]
enc_output = self.src_word_emb(src_seq)
if self.scale_emb: #False
enc_output *= self.d_model ** 0.5
enc_output = self.dropout(self.position_enc(enc_output)) #enc_output[64, 27, 512]
enc_output = self.layer_norm(enc_output)#enc_output[64, 27, 512]
for enc_layer in self.layer_stack:
enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask)
enc_slf_attn_list += [enc_slf_attn] if return_attns else []
#enc_output [b, 27, 512]
if return_attns:
return enc_output, enc_slf_attn_list
return enc_output,
class Decoder(nn.Module):
''' A decoder model with self attention mechanism. '''
def __init__(
self, n_trg_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, n_position=200, dropout=0.1, scale_emb=False):
super().__init__()
self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
#trg_seq[64, 25] trg_mask[64, 25, 25] enc_output[64, 27, 512] src_mask[64, 1, 27]
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
dec_slf_attn_list, dec_enc_attn_list = [], []
# -- Forward dec_output[64, 25, 512]
dec_output = self.trg_word_emb(trg_seq)
if self.scale_emb: #False
dec_output *= self.d_model ** 0.5
dec_output = self.dropout(self.position_enc(dec_output)) #dec_output[64, 25, 512]
dec_output = self.layer_norm(dec_output) #dec_output[64, 25, 512]
for dec_layer in self.layer_stack:
dec_output, dec_slf_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)
dec_slf_attn_list += [dec_slf_attn] if return_attns else []
dec_enc_attn_list += [dec_enc_attn] if return_attns else []
if return_attns:
return dec_output, dec_slf_attn_list, dec_enc_attn_list
return dec_output, #[64, 28, 512]
# transformer = Transformer(
# opt.src_vocab_size, #9521
# opt.trg_vocab_size, #9521
# src_pad_idx=opt.src_pad_idx, #1
# trg_pad_idx=opt.trg_pad_idx, #1
# trg_emb_prj_weight_sharing=opt.proj_share_weight, #True
# emb_src_trg_weight_sharing=opt.embs_share_weight, #True
# d_k=opt.d_k, #64
# d_v=opt.d_v, #64
# d_model=opt.d_model, #512
# d_word_vec=opt.d_word_vec,#512
# d_inner=opt.d_inner_hid, #2048
# n_layers=opt.n_layers, #6
# n_head=opt.n_head, #8
# dropout=opt.dropout, #0.1 #scale_emb_or_prj=prj
# scale_emb_or_prj=opt.scale_emb_or_prj).to(device)
class Transformer(nn.Module):
''' A sequence to sequence model with attention mechanism. '''
def __init__(
self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx,
d_word_vec=512, d_model=512, d_inner=2048,
n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200,
trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True,
scale_emb_or_prj='prj'):
super().__init__()
#src_pad_idx=1 trg_pad_idx =1
self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx
# In section 3.4 of paper "Attention Is All You Need", there is such detail:
# "In our model, we share the same weight matrix between the two
# embedding layers and the pre-softmax linear transformation...
# In the embedding layers, we multiply those weights by \sqrt{d_model}".
#
# Options here:
# 'emb': multiply \sqrt{d_model} to embedding output
# 'prj': multiply (\sqrt{d_model} ^ -1) to linear projection output
# 'none': no multiplication
assert scale_emb_or_prj in ['emb', 'prj', 'none']
scale_emb = (scale_emb_or_prj == 'emb') if trg_emb_prj_weight_sharing else False #scale_emb=False
self.scale_prj = (scale_emb_or_prj == 'prj') if trg_emb_prj_weight_sharing else False #True
self.d_model = d_model #512
self.encoder = Encoder(
n_src_vocab=n_src_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=src_pad_idx, dropout=dropout, scale_emb=scale_emb)
self.decoder = Decoder(
n_trg_vocab=n_trg_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=trg_pad_idx, dropout=dropout, scale_emb=scale_emb)
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
assert d_model == d_word_vec, \
'To facilitate the residual connections, \
the dimensions of all module outputs shall be the same.'
if trg_emb_prj_weight_sharing:
# Share the weight between target word embedding & last dense layer
self.trg_word_prj.weight = self.decoder.trg_word_emb.weight
if emb_src_trg_weight_sharing:
self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight
#src_seq[64, 25] trg_seq[64, 27]
def forward(self, src_seq, trg_seq):
src_mask = get_pad_mask(src_seq, self.src_pad_idx) ##src_seq[64, 25] src_mask[64,1 25]
cc0 = get_pad_mask(trg_seq, self.trg_pad_idx) #[64, 1, 27]
cc = get_subsequent_mask(trg_seq) #[1, 27, 27]
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq) #[64, 27, 27]
# a0 = trg_mask[0][0]
# a1 = trg_mask[0][1]
#
# b0 = trg_mask[1][0]
# b1 = trg_mask[1][1]
enc_output, *_ = self.encoder(src_seq, src_mask) #src_seq[64, 27] src_mask[64, 1, 27]
#dec_output[64, 27, 512] trg_seq[64, 27] trg_mask[64, 27, 27] enc_output[64, 23, 512] src_mask[64, 1, 23]
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)
#seq_logit [64, 27, 9512]
seq_logit = self.trg_word_prj(dec_output)
if self.scale_prj: #True
seq_logit *= self.d_model ** -0.5
#tmp_0 [1600, 9521] #seq_logit [64, 25, 9512]
tmp_0 = seq_logit.view(-1, seq_logit.size(2))
return seq_logit.view(-1, seq_logit.size(2))
/attention-is-all-you-need-pytorch-master/transformer/Modules.py
import torch
import torch.nn as nn
import torch.nn.functional as F
__author__ = "Yu-Hsiang Huang"
"""
q: [64, 8, 26, 64]
k: [64, 8, 26, 64]
v: [64, 8, 26, 64]
"""
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
##encode q,k,v [64, 8, 26, 64] mask[64, 1, 1, 26]
##decode q,k,v [64, 8, 34, 64] mask[64, 1, 34, 34]
def forward(self, q, k, v, mask=None):
k_tmp = k.transpose(2, 3) #[64, 8, 64, 26]
#attn[64, 8, 26, 26] q: [64, 8, 26, 64] k_tmp[64, 8, 64, 26]
#attn[64, 8, 26, 26] 这里的26就是单词个数,是一个关系矩阵,表示自己和其他单词的关系相似度如何
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
#这里很巧妙的encode和decode共用了一个函数, encode的时候mask[64, 1, 1, 26], decode的时候mask[64, 1, 34, 34]
#这里就是decode的时候,attn关系矩阵当前词只有他和他之前的有关,看不到后面,所以mask是一个上三角
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
#attn [64, 8, 26, 26]
attn = self.dropout(F.softmax(attn, dim=-1))
#output [64, 8, 26, 64] attn [64, 8, 26, 26] v: [64, 8, 26, 64]
#这里相当于根据关系矩阵去取每个词的特征,加权和, 关系大的系数大
output = torch.matmul(attn, v) #v: [64, 8, 26, 64]
return output, attn
/attention-is-all-you-need-pytorch-master/transformer/SubLayers.py
''' Define the sublayers in encoder/decoder layer '''
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from transformer.Modules import ScaledDotProductAttention
__author__ = "Yu-Hsiang Huang"
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module
d_model = 512
d_inner = 2048
n_head = 8
d_k = 64
d_v = 64
'''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
#"decode"
#q:[64, 27, 512]
#k:[64, 27, 512]
#v:[64, 27, 512] mask: [64, 27, 27]
#"encode"
#q:[64, 25, 512]
#k:[64, 25, 512]
#v:[64, 25, 512] mask: [64, 1, 25]
def forward(self, q, k, v, mask=None):
# d_k=64, d_v=64, n_head=8
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
# sz_b=64, len_q=26, len_k=26, len_v=26
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv self.w_qs = nn.Linear(512, 8 * 64, bias=False)
# q_tmp [64, 27, 512]
q_tmp = self.w_qs(q)
#q[64, 27, 8, 64]
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k) #n_head=8 d_k=64
#k[64, 27, 8, 64]
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
#v[64, 27, 8, 64]
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
###q[64, 8, 27, 64] k[64, 8, 27, 64] v[64, 8, 27, 64]
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None: #mask[64, 1, 27] --->>> [64, 1, 1, 27] ||||| decode #mask[64, 34, 34] --->>> [64, 1, 34, 34]
mask = mask.unsqueeze(1) # For head axis broadcasting.
#q[64, 8, 27, 64] #attn[64, 8, 27, 27] ###q[64, 8, 27, 64] k[64, 8, 27, 64] v[64, 8, 27, 64]
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
# q [64, 27, 512] q[64, 8, 27, 64] -->> [64, 27, 8, 64] -->> [64, 27, 8* 64]
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q)) # q [64, 27, 512]
q += residual
q = self.layer_norm(q)
return q, attn
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
/attention-is-all-you-need-pytorch-master/train.py
'''
This script handles the training process.
'''
import argparse
import math
import time
import dill as pickle
from tqdm import tqdm
import numpy as np
import random
import os
import torch
import torch.nn.functional as F
import torch.optim as optim
from torchtext.data import Field, Dataset, BucketIterator
from torchtext.datasets import TranslationDataset
import transformer.Constants as Constants
from transformer.Models import Transformer
from transformer.Optim import ScheduledOptim
__author__ = "Yu-Hsiang Huang"
def cal_performance(pred, gold, trg_pad_idx, smoothing=False):
''' Apply label smoothing if needed '''
loss = cal_loss(pred, gold, trg_pad_idx, smoothing=smoothing)
pred = pred.max(1)[1]
gold = gold.contiguous().view(-1)
non_pad_mask = gold.ne(trg_pad_idx)
n_correct = pred.eq(gold).masked_select(non_pad_mask).sum().item()
n_word = non_pad_mask.sum().item()
return loss, n_correct, n_word
def cal_loss(pred, gold, trg_pad_idx, smoothing=False):
''' Calculate cross entropy loss, apply label smoothing if needed. '''
gold = gold.contiguous().view(-1)
if smoothing:
eps = 0.1
n_class = pred.size(1)
one_hot = torch.zeros_like(pred).scatter(1, gold.view(-1, 1), 1)
one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (n_class - 1)
log_prb = F.log_softmax(pred, dim=1)
non_pad_mask = gold.ne(trg_pad_idx)
loss = -(one_hot * log_prb).sum(dim=1)
loss = loss.masked_select(non_pad_mask).sum() # average later
else:
loss = F.cross_entropy(pred, gold, ignore_index=trg_pad_idx, reduction='sum')
return loss
def patch_src(src, pad_idx): #src [28,64] pad_idx 1
src = src.transpose(0, 1)#src [64, 28]
return src
"""
def patch_trg(trg, pad_idx):
aa = np.arange(1,16).reshape(-1,5)
aa_1 = torch.from_numpy(aa)
trg11, gold11 = aa_1[:, :-1], aa_1[:, 1:].contiguous().view(-1)
print("aa_1")
print(aa_1)
print("trg11")
print(trg11)
print("gold11")
print(gold11)
aa_1
tensor([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]])
trg11
tensor([[ 1, 2, 3, 4],
[ 6, 7, 8, 9],
[11, 12, 13, 14]])
gold11
tensor([ 2, 3, 4, 5, 7, 8, 9, 10, 12, 13, 14, 15])
"""
##为什么要删掉最后一位?
def patch_trg(trg, pad_idx):
# aa = np.arange(1,16).reshape(-1,5)
# aa_1 = torch.from_numpy(aa)
# trg11, gold11 = aa_1[:, :-1], aa_1[:, 1:].contiguous().view(-1)
# print("aa_1")
# print(aa_1)
# print("trg11")
# print(trg11)
# print("gold11")
# print(gold11)
trg = trg.transpose(0, 1) #[64,26]
# trg_cp = trg.clone()
trg, gold = trg[:, :-1], trg[:, 1:].contiguous().view(-1) #trg[64,25] gold[1600]
return trg, gold
def train_epoch(model, training_data, optimizer, opt, device, smoothing):
''' Epoch operation in training phase'''
model.train()
total_loss, n_word_total, n_word_correct = 0, 0, 0
desc = ' - (Training) '
for batch in tqdm(training_data, mininterval=2, desc=desc, leave=False):
# prepare data #src_seq [64,25] #trg_seq[64,27] gold[1728]
src_seq = patch_src(batch.src, opt.src_pad_idx).to(device)
#这里为啥patch_trg trg[:, :-1]最后一位不需要了? gold = trg[:, 1:].contiguous().view(-1)
trg_seq, gold = map(lambda x: x.to(device), patch_trg(batch.trg, opt.trg_pad_idx))
# forward
optimizer.zero_grad() ###pred[1600, 9521] [64 * 25, 9521]
pred = model(src_seq, trg_seq) #src_seq [64,24] #trg_seq[64,25]
# backward and update parameters
loss, n_correct, n_word = cal_performance(
pred, gold, opt.trg_pad_idx, smoothing=smoothing)
loss.backward()
optimizer.step_and_update_lr()
# note keeping
n_word_total += n_word
n_word_correct += n_correct
total_loss += loss.item()
loss_per_word = total_loss/n_word_total
accuracy = n_word_correct/n_word_total
return loss_per_word, accuracy
def eval_epoch(model, validation_data, device, opt):
''' Epoch operation in evaluation phase '''
model.eval()
total_loss, n_word_total, n_word_correct = 0, 0, 0
desc = ' - (Validation) '
with torch.no_grad():
for batch in tqdm(validation_data, mininterval=2, desc=desc, leave=False):
# prepare data
src_seq = patch_src(batch.src, opt.src_pad_idx).to(device)
trg_seq, gold = map(lambda x: x.to(device), patch_trg(batch.trg, opt.trg_pad_idx))
# forward
pred = model(src_seq, trg_seq)
loss, n_correct, n_word = cal_performance(
pred, gold, opt.trg_pad_idx, smoothing=False)
# note keeping
n_word_total += n_word
n_word_correct += n_correct
total_loss += loss.item()
loss_per_word = total_loss/n_word_total
accuracy = n_word_correct/n_word_total
return loss_per_word, accuracy
def train(model, training_data, validation_data, optimizer, device, opt):
''' Start training '''
# Use tensorboard to plot curves, e.g. perplexity, accuracy, learning rate
if opt.use_tb:
print("[Info] Use Tensorboard")
from torch.utils.tensorboard import SummaryWriter
tb_writer = SummaryWriter(log_dir=os.path.join(opt.output_dir, 'tensorboard'))
log_train_file = os.path.join(opt.output_dir, 'train.log')
log_valid_file = os.path.join(opt.output_dir, 'valid.log')
print('[Info] Training performance will be written to file: {} and {}'.format(
log_train_file, log_valid_file))
with open(log_train_file, 'w') as log_tf, open(log_valid_file, 'w') as log_vf:
log_tf.write('epoch,loss,ppl,accuracy\n')
log_vf.write('epoch,loss,ppl,accuracy\n')
def print_performances(header, ppl, accu, start_time, lr):
print(' - {header:12} ppl: {ppl: 8.5f}, accuracy: {accu:3.3f} %, lr: {lr:8.5f}, '\
'elapse: {elapse:3.3f} min'.format(
header=f"({header})", ppl=ppl,
accu=100*accu, elapse=(time.time()-start_time)/60, lr=lr))
#valid_accus = []
valid_losses = []
for epoch_i in range(opt.epoch):
print('[ Epoch', epoch_i, ']')
start = time.time()
train_loss, train_accu = train_epoch(
model, training_data, optimizer, opt, device, smoothing=opt.label_smoothing)
train_ppl = math.exp(min(train_loss, 100))
# Current learning rate
lr = optimizer._optimizer.param_groups[0]['lr']
print_performances('Training', train_ppl, train_accu, start, lr)
start = time.time()
valid_loss, valid_accu = eval_epoch(model, validation_data, device, opt)
valid_ppl = math.exp(min(valid_loss, 100))
print_performances('Validation', valid_ppl, valid_accu, start, lr)
valid_losses += [valid_loss]
checkpoint = {'epoch': epoch_i, 'settings': opt, 'model': model.state_dict()}
if opt.save_mode == 'all':
model_name = 'model_accu_{accu:3.3f}.chkpt'.format(accu=100*valid_accu)
torch.save(checkpoint, model_name)
elif opt.save_mode == 'best':
model_name = 'model.chkpt'
if valid_loss <= min(valid_losses):
torch.save(checkpoint, os.path.join(opt.output_dir, model_name))
print(' - [Info] The checkpoint file has been updated.')
with open(log_train_file, 'a') as log_tf, open(log_valid_file, 'a') as log_vf:
log_tf.write('{epoch},{loss: 8.5f},{ppl: 8.5f},{accu:3.3f}\n'.format(
epoch=epoch_i, loss=train_loss,
ppl=train_ppl, accu=100*train_accu))
log_vf.write('{epoch},{loss: 8.5f},{ppl: 8.5f},{accu:3.3f}\n'.format(
epoch=epoch_i, loss=valid_loss,
ppl=valid_ppl, accu=100*valid_accu))
if opt.use_tb:
tb_writer.add_scalars('ppl', {'train': train_ppl, 'val': valid_ppl}, epoch_i)
tb_writer.add_scalars('accuracy', {'train': train_accu*100, 'val': valid_accu*100}, epoch_i)
tb_writer.add_scalar('learning_rate', lr, epoch_i)
def main():
'''
Usage:
python train.py -data_pkl m30k_deen_shr.pkl -log m30k_deen_shr -embs_share_weight -proj_share_weight -label_smoothing -output_dir output -b 256 -warmup 128000
'''
parser = argparse.ArgumentParser()
parser.add_argument('-data_pkl', default=None) # all-in-1 data pickle or bpe field
parser.add_argument('-train_path', default=None) # bpe encoded data
parser.add_argument('-val_path', default=None) # bpe encoded data
parser.add_argument('-epoch', type=int, default=10)
parser.add_argument('-b', '--batch_size', type=int, default=2048)
parser.add_argument('-d_model', type=int, default=512)
parser.add_argument('-d_inner_hid', type=int, default=2048)
parser.add_argument('-d_k', type=int, default=64)
parser.add_argument('-d_v', type=int, default=64)
parser.add_argument('-n_head', type=int, default=8)
parser.add_argument('-n_layers', type=int, default=6)
parser.add_argument('-warmup','--n_warmup_steps', type=int, default=4000)
parser.add_argument('-lr_mul', type=float, default=2.0)
parser.add_argument('-seed', type=int, default=None)
parser.add_argument('-dropout', type=float, default=0.1)
parser.add_argument('-embs_share_weight', action='store_true')
parser.add_argument('-proj_share_weight', action='store_true')
parser.add_argument('-scale_emb_or_prj', type=str, default='prj')
parser.add_argument('-output_dir', type=str, default=None)
parser.add_argument('-use_tb', action='store_true')
parser.add_argument('-save_mode', type=str, choices=['all', 'best'], default='best')
parser.add_argument('-no_cuda', action='store_true')
parser.add_argument('-label_smoothing', action='store_true')
opt = parser.parse_args()
opt.cuda = not opt.no_cuda
opt.d_word_vec = opt.d_model #512
# https://pytorch.org/docs/stable/notes/randomness.html
# For reproducibility
if opt.seed is not None:
torch.manual_seed(opt.seed)
torch.backends.cudnn.benchmark = False
# torch.set_deterministic(True)
np.random.seed(opt.seed)
random.seed(opt.seed)
if not opt.output_dir:
print('No experiment result will be saved.')
raise
if not os.path.exists(opt.output_dir):
os.makedirs(opt.output_dir)
if opt.batch_size < 2048 and opt.n_warmup_steps <= 4000:
print('[Warning] The warmup steps may be not enough.\n'\
'(sz_b, warmup) = (2048, 4000) is the official setting.\n'\
'Using smaller batch w/o longer warmup may cause '\
'the warmup stage ends with only little data trained.')
device = torch.device('cuda' if opt.cuda else 'cpu')
#========= Loading Dataset =========#
if all((opt.train_path, opt.val_path)):
training_data, validation_data = prepare_dataloaders_from_bpe_files(opt, device)
elif opt.data_pkl:
training_data, validation_data = prepare_dataloaders(opt, device)
else:
raise
'''
Namespace(batch_size=64, cuda=True, d_inner_hid=2048, d_k=64, d_model=512, d_v=64, d_word_vec=512,
data_pkl='m30k_deen_shr.pkl', dropout=0.1, embs_share_weight=True, epoch=400,
label_smoothing=True, lr_mul=2.0, max_token_seq_len=100, n_head=8, n_layers=6,
n_warmup_steps=128000, no_cuda=False, output_dir='output', proj_share_weight=True,
save_mode='best', scale_emb_or_prj='prj', seed=None, src_pad_idx=1, src_vocab_size=9521,
train_path=None, trg_pad_idx=1, trg_vocab_size=9521, use_tb=False, val_path=None)
'''
print(opt)
transformer = Transformer(
opt.src_vocab_size, #9521
opt.trg_vocab_size, #9521
src_pad_idx=opt.src_pad_idx, #1
trg_pad_idx=opt.trg_pad_idx, #1
trg_emb_prj_weight_sharing=opt.proj_share_weight, #True
emb_src_trg_weight_sharing=opt.embs_share_weight, #True
d_k=opt.d_k, #64
d_v=opt.d_v, #64
d_model=opt.d_model, #512
d_word_vec=opt.d_word_vec,#512
d_inner=opt.d_inner_hid, #2048
n_layers=opt.n_layers, #6
n_head=opt.n_head, #8
dropout=opt.dropout, #0.1 #scale_emb_or_prj=prj
scale_emb_or_prj=opt.scale_emb_or_prj).to(device)
optimizer = ScheduledOptim(
optim.Adam(transformer.parameters(), betas=(0.9, 0.98), eps=1e-09),
opt.lr_mul, opt.d_model, opt.n_warmup_steps)
train(transformer, training_data, validation_data, optimizer, device, opt)
def prepare_dataloaders_from_bpe_files(opt, device):
batch_size = opt.batch_size
MIN_FREQ = 2
if not opt.embs_share_weight:
raise
data = pickle.load(open(opt.data_pkl, 'rb'))
MAX_LEN = data['settings'].max_len
field = data['vocab']
fields = (field, field)
def filter_examples_with_length(x):
return len(vars(x)['src']) <= MAX_LEN and len(vars(x)['trg']) <= MAX_LEN
train = TranslationDataset(
fields=fields,
path=opt.train_path,
exts=('.src', '.trg'),
filter_pred=filter_examples_with_length)
val = TranslationDataset(
fields=fields,
path=opt.val_path,
exts=('.src', '.trg'),
filter_pred=filter_examples_with_length)
opt.max_token_seq_len = MAX_LEN + 2
opt.src_pad_idx = opt.trg_pad_idx = field.vocab.stoi[Constants.PAD_WORD]
opt.src_vocab_size = opt.trg_vocab_size = len(field.vocab)
train_iterator = BucketIterator(train, batch_size=batch_size, device=device, train=True)
val_iterator = BucketIterator(val, batch_size=batch_size, device=device)
return train_iterator, val_iterator
def prepare_dataloaders(opt, device):
batch_size = opt.batch_size
data = pickle.load(open(opt.data_pkl, 'rb'))
opt.max_token_seq_len = data['settings'].max_len #100
opt.src_pad_idx = data['vocab']['src'].vocab.stoi[Constants.PAD_WORD]
opt.trg_pad_idx = data['vocab']['trg'].vocab.stoi[Constants.PAD_WORD]
opt.src_vocab_size = len(data['vocab']['src'].vocab) #9521
opt.trg_vocab_size = len(data['vocab']['trg'].vocab)#9521
#========= Preparing Model =========#
if opt.embs_share_weight: #True
assert data['vocab']['src'].vocab.stoi == data['vocab']['trg'].vocab.stoi, \
'To sharing word embedding the src/trg word2idx table shall be the same.'
fields = {'src': data['vocab']['src'], 'trg':data['vocab']['trg']}
train = Dataset(examples=data['train'], fields=fields)
val = Dataset(examples=data['valid'], fields=fields)
train_iterator = BucketIterator(train, batch_size=batch_size, device=device, train=True)
val_iterator = BucketIterator(val, batch_size=batch_size, device=device)
return train_iterator, val_iterator
if __name__ == '__main__':
main()
好记性不如烂键盘---点滴、积累、进步!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!