
pytorch torchvision.ops.roi_align
pytorch的torchvision.ops.roi_align这个算子真的是坑我好多天啊!害我连续加班半个月!二阶段目标检测后面用roi_align来提取特征。
接口官方说明:
https://pytorch.org/vision/stable/generated/torchvision.ops.roi_align.html?highlight=roi_align#torchvision.ops.roi_align
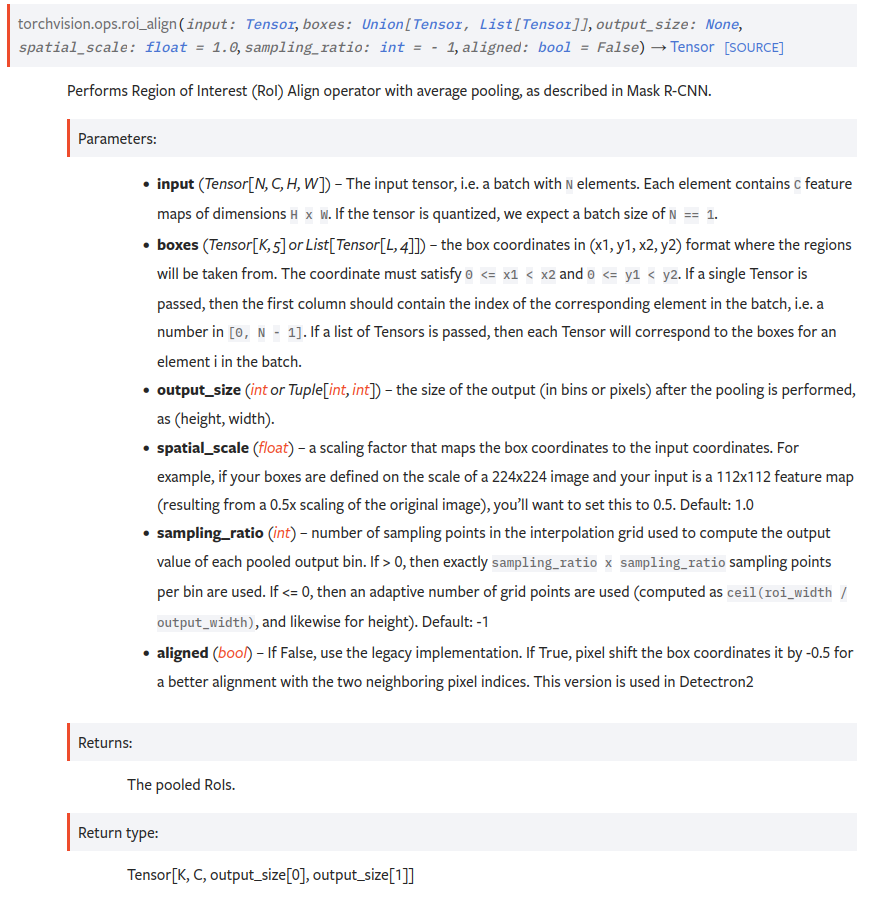
boxes (Tensor[K, 5] or List[Tensor[L, 4]]) – the box coordinates in (x1, y1, x2, y2) format where the regions will be taken from. The coordinate must satisfy 0 <= x1 < x2 and 0 <= y1 < y2. If a single Tensor is passed, then the first column should contain the index of the corresponding element in the batch, i.e. a number in [0, N - 1]. If a list of Tensors is passed, then each Tensor will correspond to the boxes for an element i in the batch.
我做的是caffe转pytorch,caffe网络用到了roi_align这个算子。caffe的网络prototxt是这么的:
layer {
name: "persion_roi_pooling"
type: "ROIAlignment"
bottom: "p3_conv" #[b 128 24 72]
bottom: "persion_detection_out" #[1 1 18 7]
top: "persion_roi_pooling" #[18 128 7 7]
propagate_down: true
propagate_down: false
roi_alignment_param {
pooled_height: 7
pooled_width: 7
}
}
这里解释一下,p3_conv是卷积网络的featuremap,其shape是[b 128 24 72]
persion_detection_out是第一阶段输出检测出18个目标,7是[b,label,score,xmin,ymin,xmax,ymax]. 其实roialign里面只需要5个就可以了[b,xmin,ymin,xmax,ymax],label和score用不到。
然后roialign的输出persion_roi_pooling是[18 128 7 7]。
这里就是把之前的batch丢了,现在是18, 18是目标个数。然后后续还是需要卷积做一些回归任务,比如回归深度,然后接入卷积最后的输出的是[18 1 1 1], 然后和gt那边一堆逻辑操作下来也是的shape是[18, 1]. 所以这个就可以接入smoothl1做回归任务了。
这是caffe的,我们只需要搞懂输入输出就可以了。这里注意一下,输入的bottom: "persion_detection_out" #[1 1 18 7],这里xmin,ymin是0.2,0.1之类的相对值。
然后到pytorch这边,网上的示例确实也是这样的:
https://blog.csdn.net/Bit_Coders/article/details/121203584
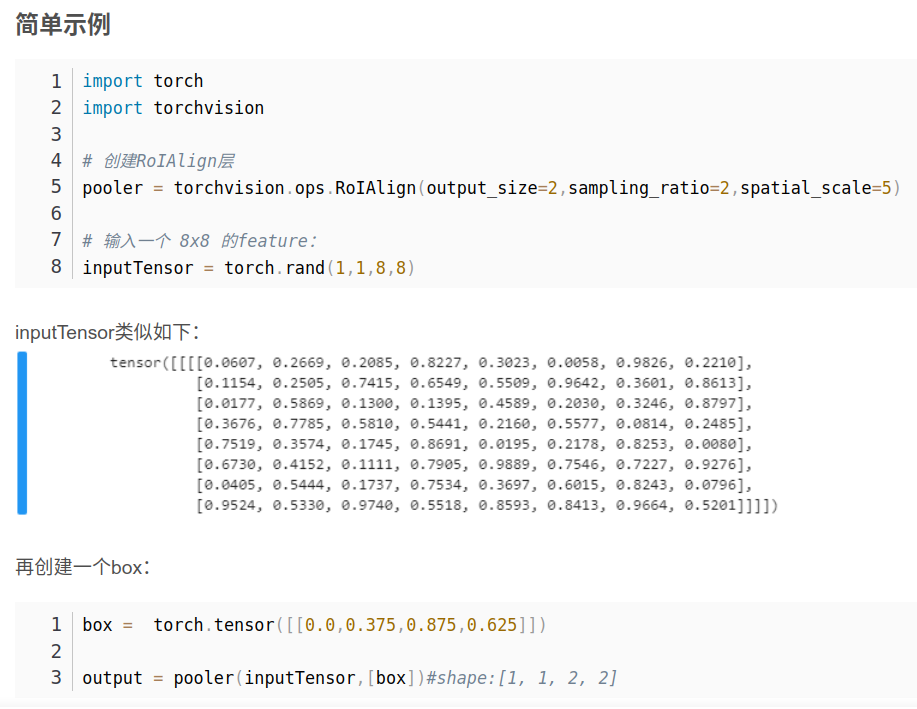
box = torch.tensor([[0.0,0.375,0.875,0.625]])
然后自然而然的我在我的实现中也这样。
最后整个pytorch弄完毕,不收敛啊,loss巨大!不知道哪里出问题,然后一层层排查,固定caffe输出和pytorch验证。
验证下来就是经过roialign这个算子之后两边不一样!
当初觉得是两个框架实现这么复杂逻辑哪里不一样正常,我就直接用pytorch的训练就可以了。但是loss依旧大不收敛!!!
自闭了,这个任务搞了好久,任务延期再延,加班再加!
这里略过很多。。
最后发现pytorch的roialign不是和网上说的一样啊,他输入的bbox框坐标是需要相对于input的坐标的啊!比如inpu的featuremap的width是24,那么就要求框坐标是[0-23]之间的数!
在pytorch源码里面/pytorch-master/caffe2/operators/roi_align_op.cu
#include "caffe2/operators/roi_align_op.h"
#include <stdio.h>
#include <cfloat>
#include "caffe2/core/context_gpu.h"
#include "caffe2/utils/math.h"
namespace caffe2 {
namespace {
template <typename T>
__device__ T bilinear_interpolate(
const T* bottom_data,
const int height,
const int width,
T y,
T x) {
// deal with cases that inverse elements are out of feature map boundary
if (y < -1.0 || y > height || x < -1.0 || x > width) {
// empty
return 0;
}
if (y <= 0) {
y = 0;
}
if (x <= 0) {
x = 0;
}
int y_low = (int)y;
int x_low = (int)x;
int y_high;
int x_high;
if (y_low >= height - 1) {
y_high = y_low = height - 1;
y = (T)y_low;
} else {
y_high = y_low + 1;
}
if (x_low >= width - 1) {
x_high = x_low = width - 1;
x = (T)x_low;
} else {
x_high = x_low + 1;
}
T ly = y - y_low;
T lx = x - x_low;
T hy = 1. - ly, hx = 1. - lx;
// do bilinear interpolation
T v1 = bottom_data[y_low * width + x_low];
T v2 = bottom_data[y_low * width + x_high];
T v3 = bottom_data[y_high * width + x_low];
T v4 = bottom_data[y_high * width + x_high];
T w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
T val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4);
return val;
}
template <typename T>
__global__ void RoIAlignForward(
const int nthreads,
const T* bottom_data,
const T spatial_scale,
const int channels,
const int height,
const int width,
const int pooled_height,
const int pooled_width,
const int sampling_ratio,
const T* bottom_rois,
int roi_cols,
T* top_data,
bool continuous_coordinate) {
CUDA_1D_KERNEL_LOOP(index, nthreads) {
// (n, c, ph, pw) is an element in the pooled output
int pw = index % pooled_width;
int ph = (index / pooled_width) % pooled_height;
int c = (index / pooled_width / pooled_height) % channels;
int n = index / pooled_width / pooled_height / channels;
// RoI could have 4 or 5 columns
const T* offset_bottom_rois = bottom_rois + n * roi_cols;
int roi_batch_ind = 0;
if (roi_cols == 5) {
roi_batch_ind = offset_bottom_rois[0];
offset_bottom_rois++;
}
// Do not using rounding; this implementation detail is critical
T roi_offset = continuous_coordinate ? T(0.5) : 0;
T roi_start_w = offset_bottom_rois[0] * spatial_scale - roi_offset;
T roi_start_h = offset_bottom_rois[1] * spatial_scale - roi_offset;
T roi_end_w = offset_bottom_rois[2] * spatial_scale - roi_offset;
T roi_end_h = offset_bottom_rois[3] * spatial_scale - roi_offset;
T roi_width = roi_end_w - roi_start_w;
T roi_height = roi_end_h - roi_start_h;
if (!continuous_coordinate) { // backward compatibility
// Force malformed ROIs to be 1x1
roi_width = c10::cuda::compat::max(roi_width, (T)1.);
roi_height = c10::cuda::compat::max(roi_height, (T)1.);
}
T bin_size_h = static_cast<T>(roi_height) / static_cast<T>(pooled_height);
T bin_size_w = static_cast<T>(roi_width) / static_cast<T>(pooled_width);
const T* offset_bottom_data =
bottom_data + (roi_batch_ind * channels + c) * height * width;
// We use roi_bin_grid to sample the grid and mimic integral
int roi_bin_grid_h = (sampling_ratio > 0)
? sampling_ratio
: ceil(roi_height / pooled_height); // e.g., = 2
int roi_bin_grid_w =
(sampling_ratio > 0) ? sampling_ratio : ceil(roi_width / pooled_width);
// We do average (integral) pooling inside a bin
const T count = roi_bin_grid_h * roi_bin_grid_w; // e.g. = 4
T output_val = 0.;
for (int iy = 0; iy < roi_bin_grid_h; iy++) // e.g., iy = 0, 1
{
const T y = roi_start_h + ph * bin_size_h +
static_cast<T>(iy + .5f) * bin_size_h /
static_cast<T>(roi_bin_grid_h); // e.g., 0.5, 1.5
for (int ix = 0; ix < roi_bin_grid_w; ix++) {
const T x = roi_start_w + pw * bin_size_w +
static_cast<T>(ix + .5f) * bin_size_w /
static_cast<T>(roi_bin_grid_w);
T val = bilinear_interpolate(
offset_bottom_data, height, width, y, x);
output_val += val;
}
}
output_val /= count;
top_data[index] = output_val;
}
}
} // namespace
template <>
C10_EXPORT bool RoIAlignOp<float, CUDAContext>::RunOnDevice() {
auto& X = Input(0); // Input data to pool
auto& R = Input(1); // RoIs
// RoI pooled data
if (R.numel() == 0) {
// Handle empty rois
Output(0, {0, X.dim32(1), pooled_h_, pooled_w_}, at::dtype<float>());
return true;
}
assert(sampling_ratio_ >= 0);
auto* Y = Output(
0, {R.dim32(0), X.dim32(1), pooled_h_, pooled_w_}, at::dtype<float>());
int output_size = Y->numel();
RoIAlignForward<float>
<<<CAFFE_GET_BLOCKS(output_size),
CAFFE_CUDA_NUM_THREADS,
0,
context_.cuda_stream()>>>(
output_size,
X.data<float>(),
spatial_scale_,
X.dim32(1),
X.dim32(2),
X.dim32(3),
pooled_h_,
pooled_w_,
sampling_ratio_,
R.data<float>(),
R.dim32(1),
Y->mutable_data<float>(),
aligned_);
C10_CUDA_KERNEL_LAUNCH_CHECK();
return true;
}
REGISTER_CUDA_OPERATOR(RoIAlign, RoIAlignOp<float, CUDAContext>);
} // namespace caffe2
using RoIAlignOpFloatCUDA = caffe2::RoIAlignOp<float, caffe2::CUDAContext>;
C10_EXPORT_CAFFE2_OP_TO_C10_CUDA(RoIAlign, RoIAlignOpFloatCUDA);
通过这段代码:
// Do not using rounding; this implementation detail is critical
T roi_offset = continuous_coordinate ? T(0.5) : 0;
T roi_start_w = offset_bottom_rois[0] * spatial_scale - roi_offset;
T roi_start_h = offset_bottom_rois[1] * spatial_scale - roi_offset;
T roi_end_w = offset_bottom_rois[2] * spatial_scale - roi_offset;
T roi_end_h = offset_bottom_rois[3] * spatial_scale - roi_offset;
T roi_width = roi_end_w - roi_start_w;
T roi_height = roi_end_h - roi_start_h;
if (!continuous_coordinate) { // backward compatibility
// Force malformed ROIs to be 1x1
roi_width = c10::cuda::compat::max(roi_width, (T)1.);
roi_height = c10::cuda::compat::max(roi_height, (T)1.);
}
T bin_size_h = static_cast<T>(roi_height) / static_cast<T>(pooled_height);
T bin_size_w = static_cast<T>(roi_width) / static_cast<T>(pooled_width);
特别是通过这里,roi_width = c10::cuda::compat::max(roi_width, (T)1.);, 这里还要求roi_width最小值为1.
所以我明白了,这里是认为输入框坐标是原图上面的,然后通过spatial_scale来映射到input大小。比如一般是下采样8倍做roialign,所以框坐标是原图上面坐标,然后spatial_scale放1/8就可以了。
所以网上那些介绍roialign示例的时候输入框还是0.1之类的小数这些都是错误的!当然也有对的,比如下面链接里面提到:
假设候选框坐标为左上角(0,105),右下角:(230,250),原图和featureMap的spaceRatio为32,那么映射到featureMap上的候选框为:左上角:(0,105/32),即为(0,3.28125);右下角:(230/32,250/32),即为(7.1875,7.8125),那么候选框在特征图上的区域即为下图中红色区域。注意,这里并没有对坐标进行取整,因此是精确的坐标,这就解决了问题二
https://zhuanlan.zhihu.com/p/565986126?utm_id=0
ps:当然我改完pytorch这边,和caffe对比,经过roialign输出还是不一样。但是loss正常了。
(⊙o⊙)…
暂时就不深究了吧!

