shell 命令记录
head -1 vs head -n 1
两者等价
lscpu|grep CPU\(s\)|head -1
等价于:
lscpu|grep CPU\(s\)|head -n 1
都显示如下:
CPU(s): 8
其中,lscpu|grep CPU(s)输入如下:
CPU(s): 8
On-line CPU(s) list: 0-7
NUMA node0 CPU(s): 0-7
awk 用法
https://www.runoob.com/linux/linux-comm-awk.html
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号
# 每行按空格或TAB分割,输出文本中的1、4项
$ awk '{print $1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
# 格式化输出
$ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
(lscpu|grep CPU\(s\)|head -1|awk '{print $2}')
显示8
shell将字符串分割为数组
https://blog.csdn.net/butterfly5211314/article/details/83095084
str="192.168.31.65"
array=(${str//\./ })
for i in "${!array[@]}"; do
echo "$i=>${array[i]}"
done
查看磁盘、文件大小 df -h 和 du命令 以及排序显示du -a|sort -rn
df -h
yhl@B-YANGHAILIN:/data_1/everyday/1012$ df -h
文件系统 容量 已用 可用 已用% 挂载点
udev 7.8G 0 7.8G 0% /dev
tmpfs 1.6G 9.6M 1.6G 1% /run
/dev/sdb2 94G 81G 8.5G 91% /
tmpfs 7.9G 24M 7.8G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 7.9G 0 7.9G 0% /sys/fs/cgroup
/dev/sda 1.8T 1.7T 67G 97% /data_2
/dev/sdc 5.5T 4.7T 531G 90% /data_1
/dev/sdb1 511M 3.7M 508M 1% /boot/efi
tmpfs 1.6G 120K 1.6G 1% /run/user/1000
df的全部参数命令:
-a或--all:包含全部的文件系统;
--block-size=<区块大小>:以指定的区块大小来显示区块数目;
-h或--human-readable:以可读性较高的方式来显示信息;
-H或--si:与-h参数相同,但在计算时是以1000 Bytes为换算单位而非1024 Bytes;
-i或--inodes:显示inode的信息;
-k或--kilobytes:指定区块大小为1024字节;
-l或--local:仅显示本地端的文件系统;
-m或--megabytes:指定区块大小为1048576字节;
--no-sync:在取得磁盘使用信息前,不要执行sync指令,此为预设值;
-P或--portability:使用POSIX的输出格式;
--sync:在取得磁盘使用信息前,先执行sync指令;
-t<文件系统类型>或--type=<文件系统类型>:仅显示指定文件系统类型的磁盘信息;
-T或--print-type:显示文件系统的类型;
-x<文件系统类型>或--exclude-type=<文件系统类型>:不要显示指定文件系统类型的磁盘信息;
--help:显示帮助;
--version:显示版本信息。
查看文件和目录大小的命令:du
du是用来查看文件和目录大小用的,和df略有区别
比如需要查看文件夹0819占用大小
du -sh /data_1/everyday/0819
显示16M /data_1/everyday/0819
或者到/data_1/everyday/0819文件夹下执行:
du -sh
显示:16M .
显示各个文件夹大小:
du -h
du -h
292K ./zd/A303
3.0M ./zd/0209
1.6M ./zd/0205
1.8M ./zd/a301
296K ./zd/A302
14M ./zd
1.1M ./mp
16M .
显示文件夹下每个文件大小
du -ah
8.0K ./install-ubuntu-GTX1080-2018.md
16K ./邮件地址簿.csv
144K ./zd/A303/A303_Q0931M_LJU7724S1AS018206_6531000032.jpg
du的全部命令:
-a或-all 显示目录中个别文件的大小。
-b或-bytes 显示目录或文件大小时,以byte为单位。
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
-k或--kilobytes 以KB(1024bytes)为单位输出。
-m或--megabytes 以MB为单位输出。
-s或--summarize 仅显示总计,只列出最后加总的值。
-h或--human-readable 以K,M,G为单位,提高信息的可读性。
-x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-L<符号链接>或--dereference<符号链接> 显示选项中所指定符号链接的源文件大小。
-S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
-X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
--exclude=<目录或文件> 略过指定的目录或文件。
-D或--dereference-args 显示指定符号链接的源文件大小。
-H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
-l或--count-links 重复计算硬件链接的文件。
比如要将文件夹中的文件按大小排序,可以用以下命令:
du -a|sort -rn
其中-r参数代表反向排序,因为sort默认是从小到大排序的,加-r是从大到小排序
-n代表按照数字排序,只认数字不认单位,本例中的数字就是文件大小,单位是默认的KB,所以这个命令不能用du -ah,这会使排序结果出现2M小于100K的情况。
环境变量
PATH: 可执行程序的查找路径
LD_LIBRARY_PATH: 动态库的查找路径
在Ubuntu中,我们可以使用三个命令来查看当前环境变量的设置,以确定我们有没有把路径加载到环境变量中去。我们可以使用
env
export,或者echo $path
printenv
来查看当前环境变量的值
这是若是没有路径,我们可以通过命令export添加路径
export PATH=$PATH:/要添加的路径
当执行文件提示缺少库的时候,可以执行命令
export
查看当前环境变量库的查找路径,若发现缺少的库不在LD_LIBRARY_PATH目录下面。
可以在终端直接敲命令添加库的搜索路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/data_1/opencv/lib
其他写法:
export LD_LIBRARY_PATH=/home/yhl/software_install/protobuf3.1.0/lib:$LD_LIBRARY_PATH
export PATH="/data_1/Yang/software_install/Anaconda1105/bin:$PATH"
临时设置
export PATH=/home/arm/3.4.1/bin:$PATH
当前用户的全局设置
打开~/.bashrc,添加行:
export PATH=/home/arm/3.4.1/bin:$PATH
使生效:
source ~/.bashrc
所有用户的全局设置
vim /etc/profile
在里面加入:
export PATH=/home/arm/3.4.1/bin:$PATH
使生效:
source /etc/profile
添加环境变量的几个位置
/etc/profile—— 此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行.并从/etc/profile.d目录的配置文件中搜集shell的设置;
/etc/environment—— 在登录时操作系统使用的第二个文件,系统在读取你自己的profile前,设置环境文件的环境变量;
/etc/bashrc—— 为每一个运行bash shell的用户执行此文件.当bash shell被打开时,该文件被读取;
~/.profile—— 每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!默认情况下,它设置一些环境变量,执行用户的.bashrc文件;
~/.bashrc—— 该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该文件被读取;
上面5个添加环境变量的位置的作用时间和作用域有所不同。
Shell中的${ }、#、##、%、%%使用范例
范例
假设定义了一个变量为,【代码如下】:
file=/dir1/dir2/dir3/my.file.txt
可以用${ }分别替换得到不同的值:
${file#/}:删掉第一个 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##/}:删掉最后一个 / 及其左边的字符串:my.file.txt
${file#.}:删掉第一个 . 及其左边的字符串:file.txt
${file##.}:删掉最后一个 . 及其左边的字符串:txt
${file%/}:删掉最后一个 / 及其右边的字符串:/dir1/dir2/dir3
${file%%/}:删掉第一个 / 及其右边的字符串:(空值)
${file%.}:删掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.}:删掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/my
【记忆的方法为】:
# 是 去掉左边(键盘上#在 $ 的左边)
%是去掉右边(键盘上% 在$ 的右边)
单一符号是最小匹配;两个符号是最大匹配
${file:0:5}:提取最左边的 5 个字节:/dir1
${file:5:5}:提取第 5 个字节右边的连续5个字节:/dir2
也可以对变量值里的字符串作替换:
${file/dir/path}:将第一个dir 替换为path:/path1/dir2/dir3/my.file.txt
${file//dir/path}:将全部dir 替换为 path:/path1/path2/path3/my.file.txt
拼接字符串 tmp=$tmp"yhl"
tmp="hello"
tmp=$tmp"yhl"
echo $tmp
helloyhl
重定向 标准文件描述符
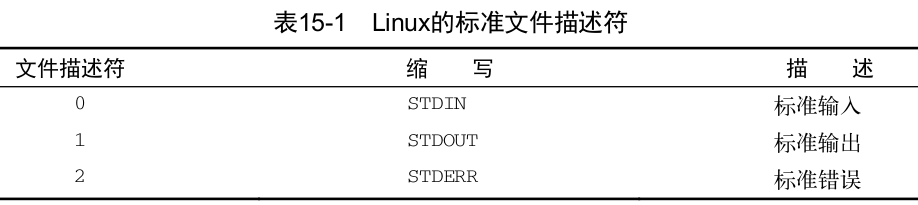
STDIN 0
可以通过 STDIN 重定向符号强制 cat 命令接受来自另一个非 STDIN 文件的输入
cat < testfile
STDOUT 1
STDOUT 文件描述符代表shell的标准输出。在终端界面上,标准输出就是终端显示器。shell的所有输出(包括shell中运行的程序和脚本)会被定向到标准输出中,也就是显示器。
默认情况下,大多数bash命令会将输出导向 STDOUT 文件描述符。用输出重定向来改变。
ls -l > test2
通过输出重定向符号,通常会显示到显示器的所有输出会被shell重定向到指定的重定向文件。
你也可以将数据追加到某个文件。这可以用 >> 符号来完成。
who >> test2
STERR 2
shell通过特殊的 STDERR 文件描述符来处理错误消息。 STDERR 文件描述符代表shell的标准错误输出。shell或shell中运行的程序和脚本出错时生成的错误消息都会发送到这个位置。
默认情况下, STDERR 文件描述符会和 STDOUT 文件描述符指向同样的地方(尽管分配给它们的文件描述符值不同)。也就是说,默认情况下,错误消息也会输出到显示器输出中。
但从上面的例子可以看出, STDERR 并不会随着 STDOUT 的重定向而发生改变。使用脚本时,你常常会想改变这种行为,尤其是当你希望将错误消息保存到日志文件中的时候。
$ ls -al badfile > test3
ls: cannot access badfile: No such file or directory
$ cat test3
生成test3是空文件,shell对于错误消息的处理是跟普通输出分开的。
重定向:
$ ls -al badfile 2> test4
$ cat test4
ls: cannot access badfile: No such file or directory
重定向错误和数据
$ ls -al test test2 test3 badtest 2> test6 1> test7
$ cat test6
ls: cannot access test: No such file or directory
ls: cannot access badtest: No such file or directory
$ cat test7
-rw-rw-r-- 1 rich rich 158 2014-10-16 11:32 test2
-rw-rw-r-- 1 rich rich
0 2014-10-16 11:33 test3
shell利用 1> 符号将 ls 命令的正常输出重定向到了test7文件,而这些输出本该是进入 STDOUT的。
所有本该输出到 STDERR 的错误消息通过 2> 符号被重定向到了test6文件。
另外,如果愿意,也可以将 STDERR 和 STDOUT 的输出重定向到同一个输出文件。为此bash shell
提供了特殊的重定向符号 &> 。
$ ls -al test test2 test3 badtest &> test7
$ cat test7
ls: cannot access test: No such file or directory
ls: cannot access badtest: No such file or directory
-rw-rw-r-- 1 rich rich 158 2014-10-16 11:32 test2
-rw-rw-r-- 1 rich rich
0 2014-10-16 11:33 test3
当使用 &> 符时,命令生成的所有输出都会发送到同一位置,包括数据和错误。你会注意到其中一条错误消息出现的位置和预想中的不一样。badtest文件(列出的最后一个文件)的这条错误
消息出现在输出文件中的第二行。为了避免错误信息散落在输出文件中,相较于标准输出,bashshell自动赋予了错误消息更高的优先级。这样你能够集中浏览错误信息了。
tee 将输出同时发送到显示器和日志文件
tee 命令相当于管道的一个T型接头。它将从 STDIN 过来的数据同时发往两处。一处是STDOUT ,另一处是 tee 命令行所指定的文件名。
由于 tee 会重定向来自 STDIN 的数据,你可以用它配合管道命令来重定向命令输出。
$ date | tee testfile
Sun Oct 19 18:56:21 EDT 2014
$ cat testfile
Sun Oct 19 18:56:21 EDT 2014
sed 插入字符串,插入倒数第二行 , sed -i '$i /opt/run_watch_dog.sh' /etc/rc.local
sed -i '$i /opt/run_watch_dog.sh' /etc/rc.local
把/opt/run_watch_dog.sh插入/etc/rc.local倒数第二行
cut
一个test_cut.txt文本中如下信息:
#define PROJECT_VERSION "1.0.5"
#define REDIS "1.0.1"
现在要获取PROJECT_VERSION,1.0.5
cat test_cut.txt |grep VERSION |cut -d "\"" -f 2
显示如下:
1.0.5
cat test_cut.txt |grep VERSION |cut -d "\"" -f 1
显示如下:
#define PROJECT_VERSION
参数-d代表自定义分隔符
-b :输入每行第n个字符(半角,注意如果有中文将乱码)。
-c :输入每行第n个字符(适用中文)。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符(例如中文)。仅和-b标志一起使用。
两个文本同行拼接空格隔开
paste -d " " img.txt label.txt &> xx.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号