
ssd loss详解
SSD的损失函数与region proposal方法有个明显的区别,在于SSD并不是针对所有的检测器计算loss。SSD会用一种匹配策略给每个检测器分配一个真实标签(背景为0,前景为对应的物体类别)。指定的标签为前景的预测器称为正样本(正样本全部计算loss)。标签为背景的预测器是负样本,并不是所有的负样本都用来计算loss(原因是每张图片中负样本的数量远远多于正样本,如果全部计算loss,则负样本的loss会主导整个loss)。此时按照预设正负样本比例(论文中为1:3),挑选出一定数量的负样本.
对于负样本的挑选,论文中称之为"困难样本挖掘",其实就是对负样本按照loss大小排序,选择前n个loss大的负样本进行梯度更新。
综上,ssd的最终loss就是挑选的正负样本的总loss。
1. 首先先计算truths(比如[2,4]--这张图上有2个目标框)与prior([8732,4])交并比。
就是计算每个truth与8732个先验框prior之间的交并比。overlaps [2,8732]。
2. 最大交并比
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
第一行的max(横向找最大)得到的best_prior_overlap,best_prior_idx意义是每个truths与哪个先验框(best_prior_idx[2,1])最大的交并比(best_prior_overlap[2,1])。
第二行的max(纵向找最大)得到的best_truth_overlap, best_truth_idx意义是每个先验框与哪个truth(best_truth_idx [1,8732])最大交并比(best_truth_overlap [1,8732])。
3. 确保truth与先验框最大交并比的在best_truth_overlap, best_truth_idx中。
best_truth_overlap.index_fill_(0, best_prior_idx, 2)
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
4. 每个先验框对应一个truth和label。把交并比小于0.5的置为背景(0)。
matches = truths[best_truth_idx] # Shape: [8732,4]
conf = labels[best_truth_idx] + 1 # Shape: [8732]
conf[best_truth_overlap < threshold] = 0 # label as background threshold是0.5
5. 每个先验框与其对应的truth做encode操作。
简单而言,就是中心点偏移做差归一化,两两w,h相除
loc = encode(matches, priors, variances) #loc [8732,4]
# idx对应的batchsize,一张张图依次来做的
loc_t[idx] = loc # [8732,4] encoded offsets to learn
conf_t[idx] = conf # [8732] conf里面大部分是0,交并比小于0.5
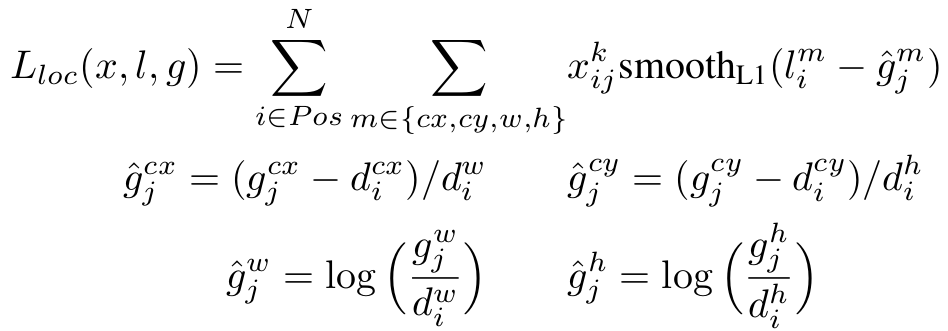
6.位置做smooth L1 loss
取正样本的位置上的值pos_idx做L1 loss
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
#loss_l tensor(14.0165, grad_fn=<SmoothL1LossBackward>)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
7. Compute max conf across batch for hard negative mining

这部分挺复杂的。简单来说就是难例挖掘
根据交叉熵计算出来的loss_c,把正样本位置填0,然后对loss_c从高到低排序,loss高的就是难样本,取3倍正样本的数量。
最后正样本和难例挖掘到的难样本做交叉熵
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
# pos [3,8732]
# neg [3,8732]
# conf_t [3,8732]
# targets_weighted [144]
targets_weighted = conf_t[(pos+neg).gt(0)] #只取True位置上的
#loss_c tensor(58.0656, grad_fn=<NllLossBackward>)
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
~~~~下面是源码分析~~~~~~
~~~~下面是源码分析~~~~~~
~~~~下面是源码分析~~~~~~
def encode(matched, priors, variances):
"""Encode the variances from the priorbox layers into the ground truth boxes
we have matched (based on jaccard overlap) with the prior boxes.
Args:
matched: (tensor) Coords of ground truth for each prior in point-form
Shape: [num_priors, 4].
priors: (tensor) Prior boxes in center-offset form
Shape: [num_priors,4].
variances: (list[float]) Variances of priorboxes
Return:
encoded boxes (tensor), Shape: [num_priors, 4]
"""
# dist b/t match center and prior's center
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2] ## [8732,2] 中心点偏移
# encode variance
g_cxcy /= (variances[0] * priors[:, 2:]) ## [8732,2] 中心点偏移 除以anchor的wh
# match wh / prior wh
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:] # [8732,2] gt的wh除以anchor的wh
g_wh = torch.log(g_wh) / variances[1]
# return target for smooth_l1_loss
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
matched的尺寸是[8732,4]
matcheds其实是groundtruth,格式是xmin,ymin,xmax,ymax。一般而言,一张图片比如有2个目标,为啥这里变8732个了呢?这个是match函数里面得到的。
具体的match函数里面讲解。大体就是每个预设的anchor(8732个)需要绑定一个gt。
以上,就是encode过程。就是把绑定的gt与anchor中心点和wh做偏移
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
"""Match each prior box with the ground truth box of the highest jaccard
overlap, encode the bounding boxes, then return the matched indices
corresponding to both confidence and location preds.
Args:
threshold: (float) The overlap threshold used when mathing boxes.
truths: (tensor) Ground truth boxes, Shape: [num_obj, num_priors].
priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
variances: (tensor) Variances corresponding to each prior coord,
Shape: [num_priors, 4].
labels: (tensor) All the class labels for the image, Shape: [num_obj].
loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
idx: (int) current batch index
Return:
The matched indices corresponding to 1)location and 2)confidence preds.
"""
# jaccard index
overlaps = jaccard(
truths, #[2,4]
point_form(priors) #[8732,4]
)#overlaps [2,8732] 计算每个gt与anchor的交并比
# (Bipartite Matching)
# [1,num_objects] best prior for each ground truth
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
# best_prior_overlap [2,1]
# best_prior_idx [2,1]
#best_prior_idx表示的是anchor的坐标索引,例如tensor([[8444],[5084]])
#意义就是每个gt与anchor的最大交并比和对应的anchor的位置。
#这个是以gt为主。每行取一个最大的。
# [1,num_priors] best ground truth for each prior
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
#best_truth_overlap [1,8732]
#best_truth_idx [1,8732]
#best_truth_idx 表示的是,如果有2个gt,那么这个里面的值取值范围是0-1.
#以anchor为主。每列取最大。
#意义就是每个anchor(8732)和gt最大交并比和每个anchor对应的gt。
best_truth_idx.squeeze_(0) # [1,8732] --> [8732]
best_truth_overlap.squeeze_(0) # [1,8732] --> [8732]
best_prior_idx.squeeze_(1) #[2,1] -->[2]
best_prior_overlap.squeeze_(1)#[2,1] -->[2]
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
#best_prior_idx表示的是gt与哪个anchor交并比最大。
# best_truth_overlap.index_fill_(0, best_prior_idx, 2)在与gt最大的anchor,赋值为2
# TODO refactor: index best_prior_idx with long tensor
# ensure every gt matches with its prior of max overlap
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
#best_truth_idx 对应的位置赋值为gt的索引
matches = truths[best_truth_idx] # Shape: [num_priors,4]
conf = labels[best_truth_idx] + 1 # Shape: [num_priors]
conf[best_truth_overlap < threshold] = 0 # label as background threshold是0.5
loc = encode(matches, priors, variances) #loc [8732,4]
loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
conf_t[idx] = conf # [num_priors] top class label for each prior | conf[8732]
#loc_t = torch.Tensor(num, num_priors, 4) 函数外面申请的,num是batchsize
#conf_t = torch.LongTensor(num, num_priors)

这里用图来表示。就是gt0最大的交并比是0.89,对应的anchor是2.
但是对于anchor2,其最大的交并比是0.9,对应的gt是1.
这种情况优先级最大的是分配gt与最大的anchor。确保gt与anchor交并比最大的留下。
那么,就
best_truth_overlap.index_fill_(0, best_prior_idx, 2) #确保gt与anchor最大的留下,并强制交并比为2
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j #对应anchor强制赋值对应的gt
意义就在于确保gt分配某个anchor,并且使得交并比最大为2。同时best_truth_idx强制赋值对应的gt。
总结下match这个函数功能就是把truth绑定到anchor上,相交的truth与anchor绑定,填充loc_t,conf_t传出。
下面给出整个ssd loss计算部分:
multibox_loss.py
class MultiBoxLoss(nn.Module):
"""SSD Weighted Loss Function
Compute Targets:
1) Produce Confidence Target Indices by matching ground truth boxes
with (default) 'priorboxes' that have jaccard index > threshold parameter
(default threshold: 0.5).
2) Produce localization target by 'encoding' variance into offsets of ground
truth boxes and their matched 'priorboxes'.
3) Hard negative mining to filter the excessive number of negative examples
that comes with using a large number of default bounding boxes.
(default negative:positive ratio 3:1)
Objective Loss:
L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
Where, Lconf is the CrossEntropy Loss and Lloc is the SmoothL1 Loss
weighted by α which is set to 1 by cross val.
Args:
c: class confidences,
l: predicted boxes,
g: ground truth boxes
N: number of matched default boxes
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
"""
def __init__(self, num_classes, overlap_thresh, prior_for_matching,
bkg_label, neg_mining, neg_pos, neg_overlap, encode_target,
use_gpu=True):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh
self.background_label = bkg_label
self.encode_target = encode_target
self.use_prior_for_matching = prior_for_matching
self.do_neg_mining = neg_mining
self.negpos_ratio = neg_pos
self.neg_overlap = neg_overlap
self.variance = cfg['variance']
def forward(self, predictions, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
targets (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
loc_data [3,8732,4]
conf_data [3,8732,21]
priors [8732,4]
"""
loc_data, conf_data, priors = predictions
num = loc_data.size(0)
priors = priors[:loc_data.size(1), :]
num_priors = (priors.size(0))
num_classes = self.num_classes
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4) #[3,8732,4]
conf_t = torch.LongTensor(num, num_priors) #[3,8732]
for idx in range(num):
truths = targets[idx][:, :-1].data
labels = targets[idx][:, -1].data
defaults = priors.data
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
# wrap targets
loc_t = Variable(loc_t, requires_grad=False) #[3,8732,4]
conf_t = Variable(conf_t, requires_grad=False) #[3,8732]
pos = conf_t > 0 #pos [3,8732] False,True
num_pos = pos.sum(dim=1, keepdim=True) #num_pos shape[3,1] | [23],[4],[9]
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4] #pos.unsqueeze(pos.dim()) [3,8732,1]
#pos_idx [3,8732,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
#loc_data[3, 8732, 4] aa[240]
aa = loc_data[pos_idx]
#[3,8732,4] bb[240]
bb = loc_t[pos_idx]
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
#loss_l tensor(14.0165, grad_fn=<SmoothL1LossBackward>)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
# Compute max conf across batch for hard negative mining
#conf_data [3,8732,21] batch_conf[3*8732,21] [26196,21]
batch_conf = conf_data.view(-1, self.num_classes)
b1 = log_sum_exp(batch_conf) #[26196,1]
b2 = batch_conf.gather(1, conf_t.view(-1, 1)) #[26196,1]
#loss_c[26196,1] #https://zhuanlan.zhihu.com/p/153535799
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# Hard Negative Mining
#loss_c[pos] = 0 # filter out pos boxes for now
#loss_c = loss_c.view(num, -1)
#loss_c [3,8732]
loss_c = loss_c.view(num, -1)
loss_c[pos] = 0 #把正样本的loss置为0
#loss_idx [3,8732]
tmp1, loss_idx = loss_c.sort(1, descending=True) ## _, loss_idx = loss_c.sort(1, descending=True)
#idx_rank [3,8732]
tmp2, idx_rank = loss_idx.sort(1) ## _, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)#num_pos shape[3,1] | [23],[4],[9]
aaaaa = self.negpos_ratio * num_pos
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)#num_pos shape[3,1] | [69],[12],[27]
#neg [3,8732] True,False 给出的是conf_data对应坐标的True与False 排序的从大到小
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)#pos[3,8732] conf_data[3,8732,21]
neg_idx = neg.unsqueeze(2).expand_as(conf_data)##neg [3,8732] conf_data[3,8732,21]
## pos_idx+neg_idx 这两者的形状都是相同的[3,8732,21] 值都是True或者False 加运算相当执行了或运算,只要有一个True就是True
#conf_p [144,21] --> 这里面的144就是上面两个pos_idx和neg_idx里面True数量之和 69+12+27+23+4+9=144
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
# pos [3,8732]
# neg [3,8732]
# conf_t [3,8732]
# targets_weighted [144]
targets_weighted = conf_t[(pos+neg).gt(0)]
#loss_c tensor(58.0656, grad_fn=<NllLossBackward>)
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = num_pos.data.sum() ##N=36 就是num_pos之和[23] + [4] + [9]
loss_l /= N
loss_c /= N
return loss_l, loss_c
关于LogSumExp:https://zhuanlan.zhihu.com/p/153535799

然后就是难例挖掘部分:
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
两次sort,把我看懵逼了。
然后查资料,写了个demo来理解:
import torch
x = torch.randn((4,5))
_,indices = x.sort(dim=1,descending=True)
_,idx = indices.sort(dim=1)
print(x)
print()
print(idx)
aa = idx < 2
print(aa)
x_selete = x[aa]
print(x_selete)
# x
tensor([[ 0.2667, 0.8747, 0.2998, -0.2021, 2.3771],
[ 1.0459, -0.0745, -1.2888, -0.0867, -0.4641],
[ 0.0052, -2.1177, -0.7523, 1.9897, -0.9098],
[ 0.0294, -1.0081, -0.8528, -0.4864, -0.7573]])
#idx
tensor([[3, 1, 2, 4, 0],
[0, 1, 4, 2, 3],
[1, 4, 2, 0, 3],
[0, 4, 3, 1, 2]])
这里可以分析其结果。就是每一行,对应的是x降续的下标。比如拿第一行举例:
0.2667, 0.8747, 0.2998, -0.2021, 2.3771
3, 1, 2, 4, 0
就是0代表最大,1,2,后面其次。
这种做法就是相当于保持坐标位置不变,每个值都对应排序的结果。
#aa
tensor([[False, True, False, False, True],
[ True, True, False, False, False],
[ True, False, False, True, False],
[ True, False, False, True, False]])
aa = idx < 2
这个意思就是取出最大值的前2位。这样得到的坐标也和x一样的格式,每行值前2位是true,其余false
#x_selete x_selete = x[aa]对应是true的位置的元素取出来
tensor([ 0.8747, 2.3771, 1.0459, -0.0745, 0.0052, 1.9897, 0.0294, -0.4864])
所以,ssd的loss里面的难例挖掘就是指定了正负样本1:3,然后对负样本loss从高到低排序取出3倍数量就可以。
这里2次sort就是为了取3倍loss大的负样本。
就是loss的位置不变,然后经过两次sort,把loss每个值打上顺序,最大的loss打的顺序标签为0,最小的loss打的顺序标签为8732.所以取前几个就是直接取。
neg = idx_rank < num_neg.expand_as(idx_rank)
num_neg就是3倍负样本个数。这样得到的neg就是对应所需要取的负样本位置。
具体的就是看我代码注释的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2019-06-14 python 语法
2019-06-14 ICDAR2015 的 Ground Truth 标注在图像数据上