
ssd 网络详解
def build_ssd(phase, size=300, num_classes=21):
if phase != "test" and phase != "train":
print("ERROR: Phase: " + phase + " not recognized")
return
if size != 300:
print("ERROR: You specified size " + repr(size) + ". However, " +
"currently only SSD300 (size=300) is supported!")
return
base_, extras_, head_ = multibox(vgg(base[str(size)], 3),
add_extras(extras[str(size)], 1024),
mbox[str(size)], num_classes)
return SSD(phase, size, base_, extras_, head_, num_classes)
网络大体分为三部分base_, extras_, head_
ssd主体网络:
class SSD(nn.Module):
"""Single Shot Multibox Architecture
The network is composed of a base VGG network followed by the
added multibox conv layers. Each multibox layer branches into
1) conv2d for class conf scores
2) conv2d for localization predictions
3) associated priorbox layer to produce default bounding
boxes specific to the layer's feature map size.
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
Args:
phase: (string) Can be "test" or "train"
size: input image size
base: VGG16 layers for input, size of either 300 or 500
extras: extra layers that feed to multibox loc and conf layers
head: "multibox head" consists of loc and conf conv layers
"""
def __init__(self, phase, size, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = (coco, voc)[num_classes == 21]
self.priorbox = PriorBox(self.cfg)
self.priors = Variable(self.priorbox.forward(), volatile=True)
self.size = size
# SSD network
self.vgg = nn.ModuleList(base)
# Layer learns to scale the l2 normalized features from conv4_3
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras)
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 0, 200, 0.01, 0.45)
def forward(self, x):
"""Applies network layers and ops on input image(s) x.
Args:
x: input image or batch of images. Shape: [batch,3,300,300].
Return:
Depending on phase:
test:
Variable(tensor) of output class label predictions,
confidence score, and corresponding location predictions for
each object detected. Shape: [batch,topk,7]
train:
list of concat outputs from:
1: confidence layers, Shape: [batch*num_priors,num_classes]
2: localization layers, Shape: [batch,num_priors*4]
3: priorbox layers, Shape: [2,num_priors*4]
"""
sources = list()
loc = list()
conf = list()
# apply vgg up to conv4_3 relu
for k in range(23):
x = self.vgg[k](x)
s = self.L2Norm(x)
sources.append(s)
# apply vgg up to fc7
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
# apply extra layers and cache source layer outputs
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
# apply multibox head to source layers
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
# loc_tmp = [o.view(o.size(0), -1) for o in loc]
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output
def load_weights(self, base_file):
other, ext = os.path.splitext(base_file)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
self.load_state_dict(torch.load(base_file,
map_location=lambda storage, loc: storage))
print('Finished!')
else:
print('Sorry only .pth and .pkl files supported.')
通过pycharm打断点拷贝的ssd网络结构如下,只是网络所用到的一些模块,具体怎么用需要看forward部分:
SSD(
(vgg): ModuleList(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(31): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(32): ReLU(inplace=True)
(33): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(34): ReLU(inplace=True)
)
(L2Norm): L2Norm()
(extras): ModuleList(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(4): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(6): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
)
(loc): ModuleList(
(0): Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(1024, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(conf): ModuleList(
(0): Conv2d(512, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(1024, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
通过summary打印的网络部分:
(pytorch torchsummary 显示每层大小 https://www.cnblogs.com/yanghailin/p/14869947.html)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 300, 300] 1,792
ReLU-2 [-1, 64, 300, 300] 0
Conv2d-3 [-1, 64, 300, 300] 36,928
ReLU-4 [-1, 64, 300, 300] 0
MaxPool2d-5 [-1, 64, 150, 150] 0
Conv2d-6 [-1, 128, 150, 150] 73,856
ReLU-7 [-1, 128, 150, 150] 0
Conv2d-8 [-1, 128, 150, 150] 147,584
ReLU-9 [-1, 128, 150, 150] 0
MaxPool2d-10 [-1, 128, 75, 75] 0
Conv2d-11 [-1, 256, 75, 75] 295,168
ReLU-12 [-1, 256, 75, 75] 0
Conv2d-13 [-1, 256, 75, 75] 590,080
ReLU-14 [-1, 256, 75, 75] 0
Conv2d-15 [-1, 256, 75, 75] 590,080
ReLU-16 [-1, 256, 75, 75] 0
MaxPool2d-17 [-1, 256, 38, 38] 0
Conv2d-18 [-1, 512, 38, 38] 1,180,160
ReLU-19 [-1, 512, 38, 38] 0
Conv2d-20 [-1, 512, 38, 38] 2,359,808
ReLU-21 [-1, 512, 38, 38] 0
Conv2d-22 [-1, 512, 38, 38] 2,359,808
ReLU-23 [-1, 512, 38, 38] 0
L2Norm-24 [-1, 512, 38, 38] 512
MaxPool2d-25 [-1, 512, 19, 19] 0
Conv2d-26 [-1, 512, 19, 19] 2,359,808
ReLU-27 [-1, 512, 19, 19] 0
Conv2d-28 [-1, 512, 19, 19] 2,359,808
ReLU-29 [-1, 512, 19, 19] 0
Conv2d-30 [-1, 512, 19, 19] 2,359,808
ReLU-31 [-1, 512, 19, 19] 0
MaxPool2d-32 [-1, 512, 19, 19] 0
Conv2d-33 [-1, 1024, 19, 19] 4,719,616
ReLU-34 [-1, 1024, 19, 19] 0
Conv2d-35 [-1, 1024, 19, 19] 1,049,600
ReLU-36 [-1, 1024, 19, 19] 0
Conv2d-37 [-1, 256, 19, 19] 262,400
Conv2d-38 [-1, 512, 10, 10] 1,180,160
Conv2d-39 [-1, 128, 10, 10] 65,664
Conv2d-40 [-1, 256, 5, 5] 295,168
Conv2d-41 [-1, 128, 5, 5] 32,896
Conv2d-42 [-1, 256, 3, 3] 295,168
Conv2d-43 [-1, 128, 3, 3] 32,896
Conv2d-44 [-1, 256, 1, 1] 295,168
Conv2d-45 [-1, 16, 38, 38] 73,744
Conv2d-46 [-1, 84, 38, 38] 387,156
Conv2d-47 [-1, 24, 19, 19] 221,208
Conv2d-48 [-1, 126, 19, 19] 1,161,342
Conv2d-49 [-1, 24, 10, 10] 110,616
Conv2d-50 [-1, 126, 10, 10] 580,734
Conv2d-51 [-1, 24, 5, 5] 55,320
Conv2d-52 [-1, 126, 5, 5] 290,430
Conv2d-53 [-1, 16, 3, 3] 36,880
Conv2d-54 [-1, 84, 3, 3] 193,620
Conv2d-55 [-1, 16, 1, 1] 36,880
Conv2d-56 [-1, 84, 1, 1] 193,620
================================================================
Total params: 26,285,486
Trainable params: 26,285,486
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 1.03
Forward/backward pass size (MB): 413.90
Params size (MB): 100.27
Estimated Total Size (MB): 515.20
----------------------------------------------------------------
具体计算规则都在ssd里面的forward函数里面,
def forward(self, x):
sources = list()
loc = list()
conf = list()
# apply vgg up to conv4_3 relu
for k in range(23):
x = self.vgg[k](x)
s = self.L2Norm(x)
sources.append(s) ##s0
# apply vgg up to fc7
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)##s1
# apply extra layers and cache source layer outputs
for k, v in enumerate(self.extras):## k=0,1,2,3,4,5,6,7 奇数的时候保存一次sources,总共保存4个
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
# apply multibox head to source layers
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
# loc_tmp = [o.view(o.size(0), -1) for o in loc]
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output
保存了6个不同层次的feature map在sources中,然后用loc和conf去卷积得到结果,然后就是各种reshape操作。最后打包输出:
output = (
loc.view(loc.size(0), -1, 4), #[batchsize,8732,4]
conf.view(conf.size(0), -1, self.num_classes),#[batchsize,8732,21]
self.priors #[8732,4]
)
注意这里的数字8732在之前分析的ssd 的anchor生成详解中也计算出8732这个数值。就是6层的feature map每个点给配4个或者6个矩形框,总共是8732个矩形框。
然后现在也通过不同层的feature map回归出8732个矩形框,并且每个矩形框给配上分数。
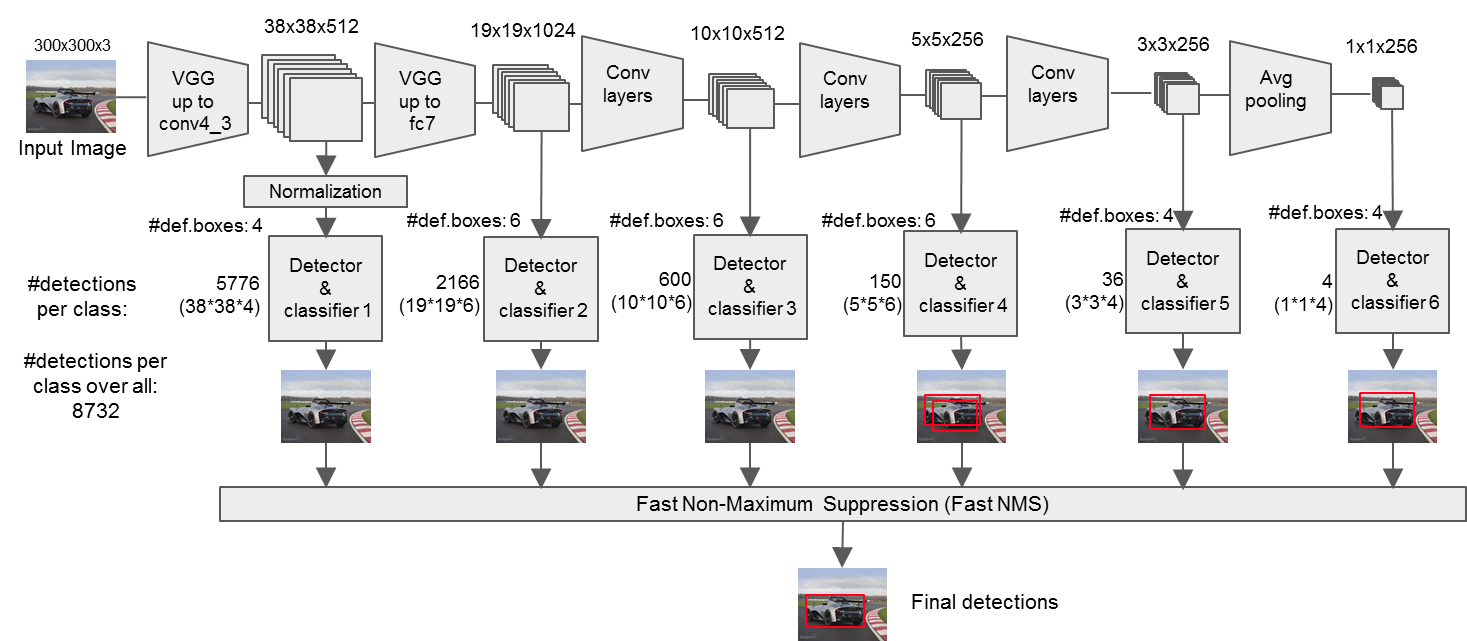
下面给出我把整个网络流程的手写图以及数据流:




可以看到,这里只是通过网络不同层feature map直接回归出位置和分数,并没有涉及到anchor。
其实,后面需要讲到的loss才会用到anchor和这里回归的位置和分数,通过损失函数约束,使得特征往标签gt的方向去学习。
好记性不如烂键盘---点滴、积累、进步!

