
目标检测---refinedet
Single-Shot Refinement Neural Network for Object Detection
论文链接:https://arxiv.org/abs/1711.06897
代码链接:https://github.com/sfzhang15/RefineDet
https://github.com/luuuyi/RefineDet.PyTorch
对于目标检测网络,two-stages 精度高,one-stage速度快。
two-stages 第一步产生一系列的候选框,候选框产生方法有Selective Search、EdgeBoxes、DeepMask、RPN),然后第二步再进行分类回归。代表方法有Faster RCNN R-FCN FPN Mask R-CNN 。
one-stage 在feature map的每个cell中产生候选框的同时进行分类回归,一步完成。代表方法有SSD Yolo Yolov2 DSSD等。
one-stage速度快,但是由于正负样本不平衡,同时一步回归,所以精度比two-stages的方法差。
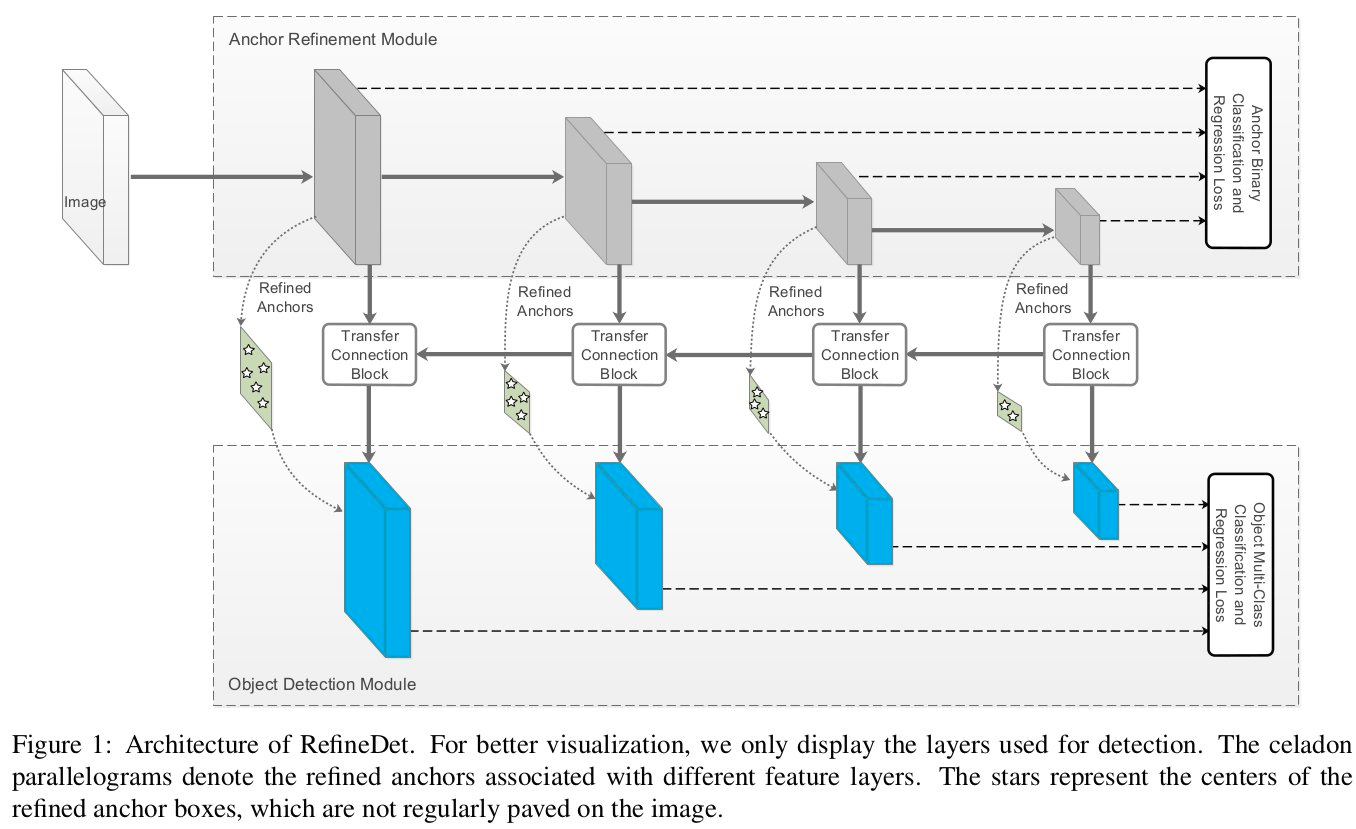
Refinedet 综合两者的特点,该网络有两个模块构成,直接上图:
第一个是anchor refinement module
1)过滤掉部分负样本候选框,减小分类器的搜索范围。
2)粗调整候选框的位置和大小
第二个是object detection module
1)对候选框进行分类和精调
两个模块中间有一个连接模块transfer connection block
- 进行特征层的融合,将高语义层上采样与上一层进行融合,提高底特征层的语义信息。上采样通过反卷积进行。
该网络主要有三个特点
1)利用TCB模块进行类似FPN 的特征融合,提高低层语义信息,有利于小物体检测
2)两步级联回归,提升框的质量,在ARM模块中利用SSD二分类网络做PRN的工作,进行粗回归调整,在ODM模块中进行位置精调。
3)负样本过滤机制,文中在进行1:3的难例挖掘前先进行了负样本的过滤,当候选框的背景置信度高(大于0.99时),直接舍去,不丢入分类器,这样能缓解样本不平衡问题,同时缩短检测速度。
efineDet的主要思想:一方面引入two stage类型的object detection算法中对box的由粗到细的回归思想(由粗到细回归其实就是先通过RPN网络得到粗粒度的box信息,然后再通过常规的回归支路进行进一步回归从而得到更加精确的框信息,这也是two stage类型的object detection算法效果优于one stage类型的一个重要原因)。另一方面引入类似FPN网络的特征融合操作用于检测网络,可以有效提高对小目标的检测效果,检测网络的框架还是SSD。
Figure1是RefineDet网络的结构图(直观的特点就是two-step cascaded regression),主要包含三个部分:anchor refinement module (ARM) 、object detection module (ODM)、transfer connection block (TCB)。
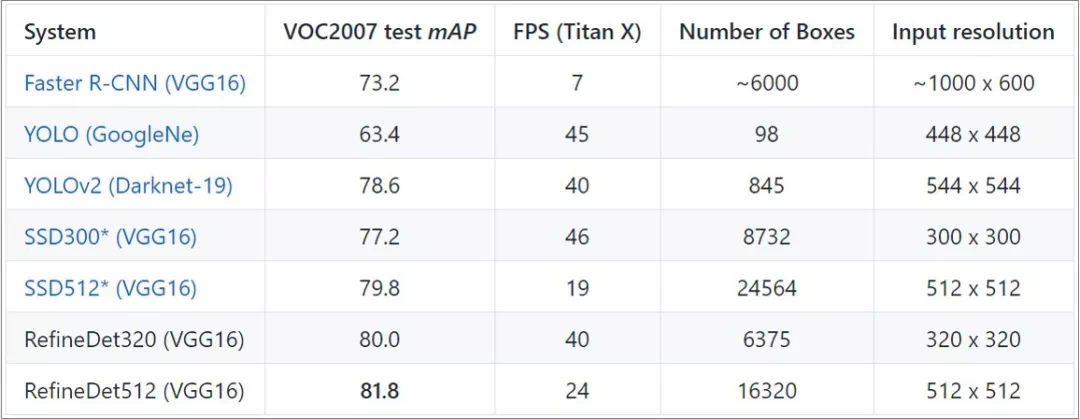
表1总结了著名检测算法的速度以及精度。RefineDet在保持一步法速度的同时,能够达到甚至超过二步法的精度。跟SSD相比,RefineDet算法框架多了下面一部分卷积层和反卷积层,速度还比SSD快一些原因是:
使用较少的anchor,如512尺度下,RefineDet共有1.6W个框,而SSD有2.5W个框。RefineDet使用较少anchor也能达到高精度的原因是二阶段回归,虽然总共预设了4个尺度(32,64,128,256)和3个比例(0.5,1,2),但是经过第一阶段的回归后,预设的anchor被极大丰富,因此用于第二阶段回归的anchor,具备丰富的尺度和比例。
使用较少的检测层:RefineDet在基础网络上新加了很少的卷积层,并只选了4个卷积层作为检测层。
anchor refinement module (ARM)
arm部分类似Faster RCNN算法中的RPN网络,主要用来得到bbox(类似Faster RCNN中的ROI或proposal)和去除一些负样本(这是因为负样本数量远大于正样本)。因此基于4层特征最后得到的还是两条支路,一个bbox的坐标回归支路,另一个是bbox的二分类支路。我们知道在Faster RCNN算法中RPN网络存在的意义就是生成proposal(或者叫ROI),这些proposal会给后续检测网络提供较好的初始信息,这也是one stage的object detection算法和two stage的object detection算法的重要区别,这里的anchor refinement module基本上扮演了RPN网络的角色,如果一定要说不同点的话,那应该就是这里的输入利用了多层特征,而RPN网络的输入是单层特征。
transfer connection block (TCB)
TCB部分是做特征的转换操作,也就是将ARM部分的输出feature map转换成ODM部分的输入,这部分其实和FPN算法的特征融合很像,FPN也是这样的upsample后融合的思想。
object detection module (ODM)
ODM部分和就基本上是SSD了,也是融合不同层的特征,然后做multi class classification和regression。主要的不同点一方面在于这部分的输入anchors是ARM部分得到的refined anchors,类似RPN网络输出的proposal。另一方面和FPN算法类似,这里的浅层feature map(size较大的蓝色矩形块)融合了高层feature map的信息,然后预测bbox是基于每层feature map(每个蓝色矩形块)进行,最后将各层结果再整合到一起。而在SSD中浅层的feature map是直接拿来用的(并没有和高层的feature map融合),也就是对bbox的预测是在每一层上进行的,预测得到结果后再将各层结果整合在一起,这是非常重要的区别。这样做的好处就是对小目标物体的检测效果更好,这在FPN和RON等算法中已经证明过了。
具体网络结构是怎么构建的呢?以特征提取网络为ResNet101,输入图像大小为320为例,在Anchor Refinement Module部分的4个灰色矩形块(feature map)的size分别是4040,2020,1010,55,其中前三个是ResNet101网络本身的输出层,最后55输出是另外添加的一个residual block。有了特征提取的主网络后,就要开始做融合层操作了,首先是55的feature map经过一个transfer connection block得到对应大小的蓝色矩形块(P6),transfer connection block后面会介绍 ,对于生成P6的这条支路而言只是3个卷积层而已。接着基于10*10的灰色矩形块(feature map)经过transfer connection block得到对应大小的蓝色矩形块(P5),此处的transfer connection block相比P6增加了反卷积支路,反卷积支路的输入来自于生成P6的中间层输出。P4和P3的生成与P5同理。
因此整体来看该网络和tow stage的结构很像(都可以概括为two-step cascaded regression),一个子模块做RPN的事,另一个子模块做SSD的事。因此SSD是直接在default box的基础上进行回归的,而在RefineDet中是先通过ARM部分生成refined anchor boxes(类似RPN网络输出的propsoal),然后在refined anchor boxes基础上进行回归,所以能有更高的准确率,而且得益于特征融合,该算法对于小目标物体的检测更有效。
以下是我自己的====================================================
关于refinedet,我做了多个跨架构的移植。libtorch,tensorrt
https://github.com/wuzuowuyou/tensorRT_RefineDet
https://github.com/wuzuowuyou/libtorch_RefineDet_2020
基础是caffe框架训练的模型,然后提取caffe权重用pytorch实现,这样的话就在caffe下训练就可以了,用libtorch或者tensorrt部署。精度一致!
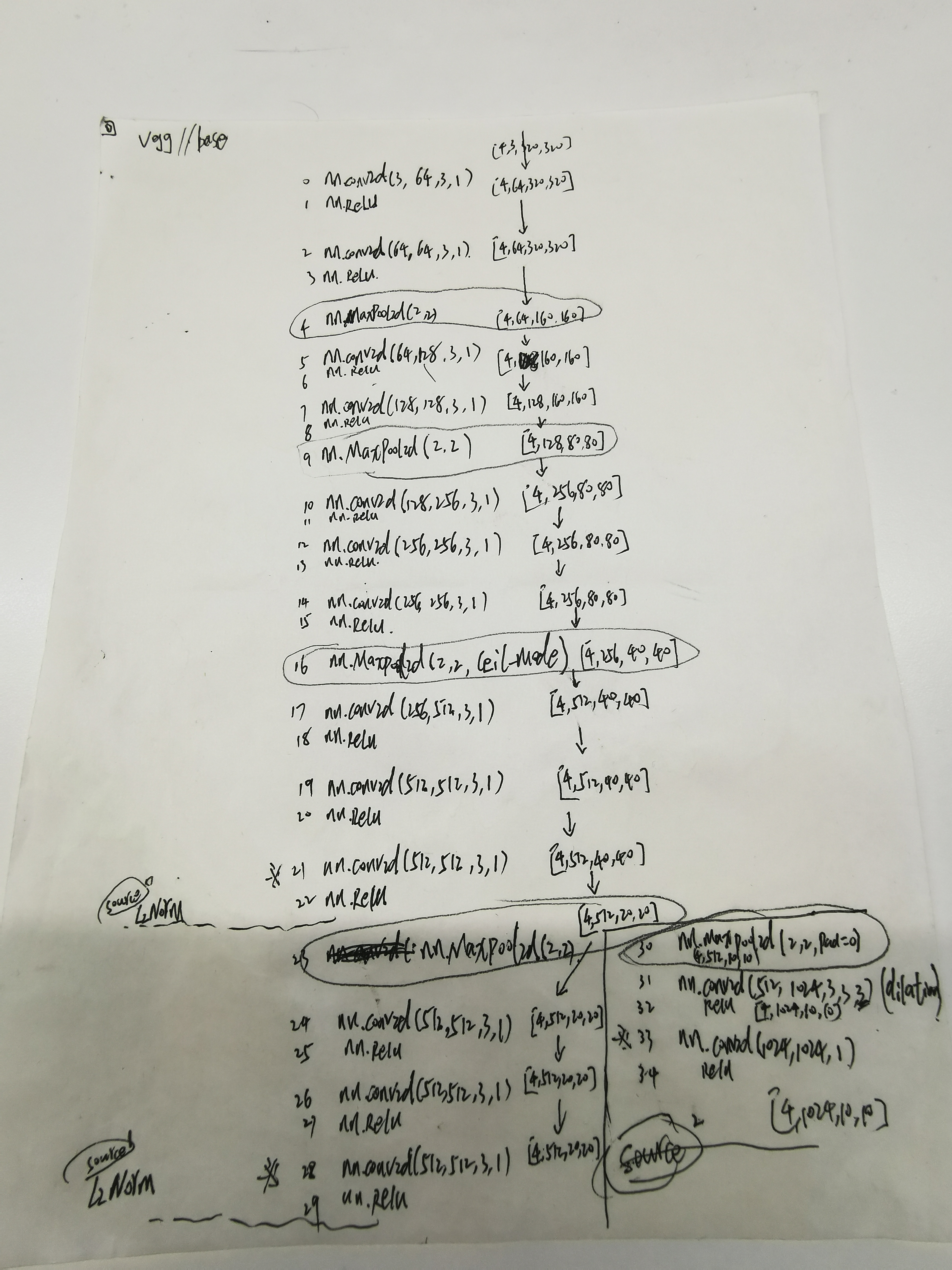

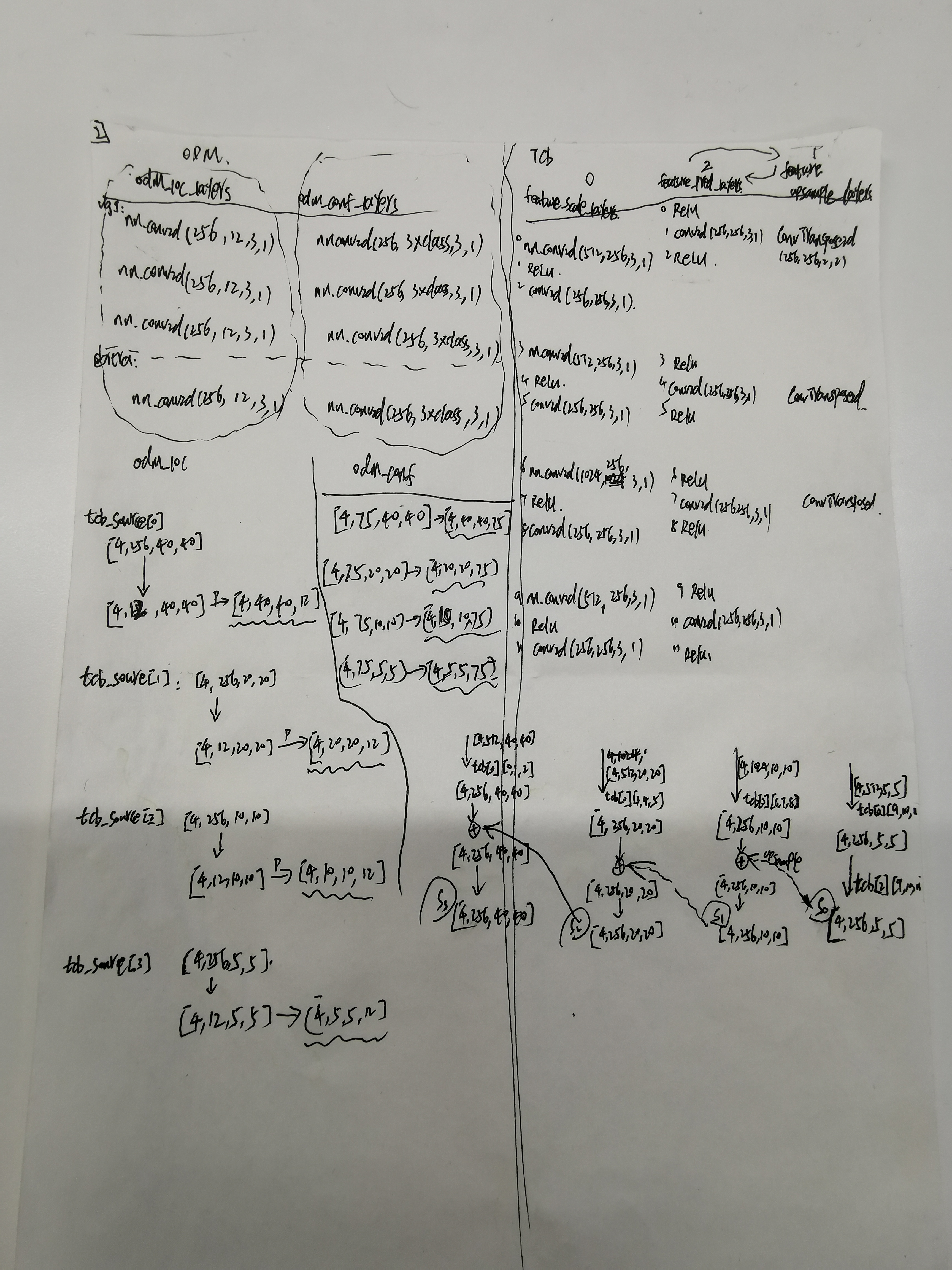

这是我当初做移植的时候把网络的数据流都写在草纸上,这里上传留个备份。同时,在网络结构图上写出数据流:
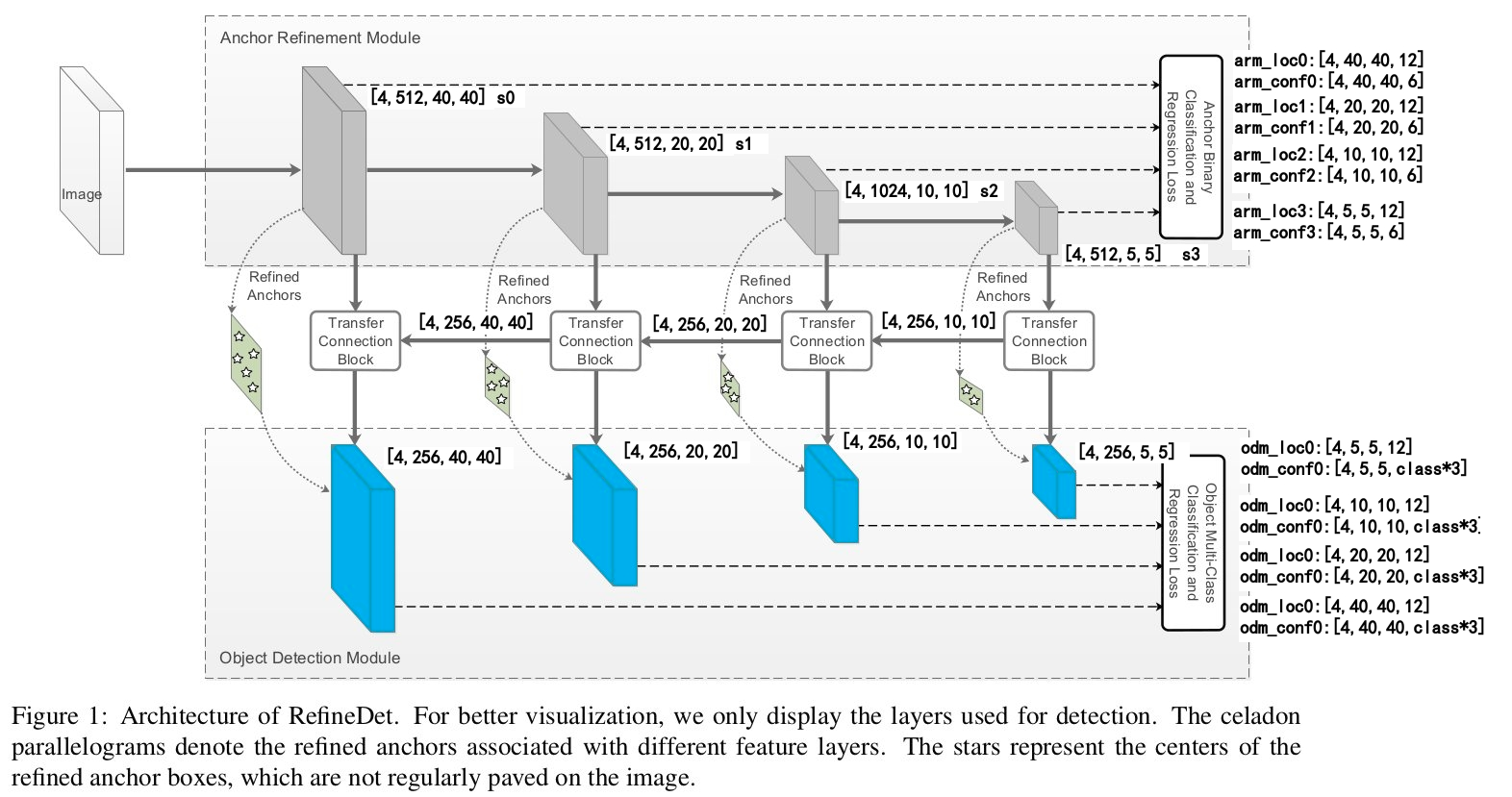
其实到这里为止,我们没有看到任何anchor的操作,都是卷积,卷出特定通道特定尺寸的数据流。网络只负责学习,至于学习什么,怎么学习,都是通过损失函数设定的规则去学习,向着损失最小的方向去学习。
至于损失函数部分,还没有细看。

RefineDet(4)_思考_CVPR2018 https://zhuanlan.zhihu.com/p/50916833
https://zhuanlan.zhihu.com/p/50917804


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律