
经典网络和问题
1.senet
SE模块主要为了提升模型对channel特征的敏感性,这个模块是轻量级的,而且可以应用在现有的网络结构中,只需要增加较少的计算量就可以带来性能的提升。
https://zhuanlan.zhihu.com/p/65459972/
https://www.cnblogs.com/bonelee/p/9030092.html

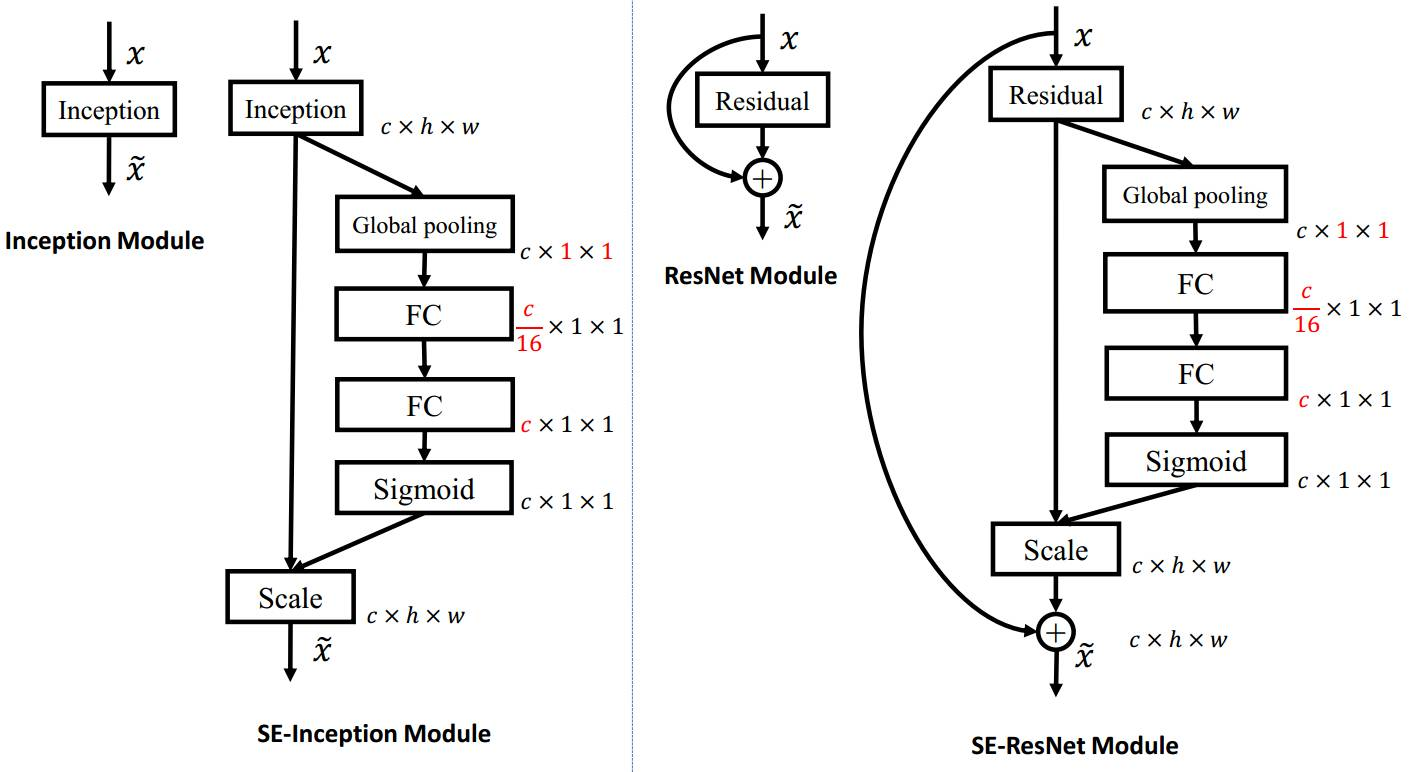
SENet是一个通道注意力机制网络,它的核心思想在于通过损失函数去学习特征权重,使得有效的feature map权重大,效果小的feature map权重小。以达到网络关注重要特征的效果。
SENet解决方案:
对特征提取后的fearture map在高和宽的维度上进行全局平均池化,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野;()
通过参数 w 来为每个特征通道生成权重,w 学习征通道间的相关性;
通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
两个细节:
1.全局平均池化之后,接两个全连接。首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样可以,具有更多的非线性,更好地拟合通道间复杂的相关性;极大地减少了参数量和计算量。
2.全连接之后痛过sigmod获得归一化的权重。特别在残差网络中sigmod在addition 前对分支上残差特征进行了特征重标定;如果在addition之后,等于主干网上存在0~1的加权操作,在网络较深BP 优化时就会在靠近输入层的地方出现梯度消散,导致模型难以优化。
2. 梯度消失和梯度爆炸的问题是如何产生的?如何解决?
答:第一个问题相对简单,由于反向传播过程中,前面网络权重的偏导数的计算是逐渐从后往前累乘的,如果使用 [公式] 激活函数的话,由于导数小于一,因此累乘会逐渐变小,导致梯度消失,前面的网络层权重更新变慢;如果权重 [公式] 本身比较大,累乘会导致前面网络的参数偏导数变大,产生数值上溢。
因为 sigmoid 导数最大为1/4,故只有当abs(w)>4时才可能出现梯度爆炸,因此最普遍发生的是梯度消失问题。
解决方法通常包括
1.使用ReLU等激活函数,梯度只会为0或者1,每层的网络都可以得到相同的更新速度
2.采用LSTM
3.进行梯度裁剪(clip), 如果梯度值大于某个阈值,我们就进行梯度裁剪,限制在一个范围内
4.使用正则化,这样会限制参数w的大小,从而防止梯度爆炸
5.设计网络层数更少的网络进行模型训练
6.batch normalization
3.为什么LSTM相比RNN能够解决long-range dependency的问题
https://zhuanlan.zhihu.com/p/85776566
4. 非平衡数据集的处理方法有哪些?
1.采用更好的评价指标,例如F1、AUC曲线等,而不是Recall、Precision
2.进行过采样,随机重复少类别的样本来增加它的数量;
3.进行欠采样,随机对多类别样本降采样
4.通过在已有数据上添加噪声来生成新的数据
5.修改损失函数,添加新的惩罚项,使得小样本的类别被判断错误的损失增大,迫使模型重视小样本的数据
6.使用组合/集成方法解决样本不均衡,在每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集和训练模型。最后在应用时,使用组合方法(例如投票、加权投票等)产生分类预测结果;
4.问题集
https://zhuanlan.zhihu.com/p/40590443

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步