

Yolov3 训练自己的数据集
一、下载源码
git clone https://github.com/ultralytics/yolov3.git
cd yolov3
git checkout cf7a4d31d37788023a9186a1a143a2dab0275ead
最新版本需要pytorch1.7,由于我是实验yolov3转tensorrt,
https://github.com/wang-xinyu/tensorrtx/tree/master/yolov3
这里需要checkout到指定版本。搭pytorch1.5,cuda10.0的环境就可以。
二、数据准备
2.1 voc格式转yolo格式
用的这个仓库:
https://github.com/ssaru/convert2Yolo
运行脚本:
python3 example.py --datasets VOC --img_path /data_2/project_2021/yolo/mydata/val/img/ --label /data_2/project_2021/yolo/mydata/val/xml/ --convert_output_path ./out/ --img_type ".jpg" --manipast_path ./ --cls_list_file /data_1/everyday/0127/convert2Yolo-master/voc.names
--img_path是图片文件夹路径
--label 是xml路径
--convert_output_path 是生成的路径 需要自己新建文件夹
--cls_list_file 是类别名字,一个类别名字一行
例如voc.names里面内容如下:
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
pottedplant
sheep
sofa
train
tvmonitor
其中,生成的格式如下:(class,center_x,center_y,w,h)
3 0.221 0.667 0.427 0.666
14 0.292 0.563 0.051 0.066
2.2 yolov3目录下新建文件夹mydata,数据按照如下格式存放
├── list_train.txt
├── list_val.txt
├── mydata.names
├── train
│ ├── images
│ │ ├── 000005.jpg
│ │ ├── 2012_004328.jpg
│ └── labels
│ ├── 000005.txt
│ └── 2012_004328.txt
└── val
├── images
│ ├── 000038.jpg
│ ├── 000039.jpg
└── labels
├── 000038.txt
└── 000039.txt
list_train.txt和list_val.txt里面存放的是文件夹images下面图片的绝对路径。
Labels是2.1生成的txt。
2.3在data目录下面新建mydata.data
里面内容如下:
classes=20
train=./mydata/list_train.txt
valid=./mydata/list_val.txt
names=./mydata/mydata.names
Classes就是自己数据集类别数量,不包括背景类。
三、网络配置文件修改yolov3/cfg/yolov3.cfg,修改类别数量
首先复制拷贝一份yolov3/cfg/yolov3.cfg,再修改yolov3.cfg里面内容
3.1修改每个yolo层的classes为自己的类别数,不包含背景类。
3.2修改每个yolo层上面filters为3*(classes+5)
每一个[region/yolo]层前的最后一个卷积层中的 filters=预测框的个数(mask对应的个数,比如mask=0,1,2, 代表使用了anchors中的前三对,这里预测框个数就应该是3*(classes+5) ,5的意义是4个坐标+1个置信度代表这个格子含有目标的概率,也就是论文中的tx,ty,tw,th,po
[convolutional]
size=1
stride=1
pad=1
filters=255 ##改为75
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80 ##改为20
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
四、下载所需要的预训练模型,需要Google上网
https://drive.google.com/drive/folders/1LezFG5g3BCW6iYaV89B2i64cqEUZD7e0
下载yolov3.pt存放在yolov3/weights/下面
五、代码修改
Train.py
Line6:注释
#from torch.utils.tensorboard import SummaryWriter
Line415:注释
#tb_writer = SummaryWriter(comment=opt.name)
Train.py的main函数修改如下:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=300) # 500200 batches at bs 16, 117263 COCO images = 273 epochs
parser.add_argument('--batch-size', type=int, default=3) # effective bs = batch_size * accumulate = 16 * 4 = 64 ##modify##################
parser.add_argument('--cfg', type=str, default='cfg/yolov3.cfg', help='*.cfg path') ##modify##################
parser.add_argument('--data', type=str, default='data/mydata.data', help='*.data path')##modify##################
parser.add_argument('--multi-scale', action='store_true', help='adjust (67%% - 150%%) img_size every 10 batches')
parser.add_argument('--img-size', nargs='+', type=int, default=[320, 640], help='[min_train, max-train, test]')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', action='store_true', help='resume training from last.pt')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--weights', type=str, default='weights/yolov3.pt', help='initial weights path') ##modify##################
parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied')
parser.add_argument('--device', default='', help='device id (i.e. 0 or 0,1 or cpu)')
parser.add_argument('--adam', action='store_true', help='use adam optimizer')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
opt = parser.parse_args()
六、运行训练
Python train.py
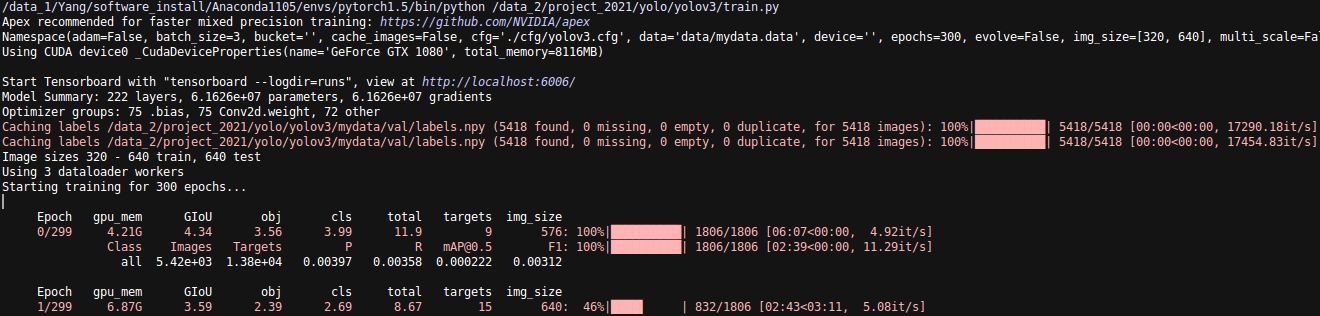
显示如下就说明可以训练了:
七、测试看效果
detect.py修改如下:
其中最下面的main修改如下:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='cfg/yolov3.cfg', help='*.cfg path')##modify##################
parser.add_argument('--names', type=str, default='mydata/mydata.names', help='*.names path')##modify##################
parser.add_argument('--weights', type=str, default='weights/best.pt', help='weights path')##modify##################
parser.add_argument('--source', type=str, default='data/samples', help='source') # input file/folder, 0 for webcam
parser.add_argument('--output', type=str, default='output', help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=512, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.3, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.6, help='IOU threshold for NMS')
parser.add_argument('--fourcc', type=str, default='mp4v', help='output video codec (verify ffmpeg support)')
parser.add_argument('--half', action='store_true', help='half precision FP16 inference')
parser.add_argument('--device', default='', help='device id (i.e. 0 or 0,1) or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
opt = parser.parse_args()
opt.cfg = list(glob.iglob('./**/' + opt.cfg, recursive=True))[0] # find file
opt.names = list(glob.iglob('./**/' + opt.names, recursive=True))[0] # find file
print(opt)
with torch.no_grad():
detect()
Data/sample放需要检测的图片,然后结果都保存在yolov3/output文件夹下。

注:voc没有领带这类

