deeplab系列论文研读
Deeplab v1:(2015)SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
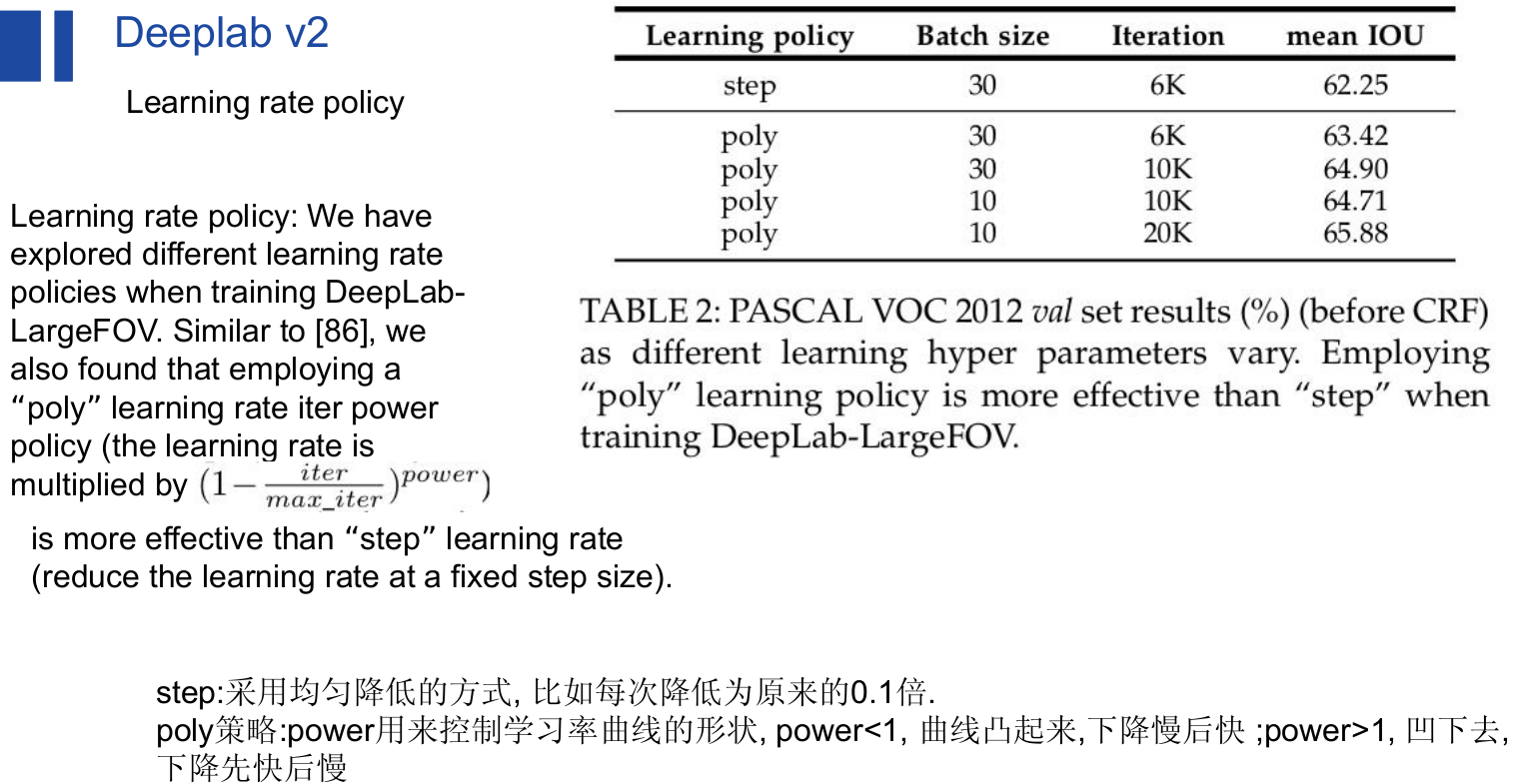
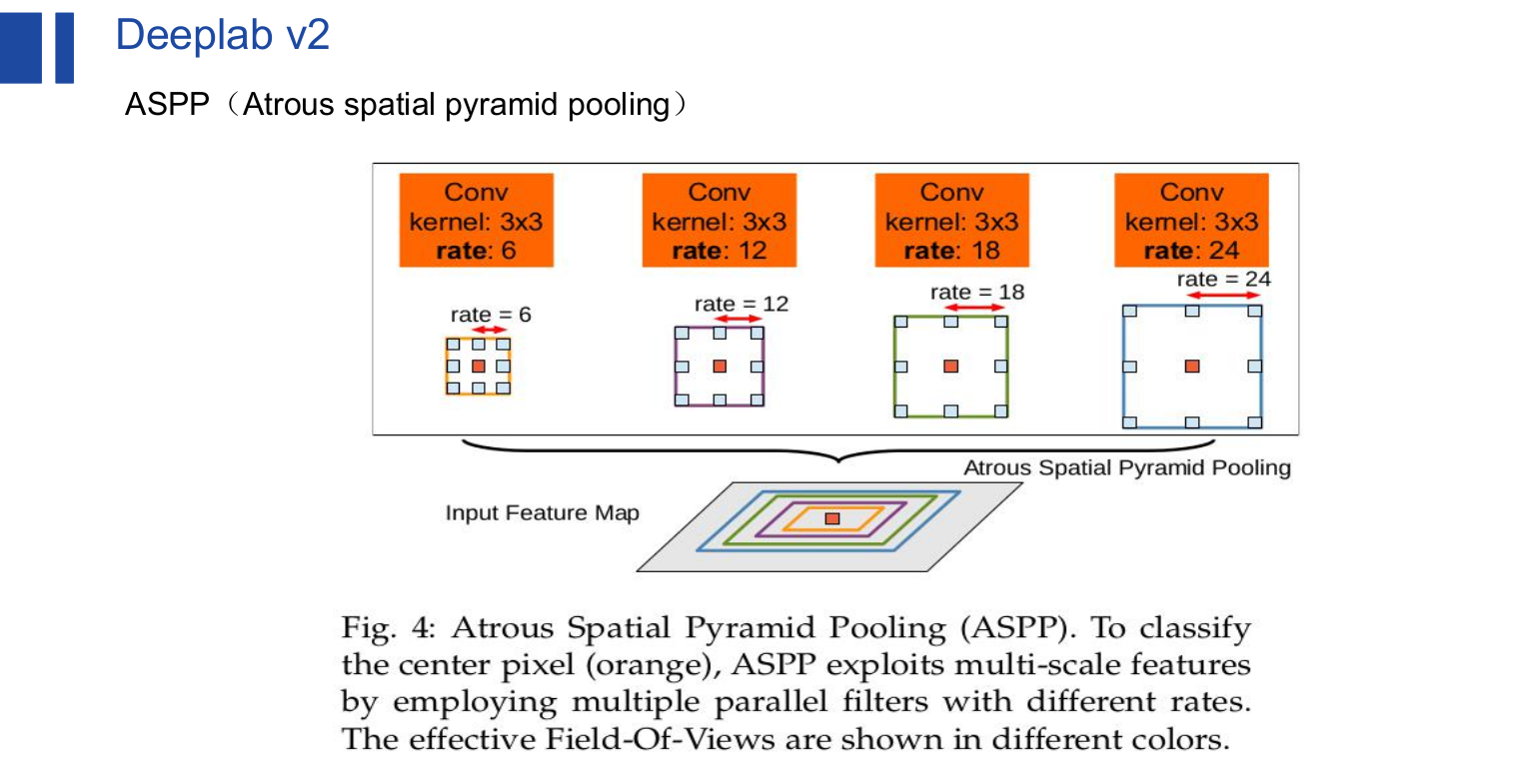
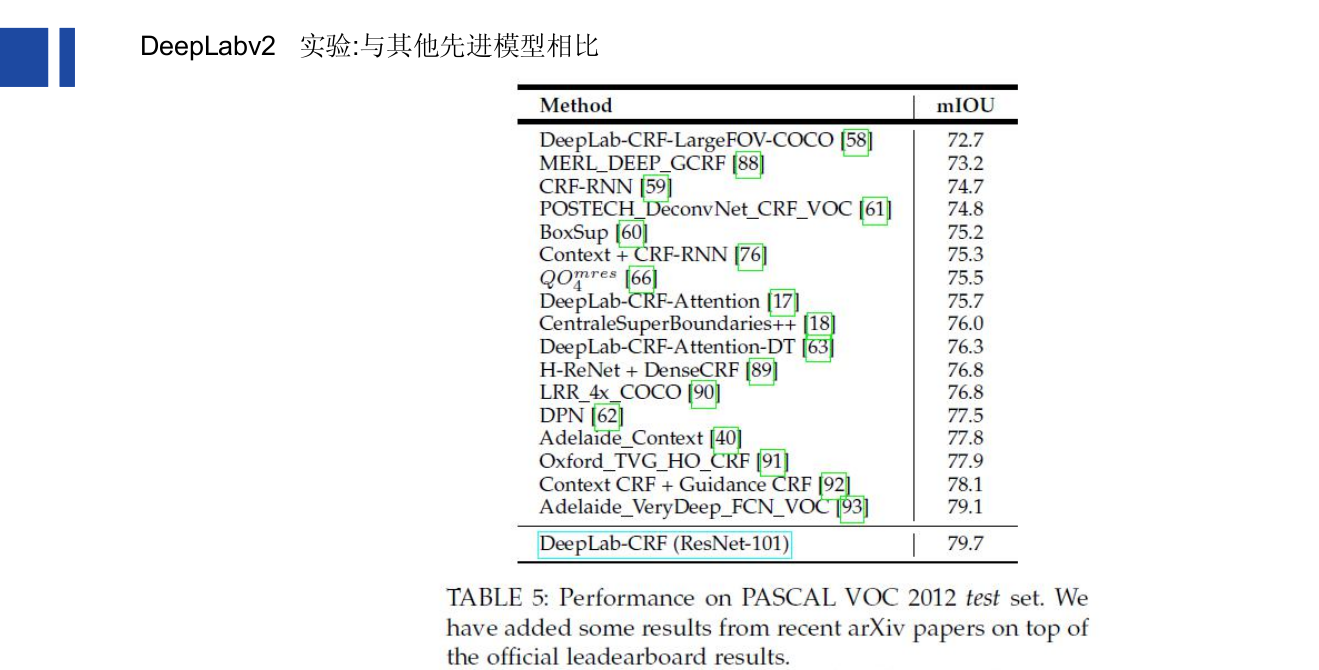
Deeplab v2:(2016.06)Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs
Deeplab v3:(2017)Rethinking Atrous Convolution for Semantic Image Segmentation
Deeplab v3+:(2018)Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Deeplab v1:(2015)SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
论文的写作时间是2014年,当时深度卷积神经网络在高级视觉研究领域取得了突破。其卷积和池化操作保证了其不变性,能够提取高级抽象特征。
不变性指的是平移不变性,卷积层扩大感知野,池化层的pooling操作,即使图像有小的位移、缩放、扭曲等,提取到的特征依然会保持不变,减小了相对空间位置的影响。
这在高级特征提取中作用重大,但在一些低级视觉研究,如语义分割任务中效果是不理想的。我们希望获取具体的空间信息,而这些信息随着网络的加深慢慢丢失掉。
于是对于语义分割任务,DCNN存在两个问题。
第一,最大池化和下采样操作压缩了图像分辨率。一般语义分割通过将网络的全连接层改为卷积层,获取得分图(或称为概率图、热图),然后对其上采样、反卷积等操作还原与输入图像同样大小。如果压缩太厉害,还原后分辨率就会比较低,因此我们希望获得更为稠密(dense)或尺寸更大的得分图;
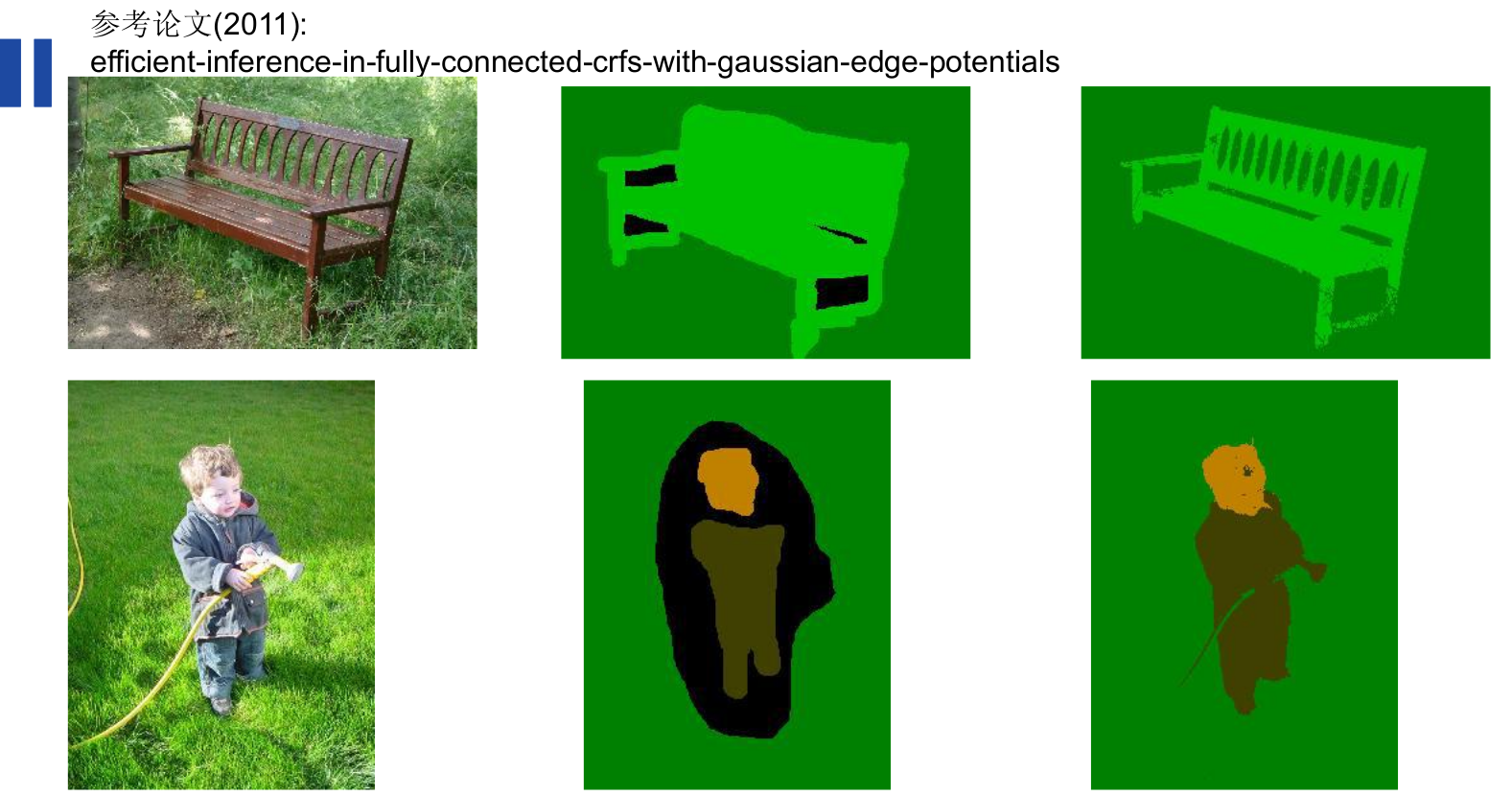
第二,对空间变换的不变性限制了模型的精度,网络丢失了很多细节,获得的概率图会比较模糊,我们希望获得更多的细节。在该文章中,提出使用空洞算法和全连接CRF分别解决这两个问题。
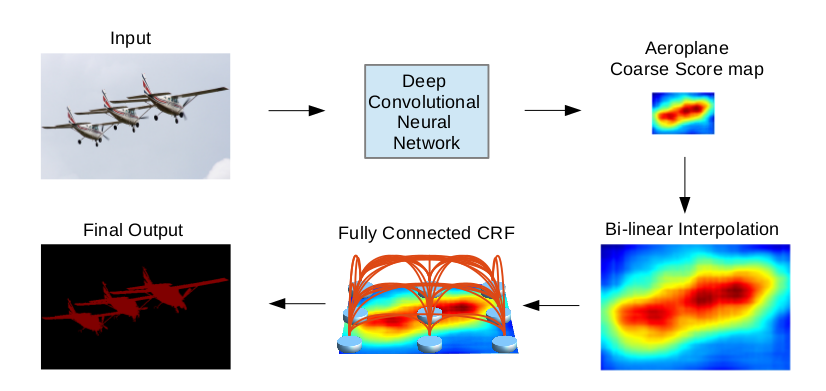
DeeplabV1方法分为两步走,
第一步仍然采用了DCNNs得到 coarse score map并插值到原图像大小.
因为缩小8倍的,所以直接放大到原图是可以接受的。如果是32倍,则需要上采样(反卷积)。
然后第二步借用fully connected CRF对从FCN得到的分割结果进行细节上的refine。
vgg16:

VGG16中,卷积层的卷积核大小统一为 33 ,步长为 1,最大池化层的池化窗口为 2 * 2 ,步长为2 。VGG16模型有5次池化,缩小 2^5=32 倍
Layer (type) Output Shape Param
Conv2d-1 [-1, 64, 321, 321] 1,792
Conv2d-2 [-1, 64, 321, 321] 36,928
MaxPool2d-3 [-1, 64, 161, 161] 0
Conv2d-4 [-1, 128, 161, 161] 73,856
Conv2d-5 [-1, 128, 161, 161] 147,584
MaxPool2d-6 [-1, 128, 81, 81] 0
Conv2d-7 [-1, 256, 81, 81] 295,168
Conv2d-8 [-1, 256, 81, 81] 590,080
Conv2d-9 [-1, 256, 81, 81] 590,080
MaxPool2d-10 [-1, 256, 41, 41] 0
Conv2d-11 [-1, 512, 41, 41] 1,180,160
Conv2d-12 [-1, 512, 41, 41] 2,359,808
Conv2d-13 [-1, 512, 41, 41] 2,359,808
MaxPool2d-14 [-1, 512, 21, 21] 0
Conv2d-15 [-1, 512, 21, 21] 2,359,808
Conv2d-16 [-1, 512, 21, 21] 2,359,808
Conv2d-17 [-1, 512, 21, 21] 2,359,808
MaxPool2d-18 [-1, 512, 11, 11] 0
Linear-19 [-1, 4096] 253,759,488
Linear-20 [-1, 4096] 16,781,312
Linear-21 [-1, 1000] 4,097,000
=========================================================
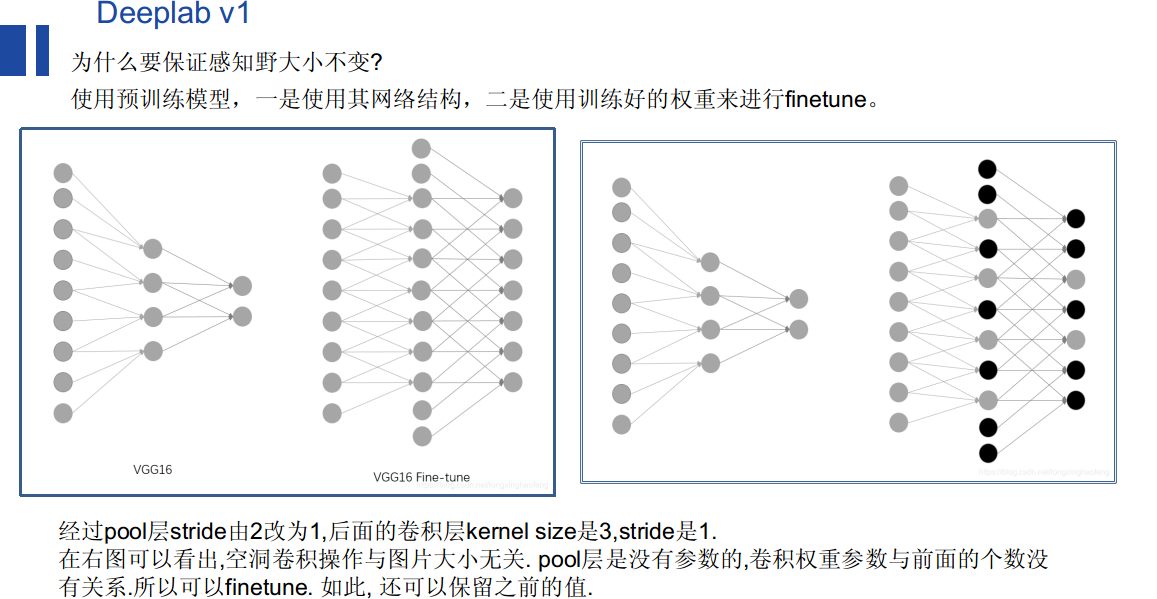
deeplap v1在vgg16基础上做了改动:
- 后面两个pool层步长变为为1
- conv4,conv5空洞卷积
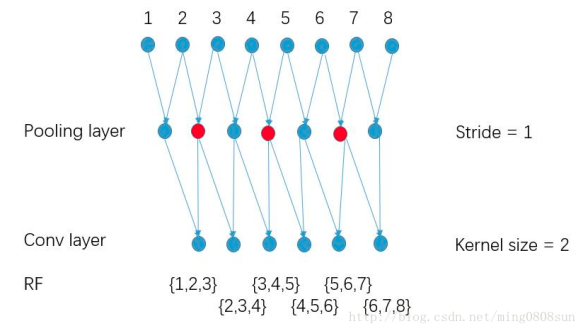
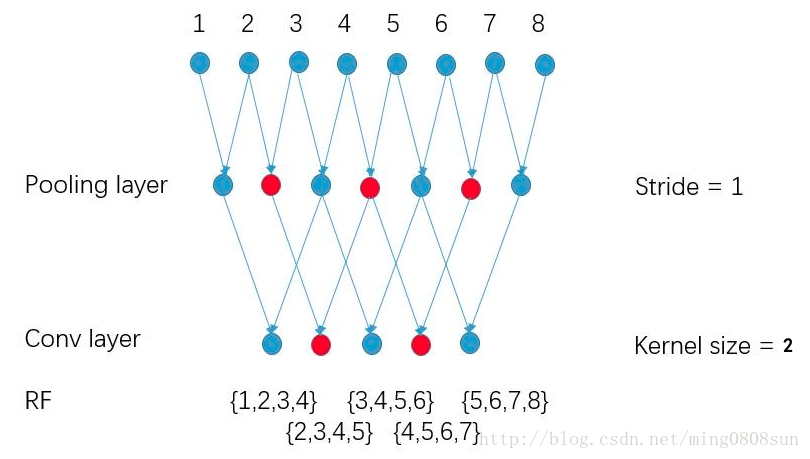
pool stride由2变为1, 如下图所示:
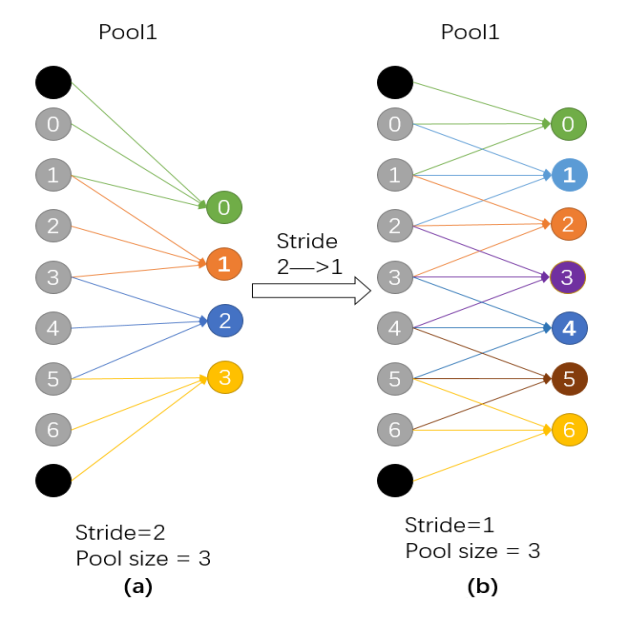
图a的输出0123对于图b输出的0246,感受野相同,但又多了其他节点,使得feature变得更加稠密。
空洞卷积或者又叫做膨胀卷积
使用hole算法后,卷积核大小变化:
k=k+(k−1)(hloesize−1)
空洞卷积优点:
不增加计算量情况下扩大感受野
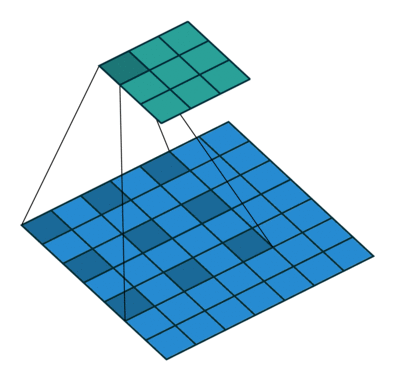
感受野的计算:


vgg16 感受野计算:
感受野计算详细代码戳
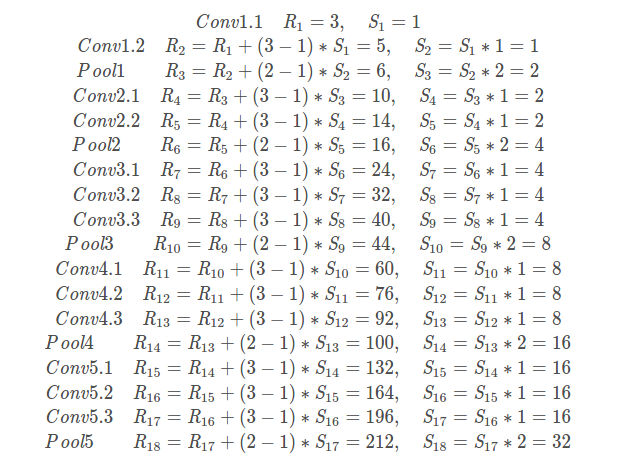


pool的stride由2变为1,使得后面的卷集层的感受野变小:
这个公式也可以看出:
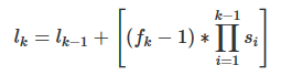



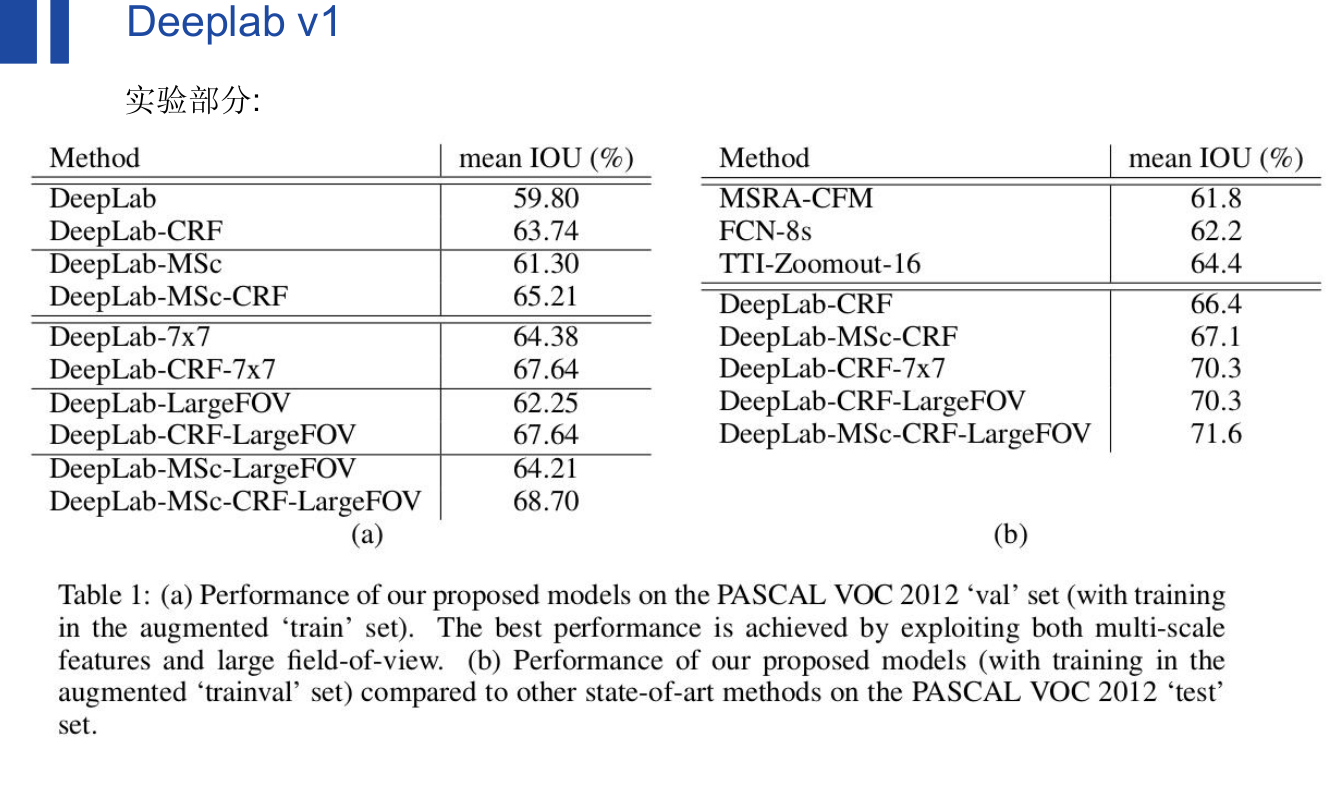
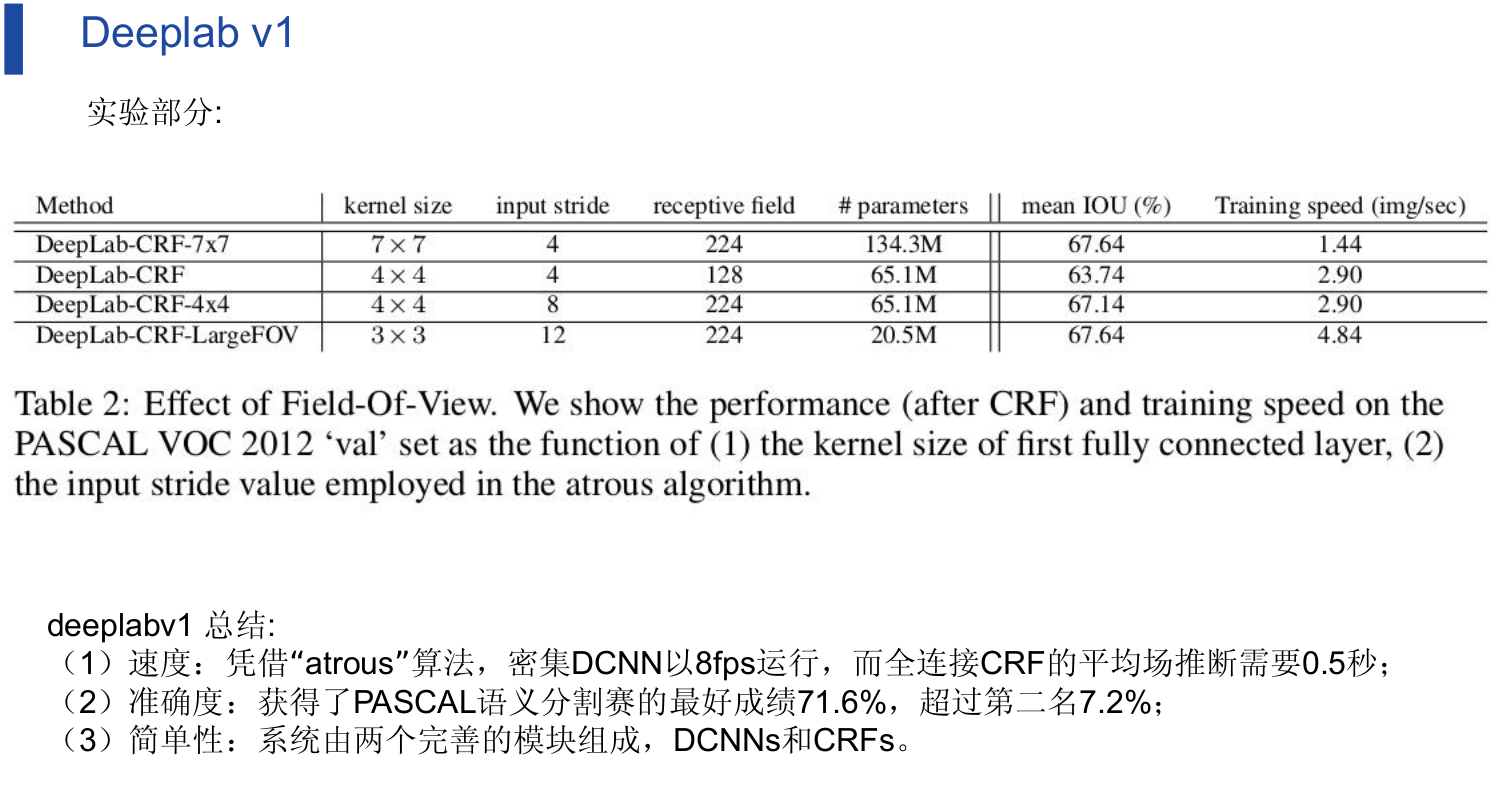
deeplab v1:


我已经不想复制粘贴了,直接截ppt图: