

psenet的后处理
深度学习ocr交流qq群:1020395892
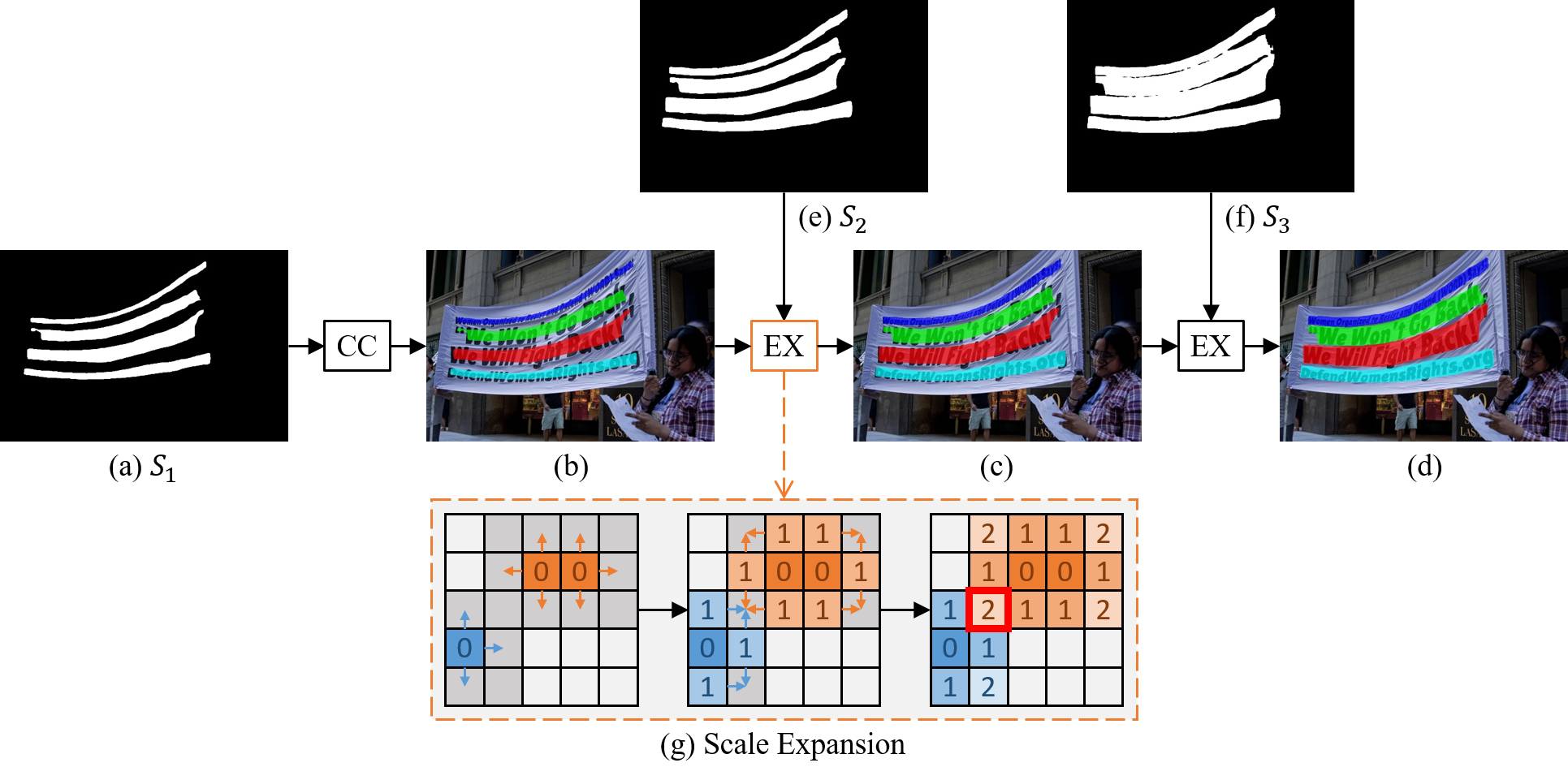
这是作者提供的图,对应的代码如下:
void growing_text_line(vector<Mat> &kernals, vector<vector<int>> &text_line, float min_area) {
Mat label_mat;
int label_num = connectedComponents(kernals[kernals.size() - 1], label_mat, 4);
// cout << "label num: " << label_num << endl;
int area[label_num + 1];//统计每个文字块像素的个数即面积
memset(area, 0, sizeof(area));
for (int x = 0; x < label_mat.rows; ++x) {
for (int y = 0; y < label_mat.cols; ++y) {
int label = label_mat.at<int>(x, y);
if (label == 0) continue;
area[label] += 1;
}
}
queue<Point> queue, next_queue;//重要:队列,先进先出
for (int x = 0; x < label_mat.rows; ++x) {
vector<int> row(label_mat.cols);
for (int y = 0; y < label_mat.cols; ++y) {
int label = label_mat.at<int>(x, y);
if (label == 0) continue;
if (area[label] < min_area) continue;
Point point(x, y);
queue.push(point);//重要:队列保存非0位置
row[y] = label;//非0的label保存
}
text_line.emplace_back(row);
}
// text_line: 传出去的text_line先保存了最瘦的那个分割图各个label
// cout << "ok" << endl;
//4邻域
int dx[] = {-1, 1, 0, 0};
int dy[] = {0, 0, -1, 1};
// 从倒数第二个开始,因为是以倒数第一个最瘦的为基础的
for (int kernal_id = kernals.size() - 2; kernal_id >= 0; --kernal_id) {
while (!queue.empty()) {
Point point = queue.front(); queue.pop();
int x = point.x;
int y = point.y;
int label = text_line[x][y];
// cout << text_line.size() << ' ' << text_line[0].size() << ' ' << x << ' ' << y << endl;
bool is_edge = true;
for (int d = 0; d < 4; ++d) {
int tmp_x = x + dx[d];
int tmp_y = y + dy[d];
if (tmp_x < 0 || tmp_x >= (int)text_line.size()) continue;
if (tmp_y < 0 || tmp_y >= (int)text_line[1].size()) continue;
if (kernals[kernal_id].at<char>(tmp_x, tmp_y) == 0) continue;
if (text_line[tmp_x][tmp_y] > 0) continue;
// 能够下来的需要满足两个条件: 1. (kernals[kernal_id].at<char>(tmp_x, tmp_y) != 0) 2. (text_line[tmp_x][tmp_y] == 0)
// 即: 1. 上个分割图对应位置上有东西 2. 本位置无东西
// 满足这两个条件就放到队列最后(queue.push(point));,同时把该位置归化为自己的label( text_line[tmp_x][tmp_y] = label;)
Point point(tmp_x, tmp_y);
queue.push(point);
text_line[tmp_x][tmp_y] = label;
is_edge = false;
}
if (is_edge) {//注:当前点都是有东西的 如果当前点任一邻域有东西(文字块内)或者当前点任一邻域对应的上一个分割图位置上没有东西(文字块边界)
next_queue.push(point);
}
}
swap(queue, next_queue);
}
}
其中参数,vector
vector<vector
min_area 是阈值(300),过滤小的干扰点。
int label_num = connectedComponents(kernals[kernals.size() - 1], label_mat, 4);
connectedComponents是opencv函数,传入的kernals[kernals.size() - 1]是最小的核,就是最瘦的那个,label_mat是传出,传出的是标签图,比如kernals[kernals.size() - 1]有6个文字块,那个label_mat就把每个文字块里面编号,比如第一个文字块里面像素全为1,第二个文字块里面像素全为2,类推。其余非文字块区域为0.同时,返回值label_num为文字块个数6. 还有一个参数4是4邻域
改注释的都在代码里面了,其实一开始理解这个循环也理解了好久,有的地方怎么想都没有想明白,比如,这个代码是如何处理两个边界融合在一起的。下面分简单和容易的来:第一种简单的情况:

比如这两张图,左边是瘦的那个,右边是轮廓稍微扩张了一点,黄色区域就是比左边的稍微外扩一点的。这是没有交叠的情况,
if (kernals[kernal_id].at
if (text_line[tmp_x][tmp_y] > 0) continue;
text_line是左边这张图,queue从上到下从左到右记录了左边这张图非0区域, (kernals[kernal_id]是右边这张图,比如左边上面第一个轮廓内,都会满足 if (text_line[tmp_x][tmp_y] > 0) continue;这个条件,(即轮廓内的任一邻域都有东西),从而is_edge=true;就会把当前点 next_queue.push(point);给到下一个队列。这里似乎没有啥难理解的。
第二种情况,有交叠了:

按照上面的:
if (kernals[kernal_id].at
if (text_line[tmp_x][tmp_y] > 0) continue;
// 能够下来的需要满足两个条件: 1. (kernals[kernal_id].at
// 即: 1. 上个分割图对应位置上有东西 2. 本位置无东西
就是看本图位置邻域没有东西,同时上一个分割图对应位置有东西,我们就把该邻域归一化为自己,按照我一开始这样的逻辑,想,那么第二个轮廓扩展的都要被第一个轮廓吞并了?成下面这样:
 ,再来一个图:
,再来一个图:
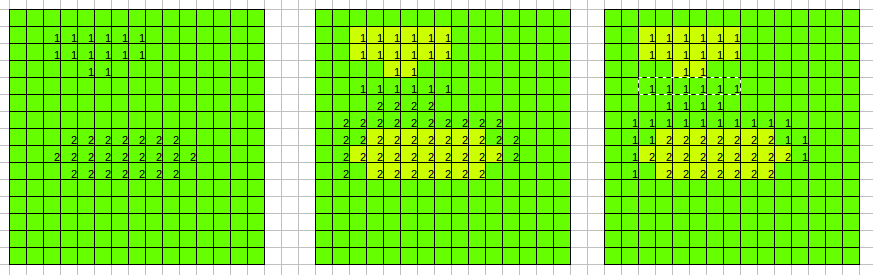 ,最左边图,然后下边有多出1,那么本来最左边图下面没有1,第二个图下面有东西,那个我就要把你归并,按照我想的,最后归并后应该是最右边那个图了,困扰了我好久好久。。。(其实这个图还有一个错误的就是归一化后第一张图也要改变,需要把归一化的也改为自己的)后来在同事的提醒下,队列,先进先出!!!其实并不是我想的这样子,它是有顺序的,比如刚刚最简单的情况:
,最左边图,然后下边有多出1,那么本来最左边图下面没有1,第二个图下面有东西,那个我就要把你归并,按照我想的,最后归并后应该是最右边那个图了,困扰了我好久好久。。。(其实这个图还有一个错误的就是归一化后第一张图也要改变,需要把归一化的也改为自己的)后来在同事的提醒下,队列,先进先出!!!其实并不是我想的这样子,它是有顺序的,比如刚刚最简单的情况:

这个其实一开始queue压入的顺序是从上到下,从左到右,完成一次迭代是最右边那个图的样子,并不是一个轮廓扩张完了再扩另外一个的。同样的,交叠的情况:

如图最右边是假设已经扩到交叠处了,那么上面的最右边要处理交叠的情况。
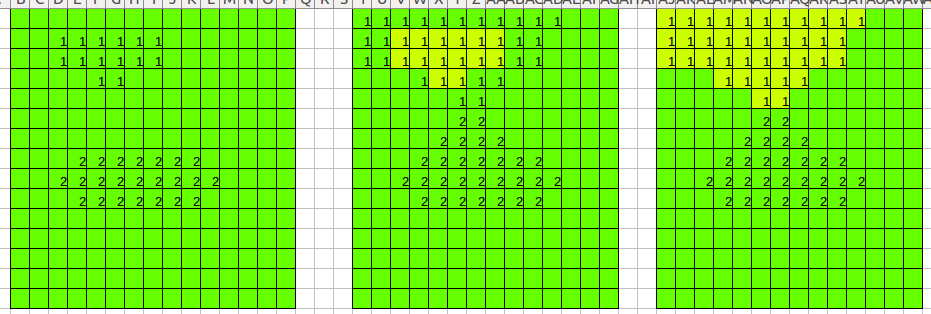
比如,中间图扩张,会把之前的text_line归并,成第三个图,上面,比如最下面的1,1,下面的邻域,发现text_line没有东西,而kernals[kernal_id]有东西,就把2归并为自己的1,然后第一个轮廓归并结束,同时,第二个下面的轮廓,准备归并同样位置的时候,发现text_line有东西,就不能再扩了,这样就是先到先得,1归并2的时候先到的就先得到,这样虽然归并错了,但是就是一两行的问题,影响不大,结果使得交叠的能够得到分割。!!!!完毕。

