

HBASE-使用问题-split region
问题描述:
HBASE表的管理以REGION分区为核心,通常面临如下几个问题:
1) 数据如何存储到指定的region分区,即rowkey设计,region splitkey设计
2)设计的splitkey是否可以解决热点问题
3)设计的splitkey是否可以解决均匀分布,避免自动分裂的问题
4)region的创建和删除问题
对于1)问题 比如:对于按照时间存储的数据,region splitkey 可以是2019,2020 ; 201901,201902;20190101 等等类似方式,可以把指定时间段的数据存储到响应splitkey的region中,达到按照时间存储的效果。
对于2)问题,同一天的数据,可以通过对rowkey或者数据中的一个或多个字段取hash方式,解决热点问题;如果数据存在重复入库,则需要保证用于hash的字段值在两次入库时不能变更,否则会存在两个rowkey数据 即splitkey中包含hash值部分,同样要求rowkey包含hash值
对于3)问题,需要考虑数据量和region分区的关系,比如一天有150G的数据量,hbase 单个region建议10~20G大小,设计时则需要考虑一天需要划分多少的region,才能避免region在数据入库时发生频繁split,会影响hbase服务(split会涉及数据移动,数据通过网络传输和落盘,影响网络和磁盘IO)
对于4)问题,未来的region是否应该提前创建,如何创建?集群存储是否足够,历史的region是否下线或者删除?
此篇文章是在提前创建region分区时遇到的问题
一般的设计方法是,在hbase 尾部region切分新的多个region,用于新的数据存储,通常使用定时任务,提前创建
切分方式是通过调用HBASE split region方法,region尾部splitkey为 20210600 ~“” 需要切分的splitkey为20210601,20210602,20210603,20210700
采用的方法是: 先20210601切分,得到如下两个region: 20210600 ~20210601, 20210601~“” 然后等待 20210601~“” 此region上线,再使用20210602切分
以此类推
但是在实际项目中发现,只切分了一个region就任务结束了,程序本身在等待新切分region上线时,可以等待1s~60秒中,发现此问题后,可以配置等待时长,
但是实际效果不好,仍会存在上述问题
1) 观察Hbase regionServer端日志,发现如下日志,debug日志显示待切分region对应的存储文件正在被引用使用,导致region split请求切分失败

2)分析Hbase 源码:

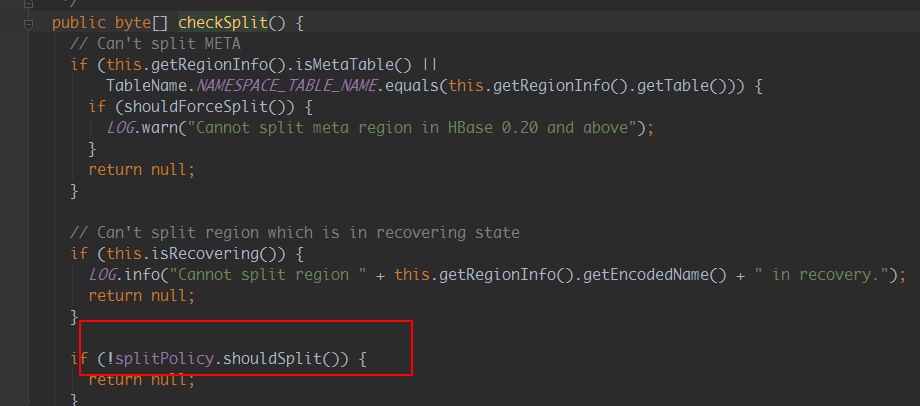
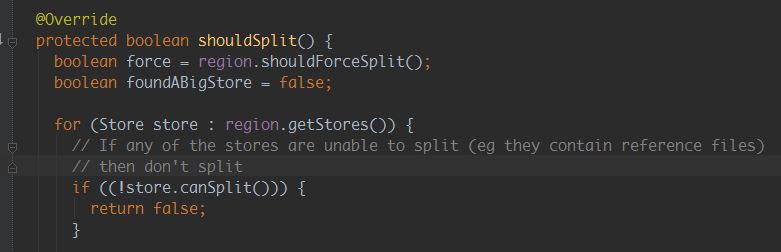
原因分析:hbase split请求调用的为异步请求,通过源码并结合hbase regionserver日志可以看出,hbase接收到split请求后,
如果发现需要被切分的region有引用文件时,就返回失败;因为时异步请求,所以程序等待新切分region上线不可行
即Hbase接收到请求后,由于存储文件被引用使用,导致请求失败,region未切分,索引新切分region不会上线,从而失败
修改后方法逻辑为:切分region,等待一段时间上线,不上线则再次切分region,以此多次,仍不成功,则等待下次定时任务触发切分
额外说明:
实际项目中被切分region如果里面有大量数据,切分速度会很快,但是对切分后的region再次切分时,文件引用有较长时间不会消失,无法再次切分
因此实际项目中考虑切分没有数据的尾部region为佳,此外重试切分的时间间隔建议可配置,以免region未及时切分,导致所有数据存入到尾部一个region中
本文来自博客园,作者:life_start,转载请注明原文链接:https://www.cnblogs.com/yangh2016/p/14745450.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号