redis的几个知识点
Redis的全称是Remote Dictionary Server,即远程字典服务,通常用作服务器缓存服务。
这里通过Redis的几个知识点来了解Redis。
Redis的通讯协议
Redis的通讯协议是文本协议,是的,Redis服务器与客户端通过RESP(Redis Serialization Protocol、Redis序列化协议)进行通信。
虽然文本协议会浪费流量,不过它的优点在于直观,非常得简单,解析性能极其好,所以我们不需要一个特殊的Redis客户端,仅靠Telnet或者是文本流就可以跟Redis进行通讯。
客户端的命令格式
1.简单字符串Simple Strings,以加号【+】开头。
2.错误Errors,以减号【-】开头。
3.整数型Integer,以冒号【:】开头。
4.大字符串类型Bulk Strings,以美元符号【$】开头。
5.数组类型Arrays,以星号【*】开头。
因为通讯协议是文本协议这一特性,一个简单的文本流就可以是Redis的客户端。
public static void set() throws UnknownHostException, IOException { Socket socket = new Socket("127.0.0.1", 8080); OutputStream os = new BufferedReader(new InputStreamReader(socket.getInputStream())); // set hello os.write("*3\r\n".getBytes()); os.write("$3\r\n".getBytes()); os.write("set\r\n".getBytes()); os.write("$5\r\n".getBytes()); os.write("hello\r\n".getBytes()); int num = 0; char ch; while ((num = br.read()) != -1) { ch = (char)num; System.out.println(ch); } socket.close(); }
这里是简单的总结,具体可以参考官方文档:https://redis.io/topics/protocol。
我的理解就是,Redis采用RESP文本协议最重要的三点:简单的实现、快速的解析和直观的理解。虽然文本协议可能会造成一定程度的流量浪费,但是在性能上和操作上却快速简单,这中间也是有一个权衡和协调的过程。
Reids的事务
Redis是有事务的,并且内置了一些事务相关的命令。
| 命令 | 描述 |
| exec | 执行所有事务块内的命令。 |
| watch | 监视一个(或多个)key,如果在事务执行之前这个(或这些)key被其他命令所改动,那么事务将被打断。 |
| discard | 取消事务,放弃执行事务块内的所有命令。 |
| unwatch | 取消watch命令对所有key的监视。 |
| multi | 标记一个事务块的开始。 |
我们知道,传统的数据库的事务一般具有四个特性,即ACID(原子性、一致性、隔离性和持久性),然后我们可以使用上面的Redis事务相关命令来检验Redis是否都具备了这事务的四个特性。
原子性
事务具备原子性是指数据库将事务中的多个操作当作一个整体来执行,服务要么执行事务中所有的操作,要么一个操作也不执行。
1.事务操作队列
Redis一旦开始执行事务开始命令multi之后,就会为这个事务生成一个队列,每次操作的命令都会按照顺序插入到这个队列中。这个队列中的操作命令不会被马上执行,直到执行exec命令提交事务的时候,队列里面的所有操作命令才会被一次性且排他地执行。
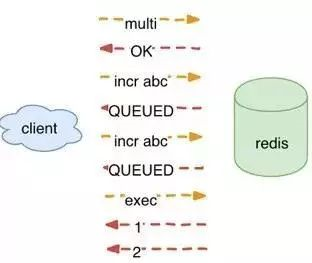
从上面的例子中可以看出,当执行一个成功的事务,事务里面的命令都是按照队列里面按顺序并且排他地执行。
2.Reids不支持回滚
原子性的特性是要么全部成功,要么全部失败,一旦事务中有一个操作失败了,那么之前成功的操作全部会回滚。
我们执行一个失败的事务,就会发现Redis并不会回滚之前成功的操作,因此从严格意义上来说Redis并不具备原子性。
这和Redis的定位和设计有关系。
对比MySQL,MySQL支持回滚是因为MySQL有完整的Redo Log,并且是在事务进行Commit之前就会写完Redo Log。

但是要知道MySQL为了能够进行回滚花了不少的性能代价。
而Redis是完成操作之后才会进行AOF日志记录,而AOF日志的定位只是记录操作的指令记录。实际上,Redis应用的场景更多的是对抗高并发的高性能,因此Redis选择了更为简单,更快速无回滚的方式处理事务也是符合场景的。
一致性
事务具备一致性指的是,如果数据在执行事务之前是一致的,那么在事务执行完成之后,无论事务是否成功,数据也应该是一致的。
对Redis来说,一致性可以从两个层面来看。一个是执行错误是否有确保一致性;另一个是宕机时,Redis是否有确保一致性的机制。
1.执行错误是否有确保一致性
假设事务中有两个操作,一个是将杨杨的余额增加100,静静的余额减少100,这两个操作完成一个【静静给杨杨转账100】的事务。那么,当操作一成功了,而操作二失败了,成功的操作一并不会回滚,这就导致杨杨的余额增加了100,而静静的余额却没有减少100,数据也就不一致了。因此Redis对执行错误并没有确保一致性的机制,可以说Redis并没有支持事务的一致性。
2.宕机对一致性的影响
暂不考虑分布式高可用的Redis解决方案,先从单机看宕机恢复是否能满足数据完成性约束。因为Redis支持将数据持久化到磁盘,宕机后可以从磁盘恢复数据。然而无论是RDB还是AOF方案去恢复数据,都只能恢复到宕机前的操作,就像前面的执行错误一样,并不会将宕机前属于同一个事务中成功的操作回滚。正是因为Redis并不支持回滚,也就不具备传统意义上的原子性,因此也不具备传统意义的一致性。
隔离性
隔离性指的是,数据库有多个事务并发的执行,各个事务之间不会相互影响,并且在并发状态下执行的事务和串行执行的事务产生的结果是完全相同的。
Redis因为是单线程操作,所以在隔离性上有天生的隔离机制,当Redis执行事务的时候,Redis的服务端保证在执行事务期间不会对事务进行中断,所以Redis事务总是以串行的方式运行,事务也具备隔离性。
持久性
事务的持久性是指,当一个事务执行完毕,执行这个事务所得到的结果会被永久地保存在持久化的磁盘存储中,即使服务器在事务执行完毕之后宕机了,执行的事务的结果也不会丢失。而Redis是否具备持久化,取决于Redis的持久化模式(三种运行模式):
1.纯粹的内存运行,不具备持久化功能。这样的话,一旦服务宕机,所有数据都会丢失(内存中的数据会因为服务器停止运行而全部清空)。
2.RDB模式运行。这一模式取决于RDB策略,只有在满足策略的情况下才会执行Bgsave,异步执行并不能保证Redis具备持久化。
3.AOF模式运行。这一模式下只有将appendfsync属性设置为always,程序才会在执行命令的时候将数据同步保存到磁盘。
Redis的持久化
Redis有两种持久化机制,一个是RDB,也就是快照,快照就是一次全量的备份,会把所有Reids的内存数据进行二进制的序列化存储到磁盘;另一种是AOF日志,AOF日志记录的是数据库操作修改的指令记录日志,可以类比MySQL的BinLog,AOF日志随着时间的推移只会无限增量。
在对Redis进行恢复的时候,RDB快照直接读取磁盘即可恢复,而AOF需要对所有的操作指令进行重放和恢复,这个过程可能非常漫长。
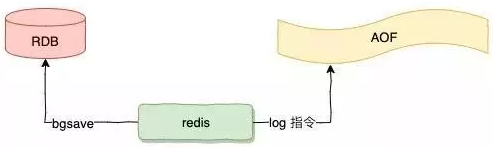
1.RDB持久化机制
Redis在进行RDB的快照生成有两种方法,一种是save,一种是bgsave。由于Redis是单进程单线程,如果直接使用save的话,会进行一个庞大的文件IO操作阻塞线上的业务,因此一般不会直接采用save而是采用bgsave。在使用basave的时候,Redis会fork一个子进程,快照的持久化就交给这个子进程去处理,而父进程继续处理线上业务的请求。
fork机制是linux操作系统的一个进程机制,当父进程fork出来一个子进程,子进程和父进程拥有共同的内存数据结构,子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。
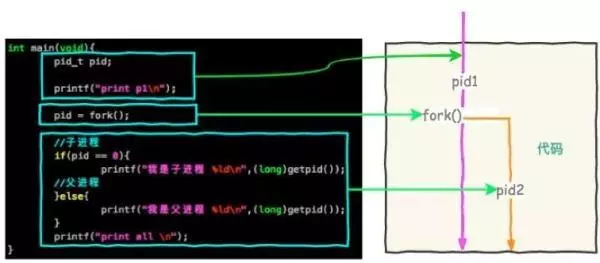
一开始两个进程都具备了相同的内存段,子进程在做数据持久化的时候,不会去修改现在的内存数据,而是会采用COW(Copy on Write)的方式将数据段页面进行分离。当父进程修改了某一个数据段时,被共享的页面就会复制一份分离出来,然后父进程再在新的数据端进行修改。这个过程也称为分裂的过程,本来父子进程都指向很多相同的内存块,但是如果父进程对其中某个内存块进行修改,就会将其复制出来,进行分裂再在新的内存块上进行修改。因为子进程在fork的时候就可以固定内存,这个时间点的数据将不会产生变化。所以我们可以安心地产生快照而不用担心快照的内容受到父进程业务请求的影响。
2.AOF持久化机制
AOF是Redis操作指令的日志存储。类似于MySQL的Binlog。假设AOF从Redis创建以来就一直执行,那么AOF就记录了所有的Redis指令的记录。如果要恢复Redis,可以对AOF进行指令重放,便可修复整个Redis实例。
不过AOF日志也有两个比较大的问题。一个问题是AOF日志会随着时间递增,如果数据量大、操作频繁和运行的时间长,AOF日志量就会异常庞大。另一个问题是AOF在做数据恢复的时候,如果日志量很大,重放的量就会很大,则数据恢复的时间就会非常长。
AOF的写操作是在Redis处理完业务逻辑之后,按照一定的策略才会进行AOF日志存盘,这点跟MySQL的Redolog和Binlog有很大的不同。这样,Redis因为处理逻辑在前而记录操作日志在后,导致了Redis无法回滚。
另外,Redis在2.4的版本之后使用了bgrewriteaof对AOF日志进行瘦身。bgrewriteaof命令用于异步只能够一个AOF文件重写操作,重写会创建一个当前AOF文件的体积优化版本。
3.RDB和AOF混合搭配持久化模式
在对Redis进行恢复的时候,如果我们采用了RDB机制,bgsave的策略可能会导致我们丢失大量的数据;如果我们采用AOF机制,通过AOF操作日志重放恢复,重放AOF日志恢复数据花费的时间比RDB要长久很多。
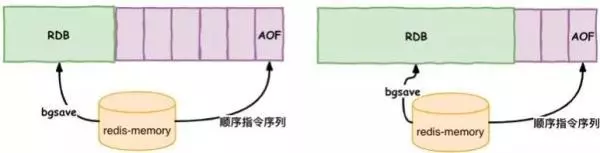
在Redis4.0的版本之后,为了解决这个问题,便引入了新的持久化模式,即混合持久化,将RDB的全量文件和局部增量的AOF文件相结合。这样,RDB就可以使用相隔时间较长的保存策略,AOF也不需要是全量日志,只需要保存前一次RDB存储开始到这段时间增量的AOF日志即可,极大地减小了AOF的日志量。
Redis在内存使用上的优化
Redis和其他传统的数据库不同,是一个纯内存的数据库,并且存储的都是一些特定数据结构的数据,如果不对内存加以控制的话,Redis很可能会因为数据量过大而导致系统奔溃。
1.Ziplist
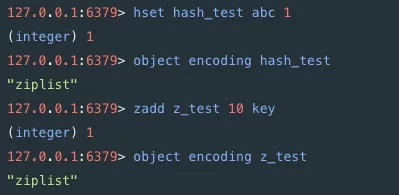
当最开始尝试开启一个小数据量的Hash结构和一个Set结构时,发现它们在Redis里面的真正结构是一个Ziplist。Ziplist是一个紧凑的数据结构,每一个元素之间都是连续的内存,如果在Redis中Redis启用的数据结构数据量很小时,Redis就会切换到使用紧凑存储的形式来进行压缩存储。
例如在上面的例子中,我们采用了Hash结构进行存储,Hash结构是一个二维的结构,是一个典型的用空间换取时间的结构。但是如果使用的数据量很小,使用二维结构反而浪费空间,在时间上的性能也并没有得到太大的提升,还不如直接使用一维结构进行存储。在查找的时候,虽然复杂度是O(n),但是因为数据量少,遍历也很快,甚至比Hash结构本身的查询速度还快。如果当集合对象的元素不断增加,或某个value的值过大,这种小对象存储也会升级成标准的结构。
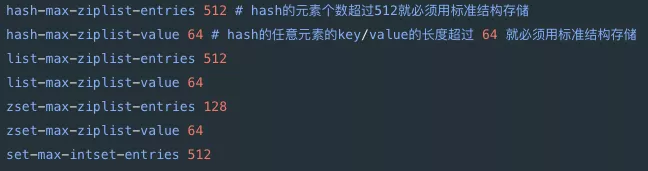
Redis可以在配置中进行紧凑结构和标准结构的转换参数:
2.Quicklist
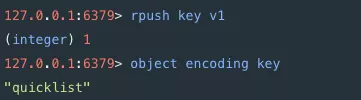
Quicklist数据结构是Redis在3.2才引入的一个双向链表的数据结构,确实来说是一个Ziplist的双向链表。Quicklist的每一个数据节点都是一个Ziplist,而Ziplist本身就是一个紧凑列表。假如Quicklist包含了5个Ziplist的节点,每个Ziplist列表又包含了5个数据,那么在外部看来,这个Quicklist就包含了25个数据项。
Quicklist的结构设计简单总结起来,是一个空间和时间的折中方案。
双向链表可以在两端进行Push和Pop操作,但是它在每一个节点除了保存自身的数据外,还要保存两个指针,增加额外的内存开销。
其次是由于每个节点都是独立的,在内存地址上并不连续,节点多了容易产生内存碎片。
另外,Ziplist本身是一块连续的内存,存储和查询的效率很高。但是它不利于修改操作,每次的数据变动都会引发内存的Realloc。如果Ziplist的长度很长的话,一次Realloc会导致大批量的数据拷贝。
所以,结合Ziplist和双向链表的优点,Quicklist就应运而生。
3.内存共享
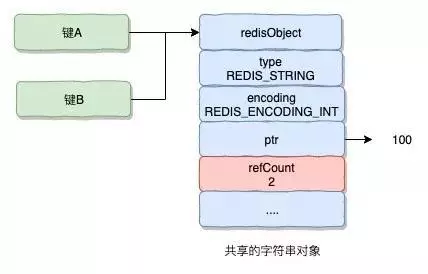
Redis在自己的对象系统中构建了一个引用计数的方法,通过这个方法,程序可以跟踪对象的引用计数信息,除了可以在适当的时候进行对象释放之外,还可以用来作为对象共享。
举个例子,假如键A创建了一个整数值100的字符串作为值对象,这个时候键B也创建保存同样整数值100的字符串对象作为值对象。那么在Reids操作的时候,会将数据库键的指针指向一个现有的值的对象,并将共享的值对象的引用计数加1。这时候,即使数据库中指向整数值100的键不止键A和键B,而是有几百个的话,Redis也只需要一个字符串对象的内存就可以保存原本需要几百个字符串对象才能保存的数据。
Redis的过期删除策略
当一个键处于过期的状态,其实在Redis中这个内存并不是实时就被从内存中摘除的,而是Redis会通过一定的机制去把一些处于过期的键进行移除,进而达到内存的释放。
处于过期状态的键被删除的时间存在三种可能性,这三种可能性也就代表了Redis的三种不同的删除策略:
1.定时删除。定时删除是在设置键过期时间的同时,创建一个定时器,让定时器在键过期时间来临的时候立即执行对键的删除操作。
2.惰性删除。惰性删除是放任键过期不管,之后在每次从键空间获取键的时候再去检查该键是否过期,如果过期的话就删除该键。
3.定期删除。每隔一段时间,程序都要对数据库进行一次检查,删除里面的过期键,至于要删除多少过期键,由算法来决定。
定时删除
定时删除是在设置键过期时间的同时,创建一个定时器,让定时器在键过期时间来临的时候立即执行对键的删除操作。
定时删除对内存是友好的,但是对CPU的时间是最不友好的,特别是在业务繁忙,过期键很多的时候,删除过期键这个操作会占据很大一部分CPU的时间。要知道,Redis是单线程操作的,在内存不紧张而CPU紧张的时候,将CPU的时间浪费在与业务无关的删除过期键的操作上面,会对Reids的服务器的响应时间和吞吐量造成影响。
另外,创建一个定时器需要用到Redis服务器中的时间事件,而当前时间事件的实现方式是无序链表,时间复杂度为O(n),让服务器大量创建定时器去实现定时删除策略,会产生较大的性能影响。所以,定时删除并不是一种好的策略。
惰性删除
惰性删除与定时删除相反,对CPU来说是最友好的,程序只有在取出键的时候才会进行检查,是一种被动的策略。与此同时,惰性删除对内存来说又是不友好的,如果一个过期键不再被取出的话,那这个键因为不会被检查,也就永远不会被删除,它占用的内存也就永远不会被释放。
很明显,惰性删除也不是一个很好的策略,因为Redis是非常依赖内存空间和较好的内存的,如果一些长期键长期没有被访问,就会造成大量的内存垃圾,甚至造成内存泄露。
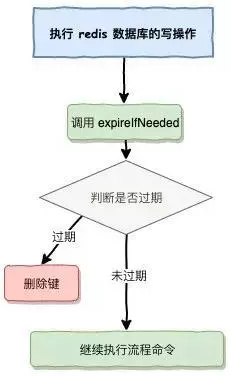
惰性删除的实现是在对执行数据写入的时候,通过expireIfNeeded函数对写入的key进行过期判断,其中expireIfNeeded在内部做了三件事情,分别是:
1.查看key是否过期。
2.向slave节点传播执行删除过期key的动作。
3.删除过期key。
定期删除
上面两种删除策略,无论是定时删除还是惰性删除,都在单一使用上存在明显的缺陷,要么占用太多的CPU时间,要么浪费太多的内存。而定期删除则是前两种删除策略的一个整合和折中。
定期删除策略是每隔一段时间执行一次删除过期键的操作,并通过限制删除操作执行的时间和频率来减少删除操作对CPU时间的影响。通过设置合理的删除执行的时长和频率来达到合理删除过期键的目的。
Redis的主从复制
先说下几个定义:
1.runID:服务器运行的ID。
2.offset:主服务器的复制偏移量和从服务器复制的偏移量。
3.Replication Baclog:主服务器的复制积压缓冲区。
在Redis2.8以后,使用psync命令代替sync命令来执行复制的同步操作,psync命令具有完整同步和部分重同步两种模式。
完整同步
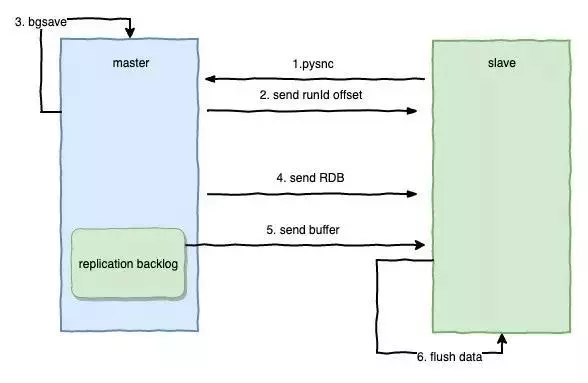
完整同步用于处理初次复制情况,完整重同步的执行步骤与sync命令的执行步骤一直,都是通过让主服务器创建并发送RDB文件,以及向从服务器发送保存在缓冲区的写命令来进行同步。
1.slave发送psync命令给master,由于是第一次发送,不带上runID和offset。
2.master接收到请求,发送master的runID和offset给从节点。
3.master生成保存RDB文件。
4.master发送RDB文件给slave。
5.在发送RDB这个操作的同时,写操作会赋值到缓冲区Replication Backlog Buffer中,并从Buffer区发送到slave。
6.slave将RDB文件的数据装载,并更新自身的数据。
如果网络的抖动或者是短时间的断连也需要进行完整的同步就会导致大量的资源开销,这些开销包括了bgsave的时间、RDB文件传输的时间、slave重新加载RDB的时间。如果salve有AOF(Append Only File),还会导致AOF重写。
部分重同步
部分重同步是用于处理断线后重新连接主服务器时,主服务器可以将主从服务器连接断开期间执行的写命令发送给从服务器,从服务器只要接受并执行这些写命令,就可以将数据库更新至主服务器当前所处的状态。

1.网络发生错误,master与slave失去连接。
2.master依然向buffer缓冲区写入数据。
3.slave重新连接上master。
4.slave向master发送自己目前的runID和offset。
5.master判断slave发送给自己的offset是否存在buffer队列中。如果存在,则发送continue给slave;如果不存在,意味着可能偏差了太多的数据,缓冲区已经清空,这个时候就需要重新进行全量的复制。
6.master发送从offset偏移后的缓冲区数据给slave。
7.slave获取数据更新自身数据。
"总不能用一身的刺去拥抱无辜的人,认识就够了,何必谈余生。"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号