流量削峰
如果你看过秒杀系统的流量监控图的话,你会发现它是一条直线,就在秒杀开始的那一秒是一条很直很直的直线,这时因为秒杀请求在时间上高度集中于某一个特定的时间点。这样一来,就会导致一个特别高的流量峰值,它对资源的消耗是瞬时的。
对于秒杀这个场景来说,最终能够抢购到商品的人数是固定的。也就是说,100个人和1000000个人发起请求的结果都是一样的,最后都只会有100个人买到秒杀的商品。这就意味着,并发量越高,最终的无效请求也就越多。
但是对于业务来说,秒杀活动本身是一种商业推广行为,肯定是希望有更多的人参与进来的。无效的请求越多,也就表示这商业推广越成功。只是在秒杀开始的时候,这些大量的秒杀请求就会给承载秒杀的服务器带来沉重的负担,因此我们可以设计一些规则,让并发的请求延缓或过滤掉这些无效请求,以此来削弱流量高峰对服务器的压力,这就是流量削峰。
为什么要削峰
我们知道,服务器的处理资源是恒定的,你用或者不用,它就在原地,处理能力不会改变。所以出现峰值的话,就很容易会导致忙到处理不过来,虽然闲的时候也会没什么要处理。但是为了保证服务质量,很多处理资源只能够按照忙的时候来预估,而这样就会导致资源的浪费。
流量削峰就好比因为存在早高峰和晚高峰的问题,所以有了错峰限行的解决方案。
削峰的存在,一是可以让服务端处理变得平稳,二是可以节省服务器的资源成本。
针对秒杀这一场景,削峰从本质上来说就是更多地去延缓用户发出的请求,以便减少和过滤掉一些无效的请求,它遵从【请求数要尽量少】的原则。
流量削峰主要有三种操作思路,一是排队,二是答题,三是分层过滤,这三种方式都是无损(即不会损失用户的请求发出)的实现方案。当然,还有些有损的实现方案,包括后面要介绍的关于稳定性的一些方法,比如限流和机器负载保护等一些强制措施也能达到削峰保护的目的,只是这些都是一些不得已的措施。
排队
要对流量进行削峰,最容易想到的解决方案就是用消息队列来缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,另一端平滑地将消息推送出去。在这里,消息队列就像一个水库一样,拦截上游的洪水,削减进入下游河道的洪峰流量,从而达到减免洪水灾害的目的。
使用消息队列来缓冲瞬时流量的方案,如下图所示:
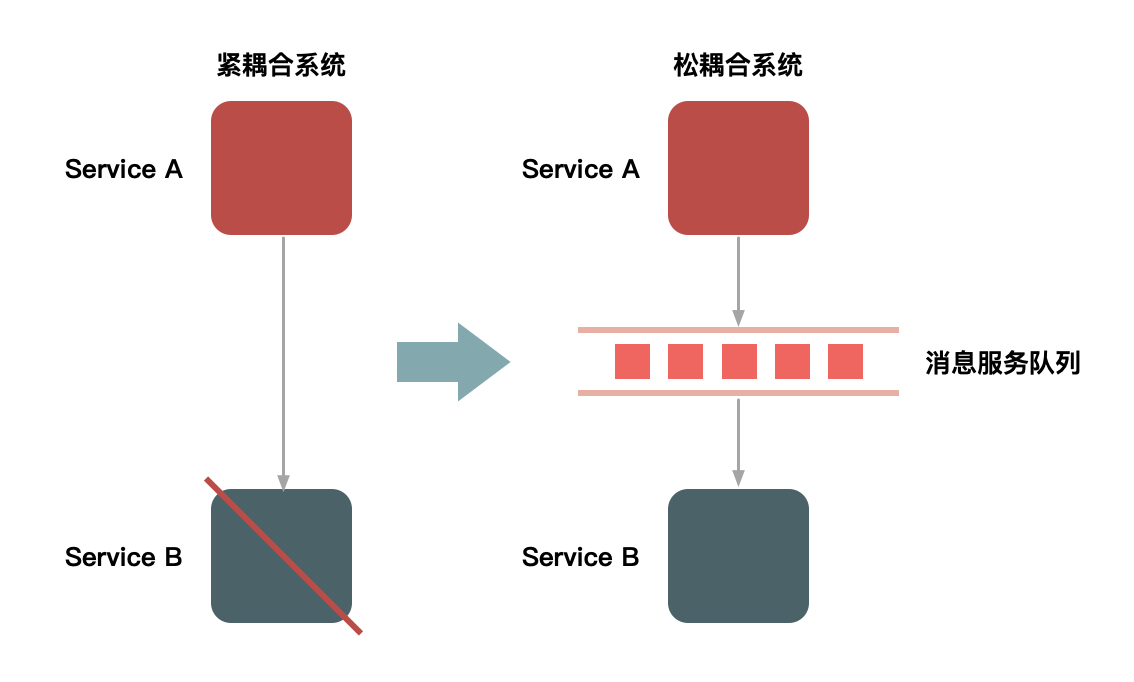
但是,如果流量峰值持续一段时间后,达到了消息队列的处理上限,比如本机的消息积压达到了存储空间的上线,消息队列同样也会被压垮。虽然这样能保护下游的系统,但是和直接把请求丢弃没有多大区别。就像遇到洪水爆发的时候,即使是有水库也无济于事。
而除了消息队列,类似的排队方式还有很多,比如
1.利用线程池加锁等待也是一种常用的排队方式。
2.先进先出、先进后出等常用的内存排队算法的实现方式。
3.把请求序列化到文件中,然后再顺序地读文件(例如基于MySQL binlog的同步机制)来恢复请求等方式。
可以看到,这些方式都有一个共同特征,就是把一步的操作变成了两步的操作,其中增加的一步操作起到缓冲的作用。
但是,因为多加了一层缓冲,就增加了访问请求的路径。虽然看起来不太合理,但是如果不增加这个缓冲的步骤,在一些场景下系统就很容易直接奔溃,不符合系统高可用的设计,所以系统设计需要做到妥协和平衡。
答题
最早期的秒杀,只是纯粹地刷新页面和点击购买按钮,后来则加上了答题功能。

加上答题功能,是为了增加购买的复杂度,从而达到两个目的。
第一个目的是防止部分买家在参加秒杀的时候使用秒杀器作弊。在2011年秒杀非常火的时候,秒杀器也比较猖獗,因而并没有达到全民参与和营销推广的目的,所以系统就增加了答题功能来限制秒杀器。在增加了答题功能后,下单的时间基本控制在2s后,秒杀器的下单比例也大大下降。
第二个目的是为了延缓请求,起到对请求流量进行削峰的作用,从而使系统能够更好地支持瞬时的流量高峰。这个重要的功能就是把峰值的下单请求拉长,从先前的1s之内延长到2s~10s。这样一来,请求峰值就基于时间分片了。这个时间的分片对服务端处理并发非常重要,会大大减轻压力。而且由于请求具有先后顺序,靠后的请求到来时自然就没有库存了,因此根本到不了最后的下单步骤,所以真正的并发写就非常有限了。这种设计思路目前用得非常普遍,如支付宝的【咻一咻】和微信【摇一摇】,都是类似的方式。
这里要重点说一下秒杀答题的设计思路,看下图:
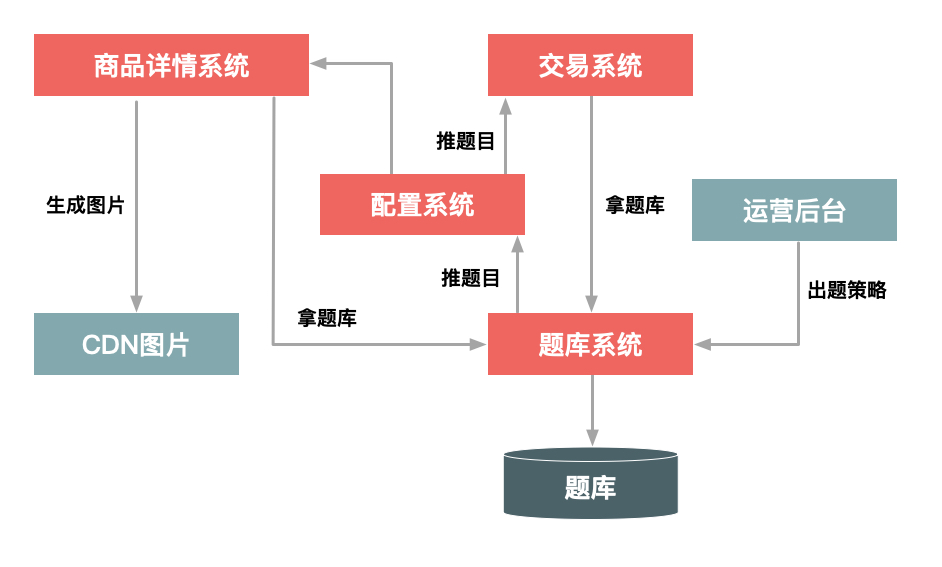
整个秒杀答题功能的逻辑,主要可以分为3个部分。
1.题库生成模块。这个部分主要就是生成一个个问题和答案,题目和答案本身都不需要太复杂,重要的能防止由机器来算出结果,防止秒杀器答题。
2.题库推送模块。这个部分用于在秒杀答题前,把题目提前推送给详情系统和交易系统。实时推送是为了保证每次用户请求的题目是唯一的,防止答题作弊。
3.题目的图片生成模块,用于把题目生成为图片格式,并且在图片里增加一些干扰因素。这也同样是为了防止机器直接来答题,它要求只有人才能理解题目本身的含义。这里还要注意一点,由于答题时网络比较拥挤,应该把题目的图片提前推送到CDN上并且要进行预热,不然的话当用户真正请求题目时,图片可能加载比较慢,从而影响答题的体验。
事实上,真正答题的逻辑是比较简单的,比较容易理解。只要将用户提交的答案与题目对应的答案做比较,比较通过则继续进行下一步逻辑,否则就失败。

要注意的是,这里面的验证逻辑,除了验证问题的答案之外,还包括用户本身身份的验证,例如是否已经登陆、用户的Cookie是否完整、用户是否重复频繁提交等。
更多的,除了做正确性校验之外,还可以对提交答案的时间做限制。例如从开始答题到接收答案的时间要超过1s,因为1s是认为操作的可能性很小,这样也能防止机器答题的问题。
分层过滤
前面介绍的排队和答题,要么是在接收请求时做缓冲,要么是减少请求的同时发送,而针对秒杀场景还有一种方法,就是对请求进行分层过滤,从而过滤掉一些无效的请求。分层过滤其实就是采用【漏斗】式的设计来处理请求。

假如请求分别经过CDN、前台读系统(如商品详情系统)、后台系统(如交易系统)和数据库这层,那么,大部分数据和流量在用户浏览器或CDN上获取,这一层可以拦截大部分数据的读取;经过第二层(即前台系统)时,数据(包括强一致性的数据)都尽量走Cache,过滤一些无效的请求;再到第三层的后台系统,主要做数据的二次校验,对系统做好保护和限流,这样数据量和请求就进一步减少;最后在数据层完成数据的强一致性校验就好了。
这样的话,就像漏斗一样,尽量把数据量和请求量一层一层地过滤和减少。
分层过滤的核心思想是在不同的层次尽可能地过滤掉无效的请求,让漏斗最末端的才是有效请求。而要达到这种效果,我们就必须对数据做分层的校验。
分层校验的基本原则是:
1.将动态请求的读数据缓存(Cache)在Web端,过滤掉无效的数据读取。
2.对读数据不做强一致性校验,减少因为一致性校验产生性能瓶颈的问题。
3.对写数据进行基于时间的合理分片,过滤掉过期的失效请求。
4.对写请求做限流保护,将超出系统承载能力的请求过滤掉。
5.对写数据进行强一致性校验,只保留最后有效的数据。
分层校验的目的是在读系统中尽量减少由于一致性校验带来的系统瓶颈,但是尽量将不影响性能的检查条件提前,比如用户是否具有秒杀资格、商品状态是否正常、用户答题是否正确、秒杀是否已经结束、是否非法请求、营销等价物是否充足等。而在写数据系统中,主要对写的数据(如库存)做一致性检查,最后在数据库层保证数据的最终准确性(如库存不能为负数)。
总结
上面的内容介绍了如何在网站面临大流量冲击时进行请求的削峰,并主要介绍了流量削峰的3种处理方式:
1.通过队列来缓冲请求,即控制请求的发出。
2.通过答题来延长请求发出的时间,在请求发出后承接请求时进行控制,最后再对不符合条件的请求进行过滤。
3.对请求进行分层过滤,一层一层过滤掉无效请求,使最后到达的有效请求少。
其中,队列缓冲方式更加通用,它适用于内部上下游系统之间调用请求不平缓的场景,由于内部系统的服务质量要求不能随意丢弃请求,所以使用消息队列能起到很好的削峰和缓冲作用。
而答题更适用于秒杀或者营销活动等应用场景,在请求发起端就控制发起请求的速度,因为越到后面无效请求也会越多,所以配合后面介绍的分层拦截的方式,可以更进一步减少无效请求对系统资源的消耗。
分层过滤非常适合交易性的写请求,比如减库存或者拼车这种场景,在读的时候需要知道还有没有库存或者是否还有剩余空座位。但是由于库存和座位是不停变化的,所以读的数据是否一定要非常准确吗?其实不一定,你可以放一些请求过去,然后在真正减的时候再做强一致性保证,这样既过滤一些请求又解决了强一致性读的瓶颈。
另外,在削峰的处理方式上除了采用技术手段,其实还可以采用业务手段来达到一定效果,例如在零点开启大促的时候由于流量太大导致支付系统阻塞,这个时候可以采用发放优惠券、发起抽奖活动等方式,将一部分流量分散到其他地方,这样也能起到缓冲流量的作用。
"有些人离开不用说再见,有些事不开口也明白。"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号