8-网页,网站,微信公众号基础入门(使用Python程序实现微信token验证)
https://www.cnblogs.com/yangfengwu/p/11062034.html


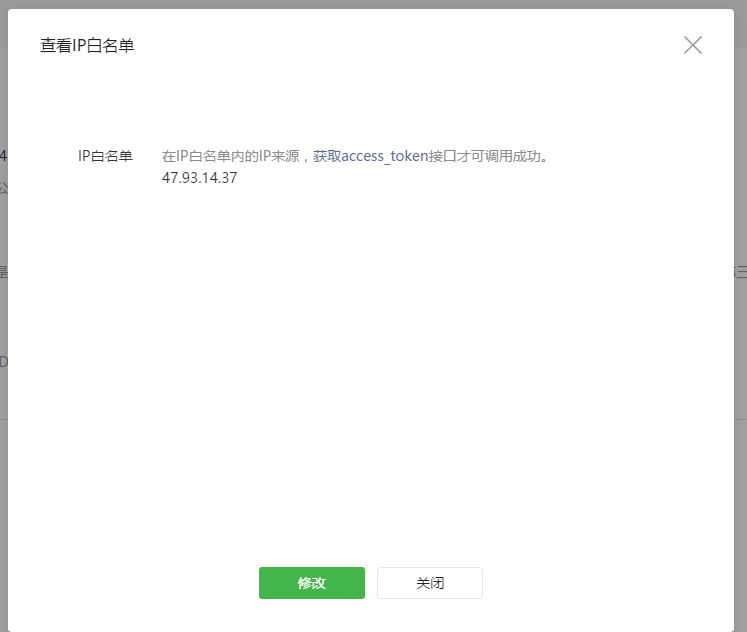
设置一下IP白名单: 填写自己的服务器的IP地址
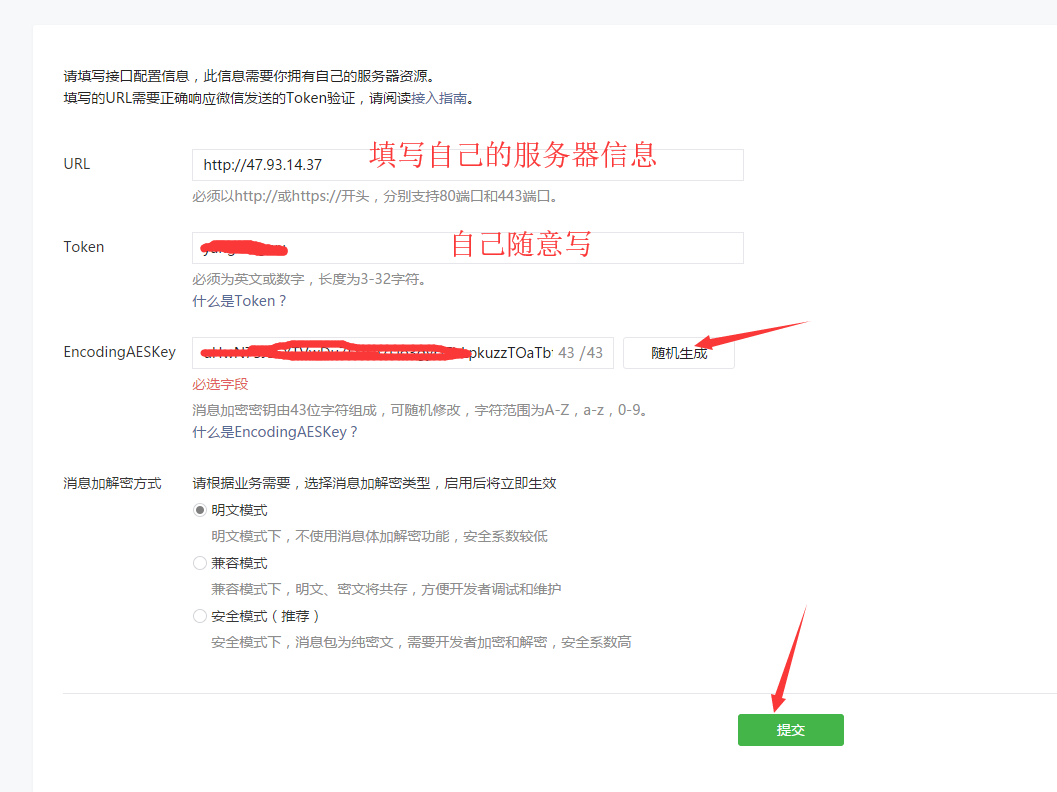
是不是不可以哈,有多少人都会入这个坑........官方呀,,,唉
https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1472017492_58YV5

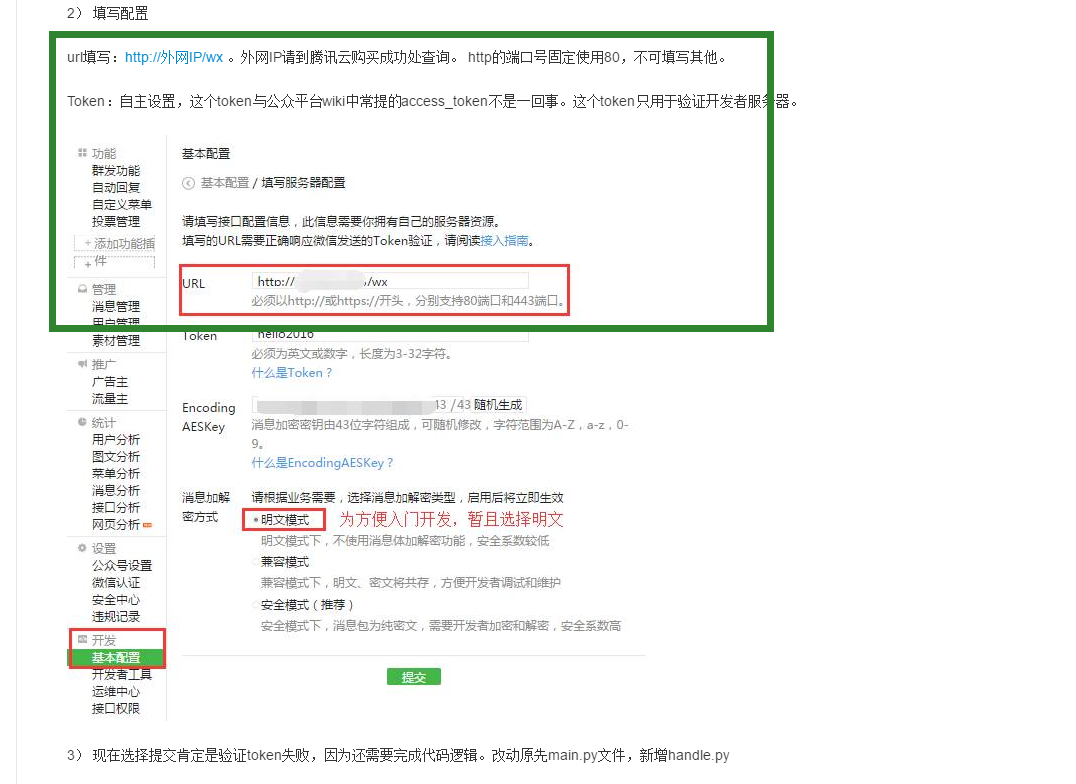
他是说,你这个
不是直接随意写个就完了,,他是会用http访问你里面的内容,你内容里面写的Token要和你网页上写的一样,然后返回给它,这样的话就OK了
所以需要自己在服务器上写一些程序
官方给了python 的参考程序
因为咱在数据篇的时候已经用了python 了,所以咱先用python 实现,然后呢,咱再用php实现
https://www.cnblogs.com/yangfengwu/category/1410242.html
前面准备了这么多知识,现在正在一点点的使用起来...整个教程真是不太好搞,,,涉及的真是太多,我在做教程之前花费了好多时间去总结......
然后才有了基础篇,升级篇,数据篇,安全篇,最后才是微信小程序篇.
总是有人给我抱怨说,为什么没有一篇直接先安装整个用到的东西的,我总会说,你直接看视频教程一节一节的看就可以,每一节用到的所有东西都放在了每一节视频教程里面.
我的教程涉及的太多太多,我这样子做是最好的方式了.
对了还有一件事情: 我对于我自己的学习能力是完全肯定的,只不过是经过长期(2~3年)的自学,形成了我现在的自学能力(学习知识的思维)..以前我从来都没有想过为什么我学一样东西总是那么的快,我以前还认为只有经过长时间的自学才能形成惊人的自学能力 , 后来偶尔读了一篇文章,我才知道我为什么学东西又快又好...原来确实有规律可寻,只不过我是长时间潜移默化形成的这种学习思维......
这是以前我写的一篇日记
https://www.cnblogs.com/yangfengwu/p/11062408.html
先说一下我学东西哈:我每学一个知识点,都会力求让自己给自己讲明白这个知识点,如果给自己讲不明白,就再接着看这个知识点,然后就是一直循环,直至自己给自己说,我确确实实完全明白了这个知识点...我大学里面大二以后都是这样自学过来的..孤独,煎熬,痛苦,但会一直坚持着,因为....我也不知道为什么我能一直坚持下去,当所有人都不认可我的时候,当很多人都不看好我的时候,当很多人开始嘲讽我的时候......我越是那么的坚持....算了,都是些陈年往事
大家百度下 费曼学习法 世界公认最好的学习法 我是100%认同的
https://jingyan.baidu.com/article/4ae03de3cf103c3eff9e6bb6.html
好了,,接着说
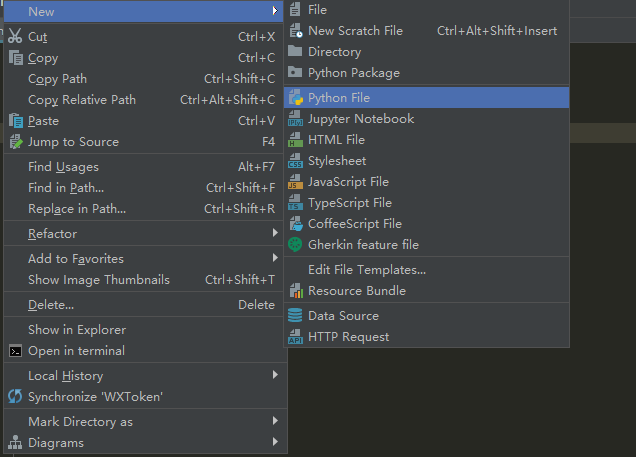
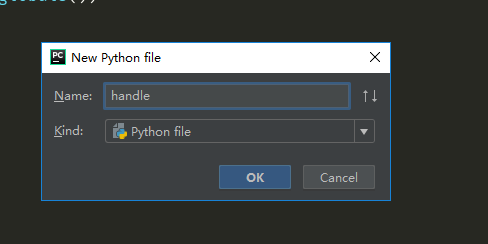
咱打开咱数据篇开发python的软件,新建一个工程,把官方给的例子复制过去
实际上就是用python实现的Web服务器,然后如果收到get指令,解析一下微信get指令(就是咱点击提交的时候微信自己给咱发的get信息,get的地址就是咱上面填写的地址)里面携带的信息,然后返回信息...完了

可以按照官方的来,,新建一个main.py 用来测试Web服务器是不是可以

咱让软件安装一下Web模块...可以参考数据篇的 https://www.bilibili.com/video/av55668802
还有就是这个 https://www.cnblogs.com/yangfengwu/p/10177261.html
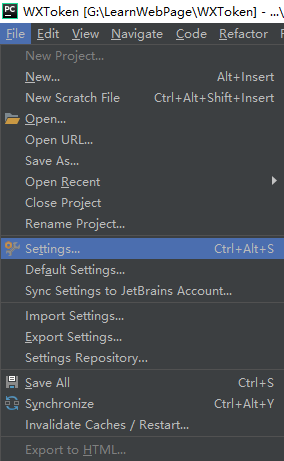
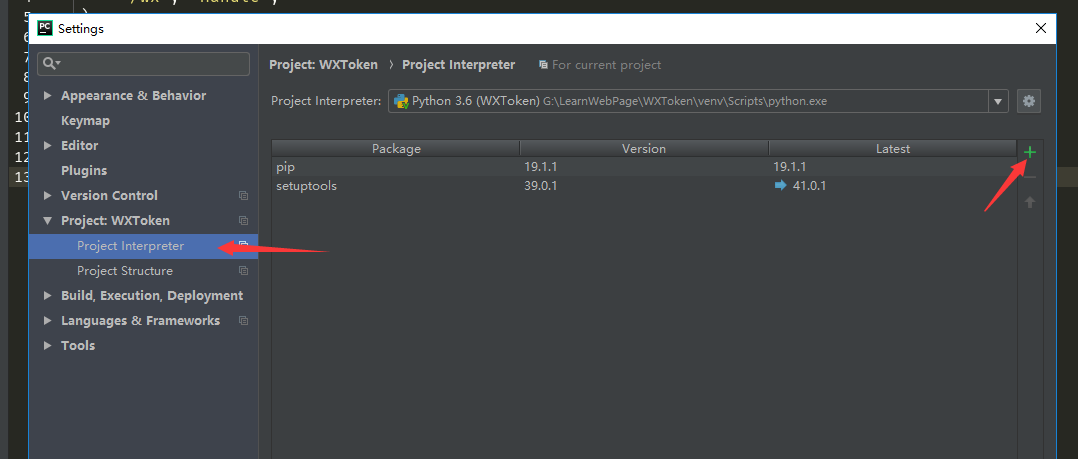

安装失败了
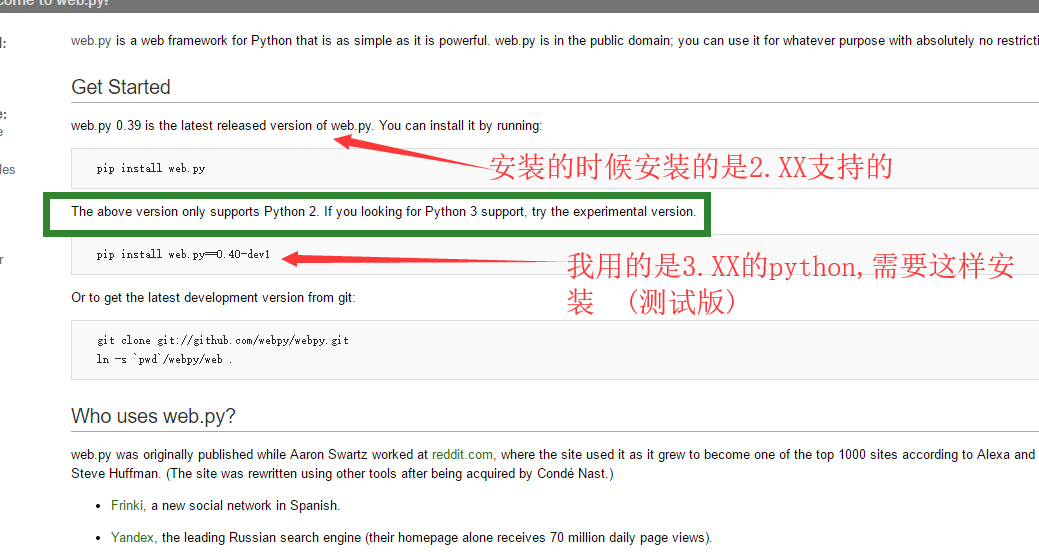
在pycharm界面按alt+F12调出命令行窗口

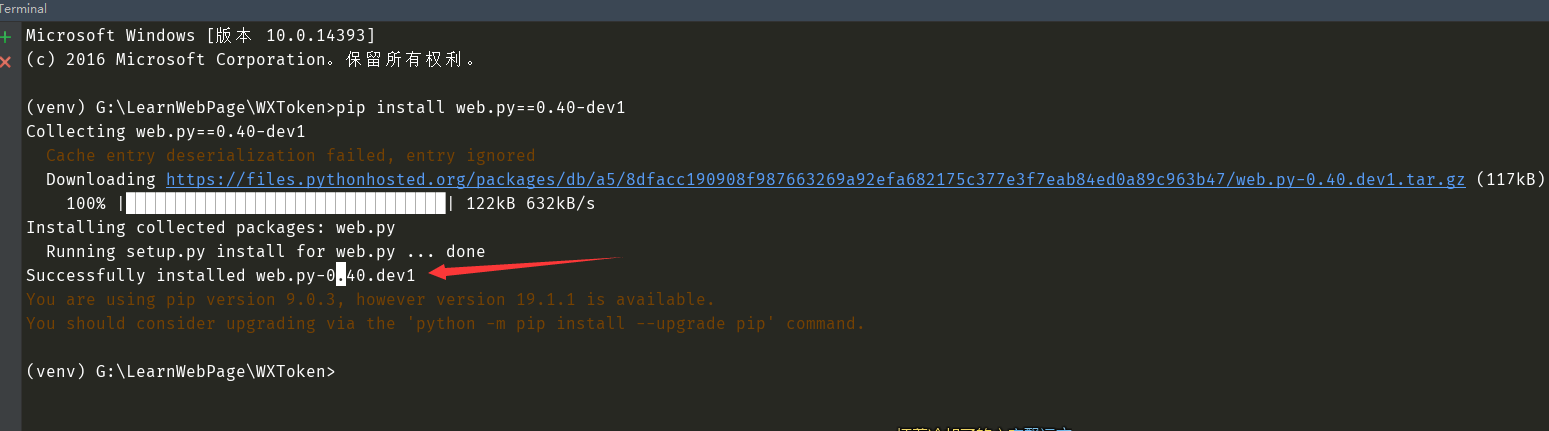
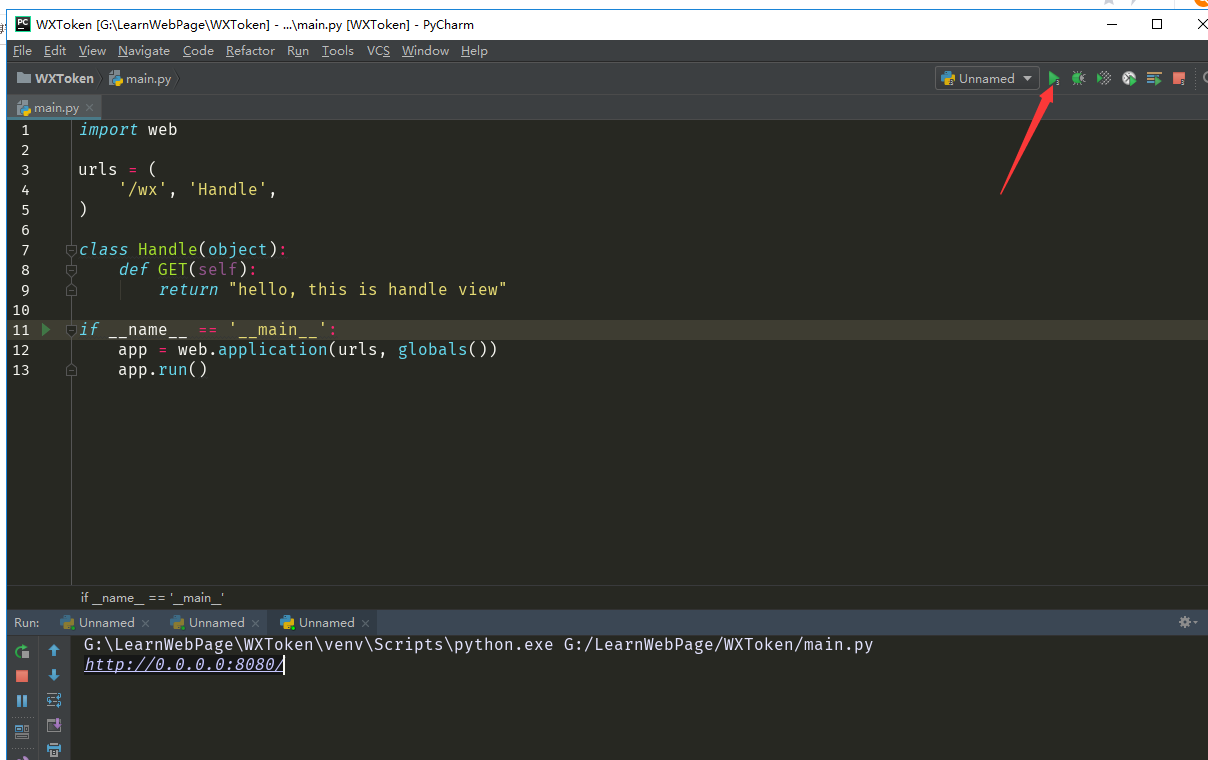
具体看 http://webpy.org/docs/0.3/tutorial
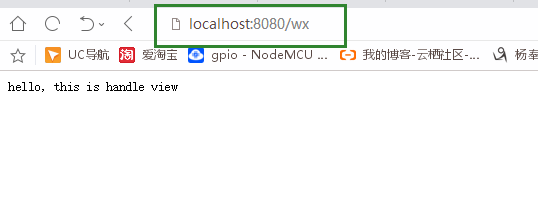
这样就证明可以了 , 这个程序是可用的
然后接着写
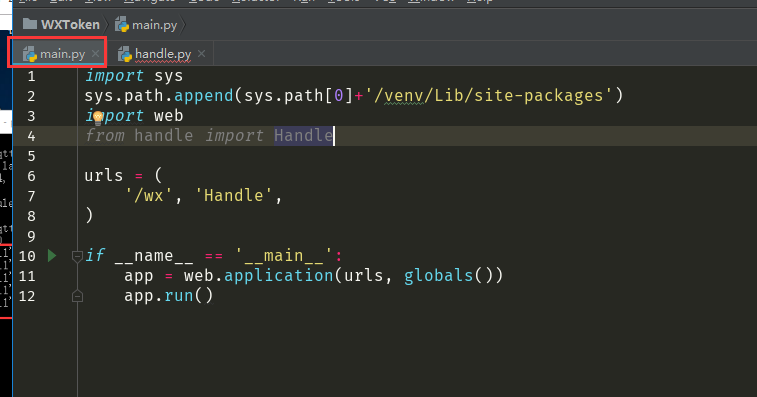
import sys sys.path.append(sys.path[0]+'/venv/Lib/site-packages') import web from handle import Handle urls = ( '/wx', 'Handle', ) if __name__ == '__main__': app = web.application(urls, globals()) app.run()
版本问题报了个错
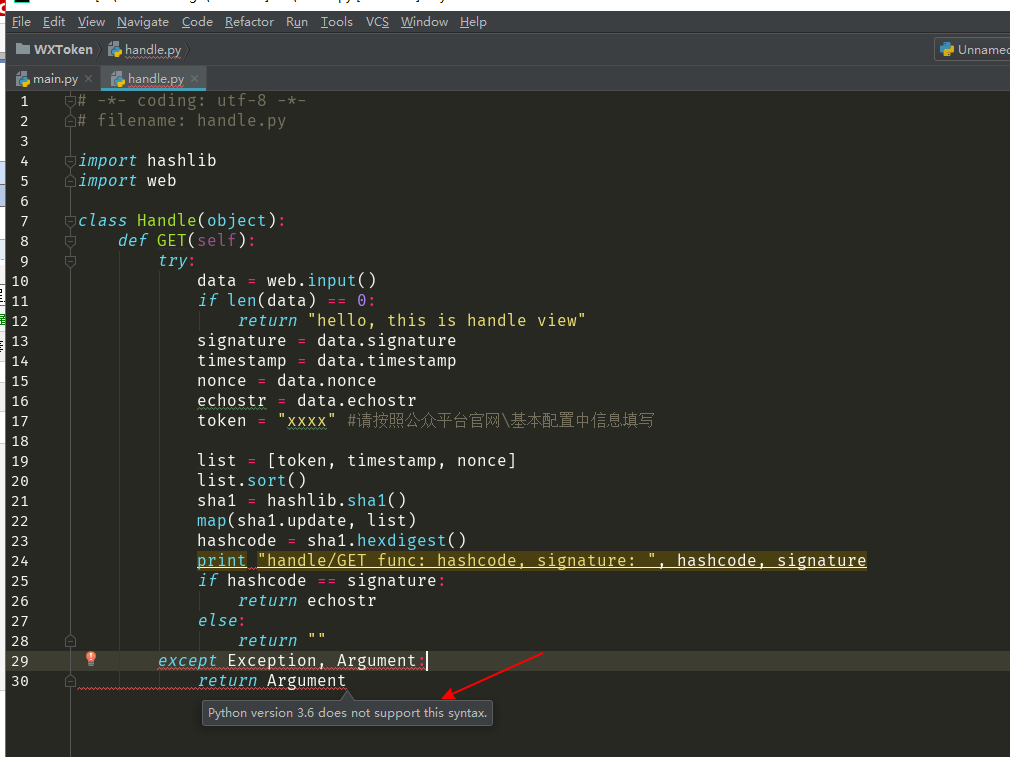
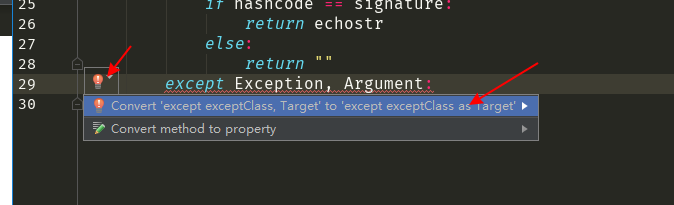
3.6版本的还有个地方
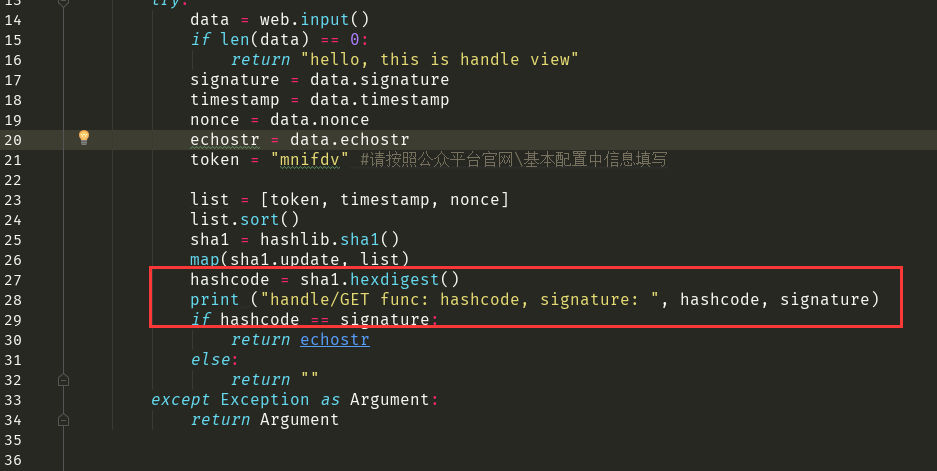
需要加括号
但是还有问题...导入不了这个模块
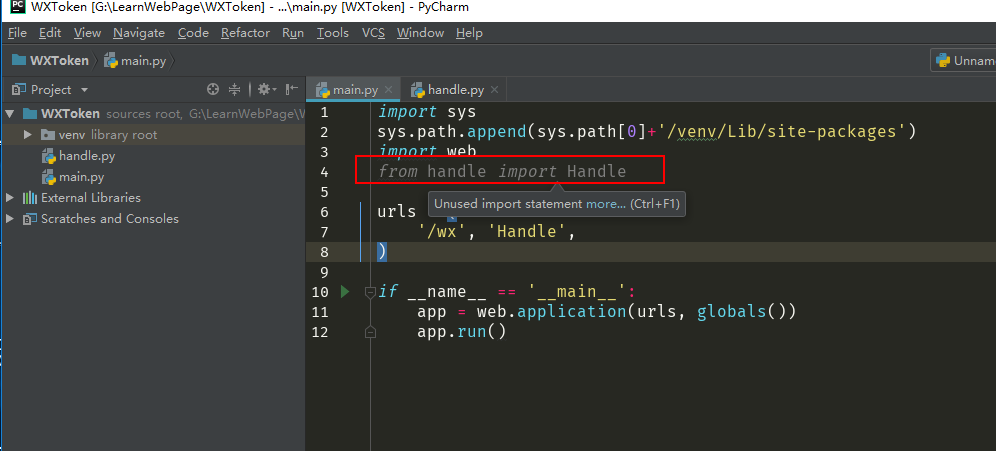
....先不找解决方案,我就来个直接的
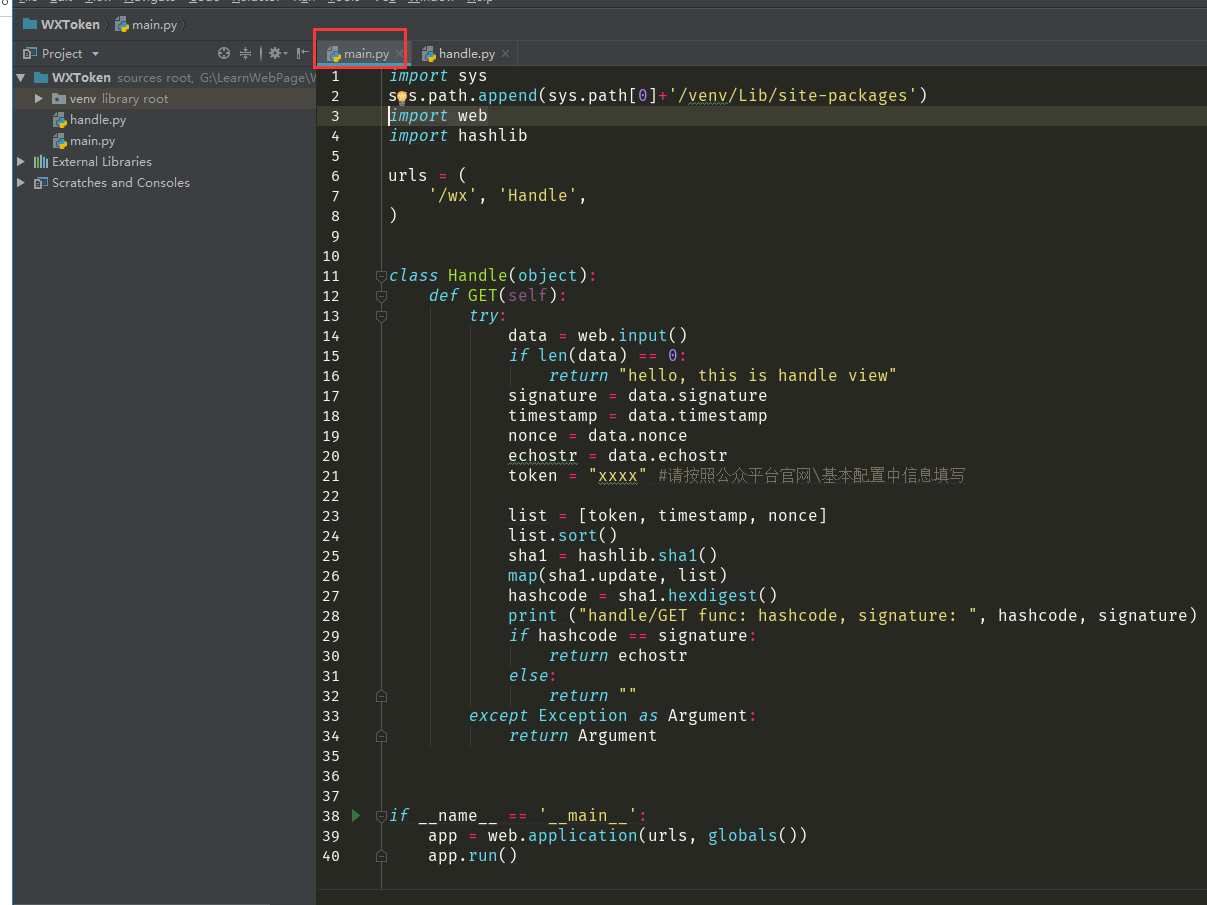
import sys sys.path.append(sys.path[0]+'/venv/Lib/site-packages') import web import hashlib urls = ( '/wx', 'Handle', ) class Handle(object): def GET(self): try: data = web.input() if len(data) == 0: return "hello, this is handle view" signature = data.signature timestamp = data.timestamp nonce = data.nonce echostr = data.echostr token = "xxxx" #请按照公众平台官网\基本配置中信息填写 list = [token, timestamp, nonce] list.sort() sha1 = hashlib.sha1() map(sha1.update, list) hashcode = sha1.hexdigest() print ("handle/GET func: hashcode, signature: ", hashcode, signature) if hashcode == signature: return echostr else: return "" except Exception as Argument: return Argument if __name__ == '__main__': app = web.application(urls, globals()) app.run()
还有一点

然后把工程放到云端去,最好先压缩再上传,否则会比较慢
记得关掉以前的

报错了
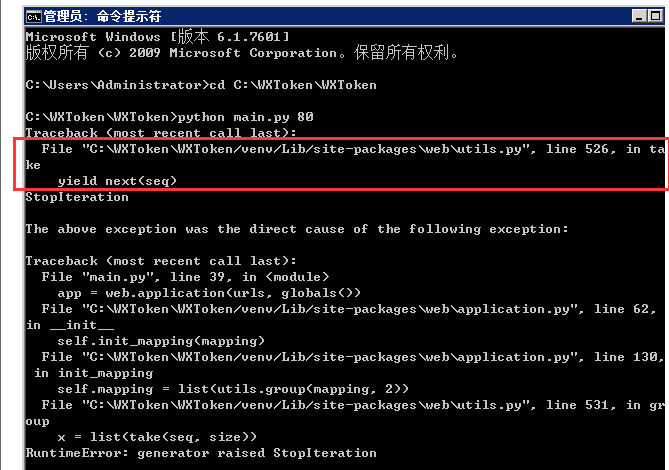
最好用软件打开修改,,,否则有可能由于别的记事本文件的编码和缩进问题造成代码看着没有问题,实质上内部编码上就是有问题
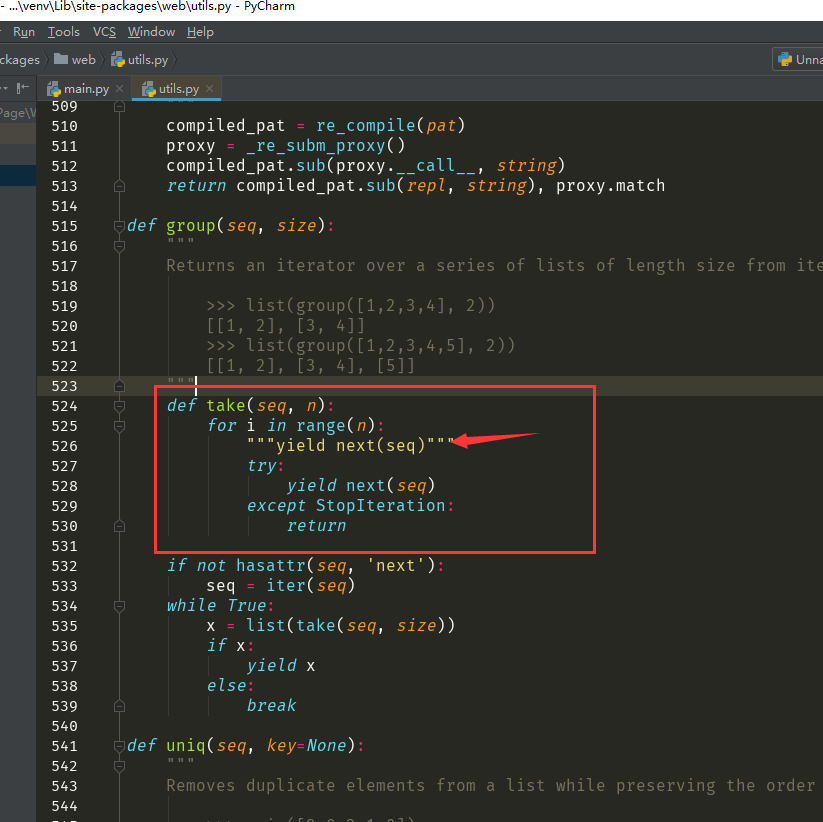
把原来的
yield next(seq)
改为
try:
yield next(seq)
except StopIteration:
return
注意一下缩进
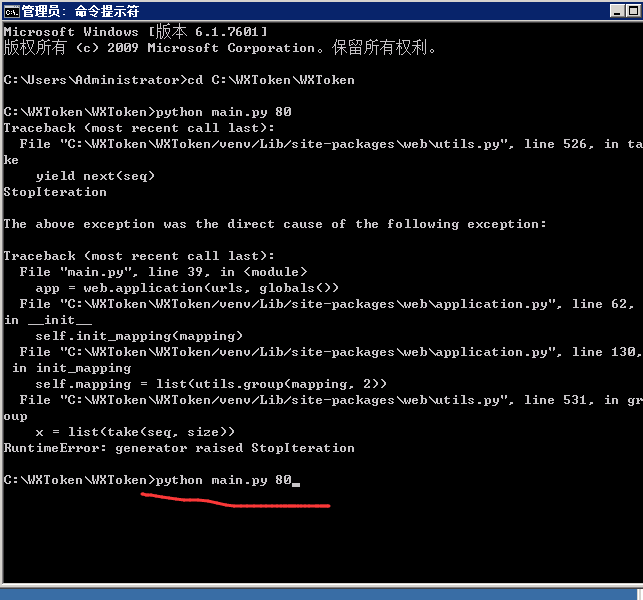
如果还有问题,自己先在自己电脑本地修改测试,然后再放到云端
然后
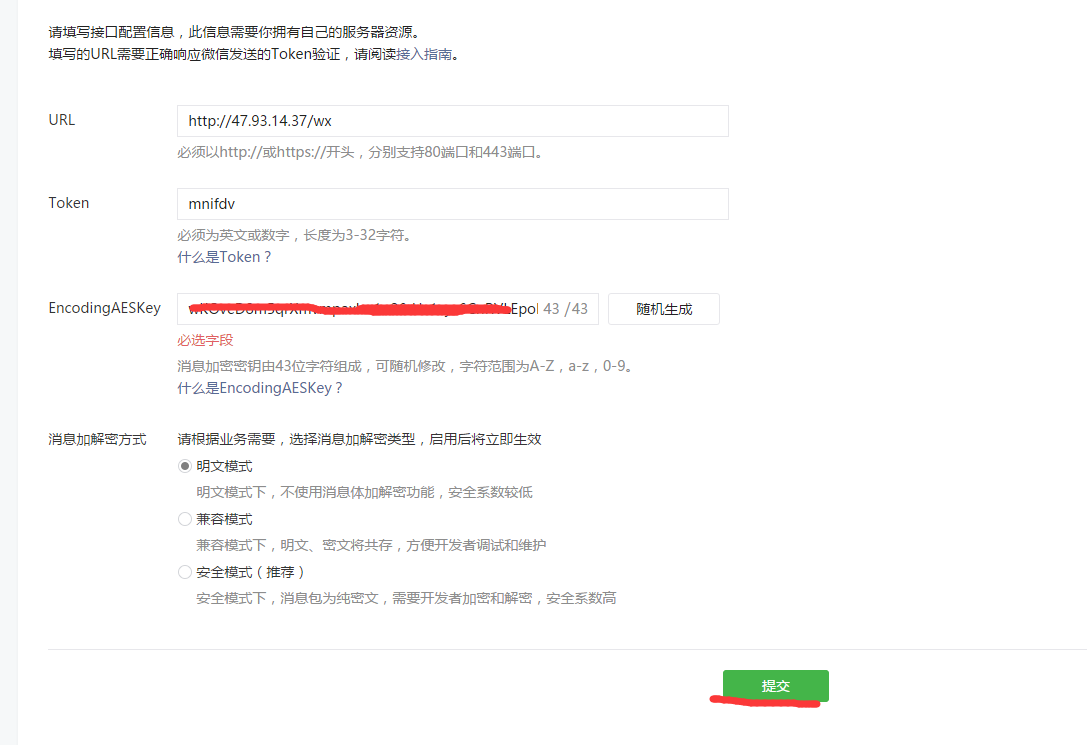
还是有问题

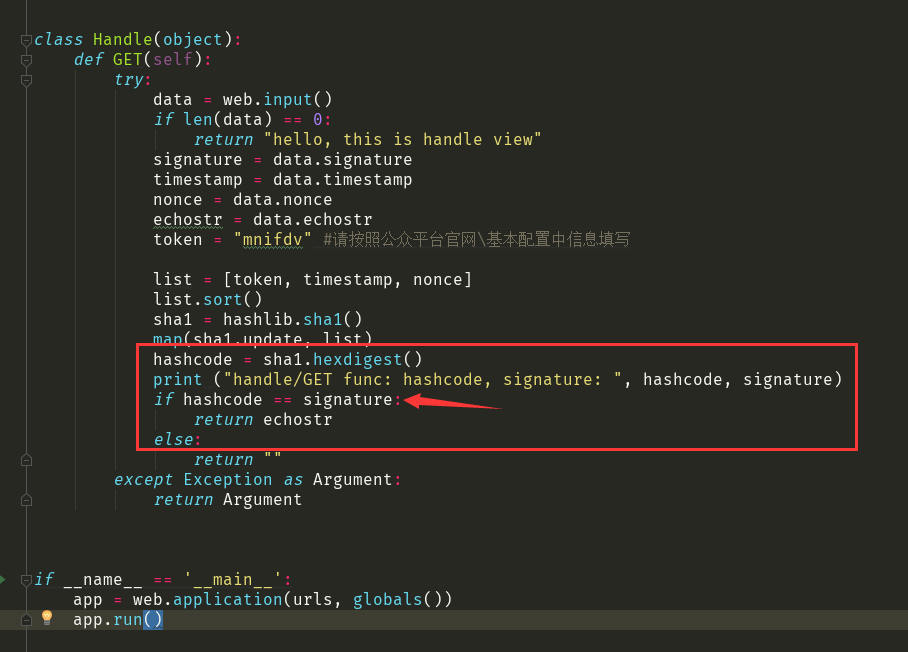
计算出来的两个值不一样......................
handle/GET func: hashcode,signature: da39a3ee5e6b4b0d3255bfef95601890afd80709
494b4ed79eb454e574421526b8a053799075299f
223.166.222.112:49585 - - [21/Jun/2019 07:54:58] "HTTP/1.1 GET /wx" - 200 OK
hashcode = da39a3ee5e6b4b0d3255bfef95601890afd80709
signature = 494b4ed79eb454e574421526b8a053799075299f
......我再找找原因
可以了,不过需要修改下代码
修改了一下代码
import sys sys.path.append(sys.path[0]+'/venv/Lib/site-packages') import web import hashlib urls = ( '/wx', 'Handle', ) class Handle(object): def GET(self): try: wechat_data = web.input() signature = wechat_data['signature'] timestamp = wechat_data['timestamp'] nonce = wechat_data['nonce'] echostr = wechat_data['echostr'] token = 'mnifdv' check_list = [token, timestamp, nonce] check_list.sort() s1 = hashlib.sha1() s1.update(''.join(check_list).encode()) hashcode = s1.hexdigest() print("handle/GET func: hashcode, signature:{0} {1}".format(hashcode, signature)) if hashcode == signature: return echostr else: return "" except Exception as Argument: return Argument """ class Handle(object): def GET(self): try: data = web.input() if len(data) == 0: return "hello, this is handle view" signature = data.signature timestamp = data.timestamp nonce = data.nonce echostr = data.echostr token = "mnifdv" #请按照公众平台官网\基本配置中信息填写 list = [token, timestamp, nonce] list.sort() sha1 = hashlib.sha1() map(sha1.update, list) hashcode = sha1.hexdigest() print("signature=%s\r\n", signature) print("timestamp=%s\r\n", timestamp) print("nonce=%s\r\n", nonce) print("echostr=%s\r\n", echostr) print("hashcode=%s\r\n", hashcode) if hashcode == signature: return echostr else: return "" except Exception as Argument: return Argument """ if __name__ == '__main__': app = web.application(urls, globals()) app.run()
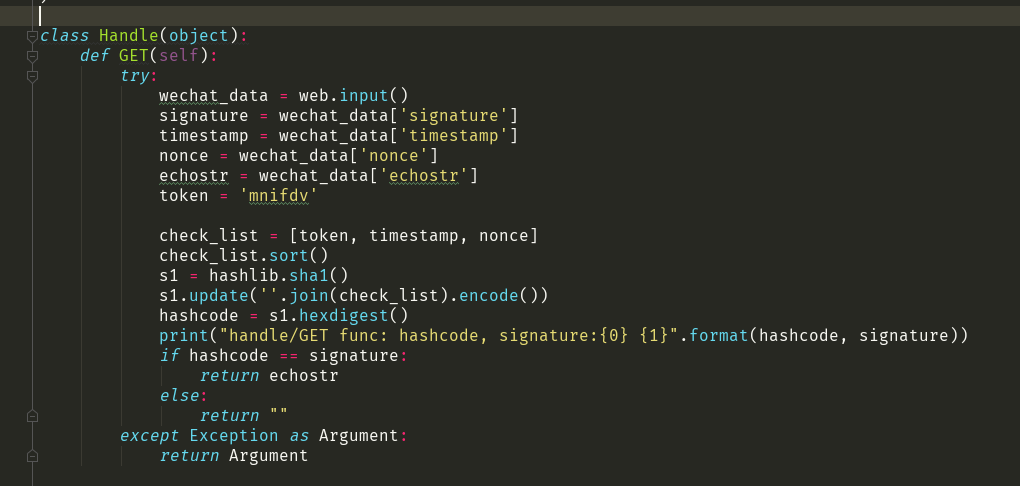
其实我是直接百度的 微信token验证 python 因为我看了程序,实质就是微信会先用hash 通过
token, timestamp, nonce 用 hash 算出来 signature
咱也用他的算法,算出来 hashcode 然后比较一下两个一不一样...如果一样就返回 echostr
因为就是这样算的...所以如果算不对,肯定是程序哪地方获取数据的方式,或者计算时候的一些小细节影响了计算数据...
别人呢一定研究过,碰到过类似的问题,所以直接百度就好
替换掉原来的main.py

https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.3e3b1deb80xzYz&id=569295486025
好了,这节先自己消化,下一节 咱用php实现
https://www.cnblogs.com/yangfengwu/p/11066036.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号
