高并发秒杀应用:高并发优化
概要
我经过一个多星期的学习和总结,这个高并发的秒杀应用功能上已经完全实现,也能够正常运行。如下:

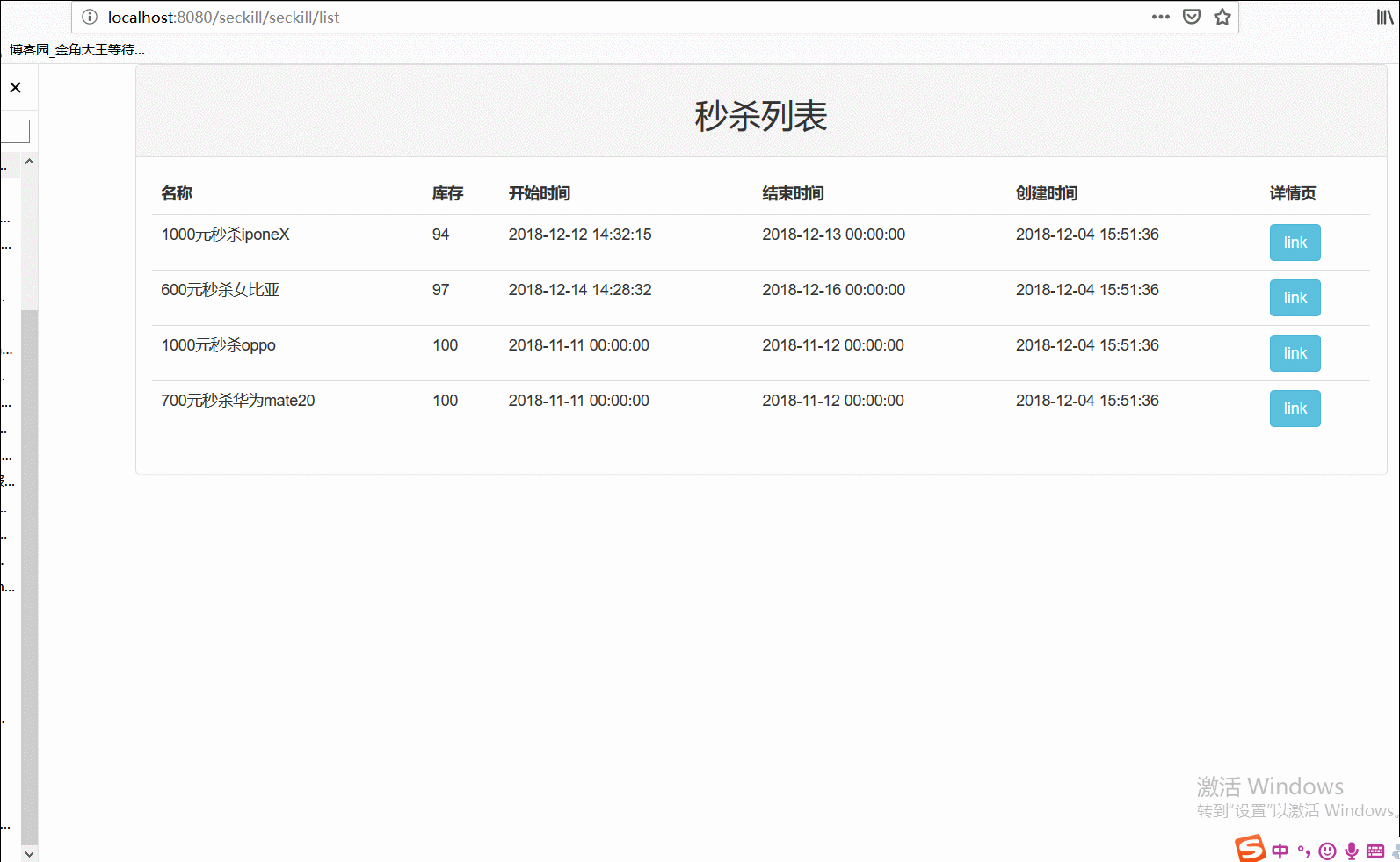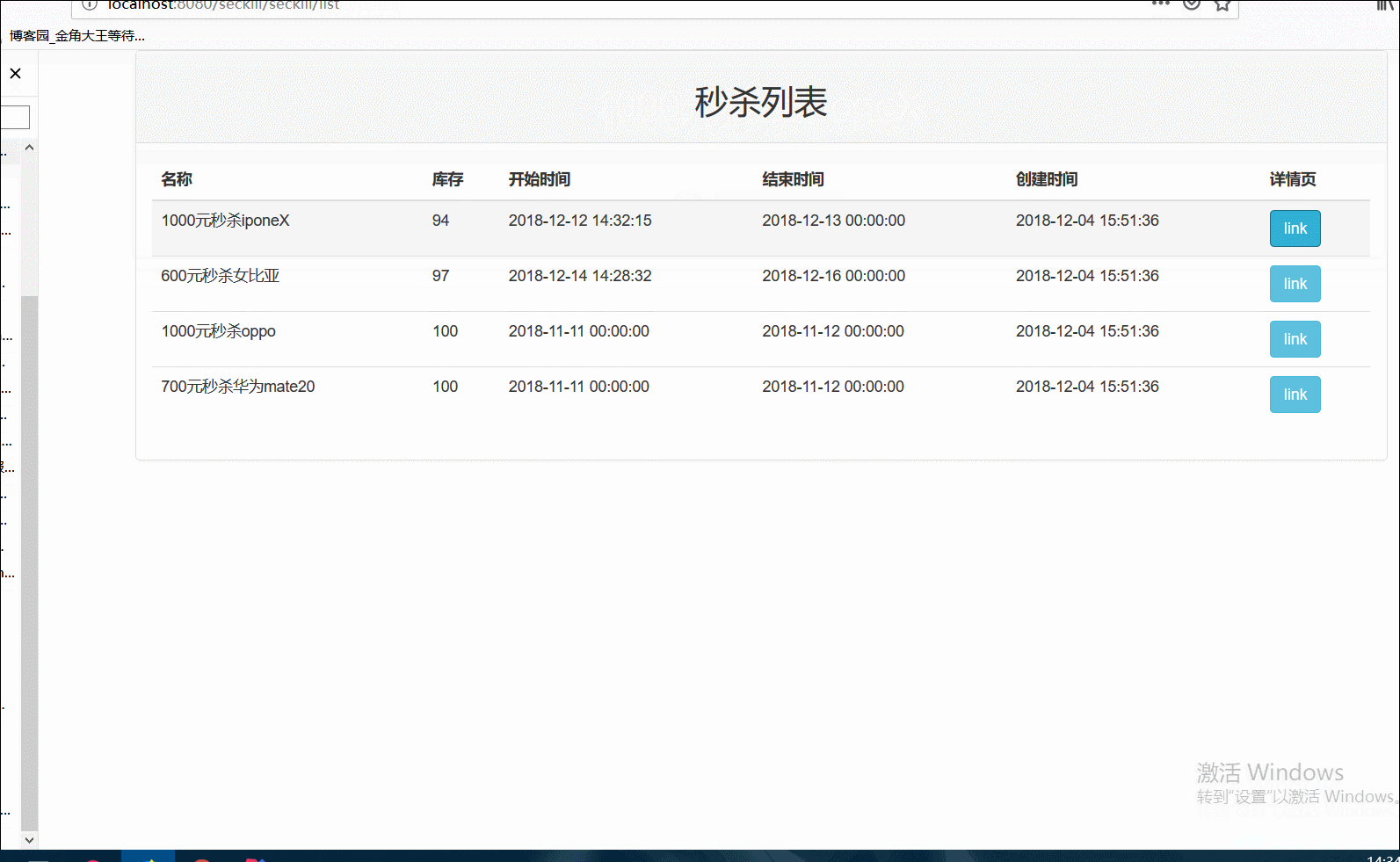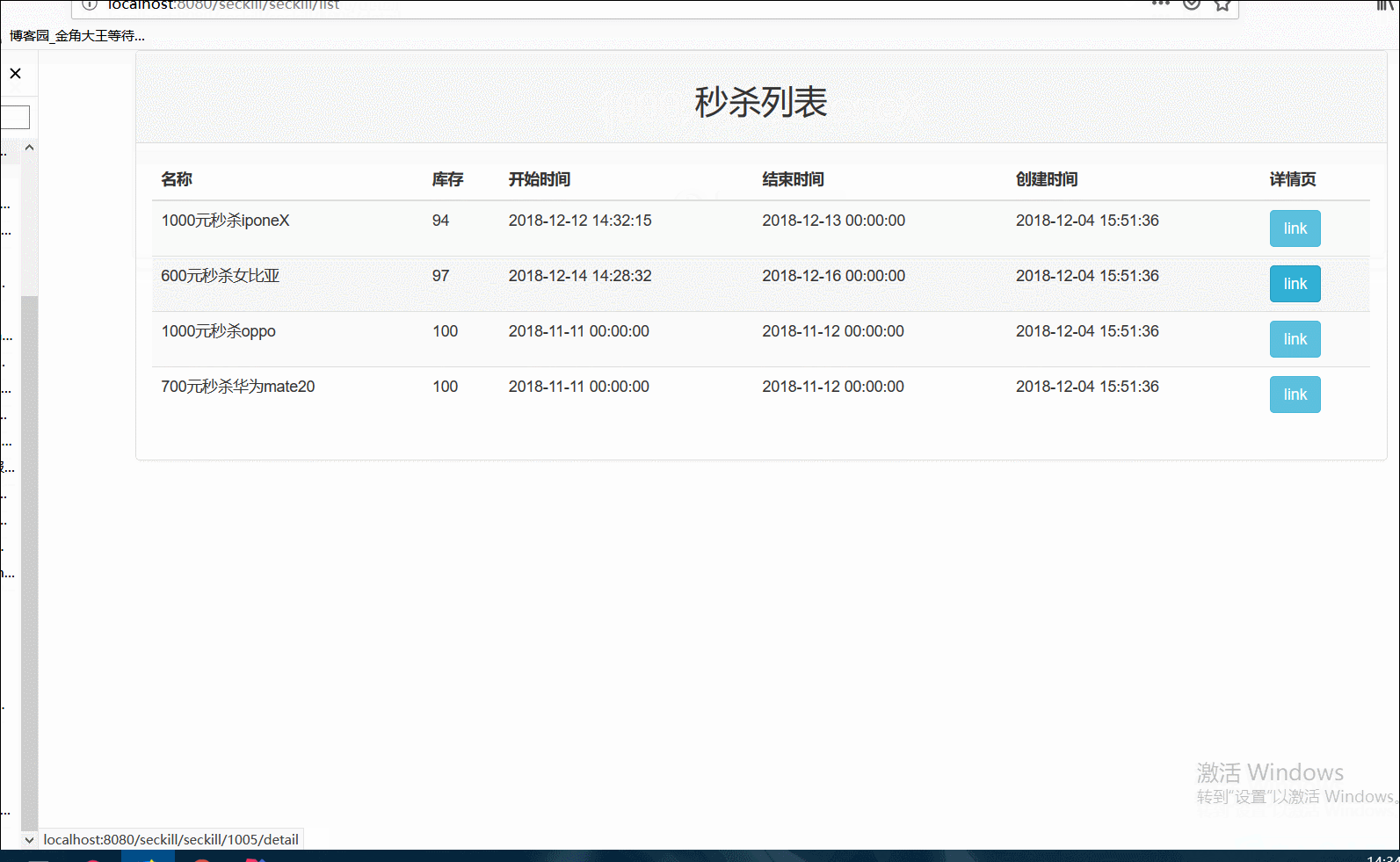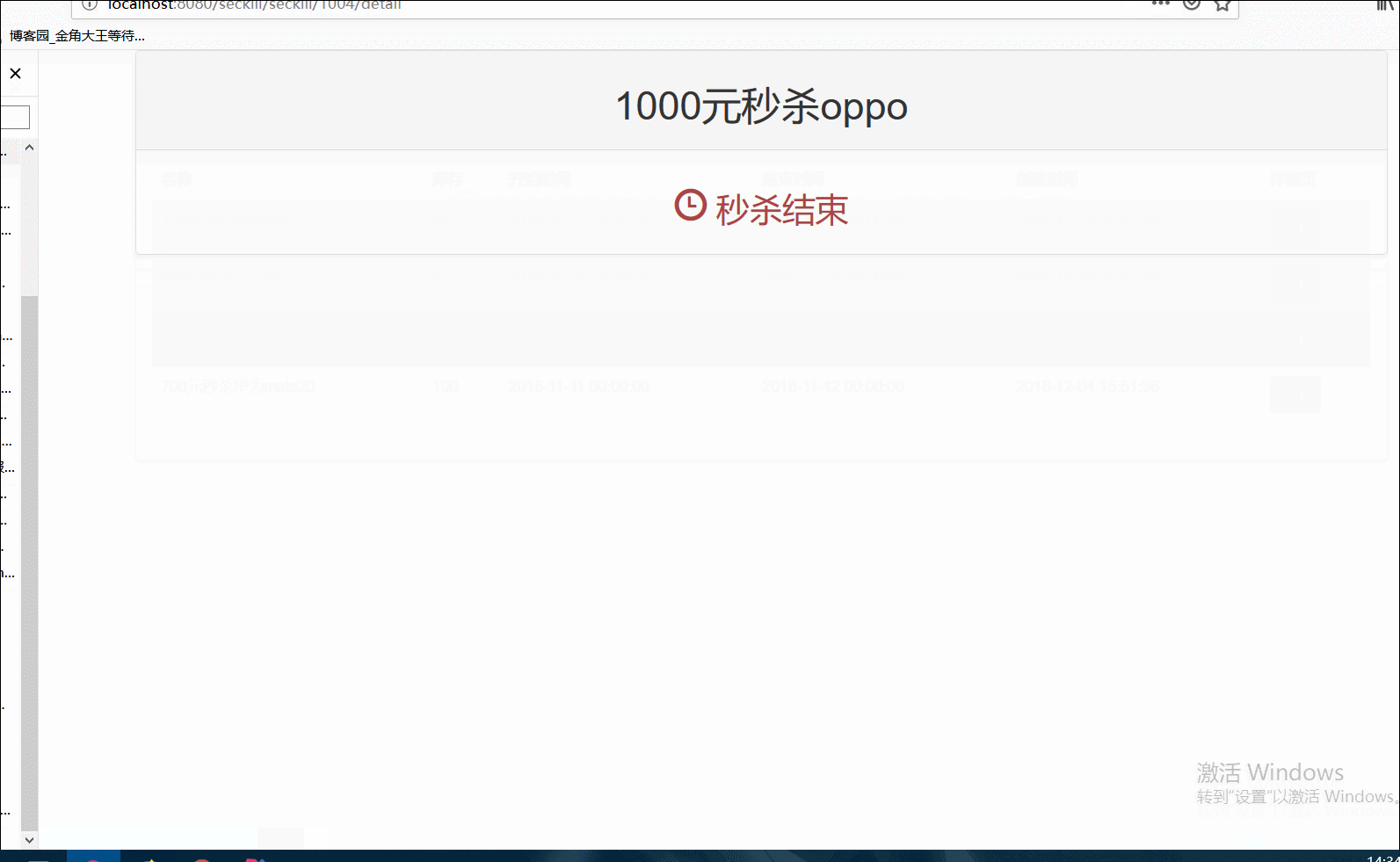
虽然能够运行,但是这个应用扛不住太大的gps,假设有成千上万的用户对一个商品秒杀的时候,在那么高的并发下我们的系统很有可能hold不住,故我们需要进一步优化。
整体分析
高并发发生在哪儿?
并发肯定发生在详情页的秒杀。在详情页的逻辑是:进入详情页->获取服务器(系统时间)->判断时间->如果时间未到进行倒计时->时间满足或者倒计时完成,暴露地址接口->执行秒杀->返回结果。我们在倒计时、返回结果、进入详情页都不会发生并发。那么并发会发生在获取服务器时间、暴露地址接口、执行秒杀获取数据的时候出现。
出现高并发的地方有些什么问题:
1.为什么要单独获取系统时间?
分析:在用户等待秒杀开始时会频繁的刷新页面,浏览器就会有如下流程:第一次打开页面时, 页面会被静态化和静态资源一起部署到CDN上面去,当用户后面刷新页面时,用户访问的秒杀地址 已经不再系统上,而是在CDN的节点上,又因为我们知道CDN值存储静态页面和一些静态资源文 件,是不会缓存时间,所以我们需要单独获取系统时间。
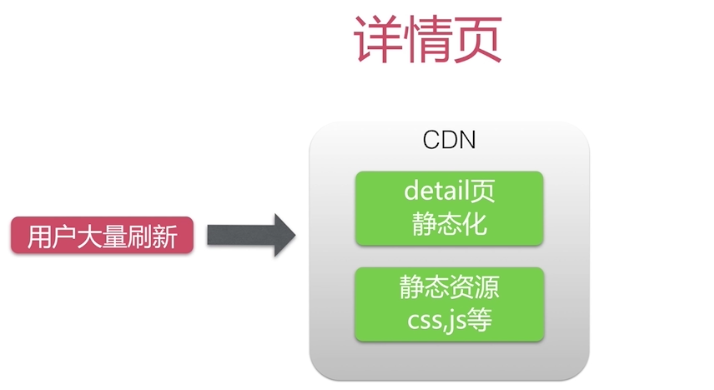
什么是CDN?
1.CDN(内容分发网络),为了加速用户获取数据的系统(具体是动态/静态资源取决于推送的策略,视频网站的加速也是依赖与此)。
2.CDN部署在离用户最近的网络节点上。
3.命中CDN不需要访问后端服务器。
4.在阿里云平台上就有CDN的租用,当然一般的企业也是租用CDN,但是牛逼的企业大多数是自己搭建得CDN,比如BAT。
获取系统时间需不需要被优化?答案是不需要,虽然CDN不缓存时间并且用户每次大量刷新页 面会获取系统时间,但是我们获取系统时间的本质是new Date(),在JAVA中访问一次内存 (cacheline)需要10ns,可以忽略不计。
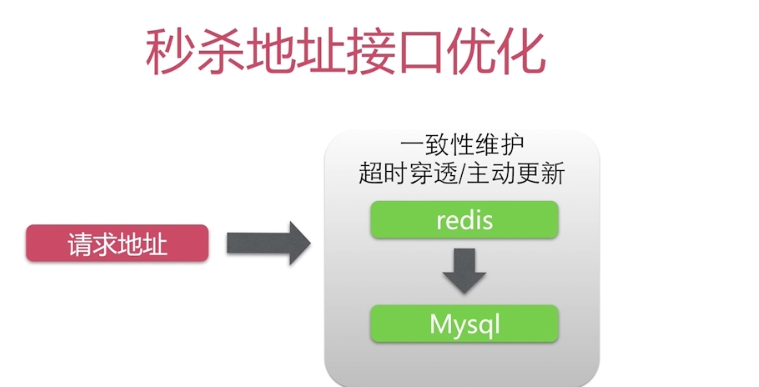
2.获取秒杀地址接口的分析:
①:无法使用CDN缓存(因为CDN缓存的数据不可变)。
②:适用于服务器端的缓存:比如Redis缓存(因为我们获取秒杀地址是根据商品Id,所以可以缓 存在Redis中)。
③:一致性维护成本低。
优化思路:把我们原来的每一次请求都是从数据库中获取,更改为,在Redis中获取,如果Redis中没有在到数据库中取,并且将其添加到Redis中。
3.秒杀操作优化分析:
①:不能使用CDN缓存。
②:后端缓存困难,因为由于库存问题,不可能在缓存中去加减库存,那么会导致不一致性问 题。
③:一行数据竞争:热点商品。
优化方案一:
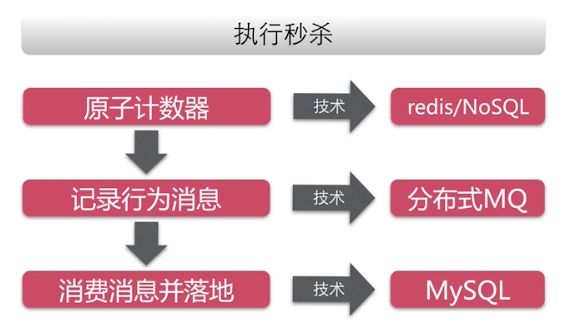
优点:可以抗住很高的并发,在redis集群和分布式MQ集群性能会更加提高。
缺点:①:运维成本和稳定性:NoSql(没有mysql稳定)。
②:开发成本:数据一致性、什么时候回滚难度大。
③:幂等性难保证:关于商品重复秒杀问题(一般的解决方案是:再增加一个分布式NOSQL 的IO方案来记录那些用户已经访问了库存。
4.为什么不用Mysql解决高并发?
分析:Mysql虽然不低效吗?做了一个同Id执行Update减库存的测试:tps可以达到4W。
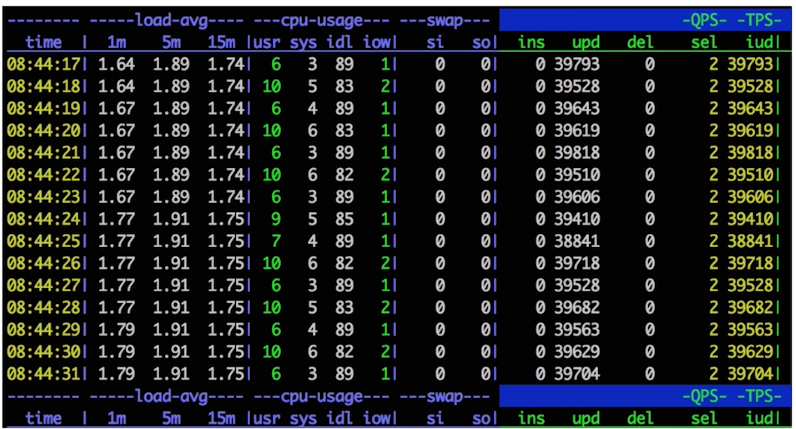
从测试来看Mysql并不低效,但是为什么不用Mysql解决高并发呢?原因如下:
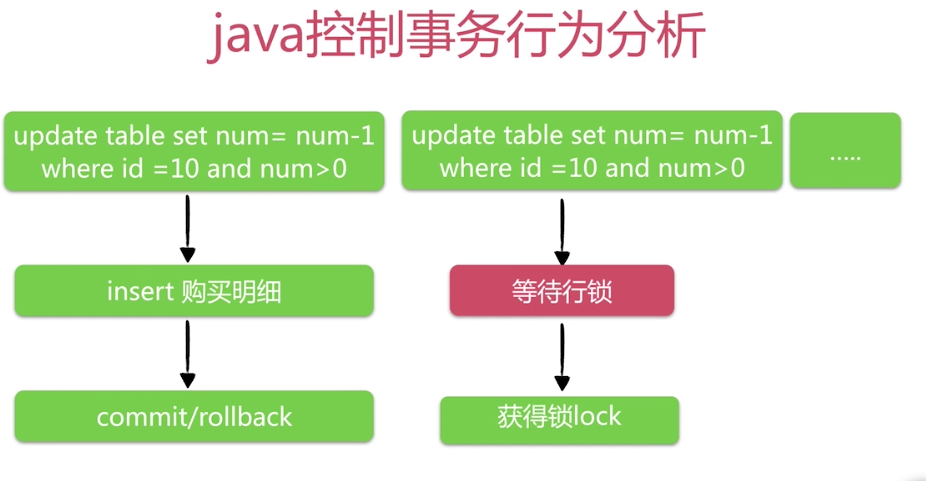
使得Mysql低效的原因是:成千上万的用户对同一个商品Update的时候,会出现一个争用mysql行级锁的情况,未得到锁的事务必须先等待,得到锁才能做相应的处理,这样就导致低效了很多。
瓶颈分析:
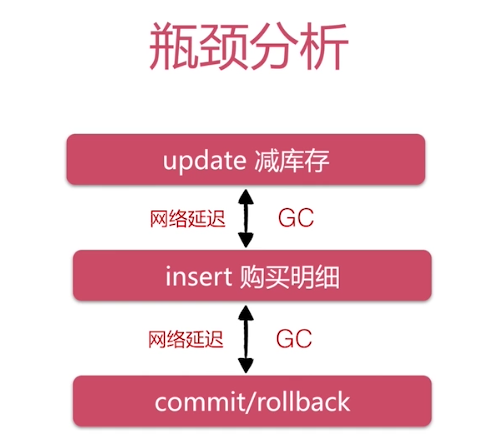
在执行Update减库存的时候,他从客户端到Mysql服务器中获得行级锁,再返回到客户端做 insert的操作,操作完成又到Mysql服务器中去commit/rollback;在两个来回的时间由于网络延 迟、GC(GC虽然不会每一次都发生,但一定会发生)花销的时间,导致单位事务占用行级锁的时 间增加,那么其他未获得行级锁的事务等待的时间也就增加了,导致效率低下。
优化:行级锁在commit/rollback后才释放,那么优化的方向就是减少行级锁持有时间。怎么减少行级锁持有时间:①:把客户端逻辑放在Mysql服务器端,避免网络延迟和Gc的影响。②:使用存储过程。
整体优化
1.Redis后端缓存优化:
Ps:使用之前,我们必须要在我们的机器上安装Redis,下载安装地址:
Linux:http://www.redis.net.cn/download/。
Window: https://github.com/dmajkic/redis/downloads。
下载后然后解压,具体安装运行过程可以参考这篇博客http://www.cnblogs.com/M-LittleBird/p/5902850.html。
由于在我们项目中要使用Redis,所有在pom.xml中要添加Redis的依赖。
<!--redis客户端-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
我们优化的思路得知,访问的地址在Redis中去获取,如果没有则,我们到数据中获取,在数据库中获取后,我们需要添加到Redis里面。
我们在dao包中增加一个RedisDao类。首先引用Redis的客户端API,引用JedisPool,并完成其构造方法:ip就是Redis服务器的地址,port是其端口号(6379)
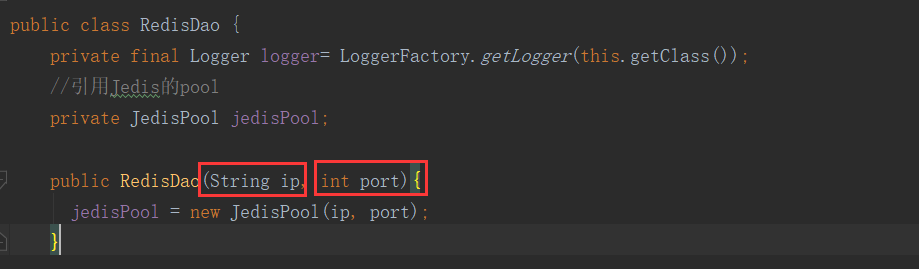
我们需要定义两个方法,一个是获取Redis的Seckill的方法,另一个是添加到Redis的方法。
getSeckill方法(我写了注解)
//使用第三方的protostuff序列化,需要先指定需要序列化的类接口,如下,但是这个类必须是pojo型。 private RuntimeSchema<SecKill> schema=RuntimeSchema.createFrom(SecKill.class); public SecKill getSeckill(long seckillId) { //缓存Redis操作。 try{ //根据jedisPool获得他们的资源 .getResource(); Jedis jedis=jedisPool.getResource(); try{ //因为Redis是key-value存储的,那么我们首先要构建一个key。 String key="seckill:"+seckillId; /* Redis并没有实现内部序列化操作。 我们需要在获取redis资源的时候要进行反序列化操作 get->byte[]->反序列化->Object(Seckill); 关于序列化的解决方案:①入门级:在需要传递的entity的对象类实现 Serializable接口;这个Serializable是 使用的是JDK的自己的序列化。 ②大师级:既然是在优化这个暴露接口,那么就把他做到最好,使用JDk原生的 序列化的速度,效率,占的空间,转化的字节数(最少,在网络中传输的字节数就会最少,效率最高)等都不是最好 的。采用自定义序列化;我们使用的是protostuff,那么在Pom.xml中添加 protostuff-core和protostuff-runtime 系列化依赖。 */ byte[]bytes=jedis.get(key.getBytes()); if(bytes!=null){ //创建一个空对象,在Redis中赋值给这个空对象。 SecKill secKill=schema.newMessage(); ProtostuffIOUtil.mergeFrom(bytes,secKill,schema); //空对象secKill,在调用上面语句之后被赋值。 return secKill; } }finally { jedis.close(); } }catch(Exception e){ logger.error(e.getMessage(),e); } return null; }
setSeckill方法
public String setSeckill(SecKill seckill) { //首先拿到Seckill,然后转换成字节数组,然后给redis try{ //获得资源 Jedis jedis=jedisPool.getResource(); try{ //封装Key String key="seckill:"+seckill.getSeckillId(); //系列化 byte[] bytes=ProtostuffIOUtil.toByteArray(seckill,schema, LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE)); int timeout=60*60; String result=jedis.setex(key.getBytes(),timeout,bytes); return result; }finally { jedis.close(); } }catch(Exception e){ logger.error(e.getMessage(),e); } return ""; }
把RedisDao类实现后,我们新建测试类测试:
package org.seckill.dao; /** * @author yangxin * @time 2018/12/12 9:34 */ @RunWith(SpringJUnit4ClassRunner.class) //告诉Junit Spring配置文件 @ContextConfiguration({"classpath:spring/springDao-config.xml"}) public class ResdisDaoTest { private long id=1002; @Autowired private RedisDao redisDao; @Autowired private SeckillDao secKillDao; @Test public void Seckill() { SecKill seckill=redisDao.getSeckill(id); if(seckill==null){ seckill=secKillDao.queryById(id); if(seckill!=null) { String string = redisDao.setSeckill(seckill); System.out.println(string); seckill = redisDao.getSeckill(id); System.out.println(seckill); } } } }
我们还需要把这个RedisDao注入到spring容器中:
<!--redis注入-->
<bean id="redisDao" class="org.seckill.dao.RedisDao">
<constructor-arg index="0" value="localhost"/>
<constructor-arg index="1" value="6379"/>
</bean>
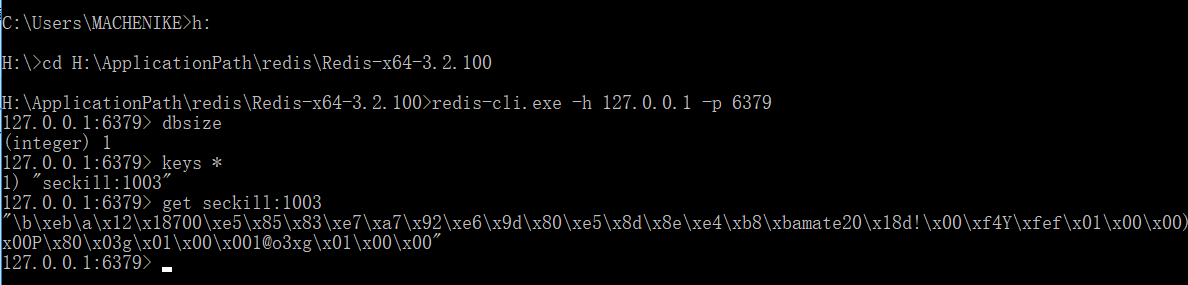
运行结果
我们在Redis中查找一下有没有这个数据。
测试没有发现任何问题,OK。
我们在SeckillServiceImpl中更改exportSeckillUrl函数的逻辑。
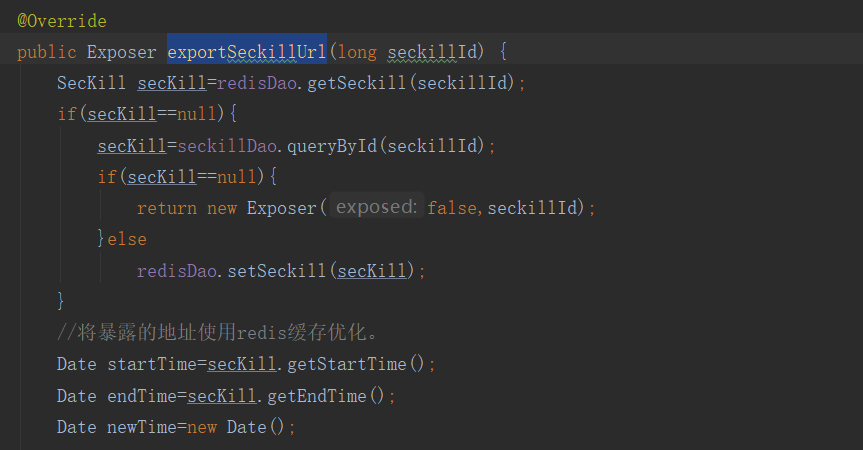
Redis后端缓存的优化完成。
2.并发优化:
①:简单的优化:我们这个框架的结构是第一图,我们首先更新库存,然后再插入明细,这样的逻辑有一个比较大的忧患,Update获得行级锁,直到最后commit/rollback才释放,但是insert并不需要锁,所以,我们将insert和update的步骤调换,那么就会减少锁持有时间;并且我们在update后直接commit/rollback,我们只需要他们影响几条数据就返回几条,如果返回0 表示rollback没有数据更新,>1就是更新数。这样的话那么update和commit/rollback都在服务器中一起完成,就没有从客服端传递到服务器端的过程,相当于两个是一个整体,减少了一个来回的网络延迟和GC。
 -----》
-----》 
代码修改第一图变成第二图

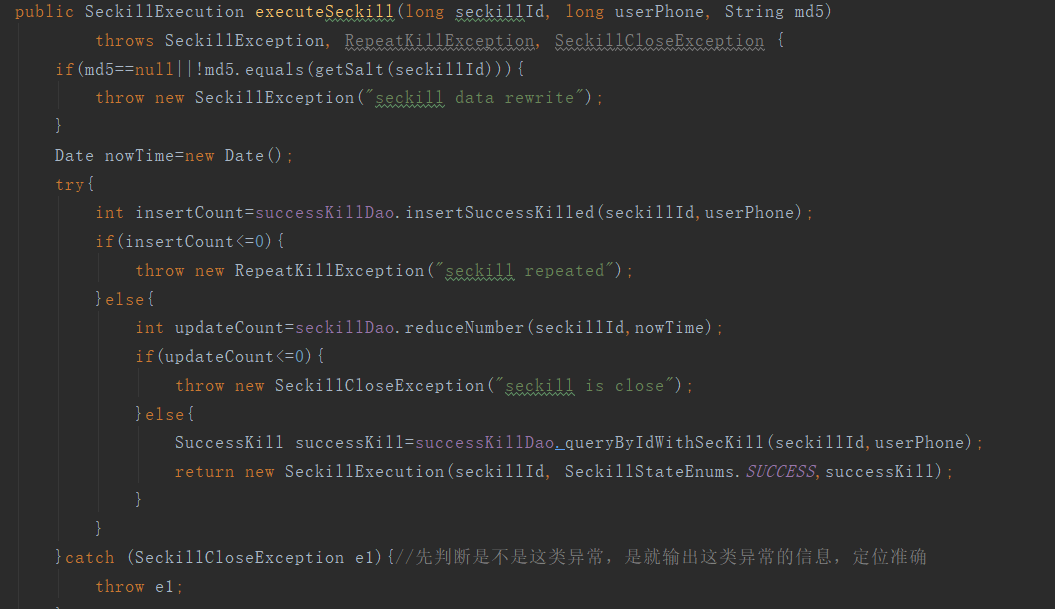
②:深度优化:使用存储过程的方式解决。在目前的优化策略中,使用存储过程的解决方案越来越不推荐,常常使用的大多数是银行业务;不过在秒杀系统中使用这个策略也是可行的。
编写存储过程脚本:
--执行秒杀的存储过程 DELIMITER $$ --把console的隔离符;转换成$$ --定义一个存储过程 --参数 in 表示输入参数;out 表示输出参数。 --row_count()表示修改上一条操作影响的行数。 --row_count()。1.如果返回0,表示未修改数据。2.如果返回1,表示修改一条数据。3.<0.sql错误。 ---- CREATE PROCEDURE `seckill`.`execute_seckill` (in v_seckill_id bigint,in v_phone bigint, in v_kill_time timestamp ,out r_result int) BEGIN DECLARE insert_count int DEFAULT 0; START TRANSACTION ; INSERT ignore INTO success_killed (seckill_id,user_phone,create_time,state) VALUES(v_seckill_id,v_phone,v_kill_time,0); SELECT ROW_COUNT() INTO insert_count; IF(insert_count=0) THEN ROLLBACK; SET r_result=-1; ELSEIF(insert_count<0) THEN ROLLBACK; SET r_result=-2; ELSE UPDATE seckill SET number=number-1 WHERE seckill_id=v_seckill_id AND end_time > v_kill_time AND start_time<v_kill_time AND number>0; SELECT ROW_COUNT () INTO insert_count; IF (insert_count=0) THEN ROLLBACK; SET r_result=-1; ELSEIF(insert_count<0) THEN ROLLBACK; SET r_result=-2; ELSE COMMIT; SET r_result=1; END IF; END IF; END; $$ --存储过程定义结束。 DELIMITER ; set @r_result=-3; call execute_seckill(1003,13255446633,now(),@r_result); --获取结果 SELECT @r_result;
在SeckillDao添加killByProcedure函数,在配置mybatis调用存储过程:
<!--mybatis调用存储过程-->
<select id="killByProcedure" statementType="CALLABLE">
call execute_seckill(
#{seckillId,jdbcType=BIGINT,mode=IN},
#{phone,jdbcType=BIGINT,mode=IN},
#{killTime,jdbcType=TIMESTAMP,mode=IN},
#{result,jdbcType=INTEGER,mode=OUT}
)
</select>
在SeckillService函数中添加存储过程实现方法
@Override public SeckillExecution executeSeckill2(long seckillId, long userPhone, String md5) { if(md5==null||!md5.equals(getSalt(seckillId))){ throw new SeckillException("seckill data rewrite"); } Date killdate=new Date(); Map<String,Object> map=new HashMap<>(); map.put("seckillId",seckillId); map.put("phone",userPhone); map.put("killTime",killdate); map.put("result",null); try{ seckillDao.killByProcedure(map); int result=MapUtils.getInteger(map,"result",-2); if(result==1){ SuccessKill sk=successKillDao.queryByIdWithSecKill(seckillId,userPhone); return new SeckillExecution(seckillId,SeckillStateEnums.SUCCESS,sk); }else{ return new SeckillExecution(seckillId,SeckillStateEnums.stateof(result)); } }catch(Exception e){ logger.error(e.getMessage(),e); return new SeckillExecution(seckillId,SeckillStateEnums.INNER_ERROR); } }
再在Controller中将调用的executeSeckill改成executeSeckill2即可。
关于SeckillService中新添加存储过程处理函数的测试函数
@Test
public void executeProcedure(){
long id=1001;
long phone=12355669988L;
Exposer exposer=seckillService.exportSeckillUrl(id);
if(exposer.isExposed()){
String md5=exposer.getMd5();
SeckillExecution execution=seckillService.executeSeckill2(id,phone,md5);
logger.info(execution.getStateInfo());
}
}
总结
经过一个星期学习,我完成秒杀应用的完整开发,不仅重新温习了SSM框架的使用,还新学到新的开发思路、算法、spring的配置技巧、功能分类、js的分包、Junit4测试类的使用;对DAO层,Service层,Web层各自负责的功能有了一个更深的理解。
在Dao层:Mybatis与Spring的整合技巧,配置之间的依赖关系,接口的设计有了新的感悟;
在Service层:使用Spring托管Service实现类,并使用了Spring声明式事务自动Commit/rollBack,spring的依赖注入等。
在Web层:学习到了restful接口的设计与实现,和前端的交互,Js的编写。
在优化过程中学会分析了秒杀的瓶颈所在,然后针对瓶颈进行了优化。
不过在SSM的框架中,我明白一个最终要的一句话:“约定大于配置。”
结语
高并发的应用学习完了,所有的博客如下:
1.项目开始。
3.高并发秒杀应用:Service层设计(Spring的IOC与AOP的使用)。
4.高并发秒杀应用:Web层设计(SpringMvc的使用)。
我是学习慕课网的课程,课程传送门如下:
1.https://www.imooc.com/learn/587。
2.https://www.imooc.com/learn/630。
3.https://www.imooc.com/learn/631。
4.https://www.imooc.com/learn/632。
我是一个很菜的程序员,如今还没有走出校园,博客中如果有错误希望大佬们多多指点,有技术方面的问题希望我们可以一起讨论讨论。

