Spark程序运行常见错误解决方法以及优化
转载自:http://bigdata.51cto.com/art/201704/536499.htm
Spark程序运行常见错误解决方法以及优化
task倾斜原因比较多,网络io,cpu,mem都有可能造成这个节点上的任务执行缓慢,可以去看该节点的性能监控来分析原因。以前遇到过同事在spark的一台worker上跑R的任务导致该节点spark task运行缓慢。
- 作者:佚名来源:数据为王|2017-04-07 09:02
-
一.org.apache.spark.shuffle.FetchFailedException
1.问题描述
这种问题一般发生在有大量shuffle操作的时候,task不断的failed,然后又重执行,一直循环下去,非常的耗时。
2.报错提示
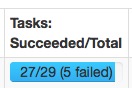
(1) missing output location
- org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 0
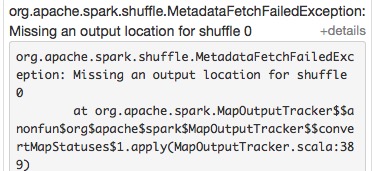
(2) shuffle fetch faild
- org.apache.spark.shuffle.FetchFailedException: Failed to connect to spark047215/192.168.47.215:50268
当前的配置为每个executor使用1cpu,5GRAM,启动了20个executor
3.解决方案
一般遇到这种问题提高executor内存即可,同时增加每个executor的cpu,这样不会减少task并行度。
- spark.executor.memory 15G
- spark.executor.cores 3
- spark.cores.max 21
启动的execuote数量为:7个
- execuoteNum = spark.cores.max/spark.executor.cores
每个executor的配置:
- 3core,15G RAM
消耗的内存资源为:105G RAM
- 15G*7=105G
可以发现使用的资源并没有提升,但是同样的任务原来的配置跑几个小时还在卡着,改了配置后几分钟就结束了。
二.Executor&Task Lost
1.问题描述
因为网络或者gc的原因,worker或executor没有接收到executor或task的心跳反馈
2.报错提示
(1) executor lost
- WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, aa.local): ExecutorLostFailure (executor lost)
(2) task lost
- WARN TaskSetManager: Lost task 69.2 in stage 7.0 (TID 1145, 192.168.47.217): java.io.IOException: Connection from /192.168.47.217:55483 closed
(3) 各种timeout
- java.util.concurrent.TimeoutException: Futures timed out after [120 second
- ERROR TransportChannelHandler: Connection to /192.168.47.212:35409 has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong
3.解决方案
提高 spark.network.timeout 的值,根据情况改成300(5min)或更高。
默认为 120(120s),配置所有网络传输的延时,如果没有主动设置以下参数,默认覆盖其属性
- spark.core.connection.ack.wait.timeout
- spark.akka.timeout
- spark.storage.blockManagerSlaveTimeoutMs
- spark.shuffle.io.connectionTimeout
- spark.rpc.askTimeout or spark.rpc.lookupTimeout
三.倾斜
1.问题描述
大多数任务都完成了,还有那么一两个任务怎么都跑不完或者跑的很慢。
分为数据倾斜和task倾斜两种。
2.错误提示
(1) 数据倾斜
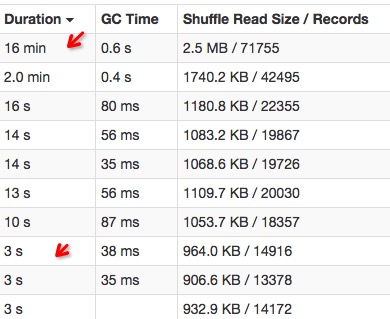
(2) 任务倾斜
差距不大的几个task,有的运行速度特别慢。
3.解决方案
(1) 数据倾斜
数据倾斜大多数情况是由于大量null值或者""引起,在计算前过滤掉这些数据既可。
例如:
- sqlContext.sql("...where col is not null and col != ''")
(2) 任务倾斜
task倾斜原因比较多,网络io,cpu,mem都有可能造成这个节点上的任务执行缓慢,可以去看该节点的性能监控来分析原因。以前遇到过同事在spark的一台worker上跑R的任务导致该节点spark task运行缓慢。
或者可以开启spark的推测机制,开启推测机制后如果某一台机器的几个task特别慢,推测机制会将任务分配到其他机器执行,最后Spark会选取最快的作为最终结果。
- spark.speculation true
- spark.speculation.interval 100-检测周期,单位毫秒;
- spark.speculation.quantile 0.75-完成task的百分比时启动推测
- spark.speculation.multiplier 1.5-比其他的慢多少倍时启动推测。
四.OOM(内存溢出)
1.问题描述
内存不够,数据太多就会抛出OOM的Exeception
因为报错提示很明显,这里就不给报错提示了。。。
2.解决方案
主要有driver OOM和executor OOM两种
(1) driver OOM
一般是使用了collect操作将所有executor的数据聚合到driver导致。尽量不要使用collect操作即可。
(2) executor OOM
1.可以按下面的内存优化的方法增加code使用内存空间
2.增加executor内存总量,也就是说增加spark.executor.memory的值
3.增加任务并行度(大任务就被分成小任务了),参考下面优化并行度的方法
优化
1.内存
当然如果你的任务shuffle量特别大,同时rdd缓存比较少可以更改下面的参数进一步提高任务运行速度。
spark.storage.memoryFraction - 分配给rdd缓存的比例,默认为0.6(60%),如果缓存的数据较少可以降低该值。
spark.shuffle.memoryFraction - 分配给shuffle数据的内存比例,默认为0.2(20%)
剩下的20%内存空间则是分配给代码生成对象等。
如果任务运行缓慢,jvm进行频繁gc或者内存空间不足,或者可以降低上述的两个值。
"spark.rdd.compress","true" - 默认为false,压缩序列化的RDD分区,消耗一些cpu减少空间的使用
如果数据只使用一次,不要采用cache操作,因为并不会提高运行速度,还会造成内存浪费。
2.并行度
- spark.default.parallelism
发生shuffle时的并行度,在standalone模式下的数量默认为core的个数,也可手动调整,数量设置太大会造成很多小任务,增加启动任务的开销,太小,运行大数据量的任务时速度缓慢。
- spark.sql.shuffle.partitions
sql聚合操作(发生shuffle)时的并行度,默认为200,如果任务运行缓慢增加这个值。
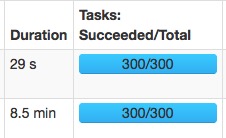
相同的两个任务:
- spark.sql.shuffle.partitions=300:
- spark.sql.shuffle.partitions=500:
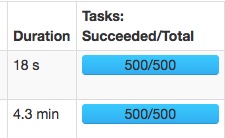
速度变快主要是大量的减少了gc的时间。
修改map阶段并行度主要是在代码中使用rdd.repartition(partitionNum)来操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号