python-初识
电脑的硬件基础
CPU
中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
中央处理器主要包括运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。它与内部存储(Memory)和输入/输出(I/O)设备合称为电子计算机三大核心部件。
CPU类似于人的大脑。
内存
内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。
内存一般采用半导体存储单元,包括随机存储器(RAM),只读存储器(ROM),以及高速缓(CACHE)。
1.随机存储器
随机存储器(Random Access Memory)表示既可以从中读取数据,也可以写入数据。当机器电源关闭时,存于其中的数据就会丢失。市场上常见的随机存储器有4G,8G,16G...
2.只读存储器
ROM表示只读存储器(Read Only Memory),在制造ROM的时候,信息(数据或程序)就被存入并永久保存。这些信息只能读出,一般不能写入,即使机器停电,这些数据也不会丢失。ROM一般用于存放计算机的基本程序和数据,如BIOS ROM。
3.高速存储器
当CPU向内存中写入或读出数据时,这个数据也被存储进高速缓冲存储器中。当CPU再次需要这些数据时,CPU就从高速缓冲存储器读取数据,而不是访问较慢的内存,当然,如需要的数据在Cache中没有,CPU会再去读取内存中的数据。
内存 高速存储器 CPU之间的关系
4.硬盘
是能够长期存储数据的,常见的硬盘的大小有1TB,512G等。
操作系统
操作系统(英语:operating system,缩写作OS)是管理计算机硬件与软件资源的计算机程序,同时也是计算机系统的内核与基石。操作系统需要处理如管理与配置内存、决定系统资源供需的优先次序、控制输入与输出设备、操作网络与管理文件系统等基本事务。操作系统也提供一个让用户与系统交互的操作界面。
操作系统的类型非常多样,不同机器安装的操作系统可从简单到复杂,可从移动电话的嵌入式系统到超级计算机的大型操作系统。许多操作系统制造者对它涵盖范畴的定义也不尽一致,例如有些操作系统集成了图形用户界面,而有些仅使用命令行界面,而将图形用户界面视为一种非必要的应用程序。
Python的介绍
python的出生和应用
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。

python应用领域:
Python在系统编程中的应用
Python语言在操作系统的内置接口,被称为Shell工具。Python程序可以搜索文件和目录树、可以运行其他的应有程序或是用进程或线程进行并行处理。Python标准库绑定了POSIX(可移植操作系统接口)以及其他常规操作系统工具。所以环境变量、管道、进程、多线程、文件、套接字、python正则表达式模式匹配、命令行参数、标准流接口、Shell 命令启动器、file扩展等。除此之外很多Python 的系统工具设计时都考虑了其可移植性。
Python在网络爬虫方面的应用
由于Python的网络方面的功能非常强大,常用来实现网络爬虫。常用框架有:
- grab – 网络爬虫框架(基于pycurl/multicur)。
- scrapy – 网络爬虫框架(基于twisted),不支持Python3。
- pyspider – 一个强大的爬虫系统。
- cola – 一个分布式爬虫框架。
- portia – 基于Scrapy的可视化爬虫。
- restkit – Python的HTTP资源工具包。它可以让你轻松地访问HTTP资源,并围绕它建立的对象。
- demiurge – 基于PyQuery的爬虫微框架。
Python在人工智能、科学计算中的应用
科学运算、人工智能: 典型库NumPy, SciPy, Matplotlib, Enthought librarys,pandas
Python在WEB开发中的应用
Python有众多优秀的WEB框架,众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣等等 典型WEB框架有Django、Flask等,享学课堂就是使用Django开发的。
Python在系统运维中的应用
Python已经成为,运维人员必备语言,尤其是在Linux运维方面,基本上是自动化运维。
Python在大数据、云计算方面的应用
Python是大数据、云计算最火的语言, 典型应用OpenStack。
Python在金融方面的应用
量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很厉害,生产效率远远高于c,c++,java,尤其擅长策略回测。
Python在图形界面方面的应用
PyQT, WxPython,TkInter
Python在企业和网站方面的案例应用
-
谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发
-
CIA: 美国中情局网站就是用Python开发的
-
NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算
-
YouTube:世界上最大的视频网站YouTube就是用Python开发的
-
Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载
-
Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发
-
Facebook:大量的基础库均通过Python实现的
-
Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
-
豆瓣: 公司几乎所有的业务均是通过Python开发的
-
知乎: 国内最大的问答社区,通过Python开发(国外Quora)
python是什么语言
解释性:
- 解释型语言提供了极佳的调试支持。
- 另一个优势是解释器比编译器容易实现。
- 解释型语言最大的优势之一是其平台独立性
- 解释型语言也可以保证高度的安全性
- 中间语言代码的大小比编译型可执行代码小很多
- 平台独立性
- 解释器也会做很多代码优化,运行时安全性检查
编译性:
- 编译型语言最大的特点的优势是执行的的速度快。用c++编写的程序比Java编写的程序,快30%-70%。
- 编译型的程序比解释性的程序消耗的内存更少。
- 编译型的程序的开发的效率低。
- 可行性的编译型的代码要比解释型的代码大许多。
- 编译型程序是面向特定平台的因而是平台依赖的。
- 由于松散的安全性和平台依赖性,编译型语言不太适合开发因特网或者基于Web的应用。
python的优缺点
优点:
- 高级语言:无需要考虑程序的内存情况等底层的细节。
- python开发效率高(比其他的解释型语言都高)由于第三方库 避免重复造轮子。
- 可嵌入性。Python代码可以移植到C/C++ 语言中。
- 可拓展性。python代码可以嵌入C/C++ 语言中。
- 可移植性:不同操作系统的移植。
- Python的定位是“优雅”、“明确”、“简单
缺点:
- 速度慢,和c比较,要慢很多,相比于Java也慢一些。
- python代码不能加密,因为PYTHON是解释性语言,它的源码都是以名文形式存放的。
- 线程不能利用多CPU问题。
python的种类

Python基础
pyhton的第一个代码
在notepad++添加python的代码
print("hello world...")
窗口键+R 输入cmd 回车 进入一个黑框

变量
声明变量:
# -*- coding: utf-8 -*-
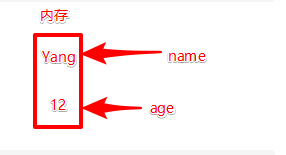
name = "Yang"
age = 12
上述声明一个变量为name和age,对应的值为"Yang"和12。
就是某个地址的内容的标签,也可以说是别名。
变量的命名规则
- 变量只能由 数字,字母,下划线任意组合。
- 不能以数字开头
- 不能是python中的关键字。关键字如下:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
- 变量要具有可描述性。
- 变量不宜过长。
- 变量不能使用中文。
推荐的定义方式:
下划线:
age_of_oldboy = 56
驼峰体:
AgeOfOldboy = 56
单驼峰;
Ageofoldboy = 56
常量
常量即指不变的量,如\(\pi\) 3.141592653..., 或在程序运行过程中不会改变的量。
在Python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量。
HIGHT = 50
注释
单行注释
# 注释
多行注释
"""
注释
"""
或
'''
注释
'''
基础数据类型
str
>>> name = "Yangchangjie"
>>> age = 22
>>> data = "This is a test"
>>> string_data = 'test'
>>>
怎么样解决下面的问题
>>> data = 'I'm is xxxx'
File "<stdin>", line 1
data = 'I'm is xxxx'
解决方法:
>>> data = "I'm is xxxx"
>>> data
"I'm is xxxx" # 单双括号之间的配合使用
字符串的拼接
假设想将下面的字符串进行连接
a = 'depart',b = 'ment'
使用加号(+)进行拼接:
>>> a = 'depart'
>>> b = 'ment'
>>>
>>> a + b
'department'
字符串也可以进行乘法操作
>>> string_data = 'Yang'
>>> string_data * 4
'YangYangYangYang' # 感觉就是进行了加法运算
int(整型)
在32位机器上,整数的位数为32位,取值范围为\(-2^{31}\)~\(2^{31}-1\),即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为\(-2^{63}\)~\(2^{63}-1\),即-9223372036854775808~9223372036854775807
bool
布尔类型很简单,就两个值 ,一个True(真),一个False(假)。
>>> x = 5
>>> y = 6
>>> x > y # 不成立返回False
False
>>> x < y # 成立返回True
True
>>>
用户交互
有时候我们希望和计算机进行交互,例如我们在登录账户的时候,需要进行与机器进行交互。在python可以使用input函数进行和计算机交互。
>>> name = input("Please enter you name:")
Please enter you name:Yang
>>> name
'Yang'
流程控制语句if
if语句是进行条件判断,如果满足这个条件,则去这个分支,如果其他的条件满足则去相应的分支。
常见的分支有单分支,双分支,多分支,
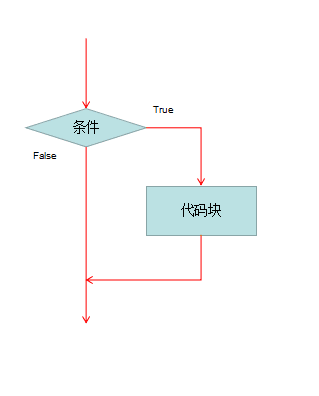
单分支的基本结构:
if 条件:
满足条件后要执行的代码块
测试
num = 45
if num > 42:
print(num)

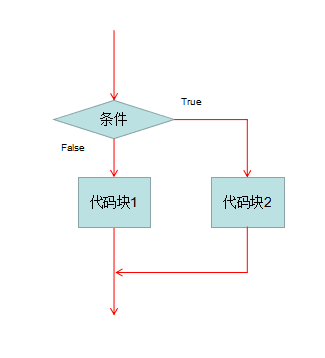
双分支的基本结构:
if 条件:
满足条件的代码块
else:
if条件不满足就这些这个代码块
测试
num = 45
if num > 42:
print(num)
else:
print(num+1)

多分支的基本结构:
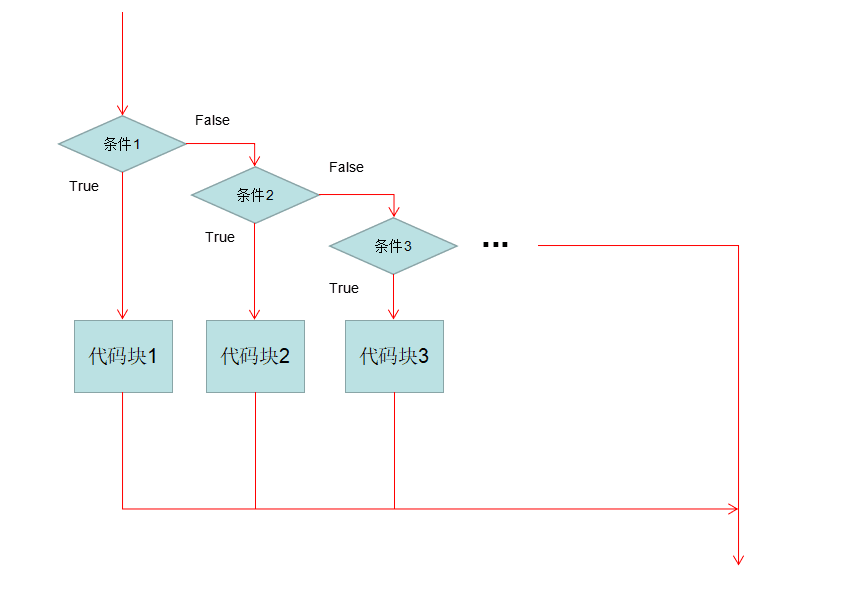
if 条件:
满足条件执行的代码
elif 条件:
上面条件不满足就执行这个代码块
elif 条件:
上面条件不满足就执行这个代码块
.....
else:
上面所有的条件都不满足,就执行下面的代码块
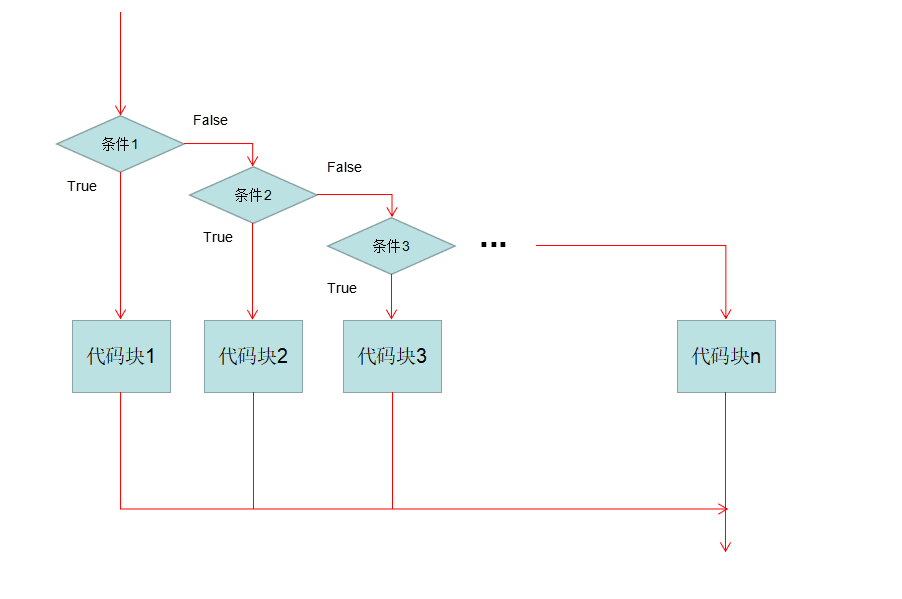
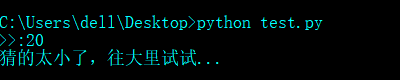
测试
age_of_oldboy = 48
guess = int(input(">>:"))
if guess > age_of_oldboy :
print("猜的太大了,往小里试试...")
elif guess < age_of_oldboy :
print("猜的太小了,往大里试试...")
else:
print("恭喜你,猜对了...")