C++
变量和基本数据类型
算术类型
算术类型包括了整型(integral type 包括了字符和布尔类型在内)和浮点型。
C++:算术数据类型:
| 类型 | 含义 | 最小尺寸 |
|---|---|---|
| bool | 布尔类型 | 未定义 |
| char | 字符 | 8位 |
| wchar_t | 宽字符 | 16位 |
| char16_t | Unicode字符 | 16位 |
| char32_t | Unicode字符 | 16位 |
| short | 短整型 | 16位 |
| int | 整型 | 16位 |
| long | 长整型 | 32位 |
| long long | 长整型 | 64位 |
| float | 单精度浮点型 | 6位有效数字 |
| double | 双精度浮点型 | 10位有效数字 |
| long double | 扩展精度浮点型 | 10位有效数字 |
各种变量类型在内存中存储值时需要占用的内存,以及该类型的变量所能存储的最大值和最小值,如下所示:

布尔类型(bool)的取值是真(true)或者假(False)
wchar_t、char16_t、char32_t。wchar_t类型用于确保可以存放机器最大扩展字符集中的任意一个字符, 类型char16_t和char32_t, 则是Unicode字符集服务(Unicode是用于表示所有自然语言中字符的标准)
C++语言规定, 一个int至少和一个short一样大, 一个long至少和一个int一样大, 一个long long 至少和一个long 一样大。其中long long是在C++11中新定义的。
除去布尔类型和扩展字符型外,其他的整型还分为带符号的(signed)和无符号(unsigned)两种,带符号的类型可以表示正数、负数或0, 无符号类型则仅能表示大于等于0的值。
类型转换
算术类型的值赋值给另外的一个类型时:
bool b = 45; // b 为True
int i = b; // i的值为1
i = 3.14;
double pi = i; // pi的值为3.0
unsigned char c = -1; //假设char占8比特,c的值为255
signed char c2 = 256; //假设char占8比特,c2的值为未定义
- 当非布尔类型赋值给布尔类型时,初始值是0,则结果是False,否则的True。
- 当布尔类型的值赋值给非布尔类型时,初始值为False,这结果是0, 初始化为True,则是1。
- 将浮点数据赋值给整型类型时,将进行近似处理,只保留整数部分。
- 将整数数据赋值给浮点类型时,小数部分记为0,如果该整数所占的空间超过了浮点类型的容量,精度可以有损失。
- 当我们赋值的无符号类型一个超出它表示的范围的值时,结果是初始化对无符号类型表示数值总数取模后的余数。
- 当我们赋值的带符号类型一个超出它表示的范围的值时,结果是未定义的。此时, 程序可以继续工作、可以崩溃、也有可能成为垃圾数据。
unsigned u1 = 42, u2 = 10;
cout << "u1-u2:" << u1 - u2 << endl; //u1 - u2:32
cout << "u2-u1:" << u2- u1 << endl; //u2-u1:4294967264(取模后是值)
unsigned u = 10, u2 = 42; // u-u2:4294967264
cout << "u-u2:" << u - u2 << endl; //u2-u:3
cout << "u2-u:" << u2-u << endl; //u2-u:32
int i=10, i2 = 45;
cout<<"i2-i:"<<i2-i<<endl; // i2-i:35
cout<<"i-i2:"<<i-i2<<endl; // i-i2:-35
cout<<"u-i:"<<u-i<<endl; // u-i:0
转义序列
C++语言规定的转义序列如下所示:
| 语义 | 符号 | 语义 | 符号 | 语义 | 符号 |
|---|---|---|---|---|---|
| 换行符 | \n | 横向制表符 | \t | 报警(响铃)符 | \a |
| 纵向制表符 | \v | 退格符 | \b | 双引号 | " |
| 反斜杠 | \ | 问号 | \? | 单引号 | ' |
| 回车 | \r | 进纸符 | \f |
上述的转义字符只能当一个字符使用。
cout<<'\n'; //转到新的一行
cout<<"\tHi!\n"; // 输出一个制表符,输出"Hi",转到新的一行
也可以使用泛化的转义序列。其中的形式是\x后面跟1个或者多个16进制的数字,或者\后面紧跟1个、2个、3个八进制数字, 其中数字部分表示的是字符对应的数值。
| 数字 | 字符 | 数字 | 字符 | 数字 | 字符 |
|---|---|---|---|---|---|
| \7 | 响铃 | \12 | 换行符 | \40 | 空格 |
| \0 | 空字符 | \115 | M | \x4d | M |
cout<<"Hi \x4dO\115!\n"<<endl; // 输出 Hi MOM ,转到下一行
cout<<'\155'<<'\n'; // 输出M,转到下一行
变量
定义变量
int sum = 0, values = 123; //都是相同的类型int
列表初始化
int units_sold = 0;
int units_sold = {0};
int units_sold{0};
int units_sold(0);
C++11新标准的一部分,用花括号来初始化变量得到的全面的运用,在之前, 这种初始化的形式仅在某些受限的场合上运用。
long double pi = 3.1415926;
//int a{pi}, b ={pi};// error转换未执行,存在丢失信息的危险
int a(pi), b=pi; //正确,确定丢失的部分值(小数部分)
变量的声明和定义
想声明变量而非定义它,就在变量名前加上关键字extern, 并不初始化变量。
extern int i;//声明i而非定义i
int j; 声明并定义i
extern double pi = 3.1416;// 定义
在函数的内部, 试图初始化一个有extern关键字标记的变量,将会引发错误。
变量能其只能定义一次,但是可以被多次的声明。
标识符
C++的标识符是有子母、数字、下划线组成的,其中子母或下划线开头,标识符的长度没有限制,但是对大小写敏感。
int somename, Samename, SAMENAME, SameName;
其中C++的关键字不能作为标识符,如上所示:
| C++关键字 | ||||
|---|---|---|---|---|
| alignas | continue | friend | register | true |
| alignof | decltype | goto | reinterpret_cast | try |
| asm | default | if | return | typedef |
| auto | delete | inline | short | typeid |
| bool | do | int | signed | typename |
| break | double | long | sizeof | union |
| case | dynamic_cast | mutable | static | unsigned |
| catch | else | namespace | static_assert | using |
| char | enum | new | static_cast | virtual |
| char16_t | explicit | noexcept | struct | void |
| char32_t | export | nullptr | switch | volatitle |
| class | extern | operator | template | wchar_t |
| const | false | private | this | while |
| constexpr | float | protected | thread_local | const_cast |
| for | public | throw |
| C++操作符替代名 | ||||
|---|---|---|---|---|
| and | bitand | compl | not_eq | or_eq |
| xor_eq | and_eq | bitor | not | or |
名字作用域
作用域(scope)是程序的一部分,在其中名字有特定的含义。c++的大部分作用域的用花括号分隔。
同一个名字在不同的作用域中可能指向不同的实体。名字的有效区域始于名字的声明语句,也声明语句的所在的作用域未端未为结束。
复合类型
引用
引用(reference)为对象起了另外一个名字,引用类型引用(refers to)另外一种类型, 通过将声明符写成&d的形式来定义引用类型,其中d表示变量名。
int ival = 1021;
int &refval = ival; // refval指向ival(是ival的另一名字)
int &refval2; //error 引用必须被初始化
引用就是别名。
引用并非对象,相反的,它只是一个已经存在的对象的另外一个名字。
引用的定义
int i = 1024, i2 = 2048; // i和i2都是int
int &r = i, r2 = i2; // r是一个引用, r2 int
int i3 = 1024, &ri = i3; // i3(int) ri(引用)
int &r3 = i3, &r4 = i2; //r3 r4 引用
int &refval = 10; // error:引用类型的初始值必须是一个对象
double dval = 3.14; //double类型的数据
int &refval2 = dval; // error:引用类型的初始值必须是int类型的数据
指针(pointer)是“指向(point to)”另外一种类型的复合类型,与引用类似,指针也实现了对其他对象的间接访问,指针和引用也有很多的不同:
- 指针本身就是一个对象,允许对指针进行赋值和拷贝,而且在指针的生命周期内可以先后指向几个不同对象的值。
- 指针无需在定义的时候, 进行赋值操作, 和其他内置的类型一样,在定义域的指针如果没有被初始化, 就是会得到一个不确定的值。
定义指针的方式是:在变量名的前面加上一个*号,例如下面所示:
int *ip1, *ip2; //ip1和ip2都是指向int型的指针。
double dp, *dp2; // dp2是指向double型的指针, 而dp是double类对象。
获取对象的地址
指针存放某个对象的地址,要获取该地址, 这需要取地址符(&)。
int val = 123;
int *p = &val;
cout<<"id:"<<p<<endl;
cout<<"val:"<<*p<<endl;
result:
id:0x61fec8
val:123
double dval;
double *pd = &dval; //true:初始值是double型对象的地址
double *pd2 =pd; //true:初始值是指向double类型的指针
int *p1 = pd; //false:指针p1的类型和pd的类型不匹配
p1 = &dval; //false:试图将double型对象的地址赋值给int型指针。
指针值
指针的值(地址)应该属于下面的四种情况。
- 指向一个对象。
- 指向紧邻对象所占空间的下一个位置。
- 空指针,意味着指针没有指向任何的对象。
- 无效指针,上述情况之外的其他值。
某些符号的多重意义
int i = 40;
int &r = i; //&在变量名后面,声明的一部分,r是一个引用
int *p; // *在变量名后面,声明的一部分,r是一个指针
p=&i; // &出现在表达式中, 是一个取地址符
*p=i; // *出现在表达式中, 是一个解引用符
int &r2=*p; //&是声明的一部分, *是一个解引用符
空指针(null pointer)不指向任何的对象。下面的生成空指针的方法:
int *p1 = nullptr;//等价于:int *p1=0; C++11标准-新引用
int * p2 = 0; //直接将p2初始化为字面常量0
int *p3 = NULL; // *p3 =0;
int zeros = 0;
int *pi;
pi = zeros //error:不能将int变量直接赋值给指针
建议:初始化所以的指针
赋值和指针
int i = 42;
int *pi = 0; //pi被初始化,没有指向任何的对象
int *pi2 = &i;//pi2被初始化,存在i的内存
int *pi3; // 如果pi3定义于快内,则pi3的值是无法确定的(随机的)
pi3 = pi2; //pi3和pi2指向同一个对象i
pi2 = 0; //现在pi2不指向任何的对象了
pi = &ival;//pi的值被改变,现在pi指向ival
*pi = 0;//ival的值被改变,指针pi并没有改变
void*指针
void指针是一种特殊的指针,用于存放任何对象的地址。一个void指针存放一个地址,也一点与其他的指针类似。不同的是,我们对该地址中到底是个什么类型的对象并不了解。
double obj = 3.14;
double *pd = &obj; //void*能存放任意类型对象的地址
void *pv = &obj;//obj可以存放任意类型的对象
pv=pd;//pv可以存放任意类型的指针
复合类型的声明
定义多个变量
int *p;//容易产生误解
int *p1, p2;//p1指向int型的指针, p2是int
int *p1, *p2//p1和p2都是指向int型的指针
int *p1;
int *p2; //一个一个写
指向指针的指针
通过 * 的个数来区分指针的级别。也就是说,** 表示指向指针的指针,*** 表示指向指针的指针的指针,依次类推。
int ival= 1024;
int *pi = &ival; //pi指向一个int类型的数
int **pi = π //ppi指向应该int类型的指针
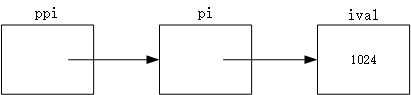
int ival= 1024;
int *pi = &ival; //pi指向一个int类型的数
int **ppi = π //ppi指向应该int类型的指针
cout<<"direct value:"<<ival<<endl;
cout<<"indirect value:"<<*pi<<endl;
cout<<"doubly indirect value:"<<**ppi<<endl;
direct value:1024
indirect value:1024
doubly indirect value:1024
指向指针的引用
int i = 42;
int *p; //p int的指针
int * &r =p;//r是对一个指针p的引用
r = &i;//r引用了一个指针,因此给r赋值&i就是令p指向i
*r = 0;//解引用r得到i,也就是p指向的对象, 将i的值改为0
const使用:
有时候, 我们希望定义这样一种变量,它的值不能被该变,在C++中,可以运用关键字const对变量进行限定。
例如如下所示:
const int i = 123;//True
const int i1; // 未初始化变量
i= 4556;//只读变量i的赋值(assignment of read-only variable 'i')
int i1 = 42;
const int c1 = i1; // i1的值拷贝给c1
int j = c1; //将c1的值拷贝给j
//如果想声明一个变量而非定义它,就在变量名前添加extern关键字,而且不要显式地初始化变量:
有时候有这种一种const变量,它的初始值不是应该常量的表达式, 但是却是有必要在文件间共享,我们想让一个文件中定义const,其他的文件中声明并使用它。
处理的方式是:
对于const变量不管是声明还是定义都添加extern关键字,这样就只需要定义一次就可以了。
//file.cpp
extern const int data = fun()'
//file_1.h 头文件
extern const int data;
当两个或者多个独立编译的源文件中使用了相同的模板并且提供了相同的模板参数时,每个文件中都会有该模板的一个实例。
模板控制的实例化
在大系统中,在多个文件中实例化相同的模板的额外开销可能非常严重,在C++11新标准中,我们可以通过显式实例化来避免这种开销。一个显式实例化具有如下形式:
extern template declaration; //实例化声明
template declaration; //实例化定义
declaration是一个类或函数的声明,其中所有的模板参数都已经被替换成为模板实参。例如:
extern template class vec<string>; //声明
template int sum(const int, const int); //定义
当编译器遇到extern模板声明时,它不会在本文件中生成实例化代码,将一个实例化声明为extern就表示承诺在程序的其他位置有该实例化的一个非extern定义。对于一个给定的实例化版本,可能有多个extern声明,但必须只有一个定义。
由于编译器在使用一个模板时自动对其实例化,因此extern声明必须出现在任何使用此实例化吧版本的代码之前。
由于以上讨论可知:extern一般是使用在多文件之间需要共享某些代码时。
const的引用
可以把引用绑定到const对象上,就像绑定带其他对象上一样,称为对常数的引用(reference to const),不能被用于修改它所绑定的对象。
const int ci = 1024;
const int &r1 = ci;// 正确:对应的对象都是常量
r1 = 42; //r1是对常量的引用(error: assignment of read-only reference 'r1')
int &r2 = ci;//错误:类型'int'和'const int'的绑定引用(error: binding reference of type 'int&' to 'const int' discards qualifiers)
初始化和对const的引用
引用的类型必须与所引用的对象类型相同, 但是两个例外。
初始化变量。
int i = 45;
const int &r1 = i; // 允许const int&绑定到一个普通的变量上
const int &r2 = 45; // r1是一个常量的引用
const int &r3 = r1*123; // r3是一个常量的引用
int &r4 = r1 * 2; // 不能将“int”的非const lvalue引用绑定到类型'int'的rvalue
double val = 123.0;
const int &data = val;
const int temple = val; //有双精度浮点数生成一个临时的int(整型)常量
//对const的引用可能引用一个并非const的对象
int i = 45;
int &ri = i;//引用ri绑定对象i
const int &r2 = i;//r2绑定对象i,但是不允许r2改变i的值
ri = 0;//ri并非常量,i的值修改成0
r2 =0; //error:r2是一个常量
指针和const
与引用一样, 可以令指针指向常量或非常量, 类似常量的引用,指向常量的指针(pointer to const)不能改变其所指对象的值,想要存放常量对象的地址, 只能使用指向常量的指针。
const double pi = 3.14;//pi是一个常量,它的值不能改变
double *ptr = π // ptr是一个普通的指针
const double * cptr = π //cptr可以指向一个双精度常量
*cptr = 42; // 不能给*cptr赋值
double values = 3.15;//values是一个双精度浮点数,它的值是可以改变
cptr = &val;//right:但是不能通过cptr改变values的值
指向常量的指针或引用,觉得自己指向了常量,所以自觉地不去改变所指对象的值。
const指针
常量指针(const pointer)必须初始化,而且一旦初始化完成,则它的值(也就是指针存放的地址)不能改变了,把*放在const关键字之前用也说明指针是一个常量, 也有另外一层的含义,即不变的是指针本身的值并非所指的那个值。
int errnumb = 0;
int *const curErr = &errNumbe;//curErr将一直指向errNumbe
const double pi = 3.14;
const double *const pip = π//pip是一个指向常量的指针
# include<iostream>
using namespace std;
int main(void)
{
int const a=123; // 初始化必须赋值
// a = 456; Error 不能给常量赋值
int b = 456;
int const *p; // const在*左边,表示*p为常量, 经*p不能更改指针所指的内容
p = &b;
//*p = 200; // "p" : 不能给常量赋值
int * const p2 = &b; // const在*右边,表示p2为常量
int c = 100;
/*p2 = &c;
*p2 = 200;*/ // 常数不能重新赋值
*p2 = 100;
cout << "p2:" << *p2 << endl;
return 0;
}
顶层const
指针本身是不是一个常量以及所指的是不是一个常量就是一个相互独立的问题,用名词顶层const(top-level const)表示指针本身是一个常量, 而用名词底层const(low-level const)表示指针所指的对象是一个变量。
顶层const也可以表示任意的对象是常量,底层const 则与指针和引用等复合类型的基本类型部分有关,指针的类型既可以是顶层const和底层const。
int i = 0;
int *const p1=&i;//不变改变p1的值,这是一个顶层const
const int ci = 42;//不能改变ci的值,这是一个顶层const
const int *p2 = &ci;//允许改变p2的值,这是一个底层const
const int *const p3 = p2;//靠右的const是一个顶层const,靠左的是一个底层const
const int &r = ci;//声明引用的const都是底层const
当执行对象拷贝时候,常量是顶层const是底层const和顶层const区别明显,顶层的const不受影响。
i=ci; //right:拷贝ci的值,ci是一个顶层const,
p2=p3;//right:p2 和 p3 都是底层const
p2 = &i;// right:int * 能转换为const int*
int &r = ci;//error:普通的int&不能绑定int常量上
const int &r2 = i;//right:const int&可以绑定到一个普通的int上
constexpr和常量表达式
一个对象(或表达式)是不是常量表达式是由它的数据类型和初始值共同决定的。
const int max_files = 20; //max_files是常量表达式
const int limit = max_files + 1; //limit是常量表达式
int staff_size = 27; //staff_size不是常量表达式
const int gz = get_size(); //sz不是常量表示式
constexpr变量
在复杂的系统,很难分辨一个初始值到底是不是常量的表达式。
在c++11新标准上,允许变量声明constexpr类型来让编译器来验证变量是值是否是一个常量表达式。声明constexpr的变量一定是一个常量,而且用常量表达式初始化。
constexpr int mf = 20; //20是一个常量的表达式
constexpr int limit = mf + 1;//mf + 1是一个常量表达式
constexpr int sz = size();//只要size是一个constexpr函数时,才是一条正确的声明语句
一般来说,你认定是常量表示式,那就把它声明成constexpr类型。
指针和constexpr
在constexpr声明中如果定义了指针,限位符constexpr仅对指针有效,与指针所指的对象无关。
const int *p = nullptr;//p是一个指向整型常量的指针(p指向常量指针)
constexpr int *q = nullptr;//q是一个指向整数的常量的指针(q一个常量指针)
// constexpr是将它所定义的对象置为了顶层的const
//constexpr指针可以指向常量,也可以指向非常量。
constexpr int *np = nullptr;//np是一个指向整型常量的指针,其值是0
int j = 0;
constexpr int i = 41;//i的类型是整型常量
constexpr const int *p = &i;//p是常量指针,指向整型变量i
constexpr int *p1 = &j;//p1是常量指针,指向整数j
处理类型
类型别名
类型别名(type alias)是一个名字,它是某种类型的同义词。
有两种方式定义类型别名,传统的方式是使用关键字typedef:
typedef double wages;//wages是double的同义词
typedef wages base , *p //base是wages的同义词,p是double*的同义词
另外一种方式是:使用关键字using作为别名声明的开始,其后面紧跟别名和等号,其作用是将左侧的名字规定成等号右侧类型的别名。
using SI = Sales_item; //SI是Sales_item的同义词
类型别名和类型的名字等价,只要是类型的名字能出现的地方,就能使用类型别名:
wages hourly , weekly;//等价于double hourly、weekly;
SI item;//等价于Sales_items item;
指针、常量和类型别名
如果某个类型的别名指的是复合类型或者常量,那么它用来声明语句会产生意想不到的错误。
typedef char* pestring;
const pestring cstr =0;//cstr是指向char的常量指针
const pestring *ps;// ps是一个指针,它的对象是指向char的常量的指针
const char *cstr = 0;//是对const pstringb cstr 的错误理解
auto类型说明符
我们常常需要将表达式的值赋值给变量,这就需要声明变量的时候知道表达式是值的类型。然而有时候, 我们做到这一点我们是不容易的,甚至是不可以的, 在c++11中引用了auto类型的说名符来解决这个问题。
在auto定义的时候的变量必须是有初始值的。
//有val1和val2相加的结果可以推断item的类型
auto item = val1 + val2;//item初始值是val1和val2相加的结果
如果val1和val2相加的类型是Sales_item类型,这item的类型也是Sales_item类型,如果两个类型是double,这相加的结果也double。
也可以auto也能在一条语句中声明多个变量,一条语句只能有一个数据类型。
auto i = 0, *p = &i;//i 是整型、p是整型指针
auto sz =0, pi =3.14;//error:sz是整型, pi浮点类型,两者类型不一致
复合类型、常量和auto
编译器推断出来的auto类型和初始值的类型并不是完全一致的,编译器和适当的改变了结果的类型使符合初始化规则。
int i = 0, &r = i;
auto a = r;//a是一个整数(r是i别名,而i是一个整数)
一般auto会忽略掉顶层的const,同时底层的const会保留下来,当指向常量的指针。
const int ci = i, &cr=ci;
auto b = ci;//b是一个整数(ci是顶层const的特性被忽略)
auto c = cr;//c是一个整数(cr是ci的别名,ci本身是一个顶层const)
auto d = &i;//d是一个整型的指针(整数的地址就是指向整数的指针)
auto e = &ci;//e是一个指向整数常量的指针(对象常量取地址一种底层const)
auto &g = ci;//g是一个整型常量的引用,绑定到ci
auto &h = 78;//error:不能将非常量绑定到字面值
const auto &j = 41;//可以为常量引用绑定字面值
auto k = ci, &l = i;//k是整型,l是整型引用
auto &m =ci, *p = &ci;//m是对整型常量的引用,p是指向整型常量的指针
auto auto &j = &ci;//error:i的类型是int,而&ci的类型是const int
decltype类型指示符
希望从表达式的类型推断出来要定义的变量和类型,但是不想用该表达式的值初化变量。在C++11引用了decltype,它的作用是返回操作数的数据类型,编译器分析表达式并得到它的类型,并不实际计算表达式值。
decltype(f()) sum = x;//sum的类型就是函数f的返回类型
decltype处理顶层const和引用的方式与auto方式有些不同,如果decltype使用的表达式是一个变量,则decltype返回该变量的类型(包括顶层const和引用在内)
const int ci = 0, &cj = ci;
decltype(ci) x = 0;//x的类型的const int
decltype(cj) y = x; y的类型是const int&, y绑定变量x
decltype(xj) z ;//error:z是一个引用,必须初始化
delctype和引用
//decltype的结果可以是引用的类型
int i= 42,*p = &i, &r = i;
decltype(r + 0) b; //right:加法的结果是int,因此b是一个(未初始化)int
decltype(*p) c;//error: c是int* ,必须初始化
//decltype的表达式如果是加上括号的变量,结果将被引用
decltype((i)) d;//error:d是int& ,必须初始化
decltype(i) e;//right:e是一个(未初始化的)int
decltype((variable))注意双层括号,如果是双层括号,结果永远被引用,而decltype(variable)结果只有当variable本身就是一个引用时才被引用。
自定义数据结构
C++语言允许用户与类形式定义数据结构,而库类型string 、istream 、ostream都是也类的形式定义的。
定义sales_data类型
Sales_data定义如下所示:
struct Sales_data{
std::string bookNo;
unsigned units_sold = 0;
double revenue = 0;
};
Sales_data也关键字struct开始,后面跟着类名和类体(类体可以为空),类体由花括号围成的新的作用域。
其他的方式
struct salues {/* */} accum, trans , *pointer;
struct salues1 {/* */}; accum, trans , *pointer;c++
不要忘记类定义后面的分号。
struct class_{};
编写自己的头文件
头文件通常包括了只能定义的一次的实体,如类、const、constexpr变量等,头文件也经常用到其他头文件的功能。如果在头文件中用到了string成员, 则我们必须包含string.h头文件。
头文件一旦改变,相关的源文件必须重新编译也获取更新说明。
预处理概述
确保头文件多次包含仍能安全的工作的常用的技术就是预处理(preprocessor),预处理在编译之前执行一段程序,可以部分改变我们的代码。例如#include, 就是将include 替换为头文件
C++程序
还会使用头文件预处理功能,叫作头文件保护符(header),预处理变量的两种状态是:已定义和未定义。
#define指令把名字设置为预处理变量, 另外两个指令则分别检查某个指点的预处理变量是否已经定义:#ifdef当且仅当也定义时为真,#ifndef当且仅当变量未定义为真时,一旦检查结果为真,执行后续的操作,直到遇到#endif指令为止。
使用这些功能有效的防止重复操作的发生。
在理论上来说可以是自由命名的,但每个头文件的这个“标识”都应该是唯一的。标识的命名规则一般是头文件名全大写,前后加下划线,并把文件名中的“.”也变成下划线,如:stdio.h
#ifndef _STDIO_H_
#define _STDIO_H_
......
#endif
#ifndef xxx//如果没有定义xxx
#define xxx//定义xxx
#endif //结束如果
add.h
#include<iostream>
using namespace std;
#ifndef TEST1_ADD_H
#define TEST1_ADD_H
double add(double a, double b)
{
double add_res = a + b;
cout<<"add:"<<add_res<<endl;
}
#endif //TEST1_ADD_H
main.cpp
#include "add.h"
int main() {
add(1.0, 2.0);
return 0;
}
add:3
字符串、向量和数组
定义和初始化对象
string对象的常见的初始化的方式:
string s1;// 默认初始化
string s2 = s1;// s2是s1的副本 等价于s2(s1)
string s3 = "hello";// s3是字符串面值的副本
string s4(10, 'c');// s4的值为cccccccccc
string s5("values")//等价于s5= values
直接初始化和拷贝初始化
如果使用"="号初始化变量,实际上执行的是拷贝初始化(copy initialization),编译器将右边的初始值拷贝到新创建的对象之中,与之相反,如果不使用等号,则就是执行的直接初始化(direct initialization)。
#include<string>
string str = "hello";// 拷贝初始化
string data("values");// 直接初始化
string data1(10, 'd');//直接初始化data1的值是;10个
string对象上的操作
os<<s; 将s写到输出流os当中,返回os
is>>s; 从is中读取字符串赋给s,字符串以空白分隔,返回is
getline(is, s) 从is中读取一行赋给s,返回is
s.empty(); s为空返回true,否则返回false
s.size(); 返回s中字符的个数
s[n]; 返回s中第n个字符的引用,位置从0计起
s1 + s2; 返回s1和s2连接后的结果
s1 = s2; 用s2的副本代替s1中原来的字符;
s1 == s2; 如果s1和s2中所含字符完全一样,,则它们相等;string对象的相
s1 != s2; 等性判断对字母的大小写敏感
<,<=,>,>= 利用字符在字典中的顺序进行比较,且对字母的大小写敏感
读入string对象
string s;
cin >> s;
cout << s << endl;
return 0;
获取未知数量的string
int main()
{
string word;
while (cin >> word)
{
cout << word << endl;
}
system("pause");
return 0;
}
this is good idea!
answer:
this
is
good
idea!
getline获取一整行
int main()
{
string line;
while(getline(cin, line))
{
cout << line << endl;
}
system("pause");
return 0;
}
this is good idea!
answer:
this is good idea!
string的empty 和size操作
empty是判断string对象是不是为空。
size返回的是string对象的长度。
while(getline(cin, line))
{
if (!line.empty())//如果为空
{
cout << "None" << endl;
}
}
string line;
while(getline(cin, line))
{
cout << line.size() << endl;//获取string长度
}
test--->test字符串
4--len()
比较string对象
- 如果两个字符串对象的长度不同,而且较短string对象的每个字符都与较长string对象那对应位置上的字符相同,就说较短的字符串小于较长的字符串。
- 有一个两个字符串在在某个对应的位置不相同,则string对象比较,就是第一个相异字符串之间的比较结果。
字符串的赋值和相加
string st1(10, 'x') ,st2;
st1 = st2; //st1也为空
//字符串相加
string s1 = "hello";
string s2 = "world!";
string s3 = s1 + s2; //helloworld!
string s4 = s1 + "," + s2;//hello,world!
string s5 = (s1 + ",") + "world!!!!!";
// string s5 = (s1 + ",") + s2;//error:字面值不能直接相加
处理字符串对象的字符
在cctype.h中定义了一些处理字符串的方法
isalnum(c) //当c是字母或数字时为真
isalpha(c)//当c为字母时为真
iscntrl(c)//当c为控制字符为真
isdigit(c)//当c为数字为真
isgraph(c)//当c不是空格,打印时为真
islower(c)//当c是小写字母时为真
isupper(c)//当c是大写字母时为真
isprint(c)//当c是可打印字符为真(即c是空格或是其他可视形式)
ispunct(c)//当c是标点符号为真(c不是控制字,数字等)
isspace(c)//当c是空白为真(空格、横向制表符、纵向制表符、回车符、换行符、进纸符中一种)
isxdigit(c)//当为16精制数字为真
tolower(c)//大写字母转换为小写,否则原样输出c
toupper(c)//小写转换为大写,否则原样输出c
string str("hello world!");
decltype(str.size()) punct_cnt = 0;//punct_cnt和str.size()返回的类型相同
for (auto c : str)
{
if (ispunct(c))// 当c为符号为真
{
++punct_cnt;
}
}
cout << punct_cnt << str << endl; // 1hello world!
for (auto &c : str)//对于str中的每个字符(c:的引用)
{
c = toupper(c);//转换位大写
cout << c;//HELLO WORLD!
}
string str("hello world!");
cout << str[str.size()-2] << endl;//d
cout << str[str.size()-1] << endl;//!
string的下标必须大于等于0而小于string.size()。
string string_data = "some string";
if (!string_data.empty())
{
string_data[0] = toupper(string_data[0]);
cout << string_data << endl;
}
for (decltype(string_data.size()) index = 0; index != string_data.size() && !isspace(string_data[index]); ++index)
string_data[index] = toupper(string_data[index]);
cout << string_data << endl;
answer:
Some string
SOME string
标准库类型
标准库类型vector表示对象的集合,其中所有的对象都是相同的。集合中的每个对象都与一个与之对应的索引,索引用于访问对象,由于vector容纳了所有的对象,称为容器(container)。
vector<int> a; //a保存int的变量
vector<Sales_item> sales_item;//sales_item保存Sales_item类型的变量
vector<vector<string>> file;//该向量元素是vector的对象
编译器会生成三不同的类型(vector<<int>、vector<\Sales_item>、vector<vector<string>>)
vector是模板而非类型,由vector生成的类型必须包含vector中的元素类型。
定义和初始化vector对象
初始化vector对象的方法
vector <T> v1; // v1是一个空的vector,它潜在的元素是T类型的,执行默认初始化
vector <T> v2(v1); //v2中包含有v1元素的所以的副本
vector <T> v2=v1; //等价于v2(v1),v2中包含有v1元素的所以的副本
vector <T> v3(n, val); //v3包括了n个重复的元素,每个元素的值都是val
vector <T> v4(n); //v4包括了n个重复地执行了初始化的对象
vector <T> v5{a,b,c,...}; //v5包含了初始值个数的元素,每个元素被赋予相应的初始值
vector <T> v5 = {a, b, c, ...};//等价于v5{a, b, c ...}
vector<int> ivec;//初始状态为空
vector<int> ivec1(ivec);//把ivec的值拷贝个ivec1
vector<int> ivec2 = ivec;//把ivec的值拷贝个ivec3
vector<string> svec(ivec)//error:类型不匹配 string和int
初始化vector对象 ####
vector<string> string_data{ "this", "is", "test" };//列表初始化
vector<int> int_data(10, 1);//10个int元素,每个初始值为1
vector<string> string_data1(10, "hi");//10个string元素, 每个初始值为“hi”
vector<int> int_data1(10);//10个元素,每个初始化为0
vector<string> string_data2(10);//10个元素,每个都是空string对象
vector<int> v1(10);//v1:10个元素,每个值为0
vector<int> v2{ 10 };//v2有一个元素,元素值为10
vector<int> v3(10, 1)//v3:10个元素, 每个值为1
vector<int> v4{ 10, 1 };//v4:两个元素,值是10, 1
vector<string> v5{ "hi" };//v5:一个元素,值为“hi”
vector<string> v6("hi");//v6:error:不能通过字符串面值来构建vector对象
vector<string> v7{10}//v7:10个默认初始值
vector<string> v8{ 10, "hi" };//v8:10个“hi”值
vector<int> v()/{} 如果是圆括号表示(个数,值)如果是{值1,值2...}
vector<string> v{} 有这几种类型{个数},值是默认,{个数, 值},{字符串,...}
向vector对象添加元素
vector<int> int_data;
for (int i = 0; i < 100;i++)
{
int_data.push_back(i);//依次将整数放在int_data的后面 添加元素push_back(i)
}
for (int i = 0; i < int_data.size(); i++)//迭代显示数据
{
cout << int_data[i]<<"-";
}
vector其他的函数操作
(1)a.assign(b.begin(), b.begin() + 3); //b为向量,将b的0~2个元素构成的向量赋给a
(2)a.assign(4, 2); //是a只含4个元素,且每个元素为2
(3)a.back(); //返回a的最后一个元素
(4)a.front(); //返回a的第一个元素
(5)a[i]; //返回a的第i个元素,当且仅当a[i]存在2013-12-07
(6)a.clear(); //清空a中的元素
(7)a.empty(); //判断a是否为空,空则返回ture,不空则返回false
(8)a.pop_back(); //删除a向量的最后一个元素
(9)a.erase(a.begin() + 1, a.begin() + 3); //删除a中第1个(从第0个算起)到第2个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+ 3(不包括它)
(10)a.push_back(5); //在a的最后一个向量后插入一个元素,其值为5
(11)a.insert(a.begin() + 1, 5); //在a的第1个元素(从第0个算起)的位置插入数值5,如a为1,2,3,4,插入元素后为1,5,2,3,4
(12)a.insert(a.begin() + 1, 3, 5); //在a的第1个元素(从第0个算起)的位置插入3个数,其值都为5
(13)a.insert(a.begin() + 1, b + 3, b + 6); //b为数组,在a的第1个元素(从第0个算起)的位置插入b的第3个元素到第5个元素(不包括b+6),如b为1,2,3,4,5,9,8 ,插入元素后为1,4,5,9,2,3,4,5,9,8
(14)a.size(); //返回a中元素的个数;
(15)a.capacity(); //返回a在内存中总共可以容纳的元素个数
(16)a.resize(10); //将a的现有元素个数调至10个,多则删,少则补,其值随机
(17)a.resize(10, 2); //将a的现有元素个数调至10个,多则删,少则补,其值为2
(18)a.reserve(100); //将a的容量(capacity)扩充至100,也就是说现在测试a.capacity();的时候返回值是100.这种操作只有在需要给a添加大量数据的时候才 显得有意义,因为这将避免内存多次容量扩充操作(当a的容量不足时电脑会自动扩容,当然这必然降低性能)
(19)a.swap(b); //b为向量,将a中的元素和b中的元素进行整体性交换
(20)a == b; //b为向量,向量的比较操作还有!=,>=,<=,>,<
元素访问
vector<int> v{ 1,2,3,4,4,5,6 };
for (auto &i : v)
{
i *= i;
}
for (auto i : v)
{
cout << i << " " << endl;
}
迭代器(iterator)
我们知道运用下标运算符来访问string对象的字符或vector对象的元素,还有另外一种更加通用的机制可以实现这种目的, 那就是迭代器(iterator)。
使用迭代
和指针不同,获取迭代器不是使用取地址符,有迭代器的类型同时拥有返回迭代器成员。比如,这些类型都拥有名为begin和end的成员。其中begin成员负责返回指向第一个元素(或第一个字符)的迭代器。
//b表示v的第一个元素,e表示v尾的下一个位置元素
auto b = v.begin() , e = v.end()//b和e的类型相同
如果迭代器为空,则begin和end返回的都是同一个迭代器,都是尾后迭代器。
迭代器的运算符
标准容器迭代器的运算符
*iter //对iter进行解引用,返回迭代器iter指向的元素的引用
iter->men //对iter进行解引用,获取指定元素中名为men的成员。等效于(*iter).men
++iter //给iter加1,使其指向容器的下一个元素
iter++
--iter //给iter减1,使其指向容器的前一个元素
iter--
iter1==iter2 //比较两个迭代器是否相等,当它们指向同一个容器的同一个元素或者都指向同同一个容器的超出末端的下一个位置时,它们相等
iter1!=iter2
将第一个字母大写
string s("some string");
if (s.begin() != s.end())//确保非空
{
auto it = s.begin();//it是s的第一个字符
*it = toupper(*it);//将当前的字符变成大写子母
}
cout << s << endl;
answer:Some string
for (auto it = s.begin(); it!= s.end() && !isspace(*it); ++it)
{
*it = toupper(*it);//将当前的字符变成大写子母
}
cout << s << endl;
answer:
SOME string
迭代器的类型
迭代器使用了标准库中iterator和const_iterator来表示迭代的类型。
vector<int>::iterator it;//it能写读vector<int>的元素
string::iterator it2;//it2只能读写string对象的字符
vector<int>::const_iterator it3;//it3只能读,不能写元素
string::const_iterator it4;////it4只能读,不能写元素
begin和end返回的具体类型由对象是否为常量决定,如果对象是常量,begin和end返回const_iterator,如果对象为常量,返回iterator:
vector<int> v;
const vector<int> cv;
auto it1 = v.begin();//it1的类型vector<int>::iterator
auto it2 = cv.begin();//it2的类型vector<int>::const_iterator
auto it3 = v.cbegin();//it3的类型vector<int>::const_iterator
(*it).empty()//解引用it,然后调用对象的empty成员
箭头运算符(->),箭头运算把解引用和成员访问两个操作结合起来,也就是说 it->men 和(*it)->men表达的意思相同。
迭代器运算
迭代器的递增运算令迭代器每次移动一个元素,标准库容器都支持递增运算的迭代器。
string和vector迭代器其他的运算符
| 表达式 | 意义 |
|---|---|
| iter+n | 迭代器加上一个整数仍是一个迭代器,迭代器指示的新位置与原位置相比向前移动了若干个元素。 |
| iter-n | 迭代器减去一个整数仍是一个迭代器,迭代器指示的新位置与原位置相比向后移动了若干个元素。 |
| iter1+=n | 复合赋值语句,将iter1加n的值赋值给iter1。 |
| iter1-=n | 复合赋值语句,将iter1减n的值赋值给iter1。 |
| iter1-iter2 | 两个迭代器相减表示他们之间的距离。 |
| >、>=、<、<= | 关系运算符,如果迭代器的指向的位置在另外一个迭代器的所指的位置之前,则前者小于后者。 |
数组
定义和初始化内置数组
数组是一种复合类型,数组的形式是a[d],a代表了数组的名,d代表数组的维度,维度表示数组的元素个数,必须大于0, 数组的维度必须是一个常量表达式。
unsigned cnt = 42;//不是常量表达式
constexpr unsigned sz = 24;//常量表达式
int arr[10];//10个整数的数组
int *arr1[10];//10个整数的指针数组
int array1[cnt];//error:cnt不是常量表达式
string strs[get_size()];//当get_size()为constexpr时正确
和内置的变量一样,如果在函数内部定义了某种内置的类型的数组,那么默认初始化会令数组含未知值。
显示初始值数组值
const int size = 3;
int arr[size]={1, 2, 3};
int arr1[] ={1, 2, 3};
int arr2[5]={1, 2, 3};
string string_array[3]={"a","b", "c"};
string string_array[2]={"a","b", "c"};//error 初始值过多
char data[] = "char";
char a1[]={'c', '+', '+', '\n'};
const char a2[6]="Daniel"; //error:没有空间存放空字符
//不允许拷贝和赋值
int a[]={1,2, 3};
int a1[] = a;//不允许使用一个数组初始化为另外一个数组
a1 = a;//不能把一个数组直接赋值给另外的数组
复杂的数组声明
和vector一样, 数组能存放大多数类型的对象,例如存放一个指针的数组。数组本身就是对,允许对数组的引用和定义数组指针。
int *ptrs[10];//ptrs是含有10个整型指针的数组
int &refs[10]="*?*";//error:不存在的引用
int (*parray)[10]=&arr;//parray指向一个含有10个整数的数组
int(&arrRef)[10]=arr;//arrRef引用一个含有10个整数的数组
访问数组元素
int a[100];
for (int i = 0; i < 100;i++)
{
a[i] = i;
}
for (auto i : a)
cout << i <<" ";//打印100个数字
数组和指针
使用地址符&来获取某个对象的指针,适用于如何的对象,对数组取地址符得到该元素的指针。
string num[] = { "a", "b", "c", "d" };
string *p1 = num;//等价于:p1=&num[0]
string *p = &num[0];//p指向num的第一个元素
int a[]={1, 2, 3, 4, 5, 6, 7, 8};//10个整型元素
auto ia2(a);//ia2是一个整型的指针,指向第一个数
ia2 = 42;//ia2是指针,不能将整数赋值给指针
int a[8]={1, 2, 3, 4, 5, 6, 7, 8};
auto id2(a);//values:1
auto id3(&a[0]);//id3是一个int* *id3对指针的值 id3:0x61fea8
decltype(a) ia3 ={0, 1, 2, 3, 4, 5, 5};
int arr[]={0, 2, 3};
int *p = arr;// 指向arr[0]
++p;// 指向arr[1]
// 标准库的begin和end
int a[8]={1, 2, 3, 4, 5, 6, 7, 8};
int * beg=begin(a);// 指向a首元素的指针
int * end_ = end(a);// 指向a尾元素的下一个位置的指针
// 指针运算
constexpr size_t size = 5;
int arr[size] = {1, 2, 3, 4, 5};
int *p = arr;// *p = &arr[0];
int *p2 = p+ 4;// p2-->arr[4]
// 和迭代器一样 指针两者相减表示两者之间的距离
int a[8]={1, 2, 3, 4, 5, 6, 7, 8};
auto x = end(a) - begin(a);// 两者之间的距离 8
int last = *(a + 4);// 表示last=a[4]
int last1 = *(a)+4;// 表示a[0]+4
// 下标和指针
int a[8]={1, 2, 3, 4, 5, 6, 7, 8};
int i= a[3];
i = *(p + 2);//-->i=a[2]
int *p = a; // 指向a[0]
int *p = &a[2];
int ia[8]={1, 2, 3, 4, 5, 6, 7, 8};
int *p = &ia[2];
int j = p[1]; // p[1]==>*[p+1] = ia[3]
int k = p[-2];//表示p[-2]是ia[0]表示的那个元素
C风格字符串
c语言风格字符串的函数。
| function | meaning |
|---|---|
| strlen(p) | 返字符串的长度,不包括空字符在内。 |
| strcmp(p1, p2) | 比较配p1和p2的相等性,如果p1==p2, 返回0,如果p1>>p2,返回一个正值,如果p1<<p2,返回一个负值。 |
| strcat(p1,p2) | 将p2附加给p1,return p1 |
| strcpy(p1,p2) | 将p2拷贝给p1 |
多维数组
当一个数组的元素也是数组时,就表示多维数组。
一个数组表示本身的大小,另外一个数组表示其元素的大小。
int ia[3][4];//大小为3的数组,每个元素含有4个整数是数组
int arr[10][20][30]={0};//数组含有30个整数的数组,初始化为0
数组的定义:
int arr[3][4]={
{1, 2, 3, 4},//第1行初始值
{1, 2, 3, 4},//第2行初始值
{1, 2, 3, 4} //第3行初始值
};
// 内嵌的花括号不是必要
int a[3][4]={1, 2, 3, 4,1, 2, 3, 4,1, 2, 3, 4}; // 3*4 //和上面定义一样
// 显示每行的初始值,其他默认
int b[3][4]= {{1},
{2},
{3},
};
// 显示一行,其他默认
int a[3][4]={1, 2, 3, 4};
多次嵌套处理数组
constexpr size_t rowcnt = 3, colcnt=4;
int ia[rowcnt][colcnt];
for(size_t i = 0; i!=rowcnt; ++i)
{
for(size_t j=0;j!=colcnt;++j)
{
ia[i][j]=i* colcnt + j;
}
}
//C++11标准中 for处理多维数组
size_t cnt = 0;
for (auto &row: arr)// 对外层的每一个元素
for (auto &col: row){ //对内层的每一个元素
col = cnt;//将下一个元素的值赋值给该元素
++cnt; //cnt加1
}
在使用for语句处理多维数组,除了最内层的循环外,其他的所以的循环的控制变量都一个是引用类型。
指针和多维数组
当程序使用多维数组的名字时,也会自动的转换成为指向数组首地址的指针。
在定义指向多维数组的指针时,千万不要忘记了这了这个数组其实是数组的数组。
由于多维数组是数组中的数组,所以有多维数组名转换位来的指针实际是指向第一个内层数组的指针。
int a[3][4]; //大小为3的数组,每个元素含有4个整数的数组
int (*p)[4]=a;//p==>4个整数的数组
//圆括号
int *ip[4];//整型指针的数组
使用auto或者decltype就能尽可能的避免在数组前面加一个指针类型了。
// 输出ia中是每个元素,每个内层的数组各占一行
//p指向含有4个元素的数组
for(auto p=ia;p!=ia+3;++p)
{ //q指含有4个元素的数组
for(auto q=*p; q!=*p=4;++p)
cout<<*q<<endl;
}
//使用标准库的函数begin和end
for(auto p=begin(ia);p!=end(ia);++p)
{ //q指向内层的数组的首元素
for(auto q=begin(*p);q!=end(*p); ++q)
cout<<*q<<endl;//输出q所指的数值
}
表达式
算术运算符
| 运算符 | 功能 | 用法 |
|---|---|---|
| + | 一元正号 | +expr |
| - | 一元负号 | -expr |
| * | 乘法 | expr1 * pxpr2 |
| / | 除法 | expr1 / expr2 |
| % | 求余 | expr1 % expr2 |
| + | 加 | expr1 + expr2 |
| - | 减 | expr1 - 0expr2 |
逻辑和关系运算符
| 结合律 | 运算符 | 功能 | 用法 |
|---|---|---|---|
| 右 | ! | 逻辑非 | !expr |
| 左 | < | 小于 | expr < expr |
| 左 | <= | 小于等于 | expr <= expr |
| 左 | > | 大于 | expr > expr |
| 左 | >= | 大于等于 | expr >= expr |
| 左 | == | 等于 | expr == expr |
| 左 | != | 不相等 | expr != expr |
| 左 | && | 逻辑与 | expr && expr |
| 左 | || | 逻辑或 | expr || expr |
sizeof运算符
sizeof运算符返回一条表达式或一个类型名字所占的字节数,sizeof运算符支持结合律,得到的值是size_t类型(size_t一般用来表示一种计数,比如有多少东西被拷贝等,保证能容纳实现所建立的最大对象的字节大小)。
运算符对象的两种形式:
- sizeof(type)
- sizeof expr
第二种中,sizeof返回是表达式类型的大小。
// example:
Sales_data data *p;//
sizeof(Sales_data);//Sales_data类型的对象所占的空间大小
sizeof data;//data的类型的大小,即sizeof(Sales_data)
sizeof p;//指针所站的空间大小
sizeof *p;//p所指类型的空间大小,sizeof(Sales_data)
sizeof data.revenue;//Sales_data的revenue成员对应类型的大小
sizeof Sales_data::revenue;//Sales_data的revenue成员对应类型的大小
位运算符(左结合律)
| 运算符 | 功能 | 用法 |
|---|---|---|
| ~ | 位求反 | ~expr |
| << | 左移 | expr1 << expr2 |
| >> | 右移 | expr1 >> expr2 |
| & | 位与 | expr1 & expr2 |
| ^ | 位异或 | expr1 ^ expr2 |
| | | 位异 | expr1 | expr2 |
类型转换
类型转换有两种,隐式转换和显示转换。
隐式转换:编译器会自动转换对象的类型。
- 在大多数的表达式,比int类型的小的整型值首先提升为较大的整型类型。
- 在条件中,非布尔值转化位布尔类型。
- 初始化过程中,初始值转换为变量类型,在赋值的语句中,右侧运算对象转换成左侧运算对象的类型。
- 如果算术运算或关系运算的运算对象有多种类型,需要转换同一种类型。
- 函数调用发生类型转换。
显示转换:有时候我们不得不使用显示转换,也下面的代码为例,显示转换将两个int的数据相除得到double类型。
int i, j:
double div_= i/j;//强制转换
虽然有时候我们不得不使用强制转换,本质是危险的。
强制转换类型转换命名习惯cast_name
cast_name是static_cast、dynamic_cast、const_cast、reinterpret_cast中的一种。
static_cast
任何具有明确定义的类型转换,只要不包括底层的const,都能使用static_cast。
- 编译器隐式执行的任何类型转换都可以用static_cast完成。
- 当一个较大的数赋值给一个较小的类型,可以用static_cas进行强制转换。
- 可以将void*指针转换为某一类的指针。
- 可以将基类指针指向派生类指针。
double slop = static_cast<double>(j)/i;
void *p=&d;
double *dp = static_cast(double)(p);
const_cast
const_cast只能改变运算对象底层的const。
- 用于移除对象的常量性。
- const_cast一般由于指针或者引用。
- 使用const_cast去除const限定不是为了修改它的内容。
- 使用const_cast去除const限定,通常是为了常数能够接受这个实际的参数。
const char *pc;
char *p = const_cast<char*>(pc);
//p
reinterpret_cast
reinterpret_cast通常为运算对象的位模式较低层次上的重新解释。
int *p;
char *pc = reinterpret_cast<int>(p);
pc所指的真实的对象是一个int而非字符。
运算符优先级
| 优先级 | 操作符 | 描述 | 例子 | 结合性 |
|---|---|---|---|---|
| 1 | () [] -> . :: ++ -- | 调节优先级的括号操作符 数组下标访问操作符 通过指向对象的指针访问成员的操作符 通过对象本身访问成员的操作符 作用域操作符 后置自增操作符 后置自减操作符 | (a + b) / 4; array[4] = 2; ptr->age = 34; obj.age = 34; Class::age = 2; for( i = 0; i < 10; i++ ) ... for( i = 10; i > 0; i-- ) ... | 从左到右 |
| 2 | ! ~ ++ -- - + * & (type) sizeof | 逻辑取反操作符 按位取反(按位取补) 前置自增操作符 前置自减操作符 一元取负操作符 一元取正操作符 解引用操作符 取地址操作符 类型转换操作符 返回对象占用的字节数操作符 | if( !done ) ... flags = ~flags; for( i = 0; i < 10; ++i ) ... for( i = 10; i > 0; --i ) ... int i = -1; int i = +1; data = *ptr; address = &obj; int i = (int) floatNum; int size = sizeof(floatNum); | 从右到左 |
| 3 | ->* .* | 在指针上通过指向成员的指针访问成员的操作符 在对象上通过指向成员的指针访问成员的操作符 | ptr->var = 24; obj.var = 24; | 从左到右 |
| 4 | * / % | 乘法操作符 除法操作符 取余数操作符 | int i = 2 * 4; float f = 10 / 3; int rem = 4 % 3; | 从左到右 |
| 5 | + - | 加法操作符 减法操作符 | int i = 2 + 3; int i = 5 - 1; | 从左到右 |
| 6 | << >> | 按位左移操作符 按位右移操作符 | int flags = 33 << 1; int flags = 33 >> 1; | 从左到右 |
| 7 | < <= > >= | 小于比较操作符 小于或等于比较操作符 大于比较操作符 大于或等于比较操作符 | if( i < 42 ) ... if( i <= 42 ) ... if( i > 42 ) ... if( i >= 42 ) ... | 从左到右 |
| 8 | == != | 等于比较操作符 不等于比较操作符 | if( i == 42 ) ... if( i != 42 ) ... | 从左到右 |
| 9 | & | 按位与操作符 | flags = flags & 42; | 从左到右 |
| 10 | ^ | 按位异或操作符 | flags = flags ^ 42; | 从左到右 |
| 11 | | | 按位或操作符 | flags = flags | 42; | 从左到右 |
| 12 | && | 逻辑与操作符 | if( conditionA && conditionB ) ... | 从左到右 |
| 13 | || | 逻辑或操作符 | if( conditionA || conditionB ) ... | 从左到右 |
| 14 | ? : | 三元条件操作符 | int i = (a > b) ? a : b; | 从右到左 |
| 15 | = += -= *= /= %= &= ^= |= <<= >>= | 赋值操作符 复合赋值操作符(加法) 复合赋值操作符(减法) 复合赋值操作符(乘法) 复合赋值操作符(除法) 复合赋值操作符(取余) 复合赋值操作符(按位与) 复合赋值操作符(按位异或) 复合赋值操作符(按位或) 复合赋值操作符(按位左移) 复合赋值操作符(按位右移) | int a = b; a += 3; b -= 4; a *= 5; a /= 2; a %= 3; flags &= new_flags; flags ^= new_flags; flags |= new_flags; flags <<= 2; flags >>= 2; | 从右到左 |
| 16 | , | 逗号操作符 | for( i = 0, j = 0; i < 10; i++, j++ ) ... | 从左到右 |
语句
-
表达式语句:是最简单的语句形式,一般格式为:表达式;
-
空语句:只由一个分号构成的语句,一般格式为: ;
注意:
-
空语句不执行任何操作,但具有语法作用。例如:for循环在有些情况下,循环体或者循环判别条件是空语句。
-
从程序结构的紧凑性与合理性角度考虑,尽量不要随便使用空语句。
-
-
复合语句:由“{}”括起来的一组语句,一般格式为:
注意:
- 复合语句描述一个块,在语法上起一个语句的作用。
- 复合语句中的每个语句以“;”结束,而整个复合语句的结束符为“}”。
-
流程控制语句:用来控制或改变程序的执行方向的语句。
条件语句
if语句表达式
//if表达式
if(condition)
statement
//if else语句的形式
if(condition)
statement
else
statement
//嵌套的if
if(condition)
statement
else if
statement
......
example:
const vector<string> scores = {"F", "E","D", "C", "B", "A"};
//小于60:F,也10分为刻度进程
if(grade<60)
lettergrade=scores[0];
else
lettergrade=scores[(grade-50)%10];
//嵌套if
if(grade %10 >7)
lettergrade+="+";//8-9添加+
else if (grade %10 <3)
lettergrade+="-";//0 1 2添加-
switch语句
unsigned aCnt = 0, eCnt = 0, iCnt = 0, oCnt = 0, uCnt = 0;
unsigned spaceCnt = 0, tabCnt = 0, newlineCnt = 0;
char ch;
cout << "请输入一段文本(之后敲回车 ctrl+z 回车):" << endl;
while (cin.get(ch))
{
switch (ch) {
case 'a':
case 'A':
++aCnt;
break;
case 'e':
case 'E':
++eCnt;
break;
case 'i':
case 'I':
++iCnt;
break;
case 'o':
case 'O':
++oCnt;
break;
case 'u':
case 'U':
++uCnt;
break;
case ' ':
++spaceCnt;
break;
case '\t':
++tabCnt;
break;
case '\n':
++newlineCnt;
break;
}
}
cout << (aCnt + eCnt + iCnt + oCnt + uCnt) << endl;
cout << (spaceCnt + tabCnt + newlineCnt) << endl;
return 0;
迭代语句
while语句
只要条件为真,while语句 就会重复执行statement,condition不能为空,如果condition第一次求值是false, statement一次都不执行。
while(condition)
statement
定义在while条件部分或者在while循环体在内的变量每次迭代都经历了从创造到被销毁的过程。
使用while循环
当不知道循环多少次数的时候,就可以使用while循环,满足一定的条件,就可以了。
int i = 0;
while (i < 10)// 条件
{
int square_i = i * i;
cout << square_i << endl;
i++;
}
vector<int> v;
int i;
while (cin >> i)
v.push_back(i);
auto beg = v.begin();
while (beg != v.end() && *beg >= 0)
++beg;
if (beg == v.end())
;
for循环
语法形式
for(init_statemen;condition;expression)//空语句,条件,表达式(可以多个,也","进行隔开)
statement
//init_statemen:声明语句、表达式语句、空语句
for (int i = 0; i < 10;i++)
{
int square_i = i*i;
cout << square_i << endl;
}
//for语句头的某些部分为空
auto beg = v.begin();
for (/* 空语句*/;beg != v.end() && beg >= 0; ++beg)
{
;
}
for (int i = 0; /*条件为空*/;++i) {
;
}
vector<int> v;
for(int i=0;cin>>i; /* 表达式为空*/)
{
v.push_back(i);
}
do while
表达式:
do
statement
while(condition)
跳转语句
break语句
break语句附近的终止它最近的while、do while、for、switch语句。
break语句只能出现的在迭代语句和switch语句之中,break语句的作用范围仅限于最近的循环或者switch:
//example
for (int i = 0; i < 9; i++)
{
if (i == 5)
break;//跳出for循环
cout << i << endl;
}
continue语句
终止本次循环的执行,即跳过当前一次循环中continue语句后尚未执行的语句,然后进行下一次循环条件的判断。
goto语句
goto语句的作用是从goto语句无条件跳转到同一个函数内的另一条语句中。
不要在程序中使用goto语句,使得程序难以理解又难修改。
语法形式
goto label;
..
.
label: statement;
//example
// 局部变量声明
int a = 10;
// do 循环执行
LOOP:do
{
if( a == 15)
{
// 跳过迭代
a = a + 1;
goto LOOP;
}
cout << "a 的值:" << a << endl;
a = a + 1;
}while( a < 20 );
goto 语句一个很好的作用是退出深嵌套例程。
for(...) {
for(...) {
while(...) {
if(...) goto stop;
.
.
.
}
}
}
stop:
cout << "Error in program.\n";
try语句块和异常处理
异常是指运行时的反常行为,超过了函数正常功能的范围。
C++异常包括了:
- throw表达式(throw expression),异常检测部分使用throw表达式来表它遇到的了无法处理的问题,我们说throw引发了异常。
- try语句块(try back),异常处理部分使用try语句块处理异常。try语句块也关键字try开始,并也一个或多个 catch子句(catch clause)结束。try语句块中的代码抛出的异常通常会被某个catch子句处理。因为catch子句“处理”异常,所以他们称为异常处理代码(exception handler)
- 一套异常类(exception class),用于throw表达式和相关的 catch子句之间的传递异常的具体信息。
throw表达式
程序的异常检测部分使用throw表达式引发异常,throw表达式包括了关键字throw和紧跟其后的一个表达式,其中表达式的类型就是抛出的异常类型。throw后面紧跟一个分号,从而构成一条表达式语句。
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。使用 try/catch 语句的语法如下所示:
try {
// 保护代码
}catch( ExceptionName e1 )
{ // catch 块
}catch( ExceptionName e2 )
{ // catch 块
}catch( ExceptionName eN )
{ // catch 块 }
如果 try 块在不同的情境下会抛出不同的异常,这个时候可以尝试罗列多个 catch 语句,用于捕获不同类型的异常。
抛出异常
您可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
以下是尝试除以零时抛出异常的实例:
double division(int a, int b)
{
if( b == 0 )
{ throw "Division by zero condition!";
}
return (a/b); }
捕获异常
catch 块跟在 try 块后面,用于捕获异常。您可以指定想要捕捉的异常类型,这是由 catch 关键字后的括号内的异常声明决定的。
try {
// 保护代码 }
catch( ExceptionName e )
{ // 处理 ExceptionName 异常的代码 }
上面的代码会捕获一个类型为 ExceptionName 的异常。如果您想让 catch 块能够处理 try 块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号 ...,如下所示:
try
{ // 保护代码
}catch(...)
{ // 能处理任何异常的代码
}
double division(int a, int b)
{
if (b == 0)
{
throw "Division by zero condition!";
}
return (a / b);
}
int main()
{
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
}
catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}
标准异常
C++中定义了一组类,用于报告标准库函数遇到的问题,也些异常可以在用户编写的程序中使用,在4个头文件中。
- exception头文件中定义了最通用的异常类exception,它只报告异常的产生,不提供 额外信息。
- stdexcept头文件提供了几种常见的异常类。如下所示:
- new头文件定义了bad_alloc异常类型。
- t'ype_info头文件定义了bad_cast异常类型。
| 类 | 解释 |
|---|---|
| exception | 最常见的问题 |
| runtime_error | 只能在运行时才能检测出的问题 |
| range_error | 运行时错误:生成的结果超过了有意义的值域范围 |
| overflow_error | 运行时错误:计算上溢 |
| underflow_error | 运行时错误:计算下溢 |
| logic_error | 程序逻辑错误 |
| domain_error | 逻辑错误:参数对应的结果值不存在 |
| invalid_argument | 逻辑错误:无效参数 |
| length_error | 逻辑错误试图创建一个超过该类型的最大长度的的对象 |
| out_of_range | 逻辑错误:使用一个超出有效范围的值 |
函数
函数是一组一起执行一个任务的语句。每个 C++ 程序都至少有一个函数,即主函数 main() ,所有简单的程序都可以定义其他额外的函数。
您可以把代码划分到不同的函数中。如何划分代码到不同的函数中是由您来决定的,但在逻辑上,划分通常是根据每个函数执行一个特定的任务来进行的。
函数声明告诉编译器函数的名称、返回类型和参数。函数定义提供了函数的实际主体。
C++ 标准库提供了大量的程序可以调用的内置函数。例如,函数 strcat() 用来连接两个字符串,函数 memcpy() 用来复制内存到另一个位置。.
函数的形式如下
return_type function_name( parameter list )
{
body of the function
}
- 返回类型:一个函数可以返回一个值。return_type 是函数返回的值的数据类型。有些函数执行所需的操作而不返回值,在这种情况下,return_type 是关键字 void。
- 函数名称:这是函数的实际名称。函数名和参数列表一起构成了函数签名。
- 参数:参数就像是占位符。当函数被调用时,您向参数传递一个值,这个值被称为实际参数。参数列表包括函数参数的类型、顺序、数量。参数是可选的,也就是说,函数可能不包含参数。
- 函数主体:函数主体包含一组定义函数执行任务的语句
double min_test(double a, double b)//两个数比大小,返回小
{
double result;
if (a > b)
{
result = b;
}
else
result = b;
return result;
}
函数声明
函数声明会告诉编译器函数名称及如何调用函数。函数的实际主体可以单独定义。
函数声明包括以下几个部分:
return_type function_name( parameter list );
针对上面定义的函数min_test(),以下是函数声明:
double min_test(double num1, double num2);
在函数声明中,参数的名称并不重要,只有参数的类型是必需的,因此下面也是有效的声明:
double min_tes(double, double);
当您在一个源文件中定义函数且在另一个
文件中调用函数时,函数声明是必需的。在这种情况下,您应该在调用函数的文件顶部声明函数。
调用函数
创建 C++ 函数时,会定义函数做什么,然后通过调用函数来完成已定义的任务。
当程序调用函数时,程序控制权会转移给被调用的函数。被调用的函数执行已定义的任务,当函数的返回语句被执行时,或到达函数的结束括号时,会把程序控制权交还给主程序。
调用函数时,传递所需参数,如果函数返回一个值,则可以存储返回值。
double min_test(double a, double b)//两个数比大小,返回小
{
double result;
if (a > b)
{
result = b;
}
else
result = b;
return result;
}
int main()
{
min_test(2.0, 3.0);//函数调用
system("pause");
return 0;
}
函数参数
如果函数要使用参数,则必须声明接受参数值的变量。这些变量称为函数的形式参数。
形式参数就像函数内的其他局部变量,在进入函数时被创建,退出函数时被销毁。
当调用函数时,有两种向函数传递参数的方式:
| 调用类型 | 描述 |
|---|---|
| 传值调用 | 该方法把参数的实际值复制给函数的形式参数。在这种情况下,修改函数内的形式参数对实际参数没有影响。 |
| 指针调用 | 该方法把参数的地址复制给形式参数。在函数内,该地址用于访问调用中要用到的实际参数。这意味着,修改形式参数会影响实际参数。 |
| 引用调用 | 该方法把参数的引用复制给形式参数。在函数内,该引用用于访问调用中要用到的实际参数。这意味着,修改形式参数会影响实际参数。 |
默认情况下,C++ 使用传值调用来传递参数。一般来说,这意味着函数内的代码不能改变用于调用函数的参数。之前提到的实例,调用 max() 函数时,使用了相同的方法。
参数的默认值
当您定义一个函数,您可以为参数列表中后边的每一个参数指定默认值。当调用函数时,如果实际参数的值留空,则使用这个默认值。
这是通过在函数定义中使用赋值运算符来为参数赋值的。调用函数时,如果未传递参数的值,则会使用默认值,如果指定了值,则会忽略默认值,使用传递的值。
int sum(int a, int b=20)
{
int result;
result = a + b;
return (result);
}
int main ()
{
// 局部变量声明
int a = 100;
int b = 200;
int result;
// 调用函数来添加值
result = sum(a, b);
cout << "Total value is :" << result << endl;
// 再次调用函数
result = sum(a);
cout << "Total value is :" << result << endl;
return 0;
}
Lambda 函数与表达式
C++11 提供了对匿名函数的支持,称为 Lambda 函数(也叫 Lambda 表达式)。
Lambda 表达式把函数看作对象。Lambda 表达式可以像对象一样使用,比如可以将它们赋给变量和作为参数传递,还可以像函数一样对其求值。
Lambda 表达式本质上与函数声明非常类似,具体的定义方式如下所示:
- [ capture ] ( params ) mutable exception attribute -> ret { body }
是完整的 lambda 表达式形式 - [ capture ] ( params ) -> ret { body }
const 类型的 lambda 表达式,该类型的表达式不能改捕获(“capture”)列表中的值 - [ capture ] ( params ) { body }
省略了返回值类型的 lambda 表达式,返回类型由 return 语句的返回类型确定;若无return语句,则类似void - [ capture ] { body }
省略了参数列表,类似于无参函数 f()
| 序号 | 格式 |
|---|---|
| 1 | [capture list] (params list) -> return type |
| 2 | [capture list] (params list) |
| 3 | [capture list] |
C++变量传递有传值和传引用的区别。可以通过前面的[]来指定:
[] // 沒有定义任何变量。使用未定义变量会引发错误。
[x, &y] // x以传值方式传入(默认),y以引用方式传入。
[&] // 任何被使用到的外部变量都隐式地以引用方式加以引用。
[=] // 任何被使用到的外部变量都隐式地以传值方式加以引用。
[&, x] // x显式地以传值方式加以引用。其余变量以引用方式加以引用。
[=, &z] // z显式地以引用方式加以引用。其余变量以传值方式加以引用。
对于[=]或[&]的形式,lambda 表达式可以直接使用 this 指针。但是,对于[]的形式,如果要使用 this 指针,必须显式传入:
[this]() { this->someFunc(); }();
分离式编译模式
分离式编译:分离式编译可以把程序分割到几个文件中去,每个文件独立编译
在clion软件创建创建test.h,test.cpp,main.cpp文件。
在test.h中添加头文件函数声明代码,如下所示:
#include <iostream>
using namespace std;
#ifndef TEST3_TEST_H
#define TEST3_TEST_H
class test {
public:
test()
{
cout<<"test_class"<<endl;
}
double sub(double a, double b);
};
double add_(double a, double b);
#endif //TEST3_TEST_H
在test.cpp中添加如下的代码:
#include "test.h"
#include<iostream>
using namespace std;
double add_(double a, double b)
{
return a + b;
}
double test::sub(double a, double b)// 类函数
{
return a -b;
}
main.cpp实现函数的调用,如下所示:
#include <iostream>
using namespace std;
#include "test.h"
int main(void)
{
test t;//调用构造函数
cout<<t.sub(12.0, 3.0)<<endl;
cout<< add_(12.0, 3.0)<<endl;
system("pause");
return 0;
}
参数传递
当形参引用类型时,我们所它的对应实参被引用传递(passed by reference)或者函数被传引用调用(called by reference)。和其他的引用一样,引用参数也是它绑定对象的别名,引用形参是它对应的实参的别名。
当实参的数据拷贝给形参,形参和实参是两个相互的独立的对象,我们所这样的实参被值传递(passed by value)或者所函数被值调用(called by value)。
//传值参数
int n = 0;//int类型的初始化
int i = n;//i是n的副本
i = 12;//i的值改变,n的值不改变
//指针参数
int n =0, b=12;//
int *p = &n, *q=&b;
*p=42; //n的值改变,p不变
p=q; //p改变,p指向b,但是n和b的值不变
//传引用参数
int n = 0, i=42;
int &r =n;//r和n绑定在一起
r=42;//n=42
r=i;//n和i的值为42
i=r;//i和n的值为42
使用引用用于避免拷贝
拷贝大的类类型对象或者容器对象比较低效,甚至有的类类型(包括IO类型在内),根本不支持拷贝的操作,当某种类型不支持拷贝的操作时,函数的引用只能通过引用形参是比较好。
bool isshorter(const string &a, const string &b)
{
return a.size() < b.size();
}
使用引用形参返回额外的信息
一个函数只能返回一个值,然而有时候我们需要同时返回几个值,引用形参可以帮助我们实现返回多个值的结果。定义一个find_char函数,它返回string对象中某个字符第一次出现的位置。同时,我们希望返回字符出现的总次数。
string::size_type find_char(const string &s, char c, string::size_type &occures)
{
auto ret = s.size();//第一次出现的位置
occures = 0;//出现次数的形参值
for(decltype(ret) i = 0; i!=s.size(); ++i)
{
if(s[i]==c)
{
if(ret == s.size())
ret = i;//记录c第一次出现的位置
++occures;//将出现的次数加1
}
}
return ret;
}
const形参和实参
const int i = 42;//不能改变i的值
int i_ = i;//当拷贝i,忽略了顶层const
int *const p = &i;//const是顶级的,不能赋值
*p = 0;//通过p改变所指的对象的值是可以的。i变成0
指针或引用形参与const
int i = 45;
const int *cp = &i;
const int &r= 42;
const int &r2 = i;
int *p =cp;//p的类型和cp的类型不匹配//error
int &r3 = r;//r3的类型和r的类型不匹配//error
int &r4 = 42;//不能将字面值初始值化一个常量的引用//error
const int *p =cp;
const int &r3 = r;
const int &r4 = 42;
内联函数和cnstexpr函数
在c/c++中,为了解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题,特别的引入了inline修饰符,表示为内联函数。
栈空间就是指放置程序的局部数据(也就是函数内数据)的内存空间。
inline const string &
shorterString(const string &s1, const string &s2)
{
return s1.size() <= s2.size() ? s1 : s2;
}
//那么当我们执行:
cout << shorterString(s1, s2) << endl;
//其实编译时会变成:
cout << (s1.size() < s2.size() ? s1 : s2) << endl;
内敛函数感觉类似宏替换,但是inline在替换前有类型检查,避免了宏的错误
声明Inline函数时,编译器会对函数有一个判断:该函数作为内敛函数是否合理?如果不合理,就算我们声明了Inline编译器也会将函数作为普通函数处理。
在类体中定义的成员函数的规模一般都很小,而系统调用函数的过程所花费的时间开销相对是比较大的。调用一个函数的时间开销远远大于小规模函数体中全部语句的执行时间。为了减少时间开销,如果在类体中定义的成员函数中不包括循环等控制结构,C++系统会自动将它们作为内置(inline)函数来处理。
也就是说,在程序调用这些成员函数时,并不是真正地执行函数的调用过程(如保留返回地址等处理),而是把函数代码嵌入程序的调用点。这样可以大大减少调用成员函数的时间开销。C++要求对一般的内置函数要用关键字inline声明,但对类内定义的成员函数,可以省略inline,因为这些成员函数已被隐含地指定为内置函数。
class test{
public:
void display() //也了可以写成inline void display(),两者一样
{
cout<<"test"<<endl;
}
};
应该注意的是,如果成员函数不在类体内定义,而在类体外定义,系统并不把它默认为内置(inline )函数,调用这些成员函数的过程和调用一般函数的过程是相同的。如果想将这些成员函数指定为内置函数,应当用inline作显式声明。
inline void display()//类外
{
cout<<"test"<<endl;
}
值得注意的是,如果在类体外定义inline函数,则必须将类定义和成员函数的定义都放在同一个头文件中(或者写在同一个源文件中),否则编译时无法进行置换(将函数代码的拷贝嵌入到函数调用点)不利于类的接口与类的实现分离,不利于信息隐蔽。虽然程序的执行效率提高了,但从软件工程质量的角度来看,这样做并不是好的办法。只有在类外定义的成员函数规模很小而调用频率较高时,才将此成员函数指定为内置函数。
引用:https://www.cnblogs.com/KellyHuang/p/4001470.html
constexpr
const 和 constexpr 变量之间的主要区别在于:const 变量的初始化可以延迟到运行时,而 constexpr 变量必须在编译时进行初始化。所有 constexpr 变量均为常量,因此必须使用常量表达式初始化。
constexpr float x = 42.0;
constexpr float y{108};
constexpr float z = exp(5, 3);
constexpr int i; // //未初始化
int j = 0;
constexpr int k = j + 1 // 不是常量表达式(error)
constexpr函数
constexpr 函数是在使用需要它的代码时,可以在编译时计算其返回值的函数。当其参数为 constexpr 值并且在编译时使用代码需要返回值时(例如,初始化一个 constexpr 变量或提供一个非类型模板参数),它会生成编译时常量。使用非constexpr 参数调用时,或编译时不需要其值时,它将与正则函数一样,在运行时生成一个值。
** constexpr和指针**
如果关键字const出现在星号左边,表示被指物是常量(*const p);如果出现在星号右边,表示指针本身是常量(const *p);如果出现在星号两边,表示被指物和指针两者都是常量(*const *p)。
与const不同,在constexpr声明中如果定义了一个指针,限定符constexpr仅对指针有效,与指针所指对象无关。
const int *p = 0; // non-const pointer, const data
constexpr int *q = 0; // const pointer, non-const data
//与其它常量指针类似,const指针既可以指向常量也可以指向一个非常量:
int j = 0;
constexpr int i = 2;
constexpr const int *p = &i; // const pointer, const data
constexpr int *p1 = &j; // const pointer, non-const data
通常将内联函数和constexpr函数放在头文件中。
函数指针
c/c++两种不兼容的函数指针形式:
(1) 指向C语言函数和C++静态成员函数的函数指针
(2) 指向C++非静态成员函数的函数指针
不兼容的原因是因为在使用C++非静态成员函数的函数指针时,需要一个指向类的实例的this指针,而前一类不需要。
函数指针的定义方式
data_types (*func_pointer)( data_types arg1, data_types arg2, ...,data_types argn);
example
int pointer_add(int a, int b)
{
return a + b;
}
int main(void)
{
int (*add_)(int, int );
add_ = pointer_add;
cout<<add_(2, 3);
system("pause");
return 0;
}
typedef 定义可以简化函数指针的定义**
int pointer_add(int a, int b)
{
return a + b;
}
int main(void)
{
typedef int (*add_)(int, int );
add_ f = pointer_add;
cout<<f(2, 3);
system("pause");
return 0;
}
** 函数指针同样是可以作为参数传递给函数的**
int test(int a)
{
return a-1;
}
int test(int (*fun)(int),int b)
{
int c = fun(10)+b;
return c;
}
int main(int argc,char *argv[])
{
typedef int (*fp)(int a);
fp f = test;
cout<<test(f, 1)<<endl; // 调用 test2 的时候,把test函数的地址作为参数传递给了 test2
system("pause");
return 0;
}
answer:10
利用函数指针,我们可以构成函数指针数组,更明确点的说法是构成指向函数的指针数组。
void test1(void){cout<<"1"<<endl;}
void test2(void){cout<<"2"<<endl;}
void test3(void){cout<<"3"<<endl;}
int main(int argc,char *argv[])
{
typedef void(*fun)(void);
fun b[]={test1, test2,test3};
for(int i=0; i!=3;++i)
{
b[i]();
}
system("pause");
return 0;
}
指向类成员函数的函数指针
定义:类成员函数指针(member function pointer),是 C++ 语言的一类指针数据类型,用于存储一个指定类具有给定的形参列表与返回值类型的成员函数的访问信息。
基本上要注意的有两点:
1、函数指针赋值要使用 &
2、使用 .* (实例对象)或者 ->*(实例对象指针)调用类s成员函数指针所指向的函数。
A) 类成员函数指针指向类中的非静态成员函数
对于 nonstatic member function (非静态成员函数)取地址,获得该函数在内存中的实际地址。
对于 virtual function(虚函数), 其地址在编译时期是未知的,所以对于 virtual member function(虚成员函数)取其地址,所能获得的只是一个索引值。
//指向类成员函数的函数指针
#include <iostream>
#include <cstdio>
using namespace std;
class A
{
public:
A(int aa = 0):a(aa){}
~A(){}
void setA(int aa = 1)
{
a = aa;
}
virtual void print()
{
cout << "A: " << a << endl;
}
virtual void printa()
{
cout << "A1: " << a << endl;
}
private:
int a;
};
class B:public A
{
public:
B():A(), b(0){}
B(int aa, int bb):A(aa), b(bb){}
~B(){}
virtual void print()
{
A::print();
cout << "B: " << b << endl;
}
virtual void printa()
{
A::printa();
cout << "B: " << b << endl;
}
private:
int b;
};
int main(void)
{
A a;
B b;
void (A::*ptr)(int) = &A::setA;
A* pa = &a;
//对于非虚函数,返回其在内存的真实地址
printf("A::set(): %p\n", &A::setA);
//对于虚函数, 返回其在虚函数表的偏移位置
printf("B::print(): %p\n", &A::print);
printf("B::print(): %p\n", &A::printa);
a.print();
a.setA(10);
a.print();
a.setA(100);
a.print();
//对于指向类成员函数的函数指针,引用时必须传入一个类对象的this指针,所以必须由类实体调用
(pa->*ptr)(1000);
a.print();
(a.*ptr)(10000);
a.print();
return 0;
}

B) 类成员函数指针指向类中的静态成员函数
#include <iostream>
using namespace std;
class A{
public:
//p1是一个指向非static成员函数的函数指针
void (A::*p1)(void);
//p2是一个指向static成员函数的函数指针
void (*p2)(void);
A(){
/*对
**指向非static成员函数的指针
**和
**指向static成员函数的指针
**的变量的赋值方式是一样的,都是&ClassName::memberVariable形式
**区别在于:
**对p1只能用非static成员函数赋值
**对p2只能用static成员函数赋值
**
**再有,赋值时如果直接&memberVariable,则在VS中报"编译器错误 C2276"
**参见:http://msdn.microsoft.com/zh-cn/library/850cstw1.aspx
*/
p1 =&A::funa; //函数指针赋值一定要使用 &
p2 =&A::funb;
//p1 =&A::funb;//error
//p2 =&A::funa;//error
//p1=&funa;//error,编译器错误 C2276
//p2=&funb;//error,编译器错误 C2276
}
void funa(void){
puts("A");
}
static void funb(void){
puts("B");
}
};
int main()
{
A a;
//p是指向A中非static成员函数的函数指针
void (A::*p)(void);
(a.*a.p1)(); //打印 A
//使用.*(实例对象)或者->*(实例对象指针)调用类成员函数指针所指向的函数
p = a.p1;
(a.*p)();//打印 A
A *b = &a;
(b->*p)(); //打印 A
/*尽管a.p2本身是个非static变量,但是a.p2是指向static函数的函数指针,
**所以下面这就话是错的!
*/
// p = a.p2;//error
void (*pp)(void);
pp = &A::funb;
pp(); //打印 B
return 0;
}

类成员函数指针与普通函数指针不是一码事。前者要用 .* 与 ->* 运算符来使用,而后者可以用 * 运算符(称为"解引用"dereference,或称"间址"indirection)。
普通函数指针实际上保存的是函数体的开始地址,因此也称"代码指针",以区别于 C/C++ 最常用的数据指针。
而类成员函数指针就不仅仅是类成员函数的内存起始地址,还需要能解决因为 C++ 的多重继承、虚继承而带来的类实例地址的调整问题,所以类成员函数指针在调用的时候一定要传入类实例对象。
C++
1 typedef与decltype组合定义函数类型
typedef decltype(add) add2;
decltype返回函数类型,add2是与add相同类型的函数,不同的是add2是类型,而非具体函数。
使用方法:
add2* pf;//pf指向add类型的函数指针,未初始化
2 typedef与decltype组合定义函数指针类型
typedef decltype(add)* PF2;//PF2与1.1PF意义相同
PF2 pf;// pf指向int(int,int)类型的函数指针,未初始化
3 使用推断类型关键字auto定义函数类型和函数指针
auto pf = add;//pf可认为是add的别名(个人理解)
auto *pf = add;//pf为指向add的指针
4函数指针形参
typedef decltype(add) add2;
typedef decltype(add)* PF2;
void fuc2 (add2 add);//函数类型形参,调用自动转换为函数指针
void fuc2 (PF2 add);//函数指针类型形参,传入对应函数(指针)即可
说明:不论形参声明的是函数类型:void fuc2 (add2 add);还是函数指针类型void fuc2 (PF2 add);都可作为函数指针形参声明,在参数传入时,若传入函数名,则将其自动转换为函数指针。
5 返回指向函数的指针
1 使用auto关键字
auto fuc2(int)-> int(*)(int,int) //fuc2返回函数指针为int(*)(int,int)
2 使用decltype关键字
decltype(add)* fuc2(int)//明确知道返回哪个函数,可用decltype关键字推断其函数类型,
** 6 成员函数指针**
1普通成员函数指针使用举例
class A//定义类A
{
private:
int add(int nLeft, int nRight)
{
return (nLeft + nRight);
}
public:
void fuc()
{
printf("Hello world\n");
}
};
typedef void(A::PF1)();//指针名前需加上类名限定
PF1 pf1 = &A::fuc; //必须有&
A a;//成员函数地址解引用必须附驻与某个对象地址,所以必须创建一个队形
(a.pf1)();//使用成员函数指针调用函数
2继承中的函数指针使用举例
class A
{
public:
void fuc()
{
printf("Hello fuc()\n");
}
void fuc2()
{
printf("Hello A::fuc2()\n");
}
};
class B:public A
{
public:
virtual void fuc2()
{
printf("Hello B::fuc2()\n");
}
};
typedef void(A::*PF1)();
typedef void(B::*PF2)();
PF1 pf1 = &A::fuc;
int main()
{
A a;
B b;
(a.*pf1)(); //调用A::fuc
(b.*pf1)(); //调用A::fuc
pf1 = &A::fuc2;
(a.*pf1)(); //调用A::fuc2
(b.*pf1)(); //调用A::fuc2
PF2 pf2 = &A::fuc2;
(b.*pf2)(); //调用A::fuc2
}
7重载函数的指针
1 重载函数fuc
Void fuc();
Void fuc(int);
2 重载函数的函数指针
void (*PF)(int) = fuc;//PF指向fuc(int)
int(*pf2)(int) = fuc;//错误没有匹配的类型
引用:http://www.runoob.com/w3cnote/cpp-func-pointer.html
https://www.cnblogs.com/lvchaoshun/p/7806248.html
类
类用于指定对象的形式,它包含了数据表示法和用于处理数据的方法。类中的数据和方法称为类的成员。函数在一个类中被称为类的成员。
c++类的定义
类定义是以关键字 class 开头,后跟类的名称。类的主体是包含在一对花括号中。类定义后必须跟着一个分号或一个声明列表。
其形式如下所示:
class 类名
{
public:
//行为或属性
private:
//行为或属性
protected:
//行为或属性
};//不要忘记分号
访问数据成员
也test类为例:
class test{
private://私有
int data_x, data_y;
public:
int set_xy(int x,int y){data_x=x;data_y=y;}
int get_x(){return data_x;}
int get_y(){return data_y;}
void dispaly()
{
cout<<"x="<<get_x()<<" "<<"y="<<get_y()<<endl;
}
};
int main()
{
test t;//定义对象
t.set_xy(10, 20);//设置x-y
t.dispaly();//显示
return 0;
}
测试的结果:x=10 y=20
| 概念 | 描述 |
|---|---|
| 类成员函数 | 类的成员函数是指那些把定义和原型写在类定义内部的函数,就像类定义中的其他变量一样。 |
| 类访问修饰符 | 类成员可以被定义为 public、private 或 protected。默认情况下是定义为 private。 |
| 造函数 & 析构函数 | 类的构造函数是一种特殊的函数,在创建一个新的对象时调用。类的析构函数也是一种特殊的函数,在删除所创建的对象时调用。 |
| C++拷贝构造函数 | 拷贝构造函数,是一种特殊的构造函数,它在创建对象时,是使用同一类中之前创建的对象来初始化新创建的对象。 |
| C++ 友元函数 | 友元函数可以访问类的 private 和 protected 成员。 |
| C++内联函数 | 通过内联函数,编译器试图在调用函数的地方扩展函数体中的代码。 |
| C++ 中的 this 指针 | 每个对象都有一个特殊的指针 this,它指向对象本身。 |
| C++ 中指向类的指针 | 指向类的指针方式如同指向结构的指针。实际上,类可以看成是一个带有函数的结构。 |
| C++ 类的静态成员 | 类的数据成员和函数成员都可以被声明为静态的。 |
也下就进行说明:
类的修饰符
类成员的访问限制是通过在类主体内部对各个区域标记 public、private、protected 来指定的。关键字 public、private、protected 称为访问修饰符。
class 类名
{
public://共有的
//行为或属性
private://私有的
//行为或属性
protected://受保护的
//行为或属性
};//不要忘记分号
public:公有成员在程序中类的外部是可访问的。您可以不使用任何成员函数来设置和获取公有变量的值.
private:私有成员变量或函数在类的外部是不可访问的,甚至是不可查看的。只有类和友元函数可以访问私有成员。
默认情况下,类的所有成员都是私有的.
protected:保护成员变量或函数与私有成员十分相似,但有一点不同,保护成员在派生类(即子类)中是可访问的。
class test{
protected:
int data_x;
};
class test1:test{
public:
void display();
void set_data_x(int x);
int get_data_x();
};
void test1::display(){
cout<<"test-data_x:"<<data_x<<endl;
}
void test1::set_data_x(int x){
data_x=x;
}
int test1::get_data_x(){return data_x;}
int main()
{
test1 t;
t.set_data_x(12);
t.display();
return 0;
}
继承中的特点
有public, protected, private三种继承方式,它们相应地改变了基类成员的访问属性。
- public 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:public, protected, private
- protected 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:protected, protected, private
- private 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:private, private, private
但无论哪种继承方式,上面两点都没有改变:
-
private 成员只能被本类成员(类内)和友元访问,不能被派生类访问;
-
protected 成员可以被派生类访问。
| 承方式 | 基类的public成员 | 基类的protected成员 | 基类的private成员 | 继承引起的访问控制关系变化概括 |
|---|---|---|---|---|
| public继承 | 仍为public成员 | 仍为protected成员 | 不可见 | 基类的非私有长远在子类的访问属性不变 |
| protected继承 | 变为protected成员 | 变为protected成员 | 不可见 | 基类的非私有成员都为子类的保护成员 |
| private继承 | 变为private成员 | 变为private成员 | 不可见 | 基类中的非私有成员都称为子类的私有成员 |
public继承
class A{
public:
int a;
A(){
a1 = 1;
a2 = 2;
a3 = 3;
a = 4;
}
void fun(){
cout <<"a:"<< a << endl; //正确
cout <<"a1:"<< a1 << endl; //正确
cout <<"a2"<< a2 << endl; //正确
cout <<"a3:"<< a3 << endl; //正确
}
public:
int a1;
protected:
int a2;
private:
int a3;
};
class B : public A{
public:
int a;
B(int i){
A();
a = i;
}
void fun(){
cout << "a:"<<a << endl; //正确,public成员
cout << "a1:"<<a1 << endl; //正确,基类的public成员,在派生类中仍是public成员。
cout << "a2:"<<a2 << endl; //正确,基类的protected成员,在派生类中仍是protected可以被派生类访问。
//cout <<"a3:"<<a3 << endl; //错误,基类的private成员不能被派生类访问。
}
};
int main(){
B b(10);
cout <<"a:"<<b.a << endl;
cout <<"a1:"<< b.a1 << endl; //正确
//cout << b.a2 << endl; //错误,类外不能访问protected成员
//cout << b.a3 << endl; //错误,类外不能访问private成员
system("pause");
return 0;
}
a:10
a1:1
protected继承
void fun()
{
cout << a << endl; //正确,public成员。
cout << a1 << endl; //正确,基类的public成员,在派生类中变成了protected,可以被派生类访问。
cout << a2 << endl; //正确,基类的protected成员,在派生类中还是protected,可以被派生类访问。
cout << a3 << endl; //错误,基类的private成员不能被派生类访问。
}
int main()
{
B b(10);
cout << b.a << endl; //正确。public成员
cout << b.a1 << endl; //错误,protected成员不能在类外访问。
cout << b.a2 << endl; //错误,protected成员不能在类外访问。
cout << b.a3 << endl; //错误,private成员不能在类外访问。
}
privated继承
void fun(){
cout << a << endl; //正确,public成员。
cout << a1 << endl; //正确,基类public成员,在派生类中变成了private,可以被派生类访问。
cout << a2 << endl; //正确,基类的protected成员,在派生类中变成了private,可以被派生类访问。
cout << a3 << endl; //错误,基类的private成员不能被派生类访问。
}
int main(){
B b(10);
cout << b.a << endl; //正确。public成员
cout << b.a1 << endl; //错误,private成员不能在类外访问。
cout << b.a2 << endl; //错误, private成员不能在类外访问。
cout << b.a3 << endl; //错误,private成员不能在类外访问。
system("pause");
return 0;
}
构造函数 & 析构函数
类的构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。
构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。构造函数可用于为某些成员变量设置初始值。
类的析构函数是类的一种特殊的成员函数,它会在每次删除所创建的对象时执行。
析构函数的名称与类的名称是完全相同的,只是在前面加了个波浪号(~)作为前缀,它不会返回任何值,也不能带有任何参数。析构函数有助于在跳出程序(比如关闭文件、释放内存等)前释放资源。
class A{
public:
A(){ //这个不带参数的构造函数
a=12;
b=12;
cout<<"a:"<<a<<endl;
cout<<"b:"<<b<<endl;
}
//带参数的构造函数
A(int a1, int b1){ //也可以A(int a, int b):a(a1),b(b1)
this->a=a1;
this->b=b1;
cout<<"a:"<<a<<"b:"<<b<<endl;
}
int add(int a, int b)
{
return a +b;
}
~A(){
cout<<"~A"<<endl;
}
private:
int a, b;
};
int main(){
A a;//调用未带参数的构函数
A a1(40, 45);//调用带参数的构函数
A *p = new A(12,35);//创建对象会调用构函数
delete p; //释放对象,会调用析构函数
A a3;//调用构造函数
cout<<"add:"<< a3.add(12, 23)<<endl;
system("pause");
return 0;
}
拷贝构造函数
拷贝构造函数是一种特殊的构造函数,它在创建对象时,是使用同一类中之前创建的对象来初始化新创建的对象。拷贝构造函数通常用于:
- 通过使用另一个同类型的对象来初始化新创建的对象。
- 复制对象把它作为参数传递给函数。
- 复制对象,并从函数返回这个对象。
如果在类中没有定义拷贝构造函数,编译器会自行定义一个。如果类带有指针变量,并有动态内存分配,则它必须有一个拷贝构造函数。
函数的基本形式
classname (const classname &obj) {
// 构造函数的主体
}
example:
class test{
public:
//构造函数
test(int a, int b );
//析构函数
~test();
//拷贝构造函数
test(const test &obj);
void show();
private:
int a, b;
};
test::test(int a, int b ):a(a), b(b) {
cout<<"调用构造函数"<<endl;
}
test::test(const test &obj){
a = obj.a;
b = obj.b;
cout<<"调用拷贝构造函数"<<endl;
}
test::~test(){
cout<<"析构函数...."<<endl;
}
void test::show()
{
cout<<"a:"<<a<<"b:"<<b<<endl;
}
int main()
{
test t(10, 20);//调用构造函数
test t1(t);//等价两者test t1 = t;//调用拷贝构造函数
t.show();
system("pause");
return 0;
}
引入全局函数
class test{
public:
//构造函数
test(int a, int b );
//析构函数
~test();
//拷贝构造函数
test(const test &obj);
void show();
private:
int a, b;
};
test::test(int a, int b ):a(a), b(b) {
cout<<"调用构造函数"<<endl;
}
test::test(const test &obj){
a = obj.a;
b = obj.b;
cout<<"调用拷贝构造函数"<<endl;
}
test::~test(){
cout<<"析构函数...."<<endl;
}
void test::show()
{
cout<<"a:"<<a<<"b:"<<b<<endl;
}
void get_fun(test c)//全局函数
{
cout<<"test"<<endl;
}
int main()
{
test t1(10, 20);
get_fun(t1);
system("pause");
return 0;
}
调用g_fun()时,会产生以下几个重要步骤:
(1).t1对象传入形参时,会先会产生一个临时变量,就叫 C 吧。
(2).然后调用拷贝构造函数把t1的值给C。 整个这两个步骤有点像: test C(t1);
(3).等g_Fun()执行完后, 析构掉 C 对象。
对象以值传递的方式从函数返回
test get_fun()
{
test test_(12, 23);
return test_;
}
int main()
{
get_fun();
system("pause");
return 0;
}
get_fun->return
(1). 先会产生一个临时变量,就叫XXXX吧。
(2). 然后调用拷贝构造函数把test_的值给XXXX。整个这两个步骤有点像:test XXXX(test_);
(3). 在函数执行到最后先析构test_局部变量。
(4). 等get_fun()执行完后再析构掉XXXX对象。

浅拷贝和深拷贝
class counter{
public:
counter();//计数加1
~counter();//计算减1
static int getcont();//返回计数器的个数
private:
static int count;
};
counter::counter(){
count++;
}
counter::~counter(){
count--;
}
int counter::getcont() {
return count;
}
int counter::count=0;//静态数据初始化在类外面初始化//初始化计数器
int main() {
counter c1;//counter:1
counter c2 = c1;//counter:1//拷贝对象数据没有增加1
counter c3;
cout << "counter:" << counter::getcont() << endl; //counter:2
system("pause");
return 0;
}
加入了一个静态成员,目的是进行计数。在主函数中,首先创建对象c1,输出此时的对象个数,然后使用c1复制出对象c2,再输出此时的对象个数,按照理解,此时应该有两个对象存在,但实际程序运行时,输出的都是1,反应出只有1个对象。此外,在销毁对象时,由于会调用销毁两个对象,类的析构函数会调用两次,此时的计数器将变为负数。拷贝构造函数没有处理静态static对象。
如果要改变这一结果,我们就需要在拷贝构函数中加入count++语句,具体的实现如下所示:
class counter{
public:
counter();//计数加1
~counter();//计算减1
static int getcont();//返回计数器的个数
counter(const counter &obj);
private:
static int count;
};
counter::counter(){
count++;
}
counter::~counter(){
count--;
}
int counter::getcont() {
return count;
}
counter::counter(const counter &obj)
{
count = obj.count;
count ++;
}
int counter::count=0;//静态数据初始化在类外面初始化//初始化计数器
int main() {
counter c1;
cout << "counter:" << counter::getcont() << endl; //counter:1
counter c2 = c1;
cout << "counter:" << counter::getcont() << endl; //counter:2
counter c3;
cout << "counter:" << counter::getcont() << endl; //counter:3
system("pause");
return 0;
}
浅拷贝
将一个指针值赋值给另一个指针,就会使得两个指针指向同一块空间,这就产生了浅拷贝。
class String
{
public:
String(const char* str)/
:_str(new char[strlen(str) + 1])
{
strcpy(_str, str);
}
String(const String& s)
:_str(s._str)
{}
String& operator=(const String& s)
{
if (this != &s)
{
_str = s._str;
}
return *this;
}
~String()
{
if (_str)
{
delete[] _str;
}
_str = NULL;
}
private:
char* _str;
};
nt main() {
string s1("good");
string s2(s1);
system("pause");
return 0;
}
当两个(或两个以上)指针指向同一块空间,这个内存就会被释放多次;(例如下面定义了一个String对象s1,以浅拷贝的方式拷贝构造了一个String对象s2,则s1和s2里面的指针_str就会指向同一块空间;当出了作用域,s2先调用析构函数,而上面代码中析构函数里面进行了空间的释放,也就是这个空间就会被s2释放,接下来会调用s1的析构函数,也会去释放这块空间,释放一块已经不属于我的空间就会出错)
其中深拷贝就可以解决这个问题。
深拷贝
**
传统写法 **
若用一个s1对象拷贝构造或赋值给s2对象,s2(s1)或 s2 = s1,当涉及到浅拷贝的问题时:
对于拷贝构造函数来说,s2先开一块和s1一样大的空间;而对于赋值运算符重载函数来说s2已经存在,则必须先释放s2的空间然后才让s2开与s1一样大的空间(否则就会导致s2里面的指针没有释放)。
然后让s2指向这块新开的空间,然后将s1里面的数据拷贝至s2指向的空间(自己开空间自己拷数据);
//传统拷贝构造函数
String(const String &s){
_str = new char[strlen(s._str) +1];//开辟空间
strcpy(_str, s._str);//拷贝
}
//传统赋值构造函数
String &operator=(const String &s)//必须要返回引用,为了连续的赋值
{
if(this != &s)
{
delete [] _str;
_str = NULL;
_str = new char[strlen(s._str)+1];
strcpy(_str, s._str);
}
return *this;
}
现代写法(调用其他的函数来实现自己的功能)
本质:让别人去开空间,去拷数据,而我将你的空间与我交换就可以。
实现:例如用s1拷贝构造一个s2对象s2(s1),可以通过构造函数将s1里的指针_str构造一个临时对象tmp(构造函数不仅会开空间还会将数据拷贝至tmp),此时tmp就是我们想要的哪个对象,然后将新tmp的指针_ptr与自己的指针进行交换。
对于构造函数来说,因为String有一个带参数的构造函数,则用现代写法写拷贝构造时可以调用构造函数,而对于没有无参的构造函数的类只能采用传统写法(开空间然后拷数据)。
//拷贝构造的现代写法
String(const String& s)
:_str(NULL)
{
String tmp(s._str); //调用构造函数,则tmp就是我们需要的
swap(_str, tmp._str); //将_str与tmp的_str指向的空间进行交换,tmp._str就会指向_str的空间,出了这个作用域,tmp就会调用析构函数,但是tmp里面的_str值可能不确定,所以在初始化列表中将_str置空,这样tmp._str=NULL
}
//赋值的现代写法
String& operator=(const String& s)
{
if (this != &s)
{
String tmp(s._str); //调用构造函数
swap(_str, tmp._str); //tmp是局部对象,出了这个作用域就会调用析构函数,就会将tmp里面的指针指向的空间释放掉,
}
return *this;
}
引用计数的写时拷贝
1.常用场景:
- 有时会多次调用拷贝构造函数,但是拷贝构造的对象并不会修改这块空间的值;
- 如果采用深拷贝,每次都会重复的开空间,然后拷数据,最后再释放这块空间,这会花费很大的精力。
- 我们想到浅拷贝不用重复的开空间,但是会有问题;为了解决释放多次的问题可以采用引用计数,当有新的指针指向这块空间的时候,我们可以增加引用计数,当这个指针需要销毁时,就将引用计数的值减1,当引用计数的值为1时才去释放这块空间;
- 当有一个指针指需要修改其指向空间的值时,才去开一块新的空间(也就是写时拷贝);
- 这相当于一个延缓政策,如果不需要修改,则不用开新的空间,毕竟开空间需要很大的消耗。
- 引用计数解决了空间被释放多次的问题,写时拷贝解决了多个指针指向同一块空间会修改的问题。
class String
{
public:
String(char* str="")
:_str(new char[strlen(str)+1])
, _refCount(new int(1)) //引用计数的初始值为1
{
strcpy(_str, str);
}
//拷贝构造 s1(s2),采用浅拷贝
String(const String& s)
:_str(s._str)
, _refCount(s._refCount)
{
++(*_refCount);
}
//s1=s2(先将_str指向空间的引用计数--,然后看那个空间的引用计数是否为0,如果为0,则将该空间释放,然后将s的值和引用计数赋值给_str
String& operator=(const String& s)
{
if (_str != s._str)
{
if (--(*_refCount) == 0)
{
delete[] _str;
delete _refCount;
}
_str = s._str;
_refCount = s._refCount;
++(*_refCount);
}
return *this;
}
~String() //先将自己的引用计数--,然后看该引用计数是否为0,如果为0,则将该空间释放
{
if (--(*_refCount) == 0)
{
delete[] _str;
delete _refCount;
}
}
void CopyOnWrite() //只有当引用计数大于1时才开空间,如果引用计数等于1,说明当前空间只有自己一个对象指向它,直接可以对这个空间进行操作
{
if (*_refCount > 1)
{
char* newstr = new char[strlen(_str) + 1];
strcpy(newstr, _str);
_str = newstr;
_refCount = new int(1);
}
}
private:
char* _str;
int* _refCount;
};
引用计数写时拷贝的改进
1.为什么引用计数的写实拷贝需要改进?
如果将引用计数单独的定义为一个int*的指针,它占4个字节,每次创建一个String对象,都会为其向操作系统申请4个字节的内存,这样就会经常申请许多小块内存,会造成内存碎片,也会对效率造成影响。
2.这时可以考虑将_str与引用计数放在一起,就在_str的头上4个字节存放引用计数,当我们取引用计数时,只用将*((int*)(_str-4))
class String
{
public:
String(char* str ="")
:_str(new char[strlen(str)+5]) //因为多开了4个字节给引用计数,所以这里加5,上面引用计数和_str独立加的是1,只有这里的_str包含引用计数,后面的_str都不包含引用计数
{
_str += 4; //从_str+4才表示有效的字符,前面是引用计数
strcpy(_str, str);
GetRefCount() = 1; //将引用计数置为1
}
// s2(s1)
String(const String& s)
:_str(s._str)
{
++(GetRefCount());
}
//s2 = s1
String& operator=(const String& s)
{
if (_str != s._str)
{
if (--(GetRefCount()) == 0)
{
delete[] (_str-4);
}
_str = s._str;
++GetRefCount();
}
return *this;
}
~String()
{
if (--GetRefCount() == 0)
{
delete[] (_str - 4);
}
}
int& GetRefCount()
{
return *((int*)(_str - 4));
}
const char* c_str()
{
return _str;
}
void CopyOnWrite()
{
if (GetRefCount() > 1)
{
char* newstr = new char[strlen(_str) + 5];
newstr += 4;
strcpy(newstr, _str);
--GetRefCount();
_str = newstr;
GetRefCount() = 1;
}
}
char& operator[](size_t pos)
{
CopyOnWrite();
return _str[pos];
}
private:
char* _str; // 引用计数放在_str的头上4个字节处
};
引用计数的写时拷贝,读有时也会拷贝
例如对于String类,如果想要取出里面的某个字符或者修改某个对应位置上的字符需要重载operator[ ]:
因为operator[ ]既可以读也可以修改,为了统一,无论读写,都需要重新拷贝;
char& operator[](size_t pos)
{
CopyOnWrite();
return _str[pos];
}
友元函数
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。破坏了类的封装。
友元函数的定义如下:
class test{
public :
test(int a,int b, int c):a_(a),b_(b), c_(c){
}
friend void display(test &obj);
private:
int a_;
protected:
int b_;
private:
int c_;
};
void display( test &obj){
cout<<"a:"<<obj.a_<<" "<<"b:"<<obj.b_<<" "<<"c:"<<obj.c_<<endl;
}
int main()
{
test t(12, 23, 34);
display(t);//a:12 b:23 c:34
system("pause");
return 0;
}
#include <iostream>
using namespace std;
# include<math.h>
class point{
public:
point(double x=0, double y=0):x_(x),y_(y)
{
}
private:
double x_;
friend double distance(point &a, point &b);
double y_;
};
double distance(point &a, point &b){
double data_x = a.x_ - b.x_;
double data_y = a.y_ - b.y_;
return double (sqrt(data_x * data_x + data_y * data_y));
}
int main()
{
point t(2.0, 3.0), t2(5.0, 7.0);
cout<<"Distance is:"<<distance(t, t2)<<endl;//Distance is:5
system("pause");
return 0;
}
友元类
同友元函数一样,一个类可以将另一个类声明为友元类。若A类为B类的友元函类,则A类中的所有成员函数都是B类的友元函数,都可以访问B类的私有和保护成员。
class A{
public:
A(int a=0):a_(a){}
friend class B;
private:
int a_;
};
class B{
public:
B(int b=0):b_(b){}
void display(A &a);
private:
int b_;
};
void B:: display(A &a ){
cout<<"class A:"<<a.a_<<" "<<"class B:"<<b_<<endl;
}
int main()
{
A a(12);
B b;
b.display(a);//class A:12 class B:0
system("pause");
return 0;
}
注意
友元关系不能传递,友元关系是单向的,友元关系不能被继承。
内联函数
C++ 内联函数是通常与类一起使用。如果一个函数是内联的,那么在编译时,编译器会把该函数的代码副本放置在每个调用该函数的地方。
对内联函数进行任何修改,都需要重新编译函数的所有客户端,因为编译器需要重新更换一次所有的代码,否则将会继续使用旧的函数。
如果想把一个函数定义为内联函数,则需要在函数名前面放置关键字 inline,在调用函数之前需要对函数进行定义。如果已定义的函数多于一行,编译器会忽略 inline 限定符。
在类定义中的定义的函数都是内联函数,即使没有使用 inline 说明符。
inline int min(int a, int b)//定义内联函数
{
return (a > b) ? b:a;
}
int main()
{
cout<<min(12, 323);//12
system("pause");
return 0;
}
this 指针
每一个对象都能通过 this 指针来访问自己的地址。this 指针是所有成员函数的隐含参数。因此,在成员函数内部,它可以用来指向调用对象。this指针记录每个对象的内存地址,然后通过运算符->访问该对象的成员.
友元函数没有 this 指针,因为友元不是类的成员。只有成员函数才有 this 指针。
class A{
public:
A(int a):a_(a){}
int add(int a);
private:
int a_;
};
int A::add(int a)
{
return this->a_ + a;//this指针
}
int main()
{
A a(1);
cout<<a.add(2)<<endl;//3
system("pause");
return 0;
}
类的静态成员
我们可以使用 static 关键字来把类成员定义为静态的。当我们声明类的成员为静态时,这意味着无论创建多少个类的对象,静态成员都只有一个副本。
静态成员在类的所有对象中是共享的。如果不存在其他的初始化语句,在创建第一个对象时,所有的静态数据都会被初始化为零。我们不能把静态成员的初始化放置在类的定义中,但是可以在类的外部通过使用范围解析运算符 :: 来重新声明静态变量从而对它进行初始化。
- static成员独立于类对象而存在,也就所它不属于某个对象的成员,被全体的对象所共享
- 统计类型的对象创建的个数,用static成员来实现。
- 非static成员它属于类的对象,每个对象都有一份拷贝。
- static成员没有this指针,它不能访问非static成员,也不能用非static成员函数。
class count{
public:
static int count_;
count(int a= 0, int b=0):a_(a), b_(b)//构造函数
{
count_++;
}
count(const count & obj)//拷贝构造函数
{
count_++;
}
private:
int a_;
int b_;
};
int count::count_ = 0;//初始化为0
int main()
{
count a;//调用构造函数
count b(12, 23);//调用构造函数
count c(b);//调用拷贝构造函数
cout<<"count:"<<count::count_<<endl;//count:3
system("pause");
return 0;
}
指向类的指针
一个指向 C++ 类的指针与指向结构的指针类似,访问指向类的指针的成员,需要使用成员访问运算符 ->,就像访问指向结构的指针一样。与所有的指针一样,您必须在使用指针之前,对指针进行初始化。
class test{
private:
int a_;
public:
test(int a);
int add(int b);
void display();
};
test::test(int a):a_(a){cout<<"构造函数"<<endl;};
int test::add(int b){
return this->a_ + b;
}
void test::display(){cout<<"A:"<<a_<<endl;}
int main()
{
test t(10);
test *test_p;
test_p = &t;
cout<<test_p->add(12)<<"\n";//22
test t1(20);
test_p = &t1;
test_p->display();
system("pause");
return 0;
}
构造函数
22
构造函数
A:20
继承
继承允许我们依据另一个类来定义一个类,这使得创建和维护一个应用程序变得更容易。这样做,也达到了重用代码功能和提高执行时间的效果。
当创建一个类时,您不需要重新编写新的数据成员和成员函数,只需指定新建的类继承了一个已有的类的成员即可。这个已有的类称为基类,新建的类称为派生类。一个类可以派生自多个类,这意味着,它可以从多个基类继承数据和函数。定义一个派生类,我们使用一个类派生列表来指定基类。类派生列表以一个或多个基类命名。
单继承
class A{
private:
int a_;
public:
A(int a=0):a_(a){}
~A(){}
A(const A &str){}
void show(){}
};
class B : public A//派生类
{
private:
int b_;
public:
~B(){}
B(int b =0):b_(b){}
B(const B &str){}
};

多继承
class A{
private:
int a_;
public:
A(int a=0):a_(a){}
~A(){}
A(const A &str){}
void show(){}
};
class C{
public:
C(int c=0):c_(c){}
~C(){}
C(const C & str){}
private:
int c_;
};
class B : public A, C
{
private:
int b_;
public:
~B(){}
B(int b =0):b_(b){}
B(const B &str){}
};

菱形继承
class A{
private:
int a_;
public:
A(int a=0):a_(a){}
~A(){}
A(const A &str){}
void show(){}
};
class B:public A
{
private:
int b_;
public:
~B(){}
B(int b =0):b_(b){}
B(const B &str){}
};
class C:public A{
public:
C(int c=0):c_(c){}
~C(){}
C(const C & str){}
private:
int c_;
};
class D:public B,C{
public:
D(int d=0):d_(d){}
~D(){}
D(const D &str){}
private:
int d_;
};

**承与基类成员在派生类中的访问关系表 **

- 基类的私有成员在派生类中不能被访问,如果一些基类成员不想被基类对象直接访问,可以定义为保护成员。
- public继承是一个接口继承,保持is-a原则,每个父类可用的成员对子类也可用,因为每个子类对象也是一个父类对象。
- protect/private继承基类的部分成员并未成为子类的一部分,是has-a的关系原则,这种继承关系很少用,一般用public继承关系
- 不管哪种继承关系,在派生类内部都可以访问基类中的公有成员和保护成员,但是子类中的成员不能访问父类中的私有成员。
- 使用struct时的默认继承关系是public,而class时的默认继承关系是private,最好是把继承方式写出来。
**继承与转换 **
1)子类对象可以赋值给父类对象。
2)父类对象不可以赋值给子类对象。
3)父类对象的指针和引用可以指向子类对象。
4)子类对象的指针和引用不能指向父类对象,但是可以通过强制转化完成。
重载运算符和重载函数
运算符重载是针对新类型数据的实际需要,对原有运算符进行适当的改造,一般来讲,重载的功能应当与原有功能相类似,不能改变原运算符的操作对象个数,同时至少要有一个操作对象是自定义类型。
可以进行运算符重载的有:
不能重载的运算符只有5个,它们是类属关系运算符“.”、成员指针运算符“.*”、作用域分辨符“::”、sizeof运算符和三木运算符“?:”
友元函数的类型
class test {
public:
test(int a_, int b_);
test() {};
friend test operator + (test &temp1, test &temp2);
friend test operator - (test &temp1, test &temp2);
friend test operator * (test &temp1, test &temp2);
friend test operator / (test &temp1, test &temp2);
friend test operator ++ (test &temp1);//前置++
friend test operator -- (test &temp1, int);//后置++
int a;
int b;
};
test::test(int a_, int b_) :a(a_), b(b_) {}
test operator + (test &temp1, test &temp2)
{
test ret;
ret.a = temp1.a + temp2.a;
ret.b = temp1.b + temp2.b;
return ret;
}
test operator - (test &temp1, test &temp2)
{
test ret;
ret.a = temp1.a - temp2.a;
ret.b = temp1.b - temp2.b;
return ret;
}
test operator * (test &temp1, test &temp2)
{
test ret;
ret.a = temp1.a * temp2.a;
ret.b = temp1.b * temp2.b;
return ret;
}
test operator / (test &temp1, test &temp2)
{
test ret;
ret.a = temp1.a / temp2.a;
ret.b = temp1.b / temp2.b;
return ret;
}
test operator ++(test &temp1)
{
temp1.a = temp1.a + 1;
temp1.b = temp1.b + 1;
return temp1;
}
test operator ++(test &temp1, int)//后置++
{
temp1.a = temp1.a++;
temp1.b = temp1.b++;
return temp1;
}
内部函数的形式
class test {
public:
test(int a_, int b_);
test() {};
test operator + (test &temp1);
test operator - (test &temp1);
test operator * (test &temp1);
test operator / (test &temp1);
test operator ++ ();//前置++
test operator ++ (int);//后置++
int a;
int b;
};
test::test(int a_, int b_) :a(a_), b(b_) {}
test test:: operator + (test &temp1)
{
test ret;
ret.a = a + temp1.a;
ret.b = b+ temp1.b;
return ret;
}
test test:: operator - (test &temp1)
{
test ret;
ret.a = a - temp1.a;
ret.b = b - temp1.b;
return ret;
}
test test :: operator * (test &temp1)
{
test ret;
ret.a = a * temp1.a;
ret.b = b * temp1.b;
return ret;
}
test test :: operator / (test &temp1)
{
test ret;
ret.a = a / temp1.a;
ret.b = b / temp1.b;
return ret;
return ret;
}
test test:: operator ++()//前置++
{
a = a + 1;
b = b + 1;
return *this;
}
test test:: operator ++(int)//后置++
{
a = a++;
b = b++;
return *this;
}
int main()
{
test t1(10, 20);
test t2(20, 30);
cout << "(10, 20)" << endl;
cout << "(20, 30)" << endl;
cout << "_____+______" << endl;
test res = t1 + t2;
cout << "x=" << res.a << " " << "y=" << res.b << endl;
cout << "_____*______" << endl;
test res1 = t1 * t2;
cout << "x=" << res1.a << " " << "y=" << res1.b << endl;
cout << "_____-______" << endl;
test res2 = t1 - t2;
cout << "x=" << res2.a << " " << "y=" << res2.b << endl;
cout << "_____/______" << endl;
test res3 = t1 / t2;
cout << "x=" << res3.a << " " << "y=" << res3.b << endl;
cout << "_____++t1______" << endl;
test res4 = ++t1;
cout << "x=" << res4.a << " " << "y=" << res4.b << endl;
cout << "_____t1++______" << endl;
test res5 = t1++;
cout << "x=" << res5.a << " " << "y=" << res5.b << endl;
system("pause");
return 0;
}
接口的实现
有时候,我们得提供一些接口给别人使用。接口的作用,就是提供一个与其他系统交互的方法。其他系统无需了解你内部细节,并且也无法了解内部细节,只能通过你提供给外部的接口来与你进行通信。根据c++的特点,我们可以采用纯虚函数的方式来实现。这样做的好处是能够实现封装和多态。
也下是interfacedefineandrealize.h头文件的定义:
#ifndef _INTERFACE_DEFINE_AND_REALIZE_H
#define _INTERFACE_DEFINE_AND_REALIZE_H
#include<string>
using std::string;
class Person
{
public:
Person() :str_name("xxxxx") {};
virtual~Person() =0;
virtual void Eat()=0;//吃
virtual void Sleep()=0;//睡觉
virtual void work() = 0;//工作
virtual void set_name(const string name)=0;//设置名字
virtual string get_name()=0;//获取名字
private:
string str_name;
};
class student :public Person {
private:
string str_name;
public:
student() :str_name("xxx") {};
~student();
void Eat();
void Sleep();
void work();
void set_name(const string name);
string get_name();
};
#endif //_INTERFACE_DEFINE_AND_REALIZE_H
以下是interfacedefineandrealize.cpp文件:
#include "pch.h"
#include "interfaceAndRealize.h"
#include<iostream>
#include<string>
using std::string;
using namespace std;
void student::Sleep()
{
cout << "student sleep" << endl;
}
void student::Eat()
{
cout << "students eat" << endl;
}
void student::work()
{
cout << "Studets work" << endl;
}
void student::set_name(const string name)
{
str_name = name;
}
string student::get_name()
{
return str_name;
}
接口导出//需要导出函数,即用户会在外部可以调用的接口InterfaceDefineAndRealize.def
//需要导出函数,即用户会在外部可以调用的接口
_declspec(dllexport)bool GetPersonObject(void** _RtObject)
{
Person *pMan = NULL;
pMan = new student();
*_RtObject = (void*)pMan;
return true;
}
新建项目,加载上述三个文件,设置项目属性—>配置属性——>常规——>配置类型 ,选择"动态库.dlll",生成可用的动态库,假如项目名称为InterfaceDefineAndRealize(注意:项目名称必须与模块定义文件中 LIBRARY 后面定义的名字相同,否则将导致出现无法找到动态库的错误。),则在该项目的当前工作目录下位生成动态库和它的导入库。
接口的调用
为了与常规的调用动态库的方式保持一致,这里做一些额外工作。新建“include”文件夹,并将InterfaceDefineAndRealize.h放到此文件夹下,新建“lib”文件夹并将InterfaceDefineAndRealize.lib文件放到此文件夹下。新建项目UsingInterface,添加源文件实现调用接口的功能。
- 为项目添加附加包含目录
方法1:项目属性——>配置属性——>C/C++——>常规——>附加包含目录 将include文件夹的全路径添加进来。
方法2:项目属性——>配置属性——>VC++目录——>包含目录 中将include文件夹的全路径添加进来。
- 为项目添加附加库
方法1:项目属性——>配置属性——>链接器——>常规——>附加库目录 将lib文件夹的全路径添加进来。
方法2:项目属性——>配置属性——>VC++目录——>库目录 将lib文件夹的全路径添加进来。
注意:2.1中的方法1与2.2中的方法1对应,2.1中的方法2与2.2中的方法2对应,不能不换使用。
- 为项目添加导入库
项目属性——>配置属性——>链接器——>输入——>附加依赖项 中添加InterfaceDefineAndRealize.lib
- 为项目提供动态库
将生成的.dll动态库放到项目的当前目录下的Debug目录下,防止出现缺少动态库的错误。
#include <iostream>
#include "InterfaceDefineAndRealize.h"
bool _declspec(dllimport) GetPersonObject(void** _RtObject);
int main()
{
Person* person=NULL;
void* pObj=NULL;
if(GetPersonObject(&pObj))//调用接口
{
person=(Person*)pObj;
person->Eat();
person->Sleep();
person->set_name("devil");
cout<<person->get_name()<<endl;
person->Work();
if(person!=NULL)
{
delete person;
person=NULL;
}
}
system("pause");
return 0;
}
