ShardedJedisPipeline 源码分析
一、什么是pipeline?什么是ShardedJedis?
由于pipeline和ShardedJedis的介绍和源码分析在网上已经有了,本文就不再赘述,直接给出链接:
pipeline的介绍:
http://blog.csdn.net/freebird_lb/article/details/7778919
pipeline源码分析:
http://blog.csdn.net/ouyang111222/article/details/50942893
ShardedJedis :
http://blog.csdn.net/ouyang111222/article/details/50958062
请读者在继续阅读之前确保自己掌握了pipeline和shardedJedis的概念。
二、ShardedJedisPipeline源码分析
1:怎么使用?
如同名字一样,ShardedJedisPipeline是分布式异步调用的方式,即后端支持多台Redis实例,并且可以从客户端以pipeline的方式打包发送命令,先来看看怎么使用:
public static void main(String[] args) {
List<JedisShardInfo> shards = Arrays.asList(
new JedisShardInfo("IP1", 6379),
new JedisShardInfo("IP2", 6379),
new JedisShardInfo("IP3", 6379)
);
ShardedJedis shardedJedis = new ShardedJedis(shards);
ShardedJedisPipeline shardedJedisPipeline = shardedJedis.pipelined();
for (int i = 0; i < 10; i++) {
shardedJedisPipeline.set("k" + i, "v" + i);
}
shardedJedisPipeline.sync();
}因为客户端有Hash算法,所以在for循环中set的k1~k9会被打散分配到三台机器上(为了模拟效果,也可以在同一台机器上启动三个Redis实例),下面是分别去三台机器上查看key的分布情况:
第一台:
127.0.0.1:6379> keys k*
1) "k2"
2) "k0"
第二台:
127.0.0.1:6379> keys k*
1) "k4"
2) "k5"
3) "k3"
4) "k9"
5) "k8"
第三台:
127.0.0.1:6379> keys k*
1) "k1"
2) "k6"
3) "k7"
如上所示,k1 ~ k9 分别在不同的机器上,我们接下来把数据拿回来:
for (int i = 0; i < 10; i++) {
shardedJedisPipeline.get("k"+i);
}
List<Object> list = shardedJedisPipeline.syncAndReturnAll();
for(Object obj:list) {
System.out.println(obj);
}执行结果如下:
这时候难道不应该思考一个问题吗?
虽然我们get操作是依次 get k1 ~ k9 ,但是由于k1 ~ k9分别在不同的机器上,怎么保证他们回来的顺序呢?请在继续往下看之前先思考这个问题你会怎么解决。
2:开始分析
首先整一份Jedis的源码下来,推荐用IDEA打开,因为IDEA有功能可以生成类的调用图http://blog.csdn.net/qq_27093465/article/details/52857307,我生成的类图如下所示:
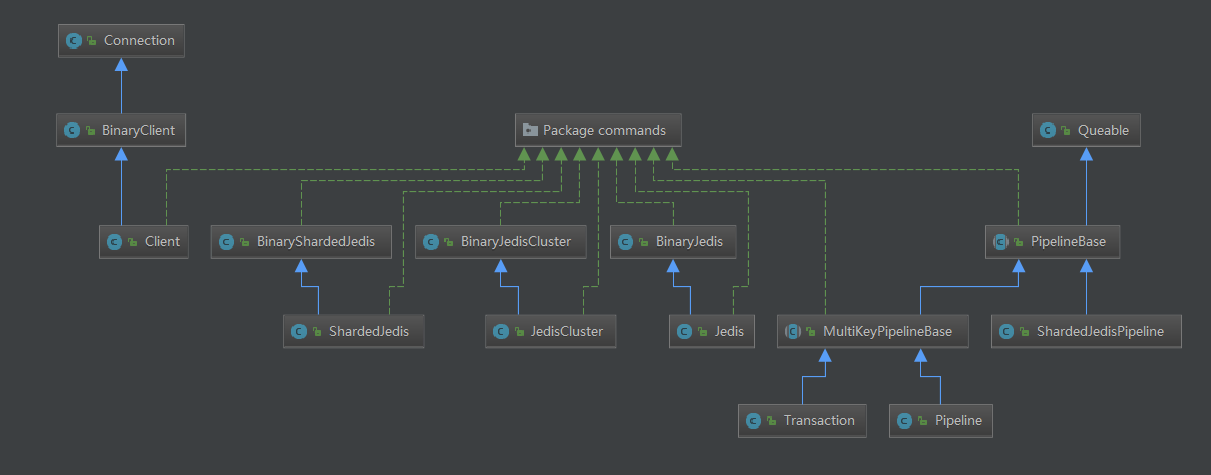
可以看到ShardedJedisPipeline继承自PipelineBase,继续继承自Queable。我们从get的代码开始,注意看我的注释,我保证以最简单的方式解释清楚这个问题:
shardedJedisPipeline.get("k"+i);它的实现在PipelineBase中:
public Response<String> get(String key) {
this.getClient(key).get(key);
return this.getResponse(BuilderFactory.STRING);
}我们接着去看看getClient(key) :
protected Client getClient(String key) {
/*getShard对key做HASH,同时返回这个key对应的client对象,一个client对象就代表了一条连接,此时返回的对象和set的时候后端对应的Redis机器IP和PORT是一样的,这样才能保证这条get命令发出去能去正确的机器上拿回数据*/
Client client = jedis.getShard(key).getClient();
/*!!! 关键点
private Queue<Client> clients = new LinkedList<Client>();
上面是clients的定义,是一个队列,它会按照client的使用顺序把它入队,相当于按照顺序保存了每个命令对应的连接(保存的本地端口是关键),因为回来的时候就按照这个顺序依次去端口读取数据了*/
clients.add(client);
results.add(new FutureResult(client));
return client; //最后把client返回
}再回去看 this.getClient(key).get(key)其实相当于调用 client.get(key),这样会把这条命令添加到outputstream,但是不会发送,(因为是pipeline的方式,最后才会统一刷新输出流)this.getResponse(BuilderFactory.STRING)相当于为每个回来的包准备一块空间。
接下来我们调用了:
List<Object> list = shardedJedisPipeline.syncAndReturnAll();去看看syncAndReturnAll()方法:
public List<Object> syncAndReturnAll() {
List<Object> formatted = new ArrayList<Object>();
/* 遍历clients 队列,按照先进先出的规则,依次从每个client对象拿出一条(getOne())返回结果。看下面的图解。
*/
for (Client client : clients) {
formatted.add(generateResponse(client.getOne()).get());
}
/*将结果添加到formatted返回*/
return formatted;
}
说明:
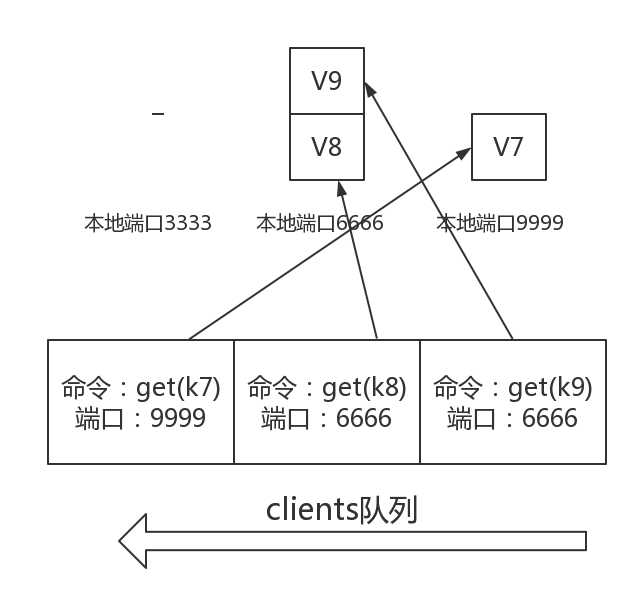
- 因为有三台Redis服务器,所以会有三条socket连接,假设他们对应的本地端口为3333,6666,9999,后面是每个连接的接收缓冲区。
- Redis服务器是单线程,所以每条连接上接收缓冲区返回的结果一定是按照顺序的,比如发送按照getk0,getk2的顺序,则结果也是按照这样返回。
- clients队列中记录了每个client对象,它能标识这条get命令应该去哪个本地端口读取数据,getone按照Redis协议分隔读取一条就是相应的结果
就这样依次出队,依次解析,现在我们假设队列读取到了最后的三条,则情况如下:
3:总结
其实这种方法很巧妙的原因也得益于Redis是一个单线程的服务器,对于发送向它的命令,总是按照发送的顺序返回,也正是这样,才能有pipeline这种方式,不然多线程各自都有自己的缓冲区,自己如果处理完就返回了,这样是没法玩的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号