深度学习-迁移学习笔记
1.什么是迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务,虽然大多数机器学习算法都是为了解决单个任务而设计的,但是促进迁移学习的算法的开发是机器学习社区持续关注的话题。找到目标问题的相似性,迁移学习任务就是从相似性出发,将旧领域(domain)学习过的模型应用在新领域上。
2.为什么需要迁移学习
使用深度学习技术解决问题的过程中,最常见的障碍在于,因为模型有大量的参数需要训练,因此需要海量训练数据作支撑。虽然有大量的数据,但往往都是没有标注的,无法训练机器学习模型。人工进行数据标定太耗时。
在面对某一领域的具体问题时,通常可能无法得到构建模型所需规模的数据。普通人无法拥有庞大的数据量与计算资源。因此需要借助于模型的迁移。
借助迁移学习,在一个模型训练任务中针对某种类型数据获得的关系也可以轻松地应用于同一领域的不同问题。
3.迁移学习的基本问题有哪些?
基本问题主要有3个:
- How to transfer: 如何进行迁移学习?(设计迁移方法)
- What to transfer: 给定一个目标领域,如何找到相对应的源领域,然后进行迁移?(源领域选择)
- When to transfer: 什么时候可以进行迁移,什么时候不可以?(避免负迁移)
4.迁移学习与传统机器学习有什么区别?
迁移学习 传统机器学习
数据分布 训练和测试数据不需要同分布 训练和测试数据同分布
数据标签 不需要足够的数据标注 足够的数据标注
建模 可以重用之前的模型 每个任务分别建模
5.迁移学习分类
先介绍一下一些词的意义:
域(Domain):数据特征和特征分布组成,是学习的主体
-
- 源域(source domain): 已有知识的域
- 目标域(target domain): 要进行学习的域
任务:由目标函数和学习结果组成,是学习的结果
-
按特征空间分类
- 同构迁移学习(Homogeneous TL): 源域和目标域的特征空间相同, Ds=Dt
- 异构迁移学习(Heterogeneous TL):源域和目标域的特征空间不同, Ds≠Dt
-
按迁移情景分类
- 归纳式迁移学习(Inductive TL):源域和目标域的学习任务不同
- 直推式迁移学习(Transductive TL):源域和目标域不同,学习任务相同
- 无监督迁移学习(Unsupervised TL):源域和目标域均没有标签
-
按迁移方法分类
-
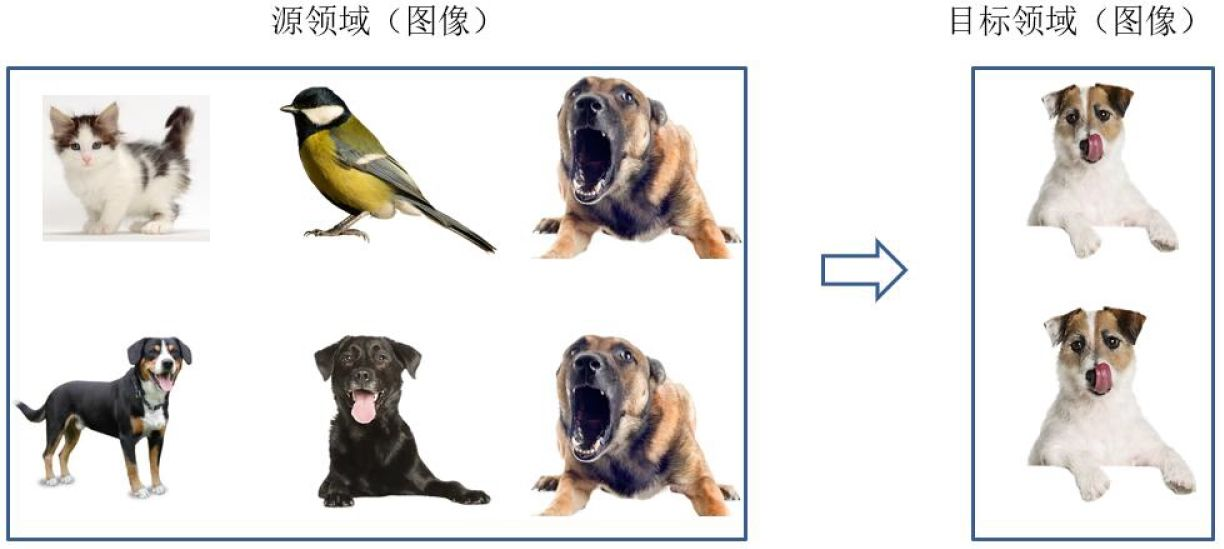
基于样本的迁移 (Instance based TL):通过权重重用源域和目标域的样例进行迁移
基于样本的迁移学习方法 (Instance based Transfer Learning) 根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习。下图形象地表示了基于样本迁移方法的思想源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗这一种类别。在迁移时,为了最大限度地和目标域相似,我们可以人为地提高源域中属于狗这个类别的样本权重。
![]()
-
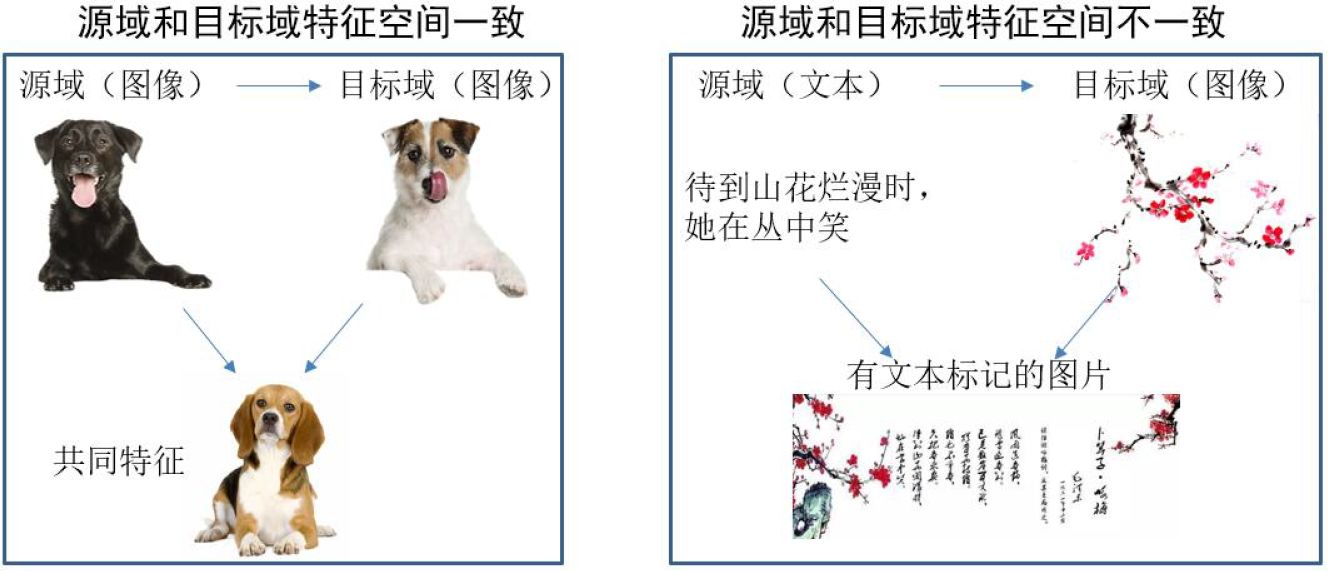
基于特征的迁移 (Feature based TL):将源域和目标域的特征变换到相同空间
基于特征的迁移方法 (Feature based Transfer Learning) 是指将通过特征变换的方式互相迁移,来减少源域和目标域之间的差距;或者将源域和目标域的数据特征变换到统一特征空间中,然后利用传统的机器学习方法进行分类识别。根据特征的同构和异构性,又可以分为同构和异构迁移学习。下图很形象地表示了两种基于特 征的迁移学习方法。
![]()
-
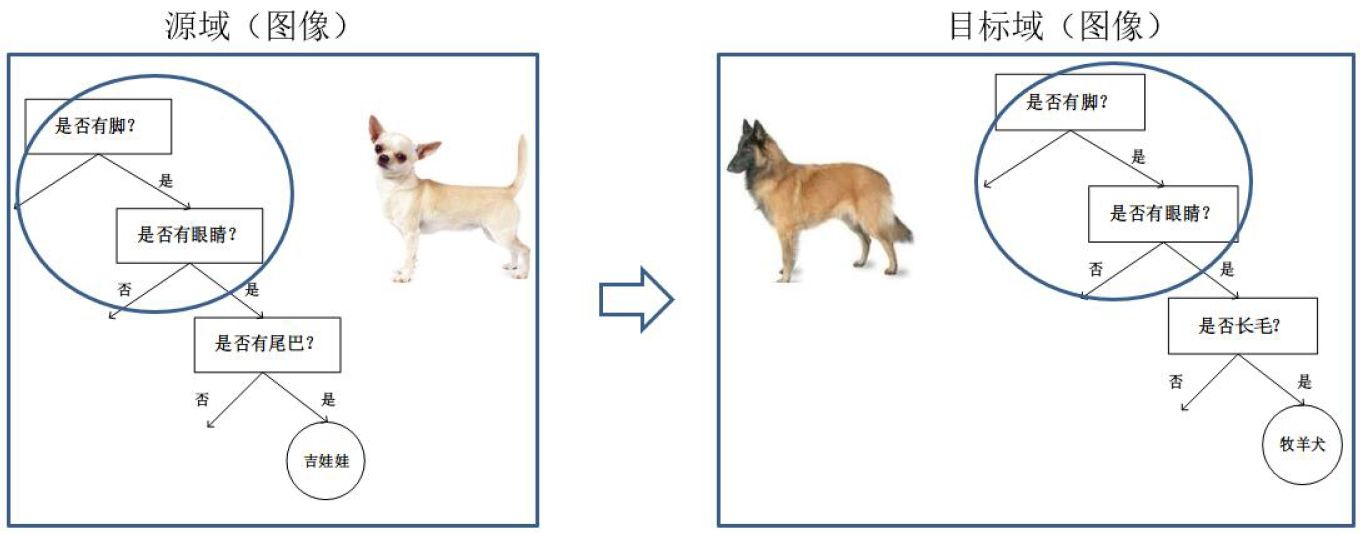
基于模型的迁移 (Parameter based TL):利用源域和目标域的参数共享模型
基于模型的迁移方法 (Parameter/Model based Transfer Learning) 是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是: 源域中的数据与目标域中的数据可以共享一些模型的参数。下图形象地表示了基于模型的迁移学习方法的基本思想。
![]()
-
基于关系的迁移 (Relation based TL):利用源域中的逻辑网络关系进行迁移
基于关系的迁移学习方法 (Relation Based Transfer Learning) 与上述三种方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关系。下图形象地表示了不 同领域之间相似的关系。
![]()
![]()
-


6. 迁移学习的核心及度量准则?
迁移学习的总体思路可以概括为:开发算法来最大限度地利用有标注的领域的知识,来辅助目标领域的知识获取和学习。
迁移学习的核心是:找到源领域和目标领域之间的相似性,并加以合理利用。这种相似性非常普遍。比如,不同人的身体构造是相似的;自行车和摩托车的骑行方式是相似的;国际象棋和中国象棋是相似的;羽毛球和网球的打球方式是相似的。这种相似性也可以理解为不变量。以不变应万变,才能立于不败之地。
有了这种相似性后,下一步工作就是, 如何度量和利用这种相似性。度量工作的目标有两点:一是很好地度量两个领域的相似性,不仅定性地告诉我们它们是否相似,更定量地给出相似程度。二是以度量为准则,通过我们所要采用的学习手段,增大两个领域之间的相似性,从而完成迁移学习。
一句话总结: 相似性是核心,度量准则是重要手段。
7. 迁移学习与其他概念的区别?
- 迁移学习与多任务学习关系:
- 多任务学习:多个相关任务一起协同学习;
- 迁移学习:强调信息复用,从一个领域(domain)迁移到另一个领域。
- 迁移学习与领域自适应: 领域自适应:使两个特征分布不一致的domain一致。
- 迁移学习与协方差漂移: 协方差漂移:数据的条件概率分布发生变化。
8. 什么情况下可以使用迁移学习?
迁移学习 最有用的场合是,如果你尝试优化任务B的性能,通常这个任务数据相对较少。 例如,在放射科中你知道很难收集很多射线扫描图来搭建一个性能良好的放射科诊断系统,所以在这种情况下,你可能会找一个相关但不同的任务,如图像识别,其中你可能用 1 百万张图片训练过了,并从中学到很多低层次特征,所以那也许能帮助网络在任务在放射科任务上做得更好,尽管任务没有这么多数据。
假如两个领域之间的区别特别的大, 不可以直接采用迁移学习,因为在这种情况下效果不是很好。在这种情况下,推荐以上的方法,在两个相似度很低的domain之间一步步迁移过去(踩着石头过河)。
9. 什么是finetune?
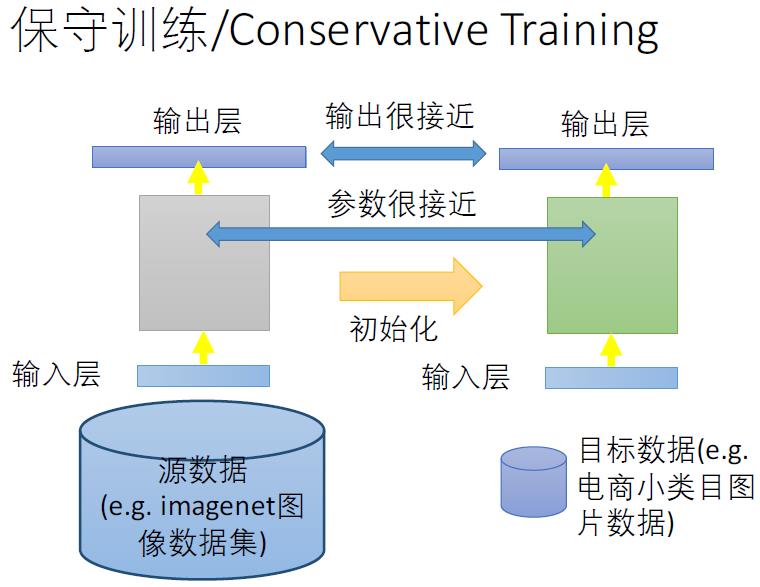
度网络的finetune也许是最简单的深度网络迁移方法。 Finetune,也叫微调、fine-tuning, 是深度学习中的一个重要概念。简而言之,finetune就是利用别人己经训练好的网络,针对自己的任务再进行调整。从这个意思上看,我们不难理解finetune是迁移学习的一部分。
为什么需要已经训练好的网络?
在实际的应用中,我们通常不会针对一个新任务,就去从头开始训练一个神经网络。这样的操作显然是非常耗时的。尤其是,我们的训练数据不可能像ImageNet那么大,可以训练出泛化能力足够强的深度神经网络。即使有如此之多的训练数据,我们从头开始训练,其代价也是不可承受的。
为什么需要 finetune?
因为别人训练好的模型,可能并不是完全适用于我们自己的任务。可能别人的训练数据和我们的数据之间不服从同一个分布;可能别人的网络能做比我们的任务更多的事情;可能别人的网络比较复杂,我们的任务比较简单。
什么情况下可以fine-tune以及如何fine-tune?https://www.jianshu.com/p/445a49c09769
a. 新数据集比较小且和原数据集相似,因为新数据集比较小(比如<5000),如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当作特征提取器,用提取的特征训练线性分类器。
b. 新数据集比较大且和原数据集类似(比如>10000),因为新数据集足够大,可以fine-tune微调整个网络。
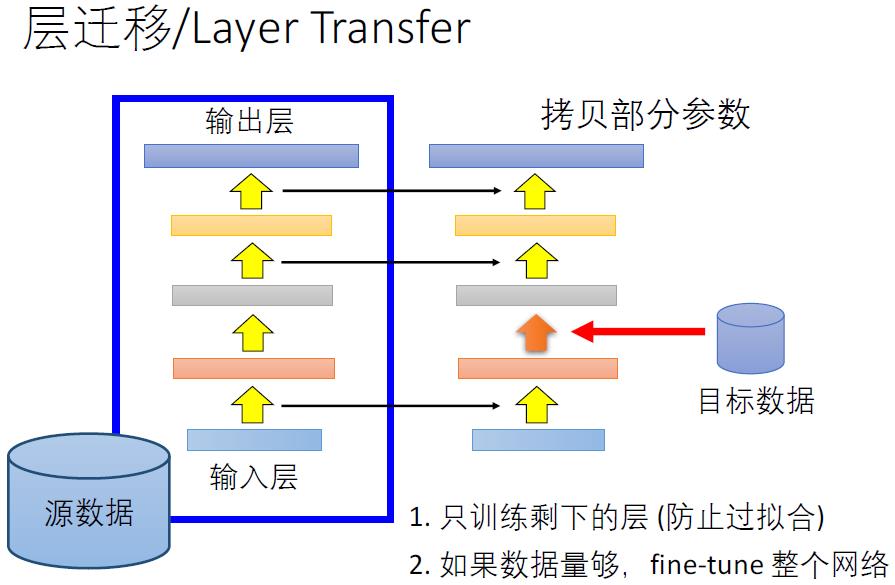
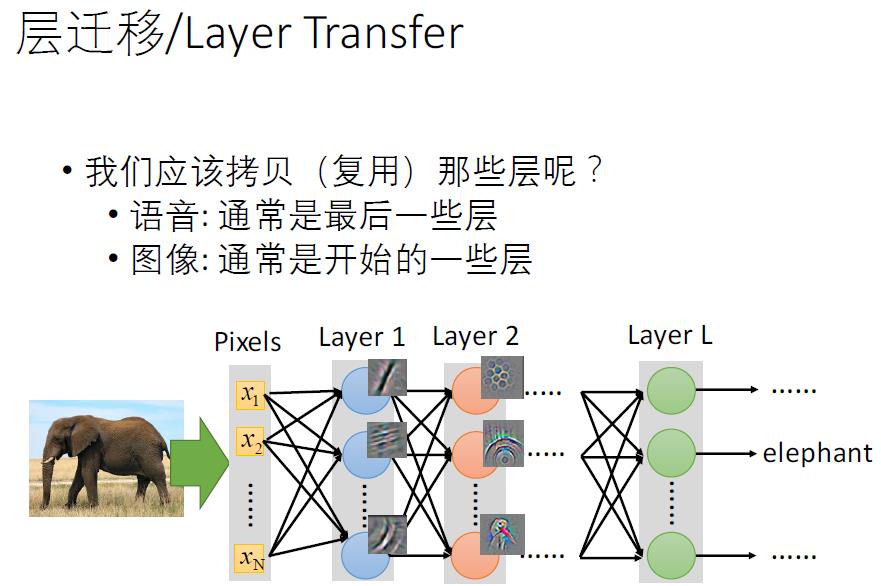
c.新数据集比较小且和原数据集不相似,新数据集比较小,最好不要fine-tune。和原数据集不类似,最好也不要使用高层特征。这时,可以使用前面的特征来训练分类器。
d.新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练,但是在实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
这边需要注意的是:网络的前几层学到的是通用的特征,后面几层学到的是与类别相关的特征。所以可以冻结去降低成本。本质上fine-tune基本思路都是一样的,就是解锁少数卷积层继续对模型进行训练。
10. 什么是深度网络自适应?
深度网络的 finetune 可以帮助我们节省训练时间,提高学习精度。但是 finetune 有它的先天不足:它无法处理训练数据和测试数据分布不同的情况。而这一现象在实际应用中比比皆是。因为 finetune 的基本假设也是训练数据和测试数据服从相同的数据分布。这在迁移学习中也是不成立的。因此,我们需要更进一步,针对深度网络开发出更好的方法使之更好地完成迁移学习任务。
以我们之前介绍过的数据分布自适应方法为参考,许多深度学习方法都开发出了自适应层(AdaptationLayer)来完成源域和目标域数据的自适应。自适应能够使得源域和目标域的数据分布更加接近,从而使得网络的效果更好。
11. GAN在迁移学习中的应用
生成对抗网络 GAN(Generative Adversarial Nets) 受到自博弈论中的二人零和博弈 (two-player game) 思想的启发而提出。它一共包括两个部分:
- 一部分为生成网络(Generative Network),此部分负责生成尽可能地以假乱真的样本,这部分被称为生成器(Generator);
- 另一部分为判别网络(Discriminative Network), 此部分负责判断样本是真实的,还是由生成器生成的,这部分被成为判别器(Discriminator) 生成器和判别器的互相博弈,就完成了对抗训练。
- GAN 的目标很明确:生成训练样本。这似乎与迁移学习的大目标有些许出入。然而,由于在迁移学习中,天然地存在一个源领域,一个目标领域,因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据 (通常是目标域) 当作是生成的样本。此时,生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器 (Feature Extractor)。而生成器通过多次循环就可以捕捉到源域与目标域共同的特征信息。我们也可以称之为域对抗/Domain-‐adversarial training,注意:原始数据有标签,目标数据无标签。

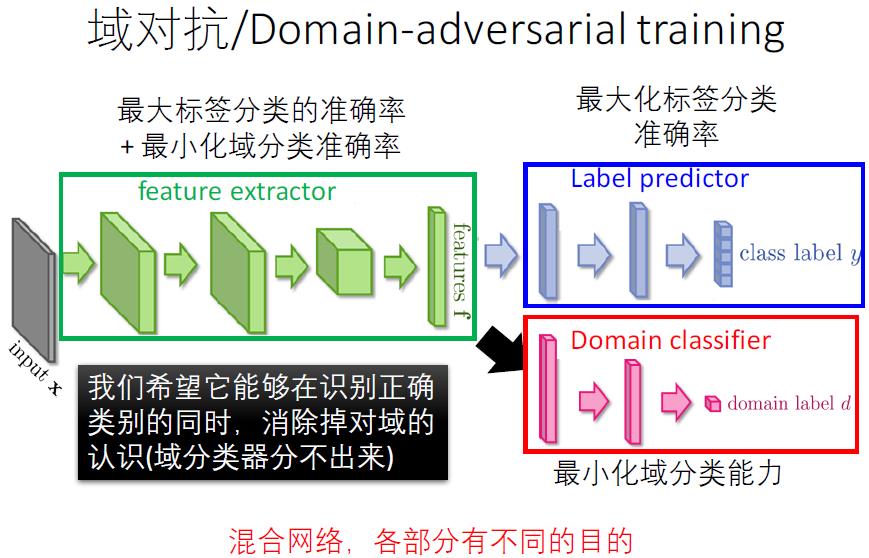

对于域对抗网络可以参见https://zhuanlan.zhihu.com/p/51499968,此文说的还算详细,注意域分类器(domain classifier)中将源域与目标域混合在一起,所以才可以进行域对抗训练,使得两个域处在同一个空间的特征分布被抽象出来,域分类器就无法区分所给的数据是属于哪个域了。
(以上参照http://blog.itpub.net/69942346/viewspace-2654034/)
12.多任务学习(Multitask Learning)参照https://blog.csdn.net/catcatrun/article/details/75034476
多任务学习(Multitask learning)定义:基于共享表示(shared representation),把多个相关的任务放在一起学习的一种机器学习方法。
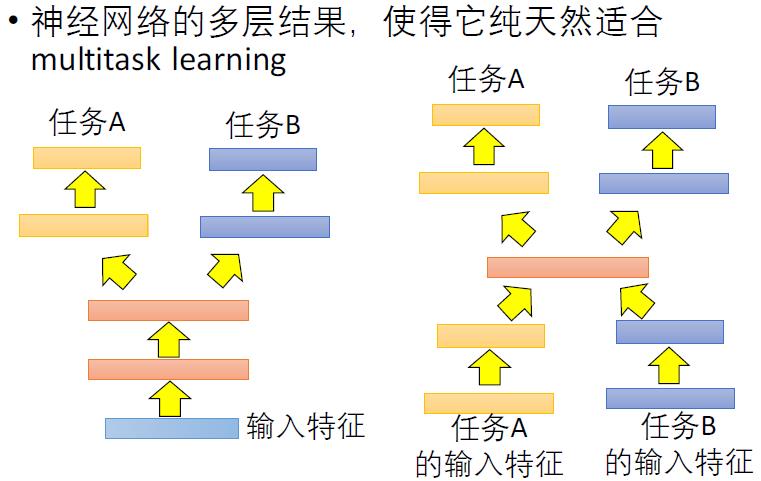
多任务学习(Multitask Learning)是一种推导迁移学习方法,主任务(main tasks)使用相关任务(related tasks)的训练信号(training signal)所拥有的领域相关信息(domain-specific information),做为一直推导偏差(inductive bias)来提升主任务(main tasks)泛化效果(generalization performance)的一种机器学习方法。多任务学习涉及多个相关的任务同时并行学习,梯度同时反向传播,多个任务通过底层的共享表示(shared representation)来互相帮助学习,提升泛化效果。
简单来说:多任务学习把多个相关的任务放在一起学习(注意,一定要是相关的任务,后面会给出相关任务(related tasks)的定义,以及他们共享了那些信息),学习过程(training)中通过一个在浅层的共享(shared representation)表示来互相分享、互相补充学习到的领域相关的信息(domain information),互相促进学习,提升泛化的效果。
共享表示shared representation:
共享表示的目的是为了提高泛化(improving generalization),多任务学习最简单的共享方式,多个任务在浅层共享参数。MTL中共享表示有两种方式:
(1)基于参数的共享(Parameter based):比如基于神经网络的MTL,高斯处理过程。
(2)基于约束的共享(regularization based):比如均值,联合特征(Joint feature)学习(创建一个常见的特征集合)。
为什么把多个相关的任务放在一起学习,可以提高学习的效果?关于这个问题,有很多解释。这里列出其中一部分,以下图中由单隐含层神经网络表示的单任务和多任务学习对比为例。
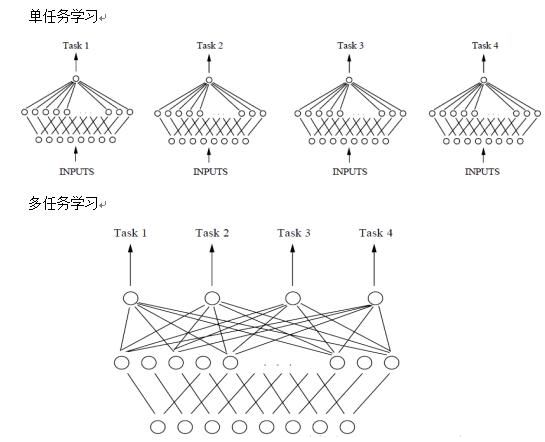
(1) 多个相关任务放在一起学习,有相关的部分,但也有不相关的部分。当学习一个任务(Main task)时,与该任务不相关的部分,在学习过程中相当于是噪声,因此,引入噪声可以提高学习的泛化(generalization)效果。
(2) 单任务学习时,梯度的反向传播倾向于陷入局部极小值。多任务学习中不同任务的局部极小值处于不同的位置,通过相互作用,可以帮助隐含层逃离局部极小值。
(3) 添加的任务可以改变权值更新的动态特性,可能使网络更适合多任务学习。比如,多任务并行学习,提升了浅层共享层(shared representation)学习速率的可能,较大的学习速率提升了学习效果。
(4) 多个任务在浅层共享表示,可能削弱了网络的能力,降低网络过拟合,提升了泛化效果。
还有很多潜在的解释,为什么多任务并行学习可以提升学习效果(performance)。多任务学习有效,是因为它是建立在多个相关的,具有共享表示(shared representation)的任务基础之上的,因此,需要定义一下,什么样的任务之间是相关的。
13.零样本学习(Zero-shot Learning)
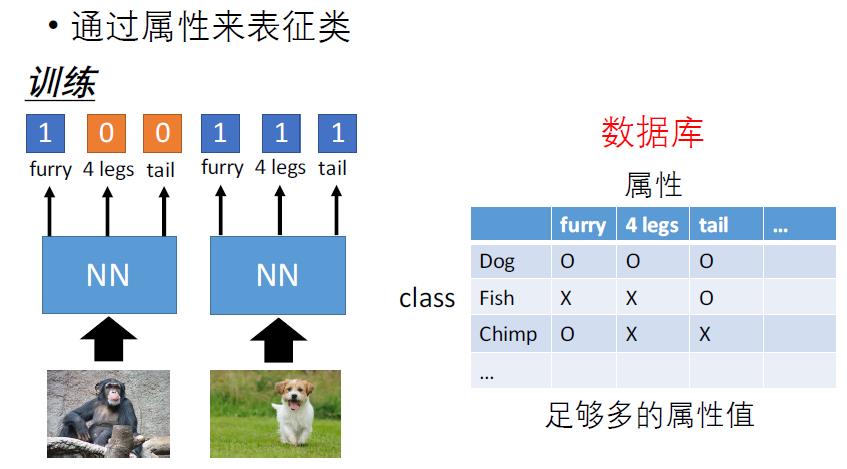
当我们有大量的数据标签库且每个标签都有一定的特征描述,假设我们并没看过“草泥马”的样子,但是我们拥有一些关于它的体型特征--四条腿、脖子的长度、耳朵的大小、全身绒毛等,有了这些特征我们就知道它是“草泥马”。重点是没有看过“草泥马”长什么样子,如果突然给计算机这样一个没有相似性的训练过的模型,这时候我们该如何通过迁移训练进行学习呢?重点来了,我们可以通过学习大量的与“草泥马”结构相近的动物的特征,诸如四条腿、全身有毛、脖子、耳朵、等。我们只关心四条腿、全身有毛、脖子、耳朵、等这些特征,并训练了大量参数,这时再进行对突然给出的陌生的图片进行--四条腿、全身有毛、脖子、耳朵、等特征的学习,然后再到数据库中找到与之相近的特征对应的标签就可以了。这就是Zero-shot Learning。简单的说,就是我要学到与目标具有相同的特征属性,再去学习目标本身这些特征属性的独特之处,再到数据库进行比对。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号