深度学习-生成对抗网络GAN笔记
生成对抗网络(GAN)由2个重要的部分构成:
生成器G(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
判别器D(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”
生成对抗网络的工作过程:
第一阶段:固定判别器D,训练生成器G
初始化判别器D,让一个生成器G不断生成“假数据”,然后给这个判别器D去判断。
一开始,生成器G还很弱,所以很容易被判断出是假的。
但是随着不断的训练,生成器G技能不断提升,最终骗过了判别器D。
此时,判别器D基本属于瞎猜的状态,判断是否为假数据的概率为50%。
第二阶段:固定生成器G,训练判别器D
当通过了第一阶段,继续训练生成器G就没有意义了。这个时候需要固定生成器G,然后开始训练判别器D。
判别器D通过不断训练,提高了自己的鉴别能力,最终他可以准确的判断出所有的假图片。
到了这个时候,生成器G已经无法骗过判别器D。
循环阶段一和阶段二
通过不断的循环,生成器G和判别器D的能力都越来越强。
最终我们得到了一个效果非常好的生成器G,我们就可以用它来生成我们想要的图片了。
通过图与公式说明GAN的工作原理
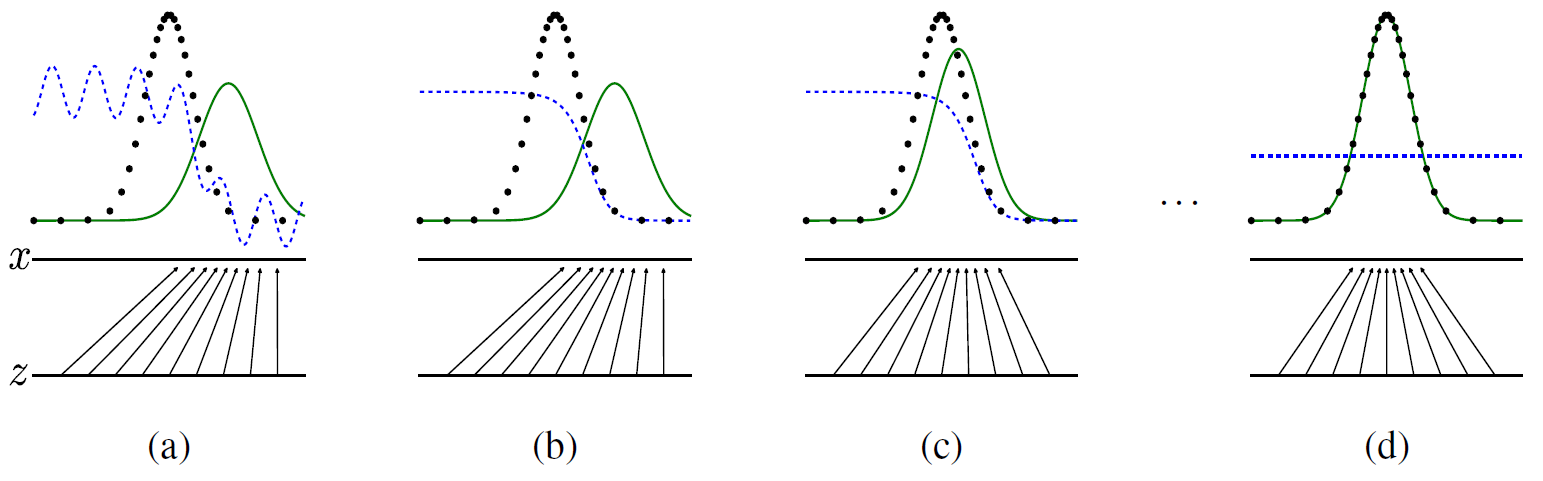
图中,黑色点线是真实数据,绿色点线是生成数据,生成器G的作用,蓝色点线是判别公式,判别器D的作用:
![]()
其中pdata(x)的值可看作是1(真实数据分布),pg(x)-->(绿色点线)看作是生成数据分布,它在循环中即将接近1,所以当判别器无法判断生成器的时候上面的公式D*(x)的值就为0.5。
x与z的关系就是真实数据与生成数据的映射关系。
在Generative Adversarial Nets原文中作者给出了损失函数公式:![]()
可以这样理解这个公式:
判别器要以最大可能判别出是生成数据,生成器生成的数据与真实数据的差距尽可能的小。也就是在循环的过程中同时增强判别器判别能力与提高生成器的生成更接近真实数据的能力。
判别器模型D:![]()
生成器模型G:![]()
D1(x)为真实数据判别值,它的期望为1,取对数的话值就变为0了,D2(G(z))为生成数据判别值,判别器期望判断出它是生成数据,所以期望它为0。而对生成器模型来说,是期望判别器判别不出来它是生成的数据,所以对于生成器来说它期望D2(G(z))的值为1。
生成对抗网络的优缺点
优点:
- 不需要大量label数据loss来源于D判定
- 产生大量生成数据用于训练,接近无监督学习
- 可以和深度神经网络结合
缺点:
- 数据直接生成,没有推导过程
- 生成器,判别器需要配合共同训练难度较大
- 容易出现训练失败
下面摘自一篇博文http://xiaoqiang.me/?p=4592,希望自己在以后的工作中能够方便自己查阅
如果你对 GANs 算法感兴趣,可以在 「GANs动物园」里查看几乎所有的算法。我们为大家从众多算法中挑选了10个比较有代表性的算法,
|
算法 |
论文 |
代码 |
|
GAN |
||
|
DCGAN |
||
|
CGAN |
||
|
CycleGAN |
||
|
CoGAN |
||
|
ProGAN |
||
|
WGAN |
||
|
SAGAN |
||
|
BigGAN |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号