深度学习-CNN+RNN笔记
以下叙述只是简单的叙述,CNN+RNN(LSTM,GRU)的应用相关文章还很多,而且研究的方向不仅仅是下文提到的1. CNN 特征提取,用于RNN语句生成图片标注。2. RNN特征提取用于CNN内容分类视频分类。3. CNN特征提取用于对话问答图片问答。还有很多领域,比如根据面目表情判断情感,用于遥感地图的标注,用于生物医学的图像解析,用于安全领域的防火实时监控等。而且现阶段关于CNN+RNN的研究应用相关文章更加多样,效果越来越好,我们可以通过谷歌学术参阅这些文章,而且大部分可免费下载阅读,至于付费的那就另说咯。
CNN与RNN对比
CNN卷积神经网络与RNN递归神经网络直观图
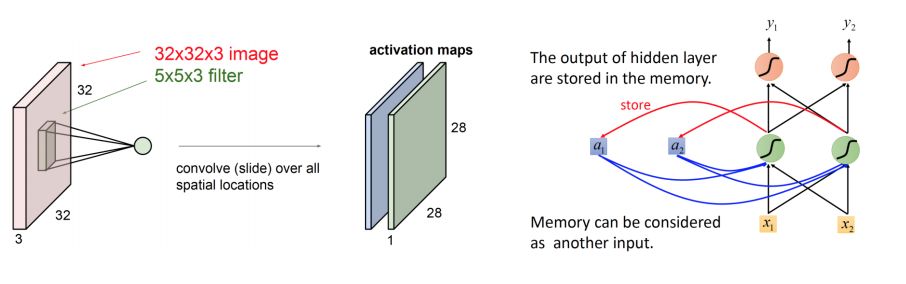
相同点:
传统神经网络的扩展。
前向计算产生结果,反向计算模型更新。
每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接。
不同点:
CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算
RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出
CNN高级100+深度,RNN深度有限
CNN+RNN组合方式
1. CNN 特征提取,用于RNN语句生成图片标注。

2. RNN特征提取用于CNN内容分类视频分类。

3. CNN特征提取用于对话问答图片问答。
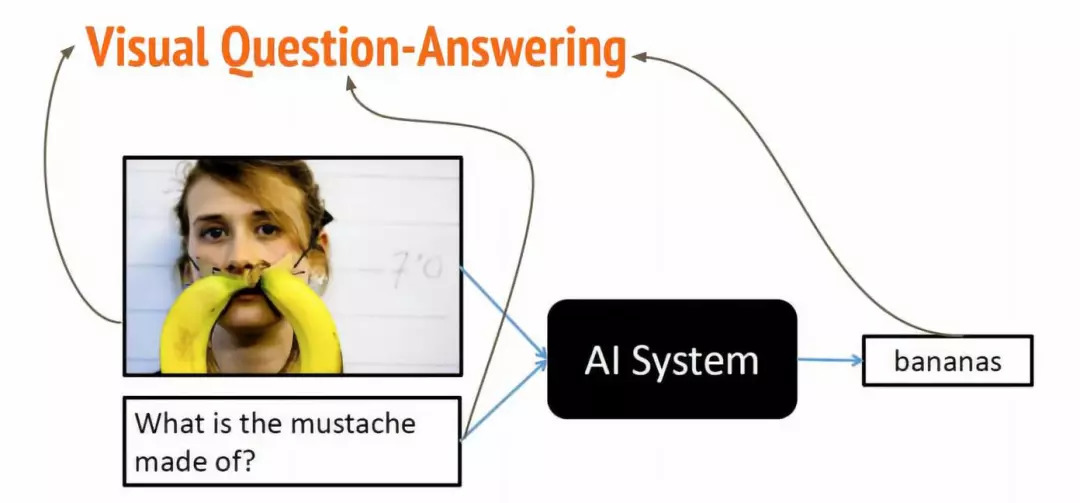
具体应用
1.图片标注
基本思路:
目标是产生标注的语句,是一个语句生成的任务,LSTM?描述的对象大量图像信息,图像信息表达,CNN?CNN网络中全连接层特征描述图片,特征与LSTM输入结合。
具体步骤:
模型设计-特征提取全连接层特征用来描述原图片LSTM输入:word+图片特征;输出下一word。

模型设计-数据准备
图片CNN特征提取2. 图片标注生成Word2Vect 向量3. 生成训练数据:图片特征+第n单词向量:第n+1单词向量。

模型训练:
运用迁移学习,CNN特征,语句特征应用已有模型2. 最终的输出模型是LSTM,训练过程的参数设定:梯度上限(gradient clipping), 学习率调整(adaptivelearning)3. 训练时间很长。
模型运行:
CNN特征提取2. CNN 特征+语句开头,单词逐个预测
2.视频行为识别
视频中在发生什么?

常用方法总结:
RNN用于CNN特征融合1. CNN 特征提取2. LSTM判断3. 多次识别结果分析。
不同的特征不同输出。
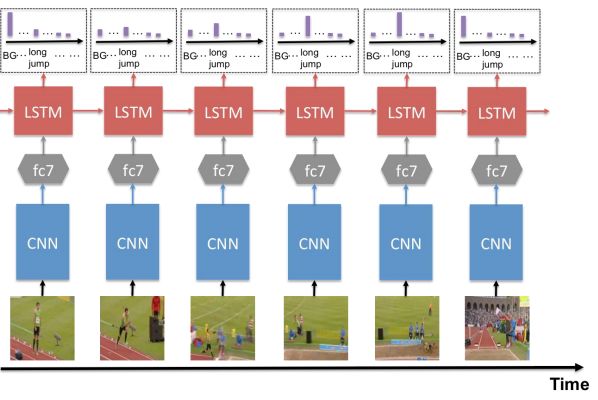
或者:所有特征作为一个输出。
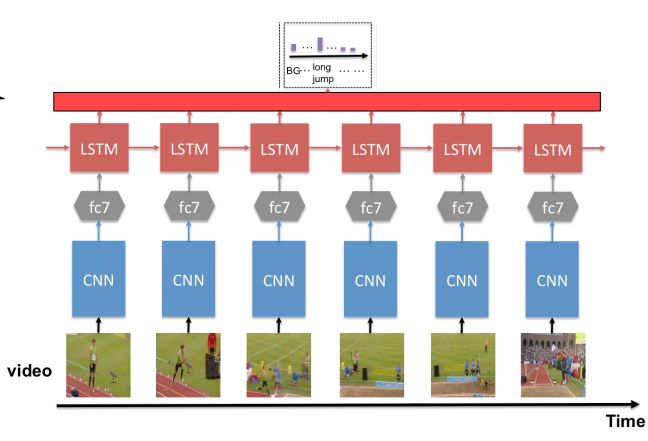
RNN用于CNN特征筛选+融合:
1.并不是所有的视频 图像包含确定分类信息
2. RNN用于确定哪些frame 是有用的3. 对有用的图像特征 融合。
RNN用于,目标检测:
1.CNN直接产生目标候选区
2. LSTM对产生候选区融合(相邻时刻位置近 似)
3. 确定最终的精确位置。
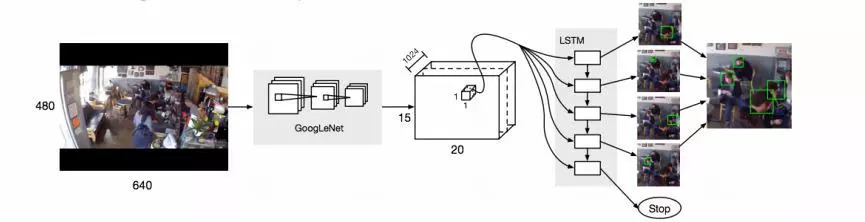
多种模型综合:
竞赛/应用中,为了产生最好结果,多采用 多模型ensemble形式。

3.图片/视频问答
问题种类:

图片问答意义:
1. 是对纯文本语言问答系统的扩展
2. 图片理解和语言处理的深度融合
3. 提高人工智能应用范围-观察,思考,表达
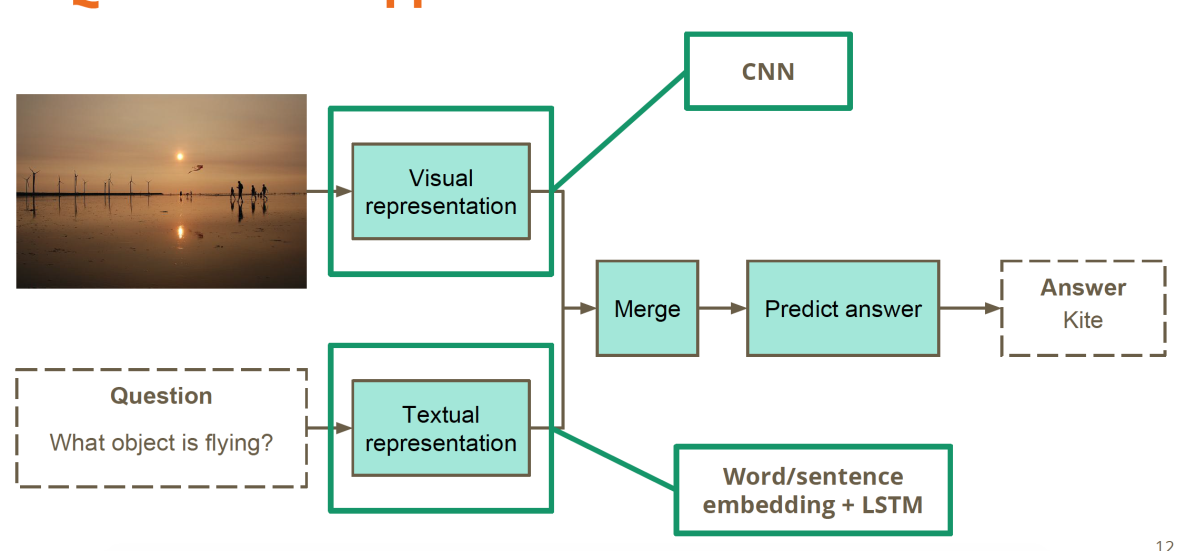
方法流程:
1.依旧按照语言问答流程解决
2.图片特征同语言特征融合
3.训练数据:问题+图片----答案
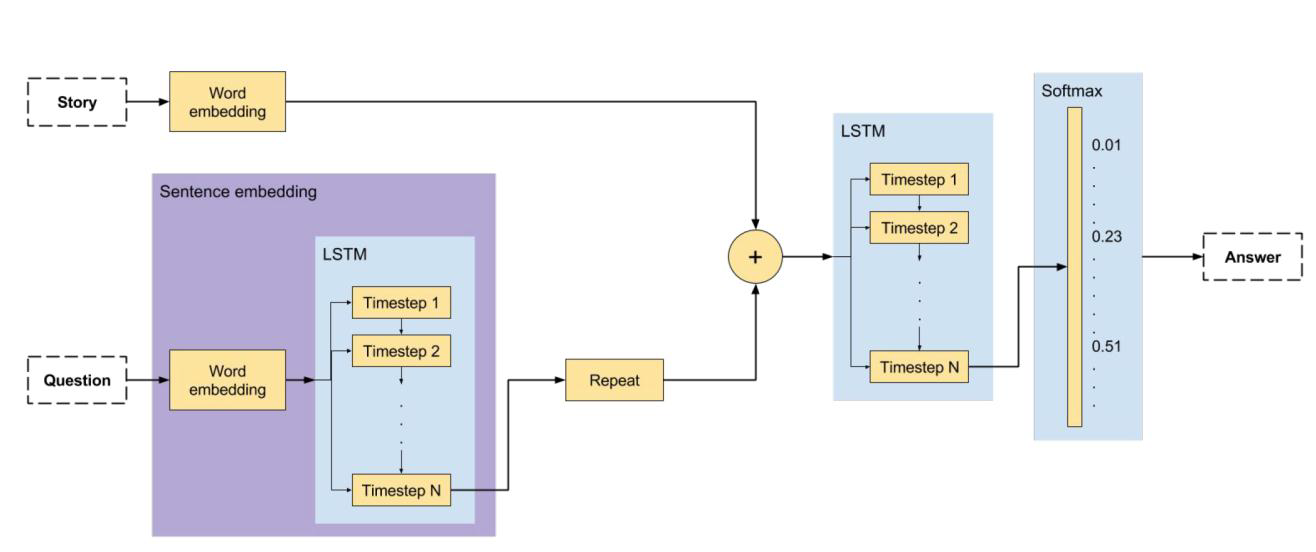
模型设计-纯文字问答系统:
1.背景故事特征生成(word embedding)
2.问题特征生成
3.背景,问题特征融合
4.标准答案回归
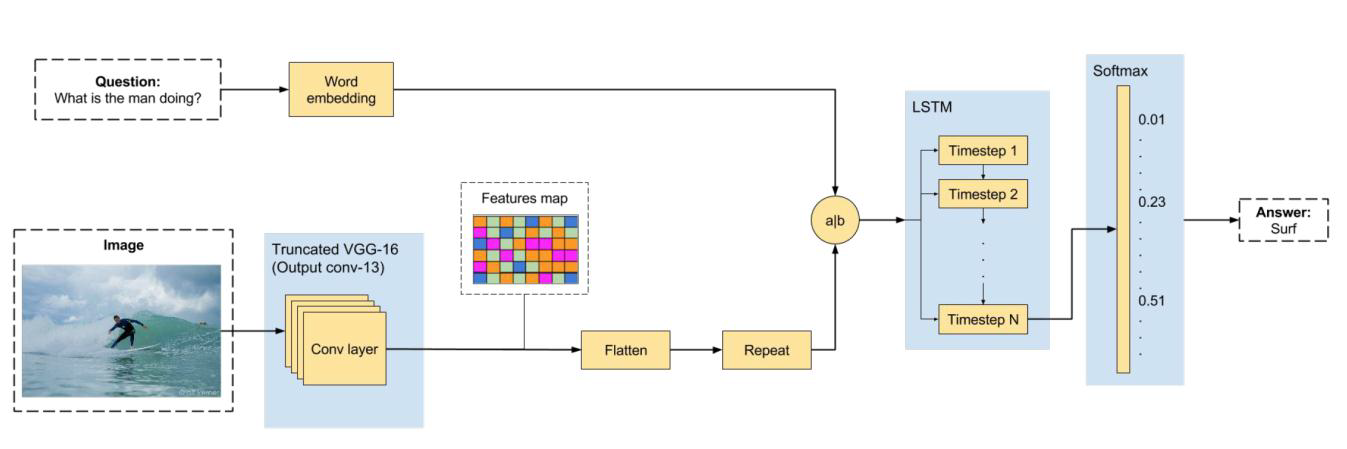
模型设计-图片问答系统:
1.背景故事特征生成CNN
2.问题特征生成
3.背景,问题特征融合
4.标准答案回归----用以训练的数据:真值是什么?
模型优化-1
对图片特征向量进一步处理,建立CNN特征的 fisher特征
提高特征表达效率,更容易同encoding 特征组合
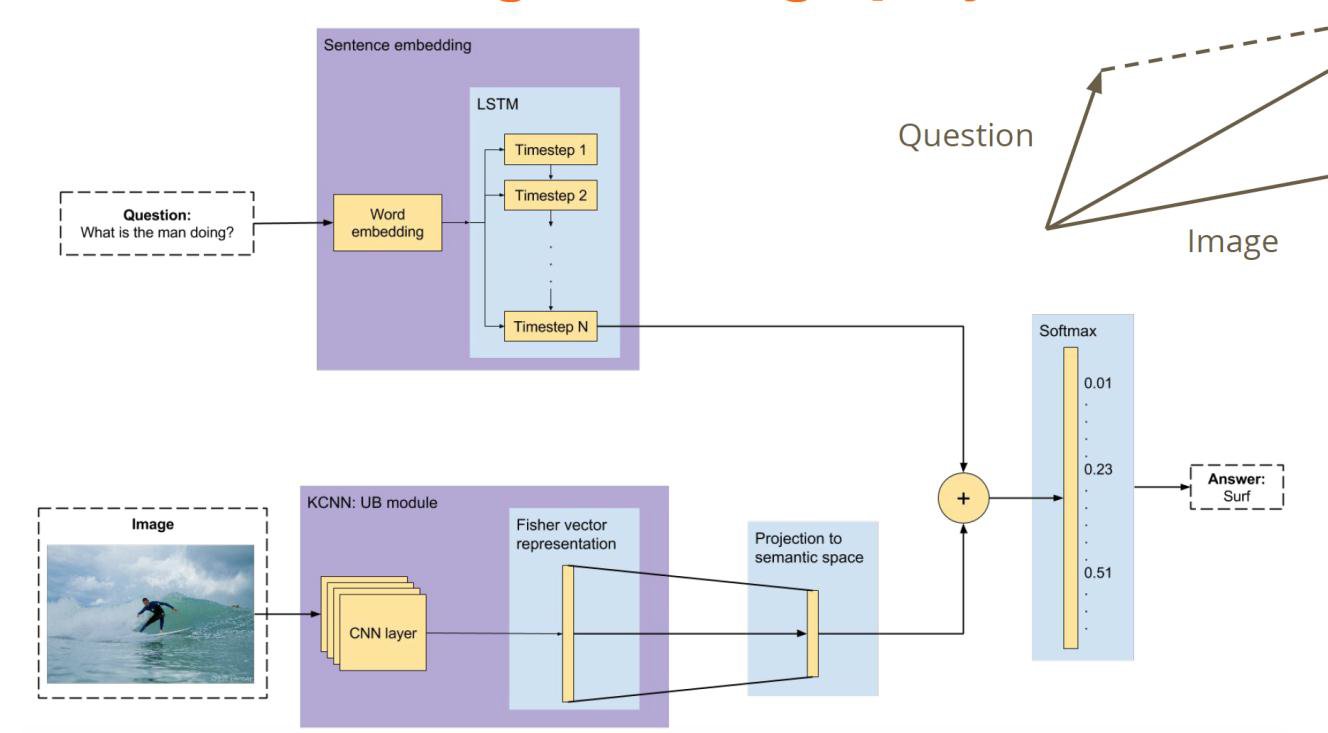
模型优化-2
用问题作为“候选区域”对原始CNN 特征图局部识别

模型优化-3
注意力图对图片问答帮助,根据问题产生第一次注意力图,然后最终注意力图,最后进行回答
什么在筐子里?
1筐子范围, 2 筐子里范围, 3 识别
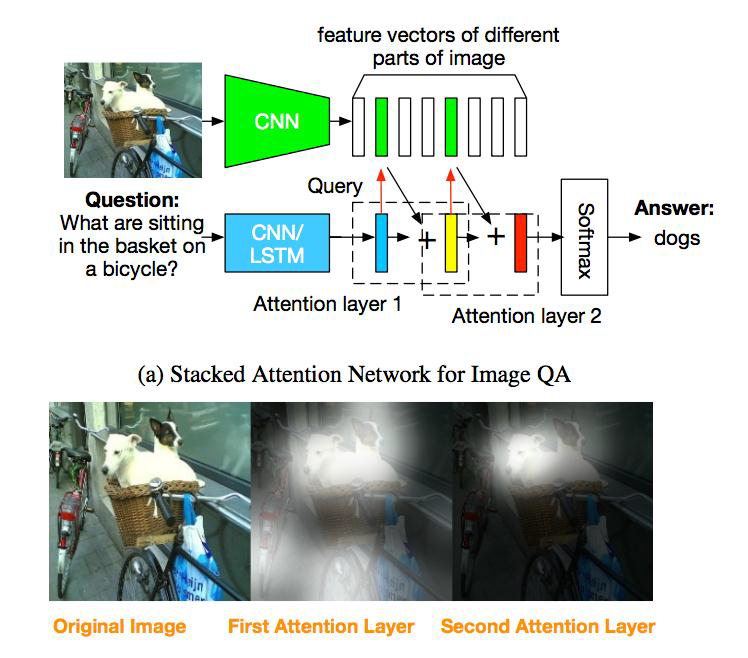
模型优化小结
1.不同的优化结构方便不同类型的问题回答,数字/种类/抽象/二值判断
2.仍然是很新的研究问题,上述例子来源于 CVPR2016,学术价值应用价值都很大
3.人机交互中图片问答在 盲人辅助/教育/智能助手等方面大有可为

 浙公网安备 33010602011771号
浙公网安备 33010602011771号