深度学习-LSTM与GRU
http://www.sohu.com/a/259957763_610300此篇文章绕开了数学公式,对LSTM与GRU采用图文并茂的方式进行说明,尤其是里面的动图,让人一目了然。https://zybuluo.com/hanbingtao/note/581764此篇文章对代码部分给予了充分说明。LSTM的详细推倒http://blog.csdn.net/u011414416/article/details/46724699,此便文章估计是展式中文推导过程最详细的吧。
在RNN训练期间,信息不断地循环往复,神经网络模型权重的更新非常大。因为在更新过程中累积了错误梯度,会导致网络不稳定。极端情况下,权重的值可能变得大到溢出并导致NaN值。爆炸通过拥有大于1的值的网络层反复累积梯度导致指数增长产生,如果值小于1就会出现消失。
由于RNN 有一定的局限性它会出现梯度消失的情况不能长时间保存记忆例如:
I am from China, I speak Chinese.这个句子中的China对Chinese具有一定的决定性,但是由于距离太远难以产生关联。
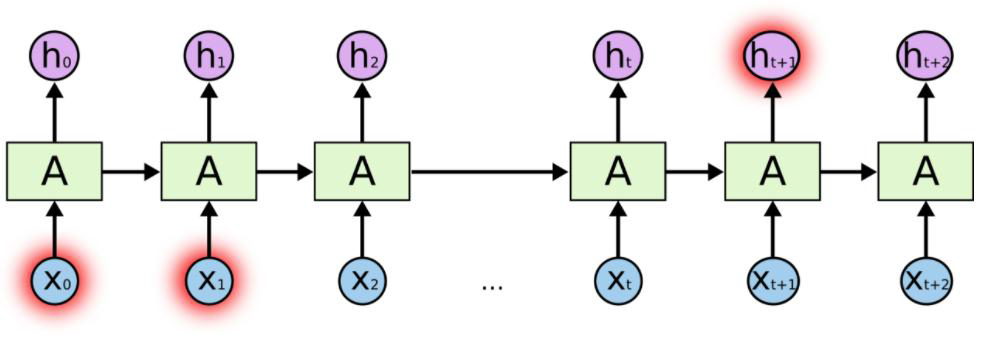
为解决这一问题,LSTM使用了Gate(“门”),它可以保存重要记忆
RNN LSTM

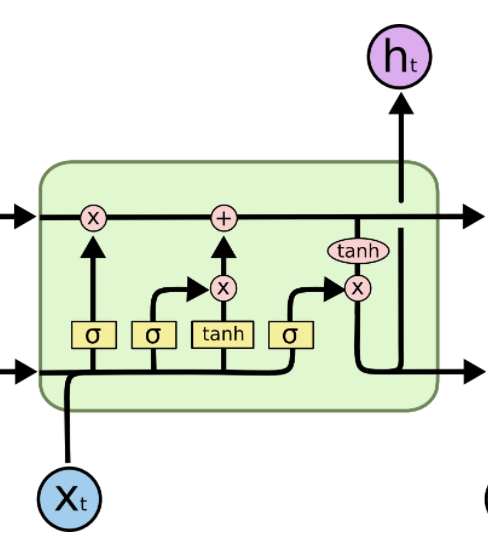
LSTM的核心内容就是Ct
信息流控制的关键,参数决定了ht传递过程中,哪些被保存或舍弃。参数被Gate影响Sigmoid函数系数决定 Ct参数的变化,而Sigmoid 函数决定于--输入, 之前状态
gate 如何进行控制?https://blog.csdn.net/m0epnwstyk4/article/details/79124800
方法:用门的输出向量按元素乘以我们需要控制的那个向量
原理:门的输出是 0到1 之间的实数向量,
当门输出为 0 时,任何向量与之相乘都会得到 0 向量,这就相当于什么都不能通过;
输出为 1 时,任何向量与之相乘都不会有任何改变,这就相当于什么都可以通过。
分步分析 LSTM 原理
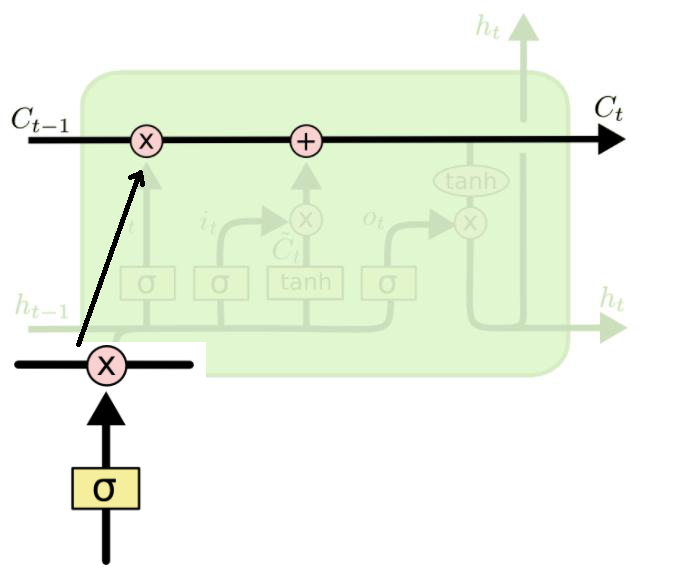
第一步:新输入xt前状态 ht-1 决定C哪些信息可以舍弃,ft与Ct-1运算,对部分信息进行去除,它就是遗忘门(forget gate),σ 是 sigmoid 函数。
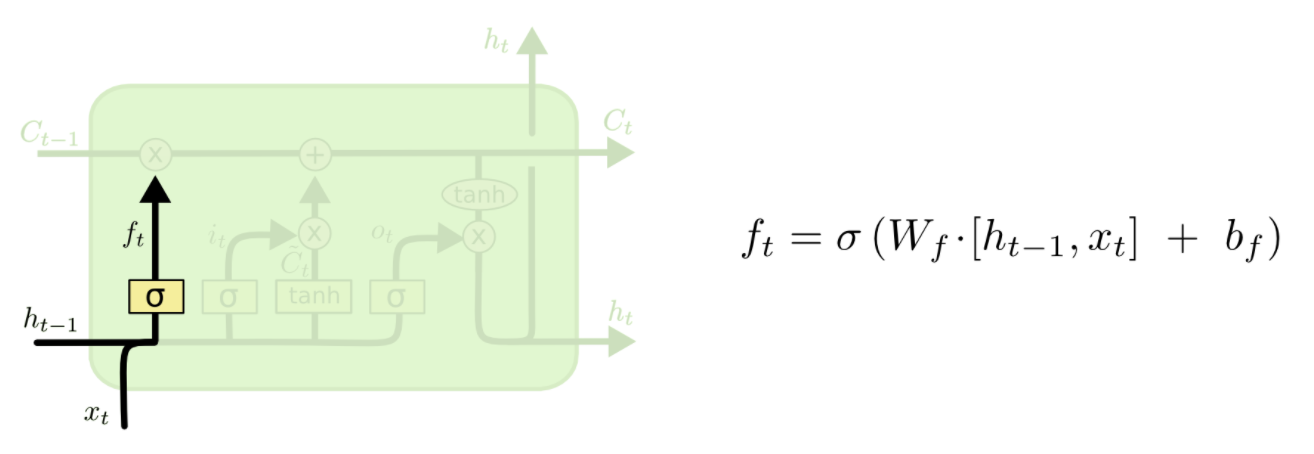
第二步:新输入xt前状态 ht-1 告诉 C 哪些新信息想要保存it:新信息添加时的系数(对比 ft)Ĉt单独新数据形成的控制参数,用于对Ct进行更新
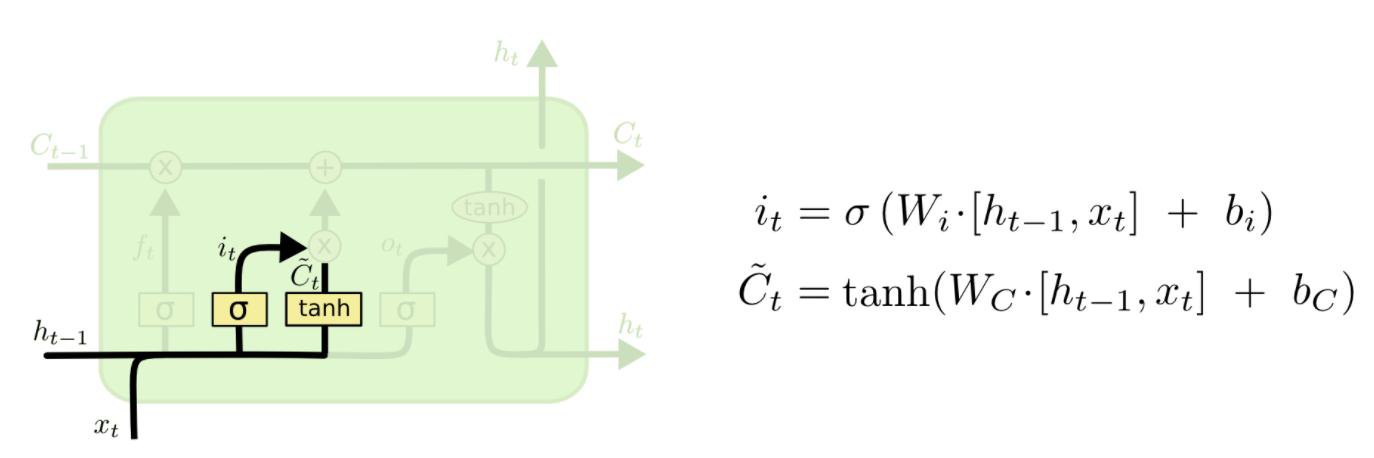
第三步:根据旧的控制参数Ct-1, 新生成的更新控制参数 Ĉt组合生成最终生成该时刻最终控制参数:
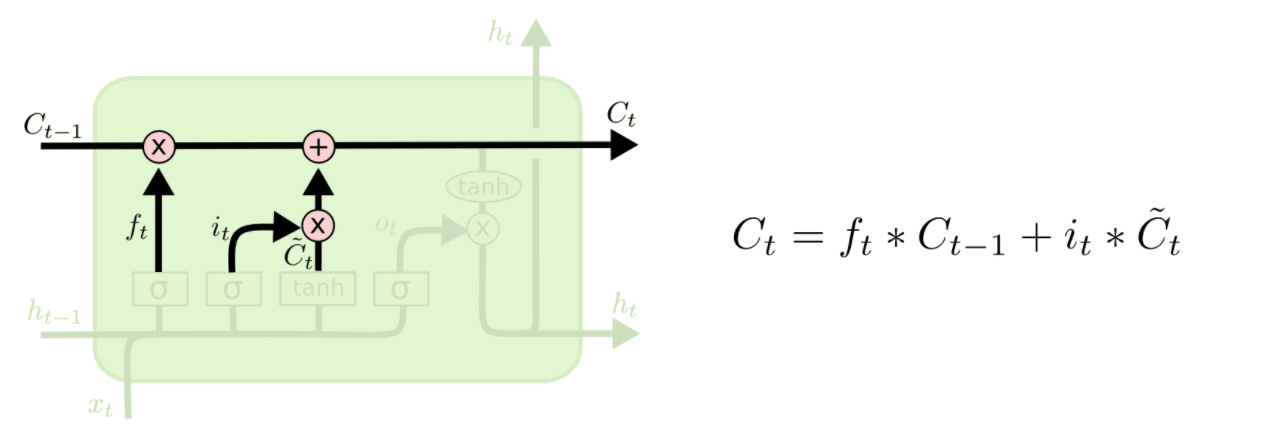
第二步与第三步合起来是输入门。
第四步:根据控制参数Ct 产生此刻的新的 LSTM 输出,它为输出门:
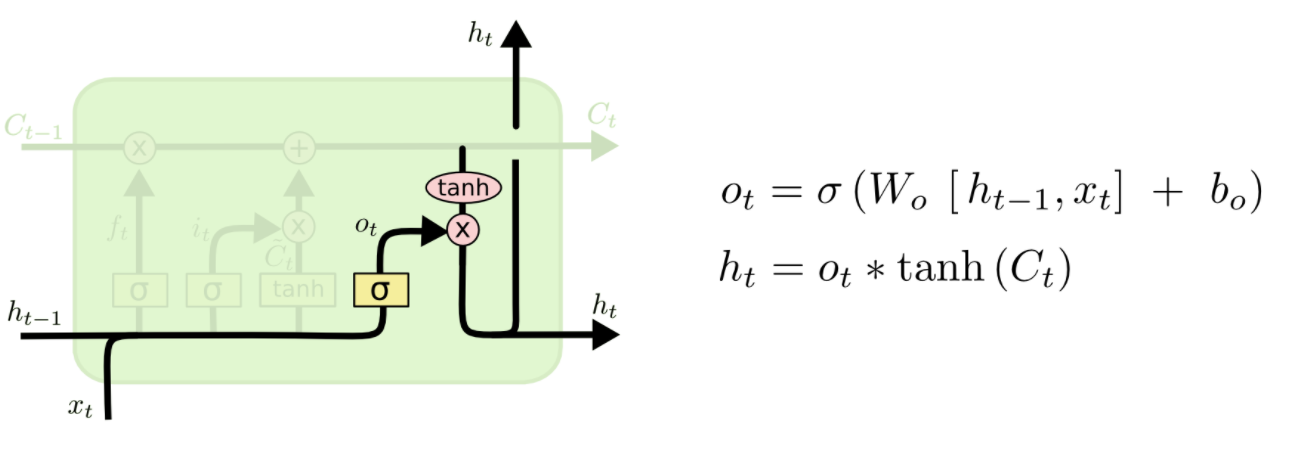
LSTM的工作方式可以总结为:1.Ct信息舍弃,2.Ct局部生成,3.Ct更新,4.Ct运算
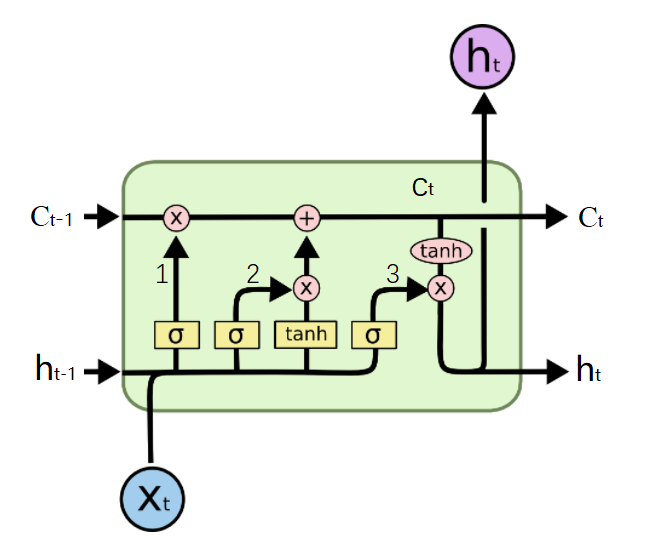
这里使用的符号具有以下含义:
a)X:缩放的信息--"门"
b)+:添加的信息
c)σ:Sigmoid层
d)tanh:tanh层
e)ht-1:上一个LSTM单元的输出
f)ct-1:上一个LSTM单元的记忆
g)Xt:输入
h)ct:最新的记忆
i)ht:输出
下面摘自http://www.atyun.com/16821.html这篇文章的一部分,说到tanh与Sigmoid两个函数的作用
为什么使用tanh?
为了克服梯度消失问题,我们需要一个二阶导数在趋近零点之前能维持很长距离的函数。tanh是具有这种属性的合适的函数。
为什么要使用Sigmoid?
由于Sigmoid函数可以输出0或1,它可以用来决定忘记或记住信息。
信息通过很多这样的LSTM单元。图中标记的LSTM单元有三个主要部分:
- LSTM有一个特殊的架构,它可以让它忘记不必要的信息。Sigmoid层取得输入Xt和ht-1,并决定从旧输出中删除哪些部分(通过输出0实现)。在我们的例子中,当输入是“他有一个女性朋友玛丽亚”时,“大卫”的性别可以被遗忘,因为主题已经变成了玛丽亚。这个门被称为遗忘门f(t)。这个门的输出是f(t)* ct-1。
- 下一步是决定并存储记忆单元新输入Xt的信息。Sigmoid层决定应该更新或忽略哪些新信息。tanh层根据新的输入创建所有可能的值的向量。将它们相乘以更新这个新的记忆单元。然后将这个新的记忆添加到旧记忆ct-1中,以给出ct。在我们的例子中,对于新的输入,他有一个女性朋友玛丽亚,玛丽亚的性别将被更新。当输入的信息是,“玛丽亚在纽约一家著名的餐馆当厨师,最近他们在学校的校友会上碰面。”时,像“著名”、“校友会”这样的词可以忽略,像“厨师”、“餐厅”和“纽约”这样的词将被更新。
- 最后,我们需要决定我们要输出的内容。Sigmoid层决定我们要输出的记忆单元的哪些部分。然后,我们把记忆单元通过tanh生成所有可能的值乘以Sigmoid门的输出,以便我们只输出我们决定的部分。在我们的例子中,我们想要预测空白的单词,我们的模型知道它是一个与它记忆中的“厨师”相关的名词,它可以很容易的回答为“烹饪”。我们的模型没有从直接依赖中学习这个答案,而是从长期依赖中学习它。
GRU可以说是LSTM的变种
介绍完LSTM的工作原理后,下面来看下门控循环单元GRU。GRU是RNN的另一类演化变种,与LSTM非常相似。GRU结构中去除了单元状态,而使用隐藏状态来传输信息。它只有两个门结构,分别是更新门和重置门。更新门的作用类似于LSTM中的遗忘门和输入门,它能决定要丢弃哪些信息和要添加哪些新信息。重置门用于决定丢弃先前信息的程度。
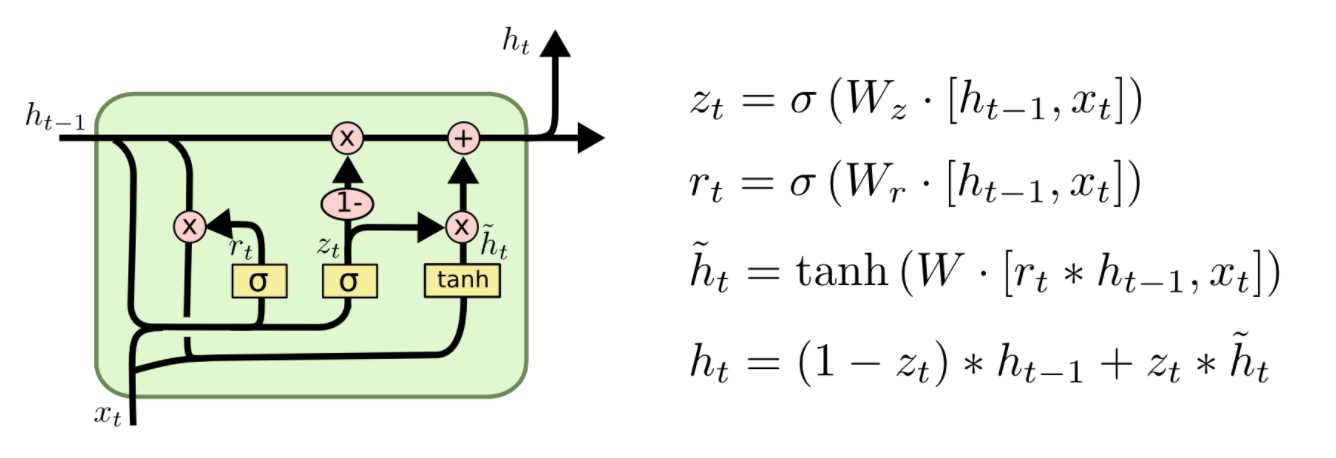
Reset gate
rt 负责决定ht−1对new memory ![]() 的重要性有多大, 如果rt约等于0 的话,ht-1就不会传递给new memory
的重要性有多大, 如果rt约等于0 的话,ht-1就不会传递给new memory![]()
new memory
![]() 是对新的输入xt和上一时刻的hidden state ht−1的总结。计算总结出的新的向量
是对新的输入xt和上一时刻的hidden state ht−1的总结。计算总结出的新的向量![]() 包含上文信息和新的输入xt.
包含上文信息和新的输入xt.
Update gate
zt负责决定传递多少ht−1给ht。 如果zt约等于1的话,ht−1几乎会直接复制给ht,相反,如果zt约等于0, new memory ![]() 直接传递给ht
直接传递给ht
Hidden state
ht 由 ht−1和![]() 相加得到,两者的权重由update gate zt控制。
相加得到,两者的权重由update gate zt控制。
可以看一下此篇https://blog.csdn.net/u012223913/article/details/77724621对LSTM与GRU做了一个具体的区别介绍。
2. 区别
1. 对memory 的控制
LSTM: 用output gate 控制,传输给下一个unit
GRU:直接传递给下一个unit,不做任何控制
2. input gate 和reset gate 作用位置不同
LSTM: 计算new memory Ĉt时不对上一时刻的信息做任何控制,而是用forget gate 独立的实现这一点
GRU: 计算new memory![]() 时利用reset gate 对上一时刻的信息 进行控制。
时利用reset gate 对上一时刻的信息 进行控制。
3. 相似
最大的相似之处就是, 在从t 到 t-1 的更新时都引入了加法。
这个加法的好处在于能防止梯度弥散,因此LSTM和GRU都比一般的RNN效果更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号