Tensorflow基本概念笔记
一、TensorFlow使用简单,部署快捷
TensorFlow使用数据流图(计算图)来规划计算流程,可以将计算映射到不同的硬件和操作平台。凭借着统一的架构,TensorFlow可以方便的部署到各种平台,大大简化了真实场景中应用机器学习算法的难度。
使用TensorFlow,我们不需要给大规模的模型训练和小规模的应用部署开发两套系统,节约时间,TensorFlow给训练和预测的共同部分提供了一个恰当的抽象。
对于大规模的神经网络训练,TensorFlow可以让用户轻松实现并行计算,同时使用不同的硬件资源进行训练,同步或异步的更新伞局共享的模型参数和状态。把一个串行的TensorFlow算法改造成并行的成本也很低。
虽然绝大多数的TensorFlow应用都在机器学习以及深度学习领域,但TensorFlow抽象出的计算图模型也可以应用在通用数值计算和符号计算上。
二、什么是计算图?(计算图又被称为有向图,数据流图)
什么是数据流图( Data Flow Graph)?
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“结点”一般用来表示施加的数学操作,但也可以表示是数据输入的起点/输出的终点,或者是读取/写入持久变量的终点。“线”表示“结点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,结点将被分配到各种计算设备完成异步并行地执行运算。
有一类特殊的边中没有数据流动,这种边被 称为依赖控制(control dependencies),作用是控 制节点的执行顺序,它可以让起始节点执行完毕再去执行目标节点,用户可以使用这样的边进行灵活控制,比如限制内存使用的最高峰值。
计算图可以使用C++,Python,Go,Java等语言设计。
计算图描述了张量数据的计算流程,负责维护和更新状态,对分支进行条件控制和循环操作。
使用图(graphs)来表示计算任务,用于搭建神经网络的计算过程,但其只搭建网络,不计算。
图(graphs)在被称之为会话(Session)的上下文(context)中执行图。
使用张量(tensor)表示数据,用“阶”表示张量的维度。关于这一点需要展开一下
0阶张量称为标量,表示单独的一个数
1阶张量称为向量, 表示一个一维数组
2阶张量称为矩阵,表示一个二维数组
张量是几阶的可以通过张量右边的方括号数来判断。例如 t = [ [ [ ] ] ],显然这个为3阶。
通过变量(Variable)维护状态
使用feed和fetch可以为任意的操作赋值或者从其中获取数据
Tensorflow是一个编程系统,使用图(graphs)来表示计算任务,图(graphs)中的节点称之为op(operation),一个op获得0个或者多个Tensor,执行计算,产生0个或多个Tensor,Tensor看作是一个n维的数组或列表。图必须在会话(Session)里被启动。
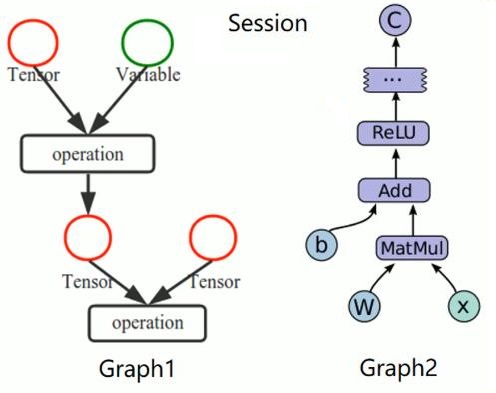
三、运算操作的相关知识点
一个运算操作代表了一种类型的抽象运算,比如矩阵乘法或向量加法。
一个运算操作可以有自己的属性,但是所有属性都必须被预先设置,或者能够在创建计算图时根据上下文推断出来。
通过设置运算操作的属性可以用来支持不同的tensor元素类型,比如让向量加法支持浮点数或者整数。
运算核(kernel)是一个运算操作在某个具体的硬件(比如在CPU或者GPU中)的实现。
在TensorFlow中,可以通过注册机制加入新的运算操作或者为已有的运算操作添加新的计算核。
四、TensorFlow内建的运算操作
标量运算 Add, Sub, Mul, Div, Exp, Log,&reater, Less, Equal
向量运算 Concat, Slice, Split, Constant, Rank, Shape, Shuffle
矩阵运算 MatMul, Matrixlnverse, MatrixDeterminant
带状态的运算 Variable, Assign, AssignAdd
神经网络组件 SoftMax, Sigmoid, ReLU, Convolution2D, MaxPooling
储存,恢复 Save, Restore
队列以及同步运算 Enqueue, Dequeue, MutexAcquire, MutexRelease
控制流 Merge, Switch, Enter, Leave, Nextlteration
五、TensorFlow实现原理
TensorFlow有一个重要组件client,也就是客户端,他通过Session的接入与master以及多个worker相连接。每个worker可以与多个硬件设备相连,比如CPU和GPU,并负责管理这些硬件。Master则负责指导所有的worker按照流程执行计算图。
TensorFlow有单机模式和分布式模式。单机模式下,client,master,worker全部在同一台计算机上的同一个进程中。分布式模式允许client,master,worker在不同机器的不同进程中,同时由集群调度系统,统一管理各项任务。

TensorFlow中每一个worker可以管理多个设备,每一个设备的name包含硬件类别、编号、任务号(单机版本没有),示例如下:
单机版本:/job:localhost/device:cpu:0 分布式版本:/job:worker/task:17/device:gpu:3
TensorFlow为CPU和GPU提供了管理设备的对象接口,每个对象负责分配、释放设备内存,以及执行节点的运算核。TensorFlow中的Tensor是多维数组,数据类型支持8位至64位的int,以及IEEE标准的float, double, complex, string。
每一个设备有单独的allocator负责存储各种数据类型的tensor,同时tensor的引用次数也会被记录。当引用计数为0时,内存被释放。
TensorFlow支持的设备包括X86架构CPU,手机上的ARM CPU,GPU,TPU (Tensor Processing Unit)。
AlphaGo就使用了大量的TPU集群计算资源。
在只有一个硬件设备的情况下,计算图会按照依赖关系被顺序执行。当一个节点的所有上游依赖全部执行完毕(依赖数==0),这个节点就会被加入就绪队列(readyqueen)以等待执行。同时这个节点的下游节点的依赖数自动减1。
当多个设备的时候,情况就变得复杂了。主要有两大难点:
(1)每一个节点该让什么设备执行?
(2)如何管理节点间的数据通信?
(1)每一个节点该让什么设备执行? TensorFlow设计了一套为节点分配设备的策略。
这个策略首先需要计算一个代价模型。代价模型首先估算每一个节点的输入,输出Tensor的大小,以及所需要的计算时间。代价模型一部分由人工经验指定的启发式规则得到,另一部分则是对一小部分数据进行实际运算测量得到。
接下来,分配策略会模拟执行整个计算图,从起点开始,按拓扑序执行。在执行一个节点时,会把每一个能执行这个节点的设备都测试一遍,测试内容包括计算时间的估算以及数据传递所需要的通信时间。最后选择一个综合时间最短的设备计算相应的节点。这是一个简单的贪婪策略。
除了运算时间,内存的最高使用峰值也会被考虑进来。
TensorFlow的节点分配策略仍在不断优化改进。未来,可能会用一个强化学习的神经网络来辅助节点分配。同时,用户可以自定义某些分配限制条件。
(2)如何管理节点间的数据通信?
当给节点分配设备的方案被确定,整个计算图就会被划分为许多子图,使用同一个设备并且相邻的节点会被划分到同一个子图。然后计算图中从x到y的边,会被取代为一个发送端的发送节点(send node),一个接收端的接受节点(receive node),以及从发送节点到接受节点的边。
把数据通信的问题转换为发送节点和接受节点的实现问题,用户不需要为不同的硬件环境实现通信方法。
两个子图之间可能会有多个接受节点,如果这些接受节点接受的都是同一个tensor,那么所有这些接受节点会被自动合并为一个,避免了数据的反复传递和设备内存占用。
发送结点和接收结点的设计简化了底层的通信模式,用户无需设计结点之间的通信流程,可以让同一套代码自动扩展到不同的硬件环境并处理复杂的通信流程。
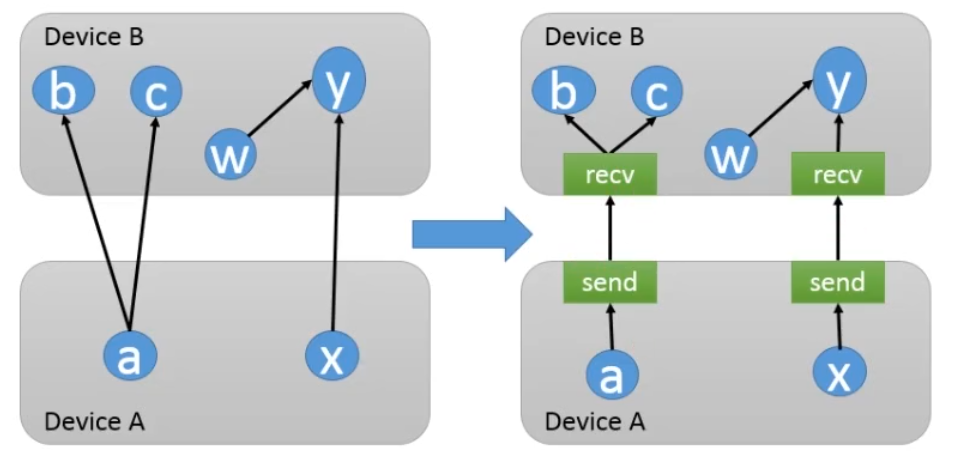
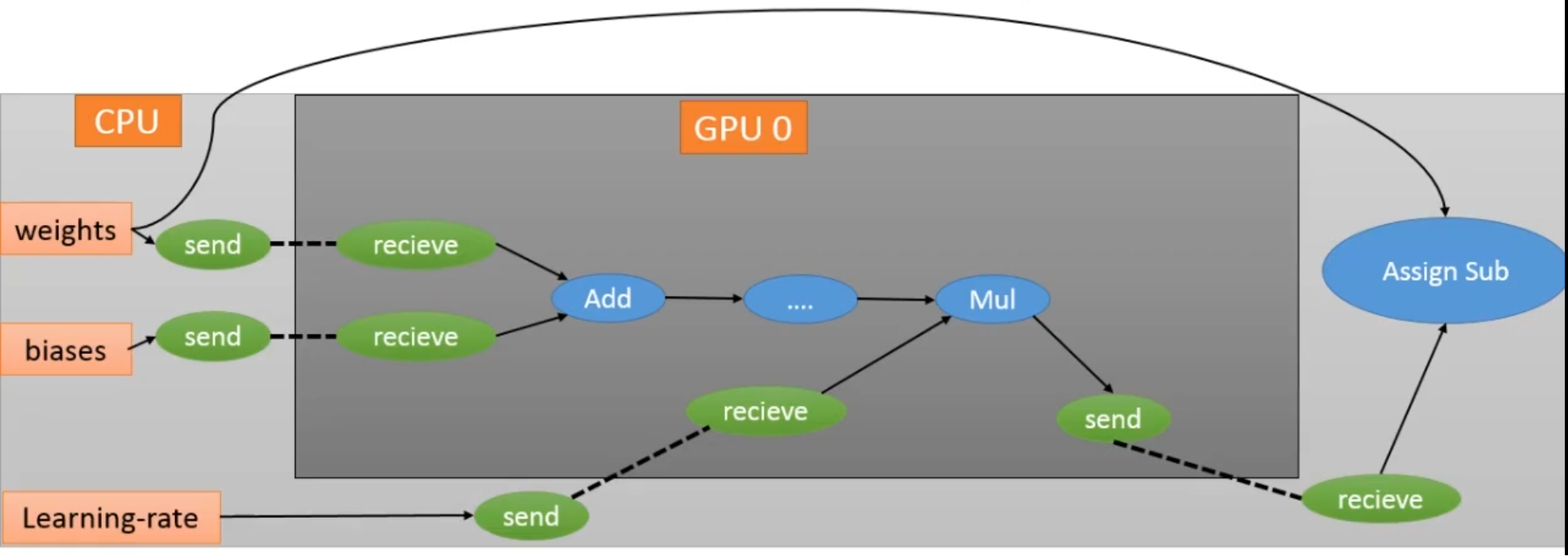
从单机单设备的版本改造为单机多设备的版本也比较容易。
1 for i in range(NUM_GPUS): 2 with tf.device('/gpu:%d' % i): 3 with tf.name_scope('gpu_%d' % i) as scope: 4 with tf.name_scope("tower_%d" % i): 5 #每个gpu里放不同的数据 6 _x = x[i * batch_size:(i + 1) * batch_size] 7 _y = y_[i * batch_size:(i + 1) * batch_size]
TensorFlow分布式执行时的通信和单机没备间的通信很像,只不过是对发送节点和接受节点的实现不同。
比如单机的CPU和GPU之间的通信变为不同机器之间的使用TCP或RDMA传输数据。
同时,容错性也是分布式TensorFlow的一个特点。通信故障会在两种情况下被检测出来:一种是信息从发送节点传输到接收节点失败时,另一种是周期性的worker心跳检测失败时。
当检测到通信故障时,整个计算图会被终止并重启。其中,Variable node可以通过检查点的保存和恢复机制持久化。每一个variable节点都会连接一个Save节点,每过几轮迭代就会保存一次数据到持久化存储系统。同样,每个variable节点也会连接一个Restore节点,在每次重启时调用以便恢复variable节点的数据。这样,发生故障以后,只要重启,接着上一个检查点继续运行就可以,无需从头再来!
代码部分
1 import tensorflow as tf 2 m1 = tf.constant([[3,3]]) #创建一个常量op 3 m2 = tf.constant([[2],[3]]) #创建一个常量op 4 product = tf.matmul(m1,m2) 5 print(product) #输出的结果是tensor 6 #Tensor("MatMul:0", shape=(1, 1), dtype=int32) 7 sess = tf.Session() #定义一个会话,启动默认图 8 result = sess.run(product) #调用sess的run方法来执行矩阵乘法op 9 print(result) #run(product)触发了图中3个op 10 sess.close()
1 import tensorflow as tf 2 m1 = tf.constant([[3,3]]) #创建一个常量op 3 m2 = tf.constant([[2],[3]]) #创建一个常量op 4 product = tf.matmul(m1,m2) 5 print(product) #输出的结果是tensor 6 #Tensor("MatMul:0", shape=(1, 1), dtype=int32) 7 with tf.Session() as sess: #不需要关闭会话sess.close() 8 result = sess.run(product) 9 print(result)
tensorflow中变量的使用
1 import tensorflow as tf 2 x = tf.Variable([1,2]) 3 a = tf.constant([3,3]) 4 sub = tf.subtract(x,a) #减法op 5 add = tf.add(x,sub) #加法op 6 7 #因为有变量所以要变量初始化,tf.global_variables_initializer表示全局初始化 8 init = tf.global_variables_initializer() 9 10 with tf.Session() as sess: 11 sess.run(init) #需要run一下初始化变量 12 print(sess.run(sub)) 13 print(sess.run(add)) 14 15 16 #创建一个变量初始化为0 17 state = tf.Variable(0,name='counter') 18 #创建一个op,作用是使state加1 19 new_value = tf.add(state,1) 20 #赋值op 21 update = tf.assign(state,new_value) 22 init = tf.global_variables_initializer() 23 24 with tf.Session() as sess: 25 sess.run(init) 26 print(sess.run(state)) 27 for _ in range(5): 28 sess.run(update) 29 print(sess.run(state))
Fetch and Feed
1 import tensorflow as tf 2 #Fetch同时执行多个op 3 input1 = tf.constant(3.0) 4 input2 = tf.constant(2.0) 5 input3 = tf.constant(5.0) 6 7 add = tf.add(input2,input3) 8 mul = tf.multiply(input1,add) 9 10 with tf.Session() as sess: 11 result = sess.run([mul,add]) 12 print(result) 13 14 #Feed 15 #创建占位符 16 input1 = tf.placeholder(tf.float32) 17 input2 = tf.placeholder(tf.float32) 18 output = tf.multiply(input1,input2) 19 20 with tf.Session() as sess: 21 #feed的数据以字典的形式传入 22 print(sess.run(output,feed_dict={input1:[8.],input2:[2.]}))
Tensorflow简单示例
1 import tensorflow as tf 2 import numpy as np 3 #使用numpy生成100个随机点 4 x_data = np.random.rand(100) 5 y_data = x_data*0.1+0.2 6 7 #构造一个线性模型 8 b = tf.Variable(1.1) 9 k = tf.Variable(0.5) 10 y = k*x_data + b 11 12 #二次代价函数 13 loss = tf.reduce_mean(tf.square(y_data-y)) 14 #定义一个梯度下降法来进行训练优化器 15 optimizer = tf.train.GradientDescentOptimizer(0.2) 16 #最小化代价函数 17 train = optimizer.minimize(loss) 18 19 init = tf.global_variables_initializer() 20 21 with tf.Session() as sess: 22 sess.run(init) 23 for step in range(201): 24 sess.run(train) 25 if step%20 == 0: 26 print(step,sess.run([k,b]))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号