机器学习-HMM隐马尔可夫模型-笔记
HMM定义
1)隐马尔科夫模型 (HMM, Hidden Markov Model) 可用标注问题,在语音识别、 NLP 、生物信息、模式识别等领域被实践证明是有效的算法。
2)HMM 是关于时序的概率模型,描述由一个隐藏的马尔科夫链生成不可观测的状态随机序列,再由各个状态生成观测随机序列的过程。
3)隐马尔科夫模型随机生成的状态随机序列,称为状态序列;每个状态生成一个观测,由此产生的观测随机序列,称为观测序列。序列的每个位置可看做是一个时刻。
隐马尔科夫模型的贝叶斯网络
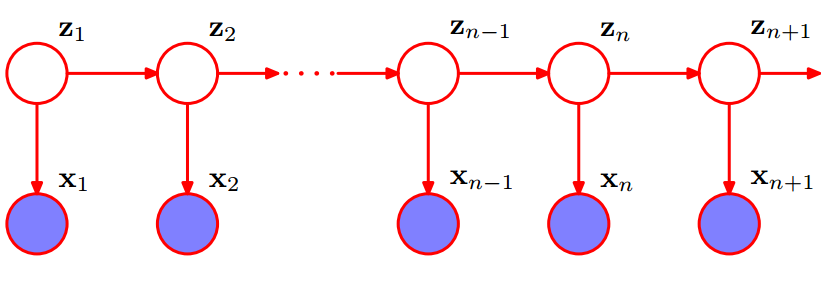
由于Z1,Z2,...,Zn,都是未知的,x1,x2,...,xn,存在一定的联系,即x1与x2不独立,x1与Z2不独立......
HMM的确定(一定要分清下面的类似条件的公式,有助于HMM的公式理解)
HMM 由初始概率分布 π向量 、状态转移概率分布 A矩阵以及观测概率分布B矩阵确定。 π 和 A 决定状态序列, B 决定观测序列。因此, HMM 可以用三元符号表示,称为HMM的三要素:
λ=(A,B,π)
Q是所有可能的状态的集合,N是可能的状态数
Q={q1,q2,...,qn}
V是所有可能的观测的集合,M是可能的观测数
V={v1,v2,...,vm}
I是长度为T的状态序列,O是对应的观测序列
I={i1,i2,...,iT} O={o1,o2,...,on}
A是状态转移概率矩阵
A=[aij]N×N
其中aij=P(it+1=qj | it=qi), aij是在时刻t处于状态qi的条件下时刻t+1转移到状态qj的概率。
B是观测概率矩阵B=[bik]N×M
其中,bik=P(ot=vk | it=qi) , bik是在时刻t处于状态qi的条件下生成观测vk的概率。
π是初始状态概率向量:π=(πi)
其中,πi=P(i1=qi), πi是时刻t=1处于状态qi的概率。
HMM的两个基本性质(很任性的具有特点的性质,为后面的公式推导做支撑)
1)齐次假设:当前状态只和上一个状态有关系,用公式表示的话就是:
![]()
2)观测独立性假设: 所有的观测之间是互相独立的,某个观测只和生成它的状态有关系,即:
![]()
此处性质若有疑问还请看看另一篇https://blog.csdn.net/xueyingxue001/article/details/52396494
HMM的3个基本问题
1) 概率计算问题:前向-后向算法—动态规划
给定模型 λ=(A,B,π)和观测序列O={o1,o2,...,oT} ,计算模型 λ下观测序列O出现的概率P(O| λ)
2) 学习问题:Baum Welch 算法状态未知EM
已知观测序列O={o1,o2,...,oT} ,估计模型 λ=(A,B,π)的参数,使得在该模型下观测序列 P(O| λ) 最大
3) 预测问题:Viterbi 算法—动态规划
解码问题:已知模型λ=(A,B,π) 和观测序列O={o1,o2,...,oT} 求给定观测序列条件概率 P(I|O,λ)最大的状态序列 I
概率计算问题
1. 直接算法: 暴力算法,在实际问题中不适用,它的时间复杂度为O(TNT),复杂度过高。
前向算法
后向算法
1-1. 直接算法,尽管不适用但是有助于对前向算法和后向算法的理解。
按照概率公式,列举所有可能的长度为 T 的状态序列I={i1,i2,...,iT},求各个状态序列 I与观测序列O={o1,o2,...,oT}的联合概率P(O,I | λ),然后对所有可能的状态序列求和从而得到 P(O|λ)。
状态序列I={i1,i2,...,iT}的概率是:
P(I|λ) = P(i1,i2, ..., iT |λ)
=P(i1 |λ)P(i2, i3, ..., iT |λ)
=P(i1 |λ)P(i2 | i1, λ)P(i3, i4, ..., iT |λ)
=......
=P(i1 |λ)P(i2 | i1, λ)P(i3 | i2, λ)...P(iT | iT-1, λ)
而上面的P(i1 |λ) 是初始为状态i1的概率,P(i2 | i1, λ) 是从状态i1转移到i2的概率,其他同理,于是分别使用初始概率分布π 和状态转移矩阵A,就得到结果:
![]()
对固定的状态序列I,观测序列O的概率是:
P(O|I,λ)=P(o1,o2,...,oT|i1,i2,...,iT,λ)=P(o1|i1,λ)P(o2|i2,λ)...P(oT|iT,λ)
![]()
O和I同时出现的联合概率是:
![]()
对所有可能的状态序列I求和,得到观测序列O的概率P(O|λ)
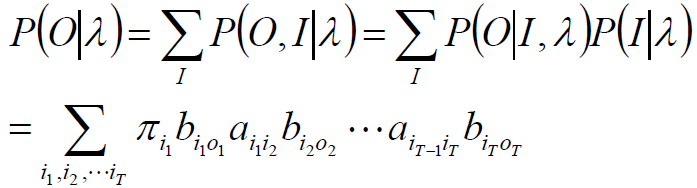
分析:加和符号中有2T个因子,I 的遍历个数为 NT,因此,时间复杂度为 O(TNT),复杂度过高。
1-2. 前向算法
αt(i)=P(y1,y2,...,yt,qt=i|λ) βt(i)=P(yt+1,yt+2,...,yT|qt=i,λ) (后向概率)
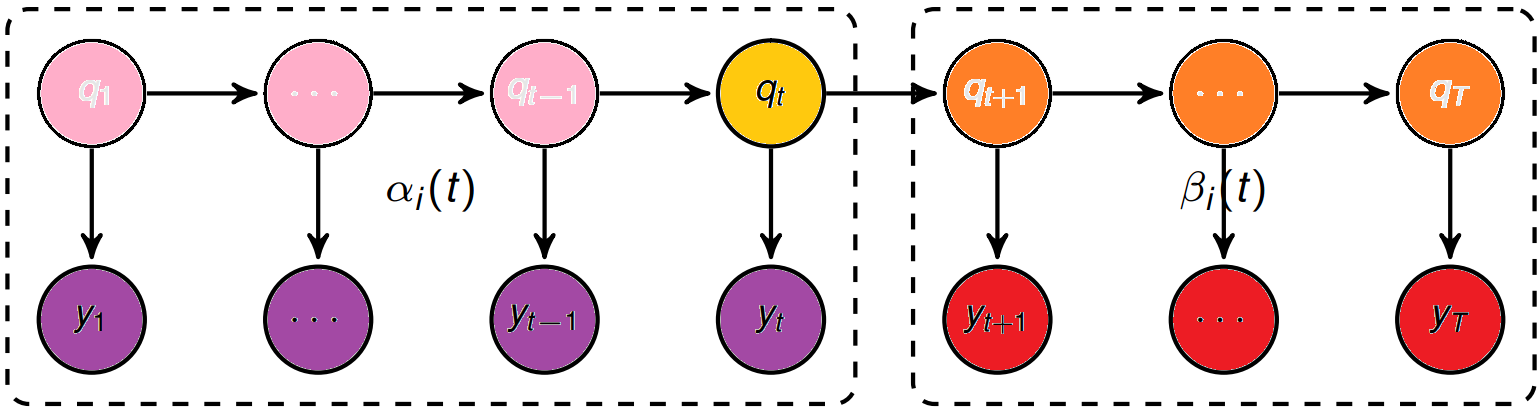
定义:给定 λ ,定义到时刻 t 部分观测序列为o1,o2…ot 且状态为 qi 的概率称为前向概率,记作:
αt(i)=P(o1,o2…ot,it=qi|λ),可以递推计算前向概率 αt(i) 及观测序列概率P(O|λ).
初值:
第一个时刻状态为第i号状态的概率是πi,在第i号状态时得到o1这个观测的概率是bio1,于是:
![]()
递推:对于t=1,2…T-1
时刻t+1的前向概率的 αt+1(i) 的求法就是:t时刻的状态转移到t+1时刻的状态的概率对所有状态求和 * t时刻的状态得到观测的概率,换句话说就是:t时刻的前向概率对所有的状态求和 * t时刻的状态得到观测的概率。(多读两遍)
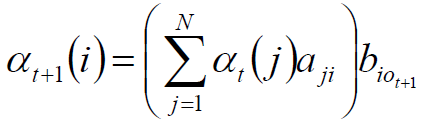
其中,αt(j)aji为时刻t状态为j的概率×状态j转移到状态i的转移概率就是时刻t+1时状态为i的概率。
最终观测序列概率:
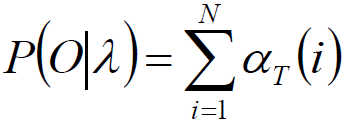
其实:P(O|λ)= αT(1) +αT(2) + ... + αT(n),既然αT(i) 可以表达出来,当然P(O|λ)就可以表达出来了。
举个例子具体是如何做的:
假设有 3 个盒子,编号为 1 、 2 、 3 ,每个盒子都装有红白两种颜色的小球,数目如下:
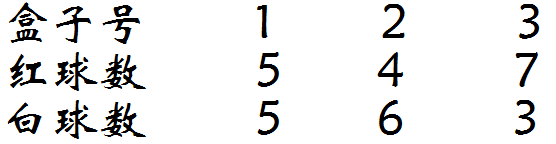
按照 π=(0.2,0.4,0.4) 的概率选择 1 个盒子,从盒子随机抽出1 个球,记录颜色后放回盒子;
考察盒子球模型,计算观测向量 O=“ 红白红”的出现概率。
初始概率分布π,状态转移概率分布A,观测概率分布B。

计算初值:第一时刻观测到红球概率的情况(初始状态)

递推(重点):第二时刻观测到白球概率的情况与第三时刻观测到红球概率情况
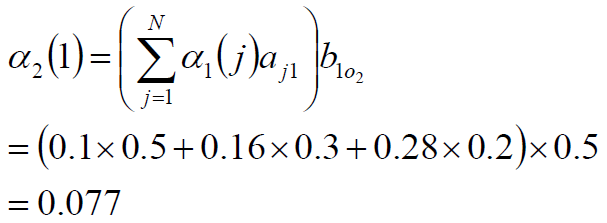
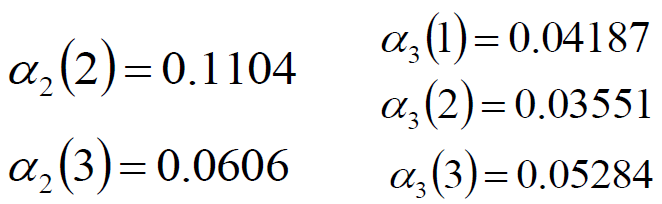
最终:观测序列为“红白红”的概率为
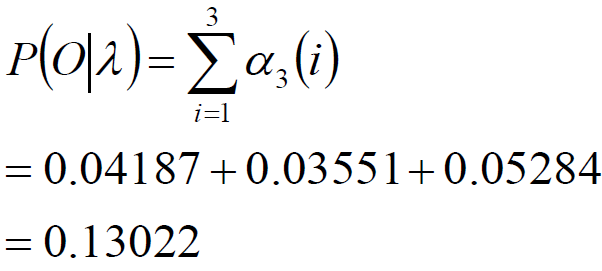
相信看完例子会舒服一点,不过我的例子写的也不算是详细,有兴趣可以看一下此博客https://blog.csdn.net/xueyingxue001/article/details/52396494
1-3. 后向算法
有了前向算法的基础,后向算法就好说了,因为就是前向算法的反过来:先计算最后一个然后推到第一个,于是详细说明就不在给了,直接上结论:
定义:给定 λ ,定义到时刻 t 状态为qi的前提下,从 t+1 到 T 的部分观测序列为 ot+1,ot+2,…,oT的概率为后向概率,记做:
![]()
可以递推计算后向概率 βt(i)及观测序列概率P(O|λ)
初值:βT(i) = 1
概率为1的原因是 -- 本来还需要看看时刻T后面有什么东西,但因为最后一个时刻T 后面已经没有时刻,即不需要再观测某个东西,所以随便给个什么都行。
递推: 对于t=T-1,T-2…,1
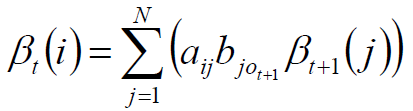
最终:

后向算法的说明:
为了计算在时刻 t 状态为 qi 条件下时刻 t+1 之后的观测序列为ot+1,ot+2 …oT 的后向概率βt(i),只需要考虑在时刻 t+1 所有可能的 N 个状态 qj的转移概率 (aij项 )),以及在此状态下的观测ot+1的观测概率
(![]() 项 ) ,然后考虑状态qj之后的观测序列的后向概率 βt+1(j)
项 ) ,然后考虑状态qj之后的观测序列的后向概率 βt+1(j)
根据前向概率后向概率定义
αt(i)=P(y1,y2,...,yt,qt=i|λ)
βt(i)=P(yt+1,yt+2,...,yT|qt=i,λ)
单个状态的概率
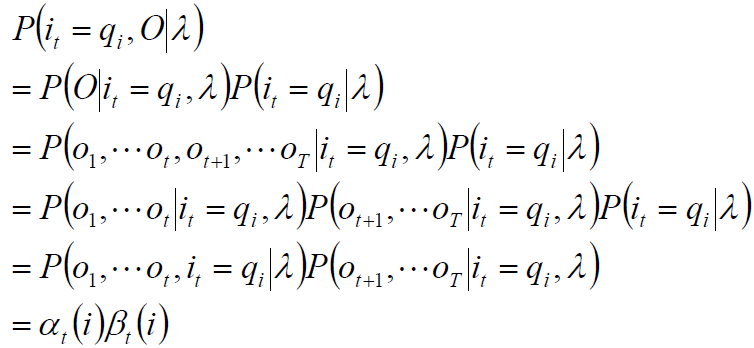
求给定模型λ和观测O,在时刻t处于状态qi的概率。记:
![]()
这个的确是求隐状态序列的一种方式,但这种有个问题 -- 求出的隐状态之间互相独立,即:没有考虑到第t+1时刻的隐状态是由第t时刻的隐状态转移过来的情况。换言之:这样求得的隐状态是“每个隐状态都是仅在当前时刻最优,每个隐状态都没考虑到全局情况”。
单个状态的概率:

γ的意义
在每个时刻 t 选择在该时刻最有可能出现的状态 it*,从而得到一个状态序列 I*={i1* i2*… iT*},将它作为预测的结果。
两个状态的联合概率
刚才“单个状态的概率”求得的t时刻的隐状态没有考虑到“上下文”,那就考虑下上下文,即:时刻t位于隐状态i时,t+1时刻位于隐状态j
求给定模型 λ 和观测 O ,在时刻 t 处于状态 qi 并且时刻 t+1 处于状态 qj 的概率。
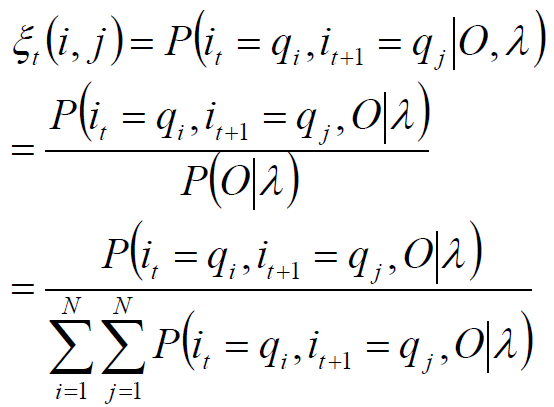
![]()
期望:
在观测O下状态i出现的期望:
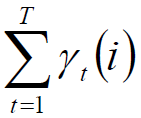
在观测O下状态i转移到状态j的期望:

2. 学习算法
1)若训练数据包括观测序列和状态序列,则HMM 的学习非常简单,是监督学习;
大数定理
假设已给定训练数据包含 S 个长度相同的观测序列和对应的状态序列
{(O1,I1), (O2,I2)…(Os ,Is)},那么,可以直接利用 Bernoulli 大数定理的结论“频率的极限是概率”,给出HMM 的参数估计。
监督学习方法

当然若是从实例出发,可以考虑一篇文档的分词,文档的词汇量可以用大数定律来解决,我们可以把每个句子看作是一个小单元,每个单元中,有初始字,终止字,中间字,单个字之分,剩下的就可以看一下https://blog.csdn.net/xueyingxue001/article/details/52396494关于这部分的举例,当然它只将词分为终止字与非终止字。
2) 若训练数据只有观测序列,则 HMM 的学习需要使用 EM 算法,是非监督学习。
Baum-Welch 算法
所有观测数据写成O=(o1,o2…oT),所有隐数据写成I=(i1,i2…iT),完全数据是(O,I)=(o1,o2…oT ,i1,i2…iT),完全数据的对数似然函数是lnP(O,I|λ)。
假设![]() 是HMM参数的当前估计值,λ为待求的参数。
是HMM参数的当前估计值,λ为待求的参数。
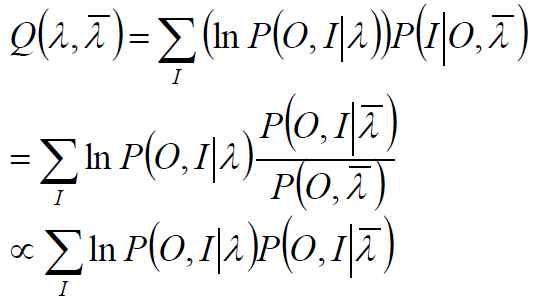
EM过程:

极大化:
极大化Q,求得参数A,B,π,由于该三个参数分别位于三个项中,可分别极大化。
Q的第一项:
![]()
注意到πi满足加和为1,利用拉格朗日乘子法,得到:
![]()
对上式相对于πi求偏导,得到:
![]()
对i求和,得到:
![]()
从而得到初始状态概率:

转移概率和观测概率
第二项可写成:
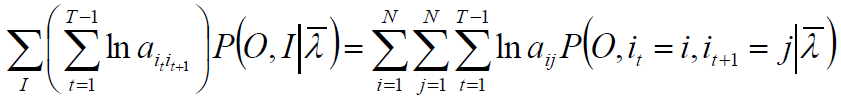
仍然使用拉格朗日乘子法,得到
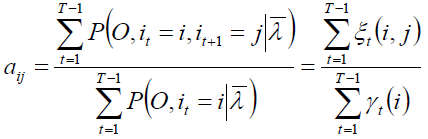
同理,得到:
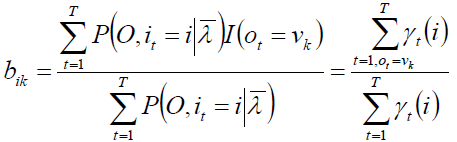
3. 预测算法
3-1预测的近似算法
在每个时刻 t 选择在该时刻最有可能出现的状态 it*,从而得到一个状态序列 I*={i1* ,i2*… iT*},将它作为预测的结果。
给定模型和观测序列,时刻 t 处于状态 qi 的概率为:

选择概率最大的 i 作为最有可能的状态:会出现此状态在实际中可能不会发生的情况。
3-2 Viterbi算法
Viterbi 算法实际是用动态规划解 HMM 预测问题,用 DP 求概率最大的路径(最优路径),这是一条路径对应一个状态序列。
定义变量 δt(i):在时刻 t 状态为 i 的所有路径中,概率的最大值。

举例
考察盒子球模型,观测向量 O=“ 红白红”,试求最优状态序列。

初始化:(下面的红色数字逻辑应该从最后一个推到第一个)
在 t=1 时,对于每一个状态 i ,求状态为 i 观测到 o1= 红的概率,记此概率为 δ1(t)
![]()
求得 δ1(1)=0.2×0.5=0.1
δ1(2)=0.4×0.4=0.16
δ1(3)=0.4×0.7=0.28
在t=2时,对每个状态i,求在t=1时状态为j观测为红并且在t=2时状态为i观测为白的路径的最大概率,记概率为δ2(t),则:
![]()
求得
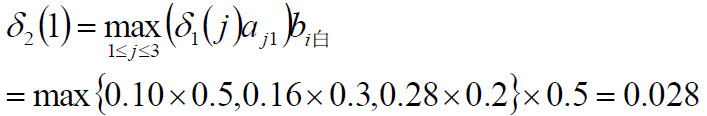
同理:
δ2(2)=max{0.1×0.2, 0.16×0.5, 0.28×0.3}×0.6=0.0504
δ2(3)=max{0.1×0.3, 0.16×0.2, 0.28×0.5}×0.3=0.042
同理,求得:
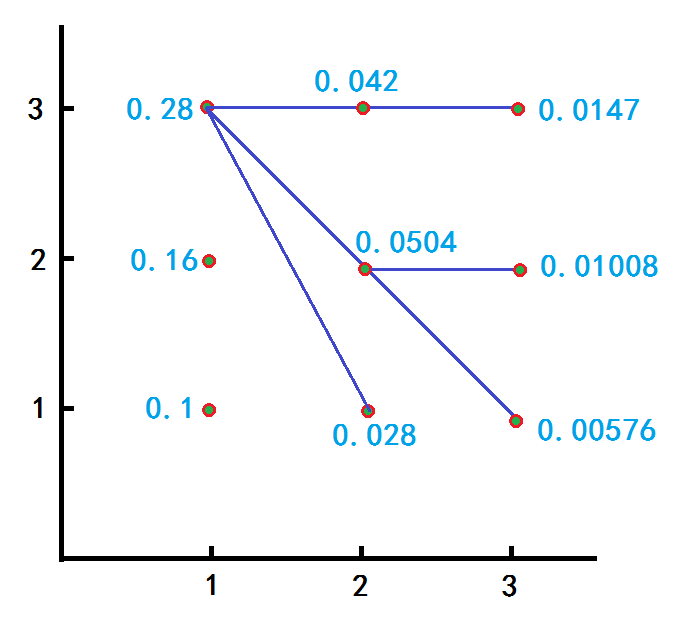
δ3(1)=max{0.028×0.5, 0.0504×0.3, 0.042×0.2}×0.5=0.00756
δ3(2)=max{0.028×0.2, 0.0504×0.5, 0.042×0.3}×0.4=0.01008
δ3(3)=max{0.028×0.3, 0.0504×0.2, 0.042×0.5}×0.7=0.0147
从而,最大是 δ3(3)= 0.0147 ,根据每一步的最大(红色数字倒推回去),得到序列是(3,3,3)。
求最优路径图解:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号