机器学习之逻辑回归(Logistic)笔记
在说逻辑回归之前,可以先说一说逻辑回归与线性回归的区别:
逻辑回归与线性回归在学习规则形式上是完全一致的,它们的区别在于hθ(x(i))为什么样的函数
当hθ(x(i))=θTx(i)时,表示的是线性回归,它的任务是做回归用的。
当![]() 时,表示的是逻辑回归,假定模型服从二项分布,使用最大似然函数推导的,它的任务是做分类用的,逻辑回归是一个广义的线性模型,是对数线性模型。
时,表示的是逻辑回归,假定模型服从二项分布,使用最大似然函数推导的,它的任务是做分类用的,逻辑回归是一个广义的线性模型,是对数线性模型。
下面就是逻辑回归的推导过程了
首先我们来看看核函数即sigmoid函数![]() 的对Z的导数
的对Z的导数
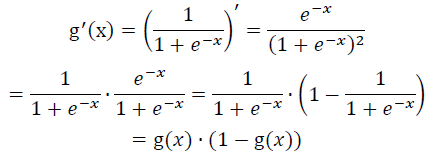
这个结果在后续的推导过程会用到,这里的Z我们可以看成θTx。
Logistic回归参数估计:
假定:P(y=1 | x; θ)=hθ(x)
P(y=0 | x; θ)=1-hθ(x)
P(y | x; θ)=(hθ(x))y(1-hθ(x))1-y,
这个是二分类任务,类别为1时发生概率为hθ(x),类别为0时发生概率为1-hθ(x),两类发生的概率独立同分布,所以可以使用似然函数将所有的样本发生的可能相乘,
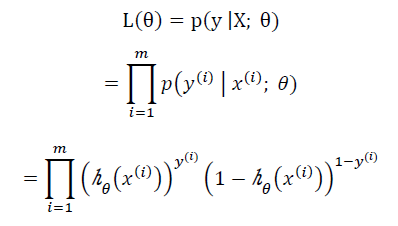
接下来就是确定θ,按部就班先对似然函数取对数,再对θ求导

![]()
逻辑回归是机器学习中的一个非常常见的模型, 逻辑回归模型其实仅在线性回归的基础上,套用了一个逻辑函数。为了训练逻辑回归模型的参数θT需要一个代价函数,算法的代价函数是对m个样本的损失函数求和,损失函数越小,机器学习的参数相对来说就越小(当然过拟合除外)。
一般逻辑回归损失函数有两种表达:
1)

2)

一个事件的几率odds,是指该事件发生的概率与该事件不发生的概率的比值,
对这个比值取对数就是对数几率:logit函数
P(y=1 | x; θ) = hθ(x)
P(y=0 | x; θ) = 1-hθ(x)
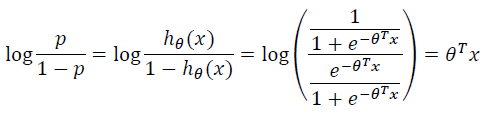
这与线性回归有一定的共性,恰恰说明逻辑回归是一个广义的线性模型,是对数线性模型。
Logistic回归总结,原话转自https://www.cnblogs.com/Luv-GEM/p/10674719.html
Logistic回归模型,相比SVM、GBDT等模型,要简单得多,但是由于这个模型可解释性强,被广泛运用于各种业务场景中。
此外,它也是如今大行其道的深度学习算法的基础之一。
逻辑回归的优点有以下几点:
1、模型的可解释性比较好,从特征的权重可以看到每个特征对结果的影响程度。
2、输出结果是样本属于类别的概率,方便根据需要调整阈值。
3、训练速度快,资源占用少。
而缺点是:
1、准确率并不是很高。因为形式非常简单(非常类似线性模型),很难去拟合数据的真实分布。
2、处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据。
3、很难处理数据不平衡的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号