Java-HashMap中源码解读、put放置、resize扩容等
1.背景
| Map类型 | 优点 | 缺点 | 线程安全性 |
|---|---|---|---|
| HashMap | 1. 查询、插入、删除操作的时间复杂度为O(1)。 2. 允许键和值为null。 |
1. 无序,不保证迭代顺序。 2. 不是线程安全的。 |
× |
| LinkedHashMap | 1. 保留插入顺序或访问顺序。 2. 与HashMap性能相似。 |
1. 内存开销较高,因为维护了一个双向链表。 2. 不是线程安全的。 |
× |
| TreeMap | 1. 保持键的自然顺序或指定的排序顺序。 2. 支持范围查询。 |
1. 查询、插入、删除操作的时间复杂度为O(log n)。 2. 内存开销较高。 |
× |
| Hashtable | 1. 线程安全,方法是同步的。 2. 不允许键和值为null。 |
1. 性能较低,因为所有方法都是同步的。 2. 无序。 |
√ |
| ConcurrentHashMap | 1. 线程安全,使用分段锁提高并发性。 2. 允许并发读取。 |
1. 内存开销较高,因为使用了分段锁。 2. 复杂度较高。 |
√ |
| WeakHashMap | 1. 使用弱引用键,当键不再被使用时,自动垃圾回收。 | 1. 性能较低,尤其在垃圾回收时。 2. 无序。 |
× |
| IdentityHashMap | 1. 使用==而不是equals来比较键。 2. 内存开销较小。 |
1. 使用场景有限。 2. 无序。 |
× |
2.HashMap
2.1 属性值
| 字段名称 | 默认值 | 描述 |
|---|---|---|
| DEFAULT_INITIAL_CAPACITY | 16 | 默认初始容量,必须是2的幂。 |
| MAXIMUM_CAPACITY | 1 << 30 | 最大容量,如果通过构造函数指定了更高的值,将使用此值,必须是2的幂且不大于2^30。 |
| DEFAULT_LOAD_FACTOR | 0.75f | 当构造函数中未指定时使用的负载因子。 |
| TREEIFY_THRESHOLD | 8 | 使用树而不是列表作为bin的阈值,当bin中的节点数量达到此数量时转换为树。 |
| UNTREEIFY_THRESHOLD | 6 | 在调整大小操作期间解树化(从树转换为列表)的阈值,应该小于TREEIFY_THRESHOLD。 |
| MIN_TREEIFY_CAPACITY | 64 | 可以进行树化的最小表容量,如果一个bin中的节点数量太多而表容量较小时,表会被调整大小。 |
2.2 hash值
2.2.1 哈希值计算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这段代码计算出键的哈希值,它通过对键的hashCode值和它右移16位之后的值进行按位异或运算来生成最终的哈希值。
2.2.2 数组位置计算
在哈希表中,数组位置通过以下公式计算:
int index = (n - 1) & hash;
其中n是哈希表的容量(数组长度)。
为啥取模是(n-1)&hash看我这篇文章:Java-取模操作中的&和(length-1)
2.2.3 逆推冲突键
比如我的key是yang,hash结果是3701497,最后(n - 1) & hash放到9号位置。
int index = (n - 1) & hash;
对于容量为16的哈希表,n - 1等于15(即二进制的0000 1111)。
所以,我们需要找到一个hash2,使得:
15 & hash2 == 9
给出一个demo代码。
package cn.yang37.map;
/**
* @description:
* @class: HashMapDebug
* @author: yang37z@qq.com
* @date: 2024/6/20 22:56
* @version: 1.0
*/
public class HashMapDebug {
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public static void main(String[] args) {
int n = 16;
// 目标位置
int targetIndex = 9;
// 要找到的键的数量
int numberOfKeysToFind = 10;
// 验证已知key "yang"
String knownKey = "yang";
int knownHash = hash(knownKey);
System.out.println(String.format("[0] Hash-'%s': %d", knownKey, knownHash));
System.out.println(String.format("[0] Index-'%s': %d", knownKey, (n - 1) & knownHash));
System.out.println();
// 找到n个可能的key
int count = 0;
for (int i = 0; count < numberOfKeysToFind; i++) {
String newKey = "test" + i;
int newHash = hash(newKey);
int nowIndex = (n - 1) & newHash;
if (nowIndex == targetIndex) {
count++;
System.out.println(String.format("[%d] Found key: %s", count, newKey));
System.out.println(String.format("[%d] Hash-'%s': %d", count, newKey, newHash));
System.out.println(String.format("[%d] Index-'%s': %d", count, newKey, nowIndex));
System.out.println();
}
}
}
}
输出结果:
[0] Hash-'yang': 3701497
[0] Index-'yang': 9
[1] Found key: test40
[1] Hash-'test40': -877157063
[1] Index-'test40': 9
[2] Found key: test51
[2] Hash-'test51': -877157095
[2] Index-'test51': 9
[3] Found key: test62
[3] Hash-'test62': -877156999
[3] Index-'test62': 9
[4] Found key: test73
[4] Hash-'test73': -877157031
[4] Index-'test73': 9
[5] Found key: test84
[5] Hash-'test84': -877157191
[5] Index-'test84': 9
[6] Found key: test95
[6] Hash-'test95': -877157223
[6] Index-'test95': 9
[7] Found key: test100
[7] Hash-'test100': -1422462167
[7] Index-'test100': 9
[8] Found key: test111
[8] Hash-'test111': -1422462199
[8] Index-'test111': 9
[9] Found key: test122
[9] Hash-'test122': -1422462103
[9] Index-'test122': 9
[10] Found key: test133
[10] Hash-'test133': -1422462135
[10] Index-'test133': 9
2.3 内部类
2.4 put方法
首先,put方法调用的是重载的put方法。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
现在,我们来分析下具体的put方法。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
| 参数名称 | 类型 | 描述 |
|---|---|---|
| hash | int | 键的哈希值。通常由键的hashCode方法生成,然后再经过某种扰动函数处理,以减少哈希冲突。 |
| key | K | 要插入的键。 |
| value | V | 要插入的值。 |
| onlyIfAbsent | boolean | 如果为true,则只有在当前映射中没有该键的映射时才插入该值。如果为false,则总是插入(覆盖现有的值)。 |
| evict | boolean | 该参数用于标识在创建模式下是否可以删除(逐出)条目。该参数在某些内部操作(如调整大小或转换为树节点时)可能会有不同的处理方式。通常,用户不需要关心此参数。 |
这里我们需要关注的是,onlyIfAbsent默认是false,为true的时候,则是存在才会插入。

像我们的putIfAbsent就是传递的true。
hashMap.putIfAbsent( k, v)

下面,我们逐步分析put方法,以下方代码为例。
public class Hash {
public static void main(String[] args) {
HashMap<String, Object> hashMap = new HashMap<>();
hashMap.put("yang", "123");
System.out.println(hashMap.size());
}
}
首先,刚进来,我们就会有疑问,tab、p、n、i都是啥?
Node<K,V>[] tab; Node<K,V> p; int n, i;
tab:类型为Node<K,V>[],表示哈希表(数组),存储的是HashMap的桶数组。
p:类型为Node<K,V>,表示一个节点。这个就是具体的元素呗,咱们的key、value组成一个Node节点。
n:类型为int,表示哈希表的长度,tab.length就是咱们桶的长度。
i:类型为int,表示计算得到的键值对应该插入的哈希表索引位置。
那我们先来看第一个if。
2.3.1 初始化
我们先来看最开始的这个if。
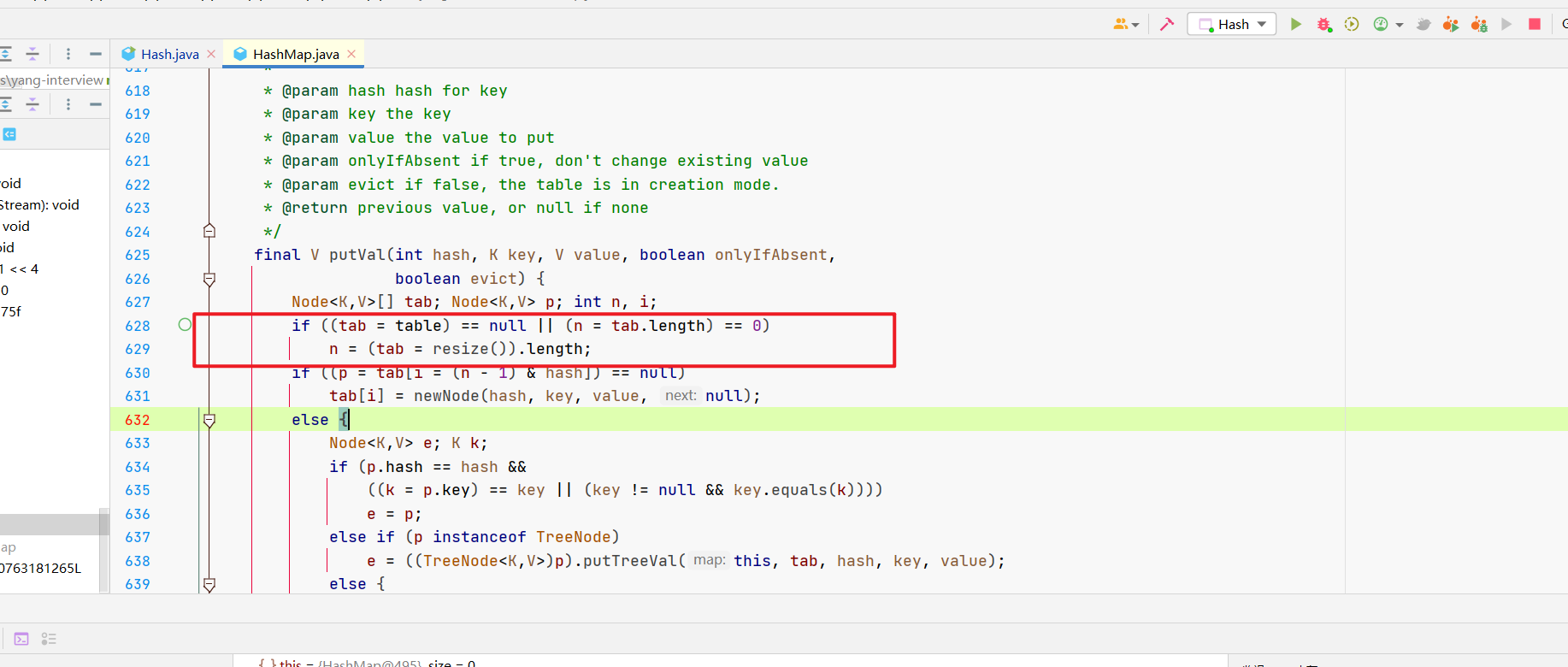
这里的tab就是我们hash的数组桶。

然后呢,table是成员变量。
源码就这样,给你搞各种简写,烦死了,那其实就是这样嘛。
// 直接把成员变量table扔给tab,最开始为null。
tab = table;
// tab的长度
n = tab.length;
if ( tab == null || n == 0)
tab = resize()
n = tab.length;
第一次进来,tab用的是table这个成员变量的值,为null。
所以,肯定会走到if里面去,执行resize方法扩容,然后更新n为长度。
resize方法看一下,它有两个用处。
- 真的是进行扩容
- 第一次的时候,初始化我们的数组。
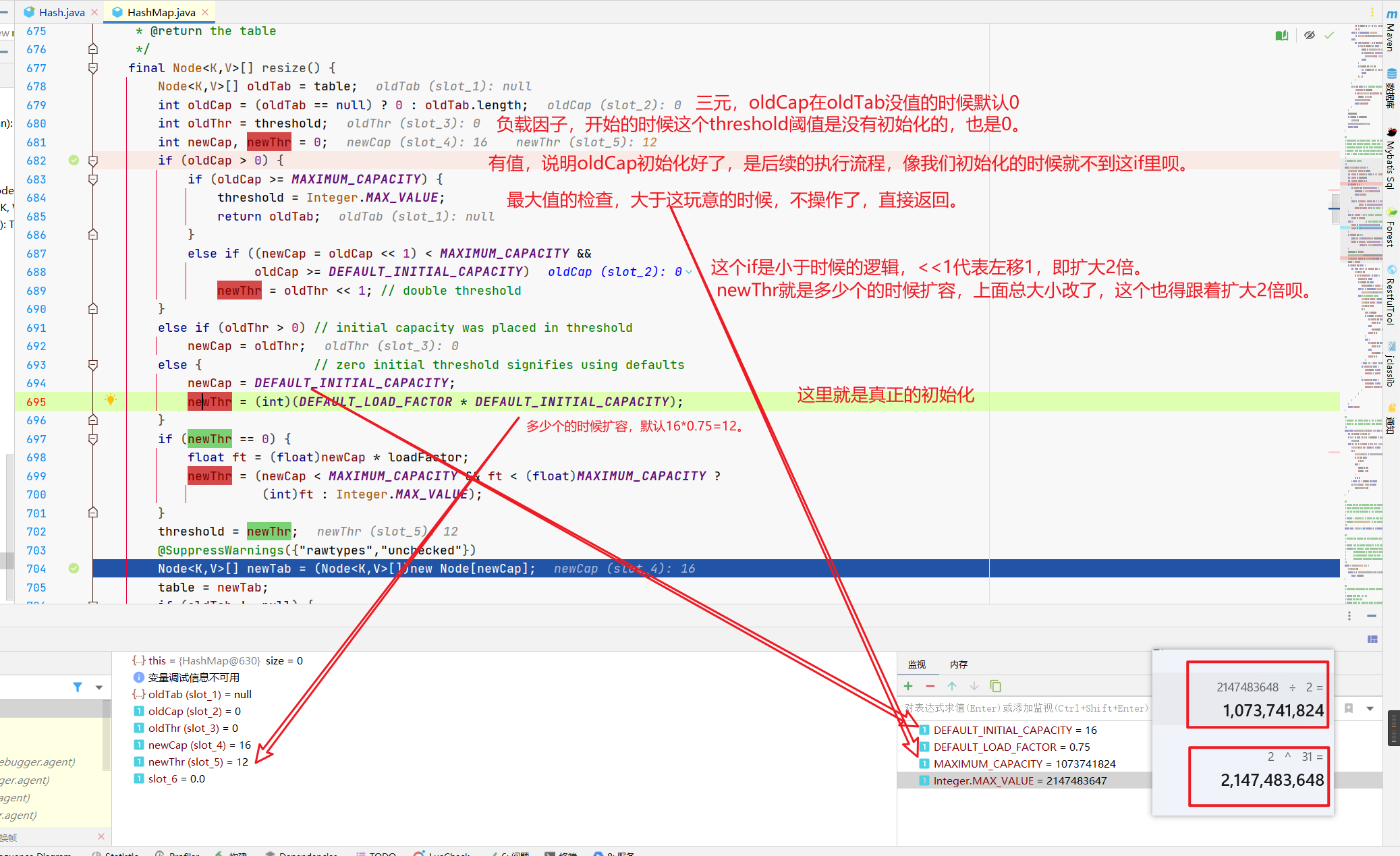
所以在resize的时候,前面的逻辑大概就是。
把咱们的数组桶(16)、扩容阈值(12)都扩容成2倍。
后面的是移动元素的,咱们先不看。
2.3.2 首次放置
所以呢,刚进来的时候,这里就是搞了个16长度的Node数组给我们,然后赋值了几下,顺便记录了下扩容的阈值是12。
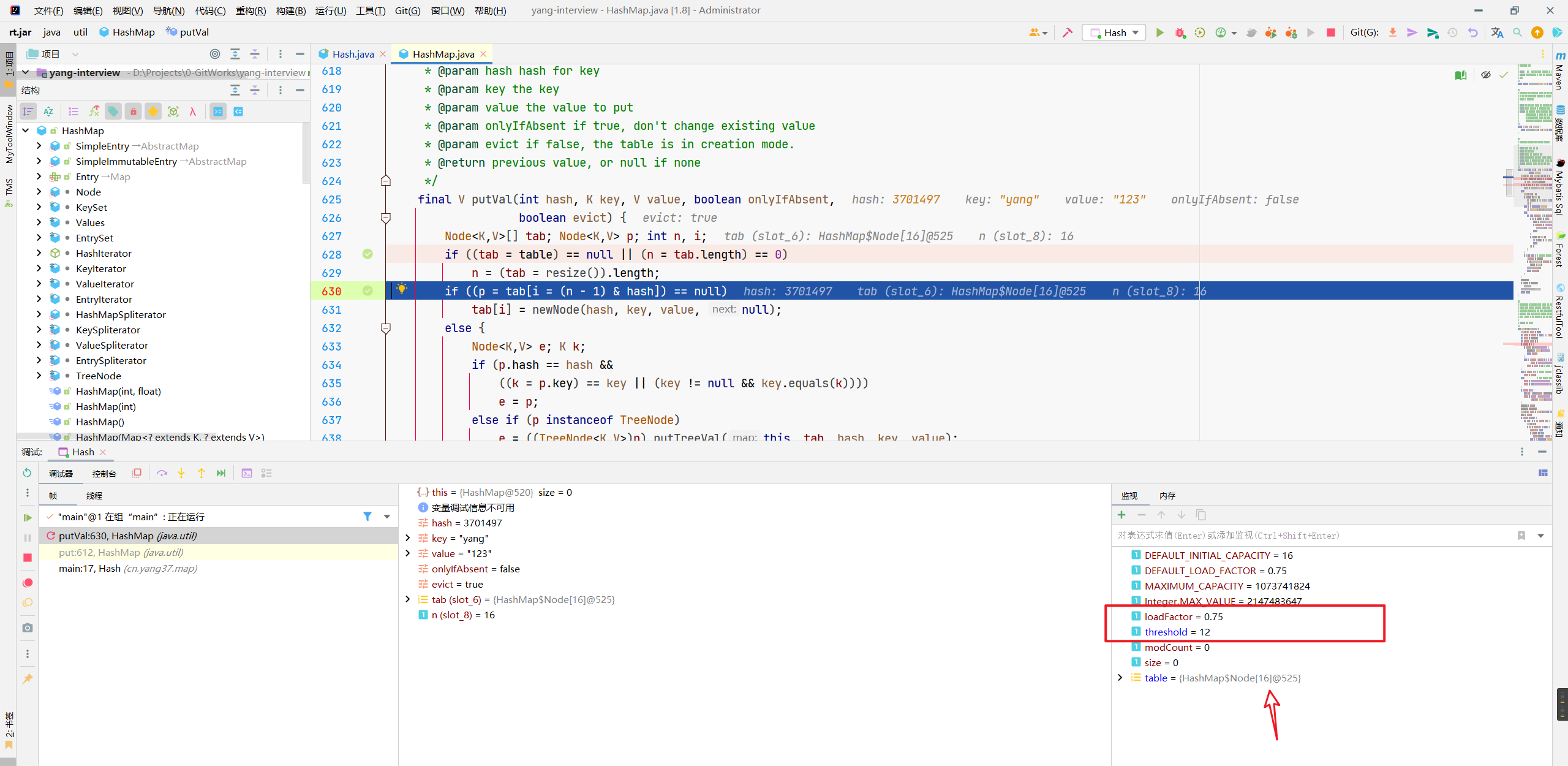
回到这个p的判断,p是什么,p就是咱们一个Node元素。
if ((p = tab[i = (n - 1) & hash]) == null)
翻译一下,为啥取模是(n-1)&hash看我这篇文章:Java-取模操作中的&和(length-1)、HashMap取模、HashMap扩容
// 这是在取模
i = (n - 1) & hash
// 就是看这个节点上有元素没
p = tab[i]
p==null?
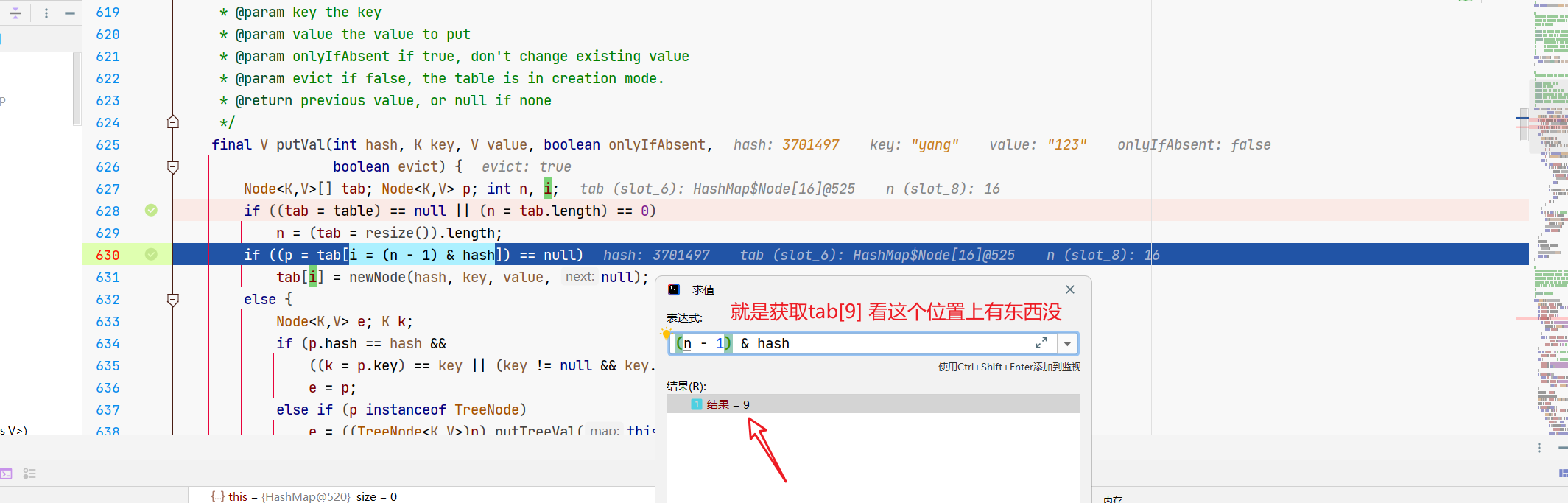
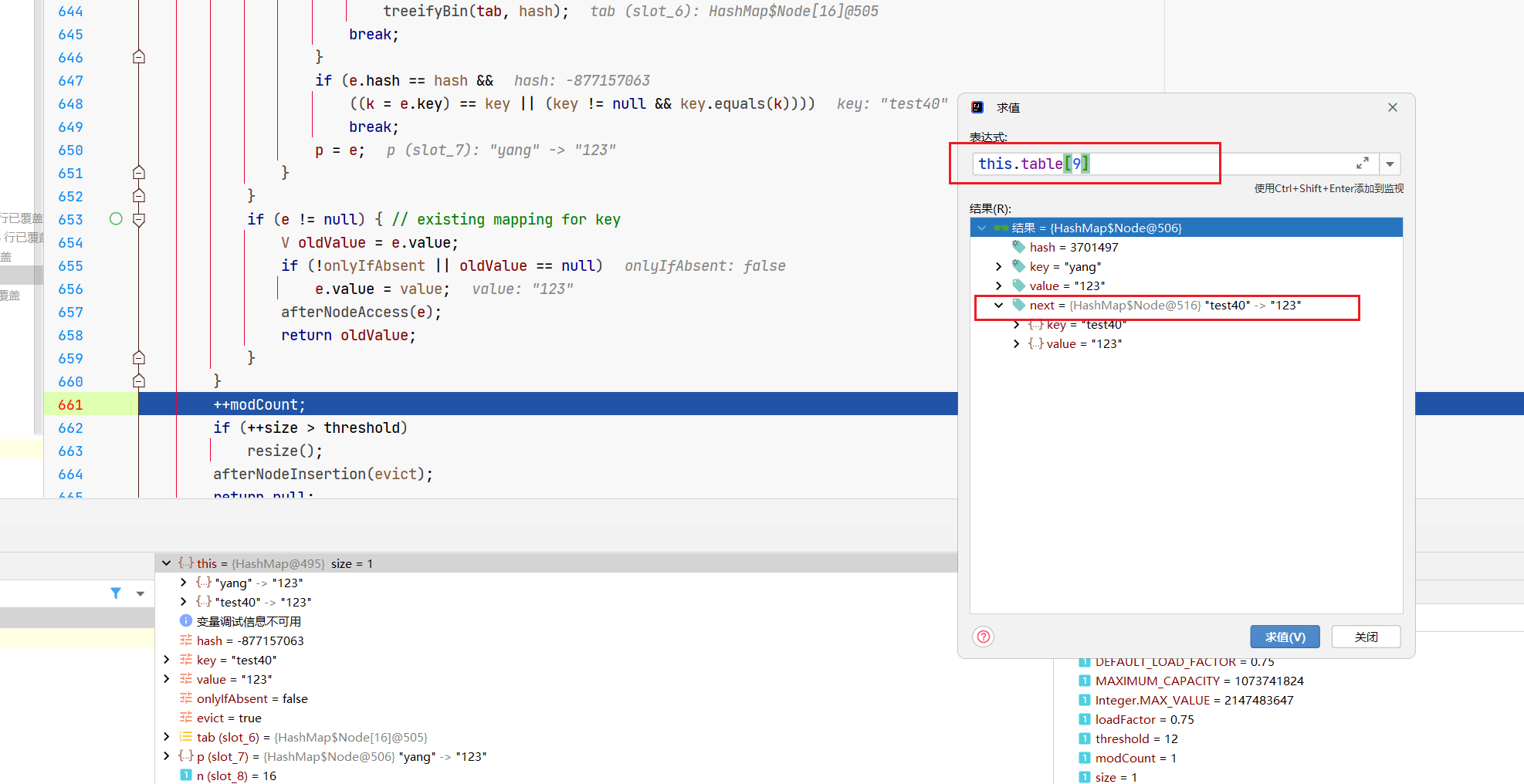
那现在刚进来,肯定就是没元素呗,所以tab[9]这个元素是空的,咱们就要创建个Node节点放上去,执行newNode()。
那tab[i]就是咱们这个数组桶上的玩意呗,它为null,说明里面没东西还,直接扔节点进去就完事,你看next固定传null。
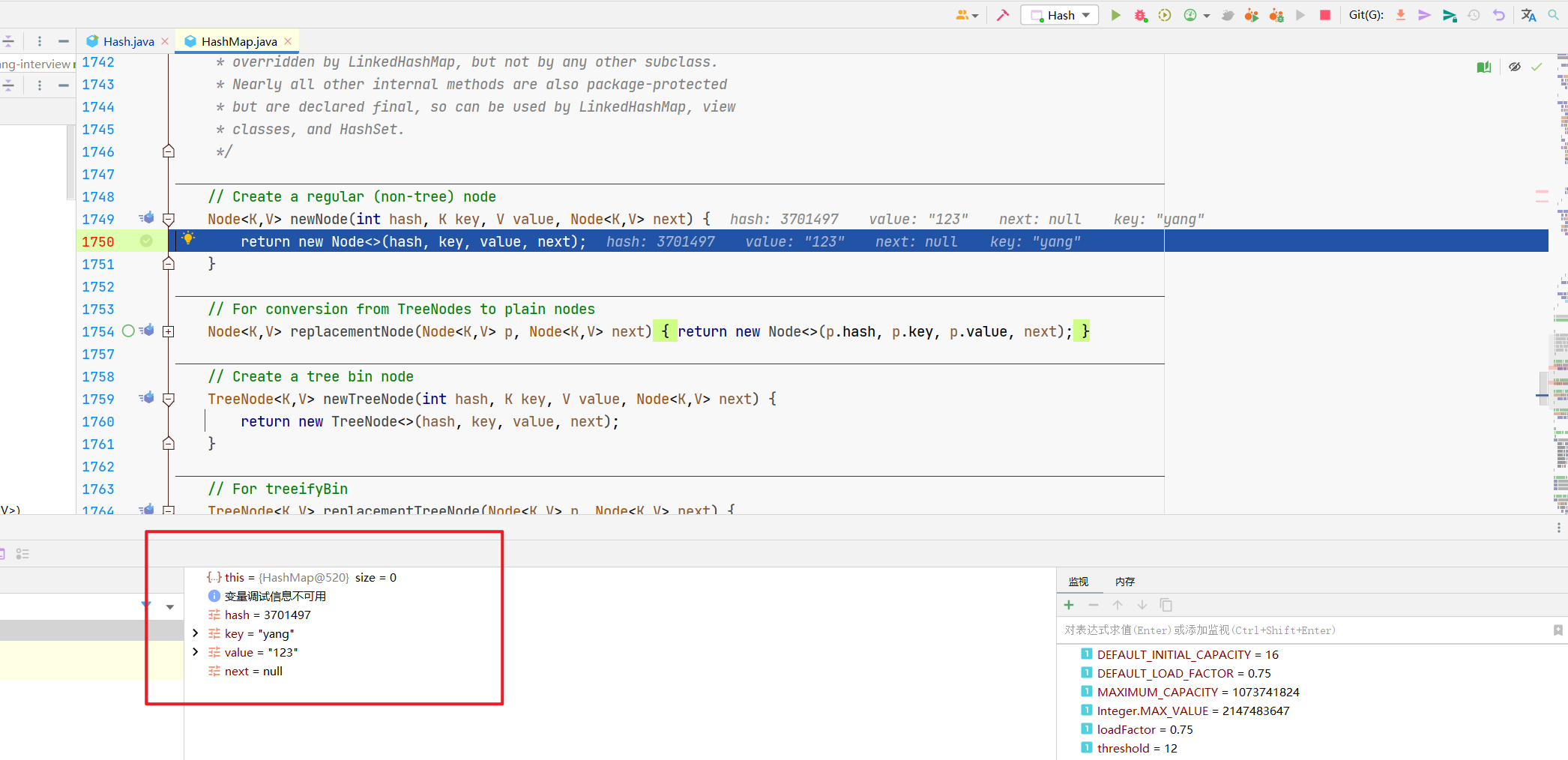
所以,tab[i]上没元素的时候很简单,放一个Node节点进来就完事。
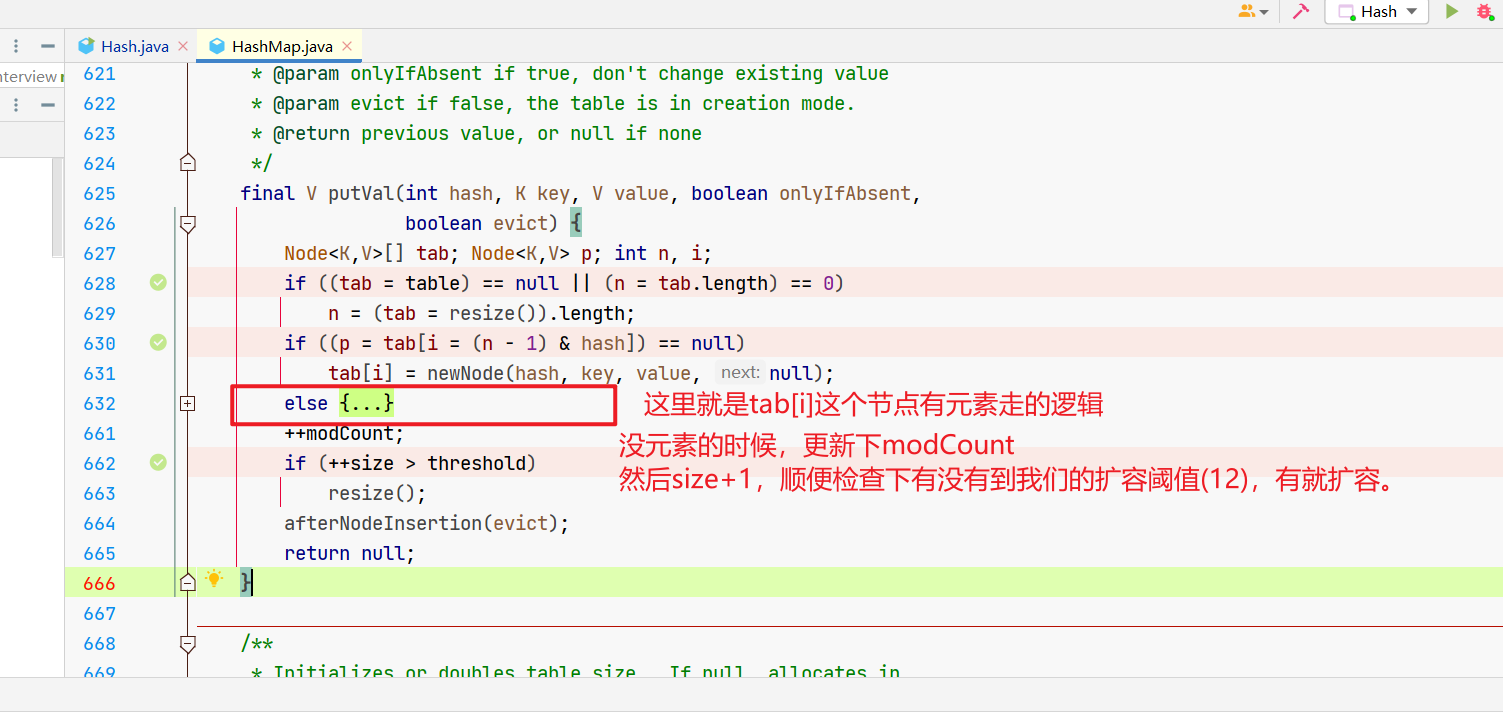
所以,当最开始的时候,咱们的逻辑很简单,初始化了下,往tab[9]扔了个Node元素。

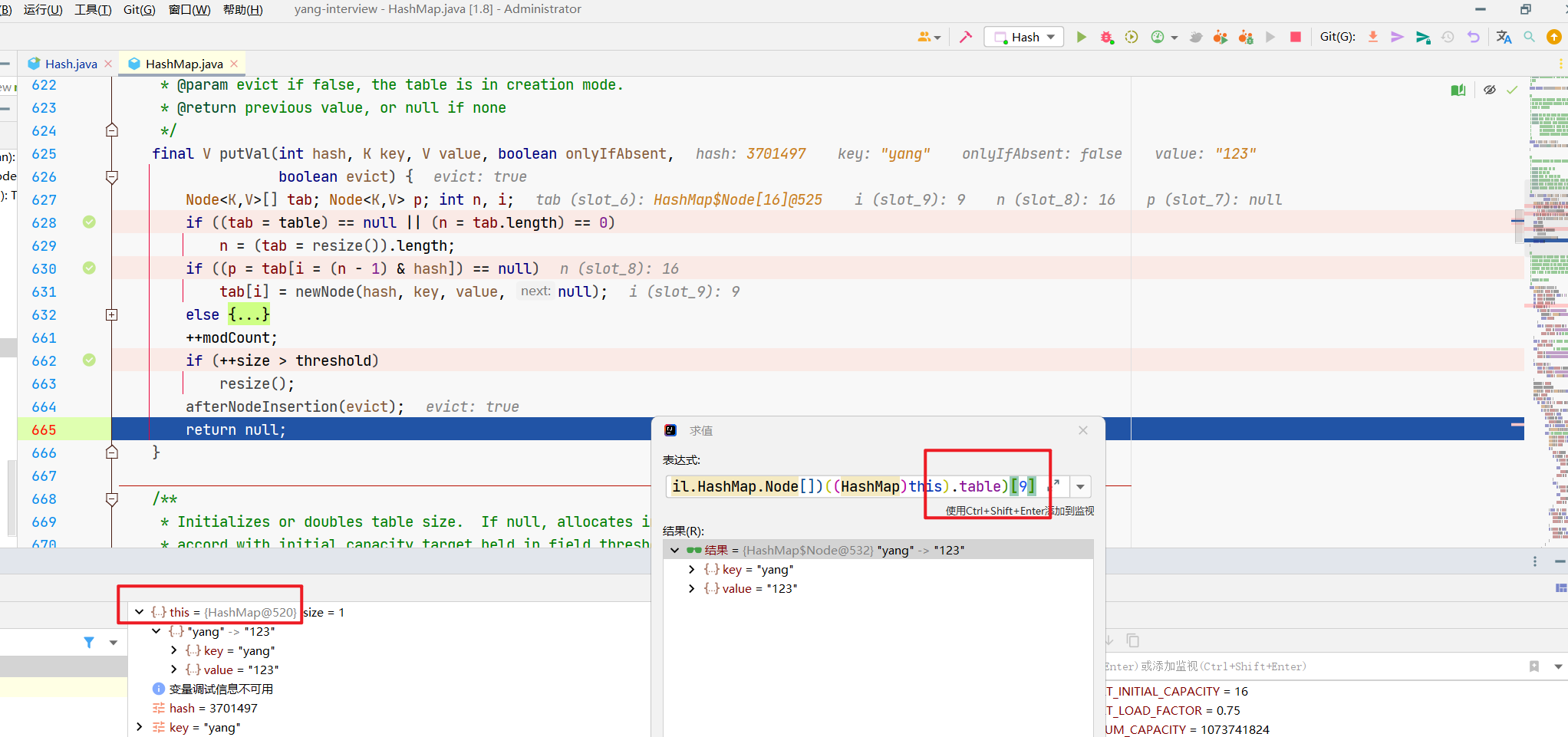
这个很简单对吧?关键是有元素的时候咋整。
2.3.2 哈希冲突
1.数组转链表
在2.2.3节中,我们已经知道,下面这些都是咱们的冲突键,它们都会落到9号位。
test40
test51
test62
test73
test84
test95
test100
test111
test122
test133
不妨增加下put。
HashMap<String, Object> hashMap = new HashMap<>();
hashMap.put("yang", "123");
hashMap.put("test40", "123");
现在我们重新debug下,看第二次的。
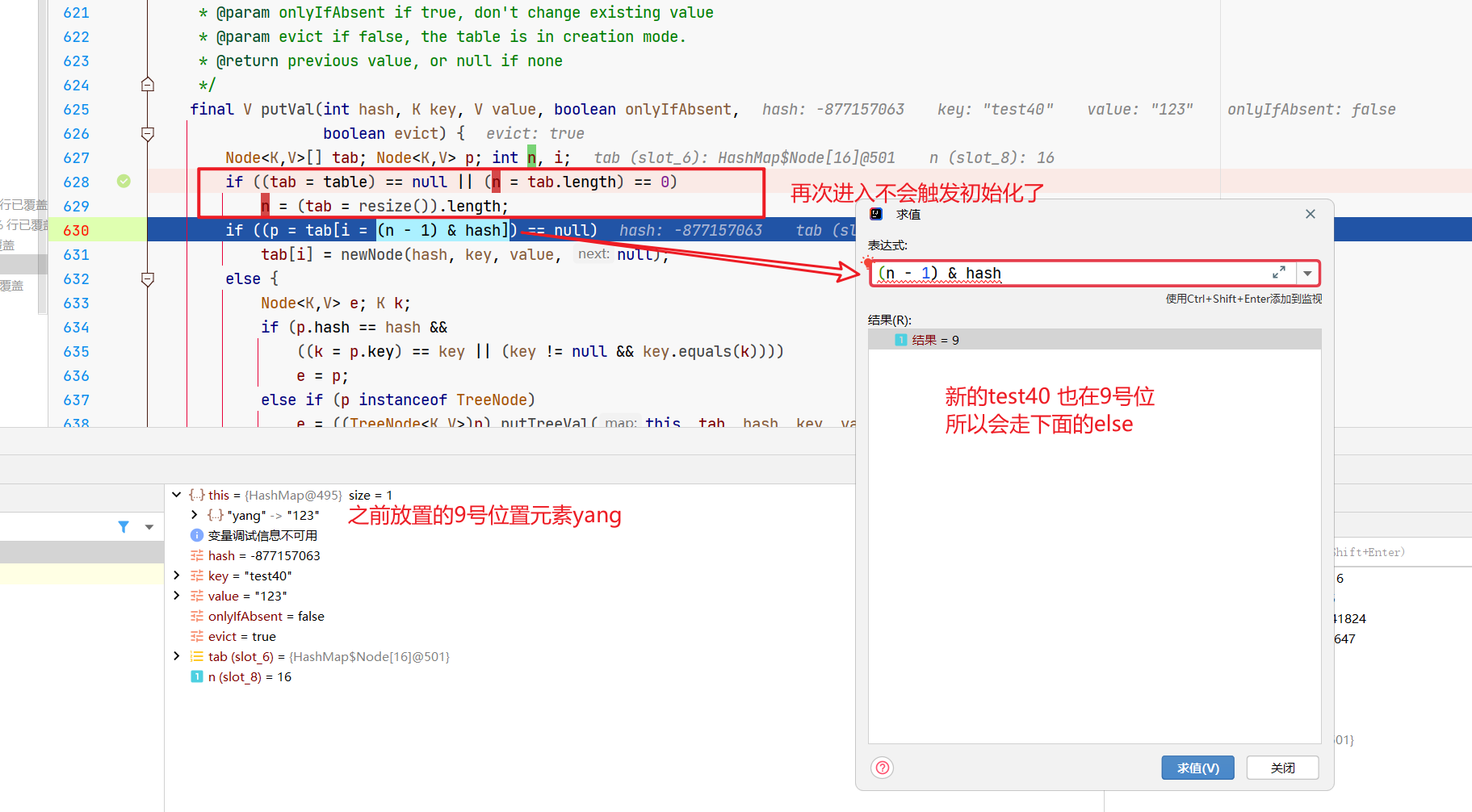
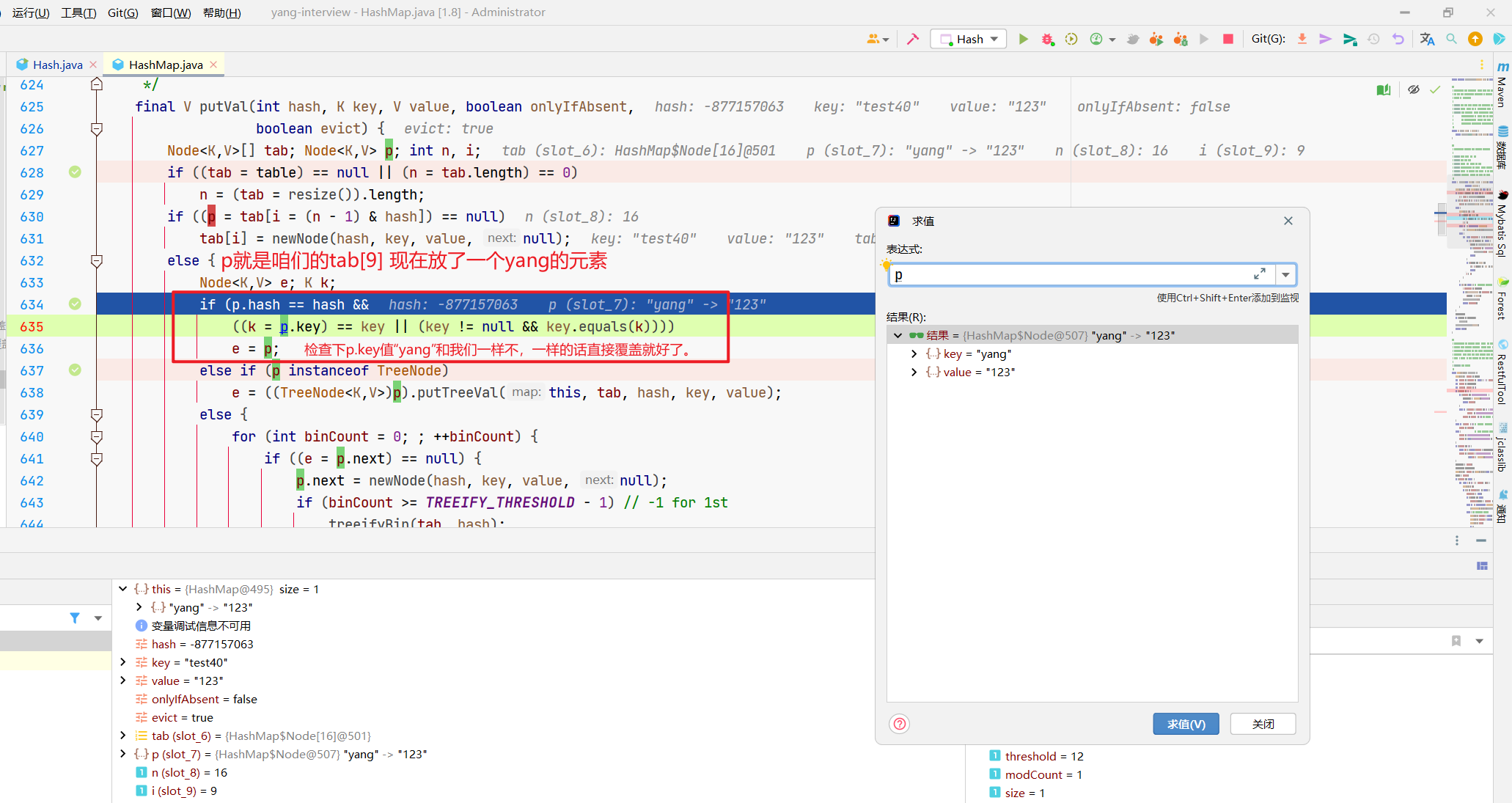
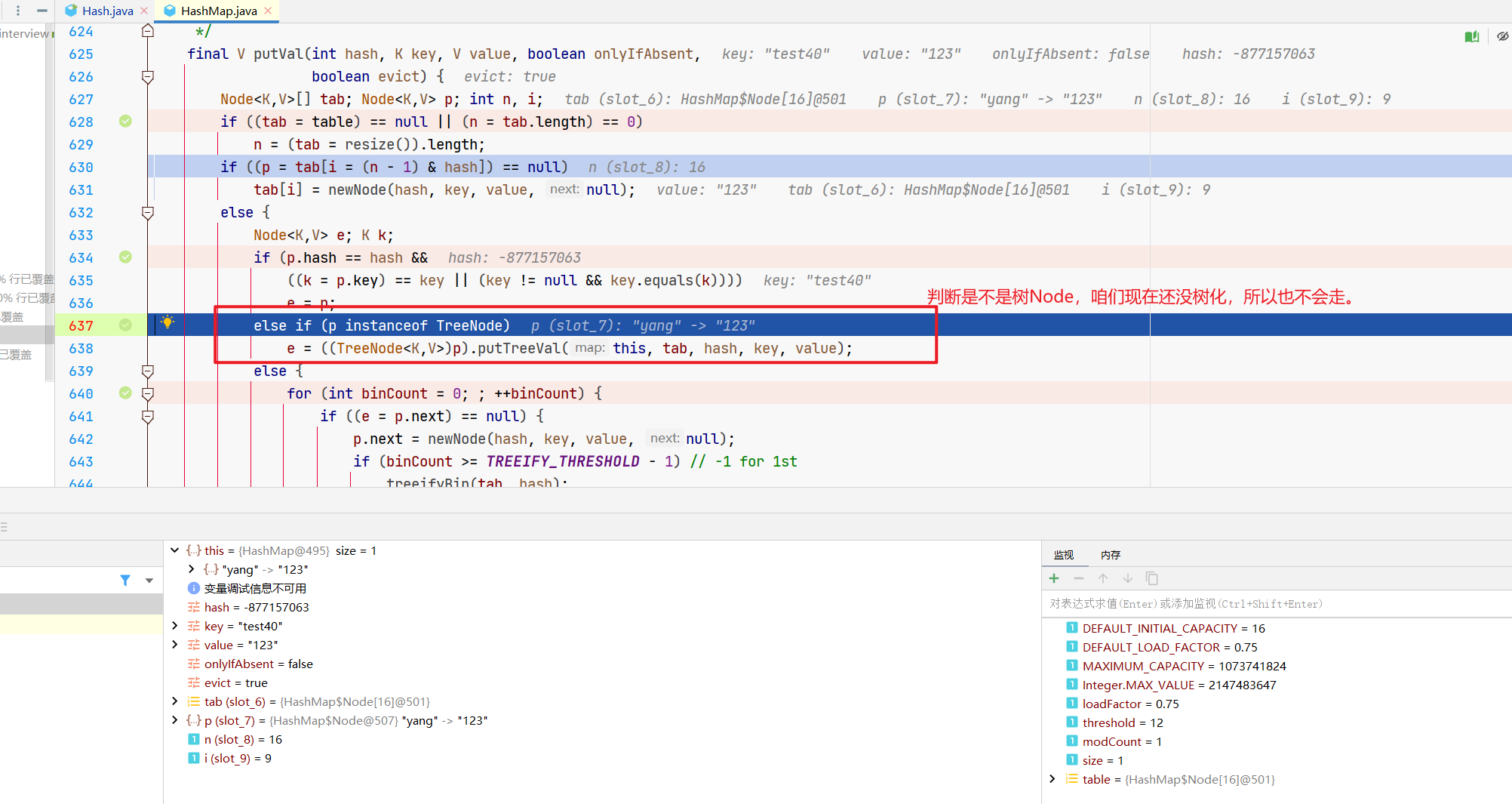
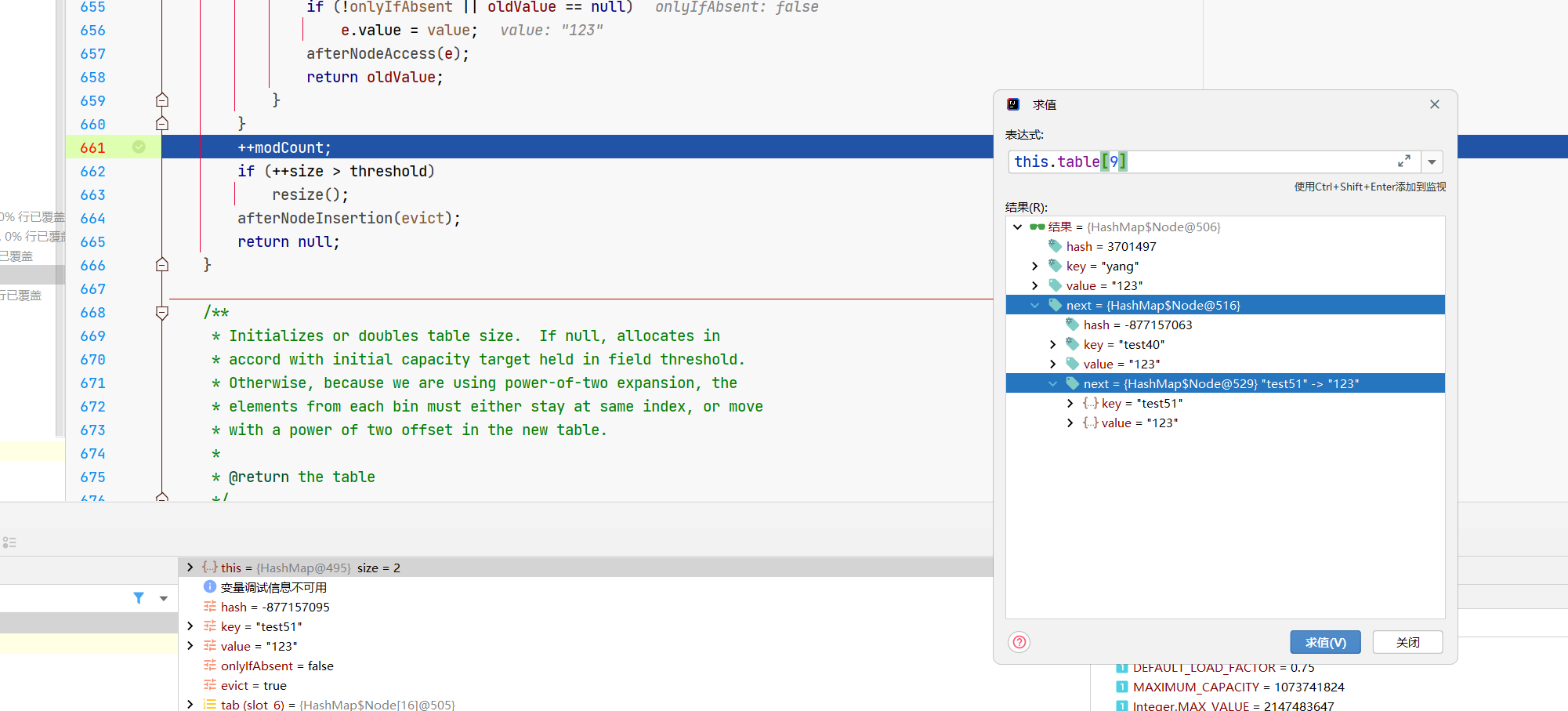
然后就来到了一个for循环。
这段代码中,e是咱们当前的元素,p是数组上的元素,最上面那个节点嘛。
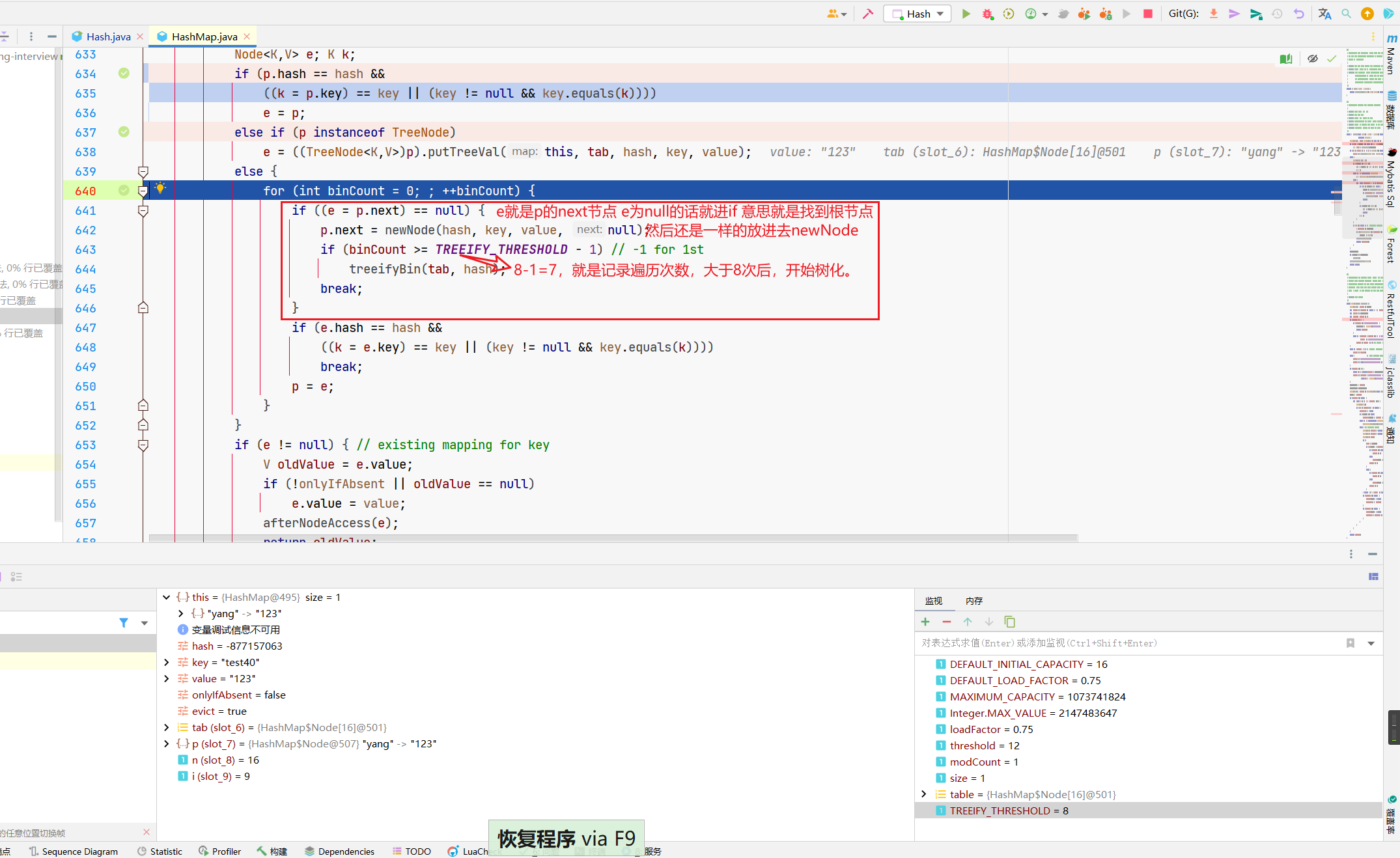
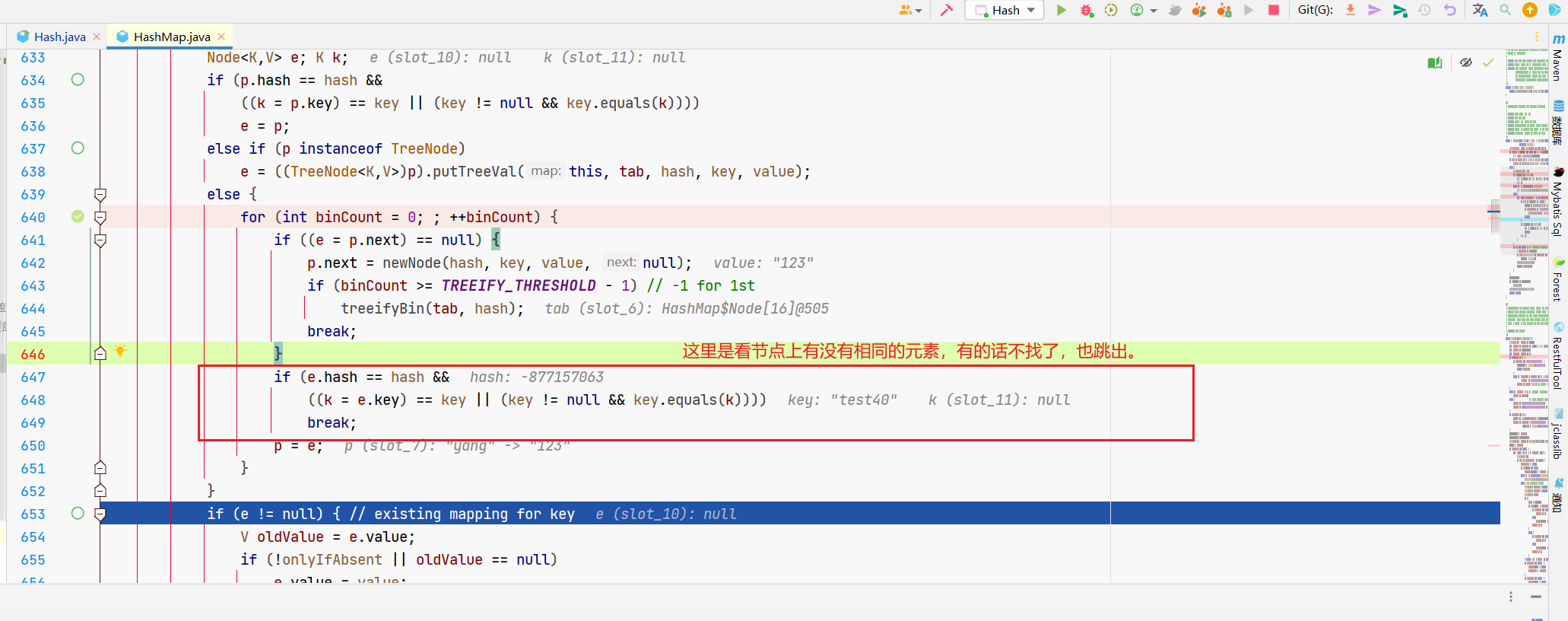
所以呢,这个大的if,就是在放置元素,有的话跳出。
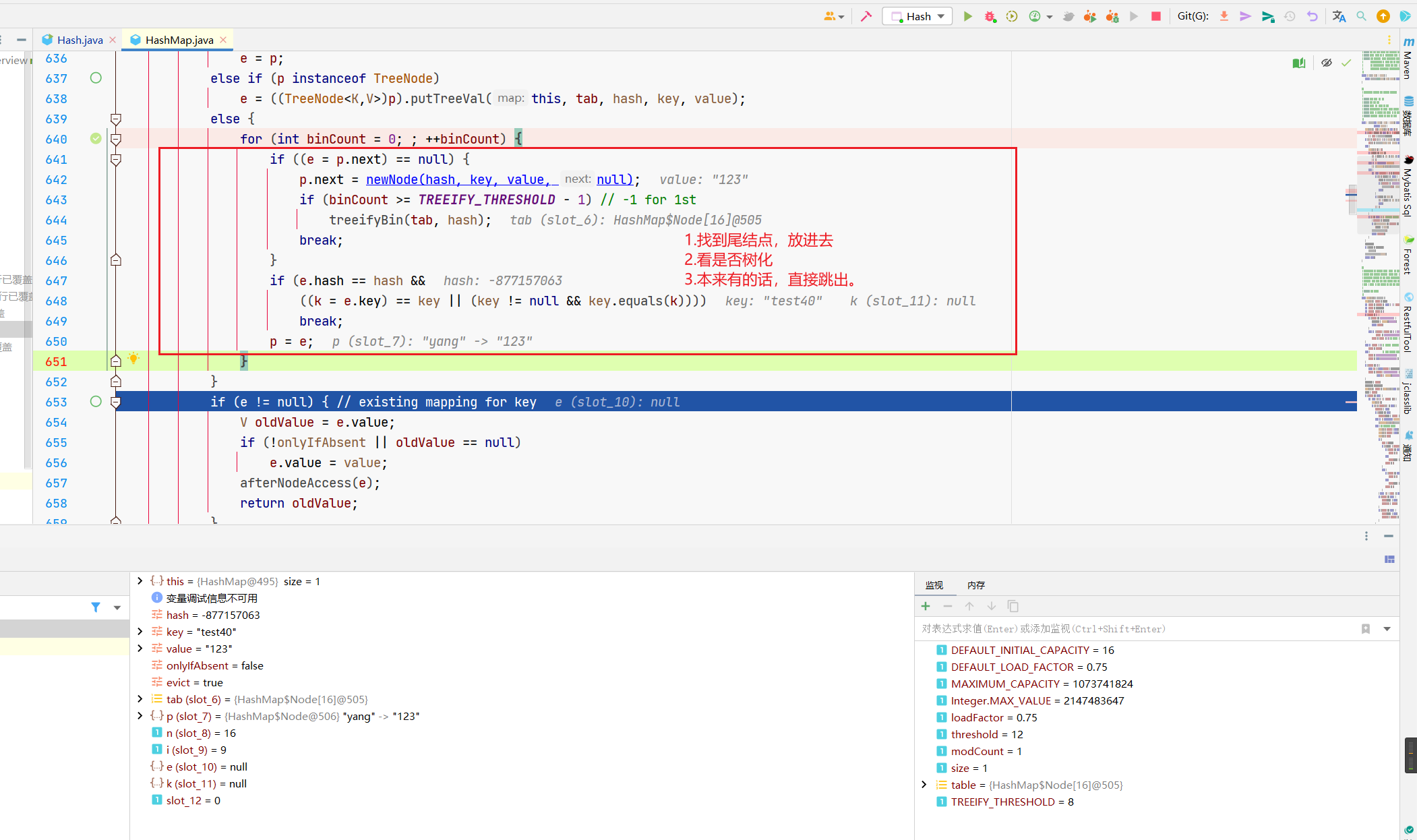
Node既然放进去了,最后就是值的填充,跟我们前面的ifAbsent标记有关,来看最后的if。
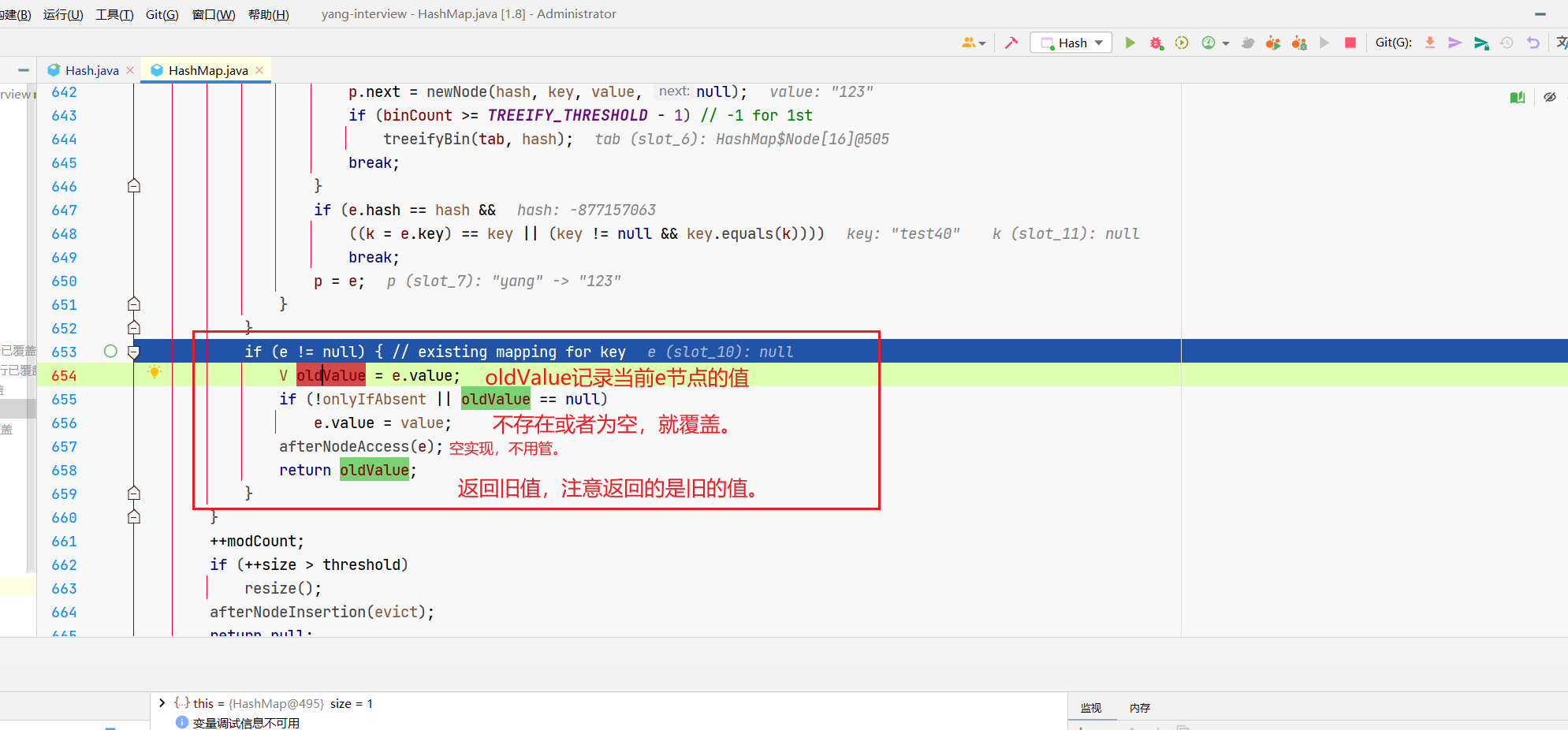
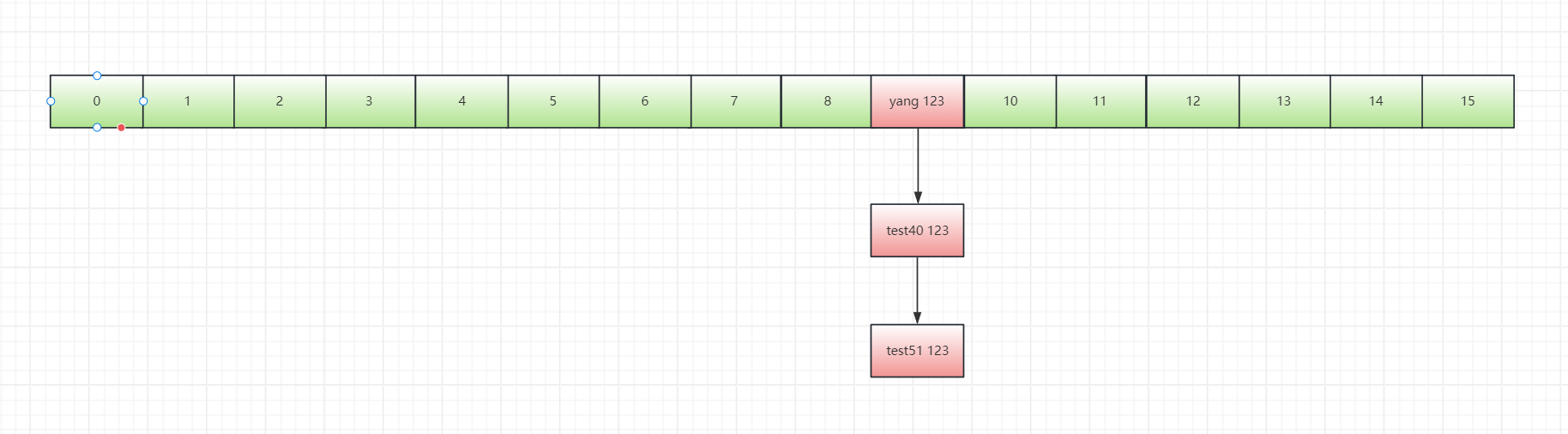
所以呢,经过上面的操作,咱们的hashMap就变成了这个样子。

然后就是追加值进去嘛。
2.链表转红黑树
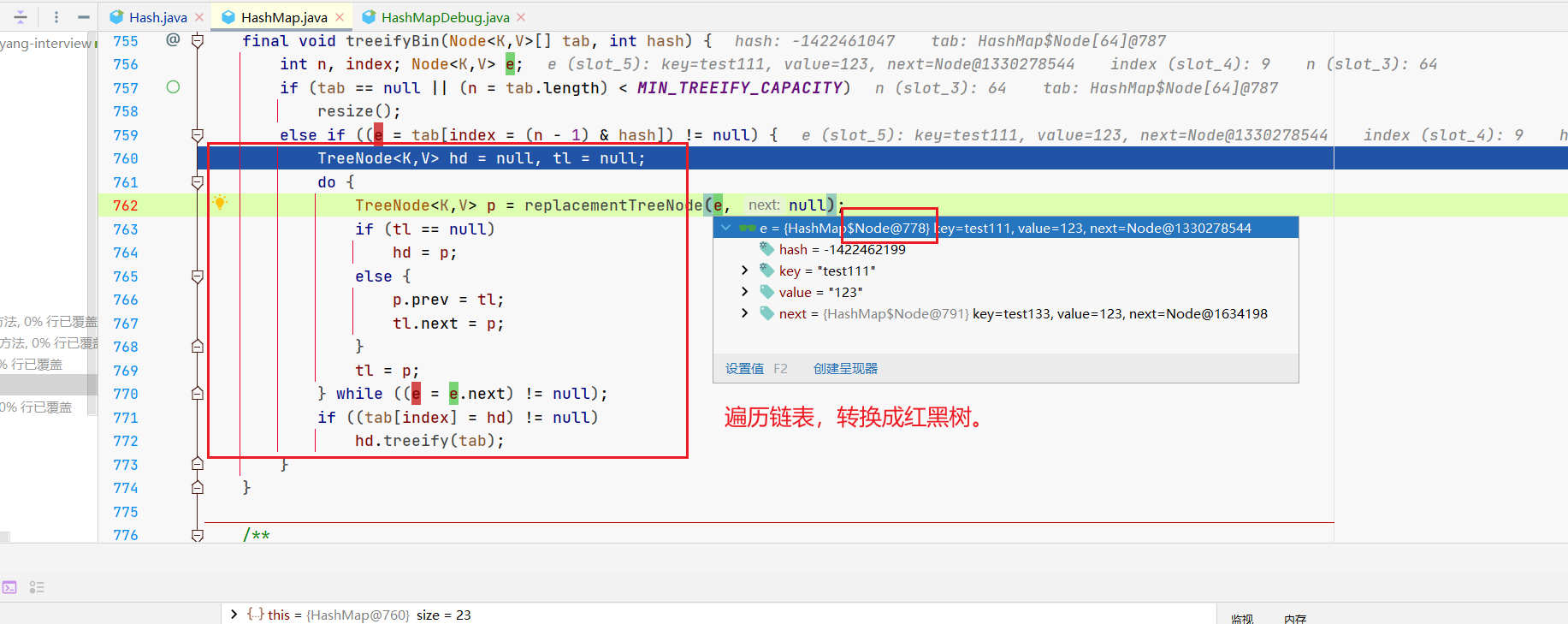
在上面的例子中,正常情况下都不会触发树化,直到有一次。
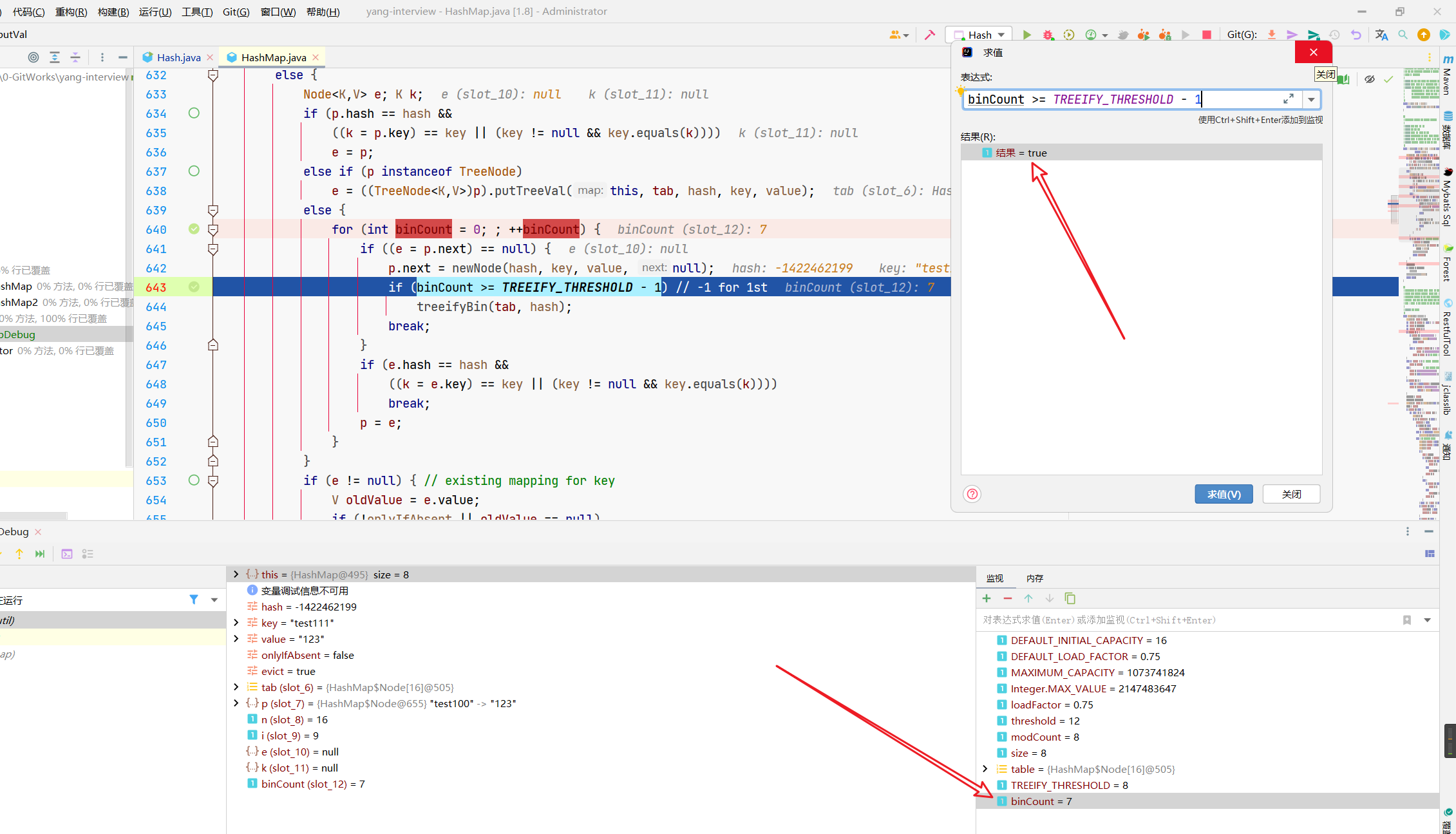
这个时候呢,咱们的链表上是有9个元素的哦,所以说,咱们的树化,是先把链表构建出来,再触发树化。
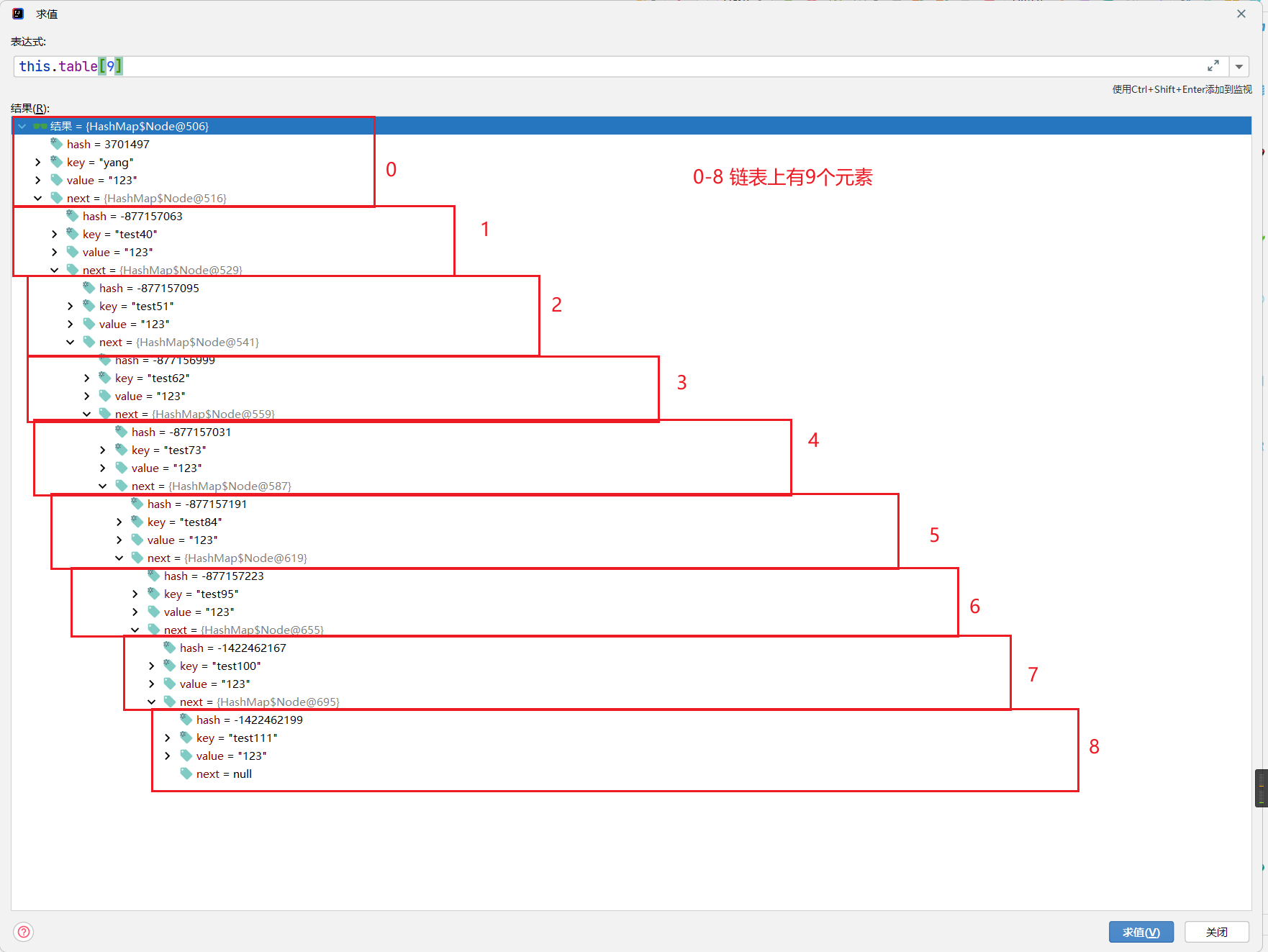
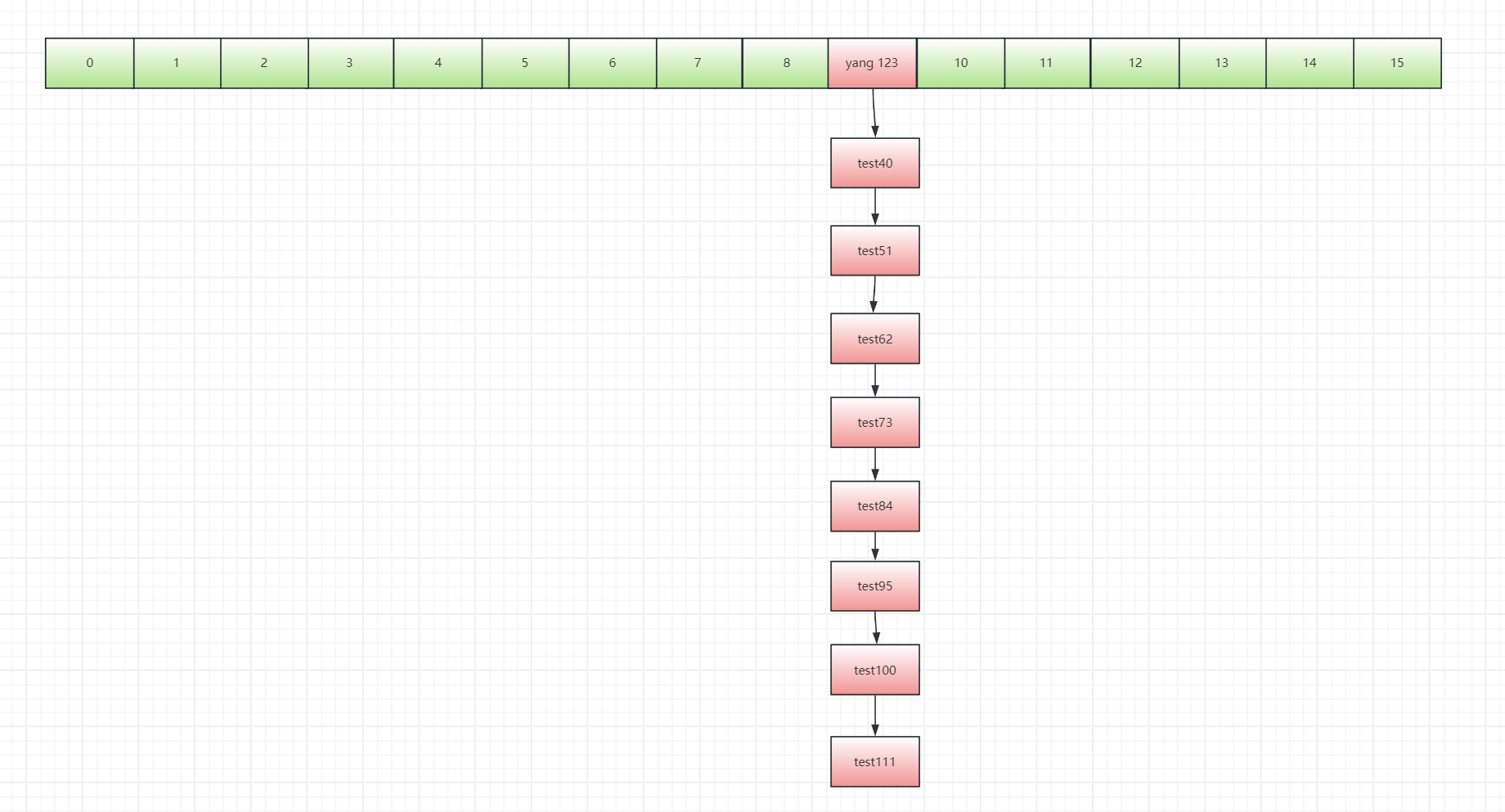
接着,就进入到咱们的treeifyBin(tab, hash);方法中。
你看,这里把咱们的tab传进来了,tab是啥,是整个hash表哈,头上这个,整个tab都传进来了(现在tab的9号位上有个链表)。
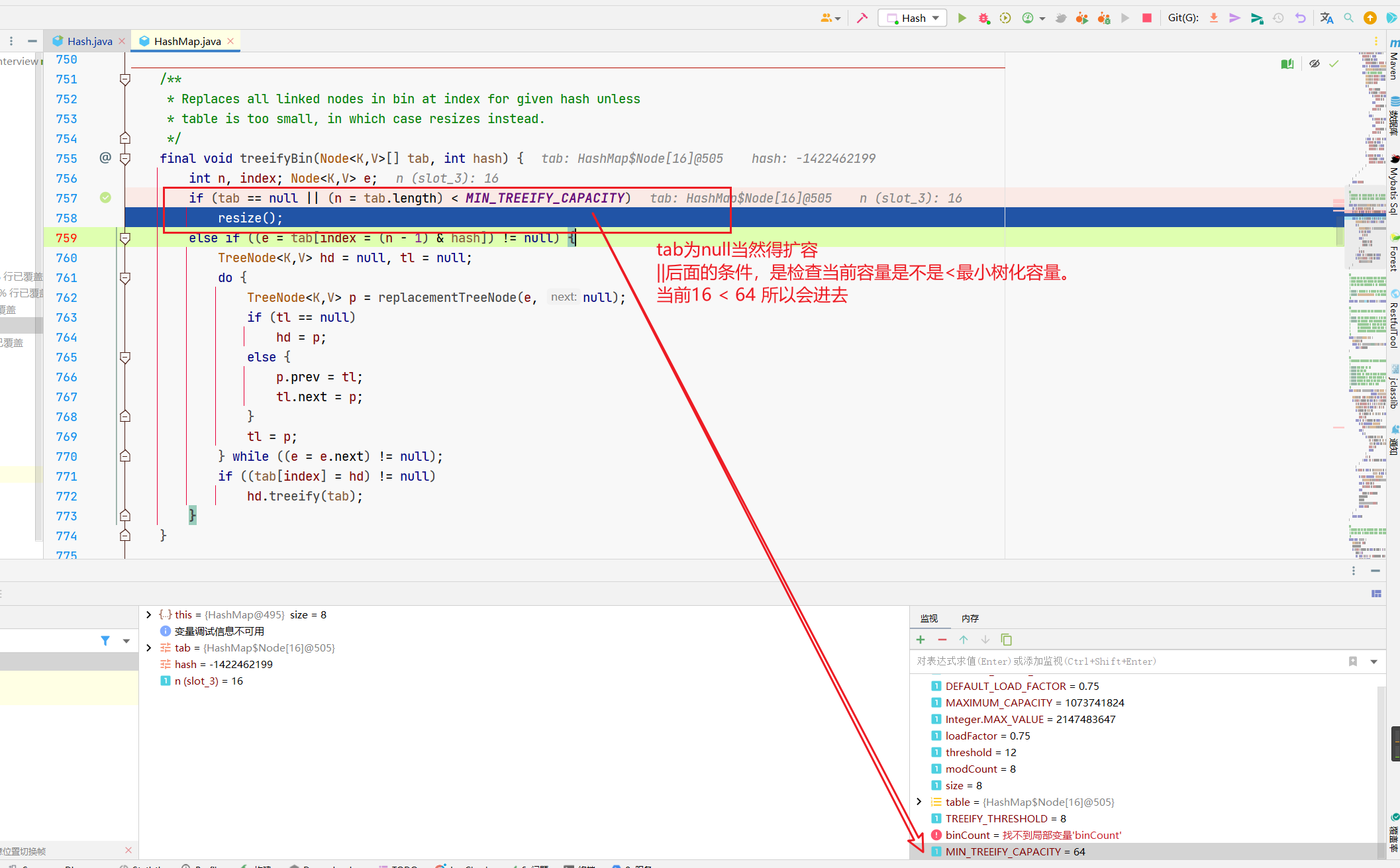
哎关键点来了,没有触发树化啊?
在HashMap中,treeifyBin方法用于将链表转换为树结构(即红黑树)以提高查找和插入性能。
但在进行这个转换之前,有一个检查条件是哈希表的容量(数组长度)是否小于一个特定的最小值MIN_TREEIFY_CAPACITY。
-
MIN_TREEIFY_CAPACITY是64。这是一个经验值,用于避免在哈希表还比较小的时候进行树化操作。 -
如果哈希表的容量小于64,即使链表的节点数量超过了
TREEIFY_THRESHOLD(8),HashMap也不会立即将链表转换为红黑树,而是优先进行扩容操作。 -
这样做的目的是在较小的哈希表中通过扩容来减少哈希冲突,从而避免过早地进行复杂的树化操作。
有办法吗?当然,根据我们的扩容规律。
12的时候会扩容到16*2=32。
24的时候会扩容到32*2=64。
所以,我们把key值拉到24个,此时数组长度是64,不满足小于条件。
package cn.yang37.map;
import java.util.HashMap;
/**
* @description:
* @class: HashCode
* @author: yang37z@qq.com
* @date: 2023/6/17 16:05
* @version: 1.0
*/
public class Hash {
public static void main(String[] args) {
HashMap<String, Object> hashMap = new HashMap<>();
hashMap.put("yang", "123");
hashMap.put("test40", "123");
hashMap.put("test51", "123");
hashMap.put("test62", "123");
hashMap.put("test73", "123");
hashMap.put("test84", "123");
hashMap.put("test95", "123");
hashMap.put("test100", "123");
hashMap.put("test111", "123");
hashMap.put("test122", "123");
hashMap.put("test133", "123");
hashMap.put("test144", "123");
hashMap.put("test155", "123");
hashMap.put("test166", "123");
hashMap.put("test177", "123");
hashMap.put("test188", "123");
hashMap.put("test199", "123");
hashMap.put("test210", "123");
hashMap.put("test221", "123");
hashMap.put("test232", "123");
hashMap.put("test243", "123");
hashMap.put("test254", "123");
hashMap.put("test265", "123");
hashMap.put("test276", "123");
System.out.println(hashMap.size());
}
}
然后再在此处断点。
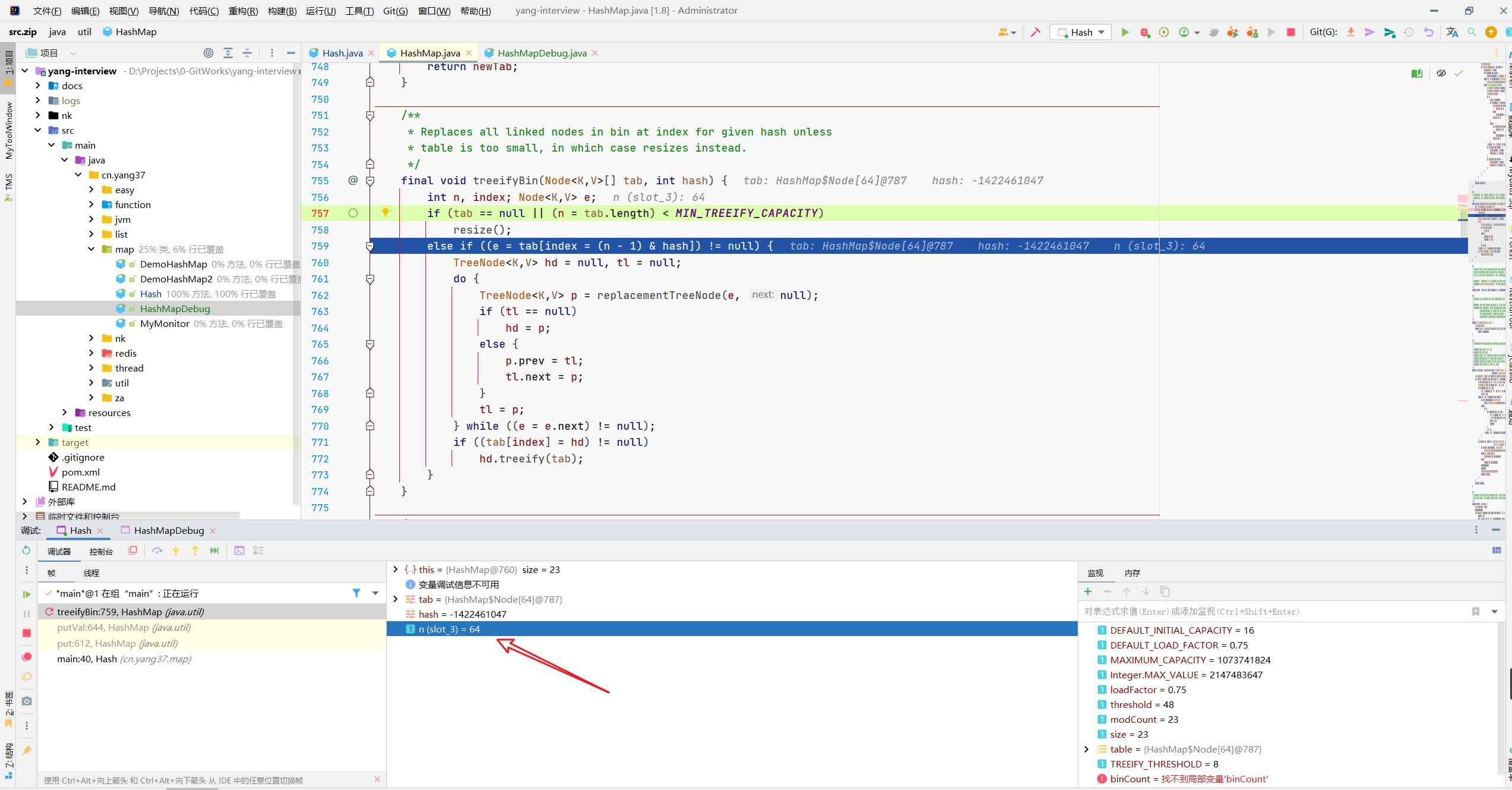
2.3.4 扩容
查看扩容方法,我们可以看到触发条件是这几个。
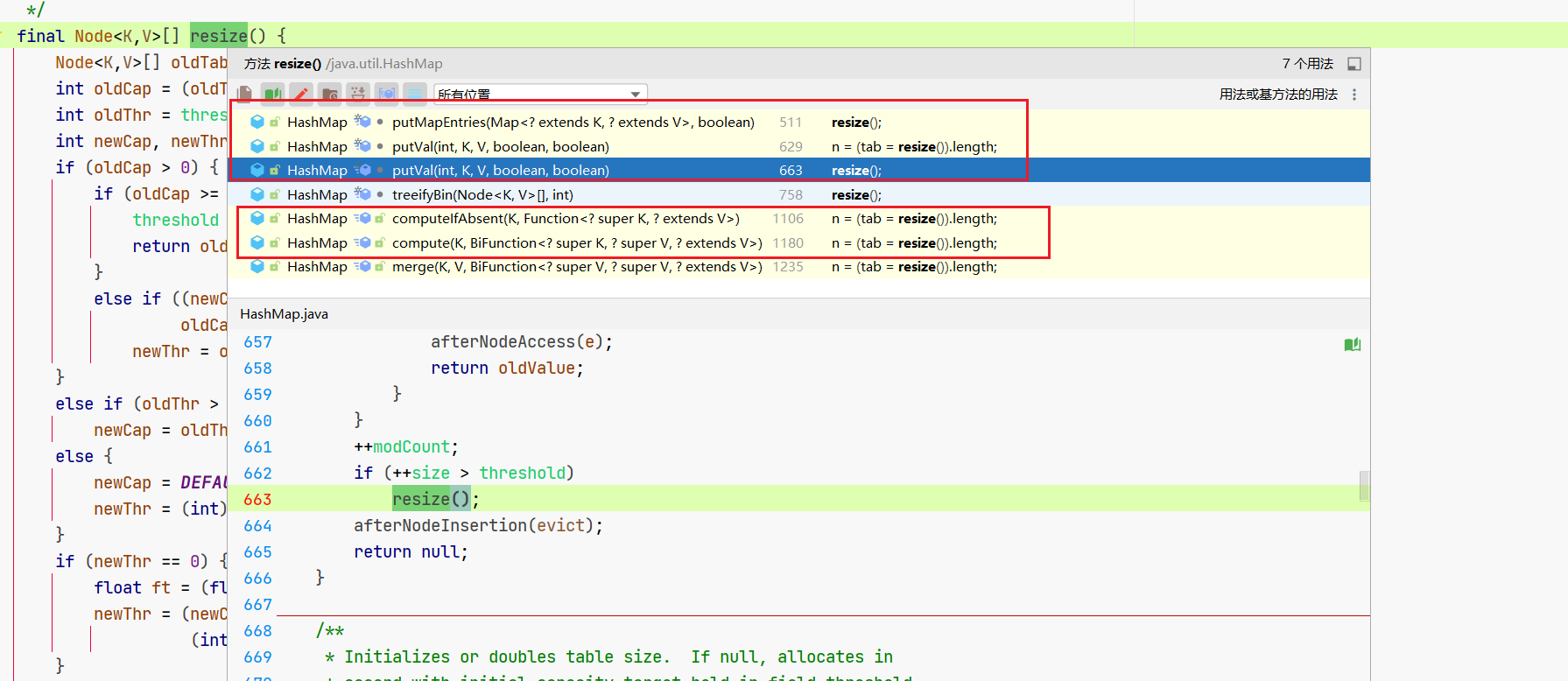
- put
- treeifyBin
- compute
- merge
好咯,treeifyBin就是树化前的检查,compute就是传递函数条件来决定是否放置,merge呢就是合并。
那根本还是在放元素进去,所以呢,我们触发扩容的检查操作是在放置元素的时候。
扩容扩的是什么:是HashMap中的哈希桶的个数。
这个容操作,主要做了两件事情。
- 扩充咱们的扩容阈值和总容量
- 移动咱们的元素到新的哈希桶
1.扩充阈值与总容量
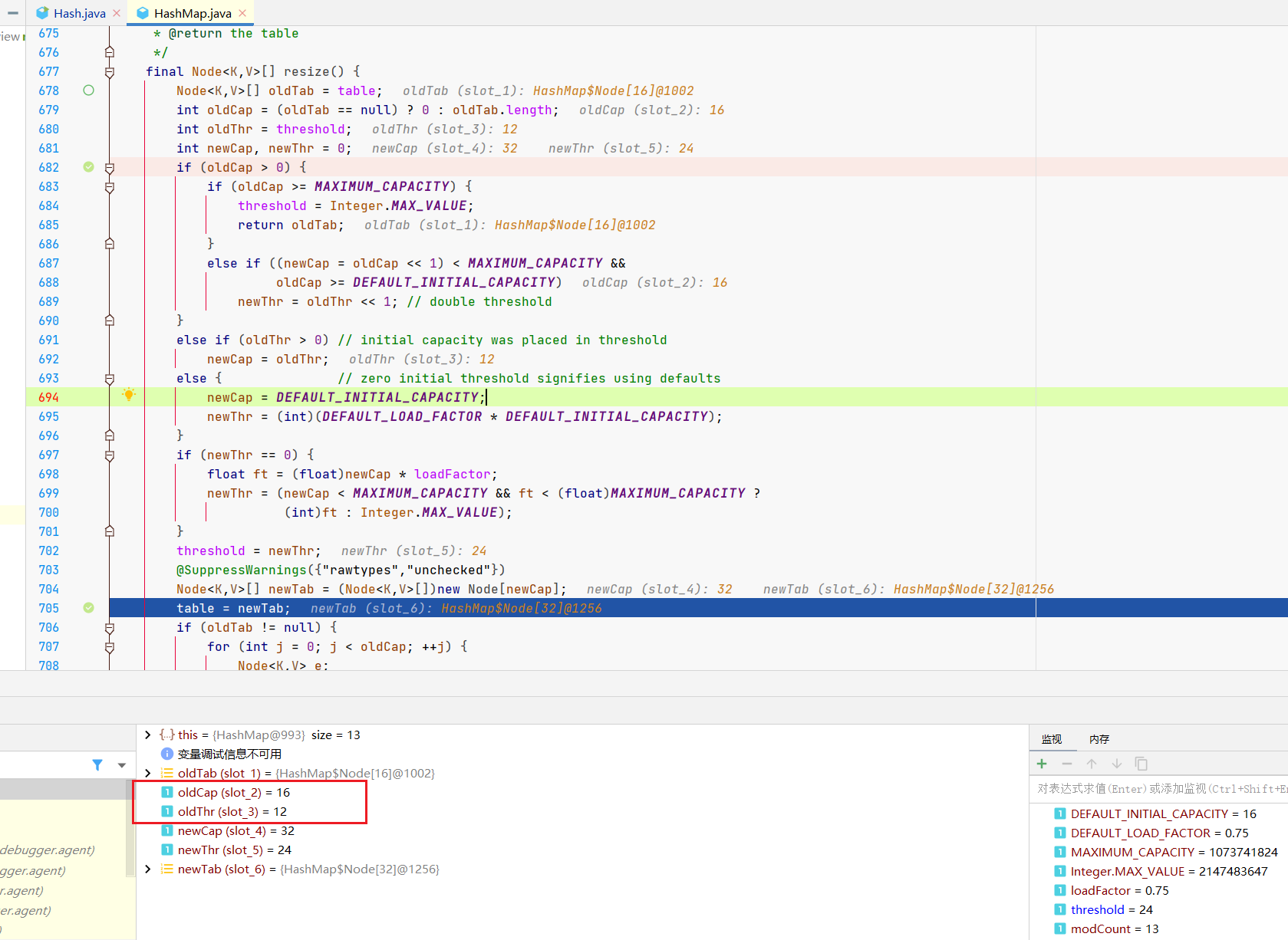
将咱们的newCap(总容量)、newThr翻倍,主要就是图中的这里。
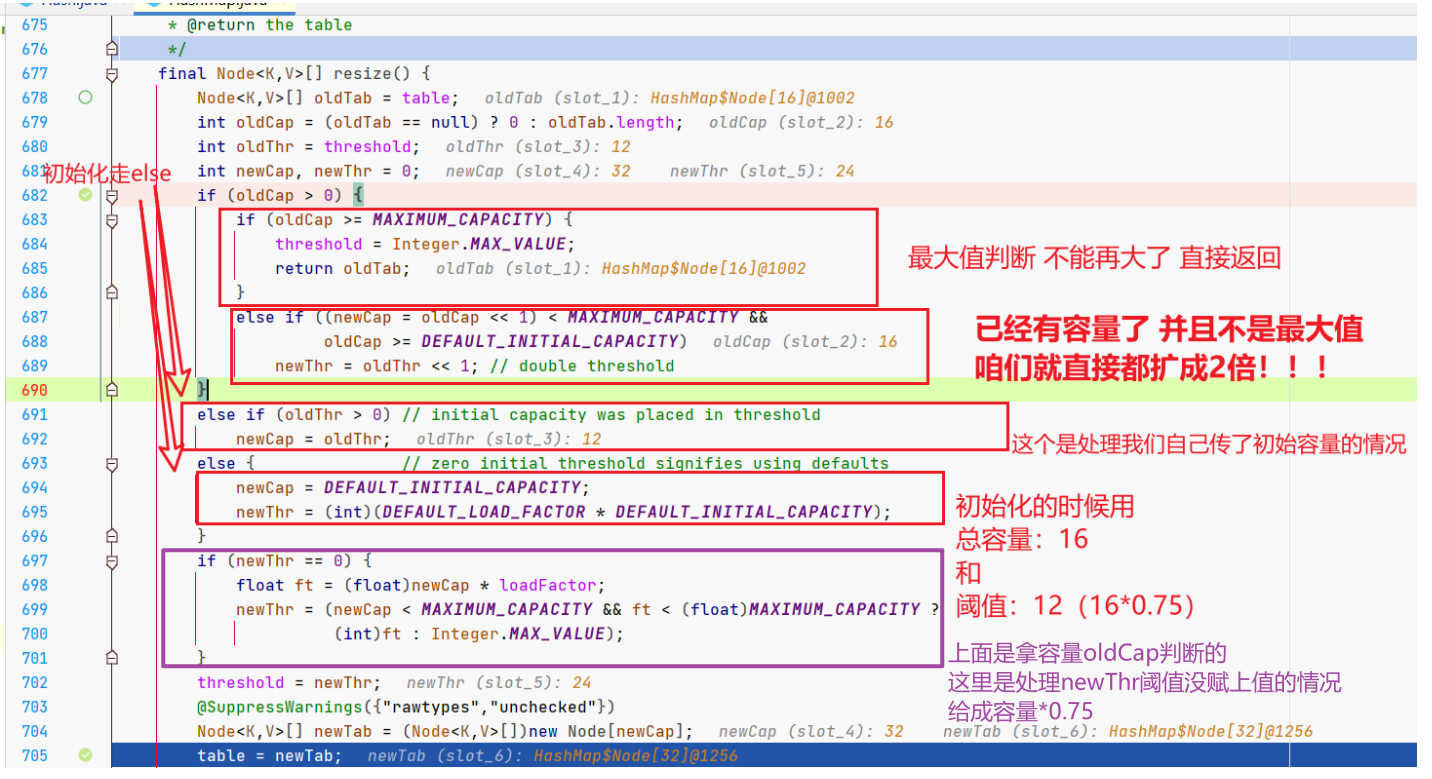
2.迁移元素
在完成容量和阈值更新后,就会开始迁移元素,就是咱们下面这个大的if。
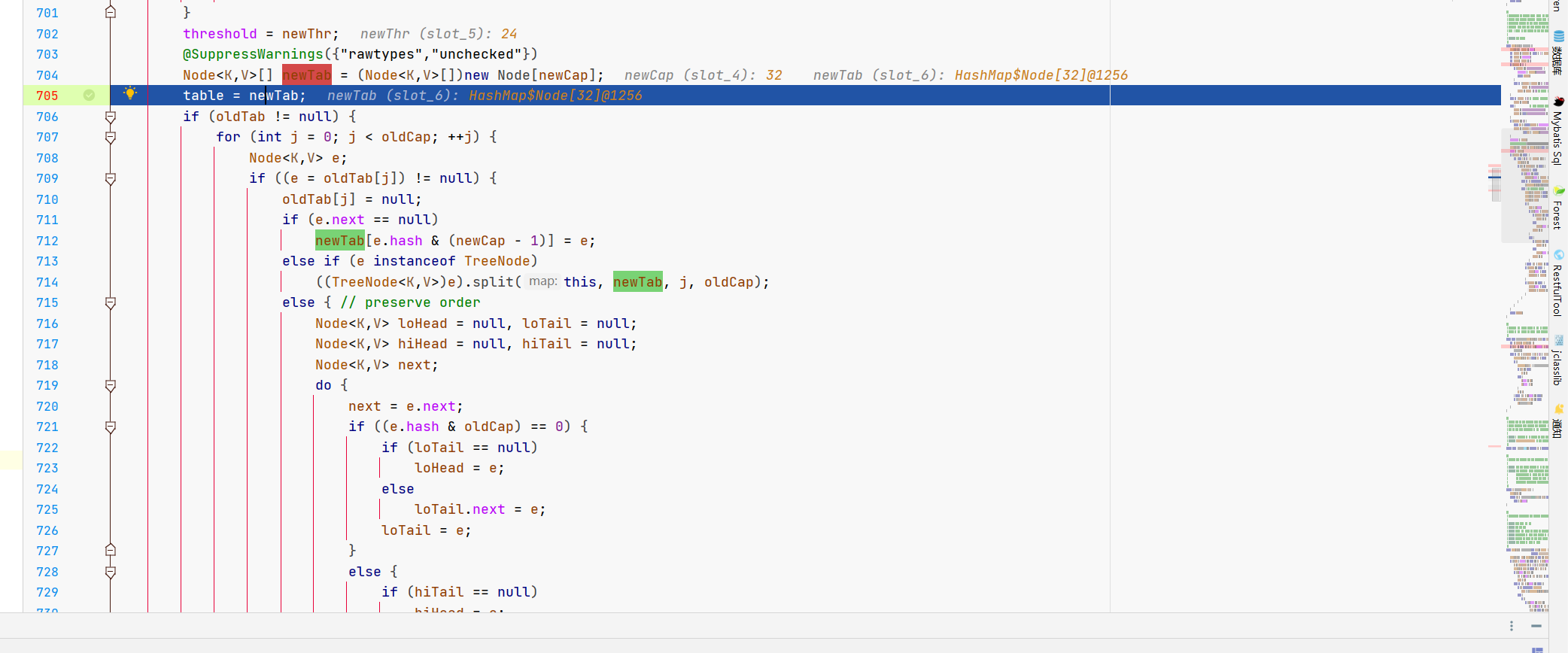
判断oldTab,旧哈希桶是不是null,然后就可以迁移了,先看大的这个for。
2.1 遍历哈希桶
这个简单呗,就是遍历咱们每个哈希桶,嗯,上面有可能是个链表,也有可能是个红黑树对吧?
先别管,你知道是在遍历哈希桶就行。


2.2 元素迁移

当前元素不为空的时候,我们赋值给e,然后清空下旧节点oldTab[j] = null(方便垃圾回收),然后分成了3种情况。
- 单个元素:if(e.next == null)
- 树形元素:else if (e instanceof TreeNode){
- 链表元素:else
2.2.1 单个元素
直接把当前的e挪过去
newTab[e.hash & (newCap - 1)] = e;
挪到哪个位置呢?
e.hash & (newCap - 1)
哎,你还记不记得第一次放置的时候,位置怎么算的?
p = tab[i = (n - 1) & hash]
// 即位置是
hash & (n - 1)
嗯?没变化是吧,不就是一样的嘛,只不过咱们是换成了新的newCap-1,这里的newCap不就是新容量嘛,跟数组长度-1一样的。
复制下前文的内容,为啥取模是(n-1)&hash看我这篇文章:Java-取模操作中的&和(length-1)、HashMap取模、HashMap扩容
2.3.2 链表元素
当链表节点被迁移到新的哈希桶时,核心逻辑是根据哈希值重新分配这些节点。
我们拆成3部分看。
- 部分1:定义链表,低位、高位。
- 部分2:填充高低位链表的具体元素
- 部分3:放置高低位链表到哈希桶的具体位置,低位不变还是原来的位置
j,高位放到新位置j+oldCap。

部分1,咱们为啥要区分高低位这么2个链表出来?
因为咱们的低位链表位置不用变,还是在哈希桶原来的位置。
好,你又想问为什么?建议看我这篇文章:Java-取模操作中的&和(length-1)、HashMap取模、HashMap扩容,看3.2节。

部分2,实际上就是在填充咱们的高低位的链表。
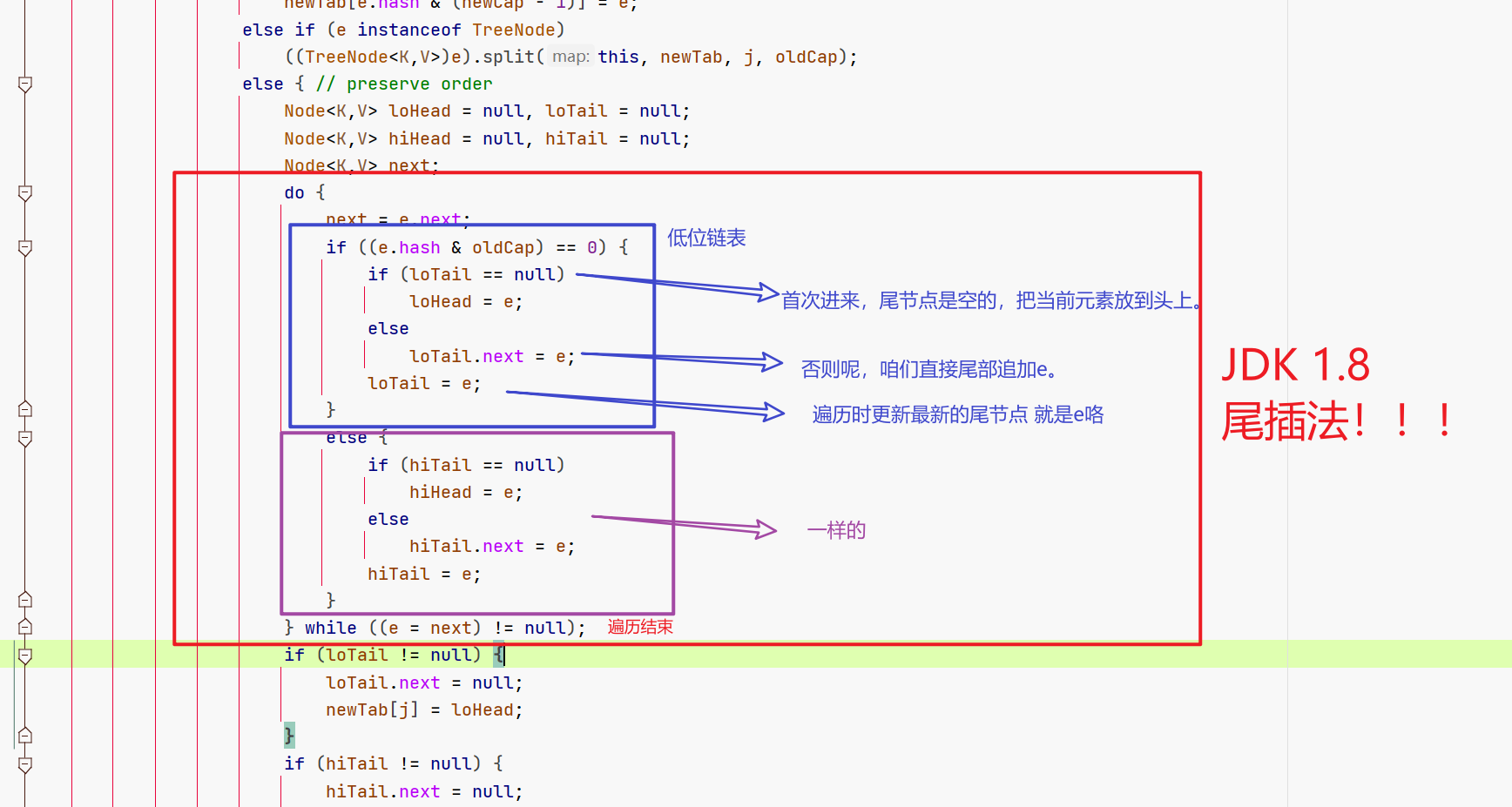
部分3,就是调整新链表的位置,低位链表不动,高位放新位置。

2.2.3 树形元素
树形元素呢,关键就是咱们的TreeNode的split方法。
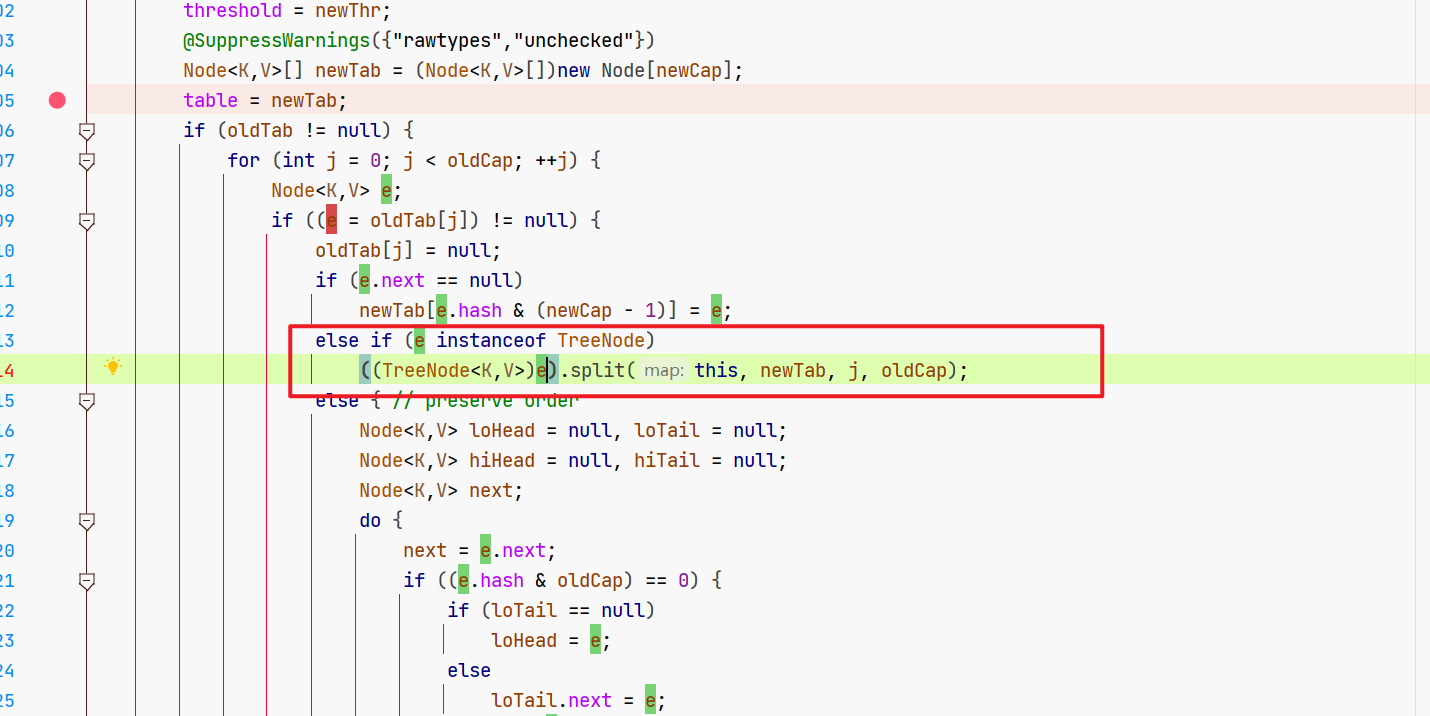
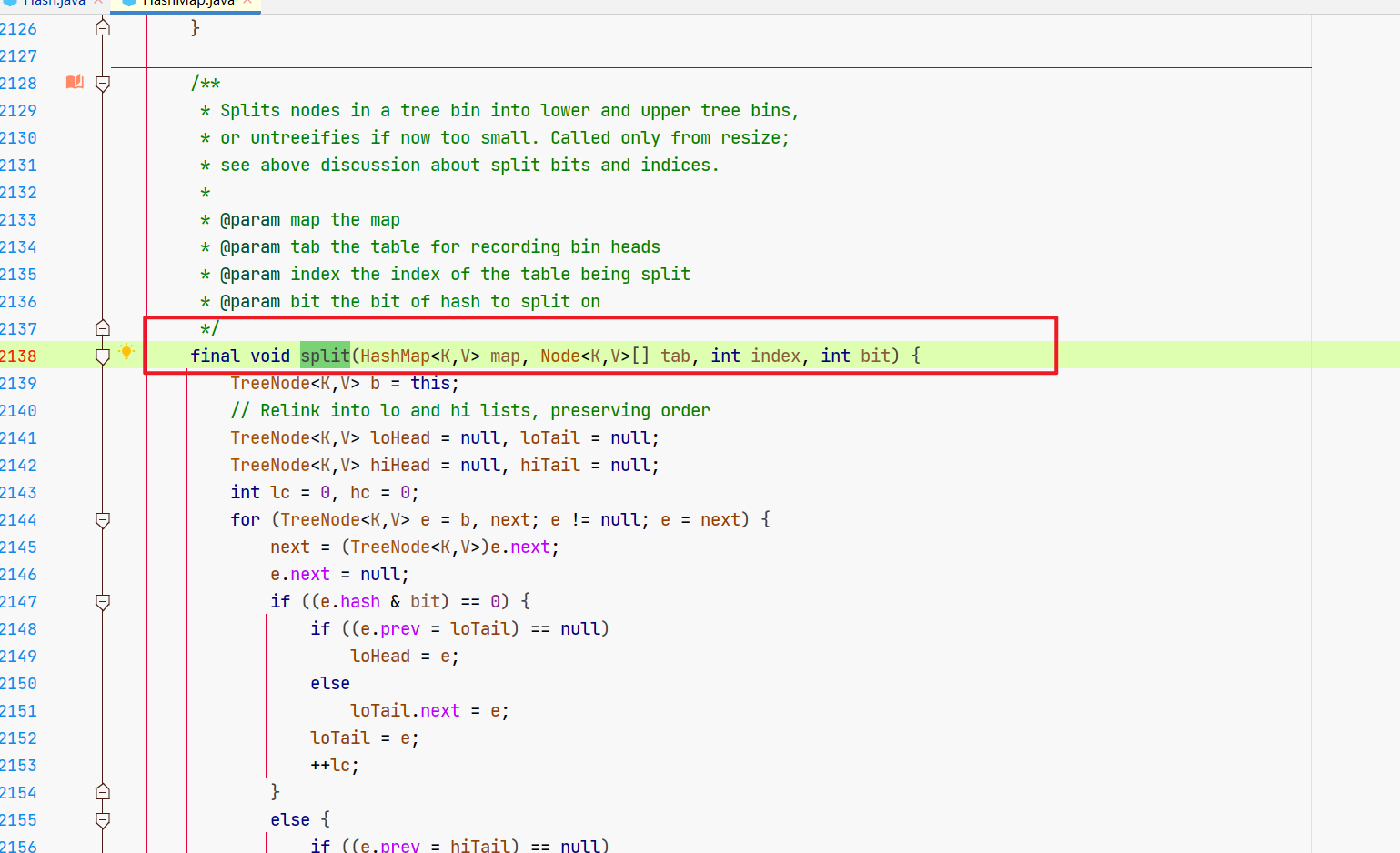
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
map: 当前 HashMap 实例。
tab: 新的哈希桶数组(即扩容后的哈希表)。
index: 当前节点在旧哈希表中的索引。
bit: 表示旧容量的最高位(额,就是旧容量嘛),用于判断节点是否应该放到新哈希表中的原索引位置,还是原索引加上旧容量的位置。
这里的核心逻辑是根据哈希值重新分配节点,咱们拆成3部分看。
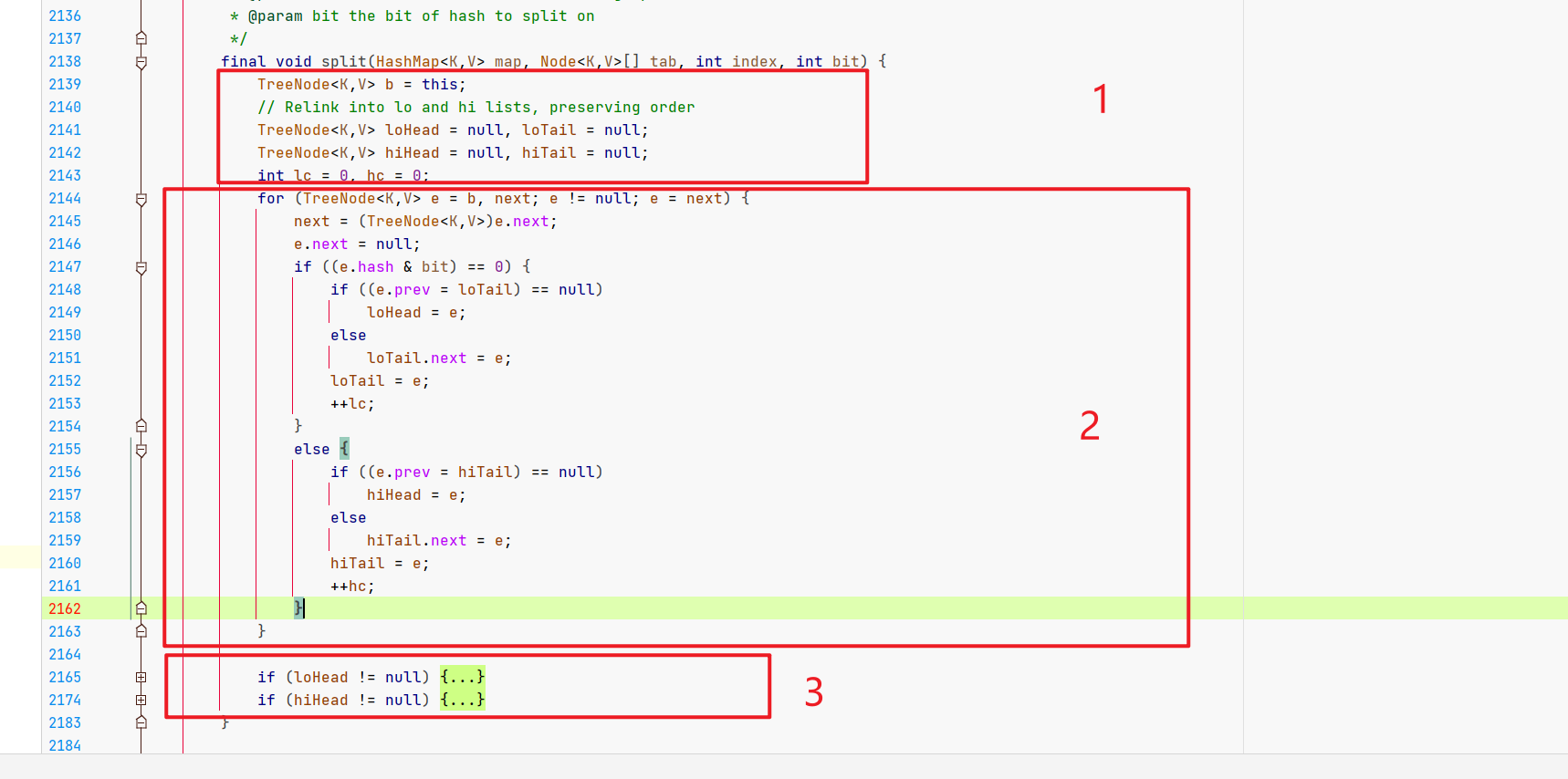
- 部分1:定义树节点(低位、高位),定义节点数量(低位、高位)。
- 部分2:填充高低位两个节点的的具体元素
- 部分3:根据高低位的树节点情况,重新分配元素位置。
部分1,定义高低位链表和存放数量等。
部分2,根据情况填充具体的元素。
好,你肯定疑惑,我这玩意不是叫treeNode吗?tree啊!它不应该是这样子吗?
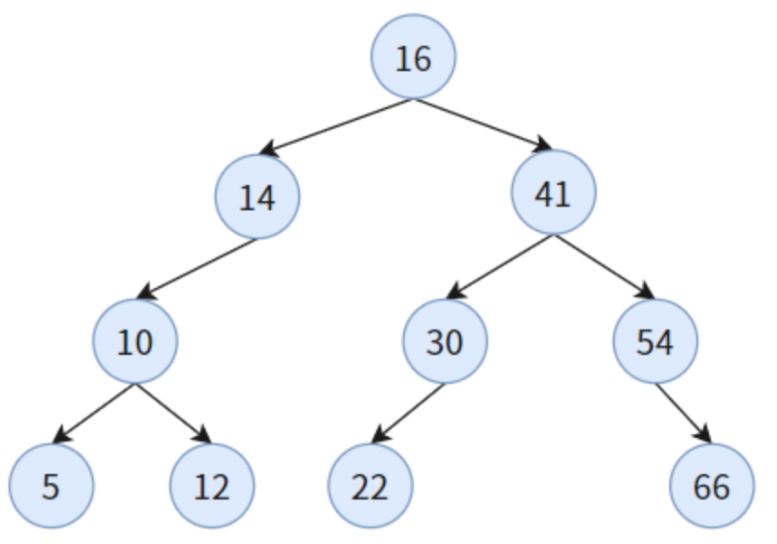
next?左还是右啊?你在next啥啊?
嗯,实际上呢,咱们的红黑树中,仍然保留了咱们的链表结构。
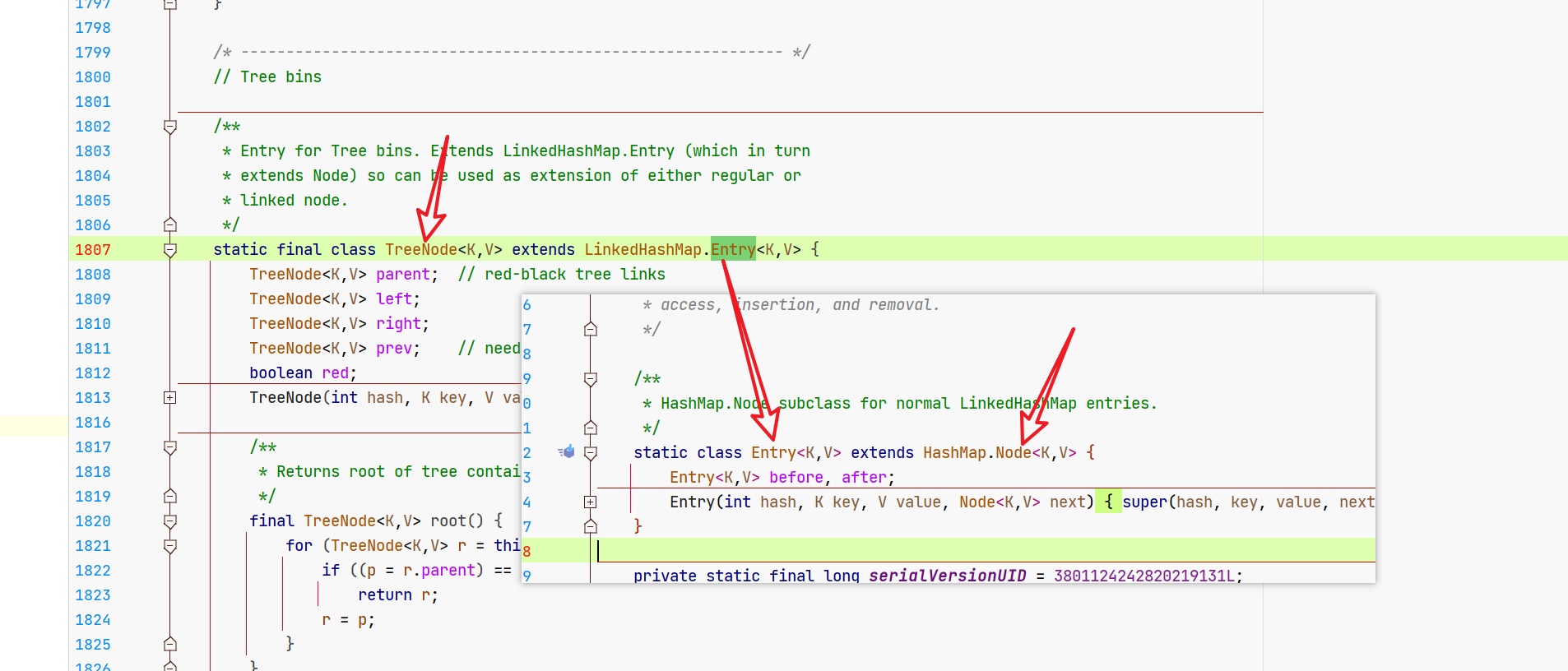
它还是Node吧?那你说咱们红黑树是不是链表转过去的?链表的时候有next属性吧?我不删除next是不是还在?能不能next?
嗯嗯嗯嗯嗯,能能能。我堂堂HashMap的TreeNode有两个形态怎么了。
所以咱们要学会换思维,next属性还在,咱们从链表的角度来看,它就是个链表。
我们用前面的例子演示下。
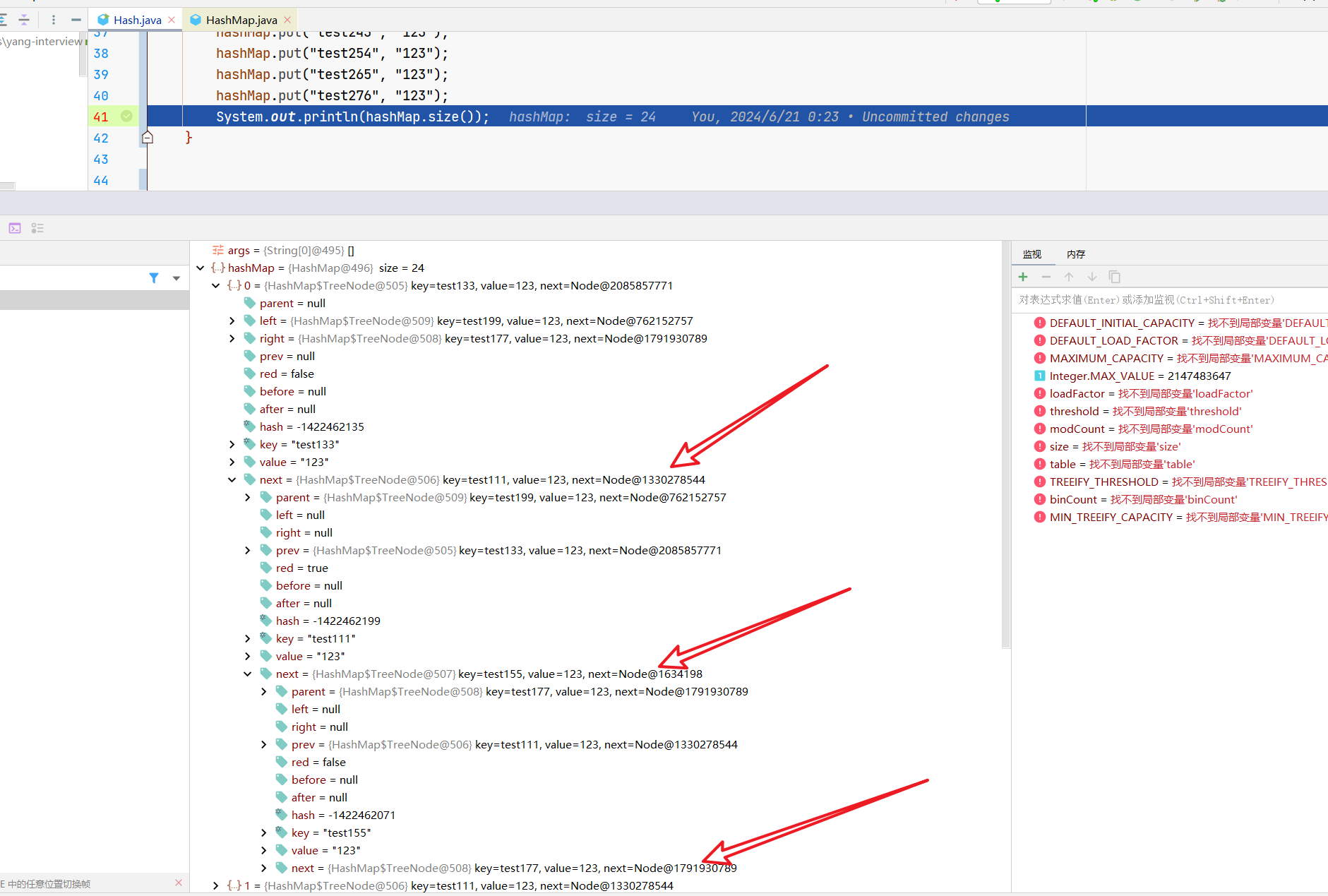
能next吧?没问题吧。
顺便提一句,为啥还是个双向链表,就是为了删除。假设删除m,找到m的prev很方便吧?把prev的next改成m的next没问题吧?
然后就是跟普通链表那里差不多的填充高低两个链表的值。
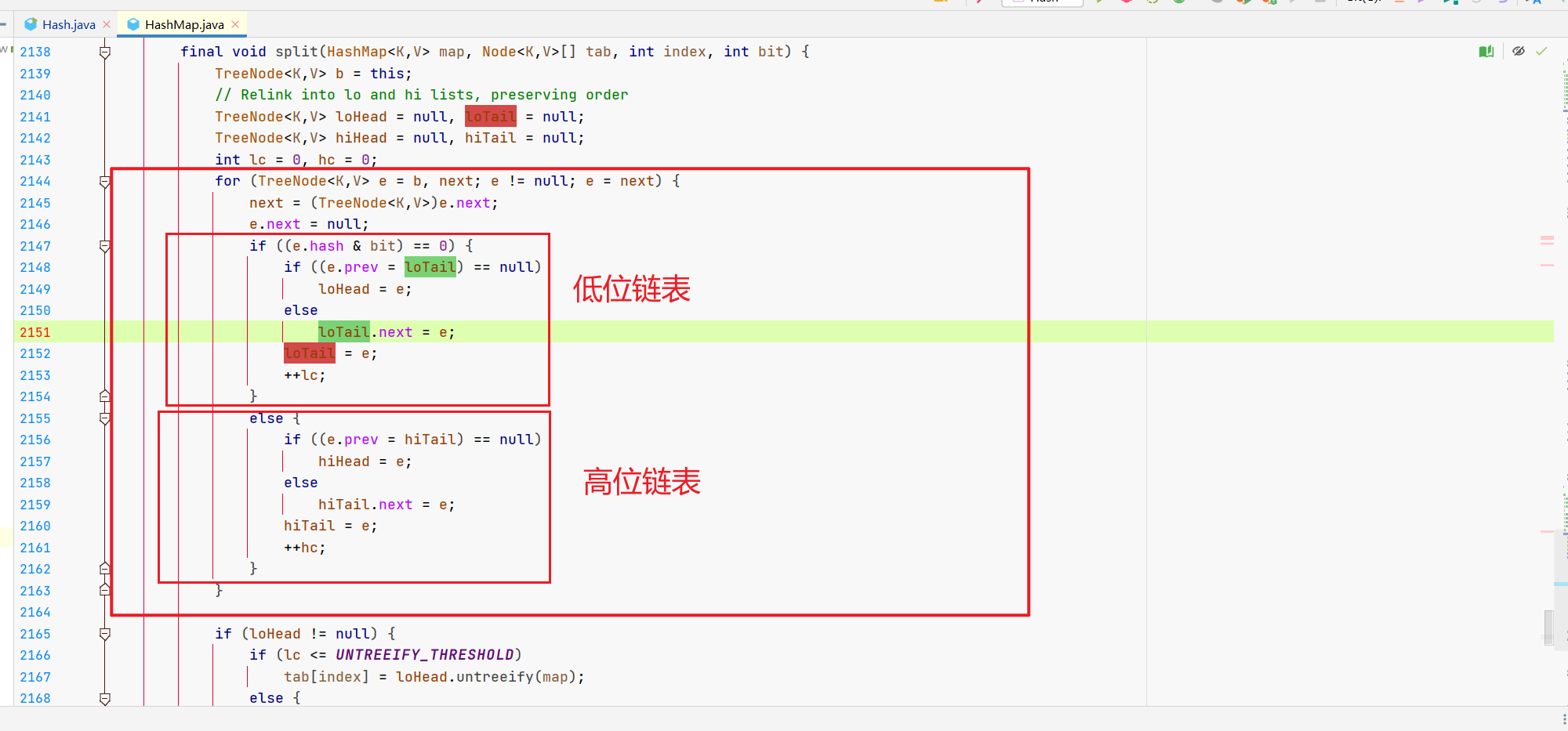
部分3,根据咱们高低位链表的情况,看存放时是否从红黑树退化成普通链表,这里JDK1.8默认的是6。

3.问题
3.1 链表转红黑树的触发条件
- 当前哈希桶上链表的节点
>=9,即放置第9个元素的时候,先放到链表上,再进行树化操作。 - 整个HashMap中哈希桶的数量
>=64
3.2 红黑树中的元素有上限吗?
红黑树本身没有固定的存储上限。
总体容量指的是桶的数量(即哈希桶的数量),而不是所有元素的数量。
HashMap 的整体存储容量由容量和负载因子(默认 0.75)共同决定,即桶数量和扩容阈值。
当 HashMap 中的元素数量超过扩容阈值时,会触发扩容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号