Redis-5-高可用
Redis高可用
高可用性(High Availability,HA)主要是为了确保系统在面对故障、负载变化等情况下仍能持续提供服务。
HA场景下,主要是解决这些问题。
| 问题 | 问题描述 | 解决方案 |
|---|---|---|
| 单点故障 | 如果只有一个 Redis 实例,当它发生故障时,整个系统将无法访问缓存数据,导致服务中断。 | 通过主从复制和哨兵机制,确保在主节点故障时可以快速切换到从节点,保持服务可用性。 |
| 数据丢失 | 在节点故障或系统崩溃时,数据可能会丢失,导致系统无法恢复到最新状态。 | 通过主从复制和持久化机制(如 RDB 和 AOF),保证数据在多个节点上有副本,降低数据丢失的风险。 |
| 负载均衡 | 单个 Redis 实例的性能有限,在高并发访问时可能成为瓶颈。 | 通过主从复制实现读写分离,从节点分担读负载;通过集群机制将数据分片到多个节点上,分散负载。 |
| 自动故障恢复 | 当节点故障时,如果需要人工介入进行恢复,将增加系统停机时间。 | 通过哨兵机制实现自动故障检测和转移,减少人工干预,快速恢复服务。 |
| 扩展性 | 随着数据量和访问量的增长,单个节点无法满足需求,需要增加更多的节点来扩展系统容量和性能。 | 通过集群机制,支持横向扩展,可以动态添加或移除节点,适应业务增长需求。 |
Redis中,针对高可用场景,主要有以下3个模式。
| 机制 | 描述 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 主从复制 | 数据从主节点复制到一个或多个从节点 | 读写分离,提高性能 数据冗余,提高可用性和安全性 |
单点故障,需要手动故障转移。 | 需要读写分离,提高读性能的场景 |
| 哨兵 (Sentinel) | 监控 Redis 实例,自动进行故障转移 | 自动化故障检测和转移 扩展性强,管理多个实例 |
配置复杂 网络分区可能导致脑裂问题 |
读多写少的场景 需要高可用性和自动故障转移的场景 |
| 集群 (Cluster) | 数据自动分片和复制,支持分布式存储 | 高可用性,通过主从复制和自动故障转移 高扩展性,支持横向扩展 |
配置和管理复杂 对网络要求高 |
大规模分布式存储需求,需高可用和扩展性 |
然后,注意下redis服务的启动方式,免得你看到后文配置时范懵。
咱们的redis-server,如果有配置文件,会从配置文件中读取值,同时,也支持启动的时候命令中传入参数。
同时存在的时候,命令行参数优先。比如配置文件里和命令行都声明了port,以命令行的为准。
正常情况下,我们直接跟上配置文件地址就行了。
redis-server /path/to/redis.conf
想要额外参数,也可以自己传入。
redis-server /path/to/redis.conf --port 6380
最后,不要纠结配置文件的名字。
记得我最开始学代码的时候,经常看到说,某某组件的必须要声明一个xx的配置文件。
其实,必须要xx名字,只是因为那个组件规定了些默认名字来读取。
redis这里没有这么复杂,我们只要能传进去合法的配置文件,redis就能正常启动。
redis-server /path/to/master.conf
redis-server /path/to/slave.conf
我们可以推测,redis这里是怎么处理的。
- 参数是个list,找到
.conf结尾的,认为是个配置文件,将其进行加载。 - 其余参数,覆盖配置文件中的参数。
那我传了两个conf进去呢?简单的方式就是直接忽略掉后面的,那我不忽略也可以,我覆盖前面重复的项。
每个人代码风格不一样,对读取配置时的思路不一样,仅此而已。
我特意写这么一点,是怕误导你,也是救赎下曾经的自己,陷在各种奇怪的问题上。
怕你以为,主从啊,它的从节点配置文件名必须是slave.conf,没有这个规定,slave666.conf也没问题。
1.1 主从复制
主从复制是 Redis 高可用性的基础,通过复制机制,数据可以从主节点(Master)复制到一个或多个从节点(Slave)。
当主节点发生故障时,从节点可以作为备份数据源,并且可以提升为新的主节点。
1.1.1 实现
首先,显然生产环境是不能单机跑的,宕机了就GG,那么必然是需要2个以上的Redis做冗余的,最简单的方式,就是两个机器同时跑。
同时跑的时候,存在几个基本问题。
- 数据一致性:只在主节点写数据,然后从节点只同步数据,这样数据就不会混乱。
- 单点故障:手动重新选取一个节点当master
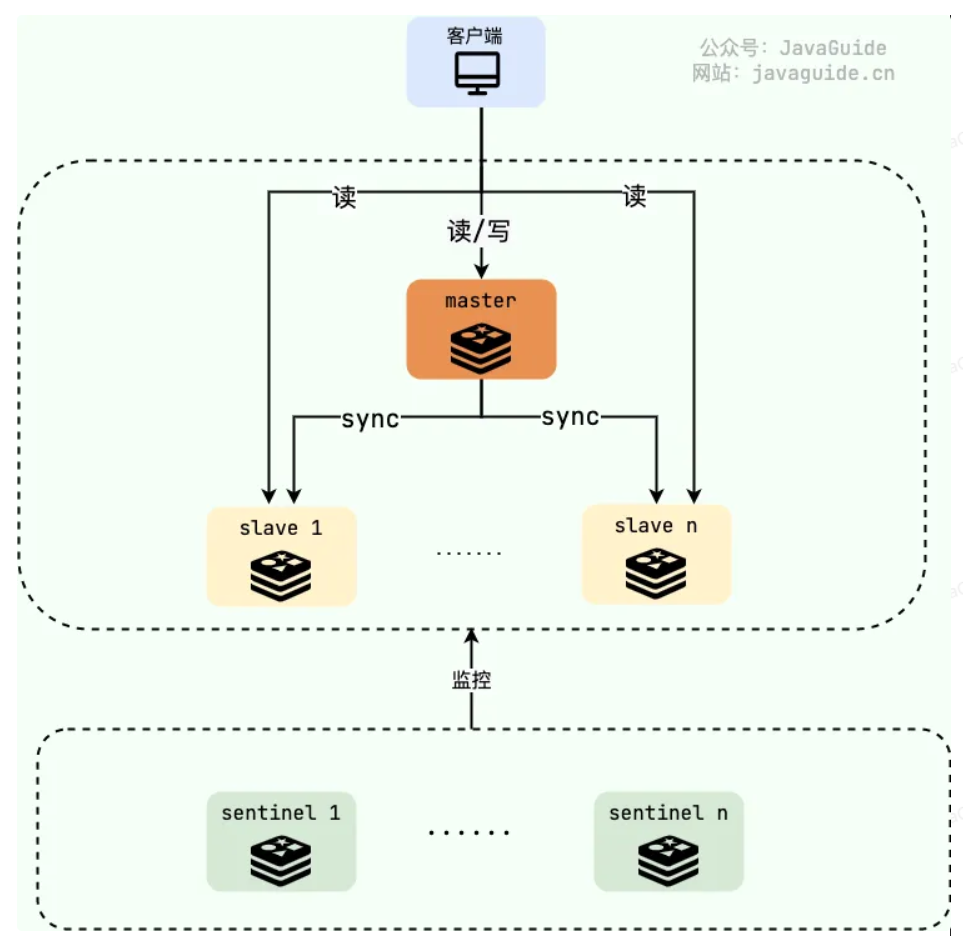
主从模式的运行图示如下,注意图中的主(master)从(slave)节点。
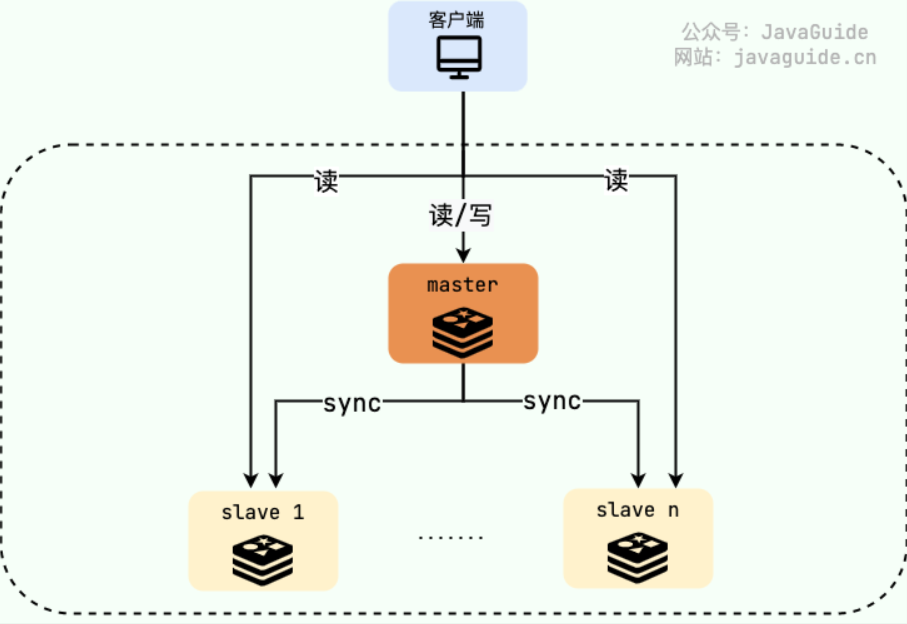
- 主节点(master):读/写
- 从节点(replica):只读
1.1.2 配置(1主1从)
下方演示一个1主1从的配置。
| 类型 | 端口 | 说明 |
|---|---|---|
| master | 6379 | redis主节点 |
| slave | 6380 | redis从节点 |
1. 配置主节点
主节点不需要特殊的配置,只需启动一个 Redis 实例即可。
# 配置文件为/etc/redis/redis.conf
# 启动主节点
redis-server /etc/redis/redis.conf
2. 配置从节点
2.1 配置文件
从节点需要配置对应的主节点。
编辑从节点的配置文件 redis.conf,添加以下配置,基本配置如下。
# 从节点配置目标主节点
replicaof 192.168.1.100 6379
# 如果主节点设置了密码,还需要在从节点配置文件中添加以下配置
masterauth password
启动从节点
redis-server /path/to/your/slave-redis.conf
2.2 命令方式
命令行是一次性的喔,重启就失效了,只是列一下。
连接到从节点
redis-cli -h <slave-ip> -p <slave-port>
在 Redis CLI 中执行以下命令配置从节点:
SLAVEOF 192.168.1.100 6379
CONFIG SET masterauth your-master-password
3.验证主从复制配置
连接到主节点和从节点,分别执行以下命令验证配置。
3.1 主节点
INFO replication
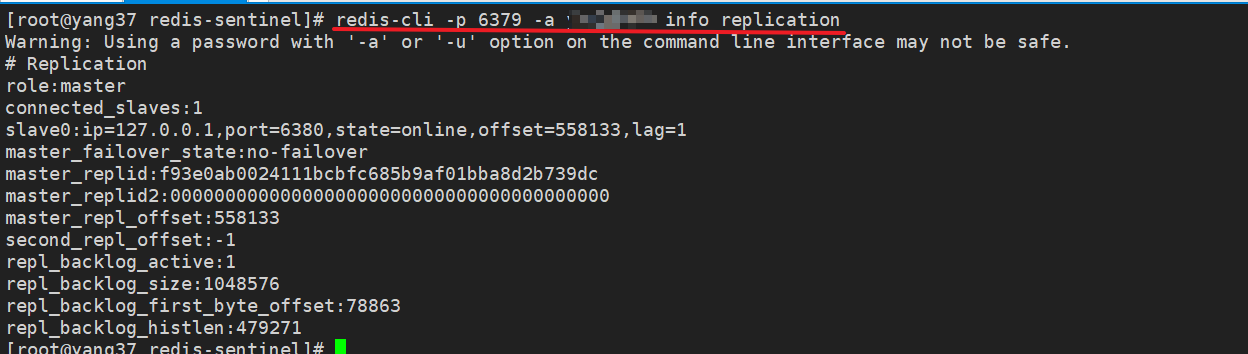
输出类似以下内容,表明主节点配置正确:
# Replication
# 角色为master
role:master
connected_slaves:1
slave0:ip=<slave-ip>,port=<slave-port>,state=online,offset=12345,lag=0
3.2 从节点
INFO replication
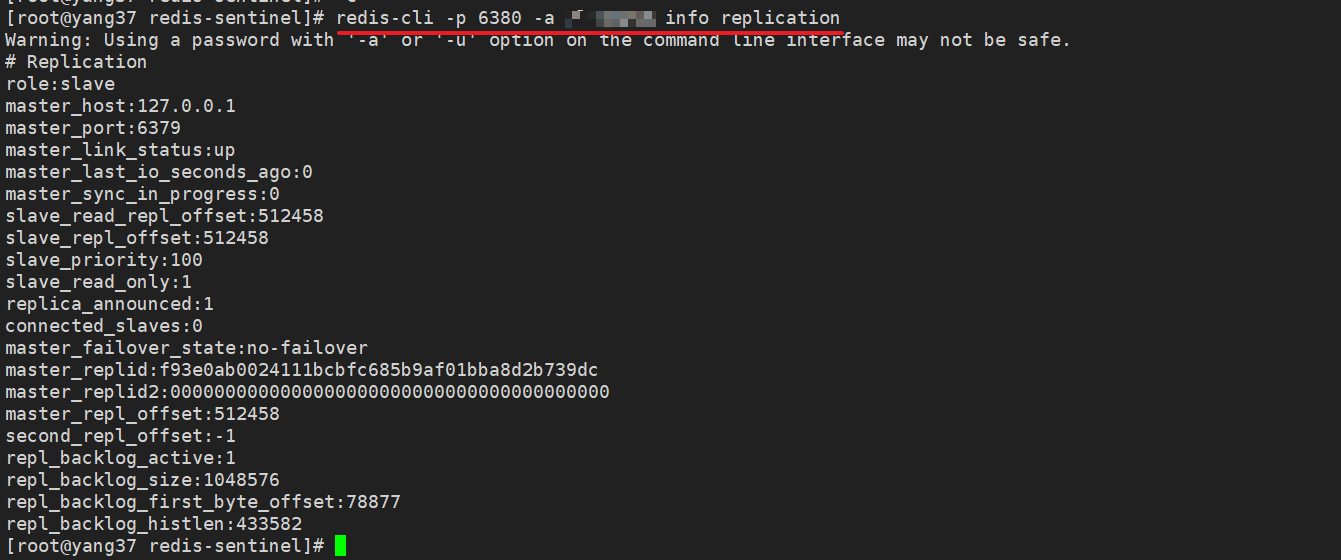
输出类似以下内容,表明从节点配置正确:
# Replication
# 角色为slave
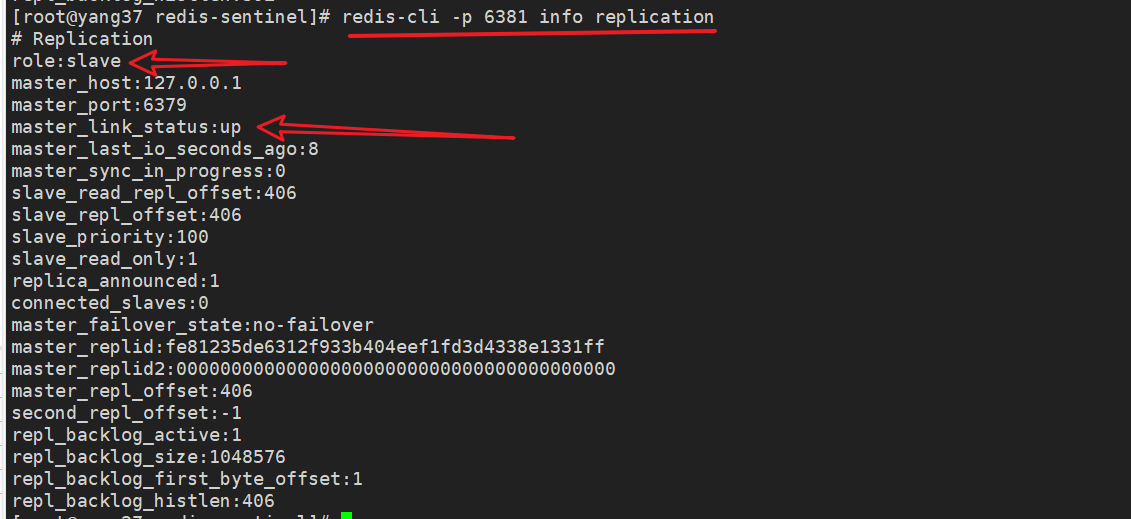
role:slave
master_host:192.168.1.100
master_port:6379
# 主节点状态up
master_link_status:up
3.3 直接查看
或者直接传入命令查看
# 6379 主节点
redis-cli -p 6379 -a 密码 info replication
# 6380 从节点
redis-cli -p 6380 -a 密码 info replication
4. 其他配置选项
可以根据需求配置一些高级选项,例如复制延迟、心跳间隔等:
repl-diskless-sync no # 是否使用无盘复制
repl-diskless-sync-delay 5 # 无盘复制延迟
repl-ping-slave-period 10 # 从节点向主节点发送 PING 命令的间隔
repl-timeout 60 # 复制超时时间
1.1.3 问题点
1.主从模式的数据同步方式
1.1 全量数据同步-SYNC
Redis 在 2.8 版本之前都是基于 SYNC 命令执行全量同步。
SYNC 命令的格式非常简单,没有参数,直接发送 SYNC 即可。
SYNC
简单来说,就是:
- slave加入后,找mater节点要RDB文件。
- master节点构建RDB文件(构建期间新增的数据,写在复制缓冲区中)
- slave收到RDB文件,重建缓存信息。
- master节点将复制缓冲区的数据同步给slave节点。
- 配置完成后,master和slave之间会保持持续的连接和同步,主节点的写命令会实时传送到从节点。
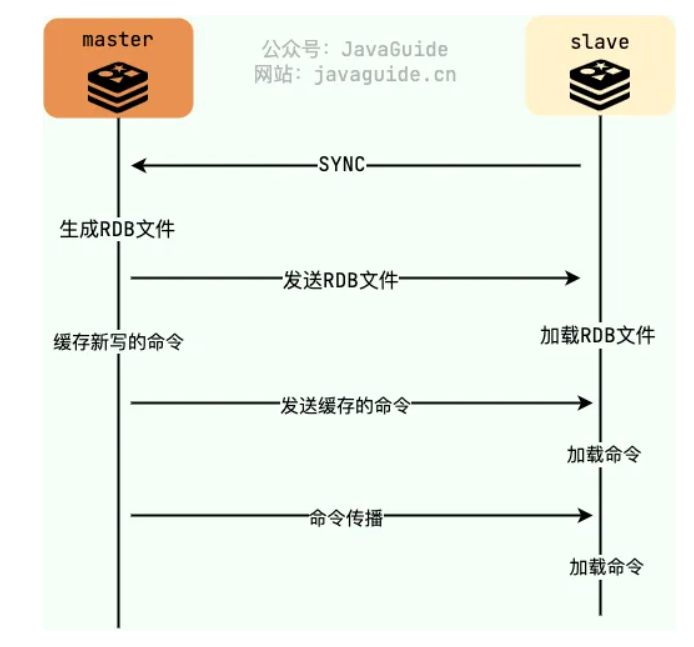
现在有个问题,master节点在收到从节点的同步请求后,会构建rdb文件,这个构建期间的命令怎么办?
master 为每一个 slave 单独开辟一块replication buffer(复制缓存区)来记录 RDB 文件生成后 master 收到的所有写命令。
当 RDB 文件传输完成并从节点加载后,主节点会将复制缓冲区中的所有写命令发送给从节点。
关于这个复制缓冲区,常见的配置如下:
client-output-buffer-limit <client-type> <hard-limit> <soft-limit> <soft-seconds>
# <client-type>:客户端类型,可以是 normal、replica 或 pubsub。
# <hard-limit>:硬限制,客户端的输出缓冲区大小达到此值时,连接将立即被断开。
# <soft-limit> 和 <soft-seconds>:软限制,客户端的输出缓冲区在 soft-seconds 秒内超过此值时,连接将被断开。
例如:
# 这个配置表示普通客户端的输出缓冲区没有任何限制,不会因为输出缓冲区过大而被断开。
client-output-buffer-limit normal 0 0 0
# normal:普通客户端(非复制客户端和非发布/订阅客户端)。
# 硬限制:0,表示不设硬限制。
# 软限制:0,表示不设软限制。
# 软秒数:0,表示不设软限制时间。
# 这个配置表示复制客户端的输出缓冲区有 256MB 的硬限制和 64MB/60秒的软限制。
client-output-buffer-limit replica 256mb 64mb 60
# replica:复制客户端(从节点)。
# 硬限制:256mb,如果复制客户端的输出缓冲区大小达到 256MB,连接将立即被断开。
# 软限制:64mb,如果复制客户端的输出缓冲区在 60 秒内超过 64MB,连接将被断开。
# 软秒数:60,软限制时间为 60 秒。
# 这个配置表示发布/订阅客户端的输出缓冲区有 32MB 的硬限制和 8MB/60秒的软限制
client-output-buffer-limit pubsub 32mb 8mb 60
# pubsub:发布/订阅客户端。
# 硬限制:32mb,如果发布/订阅客户端的输出缓冲区大小达到 32MB,连接将立即被断开。
# 软限制:8mb,如果发布/订阅客户端的输出缓冲区在 60 秒内超过 8MB,连接将被断开。
# 软秒数:60,软限制时间为 60 秒。
SYNC存在如下问题:
- slave 加载 RDB 的过程中不能对外提供读服务。
- slave 和 master 断开连接之后(本来master一直发命令给slave就好了),slave重新连上master需要重新进行全量同步。
1.2 增量同步-PSYNC
上面提到,命令传播的过程中,如果出现网络故障导致连接断开,此时新的写命令将无法同步到从库,slave重新连上master需要重新进行全量同步。
PSYNC 命令是 Redis 2.8 版本引入的一种用于主从复制的同步命令,解决了这个问题。
在从节点重新连接到主节点时,只会把断开的时候没有发生的写命令同步给从库,避免不必要的全量同步。
PSYNC <replicationid> <offset>
# <replicationid>:也叫runId,主节点的复制 ID(Replication ID),用于唯一标识主节点。
# <offset>:从节点的复制偏移量(Offset),表示从节点已经接收到的主节点数据的位置。
怎么解决断开后的同步问题呢?
-
master:记录自己写入缓冲区的偏移量(master_repl_offset),主库向从库发送 N 个字节的数据时,将自己的复制偏移量上加 N。
主节点会为每个从节点维护一个结构体(
replication),该结构体包含从节点的复制偏移量、连接状态等信息。 -
slave:记录 master 的runId和自己的复制进度(偏移量slave_repl_offset),从库接收到主库发送的 N 个字节数据时,将自己的复制偏移量加上 N。
当redis节点启动时,会生成一个唯一的 runid。
可以使用info命令查看。
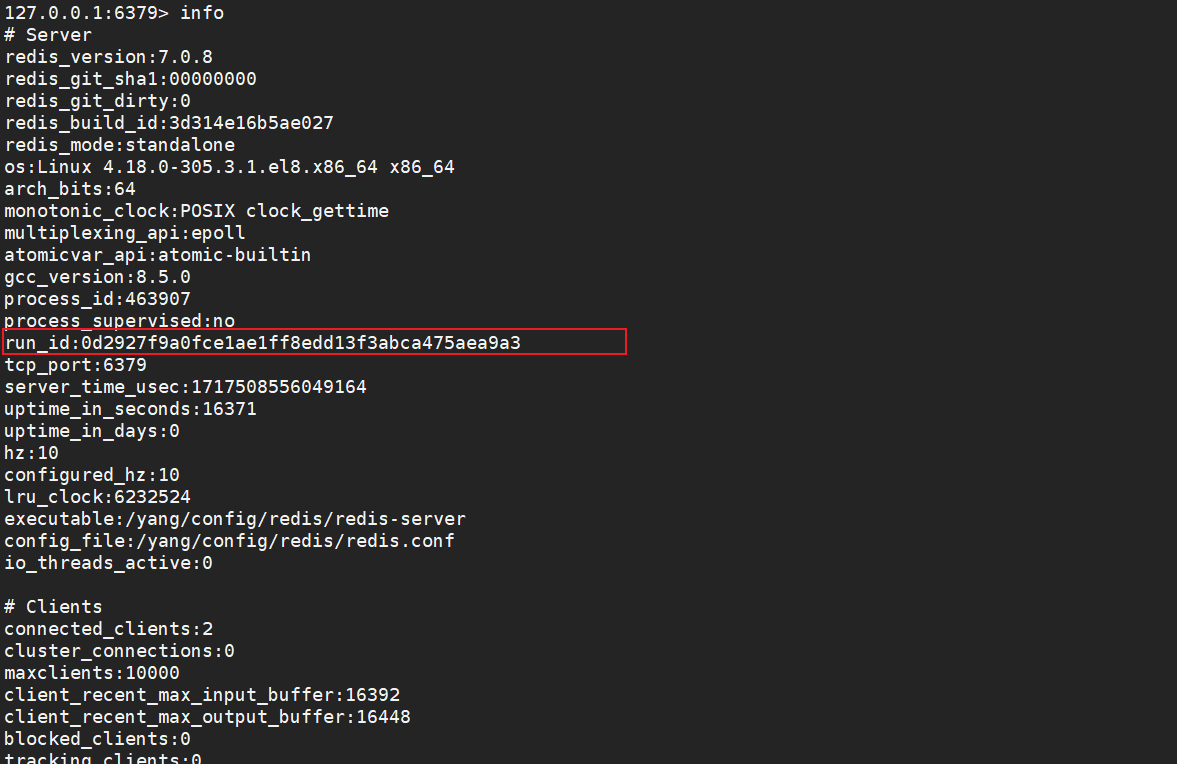
- 初次同步:当从节点首次连接到主节点时,会通过
PSYNC ? -1命令请求全量同步。主节点在响应中会返回其runid和当前的复制偏移量。 - 部分重同步
- 如果从节点与主节点的连接断开并重新连接,从节点会发送
PSYNC <replicationid> <offset>命令,其中replicationid是主节点的runid,offset是从节点最后接收到的复制偏移量。 - 主节点检查从节点提供的
replicationid是否与自己的runid匹配。如果匹配,则根据偏移量决定是否可以进行部分重同步。
- 如果从节点与主节点的连接断开并重新连接,从节点会发送
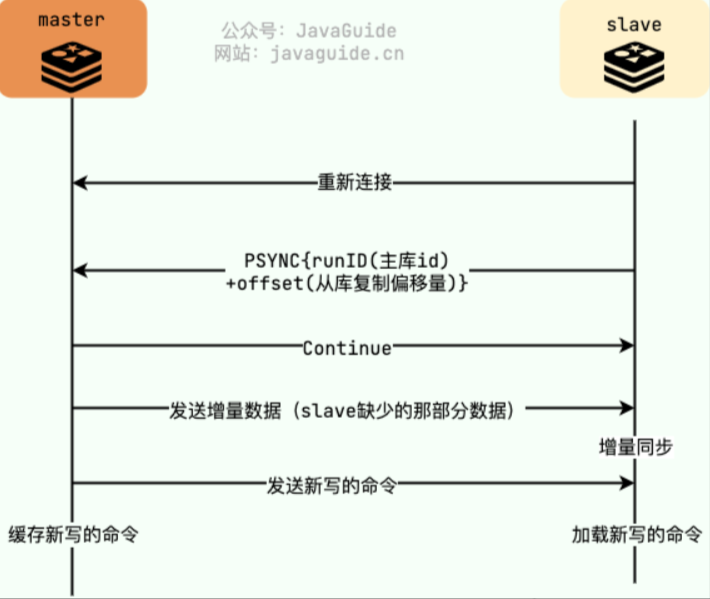
那么,怎么找到两个offset之间的数据呢?
复制缓冲区(Replication Backlog)
复制缓冲区也称之为环形缓冲区,是用于支持主从复制中的部分重同步(Partial Resynchronization)。
环形缓冲区在设计上是一个固定大小的数组,写操作以循环的方式存储在其中。
当缓冲区写满时,新写操作会覆盖旧的写操作,这样可以有效利用内存,并确保主节点可以保存最近一段时间内的写操作记录。
环形缓冲区相关配置:
repl-backlog-size 1mb # 设置复制缓冲区的大小
repl-backlog-ttl 3600 # 设置复制缓冲区的生存时间(秒)
PSYNC存在如下问题:
- 主从切换或者主节点宕机等,runid和offset这些发生变化,依然需要进行全量同步。
1.3 增量同步-PSYNC2.0
2.为什么主从全量复制使用 RDB 而不是 AOF?
Redis 在主从全量复制中使用 RDB 而不是 AOF 的主要原因在于 RDB 文件具有传输效率高、一致性好、恢复速度快和简单性高的优点。
尽管 AOF 在持久化方面具有优势,但在初次同步和全量复制的场景下,RDB 文件能够更高效地完成数据传输和同步过程。
因此,Redis 选择使用 RDB 文件进行主从全量复制,以确保高效和一致的数据同步。
3.主从复制下从节点会主动删除过期数据吗?
在 Redis 的主从复制机制下,从节点(slave)不会主动删除过期数据。过期数据的处理是由主节点(master)负责的,然后将删除操作同步给从节点。
但是,但是。
我们主节点设置10s后过期 -> 发送给从节点执行 -> 从节点设置10s后过期
从节点是收到数据报文后才执行的,是有可能比主节点晚一丢丢过期的。
这种场景,可以不考虑使用指定ttl时间的方式,改为使用这两个命令:
在指定时间过期,注意保持各节点时间一致。
- EXPIREAT
- PEXPIREAT
1.2 哨兵Sentinel
在主从模式的场景下,一旦 master 宕机,我们需要从 slave 中手动选择一个新的 master,同时需要修改应用方的主节点地址,整个过程需要人工干预,十分麻烦。
通过哨兵模式,可以解决这个自动恢复的问题。
在主节点故障时,系统能够自动提升一个从节点为新的主节点,并且其他从节点会自动重新配置为新主节点的从节点。
注意哦,哨兵模式是主从模式的升级,让哨兵来帮我们做一些事情,所以我们得先配置好主从。
然后呢,这里有几个注意的点,先列举下,后文详细讲。
- 哨兵的数量不一定要和redis服务的数量一样。比如3个哨兵看5个服务也是能行的。
- 哨兵的数量最好为单数。1个哨兵肯定也是不合适的,加上单数的建议,所以一般最低3个。
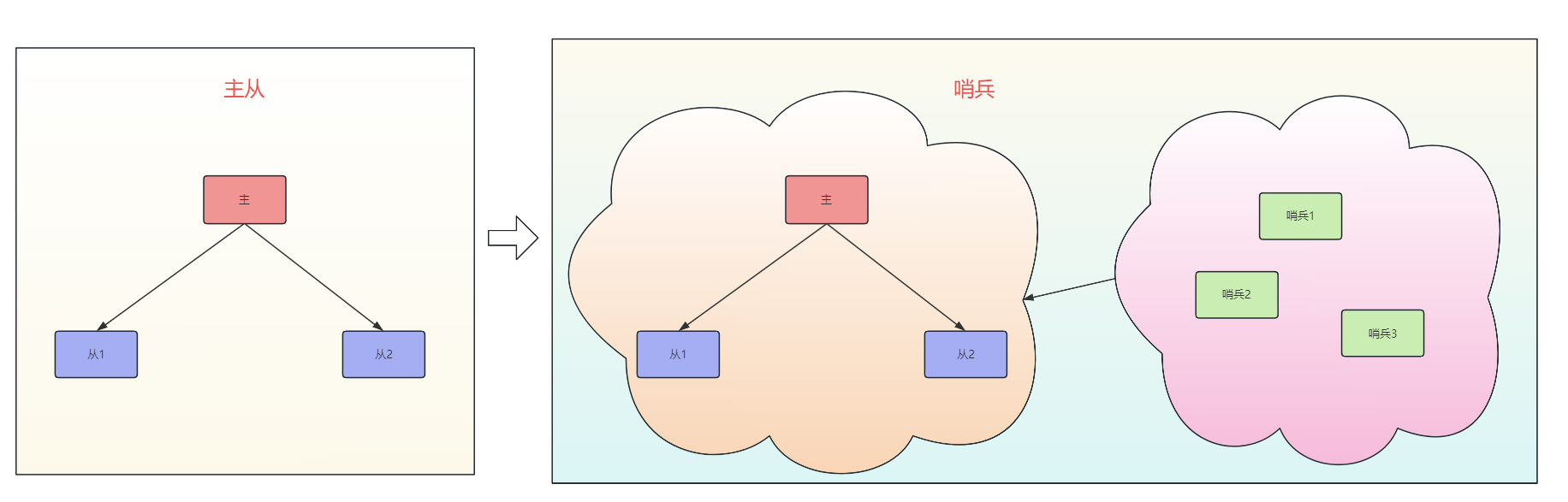
1.2.1 实现
Sentinel 是一个独立于 Redis 服务器的进程,可以在不同的主机上运行。
查看我们redis安装后的可执行文件,可以发现,除了redis-server、redis-cli这些之外,还有一个redis-sentinel。
| 进程名 | 解释 | 默认端口 | 用处 |
|---|---|---|---|
| redis-server | Redis 服务器进程,负责存储和管理数据 | 6379 | 主要用于处理客户端请求,执行数据存储和查询操作 |
| redis-cli | Redis 命令行客户端,用于与 Redis 服务器交互 | N/A | 用于手动管理和操作 Redis 数据库,执行各种 Redis 命令 |
| redis-sentinel | Redis Sentinel 进程,监控和管理 Redis 集群 | 26379 | 监控 Redis 服务器的状态,自动进行故障转移,确保高可用性 |
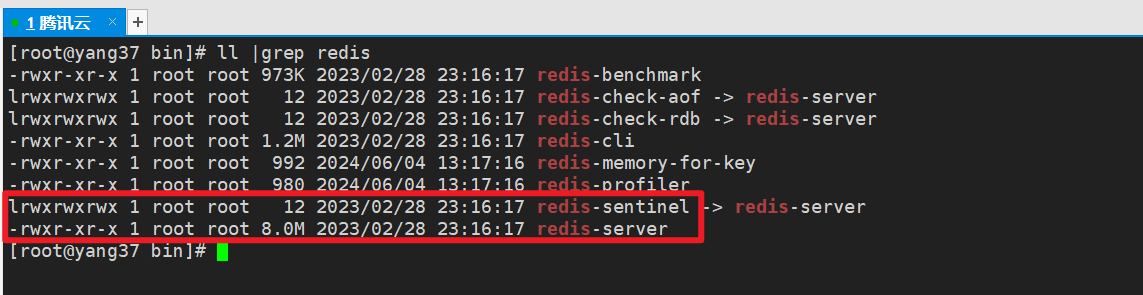
哨兵模式,基本实现如下,sentinel 程序用于监控各个redis服务的状态,基本功能如下:
- 监控:监控所有 redis 节点(包括 sentinel 节点自身)的状态是否正常。
- 故障转移:如果一个 master 出现故障,sentinel 会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。
- 通知 :通知 slave 新的 master 连接信息,让它们执行 replicaof 成为新的 master 的 slave。
- 配置提供 :客户端连接 sentinel 请求 master 的地址,如果发生故障转移,sentinel 会通知新的 master 链接信息给客户端。
1.2.2 配置(1主2从3哨兵)
下方演示一个1主2从3哨兵的配置。
| 类型 | 端口 | 配置文件 | 日志文件 | 说明 |
|---|---|---|---|---|
| master | 6379 | redis1.conf | redis1.log | redis主节点 |
| slave1 | 6380 | redis2.conf | redis2.log | redis从节点1 |
| slave2 | 6381 | redis3.conf | redis3.log | redis从节点2 |
| sentinel1 | 26379 | sentinel1.conf | sentinel1.log | 哨兵1 |
| sentinel2 | 26380 | sentinel2.conf | sentinel2.log | 哨兵2 |
| sentinel3 | 26381 | sentinel3.conf | sentinel3.log | 哨兵3 |
上述文件,位于/yang/config/redis-sentinel目录。
redis1、2、3用于存放redis的持久化文件,此处不用关注。
1.配置主从
参考上节主从复制的配置,主要是从节点上要配置主节点的信息。
1.1 主节点配置
# 运行端口
port 6379
# 以后台模式运行
daemonize yes
# 日志文件
logfile "/yang/config/redis-sentinel/redis1.log"
# 数据存储目录
dir "/yang/config/redis-sentinel/redis1"
1.2 从节点1配置
# 运行端口
port 6380
# 以后台模式运行
daemonize yes
# 从节点配置目标主节点
replicaof 127.0.0.1 6379
# 日志文件
logfile "/yang/config/redis-sentinel/redis2.log"
# 数据存储目录
dir "/yang/config/redis-sentinel/redis2"
# 如果主节点设置了密码,还需要在从节点配置文件中添加以下配置
# masterauth password
1.2 从节点2配置
# 运行端口
port 6381
# 以后台模式运行
daemonize yes
# 从节点配置目标主节点
replicaof 127.0.0.1 6379
# 日志文件
logfile "/yang/config/redis-sentinel/redis3.log"
# 数据存储目录
dir "/yang/config/redis-sentinel/redis3"
# 如果主节点设置了密码,还需要在从节点配置文件中添加以下配置
# masterauth password
2.配置哨兵
为每个 Sentinel 实例创建一个配置文件,主要是配置监控的主节点信息。
哨兵不需要配置从节点的信息,当 Sentinel 监控一个主节点时,它会自动发现与该主节点相关联的从节点。
节点的信息通过 Redis 内部的发布/订阅机制和 Sentinel 特有的协议进行传播,因此不需要在 Sentinel 配置文件中手动指定从节点。
2.1 哨兵1配置
# 哨兵运行端口
port 26379
# 以后台模式运行
daemonize yes
# 指定 Sentinel 的日志文件
logfile "/yang/config/redis-sentinel/sentinel1.log"
# 监控的主节点名称为 mymaster,地址为 127.0.0.1:6379,至少需要 2 个 Sentinel 同意认为主节点失效,才会进行故障转移
sentinel monitor mymaster 127.0.0.1 6379 2
# 主节点若配置了密码
# sentinel auth-pass mymaster xxx
# 主节点失效的判断时间(毫秒)
sentinel down-after-milliseconds mymaster 5000
# 故障转移超时时间(毫秒)
sentinel failover-timeout mymaster 60000
# 故障转移时同步的从节点数量
sentinel parallel-syncs mymaster 1
这里最后的parallel-syncs咋理解馁?
当主节点出现故障时,哨兵会进行故障转移,将一个从节点提升为新的主节点。其他从节点需要同步新的主节点的数据。
如果配置为 sentinel parallel-syncs mymaster 1,则:
-
哨兵会首先提升一个从节点为新的主节点。
-
其他从节点会按顺序一个一个地与新的主节点进行同步。
-
每次只有一个从节点与新的主节点同步。
同理,配置2就是同时2个,配置大了,不把你的主节点干懵啊。
2.2 哨兵2配置
# 哨兵运行端口
port 26380
# 以后台模式运行
daemonize yes
# 指定 Sentinel 的日志文件
logfile "/yang/config/redis-sentinel/sentinel2.log"
# 监控的主节点名称为 mymaster,地址为 127.0.0.1:6379,至少需要 2 个 Sentinel 同意认为主节点失效,才会进行故障转移
sentinel monitor mymaster 127.0.0.1 6379 2
# 主节点若配置了密码
# sentinel auth-pass mymaster xxx
# 主节点失效的判断时间(毫秒)
sentinel down-after-milliseconds mymaster 5000
# 故障转移超时时间(毫秒)
sentinel failover-timeout mymaster 60000
# 故障转移时同步的从节点数量
sentinel parallel-syncs mymaster 1
2.3 哨兵3配置
# 哨兵运行端口
port 26381
# 以后台模式运行
daemonize yes
# 指定 Sentinel 的日志文件
logfile "/yang/config/redis-sentinel/sentinel3.log"
# 监控的主节点名称为 mymaster,地址为 127.0.0.1:6379,至少需要 2 个 Sentinel 同意认为主节点失效,才会进行故障转移
sentinel monitor mymaster 127.0.0.1 6379 2
# 主节点若配置了密码
# sentinel auth-pass mymaster xxx
# 主节点失效的判断时间(毫秒)
sentinel down-after-milliseconds mymaster 5000
# 故障转移超时时间(毫秒)
sentinel failover-timeout mymaster 60000
# 故障转移时同步的从节点数量
sentinel parallel-syncs mymaster 1
3.启动主从
启动主从的redis服务。
redis-server redis1.conf
redis-server redis2.conf
redis-server redis3.conf

3.1 主节点日志
3.2 从节点1日志
3.3 从节点2日志
4.检查主从
当然咯,也可以结合主从配置那节讲的,检查一下。
4.1 主节点
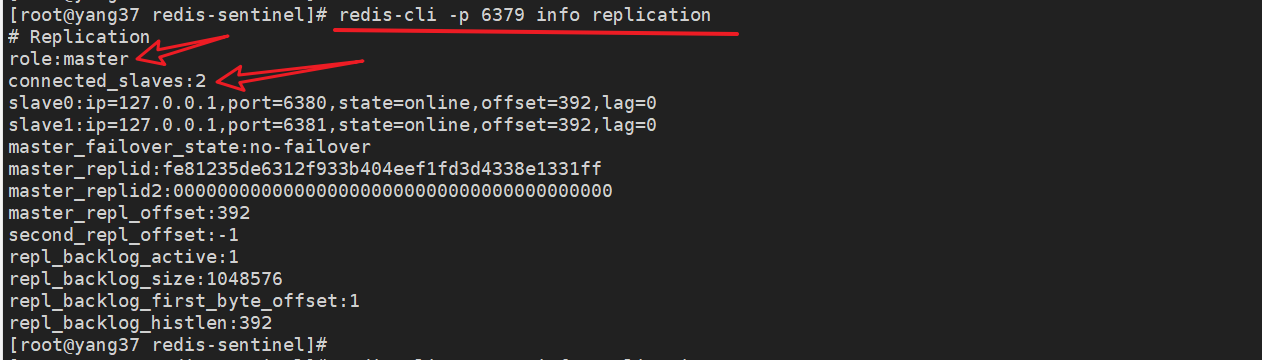
4.2 从节点1
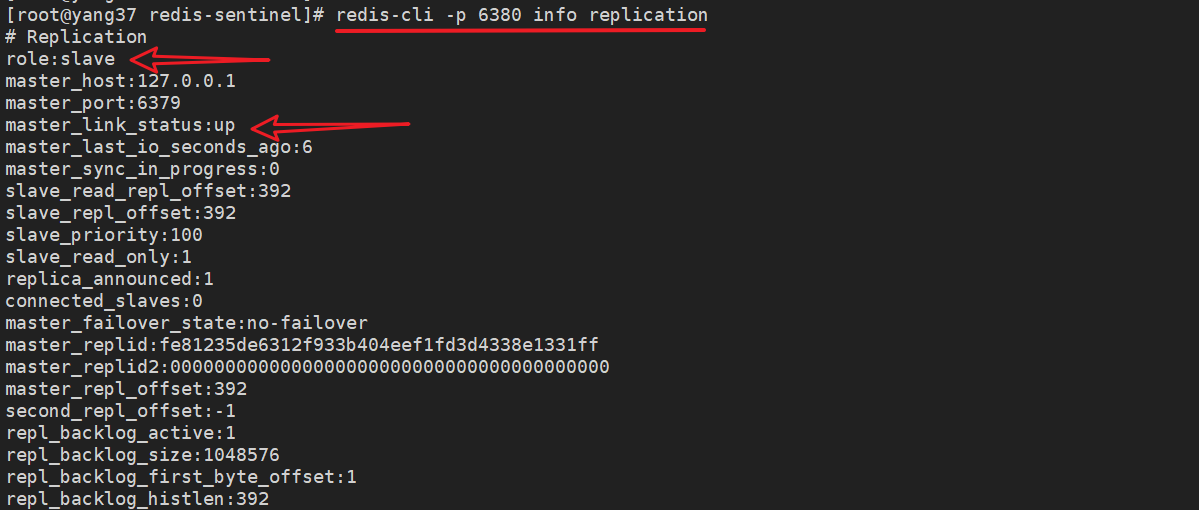
4.3 从节点2
5.启动哨兵
redis-sentinel sentinel1.conf
redis-sentinel sentinel2.conf
redis-sentinel sentinel3.conf

5.1 哨兵1启动日志
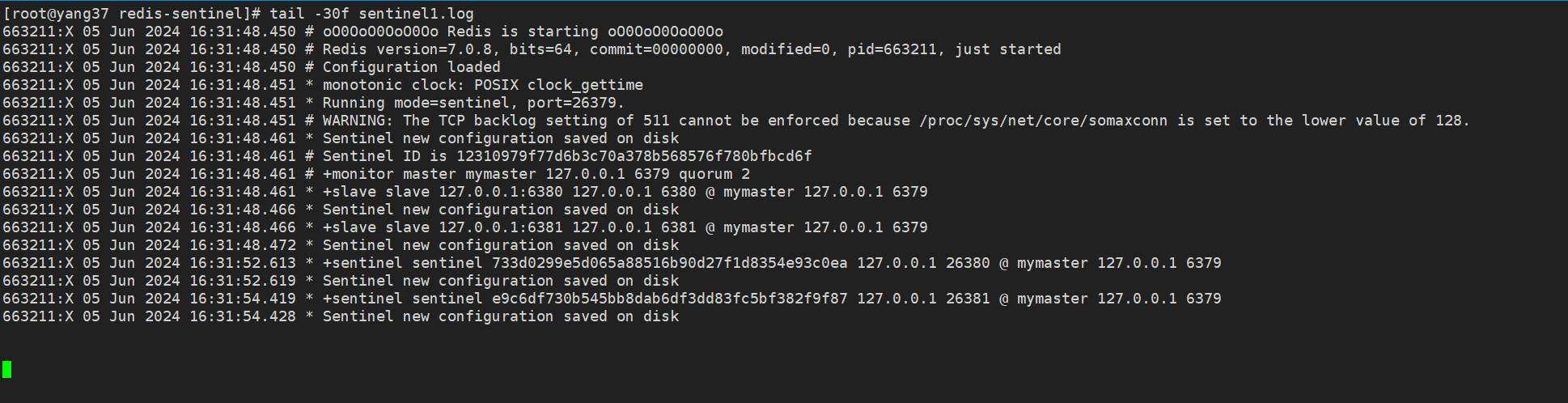
5.2 哨兵2启动日志
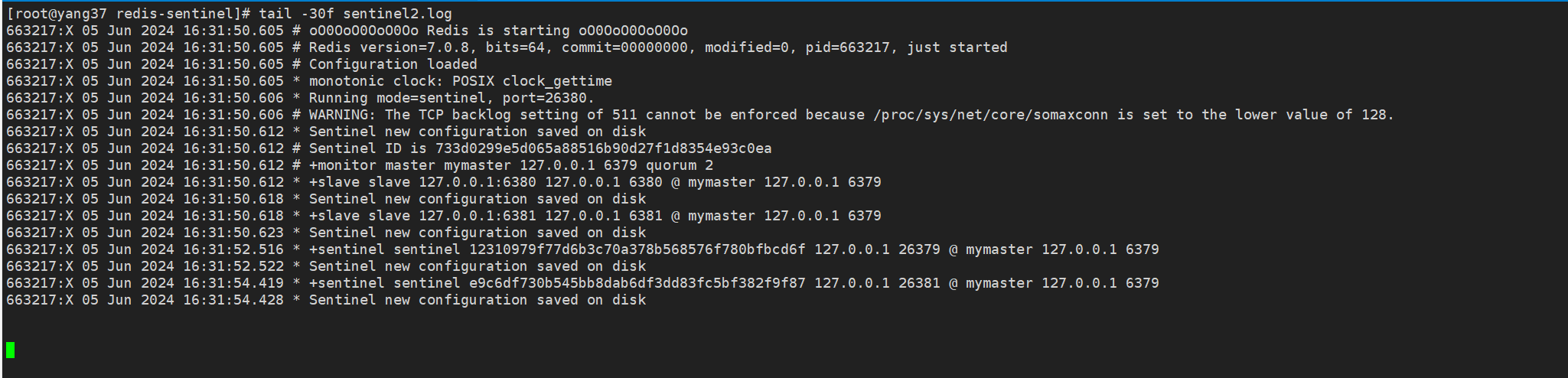
5.3 哨兵3启动日志
6.检查哨兵
使用命令连接到任一哨兵节点。
# 以26379端口所在节点的哨兵为例
redis-cli -p 26379
# 查看主节点信息
SENTINEL MASTER mymaster
# 或者一行
# redis-cli -p 26379 SENTINEL MASTER mymaster
# 查看从节点信息
SENTINEL SLAVES mymaster
# 或者一行
# redis-cli -p 26379 SENTINEL SLAVES mymaster
6.1 哨兵1
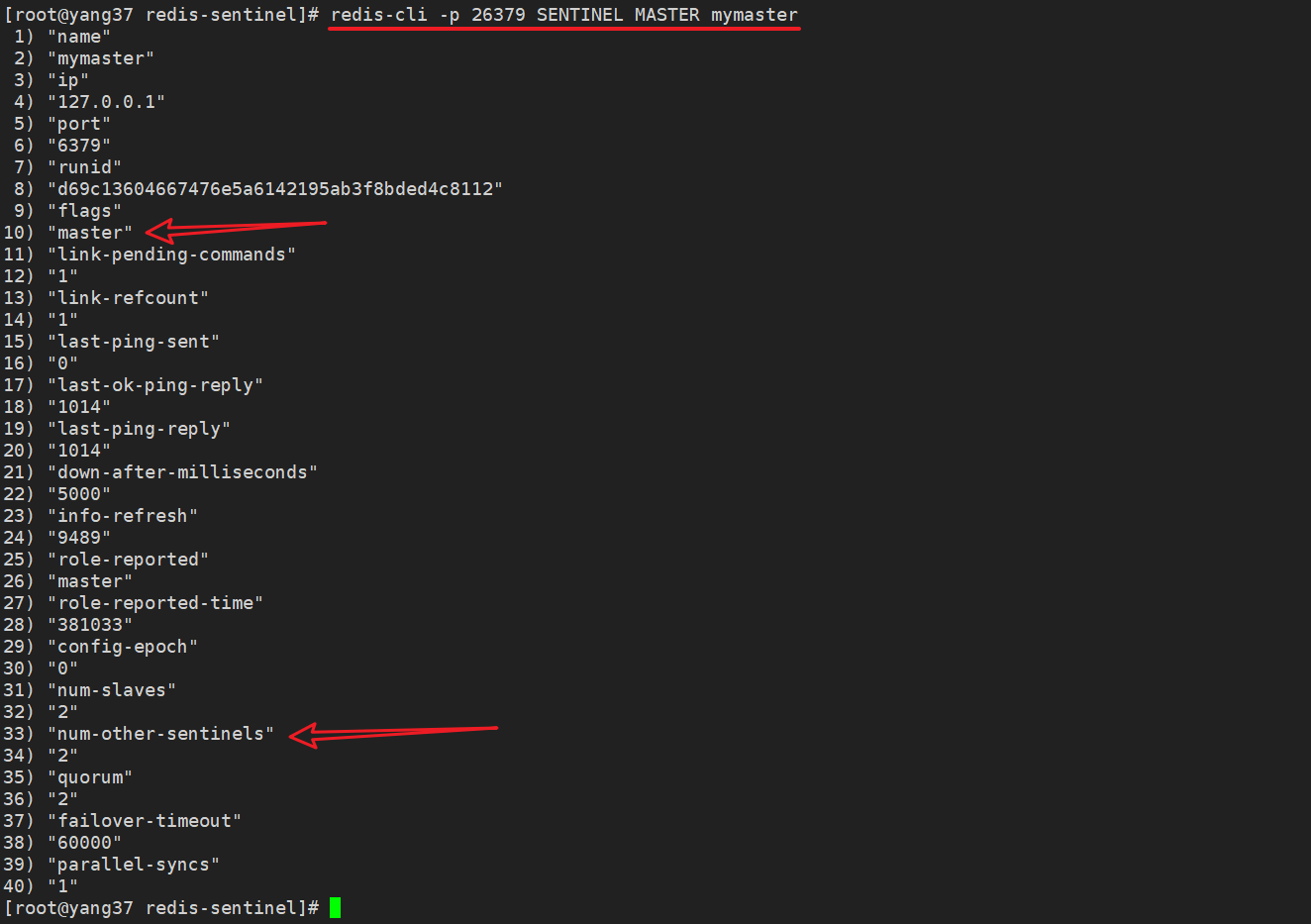
redis-cli -p 26379 SENTINEL MASTER mymaster
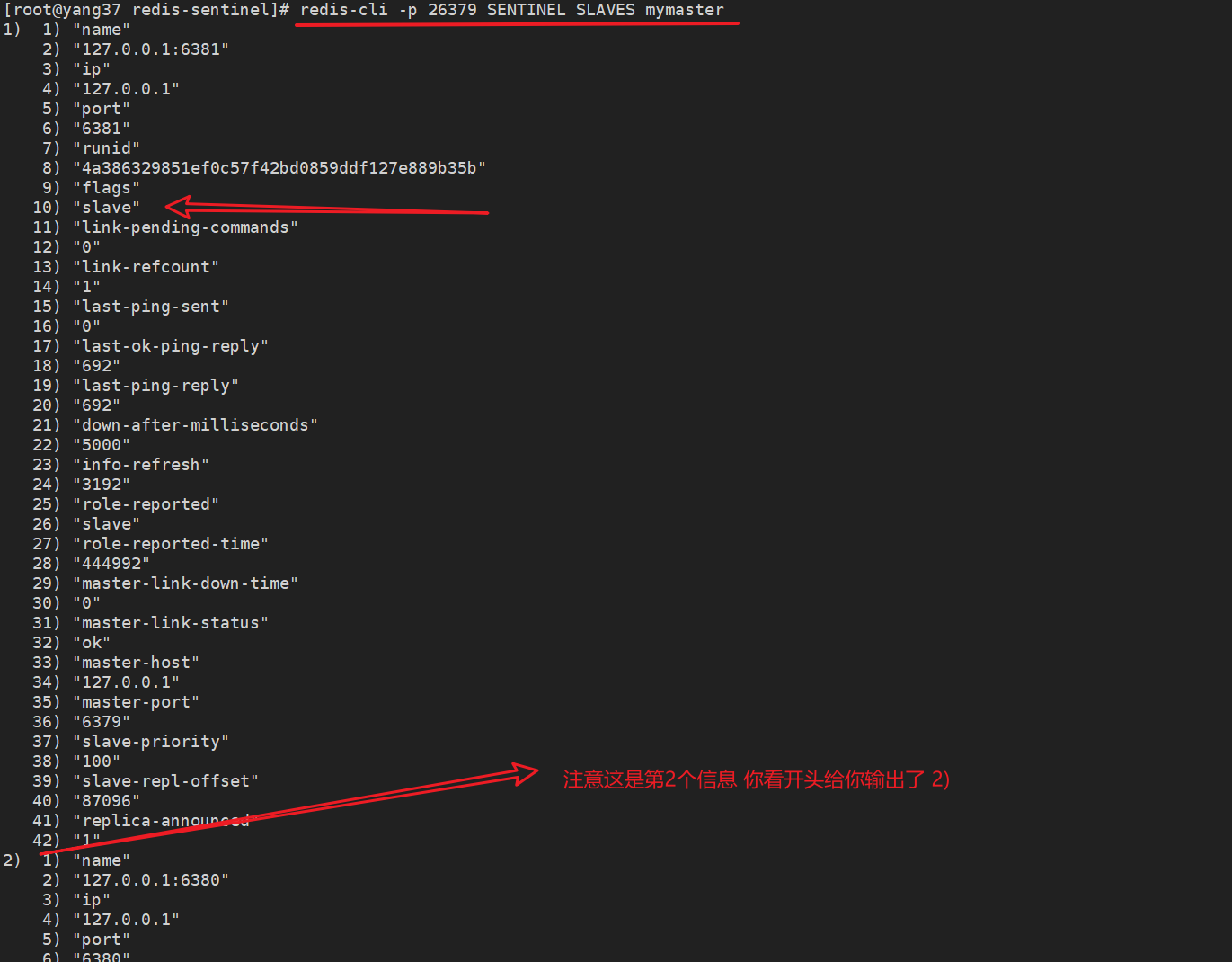
redis-cli -p 26379 SENTINEL SLAVES mymaster
6.2 哨兵2
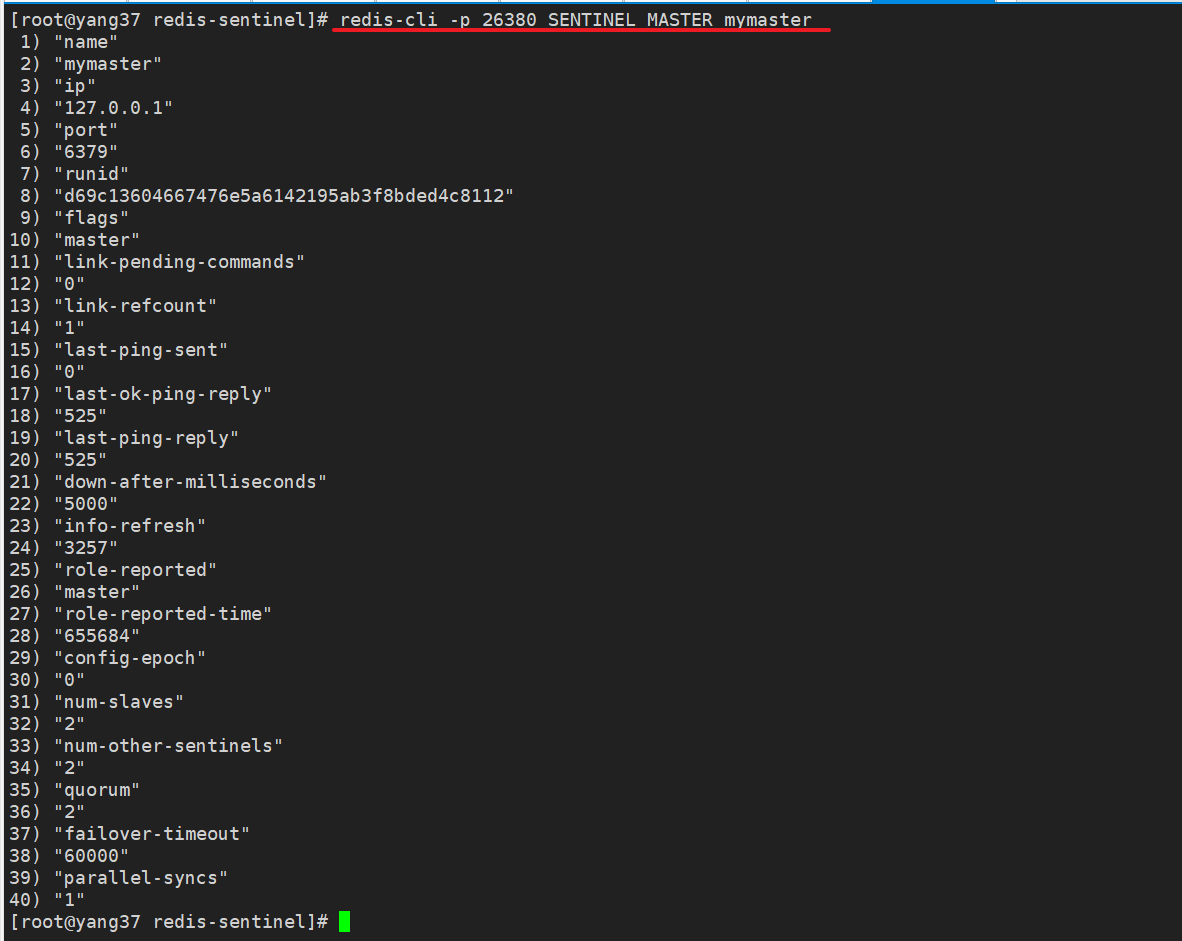
redis-cli -p 26380 SENTINEL MASTER mymaster
redis-cli -p 26380 SENTINEL SLAVES mymaster
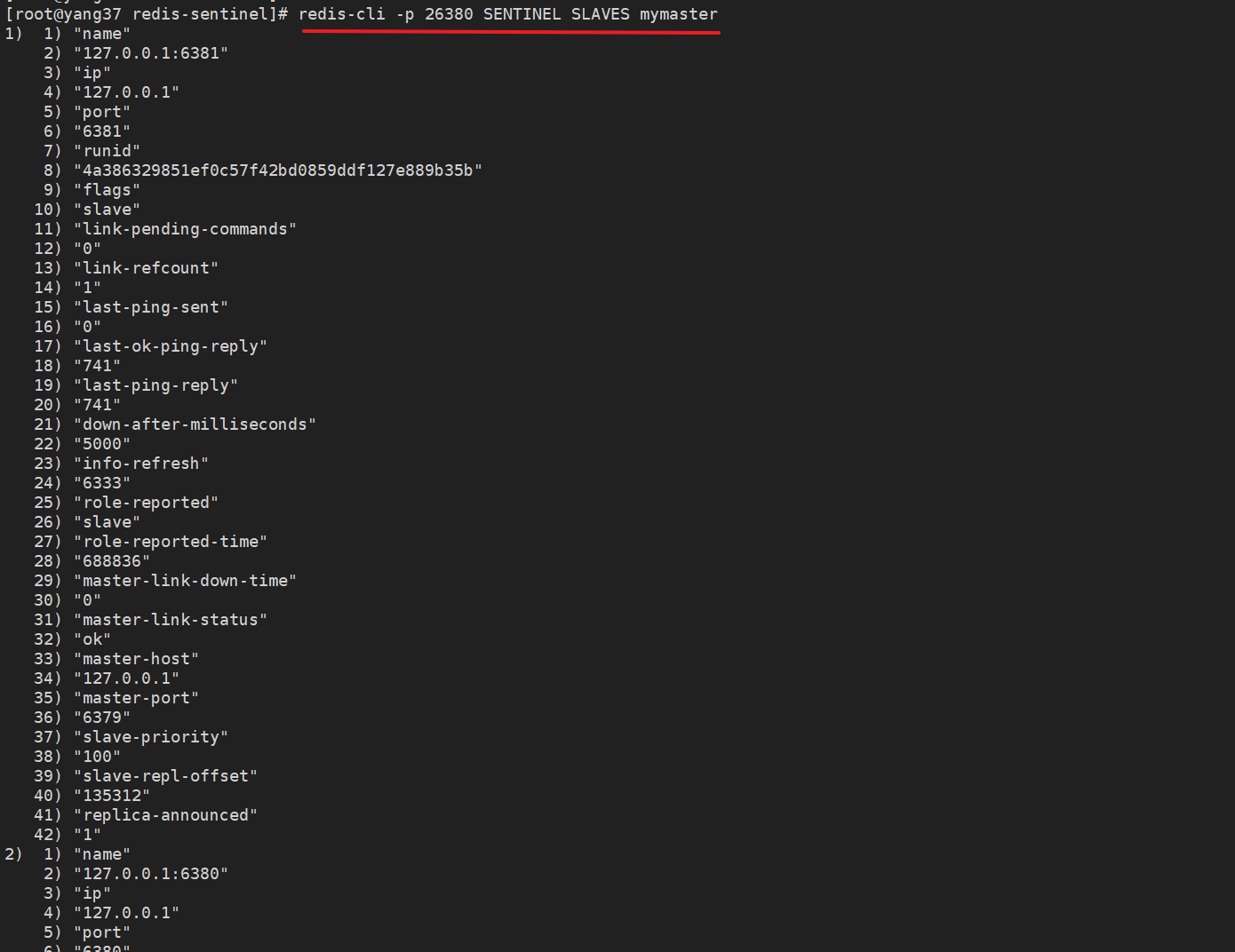
6.3 哨兵3
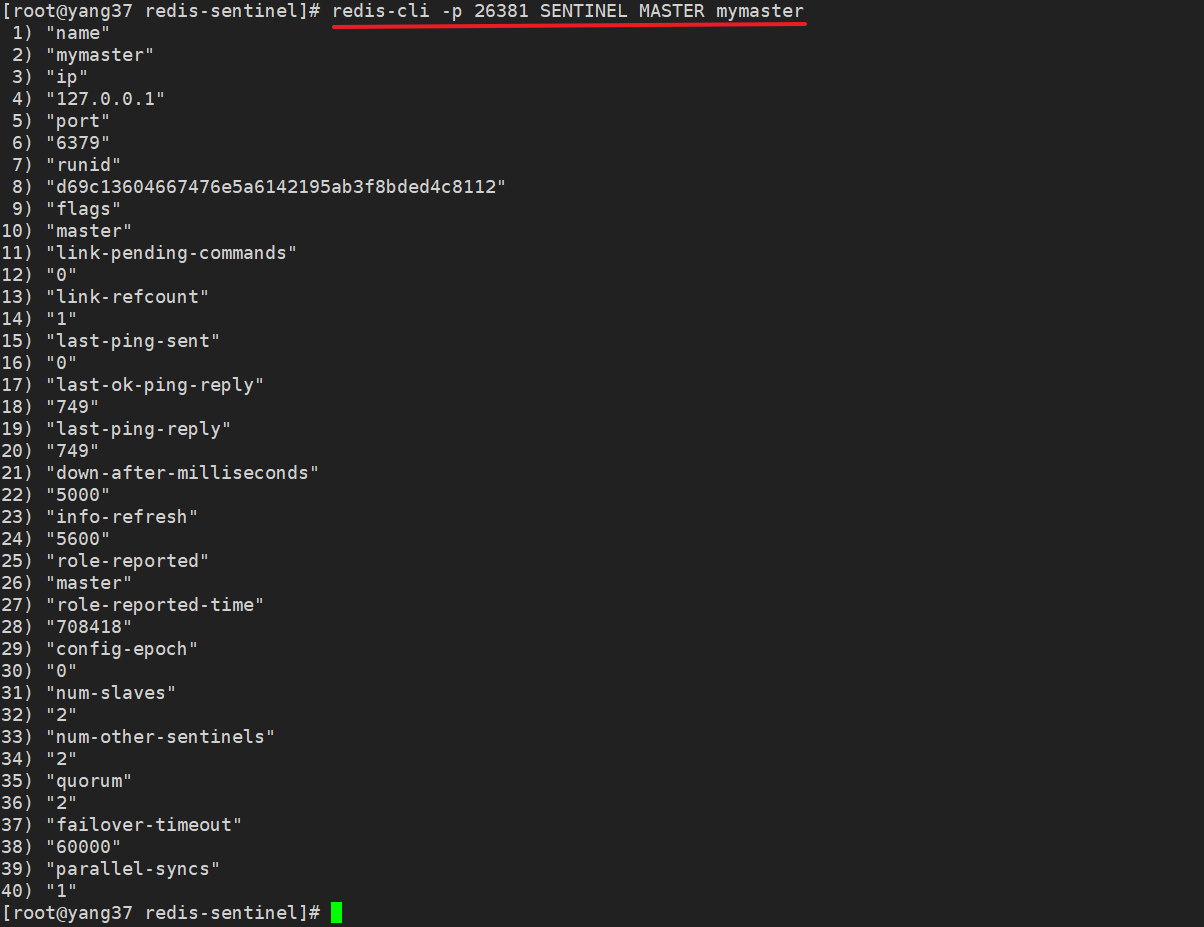
redis-cli -p 26381 SENTINEL MASTER mymaster
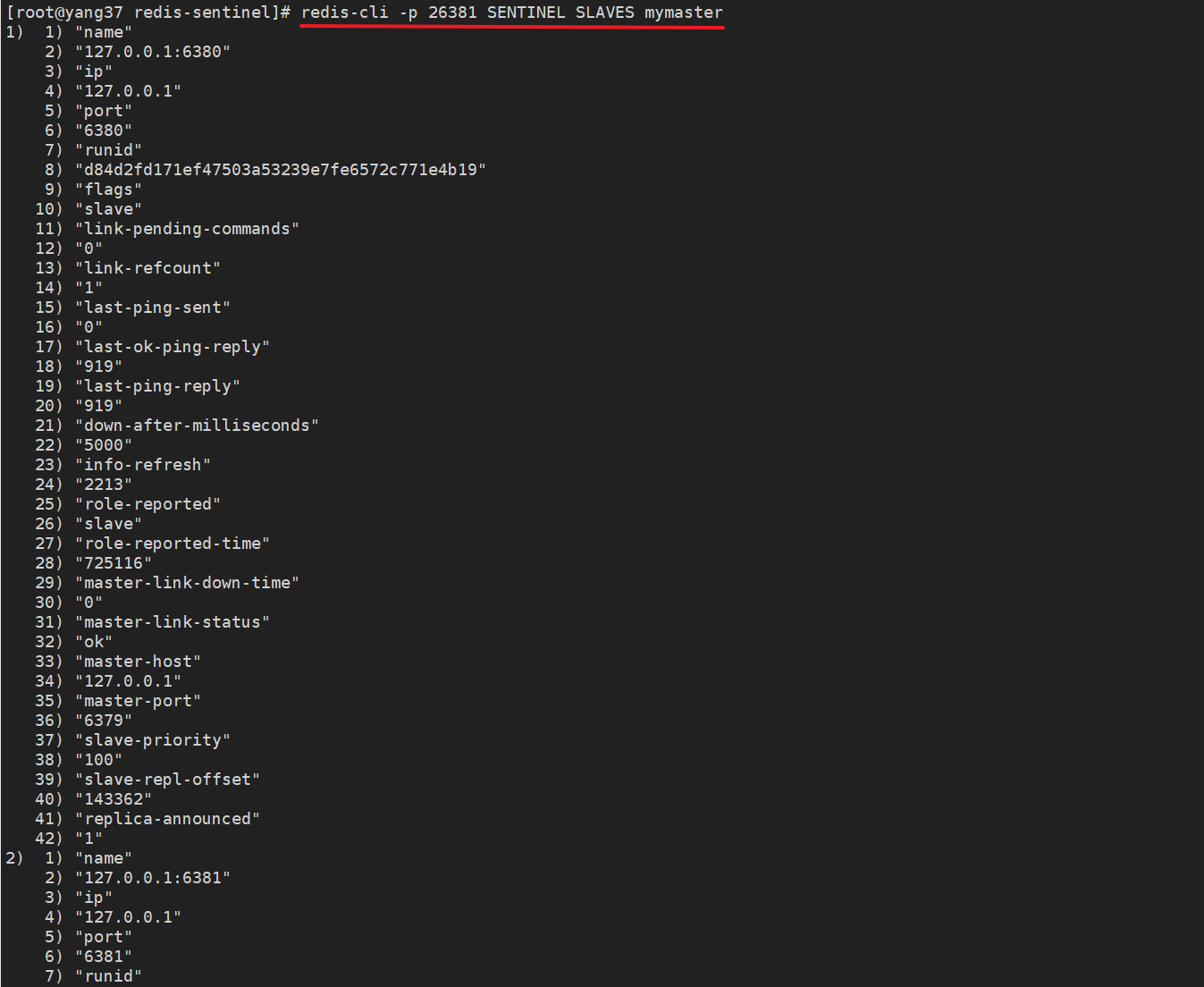
redis-cli -p 26381 SENTINEL SLAVES mymaster
6.4 扩展
6.4.1 连接异常
如果发现连接有问题,可以检查与主节点的通讯情况。
redis-cli -h 127.0.0.1 -p 6379 -a 密码 ping
正常应该相应PONG。

6.4.2 字段含义
SENTINEL MASTER xx
主节点的健康状况等
| 参数名 | 含义 | 示例值 |
|---|---|---|
| name | 主节点的名称 | mymaster |
| ip | 主节点的IP地址 | 127.0.0.1 |
| port | 主节点的端口号 | 6379 |
| runid | 主节点的唯一运行ID | d69c13604667476e5a6142195ab3f8bded4c8112 |
| flags | 节点的标识(例如 master, slave, etc.) | master |
| link-pending-commands | 等待发送的命令数量 | 0 |
| link-refcount | 与主节点的链接引用计数 | 1 |
| last-ping-sent | 上次发送ping命令的时间 | 0 |
| last-ok-ping-reply | 上次ping命令成功回复的时间 | 452 |
| last-ping-reply | 上次ping命令回复的时间 | 452 |
| down-after-milliseconds | 认定主节点下线的毫秒数 | 5000 |
| info-refresh | 信息刷新时间 | 9153 |
| role-reported | 报告的角色(如 master) | master |
| role-reported-time | 报告角色的时间 | 842336 |
| config-epoch | 配置纪元,用于实现故障转移 | 0 |
| num-slaves | 从节点的数量 | 2 |
| num-other-sentinels | 监控此主节点的其他Sentinel数量 | 2 |
| quorum | 达到法定人数所需的Sentinel数量 | 2 |
| failover-timeout | 故障转移超时时间(毫秒) | 60000 |
| parallel-syncs | 并行同步从节点的数量 | 1 |
SENTINEL SLAVES xx
从节点的健康状况以及它们与主节点的同步情况等
| 参数名 | 含义 | 示例值 |
|---|---|---|
| name | 从节点的名称 | 127.0.0.1:6381, 127.0.0.1:6380 |
| ip | 从节点的IP地址 | 127.0.0.1 |
| port | 从节点的端口号 | 6381, 6380 |
| runid | 从节点的唯一运行ID | 4a386329851ef0c57f42bd0859ddf127e889b35b, d84d2fd171ef47503a53239e7fe6572c771e4b19 |
| flags | 节点的标识(例如 master, slave, etc.) | slave |
| link-pending-commands | 等待发送的命令数量 | 0 |
| link-refcount | 与主节点的链接引用计数 | 1 |
| last-ping-sent | 上次发送ping命令的时间 | 0 |
| last-ok-ping-reply | 上次ping命令成功回复的时间 | 242 |
| last-ping-reply | 上次ping命令回复的时间 | 242 |
| down-after-milliseconds | 认定从节点下线的毫秒数 | 5000 |
| info-refresh | 信息刷新时间 | 141 |
| role-reported | 报告的角色(如 slave) | slave |
| role-reported-time | 报告角色的时间 | 1124585, 1124590 |
| master-link-down-time | 与主节点断开链接的时间 | 0 |
| master-link-status | 主从链接状态 | ok |
| master-host | 主节点的IP地址 | 127.0.0.1 |
| master-port | 主节点的端口号 | 6379 |
| slave-priority | 从节点的优先级 | 100 |
| slave-repl-offset | 从节点的复制偏移量 | 221846 |
| replica-announced | 从节点是否已被宣布 | 1 |
7.验证故障转移
7.1 停止主节点
停止主节点,观察哨兵是否会进行故障转移,并将从节点提升为新的主节点。
redis-cli -p 6379 shutdown

主节点日志
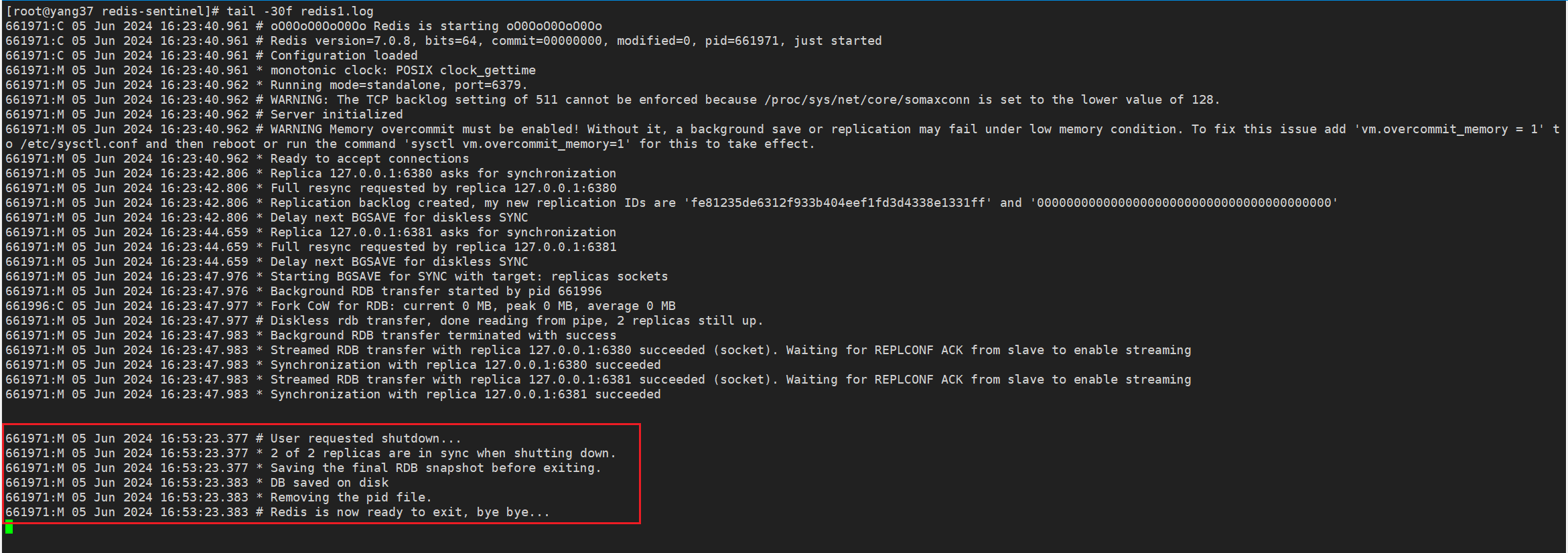
从节点1日志
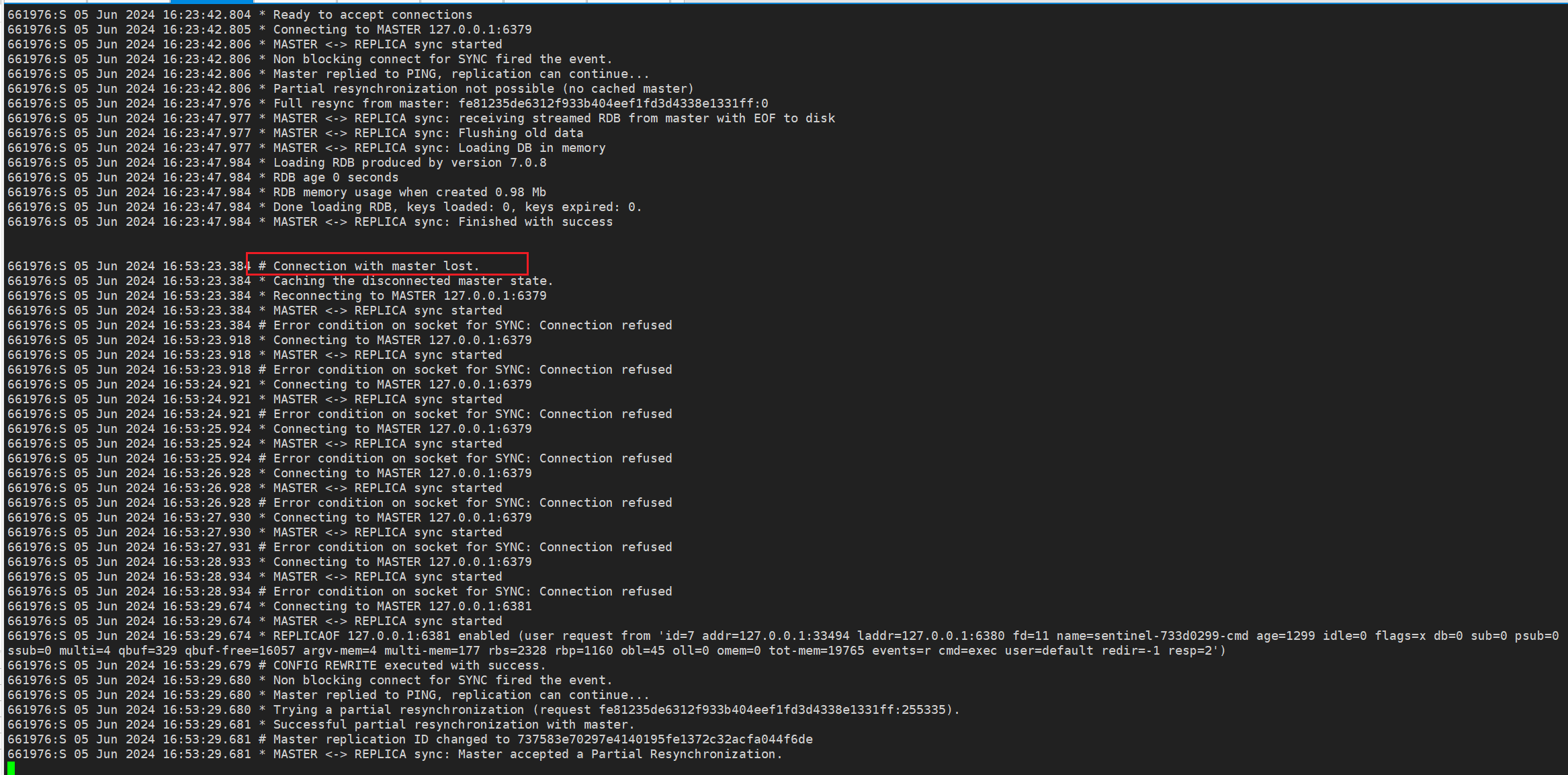
从节点2日志
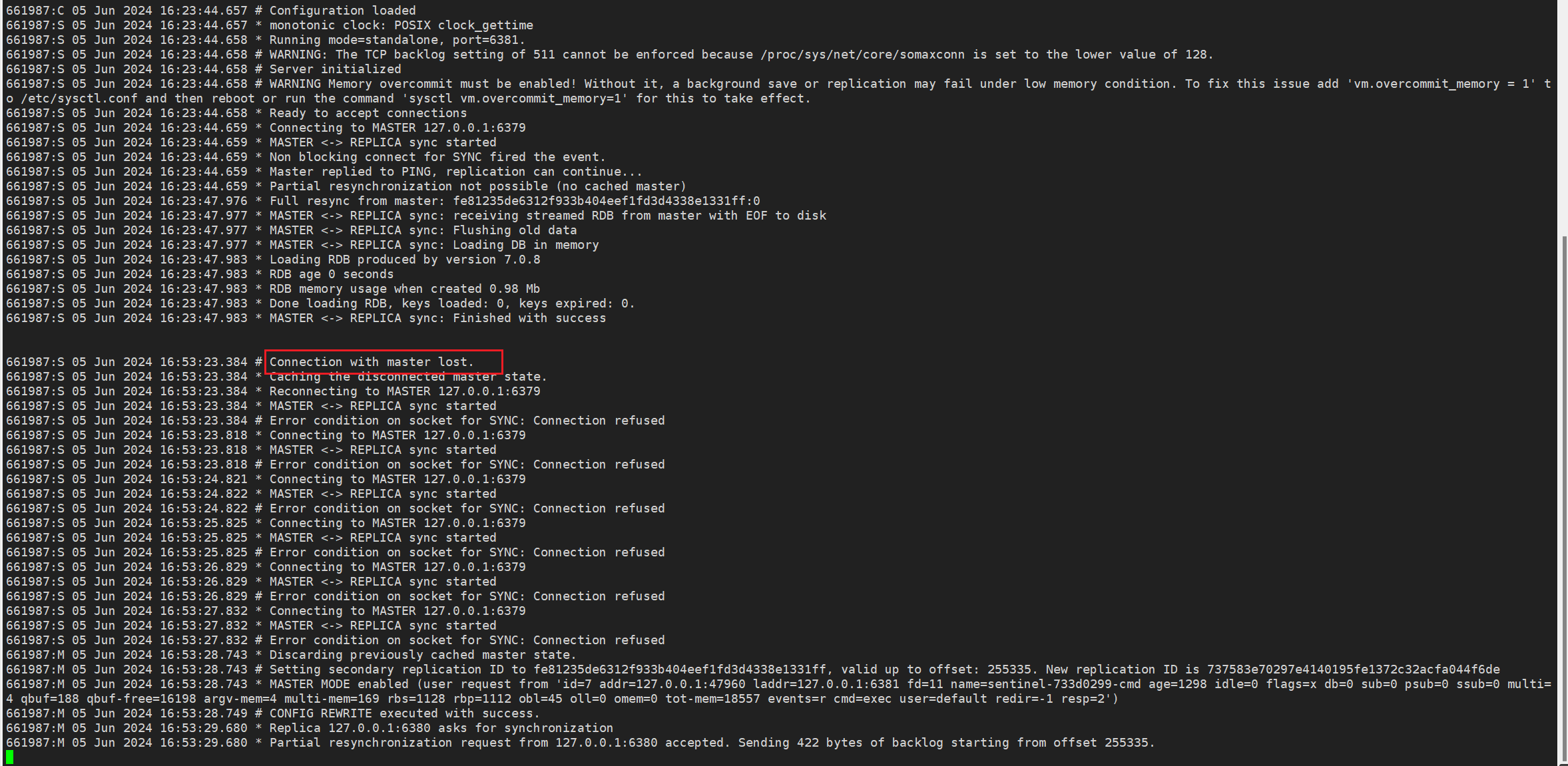
7.2 观察哨兵日志
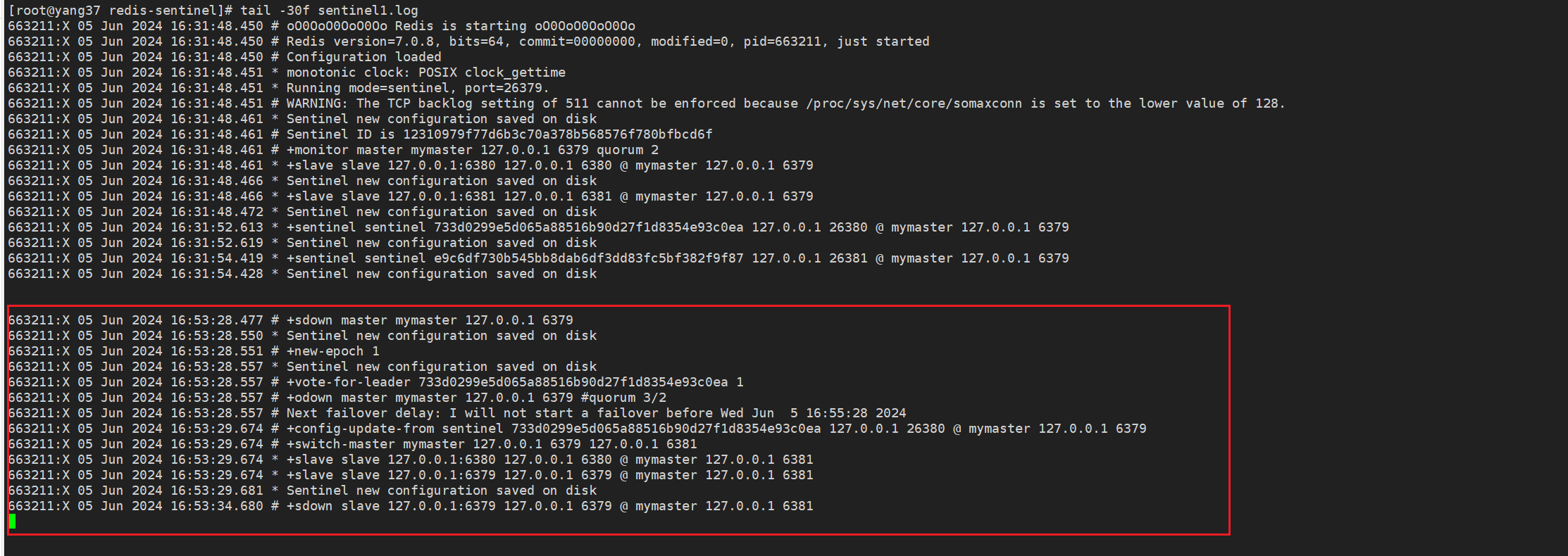
哨兵1日志
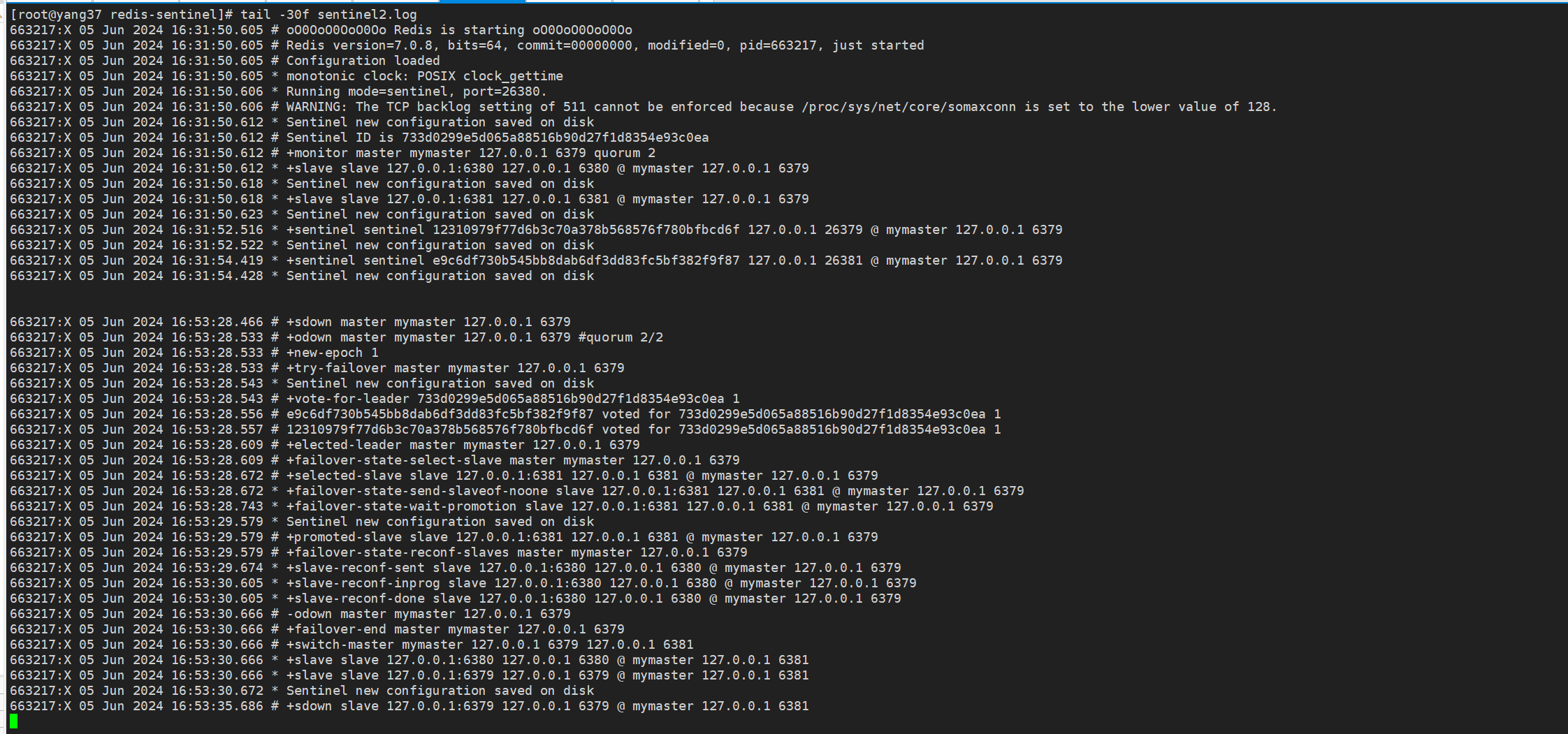
哨兵2日志
哨兵3日志
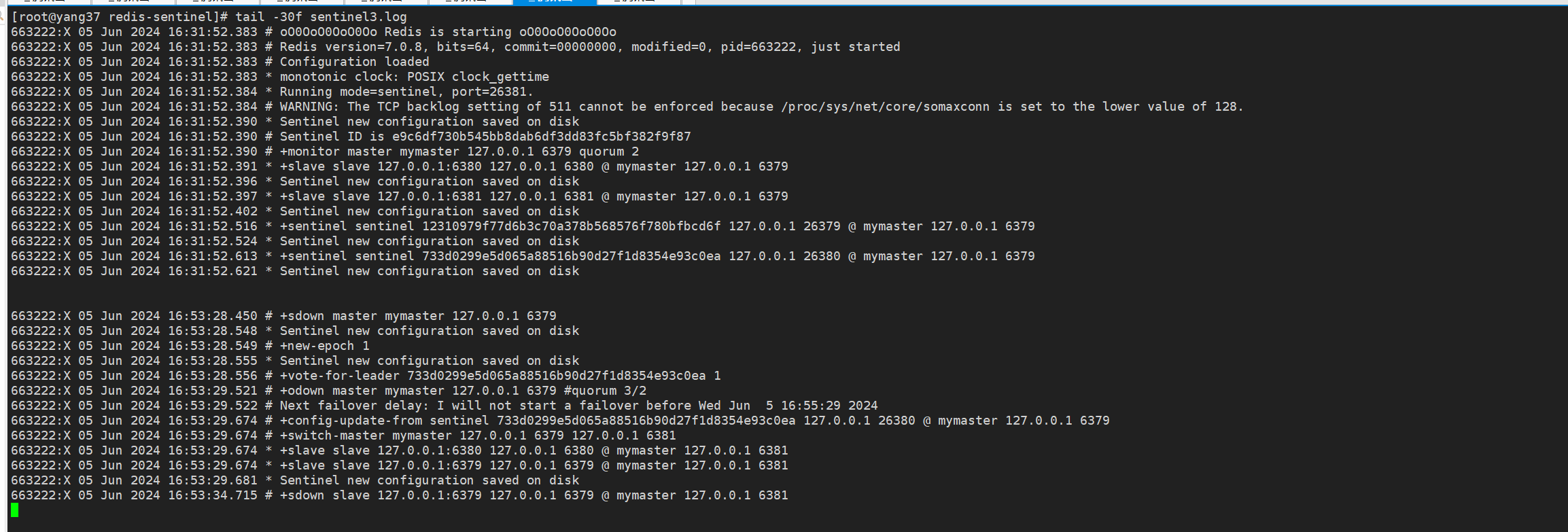
7.3 查看从节点是否被提升为主节点
现在,我们的6379停止了,场上只剩下6380、6381两个从节点了。
从上面哨兵的日志中我们可以看到,原来的从节点2,即6381端口的被选为了新的主节点。
redis-cli -p 6381 info replication
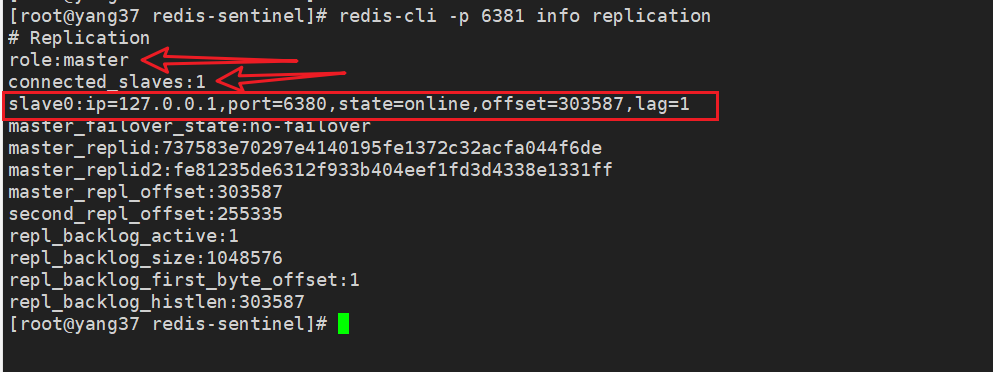
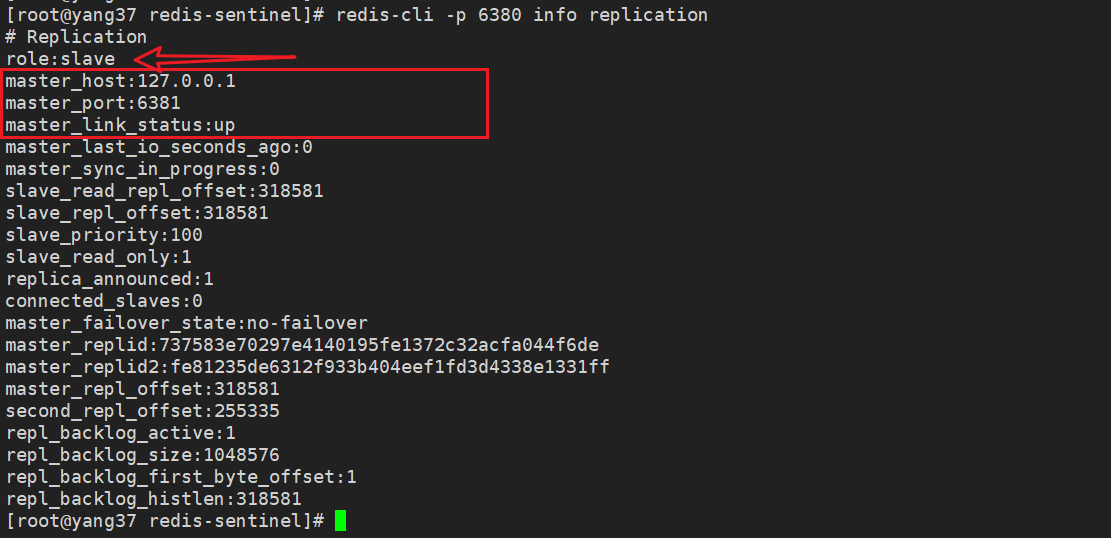
去原来的从节点1上看下呢,可以看到他的主节点已经变成了新的主节点6381。
redis-cli -p 6380 info replication
8.总结
我们不妨让gpt对日志翻译下,简单了解下过程先。
8.1 从节点1
日志记录了从服务器与主服务器连接丢失后的多次重连尝试,均因连接被拒绝而失败。
(Sentinel 完成主服务器的故障转移后)从服务器成功切换到新的主服务器,并实现了部分重同步。
| 时间戳 | 日志条目 | 解释 |
|---|---|---|
| 16:53:23.384 | Connection with master lost. |
与主服务器的连接丢失。 |
| 16:53:23.384 | Caching the disconnected master state. |
缓存断开连接时的主服务器状态。 |
| 16:53:23.384 | Reconnecting to MASTER 127.0.0.1:6379 |
尝试重新连接主服务器 127.0.0.1:6379。 |
| 16:53:23.384 | MASTER <-> REPLICA sync started |
开始主从同步。 |
| 16:53:23.384 | Error condition on socket for SYNC: Connection refused |
同步过程中出现错误,连接被拒绝。 |
| 16:53:23.918 | Connecting to MASTER 127.0.0.1:6379 |
再次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:23.918 | MASTER <-> REPLICA sync started |
再次开始主从同步。 |
| 16:53:23.918 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:24.921 | Connecting to MASTER 127.0.0.1:6379 |
第三次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:24.921 | MASTER <-> REPLICA sync started |
第三次开始主从同步。 |
| 16:53:24.921 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:25.924 | Connecting to MASTER 127.0.0.1:6379 |
第四次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:25.924 | MASTER <-> REPLICA sync started |
第四次开始主从同步。 |
| 16:53:25.924 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:26.928 | Connecting to MASTER 127.0.0.1:6379 |
第五次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:26.928 | MASTER <-> REPLICA sync started |
第五次开始主从同步。 |
| 16:53:26.928 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:27.930 | Connecting to MASTER 127.0.0.1:6379 |
第六次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:27.930 | MASTER <-> REPLICA sync started |
第六次开始主从同步。 |
| 16:53:27.931 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:28.933 | Connecting to MASTER 127.0.0.1:6379 |
第七次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:28.934 | MASTER <-> REPLICA sync started |
第七次开始主从同步。 |
| 16:53:28.934 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:29.674 | Connecting to MASTER 127.0.0.1:6381 |
Sentinel 切换到新的主服务器 127.0.0.1:6381 并尝试连接。 |
| 16:53:29.674 | MASTER <-> REPLICA sync started |
开始与新的主服务器 127.0.0.1:6381 进行主从同步。 |
| 16:53:29.674 | REPLICAOF 127.0.0.1:6381 enabled (user request from 'id=7 addr=127.0.0.1:33494 laddr=127.0.0.1:6380 fd=11 name=sentinel-733d0299-cmd age=1299 idle=0 flags=x db=0 sub=0 psub=0 ssub=0 multi=4 qbuf=329 qbuf-free=16057 argv-mem=4 multi-mem=177 rbs=2328 rbp=1160 obl=45 oll=0 omem=0 tot-mem=19765 events=r cmd=exec user=default redir=-1 resp=2') |
执行 REPLICAOF 命令,将从服务器设置为 127.0.0.1:6381 的从服务器。 |
| 16:53:29.679 | CONFIG REWRITE executed with success. |
成功执行配置重写。 |
| 16:53:29.680 | Non blocking connect for SYNC fired the event. |
非阻塞同步事件触发。 |
| 16:53:29.680 | Master replied to PING, replication can continue... |
新的主服务器响应 PING 命令,复制可以继续进行。 |
| 16:53:29.680 | Trying a partial resynchronization (request fe81235de6312f933b404eef1fd3d4338e1331ff:255335). |
尝试部分重同步。 |
| 16:53:29.681 | Successful partial resynchronization with master. |
部分重同步成功。 |
| 16:53:29.681 | Master replication ID changed to 737583e70297e4140195fe1372c32acfa044f6de |
主服务器的复制 ID 改变。 |
| 16:53:29.681 | MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization. |
主服务器接受了部分重同步。 |
8.2 从节点2
日志记录了从服务器与主服务器连接丢失后的多次重连尝试,均因连接被拒绝而失败。
(Sentinel 将从服务器切换为新的主服务器后)成功执行配置重写,新的主服务器接受了从服务器的部分重同步请求,并发送了积压的数据。
| 时间戳 | 日志条目 | 解释 |
|---|---|---|
| 16:53:23.384 | Connection with master lost. |
与主服务器的连接丢失。 |
| 16:53:23.384 | Caching the disconnected master state. |
缓存断开连接时的主服务器状态。 |
| 16:53:23.384 | Reconnecting to MASTER 127.0.0.1:6379 |
尝试重新连接主服务器 127.0.0.1:6379。 |
| 16:53:23.384 | MASTER <-> REPLICA sync started |
开始主从同步。 |
| 16:53:23.384 | Error condition on socket for SYNC: Connection refused |
同步过程中出现错误,连接被拒绝。 |
| 16:53:23.818 | Connecting to MASTER 127.0.0.1:6379 |
再次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:23.818 | MASTER <-> REPLICA sync started |
再次开始主从同步。 |
| 16:53:23.818 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:24.821 | Connecting to MASTER 127.0.0.1:6379 |
第三次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:24.822 | MASTER <-> REPLICA sync started |
第三次开始主从同步。 |
| 16:53:24.822 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:25.825 | Connecting to MASTER 127.0.0.1:6379 |
第四次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:25.825 | MASTER <-> REPLICA sync started |
第四次开始主从同步。 |
| 16:53:25.825 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:26.829 | Connecting to MASTER 127.0.0.1:6379 |
第五次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:26.829 | MASTER <-> REPLICA sync started |
第五次开始主从同步。 |
| 16:53:26.829 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:27.832 | Connecting to MASTER 127.0.0.1:6379 |
第六次尝试连接主服务器 127.0.0.1:6379。 |
| 16:53:27.832 | MASTER <-> REPLICA sync started |
第六次开始主从同步。 |
| 16:53:27.832 | Error condition on socket for SYNC: Connection refused |
同步过程中再次出现错误,连接被拒绝。 |
| 16:53:28.743 | Discarding previously cached master state. |
丢弃先前缓存的主服务器状态。 |
| 16:53:28.743 | Setting secondary replication ID to fe81235de6312f933b404eef1fd3d4338e1331ff, valid up to offset: 255335. New replication ID is 737583e70297e4140195fe1372c32acfa044f6de |
设置次要复制 ID,并更新新的复制 ID。 |
| 16:53:28.743 | MASTER MODE enabled (user request from 'id=7 addr=127.0.0.1:47960 laddr=127.0.0.1:6381 fd=11 name=sentinel-733d0299-cmd age=1298 idle=0 flags=x db=0 sub=0 psub=0 ssub=0 multi=4 qbuf=188 qbuf-free=16198 argv-mem=4 multi-mem=169 rbs=1128 rbp=1112 obl=45 oll=0 omem=0 tot-mem=18557 events=r cmd=exec user=default redir=-1 resp=2') |
启用主服务器模式(根据用户请求)。 |
| 16:53:28.749 | CONFIG REWRITE executed with success. |
成功执行配置重写。 |
| 16:53:29.680 | Replica 127.0.0.1:6380 asks for synchronization |
从服务器 127.0.0.1:6380 请求同步。 |
| 16:53:29.680 | Partial resynchronization request from 127.0.0.1:6380 accepted. Sending 422 bytes of backlog starting from offset 255335. |
部分重同步请求被接受,并开始发送积压数据。 |
8.3 哨兵1
日志记录了 Sentinel 进行了一次主服务器 mymaster 的故障转移,并将新的主服务器设置为 127.0.0.1:6381。
旧的主服务器 127.0.0.1:6379 变成了从服务器,并且在稍后的时间进入了主观下线状态等。
| 时间戳 | 日志条目 | 解释 |
|---|---|---|
| 16:53:28.450 | +sdown master mymaster 127.0.0.1 6379 |
Sentinel 检测到主服务器 mymaster(IP: 127.0.0.1, 端口: 6379)进入主观下线状态。 |
| 16:53:28.548 | Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:28.549 | +new-epoch 1 |
Sentinel 进入一个新的纪元(epoch)。 |
| 16:53:28.555 | Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:28.556 | +vote-for-leader 733d0299e5d065a88516b90d27f1d8354e93c0ea 1 |
Sentinel 为新的领导者投票。 |
| 16:53:29.521 | +odown master mymaster 127.0.0.1 6379 #quorum 3/2 |
Sentinel 达到仲裁(quorum),将主服务器标记为客观下线状态。需要至少 2 个 Sentinel 同意主服务器下线,实际有 3 个 Sentinel 同意。 |
| 16:53:29.522 | Next failover delay: I will not start a failover before Wed Jun 5 16:55:29 2024 |
Sentinel 指定在 2024 年 6 月 5 日 16:55:29 之前不会开始故障转移。 |
| 16:53:29.674 | +config-update-from sentinel 733d0299e5d065a88516b90d27f1d8354e93c0ea 127.0.0.1 26380 @ mymaster 127.0.0.1 6379 |
从 Sentinel 733d0299e5d065a88516b90d27f1d8354e93c0ea 更新了配置,监控 mymaster(IP: 127.0.0.1, 端口: 6379)。 |
| 16:53:29.674 | +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381 |
Sentinel 将主服务器从 127.0.0.1:6379 切换到 127.0.0.1:6381。 |
| 16:53:29.674 | +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 |
从服务器 127.0.0.1:6380 重新配置为新的主服务器的从服务器。 |
| 16:53:29.674 | +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 |
原来的主服务器 127.0.0.1:6379 现在成为新的主服务器的从服务器。 |
| 16:53:29.681 | Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:34.715 | +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 |
Sentinel 检测到从服务器 127.0.0.1:6379 进入主观下线状态。 |
8.4 哨兵2
日志记录了 Redis Sentinel 检测到主服务器下线,并完成故障转移的过程。
具体步骤包括检测主观下线,确认客观下线,进入新纪元,选举新领导者,选择新的主服务器,重新配置从服务器,最后完成故障转移等。
| 时间戳 | 日志条目 | 解释 |
|---|---|---|
| 16:53:28.466 | +sdown master mymaster 127.0.0.1 6379 |
Sentinel 检测到主服务器 mymaster(IP: 127.0.0.1, 端口: 6379)进入主观下线状态。 |
| 16:53:28.533 | +odown master mymaster 127.0.0.1 6379 #quorum 2/2 |
Sentinel 达到仲裁(quorum),将主服务器标记为客观下线状态。需要至少 2 个 Sentinel 同意主服务器下线。 |
| 16:53:28.533 | +new-epoch 1 |
Sentinel 进入一个新的纪元(epoch)。 |
| 16:53:28.533 | +try-failover master mymaster 127.0.0.1 6379 |
Sentinel 开始对主服务器 mymaster 进行故障转移。 |
| 16:53:28.543 | Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:28.543 | +vote-for-leader 733d0299e5d065a88516b90d27f1d8354e93c0ea 1 |
Sentinel 为新的领导者投票。 |
| 16:53:28.556 | e9c6df730b545bb8dab6df3dd83fc5bf382f9f87 voted for 733d0299e5d065a88516b90d27f1d8354e93c0ea 1 |
Sentinel 投票信息。 |
| 16:53:28.557 | 12310979f77d6b3c70a378b568576f780bfbcd6f voted for 733d0299e5d065a88516b90d27f1d8354e93c0ea 1 |
Sentinel 投票信息。 |
| 16:53:28.609 | +elected-leader master mymaster 127.0.0.1 6379 |
Sentinel 选举产生了新的领导者。 |
| 16:53:28.609 | +failover-state-select-slave master mymaster 127.0.0.1 6379 |
Sentinel 进入选择从服务器状态,开始选择新的主服务器。 |
| 16:53:28.672 | +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 |
Sentinel 选择了从服务器 127.0.0.1:6381 作为新的主服务器。 |
| 16:53:28.672 | +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 |
Sentinel 发送 SLAVEOF NO ONE 命令,将选定的从服务器提升为主服务器。 |
| 16:53:28.743 | +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 |
Sentinel 等待从服务器 127.0.0.1:6381 的提升过程完成。 |
| 16:53:29.579 | Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:29.579 | +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 |
Sentinel 确认 127.0.0.1:6381 已经被提升为主服务器。 |
| 16:53:29.579 | +failover-state-reconf-slaves master mymaster 127.0.0.1 6379 |
Sentinel 开始重新配置其他从服务器。 |
| 16:53:29.674 | +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 |
Sentinel 发送重新配置命令给从服务器 127.0.0.1:6380。 |
| 16:53:30.605 | +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 |
从服务器 127.0.0.1:6380 的重新配置正在进行中。 |
| 16:53:30.605 | +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 |
从服务器 127.0.0.1:6380 的重新配置完成。 |
| 16:53:30.666 | -odown master mymaster 127.0.0.1 6379 |
Sentinel 取消主服务器的客观下线状态。 |
| 16:53:30.666 | +failover-end master mymaster 127.0.0.1 6379 |
Sentinel 完成故障转移。 |
| 16:53:30.666 | +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381 |
Sentinel 将主服务器从 127.0.0.1:6379 切换到 127.0.0.1:6381。 |
| 16:53:30.666 | +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 |
从服务器 127.0.0.1:6380 重新配置为新的主服务器的从服务器。 |
| 16:53:30.666 | +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 |
原来的主服务器 127.0.0.1:6379 现在成为新的主服务器的从服务器。 |
| 16:53:30.672 | Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:35.686 | +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 |
Sentinel 检测到从服务器 127.0.0.1:6379 进入主观下线状态。 |
8.5 哨兵3
哨兵3与哨兵1类似
| 时间戳 | 日志条目 | 解释 |
|---|---|---|
| 16:53:28.450 | +sdown master mymaster 127.0.0.1 6379 |
Sentinel 检测到主服务器 mymaster(IP: 127.0.0.1, 端口: 6379)进入主观下线状态。 |
| 16:53:28.548 | * Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:28.549 | +new-epoch 1 |
Sentinel 进入一个新的纪元(epoch)。 |
| 16:53:28.555 | * Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:28.556 | +vote-for-leader 733d0299e5d065a88516b90d27f1d8354e93c0ea 1 |
Sentinel 开始为新的领导者投票。 |
| 16:53:29.521 | +odown master mymaster 127.0.0.1 6379 #quorum 3/2 |
Sentinel 达到仲裁(quorum),将主服务器标记为客观下线状态。需要至少 2 个 Sentinel 同意主服务器下线,实际有 3 个 Sentinel 同意。 |
| 16:53:29.522 | Next failover delay: I will not start a failover before Wed Jun 5 16:55:29 2024 |
Sentinel 指定在 2024 年 6 月 5 日 16:55:29 之前不会开始故障转移。 |
| 16:53:29.674 | +config-update-from sentinel 733d0299e5d065a88516b90d27f1d8354e93c0ea 127.0.0.1 26380 @ mymaster 127.0.0.1 6379 |
从 Sentinel 733d0299e5d065a88516b90d27f1d8354e93c0ea 更新了配置,监控 mymaster(IP: 127.0.0.1, 端口: 6379)。 |
| 16:53:29.674 | +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381 |
Sentinel 将主服务器从 127.0.0.1:6379 切换到 127.0.0.1:6381。 |
| 16:53:29.674 | * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 |
从服务器 127.0.0.1:6380 重新配置为新的主服务器的从服务器。 |
| 16:53:29.674 | * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 |
原来的主服务器 127.0.0.1:6379 现在成为新的主服务器的从服务器。 |
| 16:53:29.681 | * Sentinel new configuration saved on disk |
Sentinel 将新的配置保存到磁盘。 |
| 16:53:34.715 | +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 |
Sentinel 检测到从服务器 127.0.0.1:6379 进入主观下线状态。 |
8.6 追加的配置文件
1.2.3 问题点
1.哨兵如何判断节点下线?
Sentinel 定期向Redis实例发送 PING 命令,当某个哨兵节点发现联系不上对方的时候,则认为对方主观下线。
主观下线,只是我自己认为的,万一只是我网络抖动了下呢。所以,紧接着该哨兵节点就会发起仲裁。
当大家都认为下线的时候(达到仲裁数量quorum),才会认为该节点是真的下线了,称为客观下线。
| 机制 | 说明 |
|---|---|
| 主观下线(sdown) | - Sentinel 定期向 Redis 实例发送 PING 命令。- 如果在配置的时间( is-master-down-after-milliseconds 参数)内没有收到 PONG 响应,则认为实例处于主观下线状态。 |
| 客观下线(odown) | - Sentinel 将自己的主观下线状态广播给其他 Sentinel 实例。 - 其他 Sentinel 实例收到主观下线信息后进行确认,当确认数量达到仲裁数量(quorum)时,标记实例为客观下线(odown)。 |
相关配置参数
# 后面的那个2就是仲裁数量(quorum)
sentinel monitor mymaster 127.0.0.1 6379 2
# Sentinel多久未收到某个实例(无论是主节点还是从节点)的响应后,认为该实例主观下线(sdown)
sentinel down-after-milliseconds mymaster 3000
# Sentinel 单独判定主节点下线的等待时间
sentinel is-master-down-after-milliseconds mymaster 5000
-
从节点下线
从节点挂了影响不大,别的从节点也可以读的嘛,哨兵机制的话它自身的话就做了个记录,没有故障恢复之类的操作了。
-
主节点下线
故障恢复,选择一个从节点升级成主节点,构建新的主从。整个过程自动化完成,无需人工参与。
2.怎么选出新的master?
slave 必须是在线状态才能参加新的 master 的选举,筛选出所有在线的 slave 之后,从下方3个维度依次判断。
| 优先级 | 维度 | 说明 |
|---|---|---|
| 1 | slave 优先级 | 通过 slave-priority(在 Redis 5.0 后改为 replica-priority)配置的值来手动设置从节点的优先级。slave-priority默认值为 100,其值越小得分越高,越有机会成为 master,0表示没有资格。 示例:有三个从节点,优先级分别为 10、100、25,哨兵会选择优先级为 10 的从节点。 |
| 2 | 复制进度 | Sentinel 选择复制进度最快、数据最完整的从节点。复制进度越快得分越高。 说明:与旧 master 的数据最接近的从节点优先。 |
| 3 | runid | 如果前两轮筛选后有多个从节点相同,则选择 runid 最小的从节点。每个 Redis 节点启动时生成一个 40 字节随机字符串作为运行 id。说明: runid 是每个 Redis 实例的唯一标识符。 |
这里为啥要有个我们自己配置的slave优先级呢?因为这样我们可以让性能好的机器优先当主节点。
下面具体介绍下三个维度的情况。
1.slave 优先级
slave-priority默认值为 100,其值越小得分越高,越有机会成为 master,0表示没有资格。
可以通过修改 slave-priority(redis.conf中配置,Redis5.0 后该配置属性名称被修改为 replica-priority) 配置的值来手动设置 slave 的优先级。
比如说假设有三个优先级分别为 10,100,25 的 slave ,哨兵将选择优先级为 10 的。
如果没有优先级最高的,再判断复制进度。
2.复制进度
Sentinel 总是希望选择出数据最完整(与旧 master 数据最接近),即复制进度最快的 slave,让其提升为新的 master,复制进度越快得分也就越高。
3.runid(运行 id)
有多个 slave 的优先级和复制进度一样的话,那就 runid 小的成为新的 master,每个 redis 节点启动时都有一个 40 字节随机字符串作为运行 id。
3.哪个哨兵来做故障转移?
当 sentinel 集群确认有 master 客观下线了,就会开始故障转移流程。
故障转移流程的第一步就是在 sentinel 集群选择一个 leader,让 leader 来负责完成故障转移。
如何选择出 Leader 角色呢?
这个就涉及到分布式领域的共识算法,让分布式环境中的各个节点就某个问题达成一致。
大部分共识算法都是基于 Paxos 算法改进而来,sentinel 选举 leader 这个场景下使用的是由其改进而来的Raft 算法(更易理解和实现)。
4.哨兵机制可以防止脑裂吗?
可以在一定程度上缓解脑裂问题,但并不能完全解决脑裂问题。
什么是脑裂问题
在分布式系统中,脑裂(Split-Brain)问题指的是集群的各个节点由于网络分区或其他原因,导致部分节点失去与其他节点的通信,从而形成多个孤立的子集。每个子集认为自己是唯一的活跃集群,这会导致数据不一致和服务失效。
假设一个场景,master和2个slave,各自在自己的本地部署了一个哨兵,即下面这个样子。
主节点和从节点之间的网络断开,发生分区。
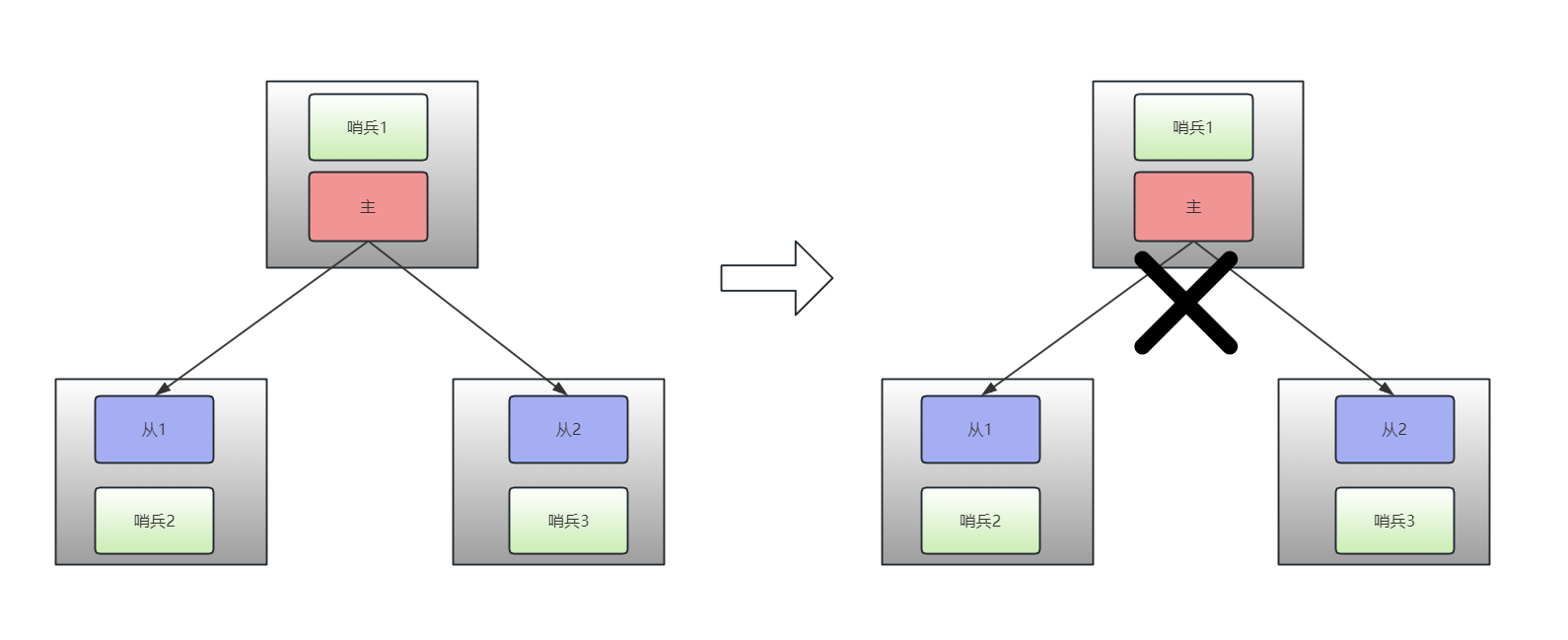
-
由于哨兵2、3联系不上主节点(也联系不上哨兵1),会触发客观下线的仲裁。
-
经过哨兵2、3的仲裁,选择升级从节点1升级为主节点,从1(新主)和从2构成新的主从。
此时,由于网络隔离,这两个玩意之间是互不知情的。变成了这个样子,主1、主2都将能接受读写请求。
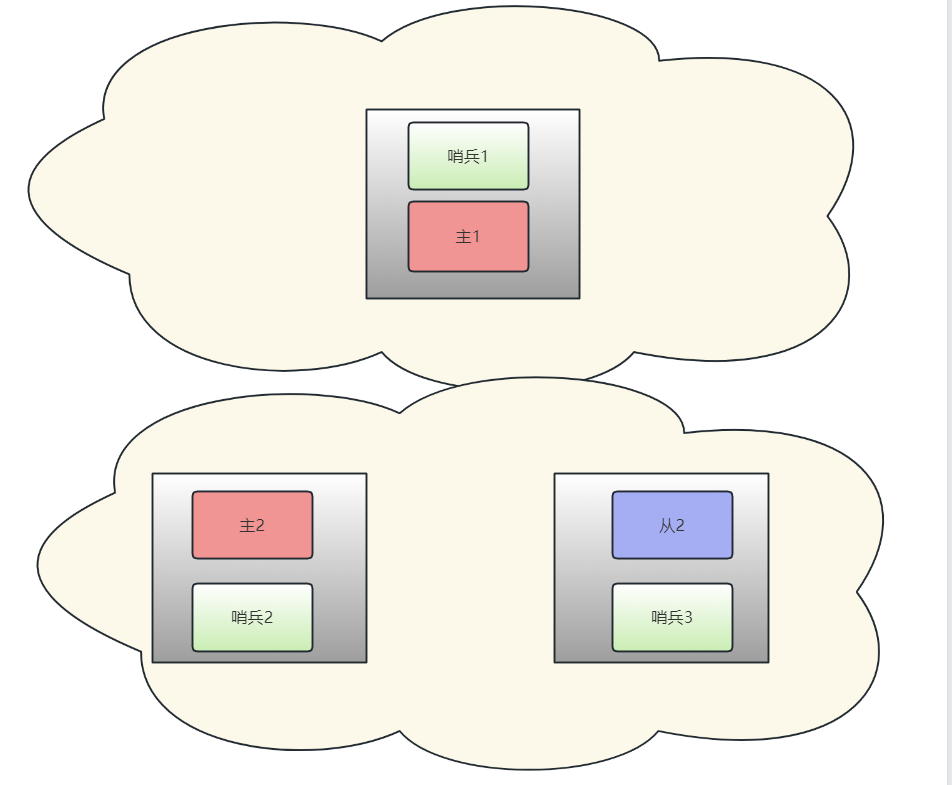
网络恢复后,主1会发现原来的从1已经被哨兵系统选举为新的主节点(主2),主1会自动降级成从节点。
此时,主1(变成从节点了)将会从主2开始同步数据:全量复制(如果数据差异较大)或部分复制(如果数据差异较小)
- 网络故障期间,从主1写入的数据会丢失。因为原来主节点1的数据在同步主2后,会被覆盖掉。
- 在数据未同步完成前,主1读取到的数据可能是不准确的。例如:主2上其实已经删除了,主1还没同步到,主1上读取的话还存在。
- 在数据未同步完成后,主1读取到的数据是准确的,此时主1数据与主2保持一致了。
上面的问题,可以通过以下配置解决。
# 主节点在接受写操作时,必须至少有一个从节点能够同步该写操作并确认成功
min-replicas-to-write 1
# 设置从节点与主节点的最大延迟时间(以秒为单位)。
# 如果从节点在指定时间内未能响应,主节点将停止接受新的写操作
min-replicas-max-lag 10
在正常情况下
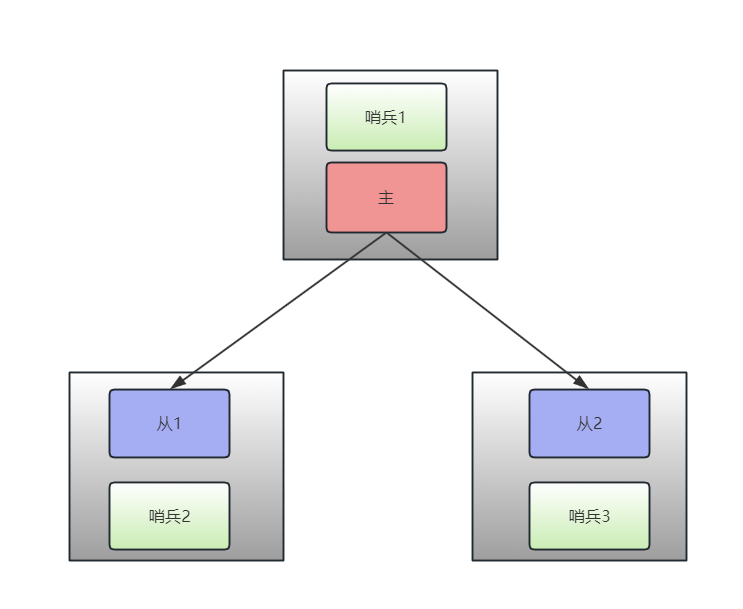
- 主节点在接受写操作时,会等待至少一个从节点(例如从3)确认成功。
- 如果从3在10秒内响应并同步数据,M1继续接受新的写操作。
网络分区情况下
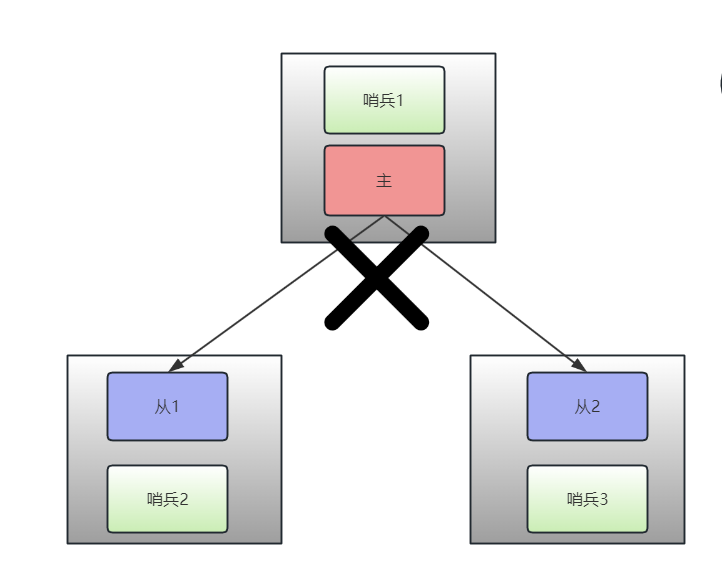
- 如果网络分区导致主1无法与从1、从2通信:
- 主1在写操作时无法得到从节点的确认,达到
min-replicas-to-write 1的条件。 - 超过
min-replicas-max-lag 10的时间,主1将停止接受新的写操作。 - 这样可以防止在网络分区期间继续写入M1导致的数据不一致。
- 主1在写操作时无法得到从节点的确认,达到
5.只用2个哨兵行不行?
非要说行也能行,但是风险也是很高的。
如果其中一个哨兵节点宕机,只剩下一个哨兵节点,无法形成多数同意进行故障转移。这会导致在主节点故障时,哨兵系统无法进行自动故障转移,集群变得不可用。
-
工作原理
- 哨兵节点负责监控主节点的状态,并在主节点故障时进行故障转移。
- 故障转移需要超过半数的哨兵节点同意(即Quorum机制)。
-
故障转移的局限性
- 单点故障风险:如果其中一个哨兵节点宕机,只剩下一个哨兵节点,无法形成多数同意进行故障转移。这会导致在主节点故障时,哨兵系统无法进行自动故障转移,集群变得不可用。
- 网络分区问题:如果哨兵节点之间的网络连接不稳定,可能导致哨兵节点无法互相通信,也会影响故障转移的决策。
1.3 集群Cluster
上面的哨兵模式看起来已经很不错了,但是为啥还有个集群模式?
不难发现哨兵模式存在以下缺点:
-
扩展性有限:哨兵模式虽然可以通过增加从节点来扩展读能力,但写能力仍然受限于主节点的性能。
-
无法水平扩展:主从和哨兵其实最终都是在翻来覆去同步同一份数据文件(就是给主节点增加副本),数据量大的时候,我加再多的节点都没有,压力还是大。
-
脑裂问题:尽管哨兵可以缓解脑裂问题,但在复杂的网络环境下,仍然可能发生脑裂和数据不一致的问题。
好,我们再来看看集群模式这的优点,先留个印象。
-
支持水平扩展:Redis集群模式支持数据分片,可以将数据分布到多个主节点上,实现水平扩展,既增加了读性能,也增加了写性能。
-
更高的可用性和容错性:通过分布式一致性协议(如RAFT),集群模式能够更好地处理节点失效和网络分区问题,保证数据的一致性和高可用性。
-
更大的数据存储能力:通过数据分片,可以存储比单个实例更多的数据。
所以,一般的项目用用哨兵已经够了,但是为了支持更大的项目和高并发的场景,我们需要选择到(切片)集群模式。
当然,集群模式配置肯定更复杂,运维起来也更难。
1.3.1 实现
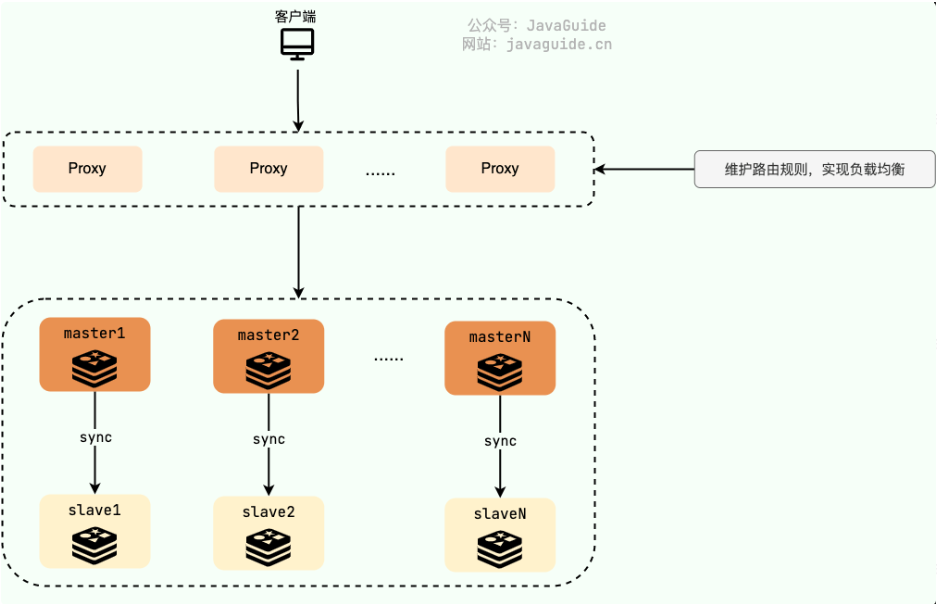
简单来说,集群模式就是部署多台Redis主节点,同时对外提供读/写服务。
然后将缓存数据相对均匀地分布在这些实例上,客户端的请求通过路由规则转发到目标 master 上。
好好好,又来抽象话术是吧。
我们简单理解下,就是用N个主从集群,然后呢,数据分散到这N个集群里。
好好好,你肯定要问,那我拆成N个主从的小集群,咋故障恢复呢。
额,这是简单的理解嘛,实际上肯定是有差别的。
比如说,Redis Cluster 中的从节点不提供读服务,仅作为备用节点,保障主节点的高可用(不要和主从复制的Redis集群搞混了)。
咱们一下子能想到的问题,Redis大哥肯定考虑到了,后文咱们慢慢学习。
先看下基本原理,内置了如此多的功能。
-
数据分片(Sharding)
- Redis Cluster将整个数据集分成16384个哈希槽(hash slots),并将这些槽分配给多个主节点(master)。
- 每个主节点管理一定范围的槽,例如:节点A负责槽0到5460,节点B负责槽5461到10922,节点C负责槽10923到16383。
-
主从复制(Replication):
- 每个主节点有一个或多个从节点(slave)作为备份。
- 从节点实时同步主节点的数据,用于读操作分担和故障恢复。
-
Gossip协议
- Redis Cluster使用Gossip协议在节点之间传播状态信息,确保每个节点都了解集群的拓扑结构和槽分配情况。
-
故障检测
- 集群中的每个节点定期向其他节点发送PING消息以检测其状态。
- 如果一个节点在指定时间内未响应PING消息,它将被标记为失效(fail)。
-
自动故障恢复
- 当主节点失效时,其他节点通过选举机制选出一个从节点作为新的主节点。
- 新的主节点接管失效主节点的槽,并继续处理读写请求。
- 故障恢复过程是自动的,无需人工干预。
用上集群后,想要扩展读写能力,直接加节点就完事。
在 Redis 3.0 之前,通常使用的是 Twemproxy、Codis 这类开源分片集群方案。
Twemproxy、Codis 就相当于是上面的 Proxy 层,负责维护路由规则,实现负载均衡。
到了 Redis 3.0 的时候,Redis 官方推出了分片集群解决方案 Redis Cluster 。
经过多个版本的持续完善,Redis Cluster 成为 Redis 切片集群的首选方案,满足绝大部分高并发业务场景需求。
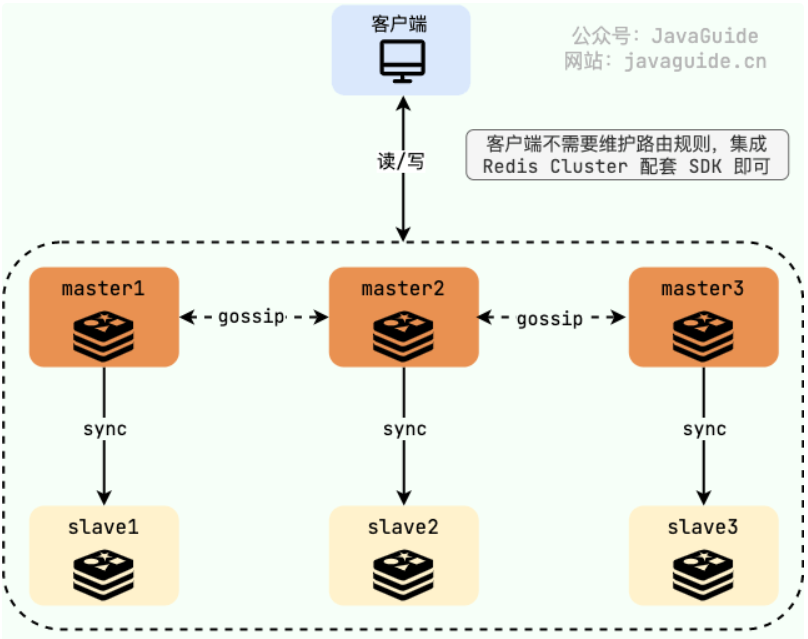
分片集群下,主节点和从节点的作用:
-
主节点(Master):负责处理写操作和部分读操作。
-
从节点(Slave):负责备份主节点的数据,并在主节点故障时接管其角色。
1.3.2 配置(3主3从)
好,1主1从肯定不ok吧?我们先讲下为啥不建议2主2从,原因还是因为不能自动故障恢复。
假设,master1、slave1、master2、slave2这么2主2从。
master2和slave2宕机了,集群中只剩下一个主节点master1,这不足以形成多数来同意进行故障转移,因此集群无法自动恢复。
这个时候由于m2和s2都无了,没有其他存的有它们的数据,这块肯定读不到了,但是这还不是最严重的。
- m1仍然在线,但由于无法形成多数,集群认为自己处于不安全状态,不再接受写请求。
- 导致整个集群的不可用,尽管部分数据仍然可以被读取。
看到没,没法写入了,这才是痛苦的点。
我们3主3从的时候,即便m2和s2宕机了,虽然它们的数据凉凉,但是起码能进行故障转移,后面读写能力不会受限,还能高可用。
下方演示一个3主3从的切片集群配置。
| 类型 | 端口 | 配置文件 | 日志文件 | 说明 |
|---|---|---|---|---|
| master1 | 6379 | redis1.conf | redis1.log | redis主节点1 |
| master2 | 6380 | redis2.conf | redis2.log | redis主节点2 |
| master3 | 6381 | redis3.conf | redis3.log | redis主节点3 |
| slave1 | 7379 | slave1.conf | slave1.log | redis从节点1 |
| slave2 | 7380 | slave2.conf | slave2.log | redis从节点2 |
| slave3 | 7381 | slave3.conf | slave3.log | redis从节点3 |
上述文件,位于/yang/config/redis-cluster目录下。
1.编辑配置文件
1.1 主节点1
编辑redis1.conf
port 6379
daemonize yes
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 5000
logfile "/yang/config/redis-cluster/redis1.log"
这里咋还配置了个文件nodes-6379.conf?
配置项cluster-config-file
- 用途:存储 Redis 集群的节点配置和状态信息。
- 作用:Redis 启动集群模式时,会使用此文件来记录和读取集群中各个节点的信息。包括节点的 ID、IP 地址、端口、角色(主节点或从节点)、分片槽位等。
1.2 主节点2
编辑redis2.conf
port 6380
daemonize yes
cluster-enabled yes
cluster-config-file nodes-6380.conf
cluster-node-timeout 5000
logfile "/yang/config/redis-cluster/redis2.log"
1.3 主节点3
编辑redis3.conf
port 6381
daemonize yes
cluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 5000
logfile "/yang/config/redis-cluster/redis3.log"
1.4 从节点1
编辑slave1.conf
port 7379
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7379.conf
cluster-node-timeout 5000
logfile "/yang/config/redis-cluster/slave1.log"
# 从节点是否支持写入操作
# replica-read-only no
1.5 从节点2
编辑slave2.conf
port 7380
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7380.conf
cluster-node-timeout 5000
logfile "/yang/config/redis-cluster/slave2.log"
1.6 从节点3
编辑slave3.conf
port 7381
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7381.conf
cluster-node-timeout 5000
logfile "/yang/config/redis-cluster/slave3.log"
2.启动各个实例
根据配置文件启动各个实例
# cd /yang/config/redis-cluster
redis-server redis1.conf
redis-server redis2.conf
redis-server redis3.conf
redis-server slave1.conf
redis-server slave2.conf
redis-server slave3.conf
3.创建redis集群
使用如下命令创建集群
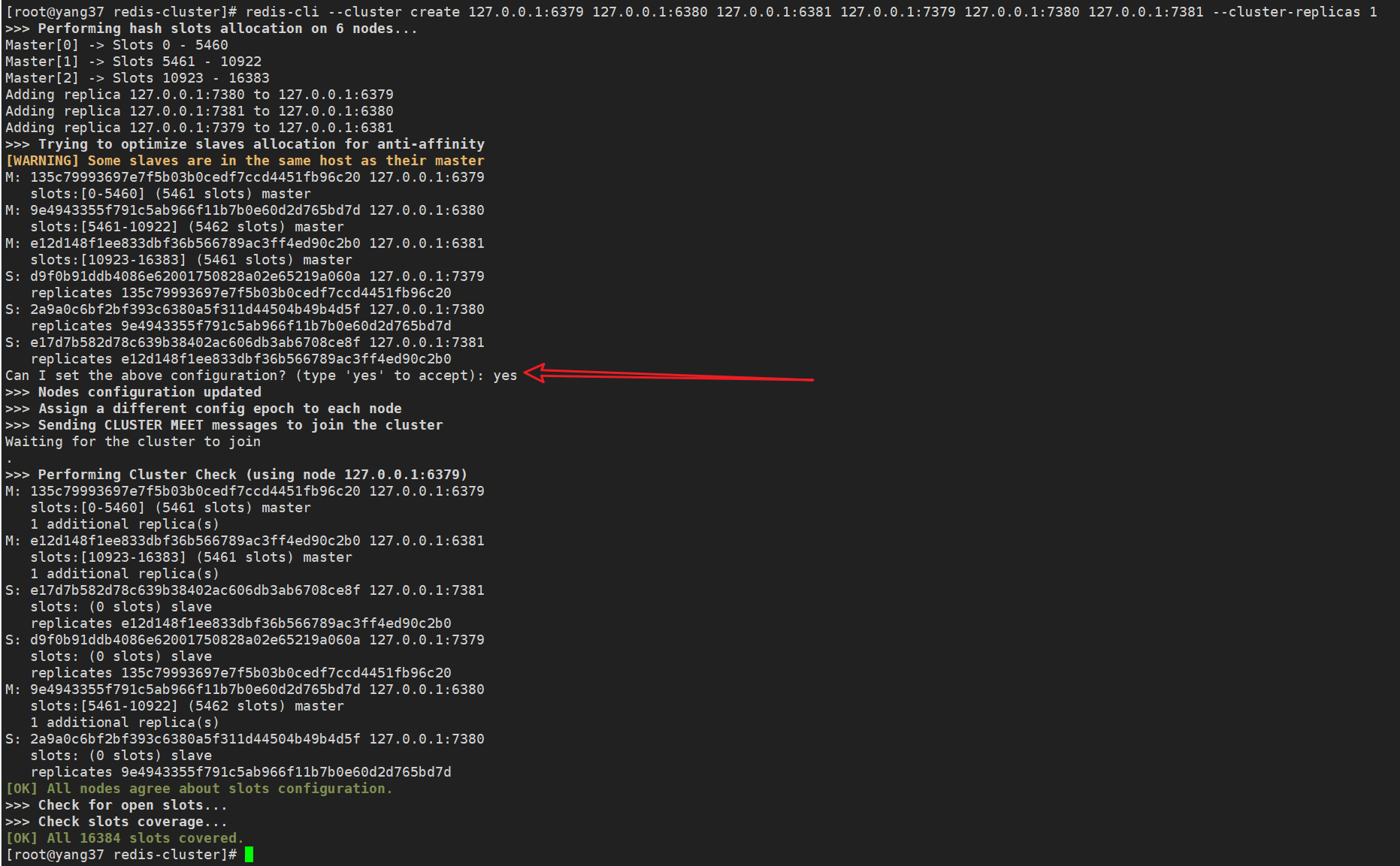
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:7379 127.0.0.1:7380 127.0.0.1:7381 --cluster-replicas 1
在创建 Redis 集群时,redis-cli --cluster create 命令会根据 --cluster-replicas 参数的值自动分配从节点,分配过程是按顺序自动进行的。
所以上方的命令,详细解释下就是:
- 每个主节点有一个从节点
- Redis 会按顺序将前 3 个实例(6379、6380 和 6381)作为主节点,后 3 个实例(7379、7380 和 7381)作为从节点。
- 127.0.0.1:7379 作为 127.0.0.1:6379 的从节点
- 127.0.0.1:7380 作为 127.0.0.1:6380 的从节点
- 127.0.0.1:7381 作为 127.0.0.1:6381 的从节点
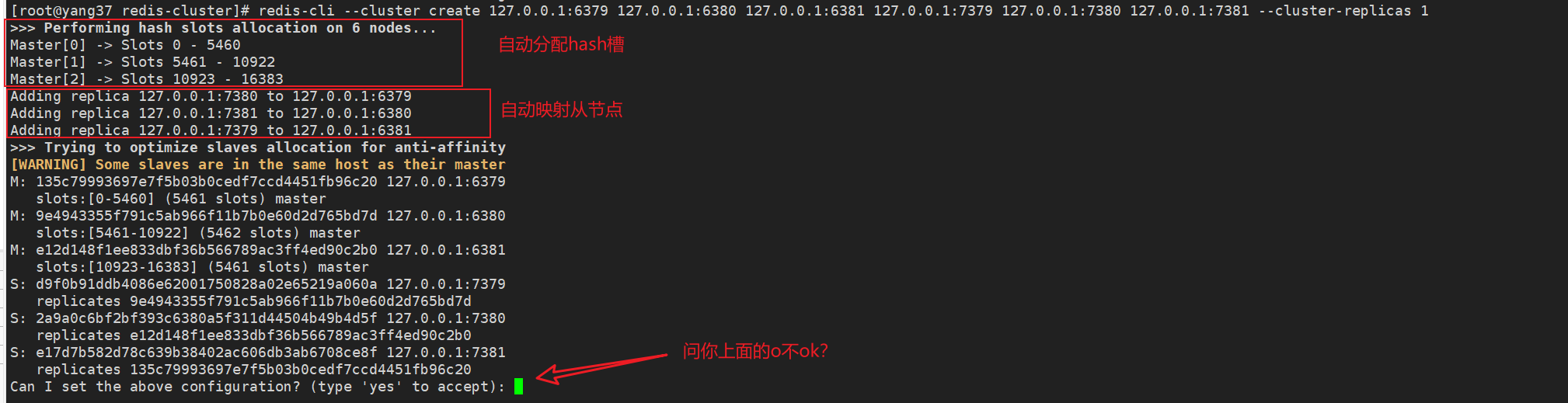
刚才的提示信息我们不妨复制出来解释下。
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
# Redis 集群将键分配到 16384 个哈希槽中,并将这些槽分配给主节点:
# Master[0] -> 槽 0 - 5460
# Master[1] -> 槽 5461 - 10922
# Master[2] -> 槽 10923 - 16383
# 这意味着三个主节点将平分 16384 个哈希槽。
Adding replica 127.0.0.1:7380 to 127.0.0.1:6379
Adding replica 127.0.0.1:7381 to 127.0.0.1:6380
Adding replica 127.0.0.1:7379 to 127.0.0.1:6381
# 127.0.0.1:7380 被分配为 127.0.0.1:6379 的从节点
# 127.0.0.1:7381 被分配为 127.0.0.1:6380 的从节点
# 127.0.0.1:7379 被分配为 127.0.0.1:6381 的从节点
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
# 尝试做反亲和性优化
# 告警给你,说有的主从节点运行在同一个机器上了。
M: 135c79993697e7f5b03b0cedf7ccd4451fb96c20 127.0.0.1:6379
slots:[0-5460] (5461 slots) master
M: 9e4943355f791c5ab966f11b7b0e60d2d765bd7d 127.0.0.1:6380
slots:[5461-10922] (5462 slots) master
M: e12d148f1ee833dbf36b566789ac3ff4ed90c2b0 127.0.0.1:6381
slots:[10923-16383] (5461 slots) master
# 主节点127.0.0.1:6379 (ID: 135c79993697e7f5b03b0cedf7ccd4451fb96c20),负责槽 0-5460 (共 5461 个槽)。
# 主节点127.0.0.1:6380 (ID: 9e4943355f791c5ab966f11b7b0e60d2d765bd7d),负责槽 5461-10922 (共 5462 个槽)
# 主节点127.0.0.1:6381 (ID: e12d148f1ee833dbf36b566789ac3ff4ed90c2b0),负责槽 10923-16383 (共 5461 个槽)
S: d9f0b91ddb4086e62001750828a02e65219a060a 127.0.0.1:7379
replicates 9e4943355f791c5ab966f11b7b0e60d2d765bd7d
S: 2a9a0c6bf2bf393c6380a5f311d44504b49b4d5f 127.0.0.1:7380
replicates e12d148f1ee833dbf36b566789ac3ff4ed90c2b0
S: e17d7b582d78c639b38402ac606db3ab6708ce8f 127.0.0.1:7381
replicates 135c79993697e7f5b03b0cedf7ccd4451fb96c20
# 从节点127.0.0.1:7379 (ID: d9f0b91ddb4086e62001750828a02e65219a060a)复制 127.0.0.1:6380 (Master ID: 9e4943355f791c5ab966f11b7b0e60d2d765bd7d)
# 从节点127.0.0.1:7380 (ID: 2a9a0c6bf2bf393c6380a5f311d44504b49b4d5f)复制 127.0.0.1:6381 (Master ID: e12d148f1ee833dbf36b566789ac3ff4ed90c2b0)
# 从节点127.0.0.1:7381 (ID: e17d7b582d78c639b38402ac606db3ab6708ce8f)复制 127.0.0.1:6379 (Master ID: 135c79993697e7f5b03b0cedf7ccd4451fb96c20)
嗯,出现了一个专业名词,反亲和性,你应该也猜到啥意思了。
在分布式系统中,反亲和性(Anti-Affinity)是一种策略,用于确保相关的系统组件(如主节点和从节点)不会部署在同一台物理主机上,这可以提高系统的容错能力和可靠性。
例如,如果一个主节点和它的从节点位于同一台主机上,那么该主机发生故障时,整个分片的数据都将不可用。然而,如果它们位于不同的主机上,那么即使一个主机故障,另一个主机上的副本仍然可用。
当然,上面的例子中,我们也可以手动设置从节点,例如:
- 先创建一个从节点为0的主节点集群
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 --cluster-replicas 0
- 为主节点单独添加从节点
redis-cli --cluster add-node 127.0.0.1:7379 127.0.0.1:6379 --cluster-slave --cluster-master-id <master-id-of-6379>
redis-cli --cluster add-node 127.0.0.1:7380 127.0.0.1:6380 --cluster-slave --cluster-master-id <master-id-of-6380>
redis-cli --cluster add-node 127.0.0.1:7381 127.0.0.1:6381 --cluster-slave --cluster-master-id <master-id-of-6381>
在这些命令中,<master-id-of-6379>、<master-id-of-6380> 和 <master-id-of-6381> 是在创建集群时得到的主节点 ID,通过以下命令获取。
redis-cli -c -h 127.0.0.1 -p 6379 cluster nodes
4.查看运行状态
# 查看集群整体信息
redis-cli -c -h 127.0.0.1 -p 6379 cluster info
# 查看集群节点信息
redis-cli -c -h 127.0.0.1 -p 6379 cluster nodes
4.1 查看集群整体信息
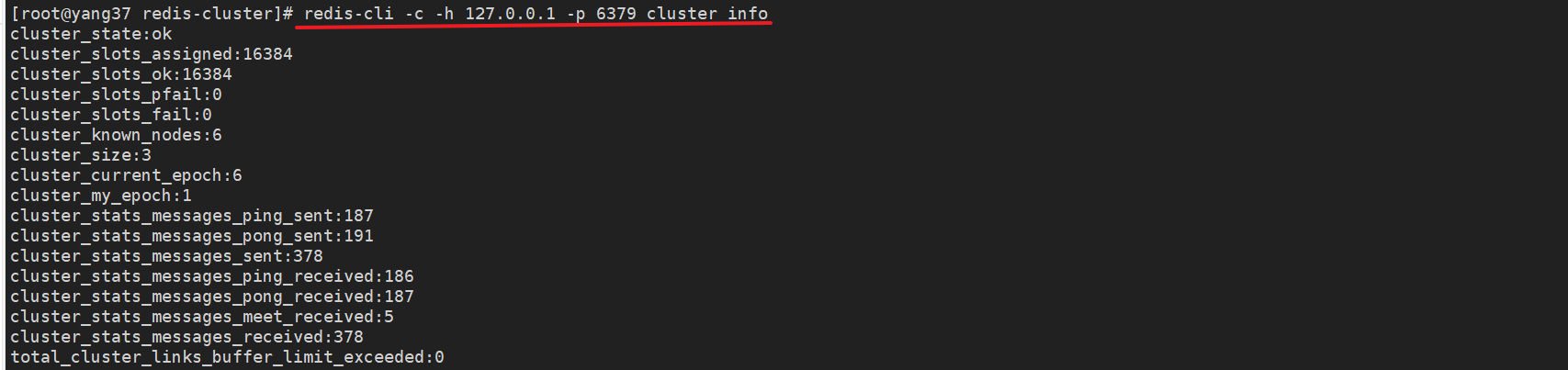
-
cluster_state:ok:集群状态正常。
-
cluster_slots_assigned:16384:所有 16384 个槽已被分配。
-
cluster_slots_ok:16384:正常的槽16384个(所有槽状态正常)。
-
cluster_slots_pfail:0:处于疑似故障状态的槽数为 0。
-
cluster_slots_fail:0:处于故障状态的槽数为 0。
-
cluster_known_nodes:6:集群中已知的节点数为 6(包括主节点和从节点)。
-
cluster_size:3:集群中的主节点数为 3。
-
cluster_current_epoch:6:当前集群纪元。
-
cluster_my_epoch:1:当前节点的纪元。
-
cluster_stats_messages_ping_sent:187:PING 消息发送次数。
-
cluster_stats_messages_pong_sent:191:PONG 消息发送次数。
-
cluster_stats_messages_sent:378:发送的消息总数。
-
cluster_stats_messages_ping_received:186:PING 消息接收次数。
-
cluster_stats_messages_pong_received:187:PONG 消息接收次数。
-
cluster_stats_messages_meet_received:5:MEET 消息接收次数。
-
cluster_stats_messages_received:378:接收的消息总数。
-
total_cluster_links_buffer_limit_exceeded:0:超过集群链接缓冲区限制的次数。
好,这里又有个关键字,epoch(纪元),这个要单独了解下,这里不细说。
在分布式系统中,epoch(纪元)是一个用来标识事件顺序的全局唯一的整数。它的概念类似于 Raft 算法中的 term(任期),用于在分布式环境中协调和管理节点间的一致性。
4.2 查看集群节点信息
redis-cli -c -h 127.0.0.1 -p 6379 cluster nodes

注意啊,我现在的节点信息是这样的。
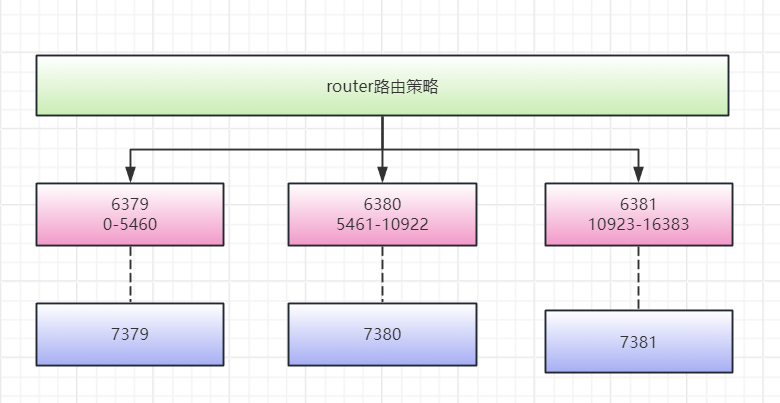
这里反应的是节点的信息,注意看图中的master和slave标识,刚好挑前两个解释下。
e12d148f1ee833dbf36b566789ac3ff4ed90c2b0 127.0.0.1:6381@16381 master - 0 1717730859177 3 connected 10923-16383
# 节点 ID:e12d148f1ee833dbf36b566789ac3ff4ed90c2b0
# 地址:127.0.0.1:6381
# 角色:master
# 槽:10923-16383
# 状态:connected
e17d7b582d78c639b38402ac606db3ab6708ce8f 127.0.0.1:7381@17381 slave e12d148f1ee833dbf36b566789ac3ff4ed90c2b0 0 1717730860580 3 connected
# 节点 ID:e17d7b582d78c639b38402ac606db3ab6708ce8f
# 地址:127.0.0.1:7381
# 角色:slave
# 复制的主节点 ID:e12d148f1ee833dbf36b566789ac3ff4ed90c2b0
# 状态:connected
5.验证集群
5.1 测试写入数据
# 连接到任意一个主节点
redis-cli -c -h 127.0.0.1 -p 6379
# 设置键值对
set key1 "value1"
set key2 "value2"
# 获取键值对
get key1
get key2
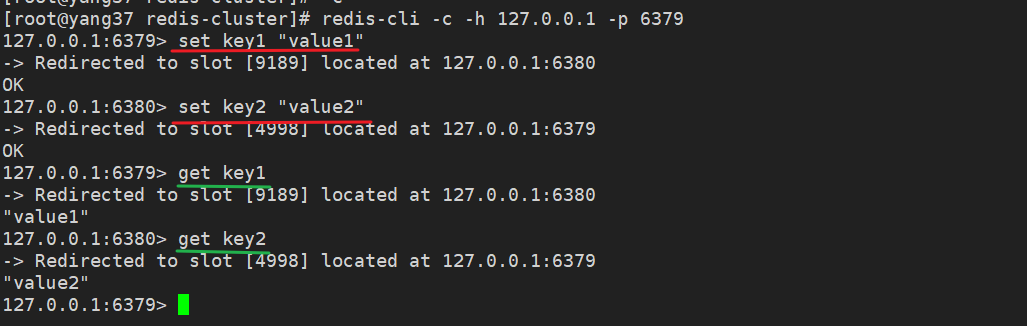
还记得刚才的槽位分配吗?
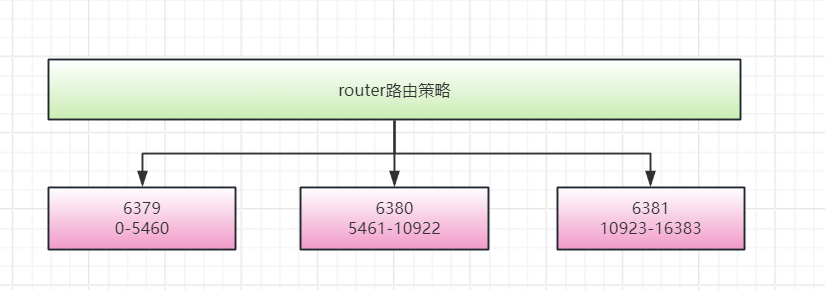
你可能会疑惑,哎,我6379不是负责0-5460吗?咋写key1的时候到9189去了。
哈哈,槽位这里强调的是存储。槽位这里强调的是存储,即最后数据落地到哪。
读/写的时候,假设计算出来的槽不在我这,我就联系对应的人,找它处理(将请求重定向到负责该哈希槽的节点)。
-
哈希槽分配:Redis 集群将 16384 个哈希槽分配给不同的主节点。每个主节点负责一个或多个连续的哈希槽范围。
-
数据映射:每个键根据 CRC16 哈希函数计算出的哈希值,被映射到一个特定的哈希槽。
-
数据存储:数据最终存储在负责该哈希槽的主节点上。如果当前节点不负责某个键的哈希槽,它会将请求重定向到负责该哈希槽的节点。
有没有注意到截图里还有段信息。
-> Redirected to slot [9189] located at 127.0.0.1:6380
# located at 127.0.0.1:6380
我想看xx数据在哪个槽的话,可以使用这个命令。
# 登录redis-cli执行
CLUSTER KEYSLOT key1
# 不登录一步到的话拼接上命令即可 -c是--cluster的简写
redis-cli -c -h 127.0.0.1 -p 6379 cluster keyslot key1

5.2 测试故障转移
注意啊,我现在的节点信息是这样的。
5.2.1 停止6379节点
# 停止某个主节点,测试故障转移
redis-cli -p 6379 shutdown
节点 127.0.0.1:7379检测到了节点 127.0.0.1:6379 的故障,并进行了故障转移(failover)
5.2.2 检查集群节点信息
# 检查从节点是否提升为主节点
redis-cli -c -h 127.0.0.1 -p 6380 cluster nodes

根据集群状态,主节点 127.0.0.1:6379 已被标记为失败,并且它的从节点 127.0.0.1:7379 被提升为新的主节点,负责管理槽位 0-5460。
135c79993697e7f5b03b0cedf7ccd4451fb96c20 127.0.0.1:6379@16379 master,fail - 1717732977551 1717732975000 1 disconnected
# 节点 ID: `135c79993697e7f5b03b0cedf7ccd4451fb96c20`
# 角色: 主节点
# 状态: 失败(fail),断开连接(disconnected)
# 负责的槽位: 未知,因为它已经失败了
5.1.3 重启6379节点
# 重启被停止的主节点并重新加入集群
redis-server redis1.conf
新启动的 Redis 实例(
127.0.0.1:6379)已经自动加入了集群,并且被配置为主节点127.0.0.1:7379的从节点。

某些场景下,比如你要来个新节点7382,咱们都配置完了,肯定就会疑惑,我集群跑的好好的,怎么把7382加进来呢?
这个时候,就要去研究下redis cluser相关的命令。
显然,这种场景,我们肯定要考虑这些事情,我来抛转引入一下。
- 新加入的是主节点还是从节点
- 主节点的话,hash槽肯定会变啊,怎么分配?
- hash槽变了,每个节点管的数据都不一样了,那么是不是得涉及到底层数据文件的迁移了,有没有性能影响?
1.3.3 问题点
进度问题,这里先不详写了,我得先去复习其他的了。
1.Redis Cluster 是如何分片的?
Redis Cluster 并没有使用一致性哈希,采用的是 哈希槽分区 ,每一个键值对都属于一个 hash slot(哈希槽) 。
Redis Cluster 通常有 16384 个哈希槽 ,要计算给定 key 应该分布到哪个哈希槽中。
- 先对每个 key 计算 CRC-16(XMODEM) 校验码
- 再对这个校验码对 16384(哈希槽的总数) 取模
- 得到的值即是 key 对应的哈希槽
客户端连接 Redis Cluster 中任意一个 master 节点即可访问 Redis Cluster 的数据,当客户端发送命令请求的时候。
- 先根据 key 通过上面的计算公示找到的对应的哈希槽
- 再查询哈希槽和节点的映射关系,即可找到目标节点。
- 如果哈希槽确实是当前节点负责,那就直接响应客户端的请求返回结果。
- 如果不由当前节点负责,就会返回
-MOVED重定向错误,告知客户端当前哈希槽是由哪个节点负责,客户端向目标节点发送请求并更新缓存的哈希槽分配信息。
1.Redis Cluster 的哈希槽为什么 是 16384 个?
CRC16 算法产生的校验码有 16 位,理论上可以产生 65536(2^16,0 ~ 65535)个值,为什么 Redis Cluster 的哈希槽偏偏选择的是 16384(2^14)个呢?
正常的心跳包会携带一个节点的完整配置,它会以幂等的方式更新旧的配置,这意味着心跳包会附带当前节点的负责的哈希槽的信息。
哈希槽采用 16384占空间 2k(16384/8),哈希槽采用 65536占空间 8k(65536/8)。
- 哈希槽太大会导致心跳包太大,消耗太多带宽;
- 哈希槽总数越少,对存储哈希槽信息的 bitmap 压缩效果越好;
- Redis Cluster 的主节点通常不会扩展太多,16384 个哈希槽已经足够用了。
2.Redis Cluster 如何重新分配哈希槽?
3.Redis Cluster 扩容缩容期间可以提供服务吗?
可以
为了保证 Redis Cluster 在扩容和缩容期间依然能够对外正常提供服务,Redis Cluster 提供了重定向机制,两种不同的类型:
- ASK 重定向 :可以看做是临时重定向,后续查询仍然发送到旧节点。
- MOVED 重定向 :可以看做是永久重定向,后续查询发送到新节点。
4.Redis Cluster 中的节点是怎么进行通信的?
Redis Cluster 是一个典型的分布式系统,分布式系统中的各个节点需要互相通信。
既然要相互通信就要遵循一致的通信协议,Redis Cluster 中的各个节点基于 Gossip 协议 来进行通信共享信息,每个 Redis 节点都维护了一份集群的状态信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号