Java-并发-并发的基本概念
0.背景
在经典八股文中,我们会背:
啊,hashmap是线程不安全的,concurrentHashMap是线程安全的。
然后呢,又背:
啊,为啥ConcurrentHashMap是安全的,因为加锁了。
好好好,接着八股:
啊,啥啥分段锁。
本文,结合实际例子来进行分析,这他妈的并发、并发问题,到底是在叭叭啥。
A.从map的size谈起
一切,从一个Hashmap的demo谈起。
public static void runDemo() {
Map<Integer, String> map = new HashMap<>();
// 创建两个线程同时向HashMap中添加元素
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
map.put(i, "");
}
});
Thread t2 = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
map.put(j, "");
}
});
t1.start();
t2.start();
try {
// 等待两个线程执行完毕
t1.join();
t2.join();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// 打印最终HashMap中的元素数量
System.out.println("map size: " + map.size());
}
在这段代码中,我们两个线程都在尝试往同一个map对象中放置元素。
然后,由于map的key值都是0-999,按照直觉,大不了放置的时候,t1或者t2的value被覆盖了呗。
由于都for的0~1000,即便存在可能覆盖的情况,最后输出的map.size()应该是1000?
我们来运行10次,看看结果。
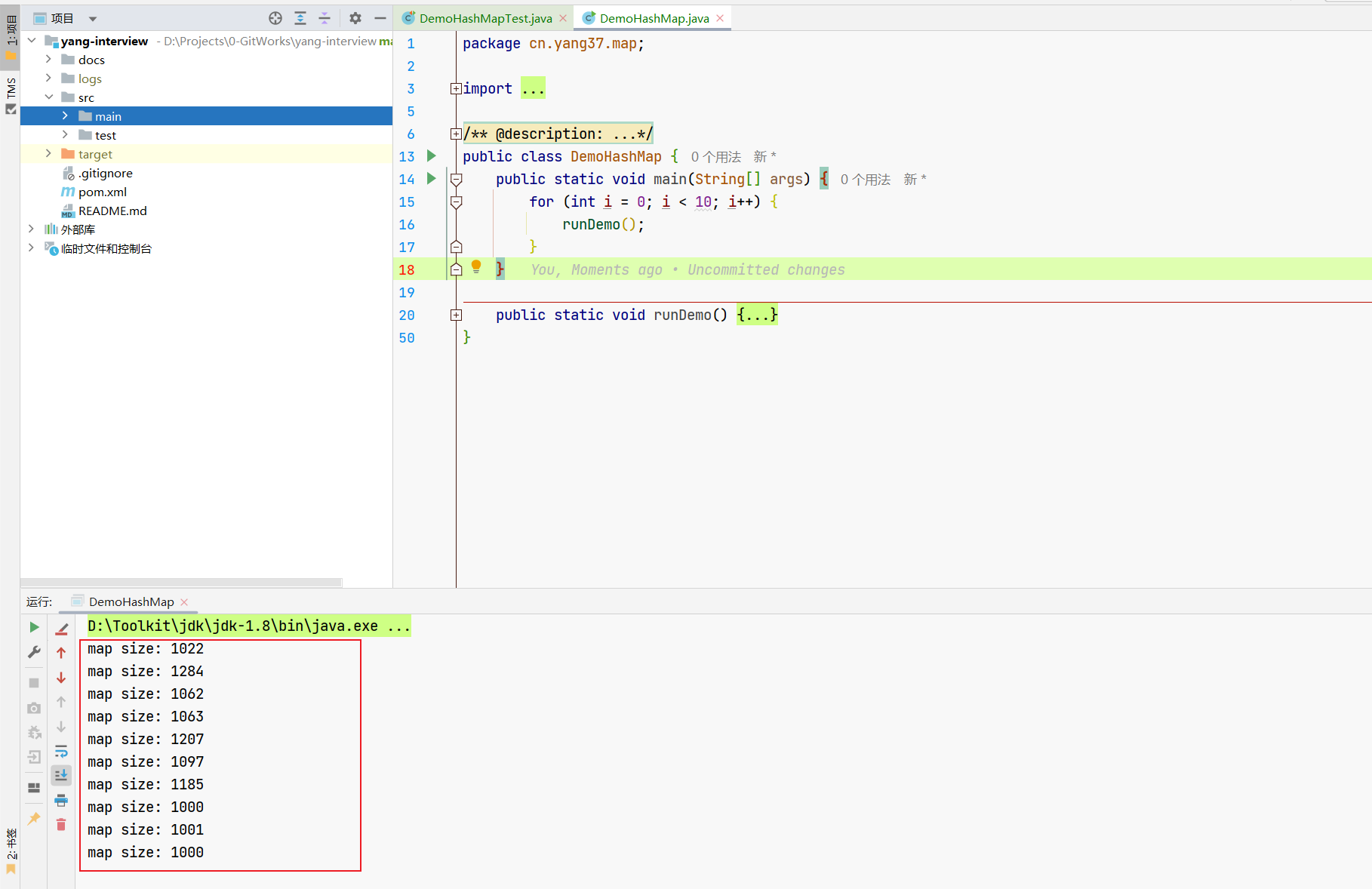
哈哈,奇怪了吧。
此处,先给出结论,后文再进行分析。
执行完后,元素的确是1000个,但是用来记录元素个数size值可能是不对的。
a.元素的确是1000个
map中的元素的确是1000个,debug可以看到。
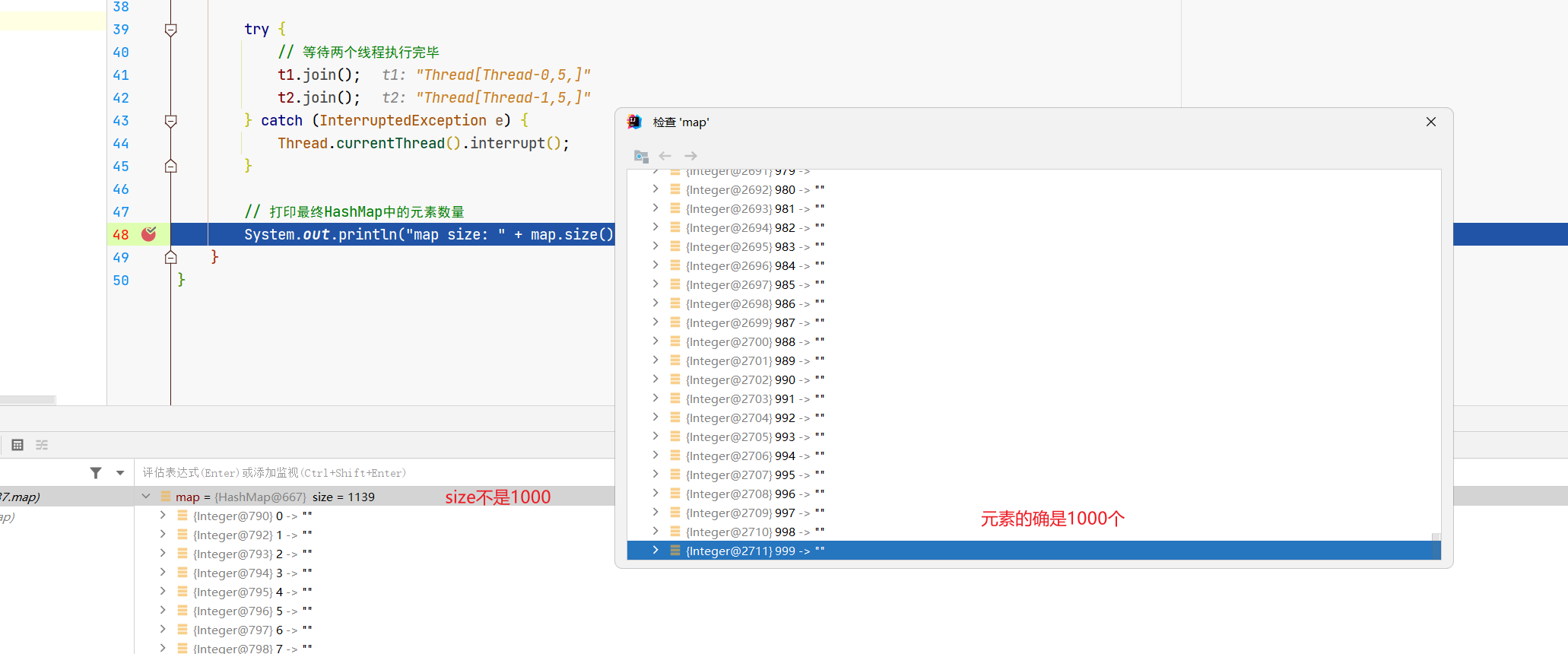
b.Map的size值可能不正确
元素个数正确,但是输出的map.size()可能不对。
我们看下size()方法,直接返回size属性值。
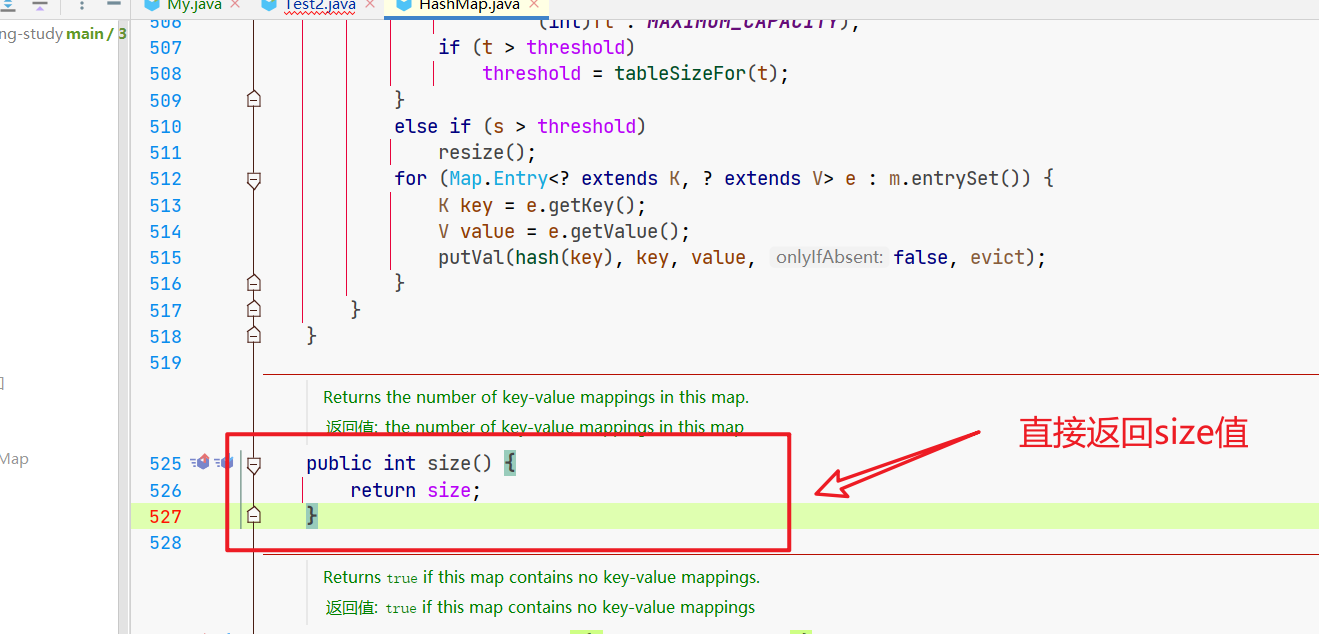
size属性如何定义的?

transient关键字你可以先忽略,序列化相关的。
c.分析
有没有get到我的点?就是实际情况下呢元素是1000个没问题,但是用来记录元素个数的这个size值可能是不对的。
咱来看看是怎么put的。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
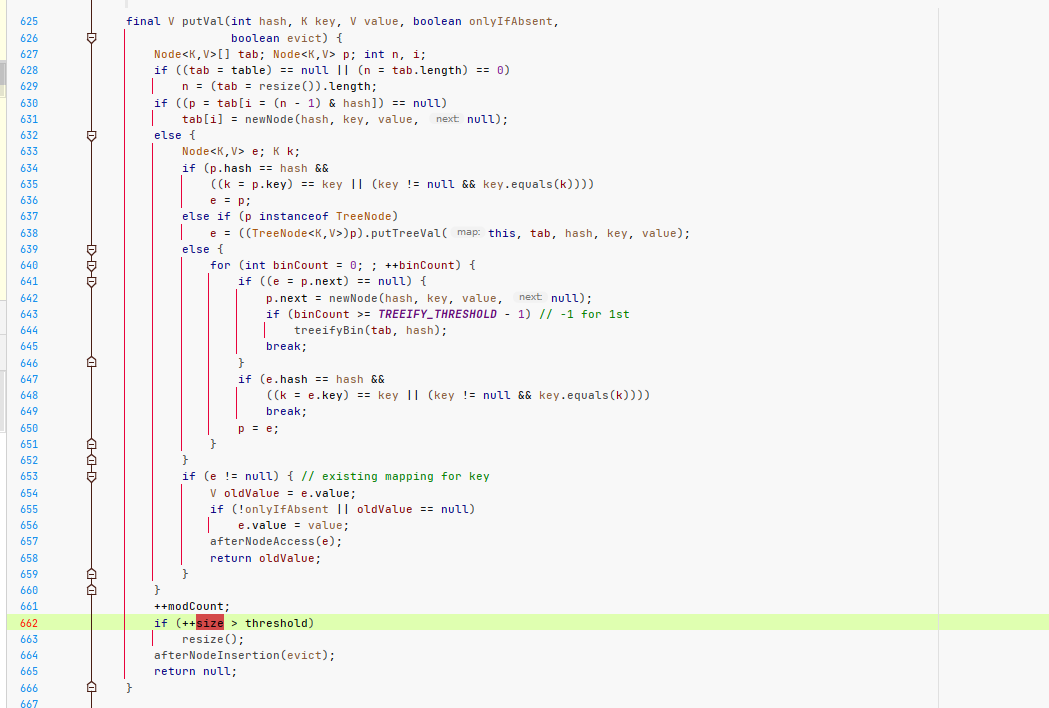
什么鸟代码,太复杂了,好,不重要,我来给你圈下。
我的idea做了配置,变量读取的时候是绿色,变量做了修改的时候是红色,可以参考我这篇文章:IDEA中高亮显示变量的使用位置和赋值位置
你可以看到,put方法里size就一个红色的地方。
我强调这个干嘛?
意思就是,别管那么多代码了,关注这个size就行了,反正就是这个方法里在给他在++i这种操作呗,然后从结果而知,出问题了。
那么,我们是不是很简单的来复现出一个最小的测试用例。
package cn.yang37.map;
/**
* @description:
* @class: DemoHashMap2
* @author: yang37z@qq.com
* @date: 2024/5/10 22:50
* @version: 1.0
*/
public class DemoHashMap2 {
private int count = 0;
void add() {
++count;
}
static void test() throws InterruptedException {
DemoHashMap2 map2 = new DemoHashMap2();
Thread thread1 = new Thread(
() -> {
for (int i = 0; i < 1000; i++) {
map2.add();
};
}
);
Thread thread2 = new Thread(
() -> {
for (int i = 0; i < 1000; i++) {
map2.add();
};
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(map2.count);
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
test();
}
}
}
- 在这个类中,我们定义了个成员变量count,然后add()就是递增而已。
- test()方法中,我们新建两个了两个线程,分别做了一千次增加操作,理想情况下结果应该是2000。
在main方法中做了10次测试,看看结果。
嗯,这几次怎么和2000对不上了?
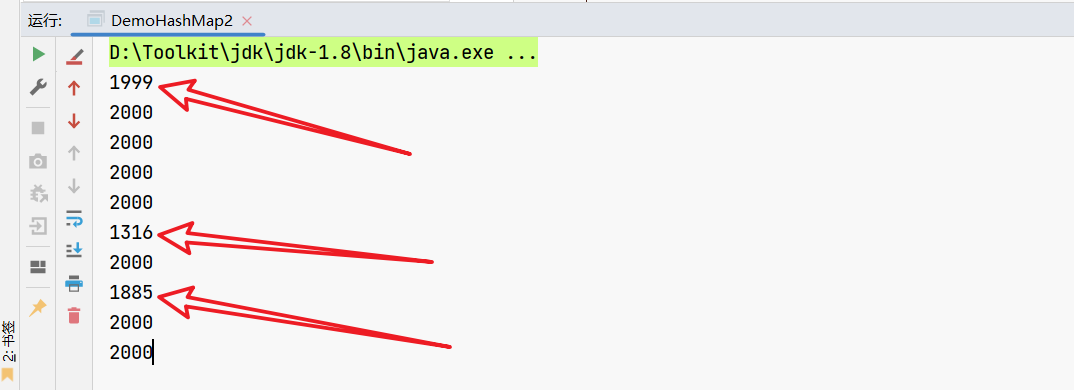
先不管为啥,咱现在起码能知道,这个++操作可能是有问题的。
1.并发、并行
线程安全,经常又叫什么并发问题,我先来谈谈我对并发和并行的理解。
1.1 并行
并行很好理解,就是真的可以同时做事情。而且理想状态下,最优解当然是可以同时做。
但是很多时候,却没法这么理想。
打王者的时候,作为一个两千分的打野选手,我总是恨自己不能同时打红蓝buff,野区没有减伤机制前,我露露总容易被可恶的老虎反野。
要是能并行就好了,就是我能有个分身,哎,对,两个我,同时打,多爽。
显而易见,这是不可能的,我也没有两个脑子。
1.2 并发
并发又是怎么来的呢?
假设我们现在只有一个cpu,我们都知道cpu和io之间存在效率冲突,cpu快,io慢。
现在要处理3个任务,每个任务内有读取数据、计算数据、展示数据这几个步骤,分别需要5s、0.2s、3s。
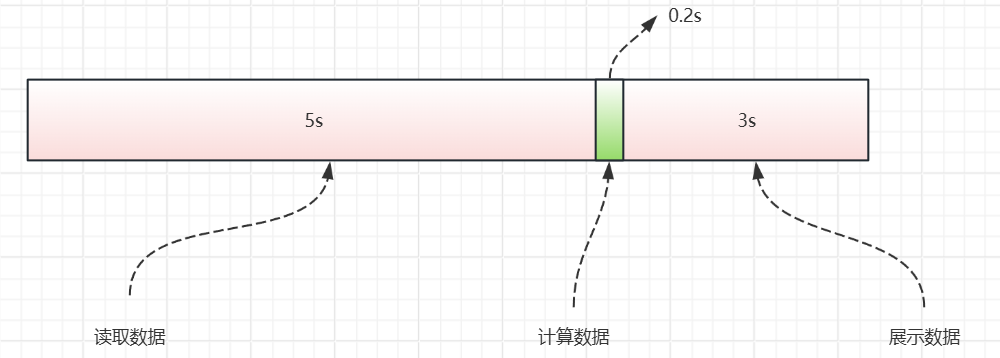
现在多个任务,假设让它们顺序执行。
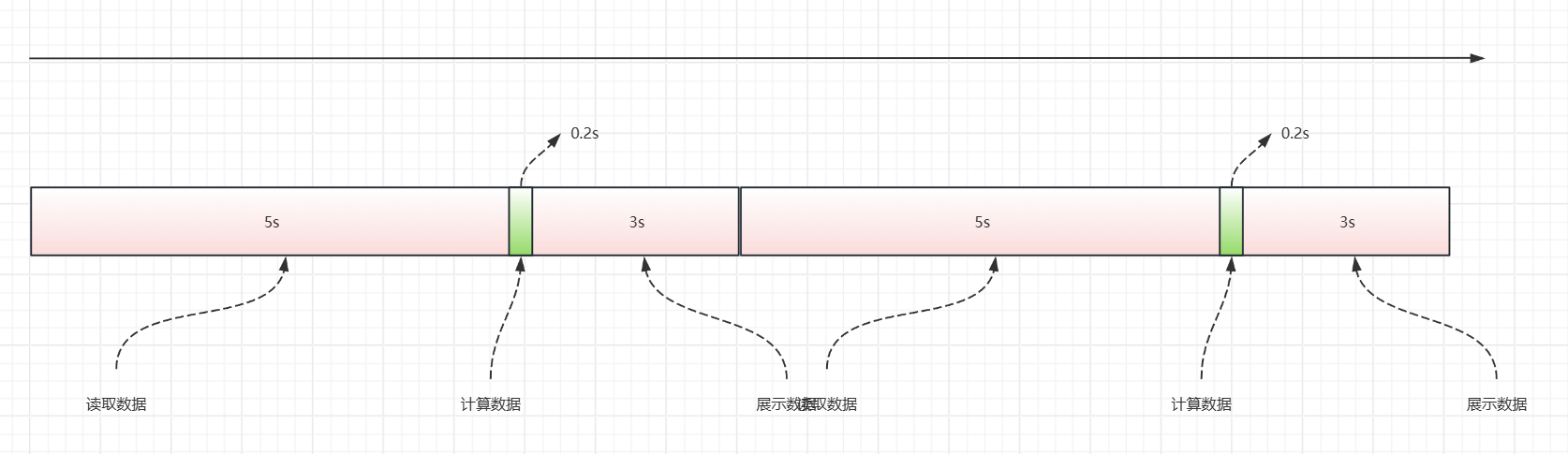
从整体角度来看,中间的5s、3s它太久了,cpu它经常是闲着没事干在那里发呆。
啊?cpu这么好的东西,你忍心让它闲着吗,不得狠狠压榨吗。
-
虽然,单个任务中,
读取数据、计算数据、展示数据三个步骤的时间我无法优化。 -
但是,从整体角度,我可以让cpu尽量的不闲着。
怎么让cpu不闲着?那就是交出cpu的使用权呗,咱用完了,就给别人用。
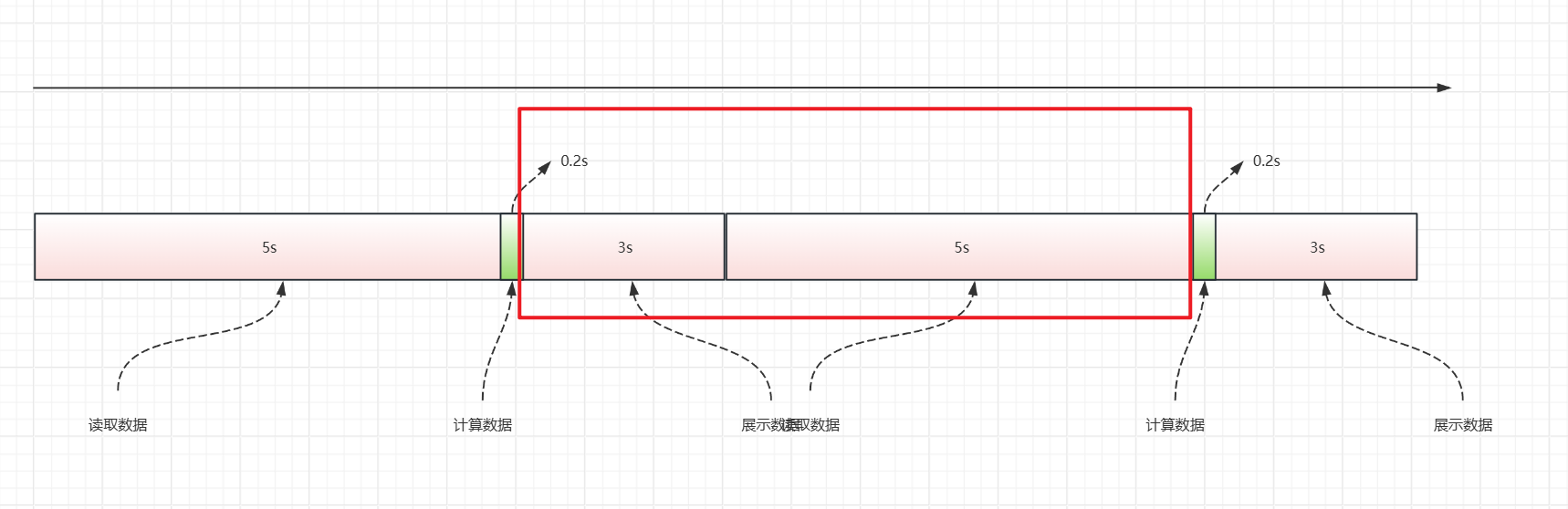
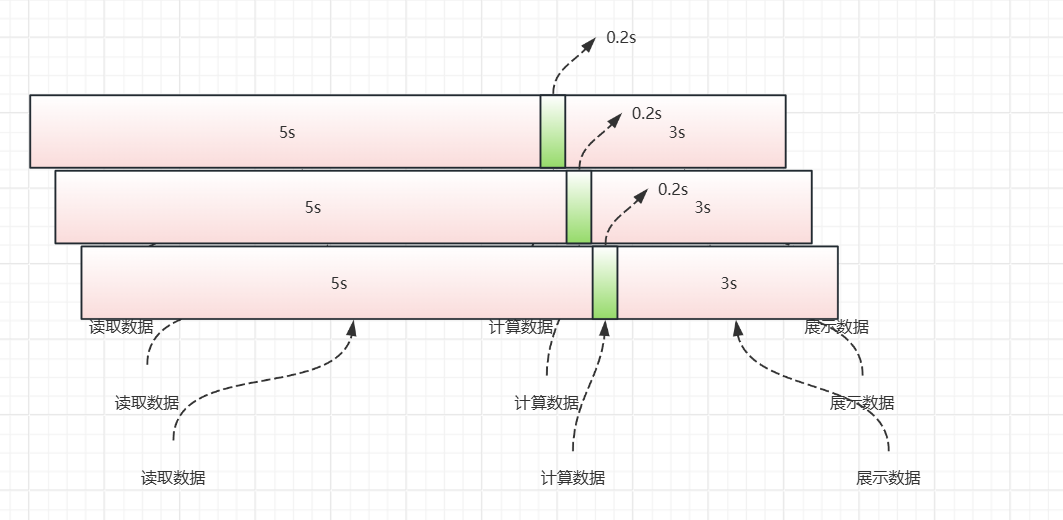
实际情况下,任务可能是几千几万个,他们经常是前前后后的先后开始了,总有人已经读取好数据了,然后渴望着cpu。
按照这种思想,cpu就能得到更好的利用,优化我们这个效率不匹配的问题。
并发,更像是逻辑层面的一种概念,强调的是同时处理多个任务的能力,只是人为角度看来像是在同时处理一样。
当然,真的不能并行吗?嗯,也很简单,我们可以再加一万个cpu嘛。
2.字节码
字节码含义:Java虚拟机指令集
回到最开始的示例,在代码中,为什么多线程操作变量i的增加操作看起来这么魔幻?
其根本原因就是i值变化的这个++i不是一个原子操作。
查看下字节码,可以看到这种信息。
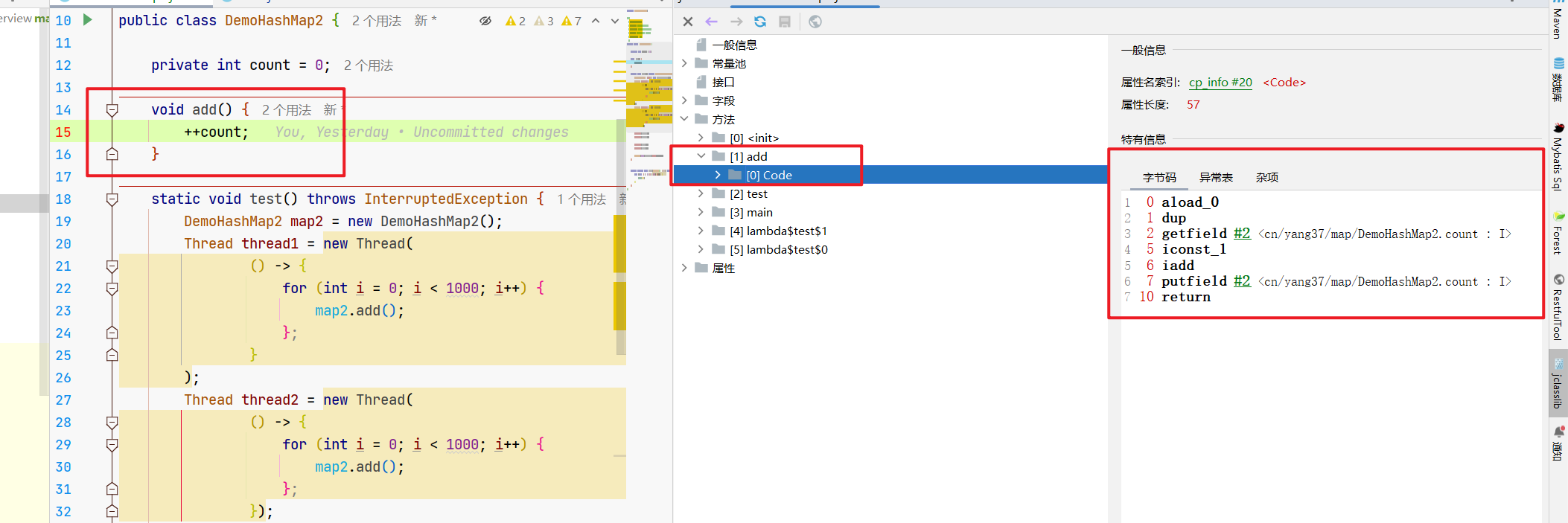
啥玩意,看不懂对吧。没关系,不影响我们的理解,起码咱们可以看出来。
看似只有一行的++i,实际上是分了很多个步骤在执行。
解析下具体的语法:
0: aload_0
加载当前对象的引用到操作数栈顶。在实例方法中,aload_0 用于加载 this 引用,因为实例方法需要访问调用该方法的对象的状态(即实例变量)。
1: dup
复制栈顶值。这里复制的是 this 引用,目的是因为接下来的操作需要使用 this 引用两次:一次用于获取字段,一次用于设置字段。
2: getfield #2 <cn/yang37/map/DemoHashMap2.count : I>
从对象中获取字段 count。此操作将会消耗之前的一个 this 引用,并将字段值 count 推送到栈顶。
5: iconst_1
将常数 1 推送到栈顶。
6: iadd
弹出栈顶的两个数(当前 count 值和 1),执行加法操作,结果(count + 1)重新推送到栈顶。
7: putfield #2 <cn/yang37/map/DemoHashMap2.count : I>
将栈顶的值(新的 count 值)存储回对象的 count 字段。这个操作同样需要一个 this 引用,这就是为什么之前需要 dup 操作,以保留 this 引用的一个副本。
10: return
从方法返回。
好,关注下这3步:
2: getfield #2 <cn/yang37/map/DemoHashMap2.count : I>
从对象中获取字段 count。此操作将会消耗之前的一个 this 引用,并将字段值 count 推送到栈顶。
5: iconst_1
将常数 1 推送到栈顶。
6: iadd
弹出栈顶的两个数(当前 count 值和 1),执行加法操作,结果(count + 1)重新推送到栈顶。
现在我们是两个线程1和2在对变量count执行递增的操作。
问题来了,假设线程1在刚执行完3个步骤中的第一步,就要交出cpu,进行线程中断和切换了,会出现什么问题?
现在用+1这个步骤来说明
- 线程1执行
getfield- 线程1执行到
getfield,读取count的当前值,此时count为0,它将这个值放到自己的操作数栈顶。
- 线程1执行到
- 线程1切换到线程2
- 在线程1增加
count之前,操作系统中断线程1的执行,切换到线程2。
- 在线程1增加
- 线程2完整执行
add方法- 线程2也从头开始执行
add方法,执行getfield读取count的当前值(仍为0,因为线程1还没来得及修改)。 - 线程2继续执行
iconst_1和iadd,将count从0增加到1。 - 线程2执行
putfield,将新值1写回count。
- 线程2也从头开始执行
- 线程2切换回线程1
- 线程1恢复执行。由于它在栈顶已经有
count的旧值0,接着执行iconst_1和iadd,也将count从0增加到1。 - 线程1执行
putfield,尝试将新值(1)写回count。
- 线程1恢复执行。由于它在栈顶已经有
一切都是合理的吧,两个线程都没有乱搞吧,就是读取然后增加。
那结果会是怎么样?
在这个例子中,尽管两个线程都尝试将 count 增加1,由于它们都从同一个原始值0开始计算,最终 count 只增加到了1,而不是正确的2。
这种问题称为丢失更新,是并发编程中常见的问题之一,源于没有适当的锁或同步机制来保护共享资源。
哇靠,丢失更新,关键字呀,熟悉吧,这些场景都是类似的,来复习下咱们Mysql中写-写场景下的2类丢失更新。
- 第一类丢失更新
这通常发生在一个事务回滚时,它撤销了另一个并发事务所做的更新。
例如,事务 A 更新了一行,然后事务 B 也更新了同一行。如果事务 A 回滚,它可能会撤销事务 B 的更新,这是因为 A 的更新被视为最终状态。
- 第二类丢失更新
发生在两个事务都试图更新同一数据行,并且第二个事务的写操作覆盖了第一个事务的写操作的场景中。
这通常是因为没有适当的锁定策略或锁定级别太低,使得两个事务都未意识到对方的存在。
好,现在咱们好像更清楚一点问题的原因了。
思考下,根本原因是什么,根本原因就在于,我们是知道这个场景下,count变量是个临界变量,但是计算机它不知道啊。
步骤是什么:读取、增加、写入
刚才的分析里不就是线程1读取完被中断了,然后线程2执行了(读取、增加、写入),线程1接着拿着旧值做了增加和写入吗。
开始有点感觉了,哈,冲突点在哪里?
- 哇靠,线程1你不知道线程2它都把值更新了吗?
- 哇靠,线程2你不能等线程1先算完吗,加1这种easy的操作都不能搞成个原子性的嘛?
嗯,这就是解决方案。
3.共享变量
从前面的例子中可以看到,根本原因在于,某些场景下,我们对变量是有要求的,刚才我们不是有个疑惑的点,就这种+1的操作不能搞个原子性的嘛?
哈哈,咱们都知道,有得必有失,原子性的东西,必然涉及到更多的成本,我必须强制的占用了这个变量,直到我搞定一切。
回过头来看,有点顾头不顾脚了哦。除了这种特殊的场景,大部分时间,咱们并不会有这个问题。
为什么这篇文章要写这个东西啊,平时咱们怎么不研究这个点?
单线程没问题吧?多线程各自请求两个api问题也不大吧?
根本原因是,多线程背景下,我们遇到了这种竞争资源的场景,产生了竞态。
先来分析下,常见的风险点,即,并发场景下,哪些地方可能遇到这个竞态。
这不就是在讨论,多线程里面,哪些玩意是可以共享的。
共享通常指的是允许多个线程访问和操作同一个内存区域或资源。
| 变量类型 | 存储位置 | 线程共享性 | 线程安全性 | 安全策略 |
|---|---|---|---|---|
| 局部变量 | 栈 | × | √ | 无需同步 |
| 成员变量 | 堆 | √ | × | 使用 synchronized,原子类 |
| 静态变量 | 堆的静态区 | √ | × | 使用 synchronized,原子类 |
| 线程局部变量 | 特定于线程 | × | √ | 使用 ThreadLocal |
volatile 变量 |
堆 | √ | 有条件 | 适用于简单操作,非复合操作需要其他同步 |
好,经典八股来了,线程安全问题是发生在JVM的哪块局域的啊?
所以关键点在哪里:它的位置多个线程会共享吗?
不过要注意怎么说哦,比如方法区是线程共享的,方法区里的数据在最开始就被设计成了线程安全的。但是核心是什么,如果没在最开始就提前这样设计好,方法区就是线程不安全的了。
哪些地方可能有线程安全问题?
我理解的核心就是竞态+共享,不过你都不能共享如何来竞态呢。
来个抽象的玩意,比如说,车位,公共车位都能停吧?共享的吧,有竞争条件吧?只不过你不傻,知道别人停一半撞上去要赔钱,咱们能线程安全的前提是别人停进去后出来了。
所以写代码的时候如何考虑,就是思考,这个东西可能被多个线程同时用到吗?然后再思考存不存在同时竞争。
就比如,我开个多线程不停地给你发请求,别的啥也不做,用得着考虑线程安全吗?当然不。
3.1 局部变量
线程安全性:由于局部变量只能被所在线程访问,它们自然是线程安全的,不需要额外的同步措施。
局部变量是在方法内部定义的变量。它们是线程安全的,因为每个线程调用一个方法时,局部变量都存储在各自线程的栈内存中。这意味着每个线程有自己的局部变量副本,其他线程无法访问这些局部变量。
3.2 成员变量(实例变量)
线程安全性:如果多个线程可能会改变同一个对象的成员变量,则这些变量必须通过同步机制(如
synchronized关键字或使用原子类)来保证线程安全。
成员变量是定义在类中但在方法外的变量。它们存储在堆内存中,并且被类的所有实例共享。如果多个线程访问同一个对象的成员变量,就必须小心处理线程安全问题。
3.3 静态变量
线程安全性:静态变量的线程安全性问题类似于成员变量。如果静态变量被多个线程访问和修改,也需要采用适当的同步措施。
静态变量也是定义在类中的变量,但它们用 static 关键字修饰。静态变量在类加载时被初始化,且在堆内存中的静态区域存储。所有的类实例共享同一个静态变量。因此,它们在多线程环境下是共享的。
3.4 线程局部变量(Thread Local)
线程安全性:
ThreadLocal变量提供了很好的线程隔离性,因此它们是线程安全的。这使得ThreadLocal非常适合于保存线程的上下文信息,比如用户会话或事务信息。
ThreadLocal 变量提供了一种线程封闭的机制,通过这种机制,每个线程可以访问到自己的一个独立副本,其他线程则不能访问。
3.5 Volatile 变量
线程安全性:
volatile变量适用于一种非常特定的情况。变量的写入操作不依赖于当前值,或只有单一的线程修改变量值,而其他线程只读取变量。对于复合操作(如递增),volatile不能保证线程安全。
使用 volatile 关键字修饰的变量可以确保每次变量的访问都是从主内存中进行的,而不是从线程的私有内存(缓存)。这确保了变量的可见性,但不保证操作的原子性。
4.解决
回顾之前的问题,很容易有些经典的解决方案。
此处先列出下,详细的内容,在[Java-线程-并发解决方案]展开。
4.1 synchronized
synchronized 是Java中的一个关键字,用于提供同步机制,保证多线程环境下对共享资源的安全访问。
通过使用 synchronized,Java虚拟机(JVM)保证同一时间内只有一个线程可以执行被 synchronized 保护的代码块或方法。
- 方法同步
可以直接在方法声明上使用
synchronized关键字,这样整个方法体成为同步区域。
public synchronized void method() {
// 同步方法
}
- 代码块同步
public void method() {
synchronized (this) {
// 同步代码块
}
}
4.2 ReentrantLock
ReentrantLock 是 java.util.concurrent 包提供的一个高级工具,提供与 synchronized 相似的同步功能,但增加了更多的灵活性。
它允许尝试锁定(tryLock),定时锁定以及中断等待锁的线程。
private final ReentrantLock lock = new ReentrantLock();
public void method() {
lock.lock();
try {
// 访问或修改共享资源
} finally {
lock.unlock();
}
}
4.3 Volatile
volatile 关键字确保了变量的可见性,通过禁止指令重排优化,使得一个线程修改的值对其他线程立即可见。
适用于一写多读的场景,但不适合作为原子性操作。
private volatile boolean flag = false;
public void reader() {
if (flag) {
// 执行某些操作
}
}
public void writer() {
flag = true;
}
4.4 原子变量
Java 的 java.util.concurrent.atomic 包提供了一系列的原子类,如 AtomicInteger、AtomicLong 等,用于无锁的线程安全编程。这些类利用 CAS(比较并交换)操作来实现线程安全的更新操作。
private final AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet();
}
4.5 并发集合
java.util.concurrent 包还提供了线程安全的集合类,如 ConcurrentHashMap、CopyOnWriteArrayList 等,这些集合内部管理了相关的同步机制,提供了比传统同步集合更好的并发性能。
Concurrent译为并发
Map<Integer, String> map = new ConcurrentHashMap<>();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号