爬取爱奇艺电影热播榜数据分析与可视化处理
一.主题式网络主题式网络爬虫设计方案
1.爬虫名称:爬取爱奇艺电影热播榜
2.爬虫爬取的内容:爬取爱奇艺电影热播榜数据。
3.网络爬虫设计方案概述:
实现思路:通过访问网页源代码,使用soup.find_all正则表达爬取数据,对数据进行保存数据,再对数据进行清洗和处理,数据分析与可视化处理。
技术难点:对一些库的使用还不太了解,爬取的内容需要分析处理。
二、主题页面的结构特征分析
1.主题页面的结构与特征分析:通过页面的结构分析,可以得到各个数据之间的便签都有关联的关系,电影名标签分布在p class="site-piclist_info_title"中,评分标签分布在span class="score"中,电影描述标签分布在p class="site-piclist_info_describe"中。
2.Htmls页面解析
网页url = 'http://www.iqiyi.com/dianying_new/i_list_paihangbang.html'


三、网络爬虫程序设计
1.数据爬取与采集
import requests from bs4 import BeautifulSoup import pandas as pd def get_html(url): headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}#伪装爬虫 try: #发送get请求 html = requests.get(url,headers = headers) #配置编码 html.encoding = html.apparent_encoding if html.status_code == 200: print("成功过获取源代码") except Exception as e: print("获取源代码失败:%s"% e) return html.text url = 'http://www.iqiyi.com/dianying_new/i_list_paihangbang.html' html = get_html(url) #提取HTML并解析想获取的数据 soup = BeautifulSoup(html, 'html.parser') #爬取电影名 #建立一个电影名列表Film_name Film_name = [] a = soup.find_all('a', pos = '2') for name in a: Film_name.append(name.text) #爬取评分 #建立一个评分列表Score Score = [] b = soup.find_all('span', class_ = 'score') for score in b: Score.append(score.text) #爬取电影描述 #建立一个电影描述列表Describe Describe = [] c = soup.find_all('p', class_ = 'site-piclist_info_describe') for describe in c: Describe.append(describe.text) #创建一个空列表lt lt = [] #爬取前25组电影数据,保存到列表lt中 print("{:^4}\t{:^5}\t{:^7}\t{:^8}".format('排名', '电影名', '评分', '电影描述')) for i in range(25): #输出前25组数据 print("{:^4}\t{:^5}\t{:^7}\t{:^8}".format(i+1, Film_name[i], Score[i], Describe[i])) lt.append([i+1, Film_name[i], Score[i], Describe[i]]) #创建DateFrame df = pd.DataFrame(lt,columns = ['排名', '电影名', '评分', '电影描述']) #保存文件,数据持久化 df.to_csv('爱奇艺电影热播榜.csv')

csv文件保存成功

2.对数据进行清洗和处理
#读取csv文件 df = pd.DataFrame(pd.read_csv('爱奇艺电影热播榜.csv')) df
截取前十几组数据

#删除无效列与行 df.drop('电影名', axis=1, inplace = True) df.drop('电影描述', axis=1, inplace = True) df.head()

#检查是否有重复值 df.duplicated()

#缺失值处理 df[df.isnull().values==True]#返回无缺失值

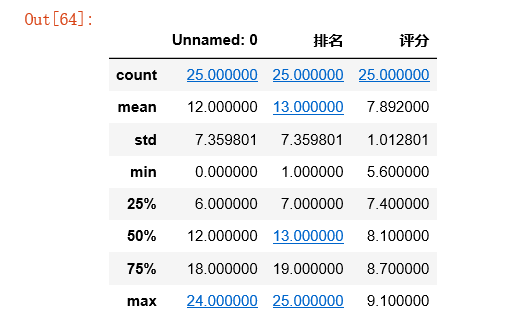
#用describe()命令显示描述性统计指标 df.describe()
3.数据分析与可视化
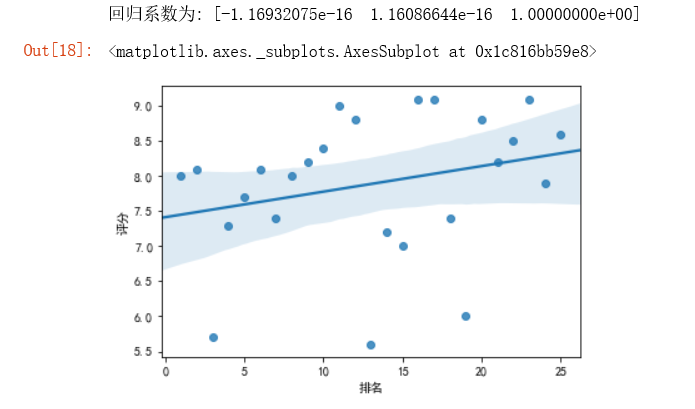
#数据分析与可视化 X = df.drop("电影名",axis=1) predict_model = LinearRegression() predict_model.fit(X,df['评分']) print("回归系数为:",predict_model.coef_) #绘制排名与评分的回归图 matplotlib.rcParams['font.sans-serif']=['SimHei']#显示黑体中文 sns.regplot(df.排名,df.评分)
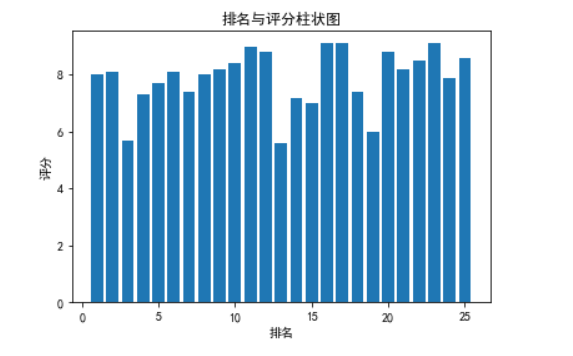
# 绘制柱状图 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 plt.bar(df.排名, df.评分, label="排名与评分柱状图") plt.xlabel("排名") plt.ylabel("评分") plt.title('排名与评分柱状图') plt.show()
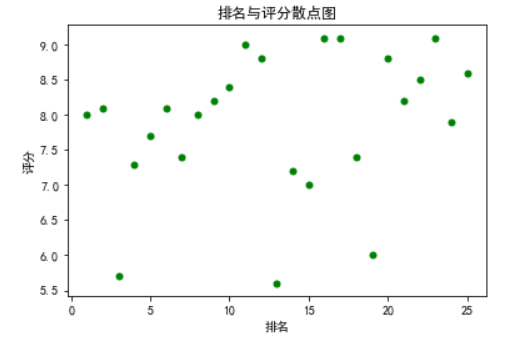
#绘制散点图 def scatter(): plt.scatter(df.排名, df.评分, color='green', s=25, marker="o") plt.xlabel("排名") plt.ylabel("评分") plt.title("排名与评分散点图") plt.show() scatter()
#绘制盒图 def box_diagram(): plt.title('绘制排名与评分-箱体图') sns.boxplot(x='排名',y='评分', data=df) box_diagram()

#绘制折线图 def line_diagram(): x = df['排名'] y = df['评分'] plt.xlabel('排名') plt.ylabel('评分') plt.plot(x,y) plt.scatter(x,y) plt.title("排名与评分折线图") plt.show() line_diagram()

#绘制分布图 sns.jointplot(x="排名",y='评分',data = df) sns.jointplot(x="排名",y='评分',data = df, kind='reg') sns.jointplot(x="排名",y='评分',data = df, kind='hex') sns.jointplot(x="排名",y='评分',data = df, kind='kde', color='r') sns.kdeplot(df['排名'], df['评分'])
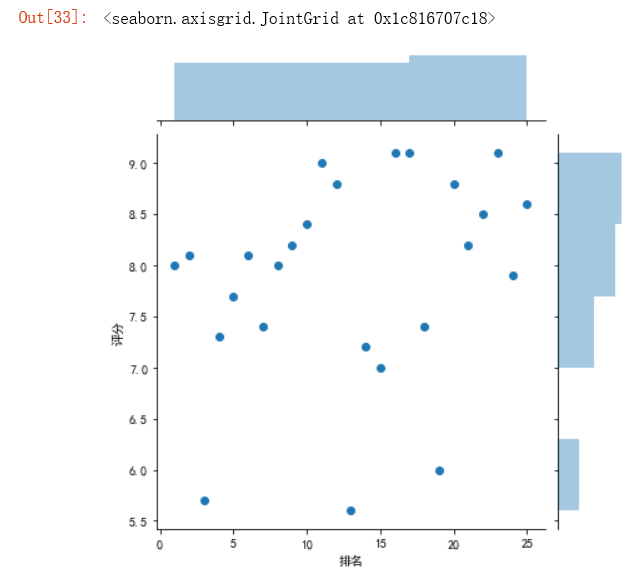

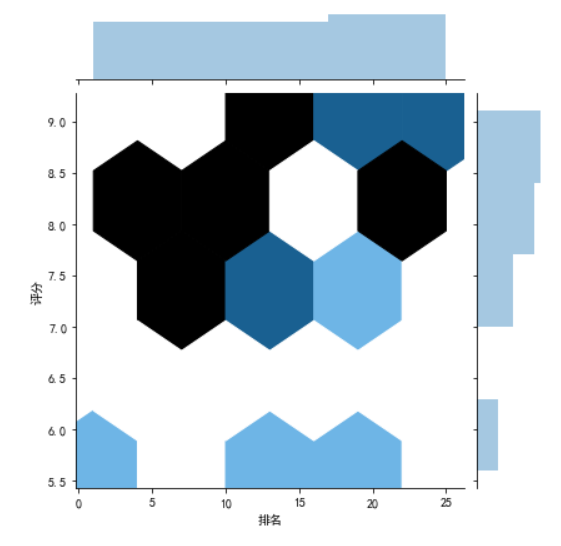
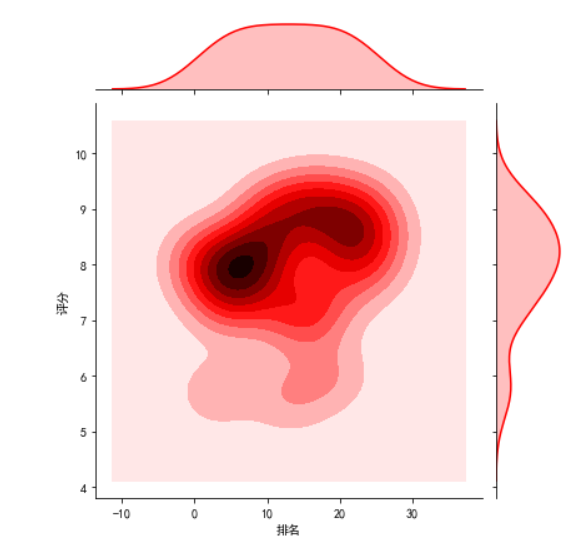

4.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
#绘制一元一次回归方程 def main(): colnames = ["排名", "电影名", "评分", "电影描述"] df = pd.read_csv('爱奇艺电影热播榜.csv',skiprows=1,names=colnames) X = df.排名 Y = df.评分 r=sts.pearsonr(X,Y) #相关性r print('相关性r',r) def func(p, x): k, b = p return k * x + b def error_func(p, x, y): return func(p,x)-y p0 = [0,0] #使用leastsq()函数对数据进行拟合 Para = leastsq(error_func, p0, args = (X, Y)) k, b = Para[0] print("k=",k,"b=",b) plt.figure(figsize=(10,6)) plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2) x=np.linspace(0,30,30) y=k*x+b plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("电影排名和评分关系图") plt.xlabel('排名') plt.ylabel('评分') plt.legend() plt.show() main()

在绘制一元一次回归方程的基础上,绘制一元二次回归方程。
#绘制一元二次回归方程 def main2(): colnames = ["排名", "电影名", "评分", "电影描述"] df = pd.read_csv('爱奇艺电影热播榜.csv',skiprows=1,names=colnames) X = df.排名 Y = df.评分 r=sts.pearsonr(X,Y) #相关性r print('相关性r',r) def func(p, x): a, b, c = p return a * x * x + b * x + c def error_func(p, x, y): return func(p,x)-y p0 = [0,0,0] #使用leastsq()函数对数据进行拟合 Para = leastsq(error_func, p0, args = (X, Y)) a, b, c = Para[0] print("a=", a,"b=", b,"c=", c) plt.figure(figsize=(10,6)) plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2) x = np.linspace(0,30,30) y = a * x * x + b * x + c plt.plot(x,y,color="red",label=u"一元二次回归方程直线",linewidth=2) plt.title("电影排名和评分关系图") plt.xlabel('排名') plt.ylabel('评分') plt.legend() plt.show() main2()

5.将以上各部分的代码汇总,附上完整程序代码
1 import requests 2 from bs4 import BeautifulSoup 3 import pandas as pd 4 import numpy as np 5 from sklearn.linear_model import LinearRegression 6 import seaborn as sns 7 import matplotlib.pyplot as plt 8 import matplotlib 9 from scipy.optimize import leastsq 10 import scipy.stats as sts 11 12 def get_html(url): 13 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}#伪装爬虫 14 15 try: 16 #发送get请求 17 html = requests.get(url,headers = headers) 18 #配置编码 19 html.encoding = html.apparent_encoding 20 if html.status_code == 200: 21 print("成功过获取源代码") 22 23 except Exception as e: 24 print("获取源代码失败:%s"% e) 25 26 return html.text 27 28 29 url = 'http://www.iqiyi.com/dianying_new/i_list_paihangbang.html' 30 html = get_html(url) 31 32 #提取HTML并解析想获取的数据 33 soup = BeautifulSoup(html, 'html.parser') 34 35 #爬取电影名 36 #建立一个电影名列表Film_name 37 Film_name = [] 38 a = soup.find_all('a', pos = '2') 39 40 for name in a: 41 Film_name.append(name.text) 42 43 #爬取评分 44 #建立一个评分列表Score 45 Score = [] 46 b = soup.find_all('span', class_ = 'score') 47 48 for score in b: 49 Score.append(score.text) 50 51 #爬取电影描述 52 #建立一个电影描述列表Describe 53 Describe = [] 54 c = soup.find_all('p', class_ = 'site-piclist_info_describe') 55 56 for describe in c: 57 Describe.append(describe.text) 58 59 #创建一个空列表lt 60 lt = [] 61 62 #爬取前25组电影数据,保存到列表lt中 63 print("{:^4}\t{:^5}\t{:^7}\t{:^8}".format('排名', '电影名', '评分', '电影描述')) 64 65 for i in range(25): 66 #输出前25组数据 67 print("{:^4}\t{:^5}\t{:^7}\t{:^8}".format(i+1, Film_name[i], Score[i], Describe[i])) 68 lt.append([i+1, Film_name[i], Score[i], Describe[i]]) 69 70 71 #创建DateFrame 72 df = pd.DataFrame(lt,columns = ['排名', '电影名', '评分', '电影描述']) 73 74 #保存文件,数据持久化 75 df.to_csv('爱奇艺电影热播榜.csv') 76 77 #读取csv文件 78 df = pd.DataFrame(pd.read_csv('爱奇艺电影热播榜.csv')) 79 df 80 81 82 #删除无效列与行 83 #df.drop('电影名', axis=1, inplace = True) 84 df.drop('电影描述', axis=1, inplace = True) 85 df.head() 86 87 88 #检查是否有重复值 89 df.duplicated() 90 91 92 #缺失值处理 93 df[df.isnull().values==True]#返回无缺失值 94 95 96 #用describe()命令显示描述性统计指标 97 df.describe() 98 99 100 101 102 #数据分析与可视化 103 104 X = df.drop("电影名",axis=1) 105 predict_model = LinearRegression() 106 predict_model.fit(X,df['评分']) 107 print("回归系数为:",predict_model.coef_) 108 109 110 #绘制排名与评分的回归图 111 matplotlib.rcParams['font.sans-serif']=['SimHei']#显示黑体中文 112 sns.regplot(df.排名,df.评分) 113 114 115 # 绘制柱状图 116 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 117 plt.bar(df.排名, df.评分, label="排名与评分柱状图") 118 plt.xlabel("排名") 119 plt.ylabel("评分") 120 plt.title('排名与评分柱状图') 121 plt.show() 122 123 #绘制散点图 124 def scatter(): 125 plt.scatter(df.排名, df.评分, color='green', s=25, marker="o") 126 plt.xlabel("排名") 127 plt.ylabel("评分") 128 plt.title("排名与评分散点图") 129 plt.show() 130 scatter() 131 132 133 #绘制盒图 134 def box_diagram(): 135 plt.title('绘制排名与评分-箱体图') 136 sns.boxplot(x='排名',y='评分', data=df) 137 box_diagram() 138 139 140 #绘制折线图 141 def line_diagram(): 142 x = df['排名'] 143 y = df['评分'] 144 plt.xlabel('排名') 145 plt.ylabel('评分') 146 plt.plot(x,y) 147 plt.scatter(x,y) 148 plt.title("排名与评分折线图") 149 plt.show() 150 line_diagram() 151 152 153 #绘制分布图 154 sns.jointplot(x="排名",y='评分',data = df) 155 156 sns.jointplot(x="排名",y='评分',data = df, kind='reg') 157 158 sns.jointplot(x="排名",y='评分',data = df, kind='hex') 159 160 sns.jointplot(x="排名",y='评分',data = df, kind='kde', color='r') 161 162 sns.kdeplot(df['排名'], df['评分']) 163 164 165 #绘制一元一次回归方程 166 def main(): 167 colnames = ["排名", "电影名", "评分", "电影描述"] 168 df = pd.read_csv('爱奇艺电影热播榜.csv',skiprows=1,names=colnames) 169 170 X = df.排名 171 Y = df.评分 172 r=sts.pearsonr(X,Y) #相关性r 173 print('相关性r',r) 174 def func(p, x): 175 k, b = p 176 return k * x + b 177 178 def error_func(p, x, y): 179 return func(p,x)-y 180 181 p0 = [0,0] 182 #使用leastsq()函数对数据进行拟合 183 Para = leastsq(error_func, p0, args = (X, Y)) 184 k, b = Para[0] 185 print("k=",k,"b=",b) 186 187 plt.figure(figsize=(10,6)) 188 plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2) 189 x=np.linspace(0,30,30) 190 y=k*x+b 191 plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) 192 193 plt.title("电影排名和评分关系图") 194 plt.xlabel('排名') 195 plt.ylabel('评分') 196 plt.legend() 197 plt.show() 198 main() 199 200 #绘制一元二次回归方程 201 def main2(): 202 colnames = ["排名", "电影名", "评分", "电影描述"] 203 df = pd.read_csv('爱奇艺电影热播榜.csv',skiprows=1,names=colnames) 204 205 X = df.排名 206 Y = df.评分 207 r=sts.pearsonr(X,Y) #相关性r 208 print('相关性r',r) 209 def func(p, x): 210 a, b, c = p 211 return a * x * x + b * x + c 212 213 def error_func(p, x, y): 214 return func(p,x)-y 215 216 p0 = [0,0,0] 217 #使用leastsq()函数对数据进行拟合 218 Para = leastsq(error_func, p0, args = (X, Y)) 219 a, b, c = Para[0] 220 print("a=", a,"b=", b,"c=", c) 221 222 plt.figure(figsize=(10,6)) 223 plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2) 224 225 x = np.linspace(0,30,30) 226 y = a * x * x + b * x + c 227 228 plt.plot(x,y,color="red",label=u"一元二次回归方程直线",linewidth=2) 229 plt.title("电影排名和评分关系图") 230 plt.xlabel('排名') 231 plt.ylabel('评分') 232 plt.legend() 233 plt.show() 234 main2()
四、结论
1.经过对主题数据的分析与可视化,得到结论:通过数据分析与可视化,了解到了电影排名与评分的关系,数据分析可以使内容更客观的体现出来,可视化体现了数据的变化规律。
2.小结:通过此次任务的完成,我学到了许多库的使用,这次任务同时提高了我对python的兴趣,提升了我的操作能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号