
memcached源码分析二-lru
在前一篇文章中介绍了memcached中的内存管理策略slab,那么需要缓存的数据是如何使用slab的呢?
1. 缓存对象item内存分布
在memcached,每一个缓存的对象都使用一个item结构体进行描述,然后再将item描述符及相应数据存储到slabs管理的内存中。缓存对象根据其大小在slabclass_t数组中选择合适的slabclass_t分配chunk进行存储。
ps: slabclass_t数组中从索引1开始,随着索引值的增加,该slabclass_t的chunk size也随之增加。因此从索引1开始,逐一比较缓存对象大小与slabclass_t的chunk size,直至找到能容纳缓存对象的最小chunk size,缓存对象即存储到该slabclass_t的空闲chunk中。
图1-1表示一个缓存对象分布在单个chunk中的情况,图1-2表示一个缓存对象分布在多个chunk中的情况,
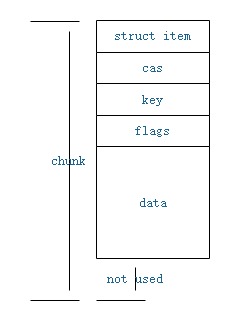
图1-1 数据在单个chunk中
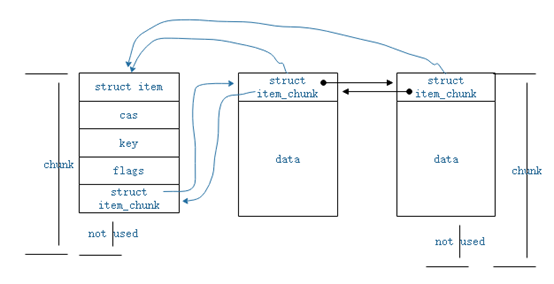
图1-1 数据在多个chunk中
当可以找到合适的slabclass_t以单个chunk存储数据时,即采用图1-1的结构,否则使用图1-2的结构。结构中的cas, flags根据情况可以不使用。由于chunk的大小固定,而缓存数据大小不固定,缓存对象将被存储在足够容纳它的最小的slabclass_t中,但可能存在部分内存未使用的情况,形成内存浪费。
分布在多个chunk中的数据以双向链表的形式进行关联,第一个chunk存储一个item结构,但不存储实际数据,以便与单个chunk中存储的item统一。后续的chunk以item_chunk结构与实际数据组成。item_chunk的结构定义如下
/* Header when an item is actually a chunk of another item. */ typedef struct _strchunk { struct _strchunk *next; /* points within its own chain. */ struct _strchunk *prev; /* can potentially point to the head. */ struct _stritem *head; /* always points to the owner chunk */ int size; /* available chunk space in bytes */ int used; /* chunk space used */ int nbytes; /* used. */ unsigned short refcount; /* used? */ uint16_t it_flags; /* ITEM_* above. */ uint8_t slabs_clsid; /* Same as above. */ uint8_t orig_clsid; /* For obj hdr chunks slabs_clsid is fake. */ char data[]; } item_chunk;
next与prev指针实现双向链表,head指针始终指向第一个chunk的item结构,slabs_clsid表示该item_chunk所在的slabclass_t的索引,orig_clsid表示第一个chunk所在的slabclass_t索引,it_flags将被设置为ITEM_CHUNK,表示该chunk是一个item_chunk结构
2. hashtable
缓存对象存储到slabs中后,如何找到需要的item数据呢? memcached使用了hashtable对缓存的item进行索引,所有的item都具有一个key,使用该key就可以在hashtable中找到对应的item的指针。
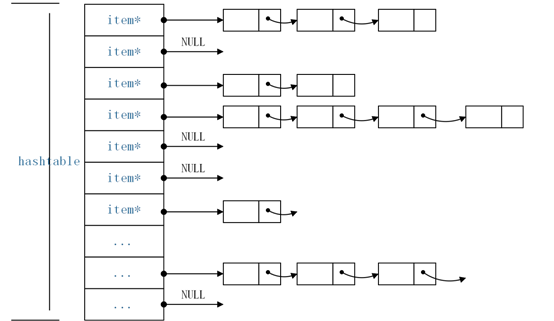
图2-1 hashtable
hashtable是一个可以动态扩展的全局数组,每一个数组元素都是一个指向item组成的单向链表的头指针,同一个单向链表上的所有item的key的 hash值相同,memcached中使用单链表的方式解决冲突。
以下是memcached中对item结构的定义,
/** * Structure for storing items within memcached. */ typedef struct _stritem { /* Protected by LRU locks */ struct _stritem *next; struct _stritem *prev; /* Rest are protected by an item lock */ struct _stritem *h_next; /* hash chain next */ rel_time_t time; /* least recent access */ rel_time_t exptime; /* expire time */ int nbytes; /* size of data */ unsigned short refcount; uint16_t it_flags; /* ITEM_* above */ uint8_t slabs_clsid;/* which slab class we're in */ uint8_t nkey; /* key length, w/terminating null and padding */ /* this odd type prevents type-punning issues when we do * the little shuffle to save space when not using CAS. */ union { uint64_t cas; char end; } data[]; /* if it_flags & ITEM_CAS we have 8 bytes CAS */ /* then null-terminated key */ /* then " flags length\r\n" (no terminating null) */ /* then data with terminating \r\n (no terminating null; it's binary!) */ } item;
其中的h_next成员即用于维护hashtable中的单向链表。
3. LRU
LRU即least recently used,由于slabs可用的内存有限,当slabs中不再有内存可用,但又有新的对象需要缓存时,根据LRU的思想,那些很久未访问的对象后续被访问的概率也最小,因此应当释放掉那些LRU的对象,缓存新的对象。LRU策略即是用来快速寻找可以释放的LRU对象的一种方案。
memcached中每一个slabclass[id]对应4条双向链表,每条双向链表以heads[id]指向链表头,tails[id]指向链表尾,item结构中的next与prev即用于组建该双向链表。heads[id]与tails[id]构成的双向链表对应slabclass[id]的hot链表,heads[64 + id]与tails[64+id]构成的双向链表对应slabclass[id]的warm链表,依此类推,如图3-1所示。一个slabclass_t中的item分布且仅分布于对应的4条链表之间。
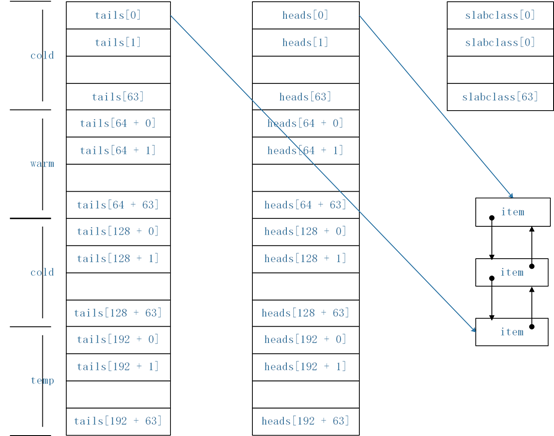
图3-1 LRU结构
在memcached中定义的HOT_LRU = 0, WARM_LRU = 64, COLD_LRU = 128, TEMP_LRU = 192,利用这些宏定义可以很方便地在对应的4条链表中跳转,如heads[WARM_LRU | id]即可跳转到对应slabclass[id]的warm链表头(id小于64)。
根据一定的策略操作item在这些链表之间移动,即可实现LRU策略。
先来看几个相关定义:
- ITEM_ACTIVE,存储在item的it_flags中,表示item处于active状态
- size_bytes[LARGEST_ID],一个长度与heads链表数组相同的数组,记录了每一条链表中所有item占用的字节总数
- time, 存储在item结构体中,记录了item最后一次被访问的时间, item的age = current_time - time
现在,来看一下item在hot, warm, cold三类链表中的移动的关系,以图3-2表示

图3-2 item转移图
- age_limit是cold链表的tails节点item的age的一个比例
- size_bytes > limit,意思是该item所在的链表所用内存超过了一定比例, limit是对应slabclass_t中存储的item所占内存的一个比例,slabclass_t中item的内存消耗存储在requested成员中。
上述的转换规则可描述如下:
- item仅在对应的3条链表间转移
- hot与warm链表上的item在非active状态下如果age > limit或者size_bytes > limit,移动到cold链表
- hot与cold链表上的item若处于active状态,移动到warm链表
- warm链表上的item若牌active状态,移动到链表头
- item移动后,处于相应链表的头部
- item移动后,清除active状态
memcached中通过函数lru_pull_tail实现以上转移规则,根据以上规则,以及新加入的item总是插入到hot链表头部,就可以实现LRU策略,得到如下结果:
- 每条链表的tail节点age最大
- cold链表上的节点相比hot与warm链表上的节点更适合释放
上面并没有提到temp链表中的item如何处理,事实上,temp链表上的item仅做简单的超时与flushed判断,满足条件即释放,否则不做操作。
- 超时: 用户为item设置一个超时时间,存储在item的exptime中,age > exptime即为超时。
- flushed: flush指令设置一个时间点settings.oldest_live或者settings.oldest_cas,item中的time < settings.oldest_live或者cas < settings.oldest_cas即为flushed。
memcached中释放item主要有3个入口:
- do_item_get操作,查找item时,如果item超时了或者是flushed,即释放
- do_item_alloc操作,如果对应slabclass_t中没有空闲chunk了,则在cold链表按照从尾到头的顺序做处理:释放超时与flushed的item,如果没有超时与flushed的item,则直接清除该item。由于链表使用LRU策略维护,因此链表最后的节点即是最适合释放的item。
- 线程lru_maintainer_thread,周期性地做一些工作:清除超时与flushed的item,按照图3-2在hot、warm与cold链表间转移item。
4.部分源码函数功能说明
static void *item_crawler_thread(void *arg)
一个crawler线程,该线程会定期的接收到任务,任务启动将会在一条链表上构造一个虚拟的item,该item从链表尾部逐渐移到到头部,对经过的item进行一定的处理。任务在遍历完链表或者处于一定数量的item后结束。memcached中定义了两类处理:1. 释放超时与flushed的item,通过函数crawler_expired_init, crawler_expired_eval, crawler_expired_doneclass与crawler_expired_finalize配合完成;2. 输出item的统计信息,通过crawler_metadump_eval与crawler_metadump_finalize函数配合完成。相应源码位于crawler.c中。
static void *lru_maintainer_thread(void *arg)
lru的定期任务线程,定期执行item在链表间转移的任务,定期启动crawler任务,定期执行slabs间移动page的任务。
static int lru_maintainer_juggle(const int slabs_clsid)
被lru_maintainer任务调用,完成对应slabclass[slabs_clsid]的4条链表上的item的释放与转移工作,通过多次调用lru_pull_tail函数完成工作。
int lru_pull_tail(const int orig_id, const int cur_lru, const uint64_t total_bytes, const uint8_t flags, const rel_time_t max_age, struct lru_pull_tail_return *ret_it)
这是一个关键函数,它会从链表尾开始处理,释放超时与flushed的item,如果没有超时或者flushed,则按照图3-2的逻辑移动item。参数orig_id表示对应的slabclass_t索引,cur_lru表示现在处理的是hot或者warm、cold还是temp链表,total_bytes表示slabclass_t中存储的item的内存消耗总量,max_age即图3-2中的age_limit,flags设置一些特殊操作的标记,如LRU_PULL_EVICT标记表示在处理cold链表时希望无论item是否超时或者flushed时,都释放item所占内存空间。
item *do_item_get(const char *key, const size_t nkey, const uint32_t hv, conn *c, const bool do_update)
通过hv与key在hashtable中查找item,返回查找结果。如果找到了,但是item超时或者flushed,则释放item, 返回NULL;如果不需要释放并且do_update非0,会更新item的状态,设置相应的ITEM_FETCHED与ITEM_ACTIVE标记。
item *do_item_alloc(char *key, const size_t nkey, const unsigned int flags, const rel_time_t exptime, const int nbytes)
根据参数,找到合适的slabclass_t申请空闲chunk,并对返回的chunk做一些初始化设置,如设置它的slabs_clsid为对应的slabclass_t索引。调用do_item_alloc_pull完成内存申请工作。
item *do_item_alloc_pull(const size_t ntotal, const unsigned int id)
在slabclass[id]中申请空闲chunk,如果申请失败,会尝试以LRU_PULL_EVICT标记调用lru_pull_tail,回收一些lru的item。
5. 其它
1. item_locks
static pthread_mutex_t *item_locks;
动态扩展的排它锁数组,数组长度与hashtable数组长度相同。即是说,每一个hashtable的数组元素,即hash值相同的item,都有一个独立的锁,增加了操作hashtable的并行度。
2. lru_locks
/* Locks for cache LRU operations */ pthread_mutex_t lru_locks[POWER_LARGEST];
static item *heads[LARGEST_ID];
排它锁数组,POWER_LARGEST与LARGEST_ID相同,即是说每一条lru相关的双向链表都有一个独立的锁保护,不同的双向链表可以并行操作,增加了并行度。
3. item的it_flags
it_flags可以是多个值的异或,这些值定义如下
#define ITEM_LINKED 1 #define ITEM_CAS 2 /* temp */ #define ITEM_SLABBED 4 /* Item was fetched at least once in its lifetime */ #define ITEM_FETCHED 8 /* Appended on fetch, removed on LRU shuffling */ #define ITEM_ACTIVE 16 /* If an item's storage are chained chunks. */ #define ITEM_CHUNKED 32 #define ITEM_CHUNK 64 /* ITEM_data bulk is external to item */ #define ITEM_HDR 128 /* additional 4 bytes for item client flags */ #define ITEM_CFLAGS 256 /* 7 bits free! */
首先,在slabs中的空闲chunk的it_flags设置为ITEM_SLABBED,当该chunk被分配时清除该标记;然后如果item加入了hashtable与lru的双向链表,设置ITEM_LINKED,从hashtable与lru双向链表移除后清除该标志。
ITEM_CHUNKED标记表明该缓存对象存储在多个chunk中,且此item是头节点,数据区存储了一个item_chunk结构指向存储数据的chunk;ITEM_CHUNK表示这是一个存储数据的item_chunk结构
ITEM_CAS标记表示item使用cas字段;ITEM_CFLAGS表示item使用flgas字段;ITEM_HDR表示使用外部存储,此处slabs的chunk中仅存储了一个头部。
