Docker从入门到精通<2>-Docker的架构、内部组件、底层原理
Docker架构

docker是一个典型的CS架构,docker client通过REST API、UNIX套接字或者网络接口和docker daemon进行通信,后者来执行构建、运行、分发工作。
docker client和 docker daemonset可以在同一台机器或者不同的机器上面。
下面介绍几点基本概念:
- Docker client:docker客户端
- Docker daemon:docker服务端
- Registry:保存docker镜像的仓库,Docker hub是一个任何人都可以使用的公共镜像仓库。在国外,访问速度比较慢。一般生产环境中都建设自己的镜像仓库。
- images:一个image是创建一个容器的只读模板。通常一个镜像是基于另外一个镜像,并额外加上一些自定义的内容
- contaners:容器,即一个image运行状态下就是一个容器
最核心的三个部分:容器、镜像、仓库
Docker 内部组件
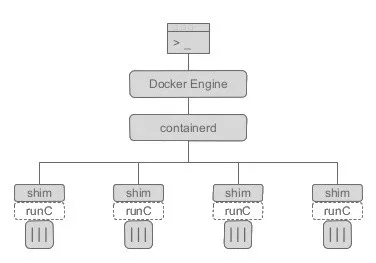
从 Docker 1.11 之后,Docker Daemon 被分成了多个模块以适应 OCI 标准。拆分之后,结构分成了以下几个部分
- docker: docker的客户端
- dockerd: docker的服务端,被client直接访问,其父进程为宿主机的systemd守护进程。
- containerd:高性能的容器运行时(containerd 独立负责容器运行时和生命周期(如创建、启动、停止、中止、信号处理、删除等),其他一些如镜像构建、卷管理、日志等由 Docker Daemon 的其他模块处理,包含containerd-shim)
- containerd-shim:是一个真实运行的容器的真实垫片载体,每启动一个容器都会起一个新的containerd-shim的一个进程,调用runc的api操作容器
- docker-proxy:容器代理。提供docker容器的端口映射功能,即实现容器通信。
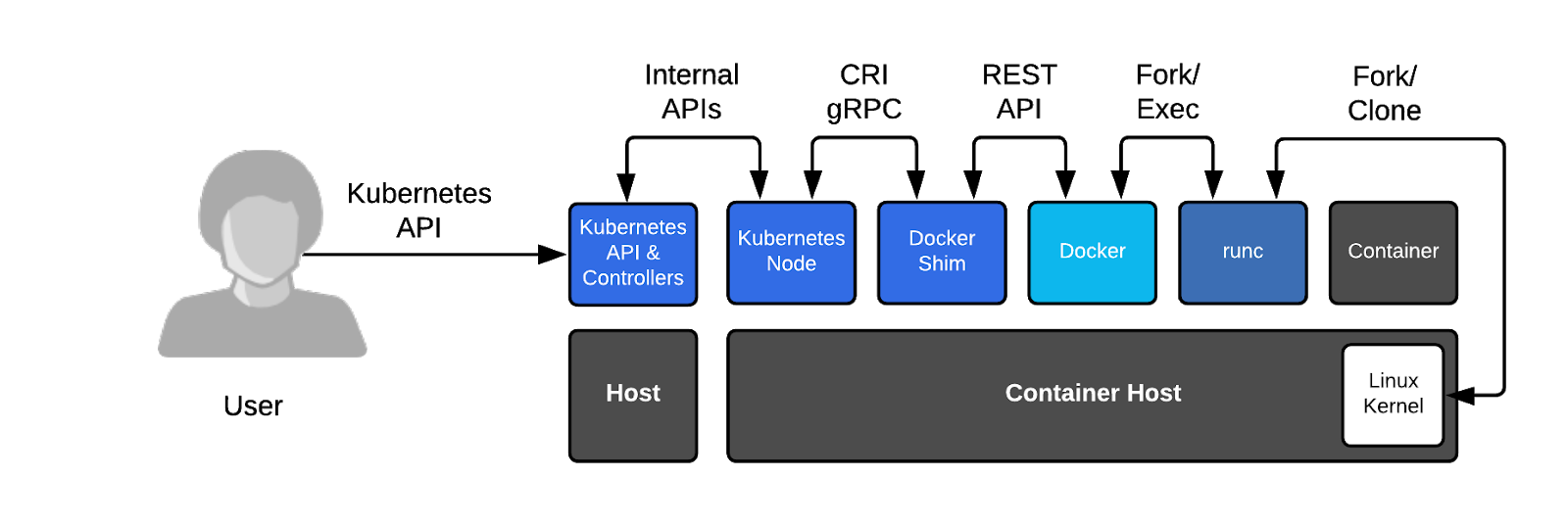
关于kubernetes弃用docker一事儿(k8s 1.20正式弃用docker-shim),估计大家都被标题党给忽悠了。kubernetes当初选择docker作为其容器运行时,是因为当时docker大火,而没有几个人知道kubernetes,为了更好支持k8s运行docker容器而开发维护一个兼容的程序叫docker-shim。真正弃用的不用docker,而是docker-shim插件的维护支持。
至于为什么要弃用docker-shim呢?
之前:
之后:
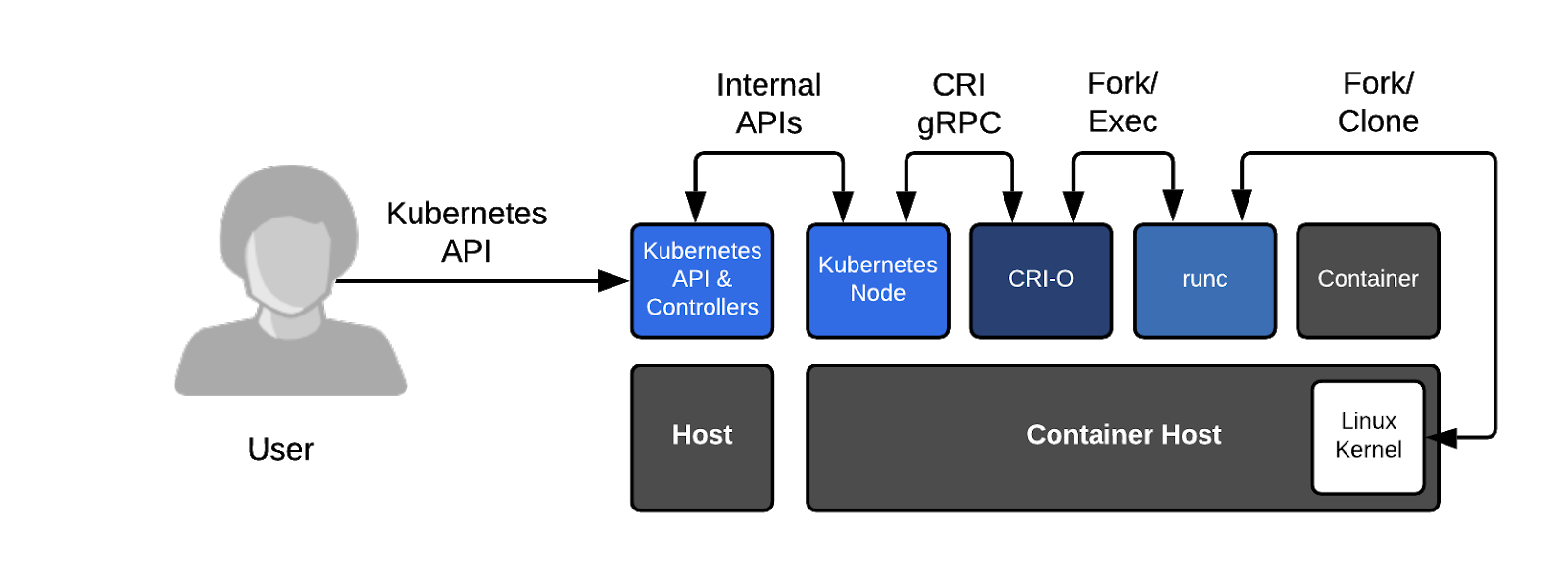
还要从k8s 在2016年发布CRI(Container Runtime Interface)标准来说起,为了支持 CoreOS 领导的容器运行时项目 rkt ,写了很多的代码。由于担心以后可能会有更新容器项目需要兼容而带来更大维护工作,所以发布了这个标准。这样的话,以后不管哪个容器项目只要支持CRL标准,就可以直接作为k8s的底层运行时。
2017 年, Docker v1.11 开始引入的容器运行时 containerd,并捐献给了CNCF,同年11月,kubernetes开始支持containerd,containerd相对于docker而言更加轻量级,是一个行业标准的运行时,强调简单性、健壮性和可移植性。
Docker的底层技术
问题:
1. 怎么保证每个容器都有不同的文件系统并且能互不影响 ?
2. 一个docker主进程内的各个容器都是其子进程,那么实现同一个进程下的不同类型的子进程?各个进程间通信互相访问(内存数据)吗?
3. 每隔容器怎么解决IP及端口分配的问题 ?
4. 多个容器的主机名能一样吗 ?
5. 每一个容器要不要都有root用户?怎么解决账户重名的问题 ?
主要是基于内核提供的namespace和cgroups技术。
namespace
namespace是Linux系统的底层概念,在内核层实现,即有一些不同类型的命名空间被部署在核内,各个docker容器运行在同一个docker主进程并且共用同一个宿主机系统内核,各个docker运行在宿主机的用户空间,每个容器都要有类似的虚拟机一样的互相隔离的运行空间,但是容器技术是在一个进程内实现运行指定服务的运行环境,并且还可以保护宿主机内核不受其他进程的干扰和影响,如文件系统空间、网络空间、进程空间等,目前主要通过以下技术实现容器运行空间的相互隔离。
namespace提供了一下6种资源隔离机制:
Mount: 隔离文件系统挂载点, Linux 2.4.19UTS: 隔离主机名和域名信息,Linux 2.6.19IPC: 隔离进程间通信,Linux 2.6.19PID: 隔离进程的ID,Linux 2.6.24Network: 隔离网络资源,Linux 2.6.29User: 隔离用户和用户组的ID,Linux 3.8
1. MNT Namespace
每个容器都要有独立的根文件系统有独立的用户空间,以实现在容器里面启动服务并且使用容器的运行环境,即一个宿主机是Ubuntu的服务器,可以在里面启动一个centos的运行环境的容器并且在容器里面启动一个Nginx服务,此Nginx运行时使用的运行环境就是CentOS系统目录的运行环境,但是在容器里面是不能访问宿主机的资源,宿主机使用chroot技术把容器锁定到一个指定的运行目录里面并作为容器运行的根运行环境。
查看当前shell 进程所在的namespace
[root@vm1 ~]# ll /proc/$$/ns 总用量 0 lrwxrwxrwx 1 root root 0 7月 6 11:44 ipc -> ipc:[4026531839] lrwxrwxrwx 1 root root 0 7月 6 11:44 mnt -> mnt:[4026531840] lrwxrwxrwx 1 root root 0 7月 6 11:44 net -> net:[4026531956] lrwxrwxrwx 1 root root 0 7月 6 11:44 pid -> pid:[4026531836] lrwxrwxrwx 1 root root 0 7月 6 11:44 user -> user:[4026531837] lrwxrwxrwx 1 root root 0 7月 6 11:44 uts -> uts:[4026531838]
cgroups
cgroups可以限制、记录任务组所使用的物理资源(包括CPU、Memory、IO等),为容器实现虚拟化提供了基本保证,是构建Docker等一系列虚拟化管理工具的基石。
实现cgroups的主要目的是为不同用户层面的资源管理,提供一个统一化的接口。从单个任务的资源控制到操作系统层面的虚拟化,
cgroups提供了以下四大功能[插图]。
❏ 资源限制:cgroups可以对任务使用的资源总额进行限制。如设定应用运行时使用内存的上限,一旦超过这个配额就发出OOM(Out of Memory)提示。
❏ 优先级分配:通过分配的CPU时间片数量及磁盘IO带宽大小,实际上就相当于控制了任务运行的优先级。
❏ 资源统计:cgroups可以统计系统的资源使用量,如CPU使用时长、内存用量等,这个功能非常适用于计费。
❏ 任务控制:cgroups可以对任务执行挂起、恢复等操作
首先,当我们登录到操作系统之后,可以通过 ps 等操作看到各式各样的进程,这些进程包括系统自带的服务和用户的应用进程。那么,这些进程都有什么样的特点?
- 第一,这些进程可以相互看到、相互通信;
- 第二,它们使用的是同一个文件系统,可以对同一个文件进行读写操作;
- 第三,这些进程会使用相同的系统资源。
这样的三个特点会带来什么问题呢?
- 因为这些进程能够相互看到并且进行通信,高级权限的进程可以攻击其他进程;
- 因为它们使用的是同一个文件系统,因此会带来两个问题:这些进程可以对于已有的数据进行增删改查,具有高级权限的进程可能会将其他进程的数据删除掉,破坏掉其他进程的正常运行;此外,进程与进程之间的依赖可能会存在冲突,如此一来就会给运维带来很大的压力;
- 因为这些进程使用的是同一个宿主机的资源,应用之间可能会存在资源抢占的问题,当一个应用需要消耗大量 CPU 和内存资源的时候,就可能会破坏其他应用的运行,导致其他应用无法正常地提供服务。
针对上述的三个问题,如何为进程提供一个独立的运行环境呢?
- 针对不同进程使用同一个文件系统所造成的问题而言,Linux 和 Unix 操作系统可以通过 chroot 系统调用将子目录变成根目录,达到视图级别的隔离;进程在 chroot 的帮助下可以具有独立的文件系统,对于这样的文件系统进行增删改查不会影响到其他进程;
- 因为进程之间相互可见并且可以相互通信,使用 Namespace 技术来实现进程在资源的视图上进行隔离。在 chroot 和 Namespace 的帮助下,进程就能够运行在一个独立的环境下了;
- 但在独立的环境下,进程所使用的还是同一个操作系统的资源,一些进程可能会侵蚀掉整个系统的资源。为了减少进程彼此之间的影响,可以通过 Cgroup 来限制其资源使用率,设置其能够使用的 CPU 以及内存量。
那么,应该如何定义这样的进程集合呢?
其实,容器就是一个视图隔离、资源可限制、独立文件系统的进程集合。所谓“视图隔离”就是能够看到部分进程以及具有独立的主机名等;控制资源使用率则是可以对于内存大小以及 CPU 使用个数等进行限制。容器就是一个进程集合,它将系统的其他资源隔离开来,具有自己独立的资源视图。
容器具有一个独立的文件系统,因为使用的是系统的资源,所以在独立的文件系统内不需要具备内核相关的代码或者工具,我们只需要提供容器所需的二进制文件、配置文件以及依赖即可。只要容器运行时所需的文件集合都能够具备,那么这个容器就能够运行起来。
Cgroup在内核层默认已经开启,从centos和ubuntu对比结果来看,显然内核比较新的ubuntu支持的功能更多。
root@ubuntu-server1:~# cat /boot/config-5.4.0-91-generic |egrep "CGROUP"|egrep -v "^#" CONFIG_CGROUPS=y CONFIG_BLK_CGROUP=y CONFIG_CGROUP_WRITEBACK=y CONFIG_CGROUP_SCHED=y CONFIG_CGROUP_PIDS=y CONFIG_CGROUP_RDMA=y CONFIG_CGROUP_FREEZER=y CONFIG_CGROUP_HUGETLB=y CONFIG_CGROUP_DEVICE=y CONFIG_CGROUP_CPUACCT=y CONFIG_CGROUP_PERF=y CONFIG_CGROUP_BPF=y CONFIG_SOCK_CGROUP_DATA=y CONFIG_BLK_CGROUP_IOCOST=y CONFIG_NETFILTER_XT_MATCH_CGROUP=m CONFIG_NET_CLS_CGROUP=m CONFIG_CGROUP_NET_PRIO=y CONFIG_CGROUP_NET_CLASSID=y root@ubuntu-server1:~# root@ubuntu-server1:~# root@ubuntu-server1:~# root@ubuntu-server1:~# cat /boot/config-5.4.0-91-generic |egrep "MEM"|grep CG|grep -v "^#" CONFIG_MEMCG=y CONFIG_MEMCG_SWAP=y CONFIG_MEMCG_KMEM=y CONFIG_SLUB_MEMCG_SYSFS_ON=y
cgroup的具体实现:
blkio: 块设备IO限制
cpu: 使用调度程序为cgroup任务提供cpu的访问
cpuacct: 产生cgroup任务的cpu资源报告
cpuset:如果是多核心的cpu,这个子系统会为cgroup任务分配单独的cpu和内存
devices:允许或拒绝cgroup任务对设备的访问
freezer: 暂停和恢复cgroup任务
memory:设置每个cgroup的内存限制以及产生内存资源报告
net_cls: 标记每个网络包以供cgroup方便使用
ns: 命名空间子系统
perf_event: 增加对每cgroup的检测跟踪的能力,可以检测属于某个特定的cgroup的所有线程以及运行在特定CPU上的线程
docker的组件和进程关系图
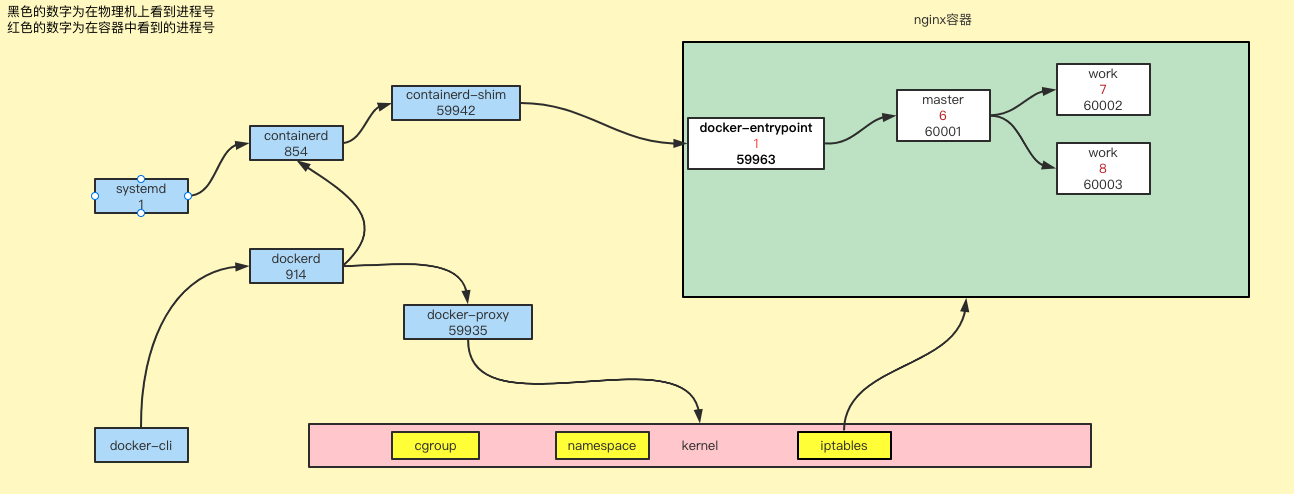
1. 容器的PID与宿主机的PID的关系?
2. 容器为什么要自定义守护进程?可不可以没有?
容器说白了在宿主机上就是一个进程,这个进程需要承载namespace、cgroup这些容器必须的环境,没有进程来承载,这些运行环境将消失。
容器技术分类
有了以上的chroot、namespace、cgroups就具备了基础的容器运行环境,但是还需要有相应的容器创建与删除的管理工具、以及怎么样把容器运行起来、容器数据怎么处理、怎么进行启动与关闭等问题需要解决,于是容器管理技术出现了。
早期有lxc、目前主要使用docker,以及docker开源出来的containerd、红帽的podman、core rkt、阿里云的Pouch等
OCI标准
容器除了docker之外,还有别的容器技术,为了保证容器生态的标准型和健康可持续发展,包括linux基金会、Docker、微软、红帽、谷歌、IBM等公司在2015年6月份共同成立了一个叫open container(OCI)的组织、其目的就是指定开放的标准的容器规范,目前OCI发布了runtime spec和image format spec等规范,这样不同的容器公司开发的容器,只要兼容这两个规范就可以保证容器的可移植性和互操作性。
容器 runtime (runtime spec):
目前主流的runtime有三种:
- Lxc,linux早期的runtime,docker早期就是采用lxc作为runtime
- ruc,目前docker默认的runtime,也符合OCI规范,所以使用rktruntime也可以运行docker容器
- rkt,是CoreOS开发的容器runtime,也符合OCI规范,所以使用rktruntime也可以运行Docker容器。
runtime是真正运行容器的地方,因此为了运行不同容器的runtime,需要和操作系统内核紧密合作相互支持,以便为容器提供相应的运行环境。
runtime主要定义了一下规范,并以json格式保存在/run/docker/runtime-runc/moby/容器ID/state.json,此文件会根据容器状态实时更新内容,
主要包括如下:
- 版本信息:存放OCI标准的具体版本号
- 容器ID:通常是一个哈希值,可以在所有的state.json文件中提供出容器ID,对容器进行批量操作 (关闭、删除等), 此文件在容器关闭后会被删除,容器启动后会自动生成
- PID: 在容器中运行的首个进程在宿主机上的进程号,即将宿主机的那个进程设置为容器的守护进程
- 容器创建:创建包括文件系统、namespace、cgroups、用户权限在内的各项内容
- 容器进程的启动:运行容器启动进程。该文件在/run/containerd/io.containerd.runtime.v1.linux/moby/容器ID/config.json
- 容器生命周期:容器进程可以被外部程序关闭,runtime规范定义了对容器操作信息的捕获,并做相应资源回收的处理,避免僵尸进程的出现
容器镜像 (image format spec):
容器镜像主要包含以下内容:
- 文件系统:定义以layer保存的文件系统,在镜像里面是layer.tar,每个layer保存了和上层之间变化的部分,image format spec定义了layer应该保存哪些文件,怎么表示增加、修改和删除的文件等操作
- manifest文件:描述有哪些layer、tag标签以及config文件名称
- config文件:是一个以hash命名的json文件,保存了镜像平台。容器运行时运行时需要的一些信息,比如环境变量、工作目录、命令参数等
- index文件: 可选的文件,指向不同平台的manifest文件,这个文件能保证一个镜像可以跨平台使用,每个平台拥有不同的manifest文件使用index作为索引
- 父镜像:大多数层的元信息结构都包含一个parent字段,指向该镜像的父镜像
参数:
ID:镜像ID,每一层都有ID
tag标签:标签用于将用户指定的、具有描述的名称对应到镜像ID
仓库:Repository镜像仓库
OS:定义类型
architecture:定义CPU架构
author:作者信息
create:镜像创建日期
通过命令查看指定
docker inspect 镜像ID
镜像简介
1. docker镜像是基于union file system将多个目录合并挂载到一个目录给容器使用2. 最底层是bootfs,镜像没有内核。使用的是宿主机的bootfs3. 一个镜像是有一层或者多层合并而成,每一层称为是一个layer4. 镜像可以基于其他的镜像进行重新构建,被引用的镜像被称为父镜像5. 一个镜像可以同时被创建为多个容器6. 镜像是只读的,任何的更改都不会直接修改镜像
通过命令查看指定容器的信息
docker inspect container ID

LowerDir: image镜像层(镜像本身,只读)UpperDir:容器的上层(读写)MergedDir:容器的文件系统,使用Union Fs(联合文件系统)将LowerDir和UpperDir合并给容器使用WorkDir: 容器在宿主机的工作目录,相当于容器被锁定到这个目录,相当于chroot到这个目录
容器和k8s是如何做限制资源?
docker 主要docker--cpus和-m来做cpu和内存的限制
--cpus 限制CPU使用
--memory 限制内存使用
kubernetes本质也是通过容器进行限制的,主要是通过两个参数request,limit
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
resources:
limits:
cpu: "1"
requests:
cpu: "0.5"
args:
- -cpus
- "2"
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
namespace: mem-example
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
resources:
requests:
memory: "50Mi"
limits:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
实验:压力测试神器stress-ng
stress-ng 将以各种可选择的方式对计算机系统进行压力测试。它旨在运行计算机的各种物理子系统以及各种操作系统内核接口。压力 ng 还具有广泛的 CPU 特定压力测试,用于练习浮点、整数、位操作和控制流。
压力 ng 最初的目的是使机器努力工作并解决硬件问题,例如热溢出以及仅在系统受到严重冲击时才会发生的操作系统错误。请谨慎使用stress-ng,因为某些测试会使系统在设计不佳的硬件上运行过热,并且还可能导致可能难以停止的过度系统抖动。
这里,我们主要来进行容器使用内存和cpu限制的压测
CPU压测
这里我们先给机器增加两核CPU看看,输入"top", 然后在输入"1",否则只会显示多核cpu的平均使用率
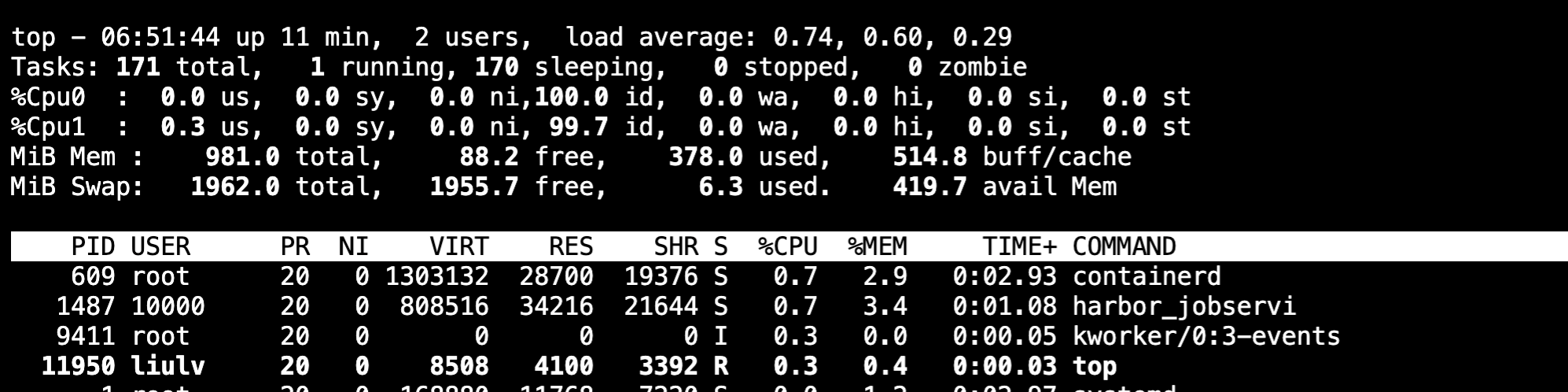
开始压测CPU
liulv@ubuntu-server1:~$ docker run --name=stress-ng --rm alexeiled/stress-ng:latest --cpu=2 stress-ng: info: [1] defaulting to a 86400 second (1 day, 0.00 secs) run per stressor stress-ng: info: [1] dispatching hogs: 2 cpu
我们在看下CPU的使用率
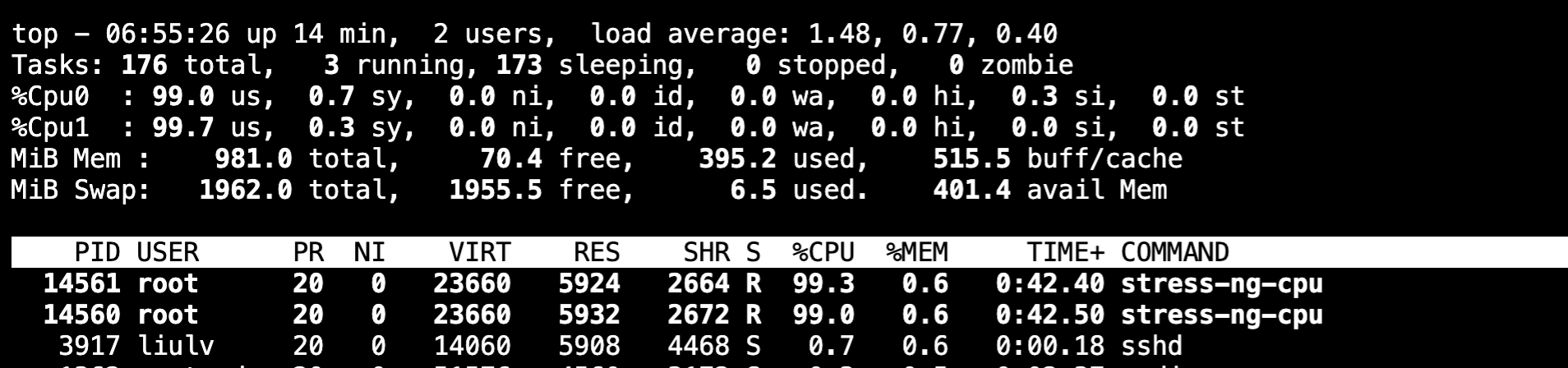
差不多两个核心都跑满了,如果压测参数不变的情况下,这里有4核,也可能会出现一个核心跑接近100%,其中两个核心加起来跑100%,一个核心空间,总之要占用两个核心的CPU 100%
限制CPU使用
如果我们对容器的CPU进行限制,我们再看下CPU使用率
liulv@ubuntu-server1:~$ docker run --name=stress-ng --rm --cpus=1 alexeiled/stress-ng:latest --cpu=2 stress-ng: info: [1] defaulting to a 86400 second (1 day, 0.00 secs) run per stressor stress-ng: info: [1] dispatching hogs: 2 cpu
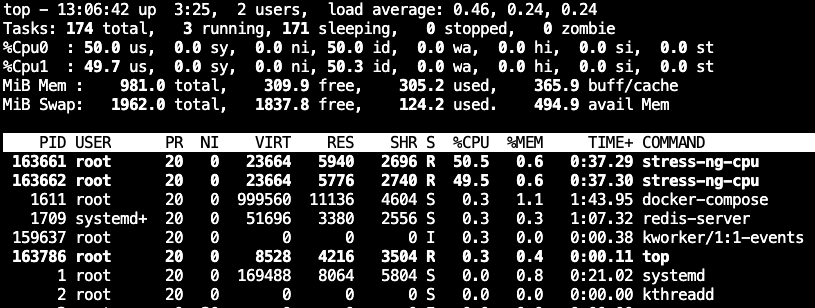
总共有2核的CPU,我限制了只能使用1核的100%,我们看到两核分别被50%左右,加在一起就是100%
到底在哪里进行了限制呢 ?我们来看下
root@ubuntu-server1:~# docker ps -f name='stress-ng' CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a761b2aac3a4 alexeiled/stress-ng:latest "/stress-ng --cpu=2" 3 minutes ago Up 3 minutes stress-ng root@ubuntu-server1:~# root@ubuntu-server1:~# root@ubuntu-server1:~# cat /sys/fs/cgroup/cpu/docker/a761b2aac3a46697413ea7d1fe2a07c33d38b8b379cb11b0c444eea559716286/cpu.cfs_quota_us 100000
这里的100000表示,1000m*100(1000m表示一核CPU 100%占用),即为10万,这里我们手动改下增加到150000看看
手动增加CPU限制
root@ubuntu-server1:~# echo 150000 > /sys/fs/cgroup/cpu/docker/a761b2aac3a46697413ea7d1fe2a07c33d38b8b379cb11b0c444eea559716286/cpu.cfs_quota_us
我们再看下cpu的使用情况,我们可以看到已经发生了变化,两核CPU占用150%
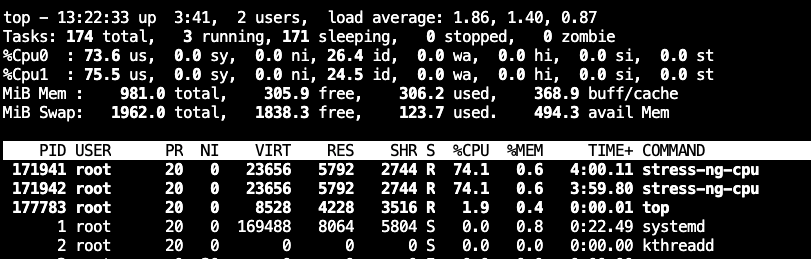
如果我们减小到50000(50*1000m)呢,也就是cpu占用50%,来看看
手动降低CPU限制
echo 50000 > /sys/fs/cgroup/cpu/docker/a761b2aac3a46697413ea7d1fe2a07c33d38b8b379cb11b0c444eea559716286/cpu.cfs_quota_us
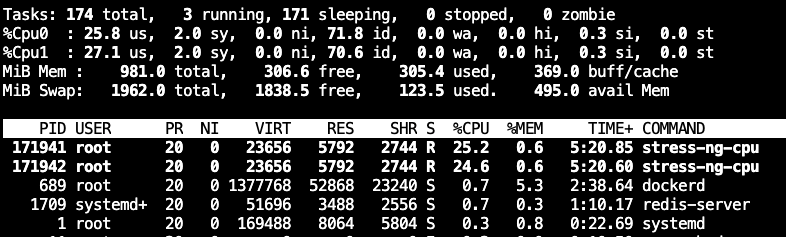
内存压测
机器总内存为2G
内存压测,上面的stress-ng最新版有点问题,这里我们使用另外一个版本
docker pull lorel/docker-stress-ng
vm=2,默认一个vm为256M,两个vm为512M
liulv@ubuntu-server1:~$ docker run --rm --name=stress-ng lorel/docker-stress-ng --vm=2 stress-ng: info: [1] defaulting to a 86400 second run per stressor stress-ng: info: [1] dispatching hogs: 2 vm
我们看下该容器的内存占用情况
docker stats stress-ng

限制内存
docker申请通过stree-ng申请512M,但是通过docker的cgroup限制只能使用256M
liulv@ubuntu-server1:~$ docker run --rm --name=stress-ng --memory=256M lorel/docker-stress-ng --vm=2 stress-ng: info: [1] defaulting to a 86400 second run per stressor stress-ng: info: [1] dispatching hogs: 2 vm
查看下
docker stats stress-ng

可见已经被限制为docker只能使用256M
手动增加内存
原来限制的内存为256M,我们手动提升限制的标准,我们设置限制为300M再观察下
liulv@ubuntu-server1:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 890186ea02a1 lorel/docker-stress-ng "/usr/bin/stress-ng …" 10 minutes ago Up 10 minutes stress-ng liulv@ubuntu-server1:~$ liulv@ubuntu-server1:~$ liulv@ubuntu-server1:~$ cat /sys/fs/cgroup/memory/docker/890186ea02a14e151d6eb8d74e4826bd5fe54321979aa98981922f3e37af2cfb/memory.limit_in_bytes 268435456 liulv@ubuntu-server1:~$ liulv@ubuntu-server1:~$ bc bc 1.07.1 Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc. This is free software with ABSOLUTELY NO WARRANTY. For details type `warranty'. 268435456/1024/1024 256 quit liulv@ubuntu-server1:~$ bc bc 1.07.1 Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc. This is free software with ABSOLUTELY NO WARRANTY. For details type `warranty'. 300*1024*1024 314572800 quit liulv@ubuntu-server1:~$ liulv@ubuntu-server1:~$ liulv@ubuntu-server1:~$ sudo -i [sudo] password for liulv: root@ubuntu-server1:~# echo 314572800 > /sys/fs/cgroup/memory/docker/890186ea02a14e151d6eb8d74e4826bd5fe54321979aa98981922f3e37af2cfb/memory.limit_in_bytes

docker内存的限制已经提高到了300M
手动减少内存
跟上面类型,假如我们要把300M的限制降低到100M
root@ubuntu-server1:~# bc bc 1.07.1 Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc. This is free software with ABSOLUTELY NO WARRANTY. For details type `warranty'. 100*1024*1024 104857600 quit root@ubuntu-server1:~# echo 104857600 > /sys/fs/cgroup/memory/docker/890186ea02a14e151d6eb8d74e4826bd5fe54321979aa98981922f3e37af2cfb/memory.limit_in_bytes -bash: echo: write error: Device or resource busys
是不被允许的,只能动态的提升内存限制,不能动态降低,否则需要重启容器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号