Python成长之路 基础篇2
基础篇2
1、模块
2、pyc文件
3、数据类型
4、列表
5、元组
6、字符串
7、字典
8、字符的转换
一、模块和pyc文件
我们脚本上是用 python 解释器来编程,如果你从 Python 解释器退出再进入,那么你定义的所有的方法和变量就都消失了。
为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
在Python中,一个.py文件就构成一个模块。一个模块中的定义可以导入(import)到另一个模块或主模块。
比如你可以通过内置模块platform来查看你当前的操作平台信息:


1 import platform 2 s = platform.platform() 3 print(s) 4 #输出为Windows-10-10.0.15063-SP0
当你要导入某个模块时,会在Python加载路径中查找相应的模块文件,比如可以使用sys模块中的sys,path属性查看查找模块文件的路径:
1 import sys 2 print(sys.path) 3 4 #['F:\\python\\day1', 'F:\\python', 'C:\\Program Files\\Python35\\python35.zip', 'C:\\Program Files\\Python35\\DLLs', 'C:\\Program Files\\Python35\\lib', 'C:\\Program Files\\Python35', 'C:\\Program Files\\Python35\\lib\\site-packages']
python中使用import语句导入模块时,python通过三个步骤来完成这个行为。
1:在python模块加载路径中查找相应的模块文件
2:将模块文件编译成中间代码
3:执行模块文件中的代码
这里面的第二步就是编译成.pyc的文件。
pyc是一种二进制文件,是由py文件经过编译后,生成的文件,是一种byte code,py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由python的虚拟机来执行的,这个是类似于JAVA或者.NET的虚拟机的概念。pyc的内容,是跟python的版本相关的,不同版本编译后的pyc文件是不同的,2.5编译的pyc文件,2.4版本的 python是无法执行的。
为什么要.pyc的文件。
网上查了很多资料发现有的人说.pyc文件主要是为了不把源代码暴露出来,同时也有人说第一次执行脚本时,会寻找是否拥有该脚本的.pyc文件。如果有了那就就直接运行,这样就会增加运行速度,如果没有就会预编译成.pyc的文件这样在下次能用到的时候他就会直接执行使之能够节约时间,那么问题就来了如果我们修改了源文件里的内容使之改变那是否也是直接使用,不会这样的因为在你想到这个问题是别人也想到了这样,它会有一个机制验证是否被修改过,是通过检验源文件和.pyc文件的最新更新时间,如果源文件的最新更新时间在.pyc后面那么编译器就会重新编译一下。这些我只是在网上了解的有可能不对或者不是很深入,
二、数据类型
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
等号(=)用来给变量赋值。
python3中有六个标准的数据类型
1、Number(数字)
2、String(字符串)
3、List(列表)
4、Tuple(元组)
5、Dictionary(字典)
6、Sets(集合)
其中Number(数字)中有int、float、bool、complex。
在Python3中只有一种整数类型int,表示长整型,Python2中长整型表示为Lang。
在Python2中当赋值的int(整数)超过了它的最大值时,会自动转换成长整型。这里我就不演示了,现在主要学python3。想知道可以去百度一下。
三、列表
序列是Python中最基本的数据结构。序列中的每一个元素都分配一个数字,我们叫做索引,通常索引的是从0开始的,索引对应位置是序列从左到右一一对应的。
序列通用的操作有索引,切片,加,乘,检查成员。
序列还内置了确定序列的长度以及确定最大和最小的元素的方法。
列表就是序列中的一种,拥有序列的一切操作。
列表中的元素都'[]'里面,且每个元素之间使用英文的逗号分隔开了。
列表的一些创建:
1 list = [] 2 list1 = ['name', 'age', 'salary'] 3 list2 = ['name', 'teacher',] 4 print(list, list1, list2) 5 6 #[] ['name', 'age', 'salary'] ['name', 'teacher']
上面列子可以知道我们能够创建一个空的列表,也可以在最后一个元素后面加上逗号或不加逗号都不影响。
列表中创建列表或者元组、字典。也可以在列表中的在列表嵌套列表,理论上可以无限嵌套,但是一般只嵌套3-5个,太多会导致列表复杂化。
1 list1 = [('name', 'Tom'), 'age', {'salary':5236}, ['num', 123]] 2 print(list1) 3 4 #[('name', 'Tom'), 'age', {'salary': 5236}, ['num', 123]]
记住列表中的元素可以是字符串,可以是变量,bool值等。
列表利用下标索引取相应的元素
1 name = ['Tom', 'Bob', 'Jack', 'Ana'] 2 print(name[1]) #通过索引取第二个元素 3 print(name[-1]) #通过索引取最后一个个元素 4 5 #下面是上面运行的结果 6 #Bob 7 #Ana
上面利用下标索引取相应的元素时,记得下标索引是从0开始的所以第一元素的下标索引为0,第二个为1,以此类推。
如果下标索引为负数,取值-1对应的是列表最右边的一个元素,也就是说负数是从右边开始与元素一一对应的,也是从-1开始取值。
列表的切片
利用切片可以取到想要的列表中某个范围内的元素。
1 number = [1, 2, 3, 4, 5, 6, 7, 8, 9] 2 3 print(number[:]) #取所有的元素 4 print(number[:4]) #取前面四个元素 5 print(number[:-2]) #取第一个到倒数第三个数元素 6 print(number[2:4]) #从第三个元素到第四个元素 7 print(number[::2]) #设步长为2,就是从第一个元素开始,每个一个元素取一个元素。 8 print(number[::-1]) #改变取元素的方向,从右开始向左开始取元素,步长为1也就是 9 print(number[3:2]) 10 print(number[3:2:-1]) 11 print(number[2:3:-1]) 12 13 #下面的和上面的print语句一一对应 14 #[1, 2, 3, 4, 5, 6, 7, 8, 9] 15 #[1, 2, 3, 4] 16 #[1, 2, 3, 4, 5, 6, 7] 17 #[3, 4] 18 #[1, 3, 5, 7, 9] 19 #[9, 8, 7, 6, 5, 4, 3, 2, 1] 20 #[] 21 #[4] 22 #[]
从上面的代码可以知道我们在切片的时候可以取三个值,以":"分隔开来最后一个值可以不取,默认为1,也就是步长值为1表示从左向右截取元素。
下面我们对照上面的代码看看每个值意义。如[x:y:z]
x:代表的时取得第一元素的下标位置
y:代表的是结束时的下标的位置
切片我们可以看看下面的图示:
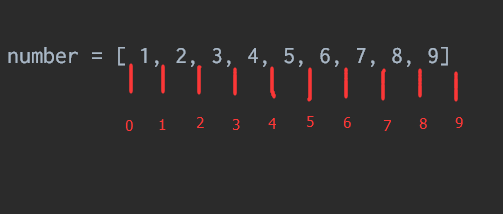
上图的红色数字就是切片时的下标,这样我们就可以看出来number[1:3]返回的值就是红色数字1和3之间元素,也就是[2, 3]。
在切片时x不写是代表的是0,y不写时代表的是取值到最后。所以上面的代码中我们可以知道
number[:]=number[0:9]
number[:4] = number[0:4]
number[1:] = number[1:9]
现在我们说一下list[x:y:z]中的 z,这个表示步长和取值的方向。
当Z>0时,我们是从列表的左边向右取值,也就是默认的方向。当z=2是就是隔一个元素取一个元素。以此类推
同时上面的x<y,否则取出的将是一个空的列表上面的代码中我们也可以看到
当z<0时,我们在列表中是从右往左取值,步长和上面一样,这个时候x>y,否则将得到的是一个空的列表。
列表的拼接
1 name = ['Tom', 'Bob', 'Jack', 'Ana'] 2 name2 = ['Lilei', 'Hanmeimei'] 3 print(name+name2) 4 5 #下面是代码执行的结果 6 #['Tom', 'Bob', 'Jack', 'Ana', 'Lilei', 'Hanmeimei']
从上面我们可以看出列表的拼接就是把2个列表合二为一。
Python列表的函数和方法
函数
1、len(list) #列表中元素的个数
2、max(list) #返回列表中元素的最大值
3、min(list) #返回列表元素中的最小值
4、list(seq) #把元组转换成列表,返回的是一个列表,元组seq本身没变。
1 name = ['Tom', 'Bob', 'Jack', 'Ana'] 2 name2 = ['Lilei', 'Hanmeimei','Jack'] 3 name3 = ['Jilei', 'Lanmeimei','Hack'] 4 name4 = (1, 2, 3, 4, 5, 6) 5 name5 = [11, 34, 55, 6] 6 7 print(len(name)) 8 print(max(name2)) 9 print(min(name2)) 10 print(max(name3)) 11 print(min(name3)) 12 print(list(name4)) 13 print(name4) 14 print(max(name5)) 15 print(min(name5)) 16 17 #执行的结果 18 #4 19 #Lilei 20 #Hanmeimei 21 #Lanmeimei 22 #Hack 23 #[1, 2, 3, 4, 5, 6] 24 #(1, 2, 3, 4, 5, 6) 25 #55 26 #6
上面代码可以看出这些函数的效果,在上面的代码中我们发现去一群字符串中取最大的元素是受字母在字母表的位置界定的。一般我们使用这个函数都是去数字的最大值。关于全字母的字符串我的代码验证中是首字母在 字母表中的位置界定的。若果错了欢迎指出或把你的见解告诉我。
list的一些方法
list.append(obj) #在列表的末尾添加新的对象,没有返回值,改变原来的列表。
list.count(obj) #统计列表中某个元素出现的次数,返回列表中该元素的个数
list.extend(seq) #在列表的末端一次性追加另一个序列中的多个值(用序列表扩展原来的列表)
上面的这个我们后面说道使用序列来扩展原来的列表,也就是说我们的seq可以是字符串,元组。且他没有返回值,列表list的自身改变。不像字符串拼接字符串本身都没有改变,只是拼接有返回值。
list.index(obj) #从列表中找出某个元素第一个匹配项的索引位置,匹配的顺序是从左向右,返回的是匹配的对象的索引位置,如果没有找到则抛出异常。这个在查找的后面可以添加从什么位置开始查找对象。
list.insert(index, obj) #在某个位置插入对象这个位置可以参考上面切片的位置理解添加到相应的位置,无返回值
list.pop(obj = list[-1]) #移除列表中的某个元素,并返回该移除的元素。默认是最后一个元素。
list.remove(obj) #删除列表中某个值的第一个匹配项,没有返回值
list.reverse() #把列表中的元素反过来显示,没有返回值
list.sort([func]) #把列表进行排序,如果有func那就会按这个函数的方法排序,没有返回值
list.clear() #清空列表,没有返回值,原列表变为一个空列表
list.copy() #返回复制后的新列表,这个复制属于浅copy也就是他只复制第一层,当它复制列表中嵌套的列表是它只会把嵌套的列表的内存地址复制给新的列表,当修改原列表中嵌套的列表的值时,新的列表中嵌套的列表值也会改变,因为嵌套的列表的内存地址是一样的。这个copy和list[:]效果一样
四、字符串
字符串是Python中常见的数据类型。我们使用引号("或')括起来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。
字符串也支持切片和索引取值。但是字符串是不可变的。
序列支持的操作字符串也能操作,方法与上面的一样。
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
Python字符串运算符
下表实例变量a值为字符串 "Hello",b变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | H in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | M not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print r'\n' prints \n 和 print R'\n'prints \n |
| % | 格式字符串 |
字符串的一些方name = "my name is Alex"
print(name.capitalize() #首字母大写
print(name.count('a')) #统计'a'有多少个
print(name.center(50,'-')) #一共打印50个字符,不够用'-'补全,name位于中间
print(name.endswith('ex')) #查看以'ex'结尾,是则返回True,否则返回Falsh
name = "my \tname is Alex"
print(name.expandtabs(tabsize = 30)) #把name中的tab键转换成30个空格
print(name.find('name')) #从下标0开始,查找在字符串里第一个出现的子串的下标并返回
print(name.find('name', 1)) #从下标1开始,查找在字符串里第一个出现的子串的下标并返回
print(name.find('Name')) #查找不到返回 -1
print(name.index('name')) #和find一样,只是找不到会报异常
print(name.isalnum()) #如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False
print(name.isalpha()) #如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False
print(name.isdigit()) #如果字符串只包含数字则返回 True 否则返回 False.
print(name.islower()) #检查字符串中的字母是否全为小写,是则返回True,否则返回False
print(name.isnumric()) #这个和isdigit()差不多都是检验它的组成是否全为数字,这种方法是只针对unicode对象
print(name.isspace()) #如果字符串中只包含空白,则返回 True,否则返回 False.
print(name.istitle()) #如果字符串的每一个单词的首字母都是大写则返回 True,否则返回 False,这里的单词划分是相连的字母为一个单词,如果'qweq1dad'这个就是2个单词
print(name.isupper()) #检查字符串中的字母是否全为大写,是则返回True,否则返回False
print(name.isdecimal()) #判断十进制的数字
print(name.isidentifier()) #判断是不是合法的变量名
print("-".join('abcdew')) #将序列中的元素以指定的字符连接生成一个新的字符串指定的字符串是join前面的双引号可以为空或者空格
p = str.maketrans("abcdefg", "1234567") #"abcdefg"和"1234567"前面和后面的字符是一一对应的下面的字符串会把有前面的字母替换成和它对应的这个只是一个映射关系。和下面的一起使用
print("my name is Tom".translate(p)) #输出为my n1m5 is Tom
print(name.ljust(width[,fillchar])) #返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串,fillchar默认为空格。fillchar='-'也可以,但是这个里面只能有一个字符如fillchar='--'这个就会报错
print(name.lower()) #转换字符穿中所有大写字符为小写
print(name.upper()) #转换字符穿中所有小写字符为大写
print(name.lstrip()) #截掉字符串左边的空格或指定字符
print(name.rstrip()) #截掉字符串右边的空格或指定字符
print(name.strip()) #截掉字符串左边和右边的空格或指定字符
print(name.replace(str1,str2[,max])) #将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次。
print(name.rfind()) #类似于 find()函数,不过是从右边开始查找
print(name.rindex()) #类似于 index(),不过是从右边开始.
print(name.rjust()) #类似于ljust,只是右对齐
print(name.split(str="", num=string.count(str)))#通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分割num个字符串,返回的是一个字符列表
print(name.splitlines([keepends])) #按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数keepends为Falsh,不包含换行符。如果为True则保留换行字符
print(name.startswith(str, beg=0,end=len(string)))#检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回False,如果参数beg和end制定值,则在指定的范围内检查
print(name.swapcase()) #将字符串中大写转换为小写,小写转换为大写
print(name.title()) #返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写,这个界限的标准就是相连的字母第一个字母改成大写,其余的改成小写
print(name.zfill()) #返回指定长度的字符串,原字符串右对齐,前面填充0。
五、元组
Python中的元组和列表相似,相当于不可变的列表。
元组使用小括号,列表使用方括号。
元组的创建和列表差不多。
元组的创建要不就是空的元组,要不创建一个元素的元组时后面必须加上都好(,),否则创建出来的为字符串
1 tuple1 = () 2 tuple2 = ('name',) 3 tuple3 = ('name') 4 print(tuple1, tuple2, tuple3) 5 6 7 8 #下面显示的就是上面运行的结果 9 #() ('name',) name
元组也属于序列中的一种所以序列支持的操作元组也支持。方法和上面序列所操作的一样。
因为元组不支持修改,但是可以删除,元组相加我们可以赋值给新的元组
同时元组也支持嵌套。因为元组的不可变,序列的一些操作都在这里面适用。
六、字典
字典是另一种可变的容器模型,且可存储任意类型对象。字典中的键值对是无序的。
字典的每个键值(key => value)对用冒号(:)分隔,每一对键值对之间用逗号(,)分隔。整个字典都在花括号中({}),格式如:
d = {key1:vlaue1, key2:value2, key3:value3}
在这里面键(key)必须是唯一的,但是值(value)可以重复,因为下面的操作有的是根据键来取相应的值。
这里面的值(value)可以是任意数据类型,但是键(key)必须是不可变的,如:字符串,数字,元组。
举个列子:
d = {"name":"Tom"} .这个可以但是当我们创建 d = {{1:2}:"Tom"}这样我们创建它就会报错。同样我们的key不能够为列表
如果我们的key为列表时,我们的字典中key是可变的。可以通过相应的操作改变其数据,这样就不符合键(key)唯一和不可变。
我们值(value)是可以为任何的数据如字典,列表什么的。
我们平常听到的字典嵌套字典,其实就是字典中的值(value)为字典。
访问字典中的值(value):
dict = {'name':'Tom', 'age':20, 'salary':5000}
print(dict['name'])
print(dict['Name'])
#下面的是上面运行的结果与上面一一对应
#Tom
#Traceback (most recent call last):
File "F:/python/day1/text.py", line 4, in <module>
print(dict['Name'])
KeyError: 'Name'
上面的代码我们可以看到,当键(key)存在于字典时他会返回对应的值(value),如果不存在的话他就会报错。
修改字典中键(key)对应的值:
1 dict = {'name':'Tom', 'age':20, 'salary':5000} 2 dict['name'] = 'Helen' 3 print(dict) 4 dict['class'] = 3 5 print(dict) 6 7 #下面是对应上面运行结果 8 #{'salary': 5000, 'name': 'Helen', 'age': 20} 9 #{'class': 3, 'salary': 5000, 'name': 'Helen', 'age': 20}
我们从上面的列子可以看到。当我们修改对应键(key)的值时,如果输入的键(key)存在,那就修改对应的值。如果间不存在,那就向字典中添加这个键值对。
删除字典中的键值对:
1 #!/usr/bin/env python 2 # -*-coding:utf-8-*- 3 d1 = {'name':'Tom', 'age':20, 'salary':5000} 4 del d1['name'] 5 print(d1) 6 d2= {'name':'Tom', 'age':20, 'salary':5000} 7 d2.clear() 8 print(d2) 9 d3 = {'name':'Tom', 'age':20, 'salary':5000} 10 del d3 11 print(d3) 12 13 #运行结果 14 {'age': 20, 'salary': 5000} 15 {} 16 Traceback (most recent call last): 17 File "F:/python/s1.py", line 11, in <module> 18 print(d3) 19 NameError: name 'd3' is not defined 20 21 Process finished with exit code 1
上面我列出了删除字典中的键值。删除字典中所有的键值。和最后删除整个字典。还有一些删除的方法比如dict.pop()和dict.popitem()。dict.pop(key) 是删除该键值对并且返回删除的值。dict.popitem()是随机删除键值对以元组的方式显示。
下面我们说下字典中的键(key),在字典中键是唯一的,所以一般只能用数字、字符串、元组。
如果我们在创建字典的时候,里面同时出现2个一样的键(key),那么会以后面的为准。如下代码
1 d1 = {'name':'Tom', 'age':20, 'salary':5000 ,'name':'Helen'} 2 print(d1) 3 4 #运行的结果 5 {'age': 20, 'name': 'Helen', 'salary': 5000}
字典的一些方法使用
字典的copy
1 d1 = {'name':'Tom', 'age':20, 'salary':5000 ,'home':{'populace':3}} 2 d2 = d1.copy() 3 print(d1) 4 print(d2) 5 d1['name'] = 'Helen' 6 d1['home']['populace'] = 5 7 print(d1) 8 print(d2) 9 10 #运行的对应的结果 11 {'salary': 5000, 'age': 20, 'name': 'Tom', 'home': {'populace': 3}} 12 {'salary': 5000, 'age': 20, 'name': 'Tom', 'home': {'populace': 3}} 13 {'salary': 5000, 'age': 20, 'name': 'Helen', 'home': {'populace': 5}} 14 {'salary': 5000, 'age': 20, 'name': 'Tom', 'home': {'populace': 5}}
与上面的结果可以看出这个copy属于浅copy,我以前也说过关于浅copy。也就是它只会复制第一层的数据,如果字典中嵌套字典那么我们copy过来的嵌套的字典和被copy字典中的嵌套字典内存中的地址是一样的。所以改变其中一个嵌套的字典值,其他的也会改变,上面举得例子我们嵌套的是字典,嵌套其它可变数据类型都是相同的结果。
fromkey()函数
1 seq = ('name', 'age', 'sex') 2 3 dict = dict.fromkeys(seq) 4 print ("新的字典为 : {}".format(dict)) 5 6 dict = dict.fromkeys(seq, 10) 7 print ("新的字典为 : {}".format(dict)) 8 9 10 #运行的结果 11 新的字典为 : {'sex': None, 'name': None, 'age': None} 12 新的字典为 : {'sex': 10, 'name': 10, 'age': 10}
dict.fromkey(seq[,value])函数我们可以看到是用来创建一个新的字典,seq作为字典的键(key)来做,value作为字典初始化的值,它可有可无,当没有的时候会默认为空
dict.get(key, default=None)
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> d1.get('name') 3 'Tom' 4 >>> d1.get('home') 5 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 6 >>> print(d1.get('name')) 7 Tom 8 >>> print(d1.get('home')) 9 None 10 >>> print(d1.get('home', 'aaa')) 11 aaa
从上面的代码中我们可以知道,使用dict.get()方法查找想要键(key)对应的值比我们上面的方法好点。
因为当我们查找的键(key)存在时,会返回相应的值,但是当我们查找的键(key)不存在时使用dict.get()方法,不会报错,如果设置了不存在时有相应返回的值那就会返回你设置的那个值,如果没有设置会默认为None。然而我们前面所说到的方法会报错。所以以后使用dict.get()方法来查找相应的值。
key in dict
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> print('name' in d1) 3 True
这个是为了查询某个键是否在这个字典中如果存在那就返回True,否则返回Flash
dict.items()
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> print(d1.items()) 3 dict_items([('age', 20), ('name', 'Tom'), ('salary', 5000)])
这个是以列表的返回可遍历的(key,value)元组数组
dict.keys()
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> print(d1.keys()) 3 dict_keys(['age', 'name', 'salary'])
这个是以列表的方式返回字典中所有的键
dict.setdefault(key, default = None)
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> d1.setdefault('home') 3 >>> print(d1) 4 {'home': None, 'age': 20, 'name': 'Tom', 'salary': 5000} 5 >>> d1.setdefault('sex',2400) 6 2400 7 >>> print(d1) 8 {'home': None, 'sex': 2400, 'age': 20, 'name': 'Tom', 'salary': 5000}
这个函数和上面的dict.get()差不多,不过当查询的键(key)不存在时,它会自动把这个键添加到字典中,默认的值为None,可以自己给它一个值。
dict.update(dict2)
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> d2 = {'mom':'Kate' ,'father':'Bob'} 3 >>> d2 = {'mom':'Kate' ,'father':'Bob', 'name':'Jack'} 4 >>> print(d1.update(d2)) 5 None 6 >>> print(d1) 7 {'mom': 'Kate', 'age': 20, 'name': 'Jack', 'salary': 5000, 'father': 'Bob'}
上面的代码中我们可以知道,这个就相当于把dict2中的键值对更新到dict中,如果dict2和dict有相同的键,那么更新后的字典中相同的键会以dict2的键值为主,相当于实时更新。
dict.values()
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> print(d1.values()) 3 dict_values([20, 'Tom', 5000])
这个和上面的dict.keys()一样不过他返回的列表是以字典中的值作为元素的。
dict.pop(key[,default])
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> print(d1.pop('name')) 3 Tom
这个 就是删除字典中的键值对,返回的是删除的键的对应的值
dict.popitem()
1 >>> d1 = {'name':'Tom', 'age':20, 'salary':5000 } 2 >>> d1.popitem() 3 ('age', 20) 4 >>> print(d1) 5 {'name': 'Tom', 'salary': 5000}
在上面的实验可以看出,这个函数是随机在字典中删除键值对。并返回删除的键值对。
七、字符的转换
Python3中的一大新的概念就是文本和二进制的区分,不会出现二者混用的概念。想要详细理解二者之间的关系可以自行上网搜下Python3的bytes/str之别。上面有详细的介绍与解释。下面的代码就是关于二者之间的转换。
1 >>> f = '欢迎光临' 2 >>> type(f) 3 <class 'str'> 4 >>> f1 = f.encode('utf-8') 5 >>> print(type(f1),f1) 6 <class 'bytes'> b'\xe6\xac\xa2\xe8\xbf\x8e\xe5\x85\x89\xe4\xb8\xb4' 7 >>> f2 = f1.decode('utf-8') 8 >>> print(type(f2),f2) 9 <class 'str'> 欢迎光临
上面在转换时,你要告诉你现在的编码格式是什么上面的实验室以'utf-8'的格式来相互转换的。
说完了字符和二进制的转换,现在我们学一个小知识。
三元运算符
三元运算符就是在赋值变量的时候可以加以判断,在直接赋值。
1 >>> a = 5 2 >>> b = 6 3 >>> c = a if a>b else b 4 >>> print(c) 5 6 6 >>> if a > b : 7 ... c = a 8 ... else: 9 ... c = b 10 ... 11 >>> print(c) 12 6
上面的代码前面使用的三元运算符来赋值,下面的是使用的if-else判断语句
三元运算符还有一些其他的的应用现在简单介绍下赋值一方面的,同时还可以运用在列表、字典、集合上等。
这期的学习就分享到这里,如果文中有什么错误的或不完善的,希望发现的您可以指出来让我这个小白学习学习。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号