SpringBoot第九篇:整合Spring Data JPA
作者:追梦1819
原文:https://www.cnblogs.com/yanfei1819/p/10910059.html
版权声明:本文为博主原创文章,转载请附上博文链接!
前言
前面几章,我们介绍了 JDBCTemplate、MyBatis 等 ORM 框架。下面我们来介绍极简模式的 Spring Data JPA。
Spring Data JPA
简介
我们先来了解几个基本概念,捋一下各个概念之间的关系。
1、JPA
JPA是Java Persistence API的简称,中文名Java持久层API,SUN公司出品。是 JDK 5.0 注解或 XML 描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
它的出现目的有两个:
- 简化数据库访问层;
- 实现 ORM 框架的统一(目前还没有完全做到)。
2、JPA 和 hibernate 的关系
-
JPA 是 Hibernate 的一个抽象,就像 JDBC 和 JDBC 驱动的关系;
-
JPA 是一种 ORM 规范,是 Hibernate 功能的一个子集 ;
-
Hibernate 是 JPA 的一个实现;
3、Spring Data
众所周知,Spring 是一个大家庭,一个技术的生态圈,其中整合的内容包罗万象。而 Spring Data xxx 系列就是 Spring 这个生态圈对数据持久化层的整合。
Spring Data是Spring用来解决数据访问的解决方案,它包含了大量关系型数据库以及NoSQL数据库的数据持久层访问解决方案。它包含Spring Data JPA、Spring Data MongoDB、Spring Data Neo4j、Spring Data GernFile、Spring Data Cassandra等。
目前现有的 Spring-data-jpa,Spring-data-template,Spring-data-mongodb,Spring-data-redis 等。当然,也包括最开始用的 mybatis-spring ,MyBatis 与 Spring 的整合。
于是,就出现了 Spring-data-jpa ,Spring 与 JPA 的整合。
具体详情参看 Spring Data 官网介绍 。
4、关于 "dao"
在 Java web 项目中,我们经常会看到这个包名或者以它为后缀名的类名,它所代表的是,数据库持久化层,是 Data Access Object 的简写。不过有时候我们也会看到 mapper 等。其实这些都是同一个意思,代表数据库持久化层。
在 JDBCTemplate 中,可能会用 "dao",在 MyBatis 中,可能会用 "mapper"(对应 xxxMapper.xml文件),在 JPA 中,可能会用"repository"等。
其实名称完全是自定义,只不过开发者在开发的时候会有一些约定俗成的习惯,仅此而已。
5、Spring Data JPA
正如上所说,Spring Data JPA 是 Spring 与 JPA 的整合。是基于 JPA 对数据库访问层的增强支持。旨在简化数据库访问层,减少工作量。
具体详情参看 Spring Data JPA 官网。
核心概念
对于开发者来说,使用起来很简单。下面我们看看 Spring Data JPA 几个核心概念。
-
Repository:最顶层的接口,是一个空的接口,目的是为了统一所有Repository的类型,且能让组件扫描的时候自动识别;
-
CrudRepository :是Repository的子接口,提供CRUD的功能;
@NoRepositoryBean public interface CrudRepository<T, ID> extends Repository<T, ID> { <S extends T> S save(S entity); <S extends T> Iterable<S> saveAll(Iterable<S> entities); Optional<T> findById(ID id); boolean existsById(ID id); Iterable<T> findAll(); Iterable<T> findAllById(Iterable<ID> ids); long count(); void deleteById(ID id); void delete(T entity); void deleteAll(Iterable<? extends T> entities); void deleteAll(); } -
JpaRepository:是PagingAndSortingRepository的子接口,增加了一些实用的功能,比如:批量操作等;
@NoRepositoryBean public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> { List<T> findAll(); List<T> findAll(Sort var1); List<T> findAllById(Iterable<ID> var1); <S extends T> List<S> saveAll(Iterable<S> var1); void flush(); <S extends T> S saveAndFlush(S var1); void deleteInBatch(Iterable<T> var1); void deleteAllInBatch(); T getOne(ID var1); <S extends T> List<S> findAll(Example<S> var1); <S extends T> List<S> findAll(Example<S> var1, Sort var2); } -
PagingAndSortingRepository:是 CrudRepository 的子接口,添加分页和排序的功能;
@NoRepositoryBean public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> { Iterable<T> findAll(Sort sort); Page<T> findAll(Pageable pageable); } -
Specification:是Spring Data JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件即可;
public interface Specification<T> extends Serializable { long serialVersionUID = 1L; static <T> Specification<T> not(Specification<T> spec) { return Specifications.negated(spec); } static <T> Specification<T> where(Specification<T> spec) { return Specifications.where(spec); } default Specification<T> and(Specification<T> other) { return Specifications.composed(this, other, CompositionType.AND); } default Specification<T> or(Specification<T> other) { return Specifications.composed(this, other, CompositionType.OR); } @Nullable Predicate toPredicate(Root<T> var1, CriteriaQuery<?> var2, CriteriaBuilder var3); } -
JpaSpecificationExecutor:用来做负责查询的接口。
public interface JpaSpecificationExecutor<T> { Optional<T> findOne(@Nullable Specification<T> var1); List<T> findAll(@Nullable Specification<T> var1); Page<T> findAll(@Nullable Specification<T> var1, Pageable var2); List<T> findAll(@Nullable Specification<T> var1, Sort var2); long count(@Nullable Specification<T> var1); }
Spring Data JPA的使用
下面我们演示几种 JPA 的使用。
使用内置方法
构建SpringBoot项目,首先引入 maven 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
然后,application.properties 中配置相关的信息:
server.address=
server.servlet.context-path=
server.port=8082
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.1.88:3306/test?serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=pass123
# 第一次建表用create,后面使用update
# 不然每次重新系统工程都会先删除表再新建
spring.jpa.hibernate.ddl-auto=create
# 控制台打印sql
spring.jpa.show-sql=true
下一步,创建实体类 User:
package com.yanfei1819.jpademo.entity;
import javax.persistence.*;
/**
* Created by 追梦1819 on 2019-05-05.
*/
@Entity
@Table(name="user")
public class User {
@Id
// 字段自动生成
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private int age;
private String name;
// set/get 省略
}
再者,创建 dao 层:
package com.yanfei1819.jpademo.repository;
import com.yanfei1819.jpademo.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
/**
* Created by 追梦1819 on 2019-05-05.
*/
public interface UserRepository extends JpaRepository<User,Long> {
}
最后,创建controller 层(此处为了简化代码,省略了 service 层):
package com.yanfei1819.jpademo.web.controller;
import com.yanfei1819.jpademo.entity.User;
import com.yanfei1819.jpademo.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.List;
/**
* Created by 追梦1819 on 2019-05-05.
*/
@Controller
public class UserController {
@Autowired
private UserRepository userRepository;
@ResponseBody
@GetMapping("/queryUser")
public List<User> queryUser(){
// 通过 jpa 内置的方法进行查询
return userRepository.findAll();
}
}
在上述示例中,我们使用的是 JPA 的内置方法 findAll() ,另外也有很多别的方法,如下:
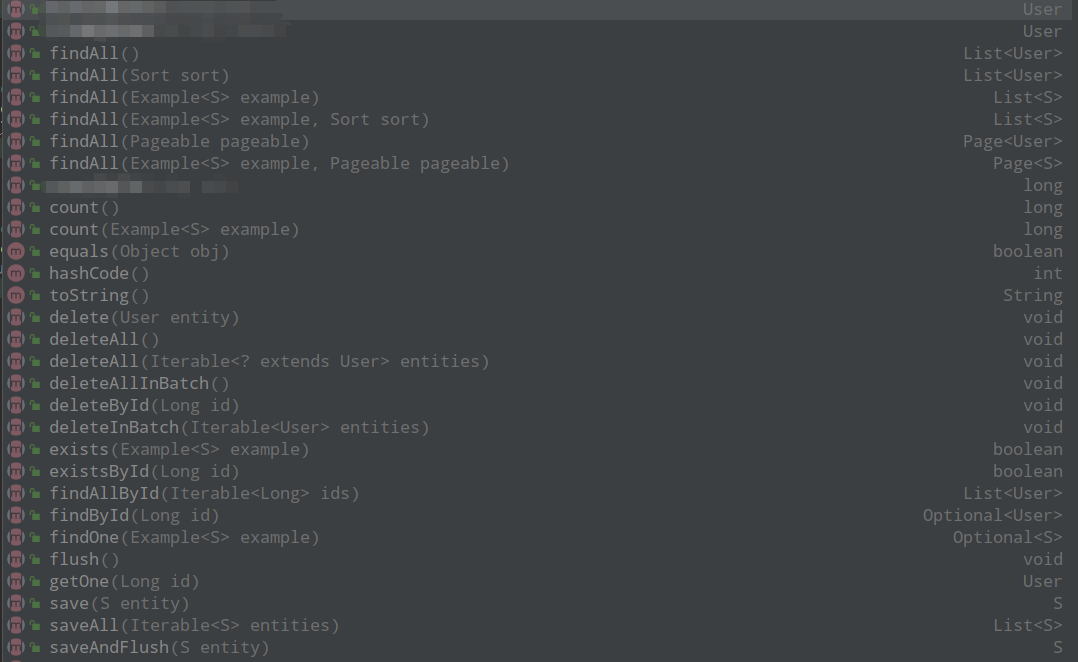
写了几个查询方法。
创建查询方法
在以上示例的基础上,我们添加一个新的方法:
UserController:
@ResponseBody
@GetMapping("/queryUser/{name}")
public User queryUserByName(@PathVariable String name){
// 通过自定义的方法进行查询
return userRepository.findByName(name);
}
UserRepository:
User findByName(String name);
spring-data-jpa 会根据方法的名字来自动生成 sql 语句,Spring Data JPA 支持通过定义在 Repository 接口中的方法名来定义查询,方法名是根据实体类的属性名来确定的。我们只需要按照方法定义的规则即可。其中findBy关键字可以用find、read、readBy、query、queryBy、get、getBy替代。
这种方式不仅仅限制这种简单的参数支持,还包括限制返回的查询的结果、返回流式查询结果、异步查询等,可以参看示例:
// 限制查询结果
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);
// 返回流式查询结果
Stream<User> readAllByFirstnameNotNull();
// 异步查询
@Async
Future<User> findByFirstname(String firstname);
@Query查询
在上述示例中添加新的方法:
UserController:
@ResponseBody
@GetMapping("/queryUser2/{id}")
public User queryUserById(@PathVariable Long id){
// 通过 @Query 注解查询
return userRepository.withIdQuery(id);
}
UserRepository:
// @Query("select u from User u where u.id = :id ")
@Query(value = "select u from User u where u.id = ?1 ",nativeQuery = true)
User withIdQuery(@Param("id") Long id);
使用这种命名查询来声明实体查询是一种有效的方法,适用于少量查询。上面的 @Query 注解需要注意的是:
1、@Query(value = "select u from User u where u.id = ?1 ",nativeQuery = true) 中的 nativeQuery 属性如果设置为 true 时,表示的意思是:可以执行原生sql语句,所谓原生sql,也就是说这段sql拷贝到数据库中,然后把参数值给一下就能运行了,原生的 sql 都是真实的字段,真实的表名。如果设置为 false 时,就不是原生的 sql ,而不是数据库对应的真正的表名,而是对应的实体名,并且 sql 中的字段名也不是数据库中真正的字段名,而是实体的字段名;
2、nativeQuery 如果不设置时,即 @Query("select u from User u where u.id = ?1 ") ,默认是 false;
3、 @Query("select u from User u where u.id = ?1 ") 可以写成 @Query("select u from User u where u.id = :id ") 。
4、如涉及到删除和修改在需要加上@Modifying.也可以根据需要添加 @Transactional对事物的支持,查询超时的设置等。
@NamedQuery查询
在以上的示例中,为了区分 User 实体类,我们重新创建一个实体类 UserVo:
package com.yanfei1819.jpademo.entity;
import javax.persistence.*;
/**
* Created by 追梦1819 on 2019-05-23.
*/
@Entity
@Table(name = "user")
@NamedQuery(name = "findAll",query = "select u from User u")
public class UserVo {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
@Column(name = "age")
private int age;
@Column(name = "name")
private String name;
// get/set 省略
}
在 UserController 中加一个方法:
@Autowired
private EntityManager entityManager;
@ResponseBody
@GetMapping("/queryUserByNameQuery")
public List<UserVo> queryUserByNameQuery(){
// 通过 @Query 注解查询
return entityManager.createNamedQuery("findAll").getResultList();
}
启动程序,访问 http://localhost:8082/queryUserByNameQuery ,能够查询到所有用户:
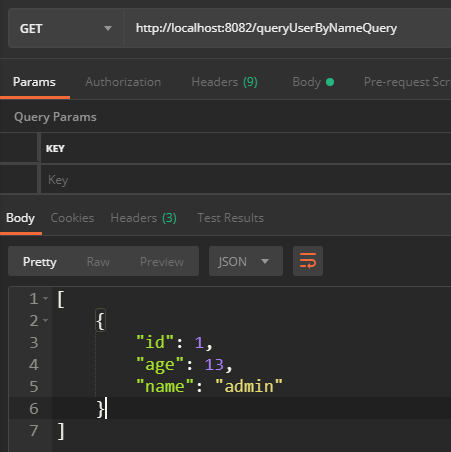
再看看控制台打印结果:

注意一点,如果是多个查询,可以使用 @NamedQuerys 。
笔者其实并不推荐使用这种自定义方法,因为它对实体类的污染很严重。不利于可读性。
总结
JPA 可以单独使用,只不过 SpringBoot 这个大平台将该技术引入进来。
JPA也是一个大的分支,细枝末节有很多,作者认为,对于 JPA 的学习,只要关注三个方面:
1) ORM 映射元数据,支持 XML 和 JDK 注解两种元数据的形式;
2) 核心的 API;
3) 查询语言:JPQL。
当然,如果感兴趣的,可以好好研究一下 JPA 的官方文档,深入研读一下其源码。此处由于篇幅所限,就不一一阐述。后续有时间会开设一个 JPA 专栏,专门讲述这一大分支,欢迎大家持续关注。
话分两头,另一方面,正如前面几章说的,各个 ORM 技术框架各有优缺点,没有一种框架是绝对完美的。技术、框架的选型,没必要追求最新,追求最适合即可。
源码:我的GitHub
参考

本文来自博客园,作者:追梦1819,转载请注明原文链接:https://www.cnblogs.com/yanfei1819/p/10910059.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号