

Linux使用jmeter对数据库进行压测
编写原因:
最早接触中石油的jmeter的linux一直没有时间整理,现在正好借着邮政的项目进行了深度的研究,最终将整体的压测流程的最”完美”文档编写出来 ,手把手的部署jemter的linux压测~~
开始执行压测步骤
将jmeter的文件放到你的linux系统中(我这里就是用centols7系统了)

检查java版本
Why?
jmeter是基于java来进行开发的所以我们再使用jmeter压测时一定要确认是否有java环境
[root@localhost bin]# java -version
授予jmeter执行权限
在windows中我们直接点看jmeter.bat程序就可以运行了,单如果想要在linux中运行就必须给咱们的文件运行权限才行
[root@localhost bin]# chmod +x jmeter-server
[root@localhost bin]# chmod +x jmeter

文件含义
Jmeter:执行jmeter压测的程序
Jmeter-server:jmeter的多并发压测服务器启动脚本
这里要引出一个jmeter的特性:
jmeter分布式测试:
jmeter提供了一个分布式压测的压测方案:
使用Master-Slave模式,用master机控制多台slave负载机,向被测服务器发送请求,从而能够支持几千几万的较大并发。
master机负责测试脚本的分发、启动、停止、从slave收集测试结果等工作。
如图:
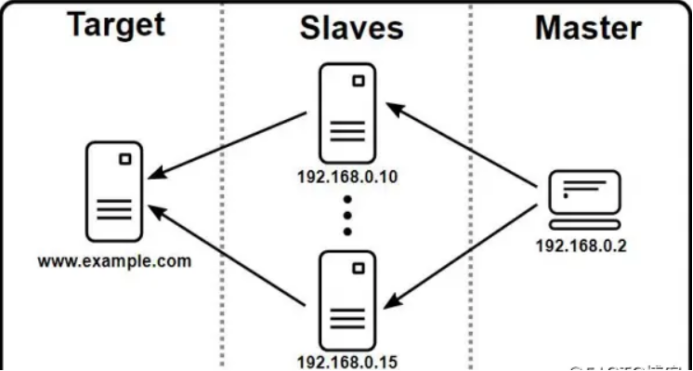
(当然本次的压测因为我只有开了一台机器,分布式压测我就不做了...)
配置我们jmeter使用的内存
Why??
我这里使用的虚拟机配置(贴出来:)
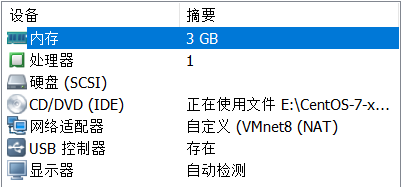
3g的内存貌似看起来也够,但往往jmeter默认压测时需要使用6-8g的内存(这么多的内存上哪弄??)没事我们可以调整jmeter的文件来让它默认使用的内存小一点:
打开jmeter文件:
查找:”/heap”
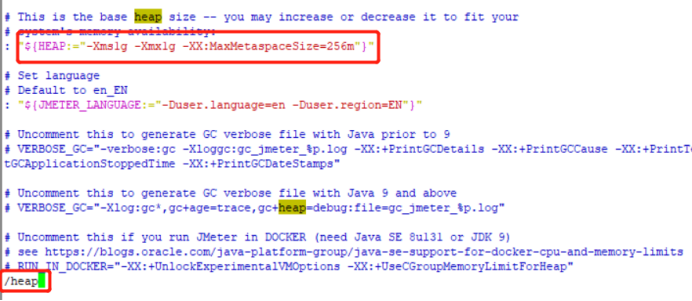
修改内存:
单位:m:兆 g:GB
我这里已经修改完了,实际的内存根据自己的机器的内存来决定.
"${HEAP:="-Xms1g -Xmx1g -XX:MaxMetaspaceSize=256m"}"

解释一下这里的意思:
-Xms1g -Xmx1g:设置jvm堆内存大小阀值:初始值 512m 最大值1024m 一般把2个值设置一样大 保证jvm不会频繁gc
创建jmeter的测试计划
因为在linux中的jmeter没有图形化因此测试计划创建起来得需要使用windows端来进行配合(说白了就是使用windows创建测试计划然后把测试计划放到linux端去执行.)【当然如果你是大佬你可以自己编写,】
:打开我们的windows端的jmeter
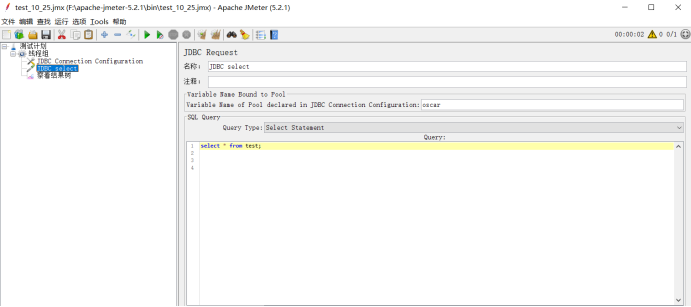
一些必要的信息要填写好,我这里为了方便就直接拿弄好的测试计划了,如果不会配置去看我的windows配置说明,哪里啥都有哈哈哈
但这里注意一点:
驱动包的路径这个一定要注意修改,当然如果不修改也没关系,后面我会在linux中进行简单的测试计划修改.

ok,当测试计划编写完毕后就可以把测试计划拿出来了
关闭jmeter----拿出测试计划!
创建两个目录存放一会我们的测试计划:
[root@localhost bin]# mkdir report
[root@localhost bin]# mkdir script
文件放进去之后就开始我们的第六步
放入数据库的驱动
要压测数据库就需要驱动进行连接,所以放入数据库的驱动
[root@localhost lib]# pwd
/root/learn_jmeter/apache-jmeter-5.2.1/lib
[root@localhost lib]# mv /opt/ShenTong/jdbc/oscarJDBC.jar ./
[root@localhost lib]# ls oscarJDBC.jar
oscarJDBC.jar
修改测试计划
前面如果没有修改驱动包的路径,那也不要紧,因为在linux里我们还能继续修改
打开测试计划:
[root@localhost script]# vim test_10_25.jmx
找到:”TestPlan.user_define_classpath”

把路径改成我们linux系统里面驱动包的路径:
<stringProp name="TestPlan.user_define_classpath">/root/learn_jmeter/apache-jmeter-5.2.1/lib/oscarJDBC.jar</stringProp>

这里对应着我们的测试计划的语句简单介绍下,如果不明白那就继续在windows上调整好在放进来也是可以的
|
name="dbUrl" |
对应着我们的url串 |
|
name="driver" |
类名 |
|
name="username" |
连接用户 |
|
name="password" |
账户密码 |
|
name="dataSource" |
jdbc连接名 |
|
name="query" |
测试语句 |
|
guiclass="ThreadGroupGui" |
线程组配置 |
|
name="queryType" |
测试语句类型 |
(目前先介绍一下常用的,如果有兴趣可以和weindows对比然后再继续添加)
修改测试jmeter分布式压测参数
Why??
上面说了我们不需要执行jmeter分布式压测,那么为什么还需要配置呢??
因为我们不需要压测但是我们的linux得需要启动jmeter-server服务才能进行压测,我们需要通过jmeter-server服务来指定自己本身为slave进行压测
打开分布式压测配置文件:
查找:
/remote_hosts

使用本机的话就默认127.0.0.1就可以
查找:
/disable
#server.rmi.ssl.disable=false
把注释去掉
server.rmi.ssl.disable=true

server.rmi.ssl.disable含义:在最新的jmeter版本中jmeter分布式压测使用的通信协议是通过key的方式建立的这个参数就是打开rmi通信建立渠道。
启动jmeter-server服务
上述一些压测参数的配置已经基本完成了,现在开始要启动我们的jmeter服务
[root@localhost bin]# ./jmeter-server -Djava.rmi.server.hostname=192.168.137.12
使用jmeter-server服务远程到本机进行压测
如果遇到:
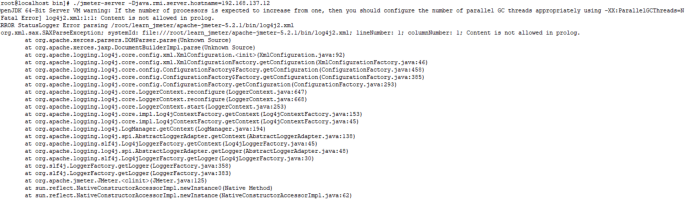
ERROR StatusLogger Error parsing log4j2.xml
这个是log4j2.xml文件的问题
打开文件: vim log4j2.xml
删掉所有的信息
添加:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Properties>
<property name="log_level" value="info" />
<Property name="log_dir" value="log" />
<property name="log_pattern"
value="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%p] - [%t] %logger - %m%n" />
<property name="file_name" value="test" />
<property name="every_file_size" value="100 MB" />
</Properties>
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="${log_pattern}" />
</Console>
<RollingFile name="RollingFile"
filename="${log_dir}/${file_name}.log"
filepattern="${log_dir}/$${date:yyyy-MM}/${file_name}-%d{yyyy-MM-dd}-%i.log">
<ThresholdFilter level="DEBUG" onMatch="ACCEPT"
onMismatch="DENY" />
<PatternLayout pattern="${log_pattern}" />
<Policies>
<SizeBasedTriggeringPolicy
size="${every_file_size}" />
<TimeBasedTriggeringPolicy modulate="true"
interval="1" />
</Policies>
<DefaultRolloverStrategy max="20" />
</RollingFile>
<RollingFile name="RollingFileErr"
fileName="${log_dir}/${file_name}-warnerr.log"
filePattern="${log_dir}/$${date:yyyy-MM}/${file_name}-%d{yyyy-MM-dd}-warnerr-%i.log">
<ThresholdFilter level="WARN" onMatch="ACCEPT"
onMismatch="DENY" />
<PatternLayout pattern="${log_pattern}" />
<Policies>
<SizeBasedTriggeringPolicy
size="${every_file_size}" />
<TimeBasedTriggeringPolicy modulate="true"
interval="1" />
</Policies>
</RollingFile>
</Appenders>
<Loggers>
<Root level="${log_level}">
<AppenderRef ref="Console" />
<AppenderRef ref="RollingFile" />
<appender-ref ref="RollingFileErr" />
</Root>
</Loggers>
</Configuration>
执行jmeter压测测试
上面我们已经把jmeter-server服务开启了,那么现在让我们使用jmeter开始进行我们的最终目的!
[root@localhost bin]# ./jmeter -n -t script/test_10_25.jmx -r -l report/test_log_25_1.jtl -j report/test_log_25_5.log
说一下含义:
-n : 使用非GUI页面进行压缩
-t : 测试计划的路径
-r : 设置为远程执行
-l : 压测报告的路径
-j : 压测日志的路径

执行之后会看到如下过程:
生成报告
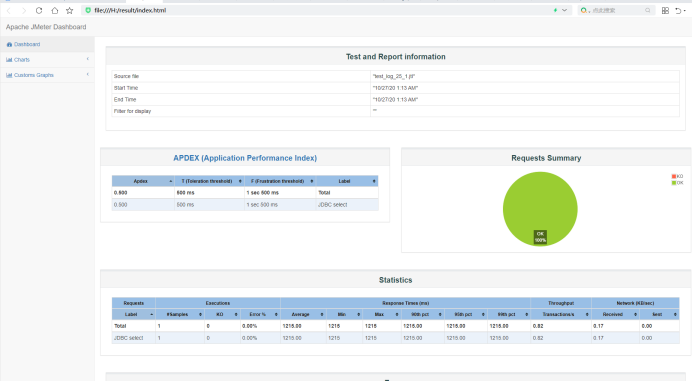
既然我们已经执行完压测结果了,那么就该做测试的最后一步生成一份可视化的报告.
执行:
[root@localhost ~]# mkdir result
[root@localhost bin]# ./jmeter -g report/test_log_25_1.jtl -e -o /root/result
-e : 路径
-o : 生成一个index文件的报告
注意:在执行jmeter的时候一定要选择空的目录否则无法生成报告!
然后我们进入到生成报告的目录>
[root@localhost ~]# cd result
[root@localhost result]# ls
content index.html sbadmin2-1.0.7 statistics.json
把东西拿到我们的windows机器上,当然如果你有火狐或者curl命令打开也不是不可以哈哈哈


Ok!至此jmeter的linux压测也就写到这里了,如果上面有什么地方说的不对的欢迎大佬指正~

