浅谈TCP和UDP
简介

在计算机网络中,TCP(传输控制协议)和UDP(用户数据报协议)是两个常用的传输层协议。它们分别提供了可靠的数据传输和快速的数据传送,成为互联网世界中的双子星。本文将探讨TCP和UDP的特点、优势和应用场景,以及如何选择合适的协议来满足不同的需求。
TCP定义
英文名:Transmission Control Protocol
中文名:传输控制协议
协议说明:TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议。
举例:打电话,需要双方都接通,才能进行对话
特点:效率低,数据传输比较安全
UDP定义
英文名:User Datagram Protocol
中文名:数据报协议
协议说明:UDP是一种面向无连接的传输层通信协议。
举例:发短信,不需要双方建立连接,But,数据报的大小应限制在64k以内
特点:效率高,数据传输不安全,容易丢包
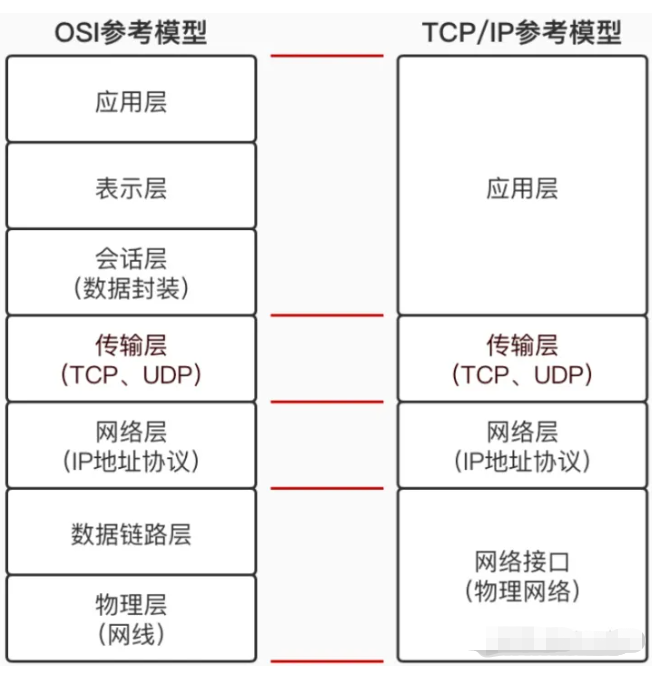
OSI模型与TCP/IP模型
TCP协议
TCP是一种面向连接的、可靠的传输控制协议,是互联网通信中最常用的协议之一。TCP的设计目标是提供可靠的数据传输、流量控制和拥塞控制机制,以确保数据在网络中准确无误地传输。
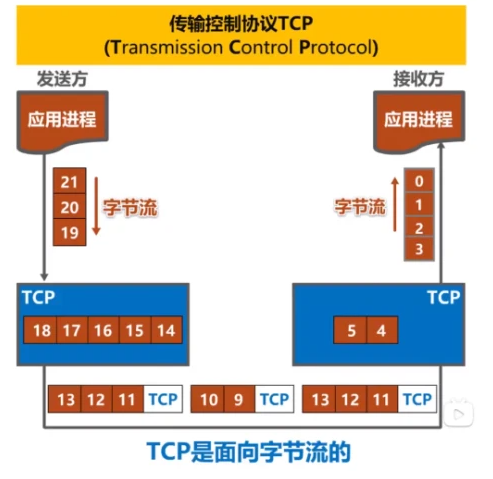
TCP协议总结起来主要有以下几个特点
-
面向连接:在TCP通信中,发送端和接收端之间需要建立一个可靠的连接,这个连接在数据传输结束后再关闭。连接的建立和断开是通过三次握手和四次挥手来完成的。
-
可靠性:TCP提供可靠的数据传输机制。它通过序列号、确认应答和重传机制来确保数据的准确传输。发送端将数据划分为称为TCP段的小块,并在每个段上添加一个序列号。接收端通过确认应答来确认已收到的数据,并可以要求发送端重新传输丢失的数据。
-
流量控制:TCP具有流量控制机制,用于控制数据发送的速率,以避免接收端无法处理过多的数据而导致的数据丢失。接收端可以通过窗口大小来通知发送端自己的接收能力,从而实现动态调整数据传输的速率。
-
拥塞控制:TCP通过拥塞控制机制来避免网络拥塞和数据丢失。它使用一种称为拥塞窗口的机制来控制数据发送的速率。当网络拥塞时,TCP会降低发送速率,从而减轻网络负载,保证网络的稳定性。
-
面向字节流:TCP是一种面向字节流的协议,将应用层传输的数据视为一连串的字节流。TCP会将数据划分为适当大小的数据段,并通过TCP头部中的序列号来对每个数据段进行标记,以便接收端正确地重组数据。
-
可靠性校验:TCP使用校验和机制来检测数据在传输过程中是否发生了错误。接收端会根据校验和的值判断数据是否被篡改,如果检测到错误,接收端会要求发送端重新传输数据。
-
有序性:TCP保证数据的有序传输。每个TCP段都有一个序列号,接收端根据序列号对接收到的数据进行排序,以确保数据按正确的顺序重新组装。
-
全双工通信:TCP支持全双工通信,即发送端和接收端可以同时进行发送和接收操作,实现双向的数据传输。
UDP协议
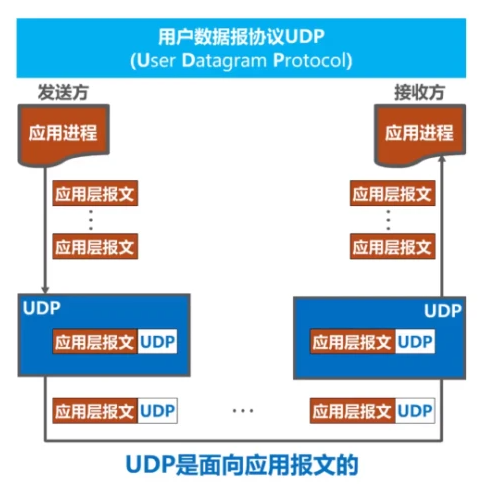
UDP是一种无连接的传输协议,相对于TCP而言,它具有以下特点:
- 无连接性:UDP是无连接的协议,发送端和接收端之间不需要建立和维护连接。每个UDP数据包都是独立的,包含完整的数据和目标端口信息。这使得UDP在数据传输的开销上比TCP更小。
- 快速传输:由于没有连接建立和维护的开销,UDP具有更低的延迟。数据包不需要等待确认应答或进行重传,因此可以更快地传输数据。这使得UDP适用于实时性要求高的应用场景,如音频和视频流传输、实时游戏和语音通信。
- 不可靠性:相对于TCP的可靠性传输,UDP是不可靠的。UDP数据包在发送后,不会保证到达接收端,也没有确认应答机制。如果在传输过程中出现丢包或错误,UDP协议本身不会进行重传或纠错,而是由应用层来处理数据的完整性和顺序性。
- 简单性:UDP的协议头较小,仅包含必要的信息,使得数据包的开销更小。UDP的设计相对简单,实现和处理也更加轻量化,使得它在资源有限的环境下更为适用。
- 支持广播和多播:UDP支持广播和多播功能。广播是将数据包发送到网络中的所有主机,而多播是将数据包发送到特定组的主机。这使得UDP适用于实现广播通信、流媒体传输和组播应用。
- 适应性:UDP对数据的处理方式非常灵活,没有严格的顺序要求。它适用于传输短消息、查询应答、简单请求响应等简单的通信模式。UDP也常用于DNS(域名系统)查询、SNMP(简单网络管理协议)以及一些轻量级的通信和传输协议。
TCP数据缓冲区
TCP协议是作用是用来进行端对端数据传送的,那么就会有发送端和接收端,在操作系统有两个空间即user space和kernal space。
每个Tcp socket连接在内核中都有一个发送缓冲区和接收缓冲区,TCP的全双工的工作模式以及TCP的流量(拥塞)控制便是依赖于这两个独立的buffer以及buffer的填充状态。
单工:只允许甲方向乙方传送信息,而乙方不能向甲方传送 ,如汽车单行道。
半双工:半双工就是指一个时间段内只有一个动作发生,甲方可以向乙方传送数据,乙方也可以向甲方传送数据,但不能同时进行,如一条窄马路同一时间只能允许一个车通行。
全双工:同时允许数据在两个方向上同时传输,它在能力上相当于两个单工通信方式的结合。
一个socket的两端,都会有send和recv两个方法,如client发送数据到server,那么就是客户端进程调用send发送数据,而send的作用是将数据拷贝进入socket的内核发送缓冲区之中,然后send便会在上层返回。也就是说send()方法返回之时,数据不一定会发送到对端即服务器上去(和write写文件有点类似),send()仅仅是把应用层buffer的数据拷贝进socket的内核发送buffer中,发送是TCP的事情,和send其实没有太大关系。
接收缓冲区把数据缓存入内核,等待recv()读取,recv()所做的工作,就是把内核缓冲区中的数据拷贝到应用层用户的buffer里面,并返回。若应用进程一直没有调用recv()进行读取的话,此数据会一直缓存在相应socket的接收缓冲区内。对于TCP,如果应用进程一直没有读取,接收缓冲区满了之后,发生的动作是:收端通知发端,接收窗口关闭(win=0)。这个便是滑动窗口的实现。保证TCP套接口接收缓冲区不会溢出,从而保证了TCP是可靠传输。因为对方不允许发出超过所通告窗口大小的数据。 这就是TCP的流量控制,如果对方无视窗口大小而发出了超过窗口大小的数据,则接收方TCP将丢弃它。
查看socket发送缓冲区大小,cat /proc/sys/net/ipv4/tcp_wmem
常见的问题
TCP粘包
TCP粘包问题是在TCP协议中常见的一个数据传输问题,指的是发送方连续发送的多个数据包在接收方接收时被粘在一起,导致接收方无法正确解析和处理数据包的边界。这种情况可能会对应用层造成困扰,因为接收方无法准确判断每个数据包的起始和结束位置,从而导致数据解析错误或数据丢失。
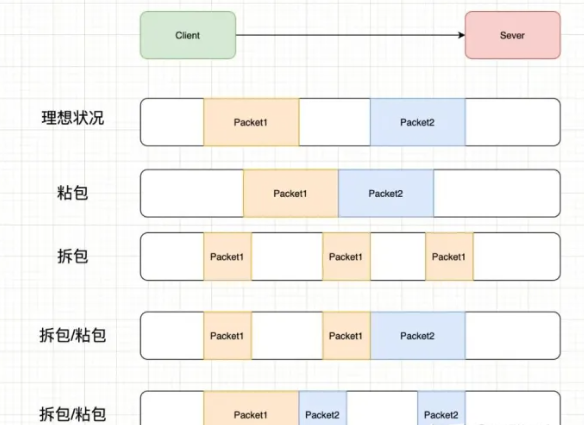
因为TCP是面向流,没有边界,而操作系统在发送TCP数据时,会通过缓冲区来进行优化,例如缓冲区为1024个字节大小。
- 如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题。
- 如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包。
粘包常见解决办法
对于粘包和拆包问题,常见的解决方案有四种:
- 发送端将每个包都封装成固定的长度,比如100字节大小。如果不足100字节可通过补0或空等进行填充到指定长度;
- 发送端在每个包的末尾使用固定的分隔符,例如\r\n。如果发生拆包需等待多个包发送过来之后再找到其中的\r\n进行合并;例如,FTP协议;
- 将消息分为头部和消息体,头部中保存整个消息的长度,只有读取到足够长度的消息之后才算是读到了一个完整的消息;
- 通过自定义协议进行粘包和拆包的处理。
Netty对TCP粘包和拆包问题的处理
Netty对解决粘包和拆包的方案做了抽象,提供了一些解码器(Decoder)来解决粘包和拆包的问题。如:
LineBasedFrameDecoder:以行为单位进行数据包的解码;
DelimiterBasedFrameDecoder:以特殊的符号作为分隔来进行数据包的解码;
FixedLengthFrameDecoder:以固定长度进行数据包的解码;
LenghtFieldBasedFrameDecode:适用于消息头包含消息长度的协议(最常用);
基于Netty进行网络读写的程序,可以直接使用这些Decoder来完成数据包的解码。对于高并发、大流量的系统来说,每个数据包都不应该传输多余的数据(所以补齐的方式不可取),LenghtFieldBasedFrameDecode更适合这样的场景。
为什么UDP没有粘包?
UDP协议不会发生粘包问题的主要原因是UDP是面向数据报的协议,每个UDP数据包都是独立的、自包含的。在UDP中,每个数据包被视为一个独立的实体,没有像TCP那样的数据流概念,因此不会发生粘包现象。
UDP协议在传输数据时,每个数据包都有自己的报文头,其中包含了目标端口、源端口、数据长度等信息。在发送端,每个UDP数据包独立发送,并且每个数据包都有固定的大小。在接收端,每次接收到一个UDP数据包时,就会被视为一个完整的数据报,而不会与其他数据包发生合并或拆分的情况。
因此,UDP协议的特性决定了它不会发生粘包问题。每个UDP数据包都具有独立性和完整性,接收方可以准确地处理每个数据包,而不需要担心数据包的边界和顺序。
然而,尽管UDP不会发生粘包问题,但它也存在其他的问题,例如数据丢失、数据无序等。由于UDP是无连接、不可靠的协议,它不提供重传机制和确认应答机制,因此在网络不稳定或拥塞的情况下,UDP数据包可能会丢失或无序到达。因此,在使用UDP进行数据传输时,应用层需要自行处理这些问题,如使用序列号、确认应答等手段来确保数据的可靠性和顺序性。
什么是零拷贝?
即所谓的 Zero-copy, 就是在操作数据时, 不需要将数据 buffer 从一个内存区域拷贝到另一个内存区域. 因为少了一次内存的拷贝, 因此 CPU 的效率就得到的提升.
在 OS 层面上的 Zero-copy 通常指避免在 用户态(User-space) 与 内核态(Kernel-space) 之间来回拷贝数据. 例如 Linux 提供的 mmap 系统调用, 它可以将一段用户空间内存映射到内核空间, 当映射成功后, 用户对这段内存区域的修改可以直接反映到内核空间; 同样地, 内核空间对这段区域的修改也直接反映用户空间. 正因为有这样的映射关系, 我们就不需要在 用户态(User-space) 与 内核态(Kernel-space) 之间拷贝数据, 提高了数据传输的效率.
而需要注意的是, Netty 中的 Zero-copy 与上面我们所提到到 OS 层面上的 Zero-copy 不太一样, Netty的 Zero-coyp完全是在用户态(Java 层面)的, 它的 Zero-copy 的更多的是偏向于 优化数据操作 这样的概念.
Netty 的 Zero-copy 体现在如下几个个方面:
Netty 提供了 CompositeByteBuf 类, 它可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝.
通过 wrap 操作, 我们可以将 byte[] 数组、ByteBuf、ByteBuffer等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作.
ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf, 避免了内存的拷贝.
通过 FileRegion 包装的FileChannel.tranferTo 实现文件传输, 可以直接将文件缓冲区的数据发送到目标 Channel, 避免了传统通过循环 write 方式导致的内存拷贝问题.
Netty的接收和发送ByteBuffer使用直接DirectBuffer内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。如果使用JVM的堆内存进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才写入Socket中。相比于使用直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号