
聊一聊:FaaS 在大规模网络爬虫的实践

1. 什么是Faas
"功能即服务"(或称为 FaaS)是一种在无状态容器中运行的事件驱动型计算执行模型,这些功能将利用服务来管理服务器端逻辑和状态。
它允许开发人员以功能的形式来构建、运行和管理这些应用包,无需维护自己的基础架构。
FaaS 是一种实现无服务器计算的方法,藉此开发人员可以编写业务逻辑,然后在完全由平台管理的 Linux 容器中执行这些业务逻辑。
该平台通常位于云端,但模型正在扩展至包含内部部署和混合部署。
无服务器会对基础架构问题进行抽象处理,例如管理或置备服务器及开发人员的资源分配,并将其提供给平台(如红帽Ⓡ OpenShiftⓇ),这样开发人员就可以专注于编写代码和实现业务价值。
功能是一个运行业务逻辑的软件。应用可以由许多功能组成。
使用 FaaS 模型是通过无服务器架构来构建应用的方法之一,但随着无服务器模式的日渐普及,开发人员正在寻找支持构建无服务器微服务和无状态容器的解决方案。
以下是 FaaS 的一些常见示例:
- AWS Lambda
- Google 云功能
- Microsoft Azure 功能(开源)
- OpenFaaS(开源)
2. 什么是 OpenFaaS
OpenFaaS作为一款开源的云原生Kubernetes Serverless平台,在2017年1月发布了第一个Release版本,其使用容器作为Serverless函数的承载体。值得一提的是,OpenFaaS在函数模板上做出的努力,其支持多种语言模板包括.NET、Dockerfile、Go、Java、NodeJS、PHP、Python、Ruby等,创建函数时,OpenFaaS为其自动生成相应的语言模板,其中包含依赖库文件、镜像Dockerfile、函数部署的yaml文件等,这样开发者只需关注于函数的逻辑实现。
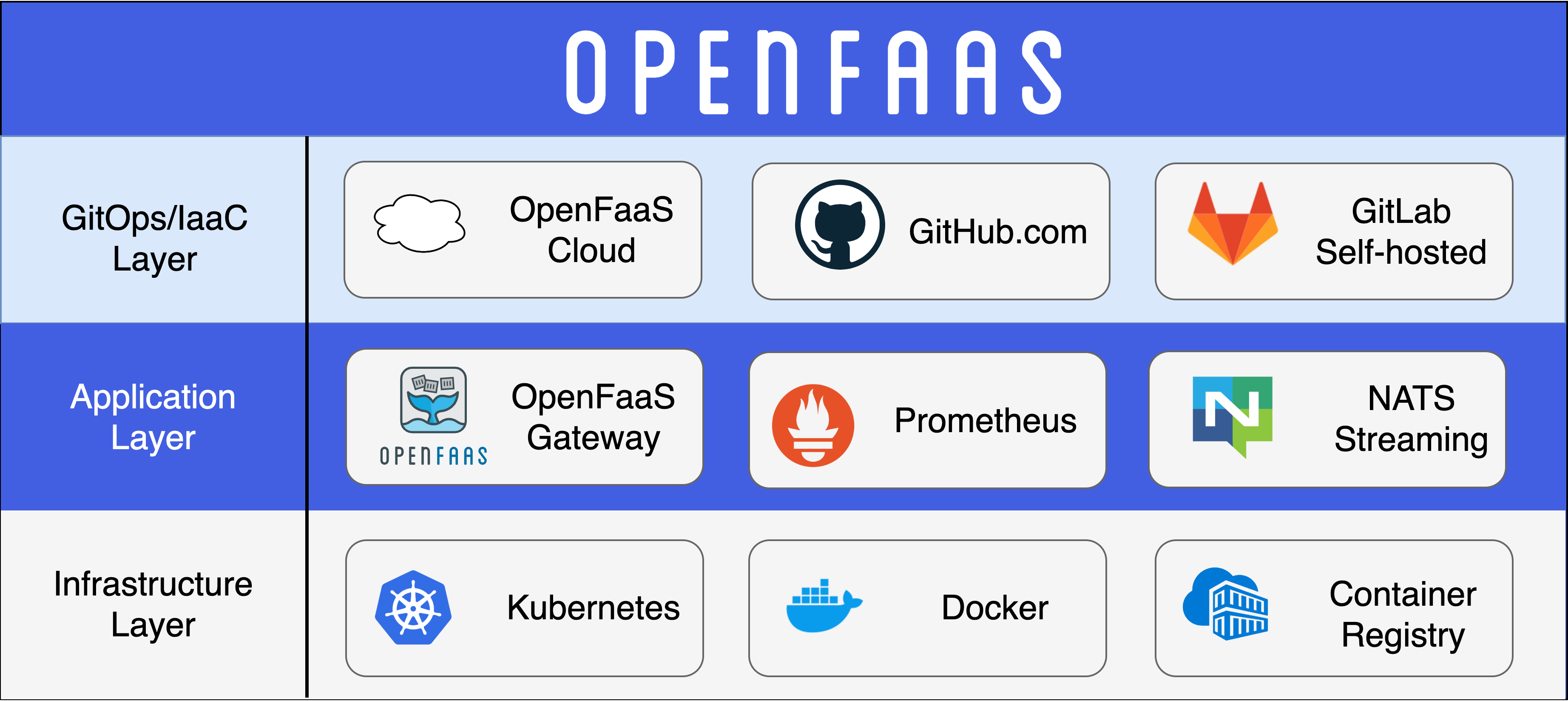
我们可以看出,OpenFaaS的基础架构体系可分为三层,每一层负责不同的部分:
基础架构层:OpenFaaS部署在Kubernetes上,以Docker运行Serverless函数,函数镜像存储至镜像仓库中;
应用层:通过OpenFaaS网关,外部用户可对Serverless函数进行CRUD和调用操作,内置的Prometheus可对函数调用行为进行监控,NATS则提供函数的异步调用;
GitOps层:OpenFaaS Cloud建立在OpenFaaS的基础上,可通过Github或自行托管的Gitlab进行DevOps交付;
除上述介绍外,OpenFaaS的正常运行还需依赖以下组件:
faas-provider: OpenFaaS提供商,可为Serverless函数提供CRUD API及调用能力
Watchdog: 负责为OpenFaaS启动和监控函数的组件;
3. 什么是大规模网络爬虫
实际上你可以将常见的搜索引擎作为一个大规模数据采集的系统的用户端产品。然而在互联网逐渐走向封闭的趋势下,搜索引擎可能已经无法让一般用户获取到自己想要寻找的数据,这也是当前网络爬虫在灰色地带肆意生长的原因。
那么从技术角度来看,一个比较完备的抓取系统需要有哪些功能:
- 可重试,轻量,灵活的抓取模块
- 可重试,幂等的Response解析落地模块
- 稳定的调度和任务分发模块
- 任务状态实时监控
- 完备清晰的日志
假如我们采用传统的架构方案,各个组件的选型可能会是这样的:
- Runtime - 实体服务器,或者虚拟机,或者容器
- 分布式存储 - HDFS / MongoDB / HBase / Cassandra等等吧
- 高性能的状态存储 - Redis / Memcached 或者直接数据库MySQL / PostgreSQL等等
- 日志存储 - ELK全套
- 定时触发器 - Quartz, Airflow或者干脆CronJob
- 消息队列 - RabbitMQ / ActiveMQ / RocketMQ / Kafka等等吧
4. Faas的技术选型
从这里可以看出实际上到此为止已经是一个相对较为复杂的但是其实也还常规的大数据架构。如果作为架构选型,更为激进的选择当前云原生的生态来实践,又会为我带来哪样一些特性:
- 将函数的超时时间扩展到我们想要的任何值
- 异步和并行运行调用
- 完成后获取带有结果的 HTTP 回调,例如 JSON 格式的屏幕截图或测试结果
max_inflight在我们的stack.yml文件中使用环境变量限制并发以防止容器过载- 从 cron 或 Kafka 和 NATS 等事件触发调用
- 从 Prometheus 获取速率、错误和持续时间 (RED) 指标,并在 Grafana 中查看它们
在网络爬虫领域,无头浏览器对许多所谓的爬虫工程师是一把双刃剑。驱动浏览器可以快速的解决一些问题,甚至不需要特别编写一些脚本,但是无头浏览器的本身又特别占用内存资源,再加上浏览器本身又会启动许多子进程,运维的难度实际是比较大的。而结合Faas的特点刚好可以解决这个问题,实现高可用、可监控、弹性伸缩的基于浏览器的服务。
我将向您介绍Puppeteer,并向您展示如何使用它来自动化和使用 OpenFaaS 功能抓取网站。
您可能希望自动化 Web 浏览器的主要原因有两个:
- 针对您的应用程序运行合规性和端到端测试
- 从没有可用 API 的网页收集信息
在测试应用程序时,有很多选项,它们分为两类:呈现的网页、使用 JavaScript 和真实浏览器运行,以及只能解析静态 HTML 的基于文本的测试。正如您想象的那样,在内存中加载一个完整的网络浏览器是一项重量级的任务。在之前的职位上,我大量使用Selenium,它具有 C#、Java、Python、Ruby 和其他语言的语言绑定。虽然我们的团队试图在单元测试层中实现我们的大部分测试,但在某些情况下,自动化 Web 测试增加了价值,这意味着 QA 团队可以通过在测试之前编写用户验收测试 (UAT) 来参与开发周期。开发人员已经开始编码。
Selenium 在业界仍然很受欢迎,它启发了W3C 的 Webdriver API 工作草案,浏览器可以实现该 API以使测试更容易。
另一个用例不是测试网站,而是在 API 不可用或没有所需端点时从中提取信息。在某些情况下,您会看到两种用例的混合,例如 - 当特定司法管辖区不提供 API 时,公司可能会使用自动网络浏览器通过网页提交税务文件。
使用 AWS Lambda 解决问题
我最近了解到一位朋友通过他的 SaaS 产品提供商标搜索,为此他选择了一种更现代的 Selenium 替代品,称为 Puppeteer。事实上,如果你在 StackOverflow 或 Google 上搜索“scraping and Lambda”,你可能会看到“Puppeteer”和“headless-chrome”一起被提及。我很好奇用 AWS Lambda 来尝试 Puppeteer,但路径并不理想,几乎每一步都存在摩擦。
- 流行的aws-chrome-lambda npm 模块大小超过 40MB,因为它提供静态二进制二进制文件,这意味着它不能作为常规 Lambda zip 文件或作为 Lambda 层上传
- zip 文件需要通过与函数位于同一区域的单独 AWS S3 存储桶上传
- 然后可以从您的函数中引用该层。
- 本地测试非常困难,关于获取 npm 模块的正确组合有很多 StackOverflow 问题
我相信这是可以做到的,并且正在大规模运行。如果小型企业不花太多时间与上述问题作斗争,并且可以保持在免费层内,那么这对小型企业来说可能非常有吸引力。
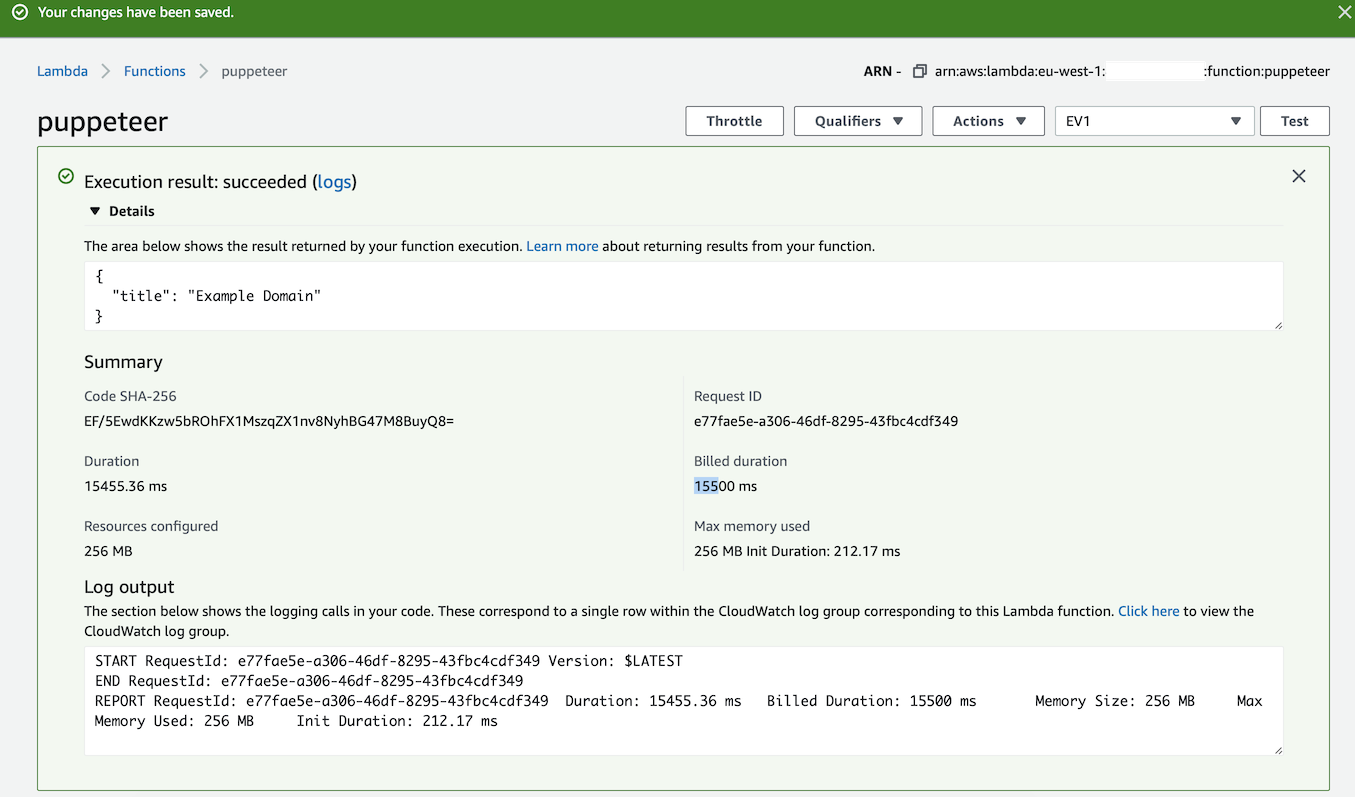
获取简单网页的标题 - 15.5s
也就是说,OpenFaaS 可以在任何地方运行,甚至可以在 5-10 美元的 VPS 上运行,而且因为 OpenFaaS 使用容器,这让我开始思考。
还有其他方法吗?
所以我想看看 OpenFaaS 的体验是否会更好。所以我开始考虑是否可以让 Puppeteer 与 OpenFaaS 一起工作,这不是我第一次去那里。这是我不时回来的事情。今天,通过buildkite.com提供预编译的无头 Chrome 浏览器,事情似乎变得更加容易。
典型任务包括登录门户并截取屏幕截图。有趣的是,当我运行一个简单的测试来导航到博客并截取屏幕截图时,这在 AWS Lambda 中需要 15.5 秒,但在我的笔记本电脑上的 OpenFaaS 中本地运行仅需要 1.6 秒。我还能够在本地构建和测试该功能,就像在云中一样。
5. OpenFaaS 实践
现在,我们将逐步介绍使用 Node.js 和 Puppeteer 设置函数的步骤,以便您调整示例并尝试可能在 AWS Lambda 上运行的现有测试。
OpenFaaS 部署选项
我们让 OpenFaaS 尽可能轻松地部署在单个 VM 或 Kubernetes 集群上。
-
如果您不熟悉容器,并且只想在保持低成本的同时提高效率,请部署到单个 VM。如果您只有几个功能,或者担心需要学习 Kubernetes,这也是理想的选择。
-
这是我们推荐用于生产用途的标准选项。通过使用容器和 Kubernetes,OpenFaaS 可以在任何云上大规模部署和运行。
许多云提供商都有自己的托管 Kubernetes 服务,这意味着获得一个工作集群是微不足道的。您只需单击一个按钮并部署 OpenFaaS,然后您就可以开始部署功能。DigitalOcean 和 Linode Kubernetes 服务特别经济。
在个人计算机上部署 Kubernetes 和 OpenFaaS
在这篇文章中,我们将在您的笔记本电脑上运行 Kubernetes,这意味着您无需在公共云上花费任何资金即可开始尝试。本教程应该花费您不到 15-30 分钟的时间来尝试。
对于不耐烦的人,我们的arkade 工具可以让您在不到 5 分钟的时间内启动并运行。您只需要在您的计算机上安装Docker。
# Get arkade, and move it to $PATH
curl -sLS https://dl.get-arkade.dev | sh
sudo mv arkade /usr/local/bin/
# Run Kubernetes locally
arkade get kind
# Kubernetes CLI
arkade get kubectl
# OpenFaaS CLI
arkade get faas-cli
# Create a cluster
kind create cluster
# Install openfaas
arkade install openfaas
该arkade info openfaas命令将打印出您登录并连接到 OpenFaaS 网关 UI 所需的所有内容。
使用 puppeteer-node12 模板创建一个函数
# Set to your Docker Hub account or registry address
export OPENFAAS_PREFIX=alexellis2
faas-cli template pull https://github.com/alexellis/openfaas-puppeteer-template
faas-cli new --lang puppeteer-node12 scrape-title --prefix $OPENFAAS_PREFIX
让我们获取通过 JSON HTTP 正文传入的网页的标题,然后将结果作为 JSON 返回。
现在编辑 ./scrape-title/handler.js
'use strict'
const assert = require('assert')
const puppeteer = require('puppeteer')
module.exports = async (event, context) => {
let browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-dev-shm-usage'
]
})
const browserVersion = await browser.version()
let page = await browser.newPage()
let uri = "https://inlets.dev/blog/"
if(event.body && event.body.uri) {
uri = event.body.uri
}
const response = await page.goto(uri)
let title = await page.title()
browser.close()
return context
.status(200)
.succeed({"title": title})
}
部署和测试scrape-title功能
将scrape-title函数部署到 OpenFaaS。
faas-cli up -f scrape-title.yml
您可以运行faas-cli describe FUNCTION以获取同步或异步 URL 以与curl函数是否已准备好进行调用一起使用。该faas-cli还可以用来调用函数,我们将做到这一点的下方。
faas-cli describe scrape-title
Name: scrape-title
Status: Not Ready
Replicas: 1
Available replicas: 0
Invocations: 0
Image: alexellis2/scrape-title:latest
Function process: node index.js
URL: http://127.0.0.1:8080/function/scrape-title
Async URL: http://127.0.0.1:8080/async-function/scrape-title
尝试同步调用该函数:
echo '{"uri": "https://inlets.dev/blog"}' | faas-cli invoke scrape-title \
--header "Content-type=application/json"
{"title":"Inlets PRO – Inlets – The Cloud Native Tunnel"}
运行time curl速度比我在分配 256MB RAM 的 AWS Lambda 上进行的测试快 10 倍。
time curl http://127.0.0.1:8080/function/scrape-title --data-binary '{"uri": "https://example.com"}' --header "Content-type: application/json"
{"title":"Example Domain"}
real 0m0.727s
user 0m0.004s
sys 0m0.004s
或者运行异步:
echo '{"uri": "https://inlets.dev/blog"}' | faas-cli invoke scrape-title \
--async \
--header "Content-type=application/json"
Function submitted asynchronously.
运行异步,将响应发布到另一个服务,如requestbin或另一个函数:
echo '{"uri": "https://inlets.dev/blog"}' | faas-cli invoke scrape-title \
--async \
--header "Content-type=application/json" \
--header "X-Callback-Url=https://enthao98x79id.x.pipedream.net"
Function submitted asynchronously.
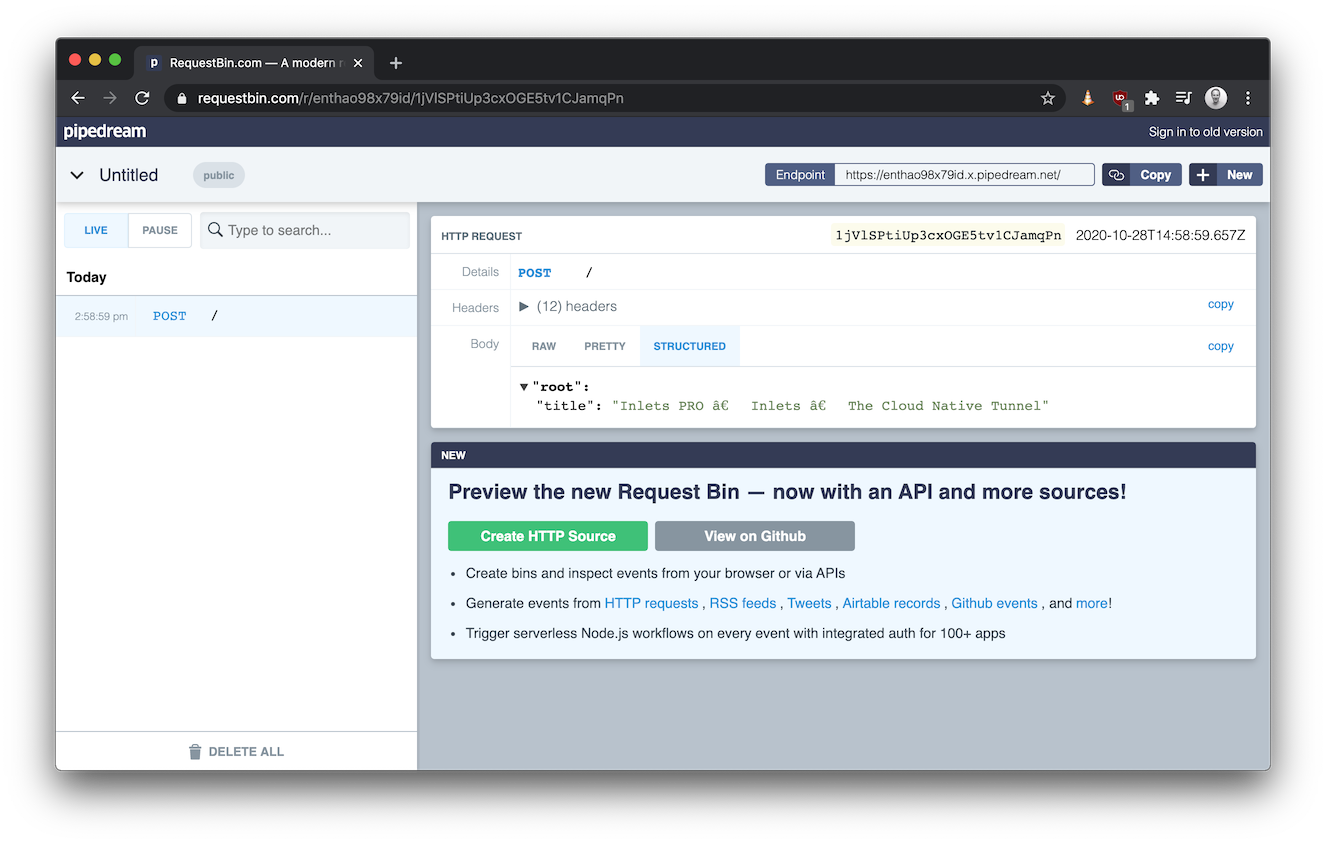
回发到 RequestBin 的结果示例
每个调用都有一个唯一的X-Call-Id标头,可用于跟踪请求并将其连接到异步响应。
截取屏幕截图并将其作为 PNG 文件返回
AWS Lambda 的限制之一是它只能返回 JSON 响应,虽然这种方法可能有充分的理由,但 OpenFaaS 允许函数的二进制输入和响应。
让我们尝试截取页面的屏幕截图,并将其捕获到文件中。
# Set to your Docker Hub account or registry address
export OPENFAAS_PREFIX=alexellis2
faas-cli new --lang puppeteer-node12 screenshot-page --prefix $OPENFAAS_PREFIX
编辑 ./screenshot-page/handler.js
'use strict'
const assert = require('assert')
const puppeteer = require('puppeteer')
const fs = require('fs').promises
module.exports = async (event, context) => {
let browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-dev-shm-usage'
]
})
const browserVersion = await browser.version()
console.log(`Started ${browserVersion}`)
let page = await browser.newPage()
let uri = "https://inlets.dev/blog/"
if(event.body && event.body.uri) {
uri = event.body.uri
}
const response = await page.goto(uri)
console.log("OK","for",uri,response.ok())
let title = await page.title()
const result = {
"title": title
}
await page.screenshot({ path: `/tmp/page.png` })
let data = await fs.readFile("/tmp/page.png")
browser.close()
return context
.status(200)
.headers({"Content-type": "application/octet-stream"})
.succeed(data)
}
现在像以前一样部署函数:
faas-cli up -f screenshot-page.yml
调用该函数,并捕获对文件的响应:
echo '{"uri": "https://inlets.dev/blog"}' | \
faas-cli invoke screenshot-page \
--header "Content-type=application/json" > screenshot.png
现在打开screenshot.png并检查结果。
制作主页横幅和社交分享图片
您还可以通过在本地渲染 HTML,然后保存屏幕截图来制作主页横幅和社交分享图像。
与 SaaS 服务不同,您无需支付月费,并且可以无限制地使用,您还可以自定义代码并随心所欲地触发它。
执行时间非常快,每个图像不到 0.5 秒,并且可以通过预加载 Chromium 浏览器并重新使用它来加快速度。如果您将图像缓存/tmp/到 CDN 或将它们保存到 CDN,则会有一位数的延迟。
# Set to your Docker Hub account or registry address
export OPENFAAS_PREFIX=alexellis2
faas-cli new --lang puppeteer-node12 banner-gen --prefix $OPENFAAS_PREFIX
编辑 ./banner-gen/handler.js
'use strict'
const assert = require('assert')
const puppeteer = require('puppeteer')
const fs = require('fs');
const fsPromises = fs.promises;
module.exports = async (event, context) => {
let browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-dev-shm-usage'
]
})
const browserVersion = await browser.version()
console.log(`Started ${browserVersion}`)
let page = await browser.newPage()
let title = "Set your title"
let avatar = "https://avatars2.githubusercontent.com/u/6358735?s=160&v=4"
console.log("query",event.query)
if(event.query) {
if(event.query.url) {
url = event.query.url
}
if(event.query.avatar) {
avatar = event.query.avatar
}
if(event.query.title) {
title = event.query.title
}
}
let html = `<html><body><h2>TITLE</h2><img src="AVATAR" alt="Avatar" width="120px" height="120px" /></body></html>`
html = html.replace("TITLE", title)
html = html.replace("AVATAR", avatar)
await page.setContent(html)
await page.setViewport({ width: 1720, height: 460 });
await page.screenshot({ path: `/tmp/page.png` })
let data = await fsPromises.readFile("/tmp/page.png")
await browser.close()
return context
.status(200)
.headers({"Content-type": "image/png"})
.succeed(data)
}
部署函数:
faas-cli up -f banner-gen.yml
用法示例:
curl -G "http://127.0.0.1:8080/function/generate-banner" \
--data-urlencode "avatar=https://avatars2.githubusercontent.com/u/6358735?s=160&v=4" \
--data-urlencode "title=Time for your favourite website to get social banners" \
-o out.png
请注意,查询字符串的输入是 URLEncoded。event.body如果您希望以编程方式而不是从浏览器访问该功能,也可以使用。
这是为我的GitHub 赞助商页面生成的示例图像,该页面使用从磁盘加载的不同 HTML 模板。
部署和 Grafana 仪表板
我们可以使用内置的 Prometheus UI 从我们的函数中观察 RED 指标,或者我们可以部署 Grafana 并访问 OpenFaaS 仪表板。
kubectl -n openfaas run \
--image=stefanprodan/faas-grafana:4.6.3 \
--port=3000 \
grafana
kubectl port-forward pod/grafana 3000:3000 -n openfaas
在 http://127.0.0.1:3000 访问 UI 并使用 admin/admin 登录。
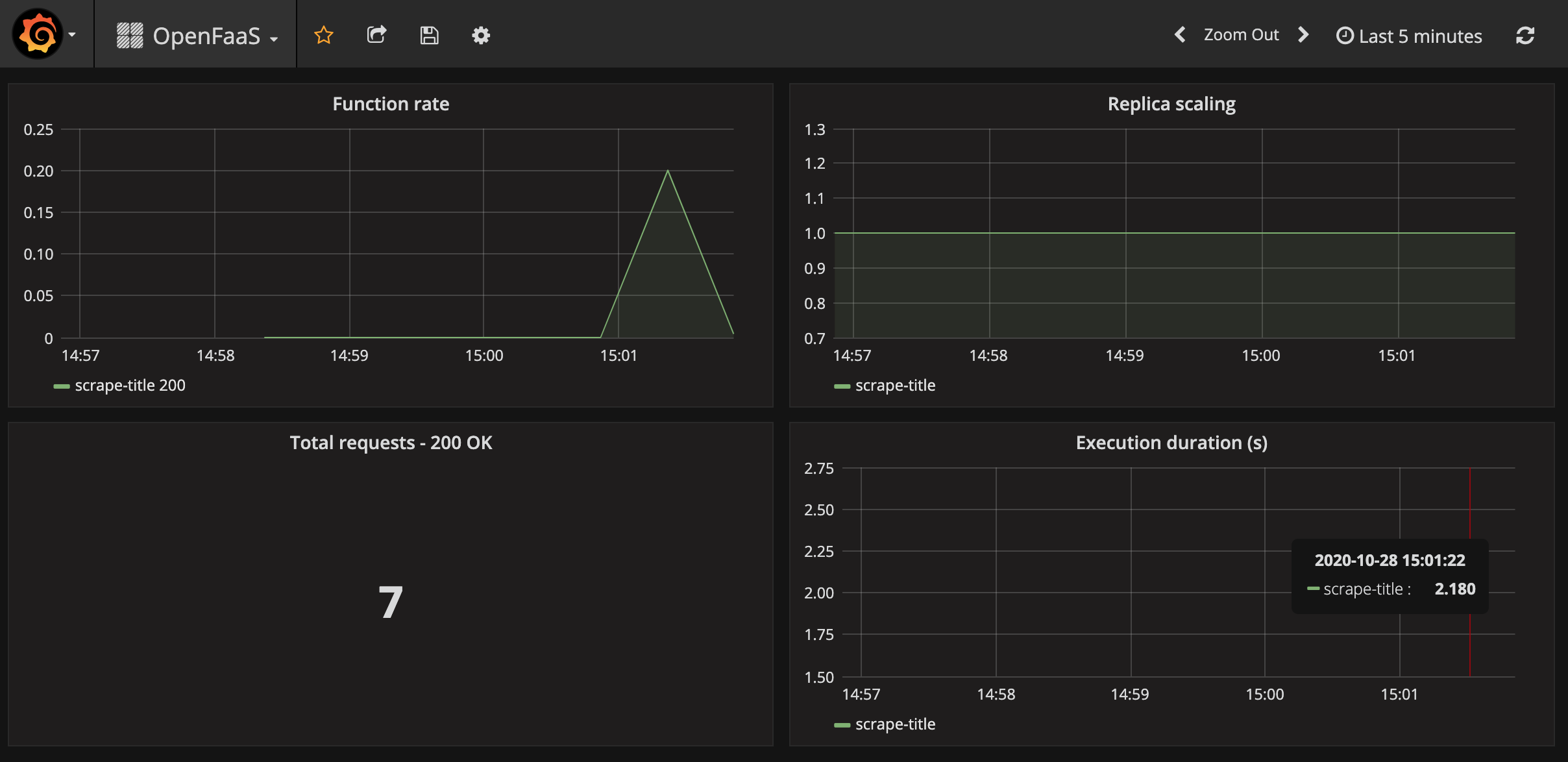
另请参阅:OpenFaaS 指标
强化设置
如果你想限制一次可以打开多少个浏览器,你可以max_inflight在函数的部署文件中设置:
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
scrape-title:
lang: puppeteer-node12
handler: ./scrape-title
image: alexellis2/scrape-title:latest
environment:
max_inflight: 1
还可以在 OpenFaaS 中配置一个单独的队列,以使用您喜欢的一组并行度进行网络抓取。
另请参阅:异步文档
如果您愿意,您还可以对内存设置硬限制:
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
scrape-title:
lang: puppeteer-node12
handler: ./scrape-title
image: alexellis2/scrape-title:latest
limits:
memory: 256Mi
另请参阅:内存限制
超时控制
虽然需要超时值,但此数字可以随您的需要而大。
另请参阅:特色教程:OpenFaaS 中的扩展超时
定时触发
如果您想定期触发该功能,例如生成每周或每日报告,那么您可以使用 cron 语法。
NATS 或 Kafka 的用户也可以直接从事件中触发函数。
另请参阅:OpenFaaS 触发器
总结
您现在拥有使用 Puppeteer 部署自动化测试和网络抓取代码所需的工具。由于 OpenFaaS 可以利用 Kubernetes,您可以使用自动扩展的节点池和比基于云的功能产品通常可用的超时时间长得多的超时。OpenFaaS 与其他功能很好地配合使用,例如支持异步调用的 NATS、收集指标的 Prometheus 以及用于观察吞吐量和持续时间并与团队中的其他人共享系统状态的 Grafana。
docker-puppeteer 和 aws-chrome-lambda 中包含的预编译版 Chrome 无法在 Raspberry Pi 或 ARM64 机器上运行,但它们有可能被重建。为了从 Raspberry Pi 或 ARM64 服务器快速抓取网页,您可以考虑其他选项,例如scrapy。
参考资料
https://bbs.huaweicloud.com/blogs/249264
https://www.redhat.com/zh/topics/cloud-native-apps/what-is-faas
https://puming.zone/post/2021-2-4-主流开源serverless平台openfaas安全性研究/
本文来自博客园,作者:YanceDev,转载请注明原文链接:https://www.cnblogs.com/yance-dev/p/16499438.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号