数据库和ado连接语句的使用总结
基本的sql语句
- 创建数据库:CREATE DATABASE database-name
- 删除数据库:drop database dbname
- 创建表:create table tabname(字段属性)
- 删除表:drop table tabname
- 增加列:Alter table tabname add column col type
- 添加/删除主键:Alter table taname add/drop(删除) primary key(列名)
- 创建索引:create [unique] index idxname on tabname(col….)
- 创建视图:create view viewname as select statement
- 查询:select * from table1 where 范围
- 插入:insert into table1(field1,field2) values(value1,value2)
- 删除:delete from table where 范围
- 更新:update table1 set field1=value1 where 范围
- 模糊查找:select * from table1 where field1 like ’%value%’
- 排序:select * from table order by field1,field2 [desc]
- 总数统计:select count(*) from table
- 求和:select sum(field) as sumvalue from table
- 平均:select avg(field) as avgvalue from table
- 最大最小:select max/min(field) as value from table
- 查询范围值: select * from table1 where time between time1 and time2
- UNION 运算符:请转表的关联查询
- EXCEPT 运算符:请转表的关联查询
- INTERSECT 运算符:请转表的关联查询
- 外连接:请转表的关联查询
- 分组:select age,SUM(age) from BaseTable GROUP BY age
- 复制表(只复制表结构): select * into b from a where 1<>1
- 复制数据: insert into b(列名) select 列名 from b;
索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
索引分为聚簇索引和非聚簇索引两种,聚簇索引 是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
触发器
触发器是一种特殊类型的存储过程,它不同于之前的我们介绍的存储过程。触发器主要是通过事件进行触发被自动调用执行的。触发器对表进行插入、更新、删除的时候会自动执行的特殊存储过程。
触发器分为after触发器,insert触发器, update触发器, delete触发器。
创建触发器语法:
create trigger tgr_name
on table_name
for 触发器类型
AS
数据库执行的语句
触发器实例
在ado数据库创建BaseTable的插入触发器:
在向表BaseTable插入一条记录时,同时触发器会向Table表也插入一条数据作为记录触发器执行成功。


ALTER TRIGGER [dbo].[tgr_name] ON [dbo].[BaseTable] for INSERT AS BEGIN declare @name varchar(20),@id int; select @id = id, @name = name from inserted; set @name = @name + convert(varchar, @id); insert into [Ado].[dbo].[Table] values(@name, 18 + @id); END
储存过程
存储过程Procedure是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。它可以重复调用。当存储过程执行一次后,可以将语句缓存中,这样下次执行的时候直接使用缓存中的语句。这样就可以提高存储过程的性能。
储存过程的优点:存储过程允许标准组件式编程,存储过程能够实现较快的执行速度,存储过程减轻网络流量,存储过程可被作为一种安全机制来充分利用。
系统储存过程:
系统存储过程是系统创建的存储过程,系统存储过程主要存储在master数据库中,以“sp”下划线开头的存储过程,有些也会在创建新数据库的时候自动创建在当前数据库。常用的系统储存过程有:
exec sp_databases; --查看数据库
exec sp_tables; --查看表
exec sp_columns student;--查看列
exec sp_helpIndex student;--查看索引
exec sp_helpConstraint student;--约束
exec sp_stored_procedures;
exec sp_helptext 'sp_stored_procedures';--查看存储过程创建、定义语句
exec sp_rename student, stuInfo;--修改表、索引、列的名称
exec sp_renamedb myTempDB, myDB;--更改数据库名称
exec sp_defaultdb 'master', 'myDB';--更改登录名的默认数据库
exec sp_helpdb;--数据库帮助,查询数据库信息
储存过程的示例调用:
重命名表的名字:exec sp_rename 'tablename', tablename1;
用户自定义储存过程
创建储存过程的语法:
Create proc|procedure proc_name
(
@参数名 类型,
….
)
As
Sql执行语句和一写判断处理
创建示例:
USE [Ado] GO /****** Object: StoredProcedure [dbo].[proc_BaseTable] Script Date: 05/25/2016 17:23:08 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO ALTER PROCEDURE [dbo].[proc_BaseTable](@name varchar(50),@age int) AS BEGIN select * from BaseTable where name=@name select * from BaseTable where age=@age return 10 select * from BaseTable where name=@name and age=@age END
视图
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,我们也可以提交数据,就像这些来自于某个单一的表。
创建视图:create view view_BaseTable as select id,name from BaseTable
数据库文件有一个BaseTableView.Sql文件执行即是此示例。
约束
在此功能上我只在BaseTable表的age字段添加check约束使年龄不能超过50.
约束的属性介绍:
NOT NULL : 用于控制字段的内容一定不能为空(NULL)。
UNIQUE : 控件字段内容不能重复,一个表允许有多个 Unique 约束。
PRIMARY KEY: 也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
FOREIGN KEY: FOREIGN KEY 约束用于预防破坏表之间连接的动作,FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
CHECK: 用于控制字段的值范围。
DEFAULT: 用于设置新记录的默认值。
示例:
NOT NULL :Create table MyTable
(
id varchar(32) not null,
name varchar (32)
)
UNIQUE:Create table MyTable
(
id varchar(32) not null UNIQUE,
name varchar (32)
)
Create table MyTable
(
id varchar(32) not null,
name varchar (32),
unique (id,.....)
)
PRIMARY KEY :Create table MyTable
(
id varchar(32) not null PRIMARY KEY,
name varchar (32)
)
Foreign Key :Create table MyTable
(
id nvarchar(32) not null primary key,
name nvarchar(32),
foreign key(id) references myTB(id)
)
Check :Create table MyTable
(
id nvarchar(32) not null,
age int not null,
check (age>15 and age <30)
)
Default:Create table MyTable
(
id int,
name nvarchar(32) default 'celly'
)
游标
游标是一种能从包含多条数据记录的结果集中每次提取一条记录的机制。将批操作变成行操作,对结果集中得某行进行操作。
数据库文件BaseTableCsr.sql是游标示例。查询BaseTable表的id与name字段循环打印出来。
表的关联查询
内连接:
只根据表查找符合添加的,不返回所有表数据。
示例代码:
select * from BaseTable join tabname on BaseTable.id=tabname.id
效果图
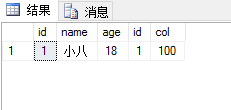
左连接查询:
以左表为主第二张表加入有符合条件的则显示数据,没有则第二张表全部为空
示例代码
select * from BaseTable left join tabname on BaseTable.id=tabname.id
效果图:
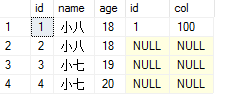
右链接查询:
以右表为主查找符合的数据,没有符合项左表显示为空
示例代码:
select * from BaseTable right join tabname on BaseTable.id=tabname.id
效果图:
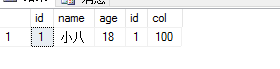
完全外连接:
查找的表所有的数据合并成一张表进行显示
示例代码:
select * from BaseTable full join tabname on BaseTable.id=tabname.id
效果图(tabname表只有一条数据):

交叉连接:
没有where语句的交叉连接产生的是两张表行数的乘积数据,如果带where的结果与内连接的结果相同。
示例代码:
select * from BaseTable cross join tabname
效果图:

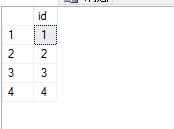
UNION运算:
分为UNION(检查重复)和UNION all(不检查重复)
检查重复示例代码:
select id from BaseTable union select id from Tables
效果图:
不检查重复代码:
select id from BaseTable union all select id from Tables
效果图:

EXCEPT运算:
从左查询中返回有右查询中没有找到的不重复项
示例代码:
select id from BaseTable except select id from tabname
效果图:

INTERSECT运算:
返回两个表都有的非重复项
示例代码:
select id From BaseTable intersect select id from tabname
效果图:

ADO
连接字符串常用属性
1、 Data Source:数据源。计算机名称或者IP地址。
2、 Server:服务器。数据库所在计算机的名称
3、 Database:数据库名称。
4、 Initail Catalog:数据库的名称。
5、 User ID:用于连接数据库的用户名称。
6、 Password:用于连接数据库的用户密码。
7、 Pooling:标志是否使用数据库连接池(少客户访问启用可以提高性能)。
8、 Intergrated Security:系统集成安全验证。标志登录数据库时是否使用系统集成验证。
9、 Connection Timeout:连接超时的时间。系统再次尝试连接数据库时所经历的时间,单位为秒,默认值为15秒。
在程序中的事务操作
首先创建事物:SqlTransaction st = conn.BeginTransaction();
开始事物(即事物的赋值):cmd.Transaction = st;
提交事务:st.Commit();
回滚事务:st.Rollback();
假如要创建某个事物保存点可以使用:st.save();
根据事物操作可以做事物回滚的批量插入,修改操作,有一条不正确即可实现事物回滚,具体请看dome代码详细介绍。
调用储存过程
使用在数据库创建的储存过程在dome中通过ado进行调用,并得到返回的表。
示例代码:

注意点:在调用储存过程中,加入你的存储过程涉及到大量的操作,查询什么的,而你只需要返回其中的某个一条查询记录,需要在储存过程中找到需要返回的语句加上return ,这样在程序中调用只会返回本条语句结果。
sql语句生成id字段
REPLACE(CAST(CAST(NEWID() as binary(10)) + CAST(GETDATE() as binary(6)) as uniqueidentifier),'-','')
查询数据库的数据文件及日志文件的大小
查询出来的单位为MB
select name, convert(float,size) * (8192.0/1024.0)/1024. from 数据库名称.dbo.sysfiles
作者:YanBigFeg —— 颜秉锋
出处:http://www.cnblogs.com/yanbigfeg
本文版权归作者和博客园共有,欢迎转载,转载请标明出处。如果您觉得本篇博文对您有所收获,觉得小弟还算用心,请点击右下角的 [推荐],谢谢!

