01.Scrapy-入门
Scrapy快速入门
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,它使用Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。个人认为Scrapy是Python世界里面最强大的爬虫框架,没有之一,它比BeautifulSoup更加完善,BeautifulSoup可以说是轮子,而Scrapy则是车子,不需要你关注太多细节,Scrapy不仅支持Python2.7,Python3也支持。
- scrapy是框架,类似于车子,会开车。
- 采用异步框架,实现高效率的网络采集。
- 最强大的框架,没有之一。
安装和文档:
- 安装:通过
pip install Scrapy即可安装。 - Scrapy官方文档:http://doc.scrapy.org/en/latest
- Scrapy中文文档:https://www.osgeo.cn/scrapy/
注意:
1 在ubuntu上安装scrapy之前,需要先安装以下依赖:
sudo apt-get install python-dev python-pip libxml2-dev libxslt-dev zliblg-dev libffi-dev libssl-dev,然后在通过pip install scrapy安装。2 如果在
windows系统下,提示这个错误ModuleNotFoundError:No module named 'win32api',那么使用以下命令可以解决:
pip install pypiwin32或pip install pywin32遇到问题
VC++14.0 Twisted解决办法:离线安装twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pip install xxx.whl [twsited.whl的路径]安装完成执行
scrapy bencn运行测试
Scrapy原理
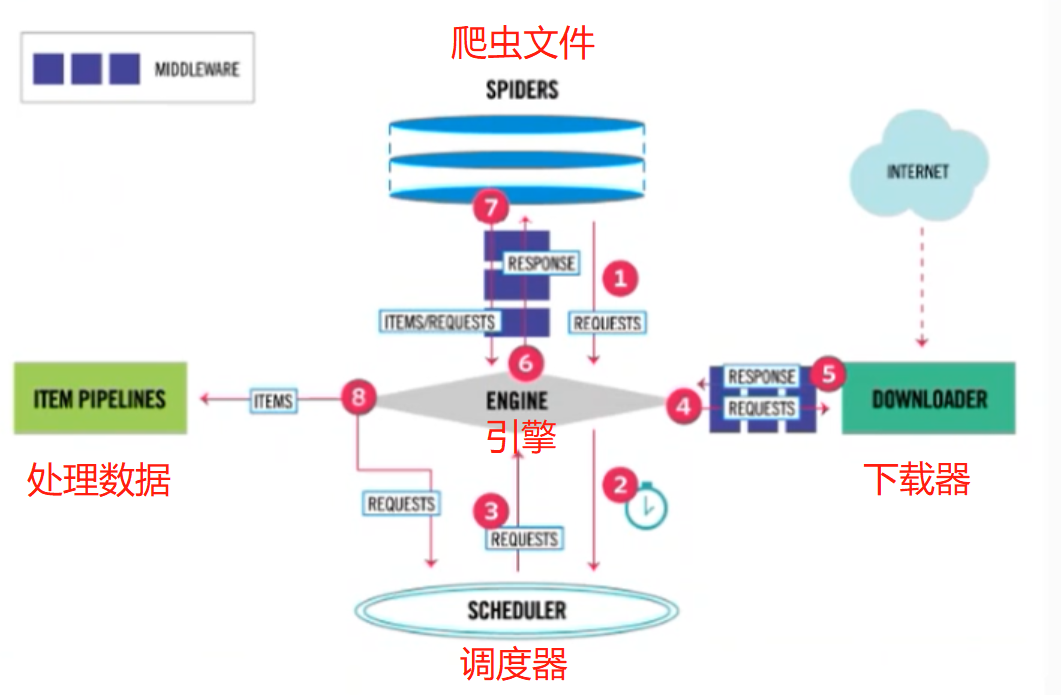
Scrapy主要包含以下组件:
- 引擎:处理整个系统的数据流,触发事务(框架核心)
- 调度器:用来接收引擎发过来的请求,压入队列中,并在引擎在此请求的时候返回,由它来决定下一个要抓取的网址是什么,同时去除重复的网址。
- 下载器:用于下载网页内容,并将网页内容返回给蜘蛛。
- Scrapy下载器是建立在Twisted这个搞笑的异步模型上的。
- 爬虫:爬虫主要是干活的,用于从特定的网页中提取自己需要的信息,即所谓的实体。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
- 项目管道:负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清楚不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件:位于Scrapy引擎和下载器直接的框架,主要是处理Scrapy引擎与下载器直接的请求及响应。
- 爬虫中间件:介于Scrapy引擎和爬虫直接的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件:介于Scrapy引擎和调度器直接的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy的运行流程大概如下
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
创建项目
Windows下,打开命令提示符窗口,进入到打算存储代码的目录中,使用下面的命令创建一个scrapy项目
scrapy startproject 项目名
项目结构
scrapy.cfg:项目的配置文件- 项目名/:该项目的python模块。之后我们将在此加入代码。
- 项目名/
items.py:用来存放爬虫爬取下来数据的模型。 - 项目名/
pipelines.py:用来将items的模型存储到本地磁盘中。 - 项目名/
settings.py: 本爬虫的一些配置信息(比如请求头、多久发送一次请求、ip代理池等)。 - 项目名/
middlewares.py: 用来存放各种中间件的文件。 - 项目名/spiders包:以后所有的爬虫,都是存放到这个里面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号