Python第六章-函数06-高阶函数
函数的高级应用
二、高阶函数
高级函数, 英文叫 Higher-order Function.
那么什么是高阶函数呢?
在说明什么是=高阶函数之前, 我们需要对函数再做进一步的理解!
2.1 函数的本质
函数的本质是什么?
函数和函数名到底是一种什么关系?
在python中,一切皆对象,那么函数也不例外,也是一种对象。
从本质上看,一个函数与一个整数没有本质区别,仅仅是他们的数据类型不同而已!
看下面的代码:
def foo():
pass
print(foo) # 这里只打印了函数名, 并没有调用 foo 函数
print(abs) # 直接打印内置函数, 而没有调用

说明:
- 从结果可以看出来, 直接把函数本身打印出来了, 自定义的函数与
at后面的可以理解成函数在内存中的地址 - 如果是 python 内置函数会告诉你这是个内置函数.
- 你可以把函数想象中以前的数字一样, 仅仅表示内存中的一个对象.
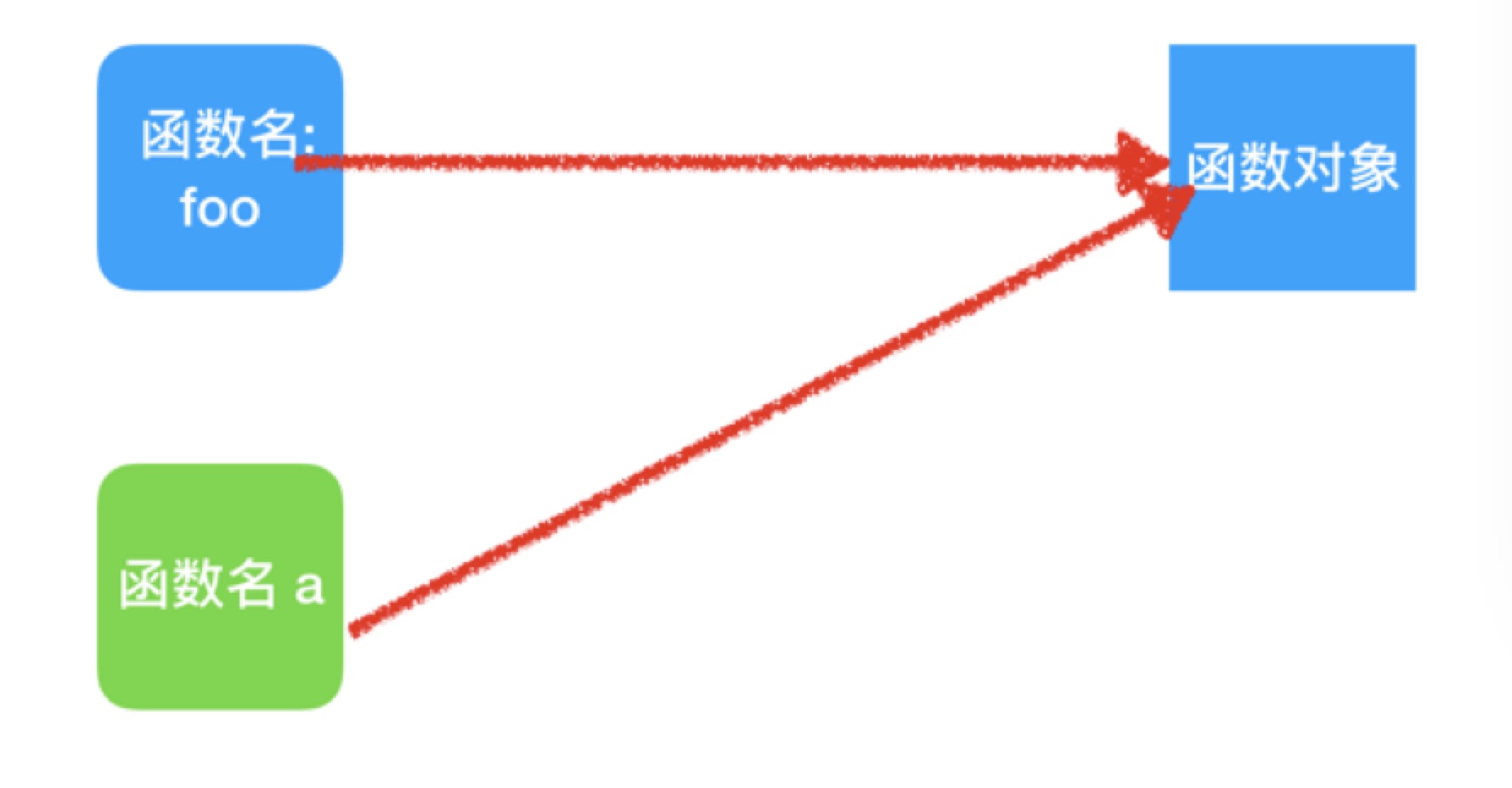
函数名和函数的关系
其实函数名和以前的变量名没有本质的区别, 变量名是指向对象的一个符号, 那么函数名也是指向对象的一个符号.

动态把函数名赋值给新变量
函数名其实就是一个指向函数对象的变量.
那么我们是不是可以再创建一个变量也指向那个函数对象呢?
答案是肯定的!
def foo():
print("我是 foo 函数内的代码")
a = foo
print(a)
print(foo)
a()

说明:
- 你会发现直接打印
a 和 foo的结果完全一样, 证明他们确实是指向了同一个函数对象 - 调用
a()执行的就是foo函数内的代码. 因为他们其实就是一个对象.
给函数名重新赋值
既然函数名是变量名, 那么函数名也应该可以重新赋值!
def foo():
print("我是 foo 函数内的代码")
foo = 3
foo()

说明:
因为函数名已经被赋值为了整数,所以再调用就会抛出异常.
2.2 高阶函数
通过前面的了解, 我们已经知道函数名其实仅仅是一个普普通通的变量名而已.
那么是不是也意味着:函数也可以作为参数传递呢?
答案是肯定的!
一个可以接收函数作为参数的函数就是高阶函数!
一个最简单的高阶函数
def foo(x, y, f): # f 是一个函数
"""
把 x, y 分别作为参数传递给 f, 最后返回他们的和
:param x:
:param y:
:param f:
:return:
"""
return f(x) + f(y)
def foo1(x):
"""
返回参数的 x 的 3次方
:param x:
:return:
"""
return x ** 3
r = foo(4, 2, foo1)
print(r) # 72
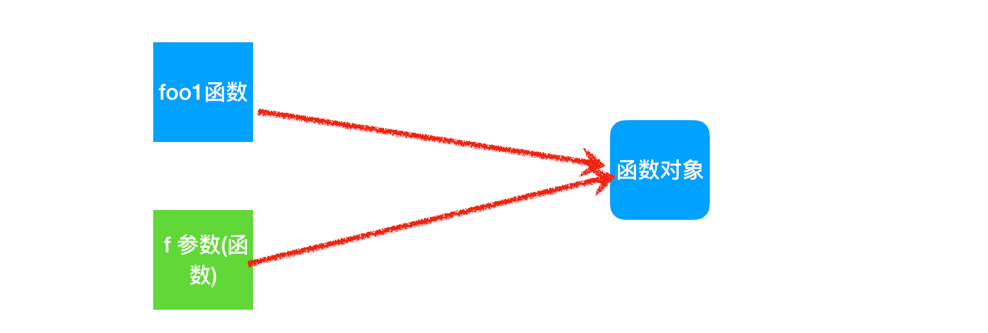
说明:
-
这里的
foo就是高阶函数, 因为他接收了一个函数作为参数. -
foo1作为参数传递给了foo, 而且foo中的局部变量f接收了foo传递过来的数据, 那么最终是foo和f同时指向了同一个对象.
总结
编写高阶函数,就是让函数的参数能够接收其他的函数。
把函数作为参数传入,这样的函数称为高阶函数,函数式编程就是指这种高度抽象的编程范式。
2.3 高阶函数另一种形式:把函数作为返回值
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
def foo():
x = 10
def temp():
nonlocal x
x += 10 #x=x+10
return x
return temp
f = foo()
print(f())
print(f())

说明:
- 调用
foo()得到的一个函数, 然后把函数赋值给变量f, 这个时候f和foo内部的temp其实指向了同一个函数对象. - 返回的函数每调用一次都会把
foo的局部变量x增加 10 .所以两次调用分别得到 20 和 30. - 返回访问了外部函数的局部变量或者全局变量的函数,这种函数就是闭包.
2.4 内置高阶函数
高阶函数在函数式编程语言中使用非常的广泛.
本节简单介绍几个常用的高阶函数.
列表的排序, map/reduce, filter等
2.4.1 排序sort()
2.41 sort()默认排序
到目前为止, 大家应该对列表已经比较熟悉了: 列表是有序, 允许重复.
注意:这里的有序是指的元素的添加顺序和迭代顺序一致.
但是我如果想对列表中的元素按照一定的规则排序该怎么做?
每个list实例都有有一个方法list.sort()可以帮我们完成这个工作.
sort() 默认对列表中的每个元素使用<进行比较,小的在前,大的在后.
也就是默认是升序排列
nums = [20, 10, 4, 5, 3, 9]
nums.sort()
print(nums)

2.4.2 更改排序规则
比如, 列表中存储的是字符串, 大小写都有, 默认是按照字母表顺序来排列.
但是我们如果想忽略大小写的进行排列. 那么默认排序就无法满足我们的需求了
这个时候就需要用到key这个参数
key必须是一个函数, 则排序的时候, python 会根据这个函数的返回值来进行排序.
ss = ["aa", "Aa", "ab", "Ca", "da"]
def sort_rule(ele):
return ele.lower()
ss.sort(key=sort_rule)
print(ss)

2.4.3 更改为降序
默认, 添加规则之后都是使用的升序排列.
如果需要降序排列, 则需要另外一个关键字参数 reverse
意思是问, 是否反序, 只要给 True 就表示降序了, 默认是 None
ss = ["aa", "Aa", "ab", "Ca", "da"]
def sort_rule(ele):
return ele.lower()
ss.sort(key=sort_rule, reverse=True)
print(ss)

2.4.2 map()和filter()
函数编程语言通常都会提供map, filter, reduce三个高阶函数.
在python3中, map和filter仍然是内置函数, 但是由于引入了列表推导和生成器表达式, 他们变得没有那么重要了.
列表推导和生成器表达式具有了map和filter两个函数的功能, 而且更易于阅读.
2.4.2.1 map
a = map(lambda x: x ** 2, [10, 20, 30, 40])
print(list(a))
print(type(a))

说明:
map函数是利用已有的函数和可迭代对象生成一个新的可迭代类型:map类型map的参数1是一个函数, 参数2是一个可迭代类型的数据.map会获取迭代类型的每个数据, 传递给参数1的函数, 然后函数的返回值组成新的迭代类型的每个元素- 也可以有多个迭代器, 则参数1的函数的参数个数也会增加.
- 新生成的迭代器类型的元素的个数, 会和最短的那个迭代器的元素的个数保持一致.
a = map(lambda x, y: x + y, [10, 20, 30, 40], [100, 200])
print(list(a))

使用列表推倒实现上面的功能
使用列表比map优雅了很多, 而且也避免了参数1的函数
list1 = [10, 20, 30, 40]
list3 = [x ** 2 for x in list1]
print(list3)

list1 = [10, 20, 30, 40]
list2 = [100, 200]
# 注意:列表推倒中这里是使用的笛卡尔积
list3 = [x + y for x in list1 for y in list2]
print(list3)
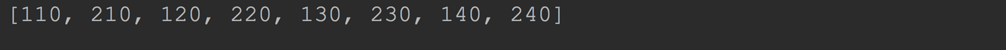
2.4.2.2 filter
对已有的可迭代类型起过滤作用, 然后生成新的可迭代类型
用法和map类型, 参数1也是函数, 会把当返回值为True的元素添加到新的可迭代类型中.
list1 = [0, 1, 3, 4, 9, 4, 7]
# 把奇数元素取出来
print(list(filter(lambda x: x % 2 == 1, list1)))
# 列表推倒的版本
list2 = [x for x in list1 if x % 2 == 1]
print(list2)

2.4.2.3 reduce
python 3中, reduce不再是直接的内置函数, 而是移到了模块functiontools内.
reduce的作用, 就是把一个可迭代序列的每一元素应用到一个具有两个参数的函数中.
例如:
reduce(lambda x, y: x+y, [1, 2, 3, 4, 5])就是计算((((1+2)+3)+4)+5)
from functools import reduce
def f(x, y):
print("x=", x, "y=", y)
return x + y
"""
参数1: 具有两个参数的函数
参数1:前面计算过的值 参数2:从可迭代类型中取得的新的值
参数2: 可迭代类型的数据
参数3: x的初始值, 默认是0
"""
r = reduce(f, [1, 2, 3, 4, 5], 0)
print(r) # 15

示例代码:使用reduce计算阶乘
from functools import reduce
def factorial(n):
"""计算n的阶乘
:param n:
:return:
"""
return reduce(lambda x, y: x * y, range(1, n + 1), 1)
print(factorial(5))
print(factorial(6))
print(factorial(7))

三、闭包
在函数编程语言中, 闭包是一个比较重要且强大的特性.
python 也支持闭包.
什么是闭包?
如果一个函数使用了外部函数的局部变量, 那么这个函数就是一个闭包.
闭包的特点:
- 闭包函数可以访问他所在的外部函数的局部变量. 即使外部函数已经运行结束, 对闭包函数来说仍然可以访问到外部函数的局部变量
- 闭包访问外部函数的局部变量的值, 总是这个变量的最新的值!
3.1.定义一个闭包
def outer():
x = 20
def inner():
"""
inner 函数访问了外部函数 outer 的局部变量 x, 所以这个时候 inner
就是一个闭包函数.
:return:
"""
nonlocal x
x += 10
return x
x = 30
return inner
# 调用 outer, 得到的是内部的闭包函数 inner 所以 f 和 inner 其实指向了同一个函数对象
f = outer()
'''
调用 f. f是一个闭包函数,所以他访问的总是外部变量的最新的值,
所以 f 执行的时候 x 的值已经是30. 最终返回的是40
'''
print(f())

3.2.闭包的应用
闭包很强大, 也有一些比较适合的场景!
惰性求值(lazy evaluation, 延迟求值)
def foo(msg):
def say_msg():
print("hello" + str(msg))
return say_msg
say = foo("志玲")
say()
说明:
上面的代码中foo函数仅仅是声明了一个嵌套函数, 和把这个嵌套函数返回.
真正的代码其实是定义在了内部的嵌套函数中.
这种写法就是一种惰性求值!
使用闭包保持状态
如果需要在一系列函数调用中保持某种状态, 使用闭包是一种非常高效的方法.
一个简单的计数器:
def count_down(num):
def next():
nonlocal num
temp = num
num -= 1
return temp
return next
# 使用前面的函数计数
next = count_down(10)
while True:
value = next() # 每调用一次就会减少一次计数
print(value)
if value == 0:
break

还有一些其他应用, 比如装饰器
四、装饰器
装饰器也是应用闭包的一种场景.
什么是装饰器?
如果一个函数已经定义完成, 需要在不修改这个函数源码的前提下给这个函数增加一些功能, 这个时候就可以使用装饰器.
装饰器本质上是一个函数, 其主要用途是包装另一个函数或类.
包装的主要目的是透明地修改和增强被包装对象的行为.
4.1定义装饰器
装饰器可以用在方法上, 也可以用在类上.
目前我们只研究方法装饰器
其实装饰器和 java 中的注解有点像, 但是比 java 的注解容易使用了很多.
如果我们要给函数hello使用装饰器的方式增强功能, 语法如下:
@strong
def hello():
print("我是 hello 函数中的代码")
说明:
- 在需要添加的装饰函数上面一行使用
@来添加装饰器 @后面紧跟中装饰器名strong, 当然你可以定于任何的名字.strong是装饰器, 本质上是一个函数. 他接收函数hello作为参数, 并返回一函数来替换掉hello(当然也可以不替换).hello使用装饰器之后, 相当于hello函数使用下面的代码被替换掉了.hello = strong(hello)- 在调用
hello的时候, 其实是调用的strong()返回的那个函数.
def strong(fun): # fun 将来就是被替换的 hello
def new_hello():
print("我是装饰器中的代码, 在 hello 之前执行的")
fun()
print("我是装饰器中的代码, 在 hello 之后...执行的")
return new_hello
@strong
def hello():
print("我是 hello 函数中的代码")
# 这里调用的其实是装饰器返回的函数.
hello()

装饰器是语法糖
严格来讲, 装饰器只是语法糖.
装饰器就是一函数, 其参数是被装饰的函数.
综上, 装饰器的一大特性就是把装饰的函数替换成其他函数, 第二大特性就是装饰函数在加载模块的时候就立即执行了.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号